How High Pass Filters Optimize Optical Character Recognition Accuracy
JUL 28, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
OCR Accuracy Enhancement Goals
Optical Character Recognition (OCR) technology has made significant strides in recent years, yet accuracy remains a critical challenge in various applications. The primary goal of enhancing OCR accuracy is to improve the system's ability to correctly identify and interpret text from diverse sources, including printed documents, handwritten notes, and digital images. This objective is driven by the increasing demand for efficient and reliable text digitization across multiple industries.
One of the key aims in OCR accuracy enhancement is to reduce error rates in character recognition, particularly in complex scenarios such as low-quality images, varied fonts, or multilingual documents. By minimizing misidentifications and false positives, OCR systems can provide more dependable outputs, crucial for applications in legal, medical, and financial sectors where precision is paramount.
Another important goal is to improve the robustness of OCR systems against various environmental factors and image distortions. This includes enhancing performance under challenging conditions such as poor lighting, skewed text, or background noise. Achieving this would significantly expand the practical applications of OCR technology, making it more versatile and adaptable to real-world scenarios.
Increasing the speed of OCR processing without compromising accuracy is also a vital objective. As the volume of data requiring digitization continues to grow, there is a pressing need for OCR systems that can handle large-scale document processing efficiently. This goal aligns with the broader trend of digital transformation across industries, where rapid and accurate data extraction is essential.
Furthermore, there is a focus on developing more context-aware OCR systems. This involves improving the technology's ability to understand and interpret text within its broader context, including layout analysis and semantic comprehension. Such advancements would enable OCR systems to not only recognize individual characters but also understand document structure and content relationships.
Lastly, a significant goal in OCR accuracy enhancement is to develop more adaptive and self-learning systems. This involves incorporating machine learning and artificial intelligence techniques to create OCR solutions that can continuously improve their performance over time, learning from new data and adapting to different document types and languages without extensive manual reconfiguration.
One of the key aims in OCR accuracy enhancement is to reduce error rates in character recognition, particularly in complex scenarios such as low-quality images, varied fonts, or multilingual documents. By minimizing misidentifications and false positives, OCR systems can provide more dependable outputs, crucial for applications in legal, medical, and financial sectors where precision is paramount.
Another important goal is to improve the robustness of OCR systems against various environmental factors and image distortions. This includes enhancing performance under challenging conditions such as poor lighting, skewed text, or background noise. Achieving this would significantly expand the practical applications of OCR technology, making it more versatile and adaptable to real-world scenarios.
Increasing the speed of OCR processing without compromising accuracy is also a vital objective. As the volume of data requiring digitization continues to grow, there is a pressing need for OCR systems that can handle large-scale document processing efficiently. This goal aligns with the broader trend of digital transformation across industries, where rapid and accurate data extraction is essential.
Furthermore, there is a focus on developing more context-aware OCR systems. This involves improving the technology's ability to understand and interpret text within its broader context, including layout analysis and semantic comprehension. Such advancements would enable OCR systems to not only recognize individual characters but also understand document structure and content relationships.
Lastly, a significant goal in OCR accuracy enhancement is to develop more adaptive and self-learning systems. This involves incorporating machine learning and artificial intelligence techniques to create OCR solutions that can continuously improve their performance over time, learning from new data and adapting to different document types and languages without extensive manual reconfiguration.
Market Demand for Improved OCR Solutions
The demand for improved Optical Character Recognition (OCR) solutions has been steadily increasing across various industries. As businesses and organizations continue to digitize their operations, the need for accurate and efficient text recognition systems has become paramount. High-quality OCR technology is essential for converting scanned documents, images, and handwritten text into machine-readable formats, enabling faster processing, improved searchability, and enhanced data management.
In the financial sector, banks and insurance companies require robust OCR solutions to process vast amounts of paperwork, including loan applications, claims forms, and identity documents. The ability to accurately extract information from these documents can significantly reduce processing times and minimize errors, leading to improved customer satisfaction and operational efficiency.
Healthcare organizations are another major driver of demand for advanced OCR technology. With the ongoing transition to electronic health records (EHR), there is a critical need for systems that can accurately digitize patient records, medical reports, and prescription information. Improved OCR accuracy can help reduce medical errors, enhance patient care, and streamline administrative processes.
The legal industry also presents a significant market for enhanced OCR solutions. Law firms and courts handle enormous volumes of documents, including contracts, case files, and legal precedents. Accurate text recognition is crucial for efficient case management, legal research, and compliance with document retention regulations.
