

How to Parallelize Band Pass Filter Function in Massive MIMO Systems
MAR 25, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Massive MIMO Filter Parallelization Background and Goals
Massive MIMO systems have emerged as a cornerstone technology for 5G and beyond wireless communications, fundamentally transforming how wireless networks handle capacity and coverage challenges. These systems deploy hundreds or thousands of antenna elements at base stations to serve multiple users simultaneously through spatial multiplexing techniques. The unprecedented scale of antenna arrays enables dramatic improvements in spectral efficiency, energy efficiency, and link reliability compared to conventional MIMO configurations.
The evolution of Massive MIMO technology traces back to early multi-antenna research in the 1990s, progressing through conventional MIMO developments in the 2000s, and reaching maturity with large-scale antenna array implementations in the 2010s. This technological progression has been driven by the exponential growth in mobile data traffic and the demand for ultra-reliable low-latency communications in emerging applications such as autonomous vehicles, industrial IoT, and augmented reality.
Band pass filtering represents a critical signal processing function within Massive MIMO systems, responsible for isolating desired frequency bands while suppressing out-of-band interference and noise. In conventional systems, sequential filter processing was adequate given the limited number of antenna elements. However, the massive scale of modern antenna arrays creates unprecedented computational demands that challenge traditional processing architectures.
The computational complexity of band pass filtering in Massive MIMO systems scales linearly with the number of antenna elements, creating significant processing bottlenecks. With hundreds of simultaneous data streams requiring real-time filtering, sequential processing approaches become inadequate for meeting stringent latency requirements. This computational challenge is further amplified by the need for adaptive filtering algorithms that must respond dynamically to changing channel conditions and interference patterns.
Current industry trends indicate a critical need for parallelization strategies that can distribute filtering computations across multiple processing units while maintaining signal integrity and synchronization. The primary technical objectives include achieving linear scalability with antenna count, minimizing inter-processor communication overhead, and maintaining real-time processing capabilities under varying system loads.
The strategic importance of solving filter parallelization challenges extends beyond immediate performance gains. Efficient parallel filtering architectures will enable cost-effective deployment of larger antenna arrays, support higher-order modulation schemes, and facilitate the integration of advanced features such as beamforming optimization and interference cancellation. These capabilities are essential for realizing the full potential of Massive MIMO technology in next-generation wireless networks.
The evolution of Massive MIMO technology traces back to early multi-antenna research in the 1990s, progressing through conventional MIMO developments in the 2000s, and reaching maturity with large-scale antenna array implementations in the 2010s. This technological progression has been driven by the exponential growth in mobile data traffic and the demand for ultra-reliable low-latency communications in emerging applications such as autonomous vehicles, industrial IoT, and augmented reality.
Band pass filtering represents a critical signal processing function within Massive MIMO systems, responsible for isolating desired frequency bands while suppressing out-of-band interference and noise. In conventional systems, sequential filter processing was adequate given the limited number of antenna elements. However, the massive scale of modern antenna arrays creates unprecedented computational demands that challenge traditional processing architectures.
The computational complexity of band pass filtering in Massive MIMO systems scales linearly with the number of antenna elements, creating significant processing bottlenecks. With hundreds of simultaneous data streams requiring real-time filtering, sequential processing approaches become inadequate for meeting stringent latency requirements. This computational challenge is further amplified by the need for adaptive filtering algorithms that must respond dynamically to changing channel conditions and interference patterns.
Current industry trends indicate a critical need for parallelization strategies that can distribute filtering computations across multiple processing units while maintaining signal integrity and synchronization. The primary technical objectives include achieving linear scalability with antenna count, minimizing inter-processor communication overhead, and maintaining real-time processing capabilities under varying system loads.
The strategic importance of solving filter parallelization challenges extends beyond immediate performance gains. Efficient parallel filtering architectures will enable cost-effective deployment of larger antenna arrays, support higher-order modulation schemes, and facilitate the integration of advanced features such as beamforming optimization and interference cancellation. These capabilities are essential for realizing the full potential of Massive MIMO technology in next-generation wireless networks.
