Optimize Active Memory for Large Data Set Processing
MAR 7, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Active Memory Optimization Background and Objectives
Active memory optimization has emerged as a critical technological frontier in the era of exponential data growth and increasingly complex computational workloads. Traditional memory hierarchies, designed for smaller datasets and sequential processing patterns, face fundamental limitations when confronted with modern big data applications that demand real-time processing of terabyte-scale datasets. The conventional approach of relying on static memory allocation and passive caching mechanisms proves inadequate for dynamic, large-scale data processing scenarios.
The evolution of active memory systems represents a paradigm shift from passive storage to intelligent, adaptive memory management. Unlike traditional memory architectures that simply store and retrieve data, active memory systems incorporate processing capabilities directly within the memory subsystem, enabling data transformation, filtering, and computation to occur closer to the storage location. This approach addresses the growing disparity between processor speed and memory bandwidth, commonly known as the memory wall problem.
Historical development in this field traces back to early research in processing-in-memory architectures during the 1990s, which laid the groundwork for contemporary active memory solutions. The resurgence of interest in recent years stems from the convergence of several technological trends: the proliferation of multi-core processors, the advent of non-volatile memory technologies, and the exponential growth in data-intensive applications across industries ranging from artificial intelligence to scientific computing.
The primary objective of active memory optimization for large dataset processing centers on minimizing data movement overhead while maximizing computational throughput. This involves developing intelligent prefetching algorithms that can predict data access patterns, implementing dynamic memory allocation strategies that adapt to workload characteristics, and creating efficient data compression and decompression mechanisms that operate transparently within the memory subsystem.
Secondary objectives include reducing overall system power consumption through localized processing, improving system scalability by distributing computational load across memory modules, and enhancing fault tolerance through redundant processing capabilities embedded within the memory architecture. These objectives collectively aim to establish a new foundation for next-generation computing systems capable of handling the unprecedented scale and complexity of modern data processing requirements.
The evolution of active memory systems represents a paradigm shift from passive storage to intelligent, adaptive memory management. Unlike traditional memory architectures that simply store and retrieve data, active memory systems incorporate processing capabilities directly within the memory subsystem, enabling data transformation, filtering, and computation to occur closer to the storage location. This approach addresses the growing disparity between processor speed and memory bandwidth, commonly known as the memory wall problem.
Historical development in this field traces back to early research in processing-in-memory architectures during the 1990s, which laid the groundwork for contemporary active memory solutions. The resurgence of interest in recent years stems from the convergence of several technological trends: the proliferation of multi-core processors, the advent of non-volatile memory technologies, and the exponential growth in data-intensive applications across industries ranging from artificial intelligence to scientific computing.
The primary objective of active memory optimization for large dataset processing centers on minimizing data movement overhead while maximizing computational throughput. This involves developing intelligent prefetching algorithms that can predict data access patterns, implementing dynamic memory allocation strategies that adapt to workload characteristics, and creating efficient data compression and decompression mechanisms that operate transparently within the memory subsystem.
Secondary objectives include reducing overall system power consumption through localized processing, improving system scalability by distributing computational load across memory modules, and enhancing fault tolerance through redundant processing capabilities embedded within the memory architecture. These objectives collectively aim to establish a new foundation for next-generation computing systems capable of handling the unprecedented scale and complexity of modern data processing requirements.
Market Demand for Large Data Processing Solutions
The global data processing market has experienced unprecedented growth driven by digital transformation initiatives across industries. Organizations worldwide are generating massive volumes of data from IoT devices, social media platforms, e-commerce transactions, and enterprise applications, creating an urgent need for efficient large-scale data processing solutions. Traditional storage and processing architectures struggle to handle these exponentially growing datasets, particularly when real-time or near-real-time processing is required.
Enterprise demand for optimized active memory solutions has intensified as businesses recognize the competitive advantages of faster data analytics. Financial institutions require millisecond-level transaction processing for algorithmic trading and fraud detection systems. Healthcare organizations need rapid analysis of genomic data and medical imaging for personalized treatment plans. Telecommunications companies demand real-time network optimization and customer behavior analysis to maintain service quality and reduce churn rates.