Government agencies and educational institutions are increasingly adopting OCR technology to manage archives, process forms, and digitize historical documents. The ability to accurately convert these materials into searchable digital formats can greatly improve accessibility and preservation efforts.
E-commerce and retail sectors are leveraging OCR for inventory management, product cataloging, and receipt processing. Improved accuracy in these areas can lead to better stock control, reduced data entry errors, and enhanced customer service.
The growing trend of mobile document scanning and capture has further fueled the demand for high-performance OCR solutions. Consumers and professionals alike expect mobile applications to quickly and accurately extract text from images captured by smartphone cameras, highlighting the need for OCR systems that can handle diverse lighting conditions and image qualities.
As businesses continue to prioritize automation and digital transformation initiatives, the market for improved OCR solutions is expected to expand further. The integration of OCR with other technologies such as artificial intelligence and machine learning is likely to drive innovation in this space, creating opportunities for more accurate, versatile, and intelligent text recognition systems.
In the financial sector, banks and insurance companies require robust OCR solutions to process vast amounts of paperwork, including loan applications, claims forms, and identity documents. The ability to accurately extract information from these documents can significantly reduce processing times and minimize errors, leading to improved customer satisfaction and operational efficiency.
Healthcare organizations are another major driver of demand for advanced OCR technology. With the ongoing transition to electronic health records (EHR), there is a critical need for systems that can accurately digitize patient records, medical reports, and prescription information. Improved OCR accuracy can help reduce medical errors, enhance patient care, and streamline administrative processes.
The legal industry also presents a significant market for enhanced OCR solutions. Law firms and courts handle enormous volumes of documents, including contracts, case files, and legal precedents. Accurate text recognition is crucial for efficient case management, legal research, and compliance with document retention regulations.
Government agencies and educational institutions are increasingly adopting OCR technology to manage archives, process forms, and digitize historical documents. The ability to accurately convert these materials into searchable digital formats can greatly improve accessibility and preservation efforts.
E-commerce and retail sectors are leveraging OCR for inventory management, product cataloging, and receipt processing. Improved accuracy in these areas can lead to better stock control, reduced data entry errors, and enhanced customer service.
The growing trend of mobile document scanning and capture has further fueled the demand for high-performance OCR solutions. Consumers and professionals alike expect mobile applications to quickly and accurately extract text from images captured by smartphone cameras, highlighting the need for OCR systems that can handle diverse lighting conditions and image qualities.
As businesses continue to prioritize automation and digital transformation initiatives, the market for improved OCR solutions is expected to expand further. The integration of OCR with other technologies such as artificial intelligence and machine learning is likely to drive innovation in this space, creating opportunities for more accurate, versatile, and intelligent text recognition systems.
High Pass Filters in OCR: Current State
High pass filters have become an integral component in modern Optical Character Recognition (OCR) systems, significantly enhancing the accuracy and reliability of text recognition. These filters are primarily used in the preprocessing stage of OCR to improve image quality by emphasizing high-frequency components while attenuating low-frequency elements.
In the current state of OCR technology, high pass filters are employed to address several key challenges. Firstly, they effectively reduce background noise and eliminate gradual variations in illumination across the image. This is particularly crucial for documents with uneven lighting or those captured under suboptimal conditions. By suppressing these low-frequency disturbances, high pass filters help isolate the text from its background, making it more distinguishable for subsequent processing steps.
Another significant application of high pass filters in OCR is edge enhancement. Text characters are typically characterized by sharp transitions between foreground and background, which correspond to high-frequency image components. By amplifying these high-frequency elements, high pass filters accentuate the edges of characters, improving their definition and making them more easily detectable by OCR algorithms.
The implementation of high pass filters in OCR systems varies, with both spatial and frequency domain approaches being utilized. In the spatial domain, simple high pass filters like the Laplacian filter or the Sobel operator are commonly used. These filters operate directly on the image pixels, computing local differences to highlight rapid intensity changes. In the frequency domain, high pass filtering is achieved through Fourier transform techniques, allowing for more precise control over the frequency components that are enhanced or suppressed.
Recent advancements in OCR technology have seen the integration of adaptive high pass filtering techniques. These methods dynamically adjust filter parameters based on local image characteristics, providing optimal enhancement for different regions of the document. This adaptivity is particularly beneficial for processing complex documents with varying text sizes, fonts, and background patterns.