Market Demand for High-Performance Massive MIMO Systems
The telecommunications industry is experiencing unprecedented demand for high-performance Massive MIMO systems, driven by the exponential growth in mobile data traffic and the deployment of 5G networks worldwide. Mobile network operators are under increasing pressure to enhance spectral efficiency, improve coverage quality, and support higher user densities while maintaining cost-effective operations. This surge in demand directly correlates with the need for advanced signal processing capabilities, particularly in band pass filtering functions that require sophisticated parallelization techniques.
Enterprise and industrial applications represent another significant growth driver for high-performance Massive MIMO systems. Smart manufacturing facilities, autonomous vehicle networks, and Internet of Things deployments require ultra-reliable low-latency communications that can only be achieved through advanced antenna array processing. These applications demand real-time signal processing capabilities where parallelized band pass filtering becomes critical for maintaining system performance under heavy computational loads.
The emergence of private 5G networks has created substantial market opportunities for specialized Massive MIMO solutions. Organizations across healthcare, logistics, and energy sectors are investing in dedicated wireless infrastructure that requires customized signal processing algorithms. These deployments often involve unique frequency bands and interference patterns, necessitating flexible and efficient filtering mechanisms that can adapt to varying operational conditions.
Cloud-based radio access networks and edge computing architectures are reshaping market requirements for Massive MIMO systems. Service providers are transitioning toward virtualized network functions that demand scalable processing capabilities. This architectural shift creates opportunities for software-defined filtering solutions that can dynamically allocate computational resources based on network traffic patterns and quality of service requirements.
The competitive landscape is intensifying as equipment manufacturers strive to differentiate their offerings through superior signal processing performance. Market leaders are investing heavily in research and development to achieve processing efficiency gains that translate into reduced power consumption and operational costs. This competitive pressure drives continuous innovation in parallelization techniques for computationally intensive functions like band pass filtering.
Regulatory requirements for spectrum efficiency and interference mitigation are creating additional market pressures for advanced filtering capabilities. Government agencies worldwide are implementing stricter standards for wireless equipment performance, particularly in dense urban environments where multiple operators share limited spectrum resources. These regulatory frameworks necessitate sophisticated filtering algorithms that can operate effectively in challenging electromagnetic environments while maintaining compliance with international standards.
Enterprise and industrial applications represent another significant growth driver for high-performance Massive MIMO systems. Smart manufacturing facilities, autonomous vehicle networks, and Internet of Things deployments require ultra-reliable low-latency communications that can only be achieved through advanced antenna array processing. These applications demand real-time signal processing capabilities where parallelized band pass filtering becomes critical for maintaining system performance under heavy computational loads.
The emergence of private 5G networks has created substantial market opportunities for specialized Massive MIMO solutions. Organizations across healthcare, logistics, and energy sectors are investing in dedicated wireless infrastructure that requires customized signal processing algorithms. These deployments often involve unique frequency bands and interference patterns, necessitating flexible and efficient filtering mechanisms that can adapt to varying operational conditions.
Cloud-based radio access networks and edge computing architectures are reshaping market requirements for Massive MIMO systems. Service providers are transitioning toward virtualized network functions that demand scalable processing capabilities. This architectural shift creates opportunities for software-defined filtering solutions that can dynamically allocate computational resources based on network traffic patterns and quality of service requirements.
The competitive landscape is intensifying as equipment manufacturers strive to differentiate their offerings through superior signal processing performance. Market leaders are investing heavily in research and development to achieve processing efficiency gains that translate into reduced power consumption and operational costs. This competitive pressure drives continuous innovation in parallelization techniques for computationally intensive functions like band pass filtering.
Regulatory requirements for spectrum efficiency and interference mitigation are creating additional market pressures for advanced filtering capabilities. Government agencies worldwide are implementing stricter standards for wireless equipment performance, particularly in dense urban environments where multiple operators share limited spectrum resources. These regulatory frameworks necessitate sophisticated filtering algorithms that can operate effectively in challenging electromagnetic environments while maintaining compliance with international standards.
Current Challenges in Band Pass Filter Parallelization
The parallelization of band pass filter functions in massive MIMO systems faces significant computational complexity challenges due to the sheer scale of antenna arrays. Modern massive MIMO implementations typically involve hundreds or even thousands of antenna elements, each requiring individual filtering operations across multiple frequency bands. The computational burden increases exponentially with the number of antennas, creating bottlenecks that traditional sequential processing approaches cannot adequately address.