The emergence of artificial intelligence and machine learning applications has further amplified market demand for enhanced memory optimization technologies. Training large language models, computer vision systems, and recommendation engines requires processing terabytes of training data efficiently. Memory bottlenecks significantly impact model training times and inference performance, directly affecting business outcomes and operational costs.
Cloud computing providers face increasing pressure to optimize resource utilization while maintaining performance guarantees for their customers. Memory optimization technologies enable better consolidation ratios and improved cost efficiency in multi-tenant environments. Edge computing scenarios present additional challenges where memory constraints are more severe, yet processing requirements remain demanding for applications like autonomous vehicles and industrial automation.
Market research indicates strong growth potential across multiple sectors including financial services, healthcare, telecommunications, retail, and manufacturing. The increasing adoption of real-time analytics, streaming data processing, and in-memory computing architectures drives sustained demand for innovative memory optimization solutions that can handle large datasets efficiently while maintaining system responsiveness and reliability.
Enterprise demand for optimized active memory solutions has intensified as businesses recognize the competitive advantages of faster data analytics. Financial institutions require millisecond-level transaction processing for algorithmic trading and fraud detection systems. Healthcare organizations need rapid analysis of genomic data and medical imaging for personalized treatment plans. Telecommunications companies demand real-time network optimization and customer behavior analysis to maintain service quality and reduce churn rates.
The emergence of artificial intelligence and machine learning applications has further amplified market demand for enhanced memory optimization technologies. Training large language models, computer vision systems, and recommendation engines requires processing terabytes of training data efficiently. Memory bottlenecks significantly impact model training times and inference performance, directly affecting business outcomes and operational costs.
Cloud computing providers face increasing pressure to optimize resource utilization while maintaining performance guarantees for their customers. Memory optimization technologies enable better consolidation ratios and improved cost efficiency in multi-tenant environments. Edge computing scenarios present additional challenges where memory constraints are more severe, yet processing requirements remain demanding for applications like autonomous vehicles and industrial automation.
Market research indicates strong growth potential across multiple sectors including financial services, healthcare, telecommunications, retail, and manufacturing. The increasing adoption of real-time analytics, streaming data processing, and in-memory computing architectures drives sustained demand for innovative memory optimization solutions that can handle large datasets efficiently while maintaining system responsiveness and reliability.
Current Memory Management Challenges in Big Data
Memory management in big data processing environments faces unprecedented challenges as data volumes continue to grow exponentially. Traditional memory architectures struggle to efficiently handle datasets that exceed available RAM capacity, leading to frequent disk I/O operations that significantly degrade performance. The fundamental issue lies in the mismatch between the linear growth of memory capacity and the exponential increase in data processing requirements.
Current memory management systems exhibit poor locality of reference when processing large datasets. Data access patterns in big data applications are often unpredictable and non-sequential, causing cache misses and inefficient memory utilization. This results in substantial performance penalties as systems resort to slower storage tiers, creating bottlenecks that limit overall processing throughput.
Memory fragmentation presents another critical challenge in large-scale data processing environments. As applications allocate and deallocate memory blocks of varying sizes, available memory becomes fragmented into non-contiguous segments. This fragmentation reduces the effective memory capacity and complicates the allocation of large memory blocks required for processing substantial datasets.
The garbage collection overhead in managed runtime environments compounds memory management difficulties. Frequent garbage collection cycles interrupt data processing operations, causing unpredictable latency spikes that affect system responsiveness. These interruptions become particularly problematic when processing time-sensitive data streams or maintaining real-time analytics pipelines.
Memory bandwidth limitations create additional constraints in multi-core processing environments. As the number of processing cores increases, memory bandwidth becomes a shared resource that limits parallel processing capabilities. This bandwidth bottleneck prevents systems from fully utilizing available computational resources, reducing the efficiency of distributed data processing operations.