The effectiveness of high pass filters in OCR has been further improved by combining them with other image processing techniques. For instance, many systems now employ a combination of high pass filtering and binarization to achieve superior text segmentation. Additionally, the use of machine learning algorithms to optimize filter parameters for specific document types has shown promising results in enhancing OCR accuracy.
While high pass filters have significantly contributed to the advancement of OCR technology, challenges remain. One notable issue is the potential amplification of high-frequency noise, which can sometimes lead to the detection of false character edges. Ongoing research is focused on developing more sophisticated filtering techniques that can better differentiate between genuine character edges and noise, further improving the robustness of OCR systems.
In the current state of OCR technology, high pass filters are employed to address several key challenges. Firstly, they effectively reduce background noise and eliminate gradual variations in illumination across the image. This is particularly crucial for documents with uneven lighting or those captured under suboptimal conditions. By suppressing these low-frequency disturbances, high pass filters help isolate the text from its background, making it more distinguishable for subsequent processing steps.
Another significant application of high pass filters in OCR is edge enhancement. Text characters are typically characterized by sharp transitions between foreground and background, which correspond to high-frequency image components. By amplifying these high-frequency elements, high pass filters accentuate the edges of characters, improving their definition and making them more easily detectable by OCR algorithms.
The implementation of high pass filters in OCR systems varies, with both spatial and frequency domain approaches being utilized. In the spatial domain, simple high pass filters like the Laplacian filter or the Sobel operator are commonly used. These filters operate directly on the image pixels, computing local differences to highlight rapid intensity changes. In the frequency domain, high pass filtering is achieved through Fourier transform techniques, allowing for more precise control over the frequency components that are enhanced or suppressed.
Recent advancements in OCR technology have seen the integration of adaptive high pass filtering techniques. These methods dynamically adjust filter parameters based on local image characteristics, providing optimal enhancement for different regions of the document. This adaptivity is particularly beneficial for processing complex documents with varying text sizes, fonts, and background patterns.
The effectiveness of high pass filters in OCR has been further improved by combining them with other image processing techniques. For instance, many systems now employ a combination of high pass filtering and binarization to achieve superior text segmentation. Additionally, the use of machine learning algorithms to optimize filter parameters for specific document types has shown promising results in enhancing OCR accuracy.
While high pass filters have significantly contributed to the advancement of OCR technology, challenges remain. One notable issue is the potential amplification of high-frequency noise, which can sometimes lead to the detection of false character edges. Ongoing research is focused on developing more sophisticated filtering techniques that can better differentiate between genuine character edges and noise, further improving the robustness of OCR systems.
Existing High Pass Filter Implementations
01 Filter design optimization
High-pass filter accuracy can be improved through optimized design techniques. This includes careful selection of components, precise circuit layout, and advanced simulation tools to predict and fine-tune filter performance. Optimization methods may focus on minimizing parasitic effects, reducing noise, and enhancing frequency response characteristics.- Filter design optimization: High-pass filter accuracy can be improved through optimized design techniques. This includes careful selection of components, precise circuit layout, and advanced modeling techniques to minimize parasitic effects and improve frequency response. Optimization algorithms and computer-aided design tools can be used to fine-tune filter parameters for enhanced performance.
- Digital signal processing techniques: Digital signal processing (DSP) techniques can be applied to enhance the accuracy of high-pass filters. These methods involve implementing filters in the digital domain, allowing for more precise control over filter characteristics. Adaptive filtering algorithms and real-time parameter adjustment can be used to compensate for variations and improve overall filter performance.
- Calibration and compensation methods: Calibration and compensation techniques can significantly improve high-pass filter accuracy. These methods involve measuring and correcting for inherent errors in the filter response, such as offset voltages, gain variations, and temperature-related drift. Automated calibration routines and built-in self-test features can be implemented to maintain filter accuracy over time and environmental conditions.
- Advanced semiconductor technologies: Utilizing advanced semiconductor technologies can enhance the accuracy of high-pass filters. This includes the use of high-precision analog components, low-noise amplifiers, and specialized integrated circuits designed for filter applications. Advanced fabrication processes can reduce component tolerances and improve overall filter performance.
- Hybrid analog-digital approaches: Combining analog and digital filtering techniques can lead to improved accuracy in high-pass filters. This hybrid approach leverages the strengths of both domains, using analog components for initial filtering and digital processing for fine-tuning and error correction. Such systems can offer enhanced flexibility and adaptability while maintaining high accuracy across a wide range of operating conditions.