Memory bandwidth limitations represent another critical constraint in filter parallelization efforts. Band pass filtering operations require frequent access to coefficient tables, input signal buffers, and intermediate calculation results. When multiple filter instances operate simultaneously, memory contention becomes severe, leading to performance degradation that can negate the benefits of parallel processing. The challenge is particularly acute in real-time systems where latency requirements are stringent.
Synchronization overhead poses substantial difficulties in maintaining coherent filtering across parallel processing units. Massive MIMO systems demand precise phase and timing alignment between antenna channels, requiring sophisticated coordination mechanisms between parallel filter instances. The synchronization protocols necessary to maintain this coherence introduce additional computational overhead and complexity, often creating new bottlenecks in the processing pipeline.
Hardware resource allocation presents ongoing challenges in optimizing filter parallelization strategies. Different processing architectures, including GPUs, FPGAs, and specialized DSP units, offer varying advantages for parallel filtering operations. However, efficiently mapping filter algorithms to available hardware resources while maintaining load balance across processing units remains a complex optimization problem that lacks standardized solutions.
Load balancing difficulties emerge when filter workloads vary dynamically based on signal characteristics and system operating conditions. Massive MIMO systems must adapt to changing channel conditions, interference patterns, and traffic demands, resulting in uneven computational requirements across different antenna elements and frequency bands. Achieving optimal load distribution while maintaining system responsiveness requires sophisticated scheduling algorithms that can adapt to these dynamic conditions in real-time.
Memory bandwidth limitations represent another critical constraint in filter parallelization efforts. Band pass filtering operations require frequent access to coefficient tables, input signal buffers, and intermediate calculation results. When multiple filter instances operate simultaneously, memory contention becomes severe, leading to performance degradation that can negate the benefits of parallel processing. The challenge is particularly acute in real-time systems where latency requirements are stringent.
Synchronization overhead poses substantial difficulties in maintaining coherent filtering across parallel processing units. Massive MIMO systems demand precise phase and timing alignment between antenna channels, requiring sophisticated coordination mechanisms between parallel filter instances. The synchronization protocols necessary to maintain this coherence introduce additional computational overhead and complexity, often creating new bottlenecks in the processing pipeline.
Hardware resource allocation presents ongoing challenges in optimizing filter parallelization strategies. Different processing architectures, including GPUs, FPGAs, and specialized DSP units, offer varying advantages for parallel filtering operations. However, efficiently mapping filter algorithms to available hardware resources while maintaining load balance across processing units remains a complex optimization problem that lacks standardized solutions.
Load balancing difficulties emerge when filter workloads vary dynamically based on signal characteristics and system operating conditions. Massive MIMO systems must adapt to changing channel conditions, interference patterns, and traffic demands, resulting in uneven computational requirements across different antenna elements and frequency bands. Achieving optimal load distribution while maintaining system responsiveness requires sophisticated scheduling algorithms that can adapt to these dynamic conditions in real-time.
Existing Parallel Band Pass Filter Solutions
01 Parallel processing architecture for digital filters
Implementation of band pass filter functions using parallel processing architectures to improve computational efficiency. This approach divides the filtering operation into multiple parallel paths or stages that can be processed simultaneously, reducing overall processing time. The architecture typically involves multiple processing units working concurrently on different portions of the input signal or different filter coefficients.- Parallel processing architecture for digital filters: Implementation of band pass filter functions using parallel processing architectures to improve computational efficiency. This approach divides the filtering operation into multiple parallel paths or stages that can be processed simultaneously, reducing overall processing time. The architecture typically involves multiple processing units working concurrently on different portions of the input signal or different filter coefficients.
- Multi-core and distributed filter processing: Techniques for distributing band pass filter computations across multiple cores or processing elements in a parallel computing environment. This includes methods for partitioning filter operations, managing data flow between processing elements, and synchronizing results. The approach enables efficient utilization of multi-core processors and distributed computing resources for real-time signal processing applications.
- Pipeline-based filter implementation: Pipeline architectures for implementing band pass filters where different stages of the filtering operation are executed in a pipelined manner. Each pipeline stage performs a specific portion of the filter computation, allowing multiple data samples to be processed simultaneously at different stages. This approach maximizes throughput and enables continuous data processing with minimal latency.
- FPGA and hardware-accelerated filtering: Hardware implementations of parallel band pass filters using field-programmable gate arrays or dedicated hardware accelerators. These implementations leverage the inherent parallelism of hardware circuits to perform multiple filter operations simultaneously. The approach provides high-speed processing capabilities and low latency, making it suitable for real-time applications requiring high throughput.
- Parallel coefficient computation and optimization: Methods for parallelizing the computation and optimization of filter coefficients in band pass filters. This includes techniques for simultaneously calculating multiple coefficient values, parallel optimization algorithms for filter design, and methods for updating filter parameters in real-time. The approach reduces the computational burden of filter design and adaptation processes.
02 Multi-core and distributed filter processing
Techniques for distributing band pass filter computations across multiple cores or processing elements in a system. This involves partitioning the filter algorithm into independent tasks that can execute concurrently on different processors or cores. The approach enables efficient utilization of multi-core processors and distributed computing resources for real-time signal processing applications.Expand Specific Solutions03 Pipeline-based filter implementation
Pipeline architectures for implementing band pass filters where different stages of the filtering process are executed in a sequential but overlapping manner. Each pipeline stage performs a specific portion of the filter operation, allowing multiple data samples to be processed simultaneously at different stages. This method achieves high throughput by maintaining continuous data flow through the filter stages.Expand Specific Solutions04 SIMD and vector processing for filters
Application of Single Instruction Multiple Data and vector processing techniques to parallelize band pass filter operations. This approach processes multiple data elements simultaneously using vector instructions, enabling efficient computation of filter coefficients and convolution operations. The method is particularly effective for filters with regular computational patterns and uniform data structures.Expand Specific Solutions05 Hardware acceleration and FPGA-based parallel filtering
Hardware-based implementations using specialized circuits or field-programmable gate arrays to achieve parallel execution of band pass filter functions. These solutions leverage dedicated hardware resources to perform multiple filter operations concurrently, offering significant performance improvements over software implementations. The approach includes custom logic designs optimized for specific filter characteristics and real-time processing requirements.Expand Specific Solutions
Key Players in Massive MIMO and DSP Industry
The parallelization of band pass filter functions in massive MIMO systems represents a rapidly evolving technological domain driven by the increasing demand for high-capacity wireless communications. The industry is in a growth phase, with the global massive MIMO market expanding significantly as 5G networks proliferate worldwide. Market size projections indicate substantial growth potential, particularly in telecommunications infrastructure and mobile communications sectors. Technology maturity varies across key players, with established telecommunications giants like Huawei Technologies, ZTE Corp., and Nokia Solutions & Networks leading in advanced implementation capabilities. Chinese companies including China Mobile Communications Group and Datang Mobile Communications Equipment demonstrate strong research foundations, while component manufacturers such as Murata Manufacturing and NEC Corp. provide essential hardware solutions. Academic institutions like Xidian University and Beijing Jiaotong University contribute fundamental research, indicating a collaborative ecosystem between industry and academia that accelerates technological advancement and practical deployment solutions.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed advanced parallel processing architectures for band pass filtering in massive MIMO systems, utilizing distributed computing frameworks across multiple antenna arrays. Their solution employs GPU-accelerated filtering algorithms that can process up to 256 antenna elements simultaneously, achieving processing latencies below 100 microseconds. The company implements frequency-domain parallelization techniques combined with time-domain optimization, enabling efficient resource allocation across massive antenna configurations. Their approach includes adaptive filtering algorithms that dynamically adjust filter parameters based on channel conditions, supporting both FDD and TDD massive MIMO deployments with scalable parallel processing capabilities.
Strengths: Industry-leading processing speed and scalability, comprehensive massive MIMO deployment experience. Weaknesses: High power consumption in dense antenna configurations, complex implementation requiring specialized hardware.
ZTE Corp.