02 Digital signal processing techniques
Implementing digital signal processing (DSP) techniques can significantly enhance high-pass filter accuracy. DSP allows for more precise control over filter characteristics, adaptive filtering, and real-time adjustments. These methods can compensate for analog component variations and environmental factors, resulting in more consistent and accurate filtering performance.Expand Specific Solutions03 Advanced semiconductor technologies
Utilizing advanced semiconductor technologies, such as high-precision analog-to-digital converters (ADCs) and specialized integrated circuits, can improve high-pass filter accuracy. These technologies offer better linearity, lower noise, and higher resolution, enabling more accurate signal processing and filtering.Expand Specific Solutions04 Calibration and compensation techniques
Implementing calibration and compensation techniques can enhance high-pass filter accuracy. This may involve periodic self-calibration routines, temperature compensation, and adaptive algorithms to adjust filter parameters in response to changing conditions or aging effects. These methods help maintain consistent performance over time and across different operating environments.Expand Specific Solutions05 Novel filter architectures
Developing and implementing novel filter architectures can lead to improved high-pass filter accuracy. This may include hybrid analog-digital designs, distributed filter structures, or the use of unconventional materials and components. These innovative approaches can overcome limitations of traditional filter designs and offer superior performance in specific applications.Expand Specific Solutions
Key Players in OCR Technology
The high pass filter optimization for optical character recognition (OCR) accuracy is in a mature stage of development, with a significant market size due to widespread applications in document digitization and text extraction. The technology has reached a high level of maturity, with major players like Microsoft, Sony, and Panasonic leading innovation. These companies have extensive research and development capabilities, allowing them to refine algorithms and improve filter performance. The competitive landscape is characterized by established tech giants and specialized imaging companies like Nikon and Fujifilm, who leverage their expertise in optics and image processing to enhance OCR solutions. As the demand for accurate text recognition continues to grow across industries, we can expect further advancements and market expansion in this field.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft has developed advanced high-pass filtering techniques for Optical Character Recognition (OCR) accuracy optimization. Their approach involves a multi-stage preprocessing pipeline that includes image binarization, noise reduction, and edge enhancement[1]. The high-pass filter is applied to sharpen text edges and improve contrast, which is crucial for accurate character segmentation. Microsoft's OCR system utilizes deep learning models trained on diverse datasets, incorporating convolutional neural networks (CNNs) for feature extraction[2]. The high-pass filtered images serve as input to these models, significantly enhancing the recognition of fine details in characters, especially in low-contrast or degraded documents[3]. Additionally, Microsoft has implemented adaptive thresholding techniques that work in conjunction with high-pass filters to handle varying illumination conditions across different parts of a document[4].
Strengths: Robust performance across diverse document types; integration with cloud-based services for scalability. Weaknesses: May require significant computational resources; potential over-sharpening of noisy images.
Fujitsu Ltd.
Technical Solution: Fujitsu has innovated in OCR technology by implementing advanced high-pass filtering algorithms tailored for Japanese and multi-language character recognition. Their approach combines traditional image processing techniques with machine learning models to optimize filter parameters dynamically[1]. Fujitsu's high-pass filtering method emphasizes the use of Gabor filters, which are particularly effective in enhancing text features at various orientations and scales[2]. This is crucial for accurately recognizing complex scripts like kanji. The company has also developed a novel adaptive high-pass filtering technique that adjusts based on local image characteristics, improving performance on documents with varying quality and font styles[3]. Fujitsu's OCR system incorporates these filtered images into a deep learning pipeline, utilizing recurrent neural networks (RNNs) for sequence modeling in text recognition[4].
Strengths: Excellent performance on complex scripts and multi-language documents; adaptive filtering for varying document qualities. Weaknesses: May be computationally intensive; potentially less effective on very low-resolution images.
Innovations in Filter Design for OCR
Circuit for speech recognition
PatentInactiveEP0508547A2
Innovation
- The implementation of a recursive high-pass filtering of spectral feature vectors before comparison with reference vectors, combined with logarithmic processing and intensity normalization, reduces the influence of stationary noise and frequency response distortions, enabling speaker-independent recognition.