Technical Solution: ZTE has implemented parallel band pass filtering solutions using multi-core DSP architectures specifically designed for massive MIMO base stations. Their technology leverages SIMD (Single Instruction, Multiple Data) processing to handle multiple filter operations concurrently across different antenna branches. The solution incorporates optimized FFT-based filtering algorithms that reduce computational complexity while maintaining filtering accuracy. ZTE's approach includes real-time adaptive filtering with parallel coefficient updates, supporting up to 128 antenna elements with sub-millisecond processing delays. Their implementation features distributed processing across multiple radio units with centralized coordination for optimal performance in 5G massive MIMO systems.
Strengths: Cost-effective implementation with good performance scalability, strong integration with existing infrastructure. Weaknesses: Limited to specific hardware platforms, lower processing capacity compared to leading competitors.
Core Innovations in MIMO Filter Parallelization
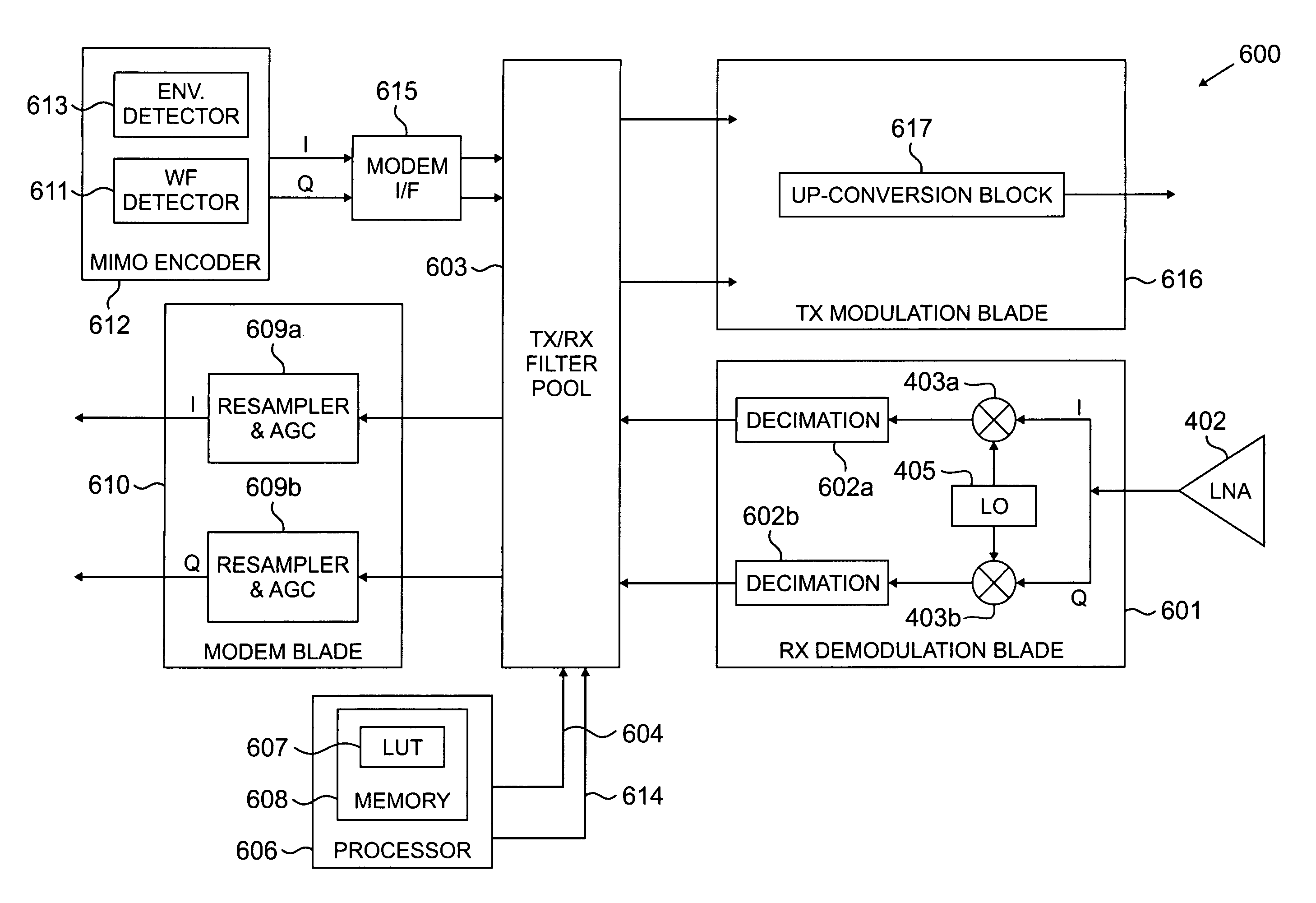
Multiple input multiple output (MIMO) transceiver with pooled adaptive digital filtering
PatentInactiveUS7864885B2
Innovation
- The implementation of pooled adaptive digital filtering, where a processor selects filter parameter values based on channel estimation and signal strength, allowing for reconfigurable filters to match receiver and transmitter filters, thereby reducing processing power and power dissipation across multiple MIMO streams.
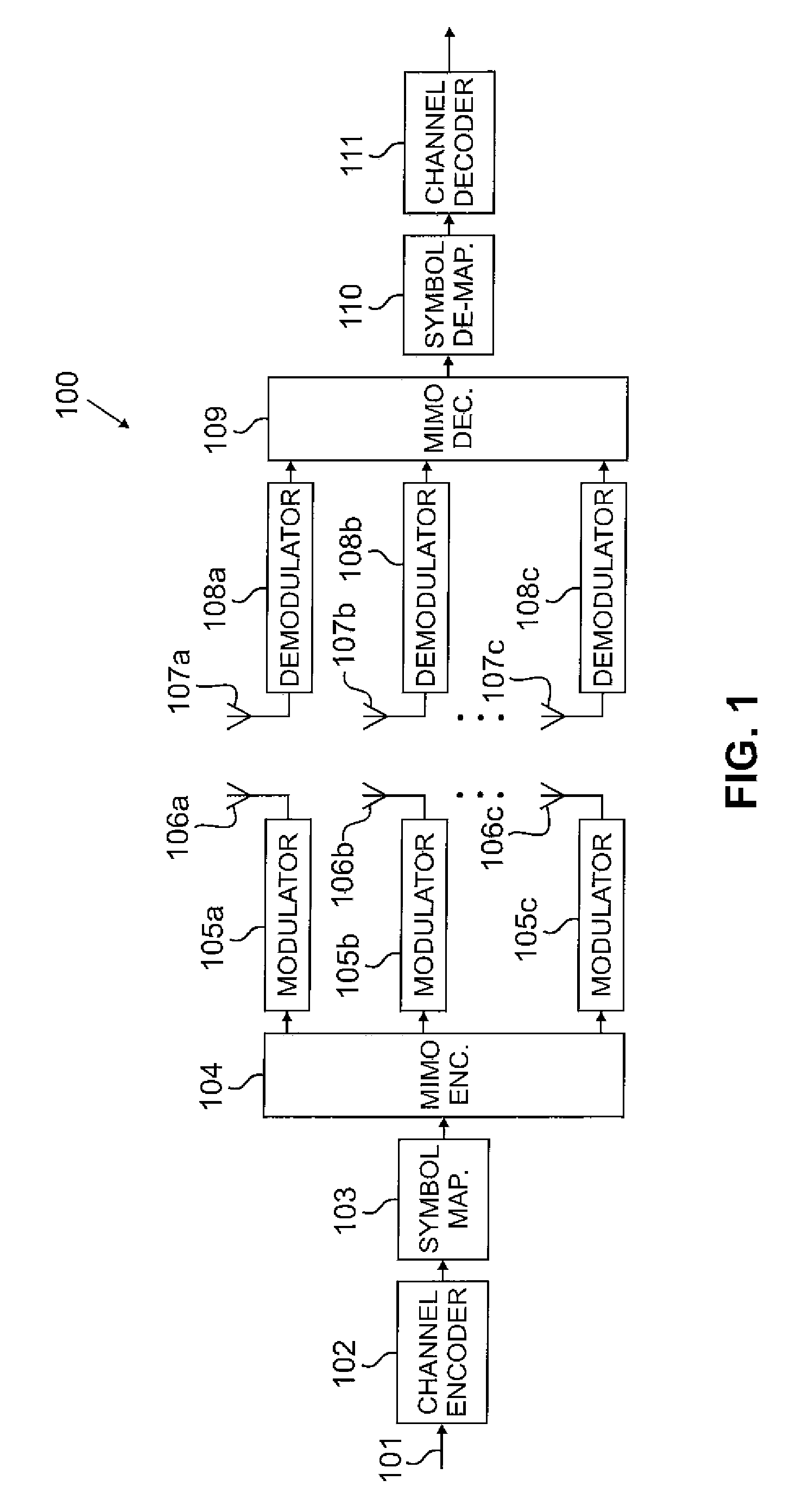

Spatial-wideband compensation in wideband massive MIMO systems
PatentActiveUS12500634B2
Innovation
- A transceiver design using lens antenna subarrays with analog filters and switches, replacing phase shifters, and employing a simplified exhaustive search to control beam squint, maintaining beam gain and reducing hardware complexity.