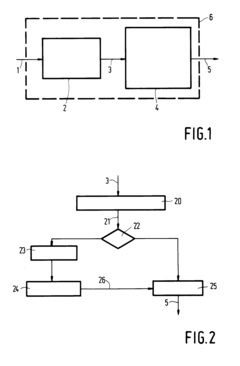
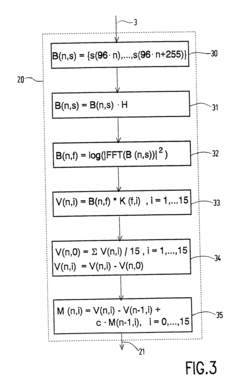
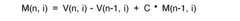
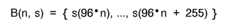
Visualisation of extreme differences in contrast for camera systems
PatentInactiveEP1326431A2
Innovation
- Implementing a high-pass filter to enhance local contrast differences while weakening large differences, achieved through weighted subtraction of a low-pass filtered image, with the correction mask calculated asynchronously at most every second image, reducing computational effort and using existing hardware and software routines.
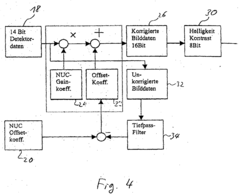
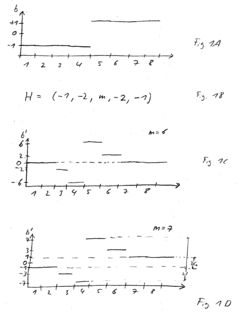
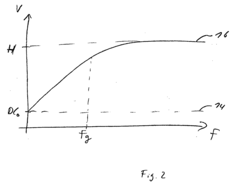
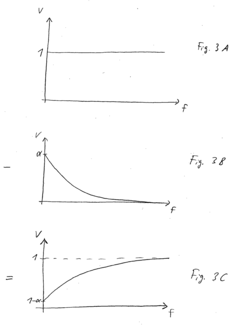
OCR Performance Metrics and Benchmarks
Optical Character Recognition (OCR) performance metrics and benchmarks play a crucial role in evaluating the effectiveness of high pass filters in optimizing OCR accuracy. These metrics provide quantitative measures to assess the quality and reliability of OCR systems, enabling researchers and developers to compare different approaches and track improvements over time.
One of the primary metrics used in OCR evaluation is character accuracy rate (CAR), which measures the percentage of correctly recognized characters in a given document. High pass filters can significantly impact CAR by enhancing the contrast between text and background, potentially leading to improved character recognition. Another important metric is word accuracy rate (WAR), which assesses the percentage of correctly recognized words. By sharpening edges and reducing noise, high pass filters can contribute to higher WAR scores.
Precision and recall are also essential metrics in OCR performance evaluation. Precision measures the proportion of correctly identified characters or words among all recognized elements, while recall indicates the proportion of correctly identified elements among all actual elements in the document. High pass filters can potentially improve both precision and recall by reducing false positives and false negatives in character recognition.
The F1 score, which combines precision and recall into a single metric, provides a balanced measure of OCR performance. This metric is particularly useful when evaluating the overall impact of high pass filters on OCR accuracy. Additionally, the edit distance or Levenshtein distance is often used to quantify the similarity between the OCR output and the ground truth text, offering insights into the effectiveness of high pass filters in minimizing recognition errors.
OCR benchmarks typically involve standardized datasets and evaluation protocols to ensure fair comparisons between different systems and approaches. Common benchmarks include the ICDAR (International Conference on Document Analysis and Recognition) datasets, which provide a diverse range of document images for testing OCR performance. These benchmarks often include various document types, such as printed text, handwritten documents, and historical manuscripts, allowing for comprehensive evaluation of high pass filter effectiveness across different scenarios.
The impact of high pass filters on OCR performance can be assessed using these metrics and benchmarks by comparing the results obtained with and without filter application. This comparative analysis helps researchers and developers optimize filter parameters and determine the most effective filtering techniques for specific document types or OCR applications.
One of the primary metrics used in OCR evaluation is character accuracy rate (CAR), which measures the percentage of correctly recognized characters in a given document. High pass filters can significantly impact CAR by enhancing the contrast between text and background, potentially leading to improved character recognition. Another important metric is word accuracy rate (WAR), which assesses the percentage of correctly recognized words. By sharpening edges and reducing noise, high pass filters can contribute to higher WAR scores.
Precision and recall are also essential metrics in OCR performance evaluation. Precision measures the proportion of correctly identified characters or words among all recognized elements, while recall indicates the proportion of correctly identified elements among all actual elements in the document. High pass filters can potentially improve both precision and recall by reducing false positives and false negatives in character recognition.
The F1 score, which combines precision and recall into a single metric, provides a balanced measure of OCR performance. This metric is particularly useful when evaluating the overall impact of high pass filters on OCR accuracy. Additionally, the edit distance or Levenshtein distance is often used to quantify the similarity between the OCR output and the ground truth text, offering insights into the effectiveness of high pass filters in minimizing recognition errors.