Hardware Acceleration Standards for MIMO Processing
The standardization of hardware acceleration for MIMO processing has become increasingly critical as massive MIMO systems demand higher computational throughput and lower latency. Current industry standards primarily focus on establishing unified frameworks for parallel processing architectures, with organizations like 3GPP, IEEE, and ETSI leading the development of comprehensive guidelines for MIMO signal processing acceleration.
OpenCL and CUDA represent the dominant programming standards for GPU-based MIMO acceleration, providing standardized APIs for parallel computation across different hardware platforms. These frameworks enable efficient implementation of band pass filtering operations through standardized kernel functions and memory management protocols. The OpenCL standard particularly emphasizes cross-platform compatibility, allowing MIMO processing algorithms to execute across diverse hardware architectures including GPUs, FPGAs, and specialized DSP units.
FPGA acceleration standards have evolved significantly with the introduction of high-level synthesis tools and standardized IP cores. Xilinx Vivado HLS and Intel Quartus Prime provide standardized development environments for implementing parallel band pass filters in massive MIMO systems. These tools support IEEE 754 floating-point standards and fixed-point arithmetic specifications, ensuring numerical accuracy and reproducibility across different implementations.
The emergence of AI accelerator standards, including ONNX and TensorFlow Lite, has introduced new paradigms for MIMO processing acceleration. These frameworks enable the deployment of machine learning-enhanced filtering algorithms on specialized neural processing units, offering potential performance improvements for adaptive filtering applications in massive MIMO systems.
Industry consortiums have established benchmarking standards for evaluating hardware acceleration performance in MIMO applications. The Embedded Microprocessor Benchmark Consortium has developed specific test suites for measuring parallel processing efficiency in wireless communication systems. These standards define metrics for throughput, latency, and power consumption, enabling objective comparison of different acceleration approaches.
Recent developments in heterogeneous computing standards, such as SYCL and OpenMP 5.0, provide unified programming models for deploying parallel band pass filters across mixed hardware architectures. These standards facilitate seamless integration of CPU, GPU, and FPGA resources within a single MIMO processing pipeline, optimizing resource utilization and computational efficiency.
OpenCL and CUDA represent the dominant programming standards for GPU-based MIMO acceleration, providing standardized APIs for parallel computation across different hardware platforms. These frameworks enable efficient implementation of band pass filtering operations through standardized kernel functions and memory management protocols. The OpenCL standard particularly emphasizes cross-platform compatibility, allowing MIMO processing algorithms to execute across diverse hardware architectures including GPUs, FPGAs, and specialized DSP units.
FPGA acceleration standards have evolved significantly with the introduction of high-level synthesis tools and standardized IP cores. Xilinx Vivado HLS and Intel Quartus Prime provide standardized development environments for implementing parallel band pass filters in massive MIMO systems. These tools support IEEE 754 floating-point standards and fixed-point arithmetic specifications, ensuring numerical accuracy and reproducibility across different implementations.
The emergence of AI accelerator standards, including ONNX and TensorFlow Lite, has introduced new paradigms for MIMO processing acceleration. These frameworks enable the deployment of machine learning-enhanced filtering algorithms on specialized neural processing units, offering potential performance improvements for adaptive filtering applications in massive MIMO systems.
Industry consortiums have established benchmarking standards for evaluating hardware acceleration performance in MIMO applications. The Embedded Microprocessor Benchmark Consortium has developed specific test suites for measuring parallel processing efficiency in wireless communication systems. These standards define metrics for throughput, latency, and power consumption, enabling objective comparison of different acceleration approaches.
Recent developments in heterogeneous computing standards, such as SYCL and OpenMP 5.0, provide unified programming models for deploying parallel band pass filters across mixed hardware architectures. These standards facilitate seamless integration of CPU, GPU, and FPGA resources within a single MIMO processing pipeline, optimizing resource utilization and computational efficiency.
Energy Efficiency in Parallel MIMO Filter Design
Energy efficiency has emerged as a critical design consideration in parallel MIMO filter implementations, driven by the exponential growth in data traffic and the proliferation of massive MIMO deployments in 5G and beyond networks. The parallelization of band pass filter functions, while offering significant performance improvements, introduces complex energy consumption patterns that require careful optimization to maintain sustainable operation.
The primary energy consumption sources in parallel MIMO filter architectures stem from computational processing units, memory access operations, and inter-processor communication overhead. Digital signal processors and field-programmable gate arrays executing parallel filtering algorithms typically consume 60-80% of the total system power, with memory subsystems accounting for an additional 15-25%. The remaining energy expenditure occurs in data movement between processing elements and synchronization mechanisms required for coherent parallel operation.
Power scaling challenges become particularly pronounced as the number of parallel processing threads increases. While theoretical computational complexity reduces linearly with parallelization factor, actual energy consumption often exhibits sublinear improvements due to coordination overhead and resource contention. Modern implementations demonstrate that beyond 16-32 parallel threads, energy efficiency gains diminish significantly, creating an optimal operating point that balances performance and power consumption.
Advanced power management techniques have been developed to address these challenges, including dynamic voltage and frequency scaling, clock gating, and adaptive precision control. These methods can achieve 30-50% energy reduction in typical massive MIMO scenarios by adjusting processing intensity based on channel conditions and traffic demands. Heterogeneous computing architectures combining general-purpose processors with specialized accelerators further optimize energy utilization by matching computational tasks to the most efficient processing units.
Emerging approaches focus on algorithm-hardware co-design strategies that minimize energy consumption at the architectural level. Approximate computing techniques, sparse matrix optimizations, and reduced-precision arithmetic operations show promising results in maintaining filtering performance while significantly reducing power requirements. These innovations are essential for enabling sustainable massive MIMO deployments in energy-constrained environments.
The primary energy consumption sources in parallel MIMO filter architectures stem from computational processing units, memory access operations, and inter-processor communication overhead. Digital signal processors and field-programmable gate arrays executing parallel filtering algorithms typically consume 60-80% of the total system power, with memory subsystems accounting for an additional 15-25%. The remaining energy expenditure occurs in data movement between processing elements and synchronization mechanisms required for coherent parallel operation.
Power scaling challenges become particularly pronounced as the number of parallel processing threads increases. While theoretical computational complexity reduces linearly with parallelization factor, actual energy consumption often exhibits sublinear improvements due to coordination overhead and resource contention. Modern implementations demonstrate that beyond 16-32 parallel threads, energy efficiency gains diminish significantly, creating an optimal operating point that balances performance and power consumption.
Advanced power management techniques have been developed to address these challenges, including dynamic voltage and frequency scaling, clock gating, and adaptive precision control. These methods can achieve 30-50% energy reduction in typical massive MIMO scenarios by adjusting processing intensity based on channel conditions and traffic demands. Heterogeneous computing architectures combining general-purpose processors with specialized accelerators further optimize energy utilization by matching computational tasks to the most efficient processing units.
Emerging approaches focus on algorithm-hardware co-design strategies that minimize energy consumption at the architectural level. Approximate computing techniques, sparse matrix optimizations, and reduced-precision arithmetic operations show promising results in maintaining filtering performance while significantly reducing power requirements. These innovations are essential for enabling sustainable massive MIMO deployments in energy-constrained environments.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!