OCR benchmarks typically involve standardized datasets and evaluation protocols to ensure fair comparisons between different systems and approaches. Common benchmarks include the ICDAR (International Conference on Document Analysis and Recognition) datasets, which provide a diverse range of document images for testing OCR performance. These benchmarks often include various document types, such as printed text, handwritten documents, and historical manuscripts, allowing for comprehensive evaluation of high pass filter effectiveness across different scenarios.
The impact of high pass filters on OCR performance can be assessed using these metrics and benchmarks by comparing the results obtained with and without filter application. This comparative analysis helps researchers and developers optimize filter parameters and determine the most effective filtering techniques for specific document types or OCR applications.
Regulatory Compliance in OCR Applications
Regulatory compliance is a critical aspect of Optical Character Recognition (OCR) applications, particularly when high pass filters are employed to optimize accuracy. As OCR technology becomes increasingly prevalent in various industries, adherence to legal and regulatory frameworks is essential to ensure data privacy, security, and ethical use of information.
One of the primary regulatory concerns in OCR applications is the protection of personal data. Many jurisdictions have implemented strict data protection laws, such as the General Data Protection Regulation (GDPR) in the European Union and the California Consumer Privacy Act (CCPA) in the United States. These regulations mandate that OCR systems must be designed with privacy in mind, incorporating features like data minimization, purpose limitation, and user consent mechanisms.
In the financial sector, OCR applications must comply with anti-money laundering (AML) and know-your-customer (KYC) regulations. High pass filters can play a crucial role in enhancing the accuracy of document verification processes, ensuring that financial institutions meet their regulatory obligations while maintaining operational efficiency.
Healthcare organizations utilizing OCR technology must adhere to regulations such as the Health Insurance Portability and Accountability Act (HIPAA) in the United States. These regulations require strict controls on the handling and storage of patient information, necessitating robust security measures and audit trails in OCR systems.
The use of high pass filters in OCR applications can also impact compliance with accessibility regulations. For instance, the Americans with Disabilities Act (ADA) mandates that digital content be accessible to individuals with disabilities. OCR systems must be designed to accurately recognize and process text in various formats, ensuring that the resulting digital documents are compatible with assistive technologies.
Regulatory compliance extends to the realm of intellectual property as well. OCR systems must be developed and implemented in a manner that respects copyright laws and licensing agreements. This is particularly important when processing copyrighted materials or when OCR technology is used in conjunction with licensed software or databases.
As OCR technology continues to evolve, regulatory frameworks are likely to adapt and expand. Organizations implementing OCR solutions must stay abreast of these changes and ensure that their systems remain compliant. This may involve regular audits, updates to data processing agreements, and ongoing staff training on regulatory requirements.
One of the primary regulatory concerns in OCR applications is the protection of personal data. Many jurisdictions have implemented strict data protection laws, such as the General Data Protection Regulation (GDPR) in the European Union and the California Consumer Privacy Act (CCPA) in the United States. These regulations mandate that OCR systems must be designed with privacy in mind, incorporating features like data minimization, purpose limitation, and user consent mechanisms.
In the financial sector, OCR applications must comply with anti-money laundering (AML) and know-your-customer (KYC) regulations. High pass filters can play a crucial role in enhancing the accuracy of document verification processes, ensuring that financial institutions meet their regulatory obligations while maintaining operational efficiency.
Healthcare organizations utilizing OCR technology must adhere to regulations such as the Health Insurance Portability and Accountability Act (HIPAA) in the United States. These regulations require strict controls on the handling and storage of patient information, necessitating robust security measures and audit trails in OCR systems.
The use of high pass filters in OCR applications can also impact compliance with accessibility regulations. For instance, the Americans with Disabilities Act (ADA) mandates that digital content be accessible to individuals with disabilities. OCR systems must be designed to accurately recognize and process text in various formats, ensuring that the resulting digital documents are compatible with assistive technologies.
Regulatory compliance extends to the realm of intellectual property as well. OCR systems must be developed and implemented in a manner that respects copyright laws and licensing agreements. This is particularly important when processing copyrighted materials or when OCR technology is used in conjunction with licensed software or databases.
As OCR technology continues to evolve, regulatory frameworks are likely to adapt and expand. Organizations implementing OCR solutions must stay abreast of these changes and ensure that their systems remain compliant. This may involve regular audits, updates to data processing agreements, and ongoing staff training on regulatory requirements.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!