Virtual memory management introduces complexity when handling large datasets that exceed physical memory capacity. Page swapping operations between memory and storage create performance degradation, while translation lookaside buffer misses add computational overhead. These factors collectively impact the predictability and consistency of memory access patterns.
NUMA architecture considerations further complicate memory management in distributed processing environments. Non-uniform memory access patterns can create performance imbalances across processing nodes, leading to suboptimal resource utilization and increased inter-node communication overhead that affects overall system scalability.
Current memory management systems exhibit poor locality of reference when processing large datasets. Data access patterns in big data applications are often unpredictable and non-sequential, causing cache misses and inefficient memory utilization. This results in substantial performance penalties as systems resort to slower storage tiers, creating bottlenecks that limit overall processing throughput.
Memory fragmentation presents another critical challenge in large-scale data processing environments. As applications allocate and deallocate memory blocks of varying sizes, available memory becomes fragmented into non-contiguous segments. This fragmentation reduces the effective memory capacity and complicates the allocation of large memory blocks required for processing substantial datasets.
The garbage collection overhead in managed runtime environments compounds memory management difficulties. Frequent garbage collection cycles interrupt data processing operations, causing unpredictable latency spikes that affect system responsiveness. These interruptions become particularly problematic when processing time-sensitive data streams or maintaining real-time analytics pipelines.
Memory bandwidth limitations create additional constraints in multi-core processing environments. As the number of processing cores increases, memory bandwidth becomes a shared resource that limits parallel processing capabilities. This bandwidth bottleneck prevents systems from fully utilizing available computational resources, reducing the efficiency of distributed data processing operations.
Virtual memory management introduces complexity when handling large datasets that exceed physical memory capacity. Page swapping operations between memory and storage create performance degradation, while translation lookaside buffer misses add computational overhead. These factors collectively impact the predictability and consistency of memory access patterns.
NUMA architecture considerations further complicate memory management in distributed processing environments. Non-uniform memory access patterns can create performance imbalances across processing nodes, leading to suboptimal resource utilization and increased inter-node communication overhead that affects overall system scalability.
Existing Active Memory Optimization Approaches
01 Memory management and allocation optimization techniques
Various techniques can be employed to optimize memory allocation and management in active memory systems. These include dynamic memory allocation strategies, memory pooling, and efficient garbage collection mechanisms. By implementing smart allocation algorithms, systems can reduce memory fragmentation and improve overall memory utilization. Advanced memory management techniques also involve predictive allocation based on usage patterns and adaptive strategies that adjust to workload changes.- Memory allocation and deallocation optimization techniques: Various techniques can be employed to optimize memory allocation and deallocation processes in active memory systems. These include implementing efficient memory management algorithms, utilizing memory pools to reduce allocation overhead, and employing garbage collection strategies to reclaim unused memory. Dynamic memory allocation schemes can be optimized through predictive algorithms that anticipate memory requirements and pre-allocate resources accordingly. These approaches help minimize memory fragmentation and improve overall system performance by reducing the time spent on memory management operations.
- Cache memory optimization and management: Cache memory optimization involves implementing strategies to improve data access patterns and reduce cache misses. This includes techniques such as cache prefetching, where data likely to be accessed is loaded into cache before it is needed, and cache partitioning to allocate cache resources efficiently among different processes. Advanced cache replacement policies can be employed to determine which data should remain in cache and which should be evicted. Multi-level cache hierarchies can be optimized through intelligent data placement strategies that consider access frequency and data relationships.
- Memory compression and data reduction techniques: Memory compression techniques can significantly increase effective memory capacity by reducing the physical space required to store data. These methods include implementing hardware-assisted compression engines, utilizing pattern-based compression algorithms, and employing deduplication strategies to eliminate redundant data. Compression can be applied selectively to less frequently accessed memory pages while keeping hot data uncompressed for faster access. Adaptive compression schemes can dynamically adjust compression ratios based on system load and performance requirements.
- Memory bandwidth optimization and access scheduling: Optimizing memory bandwidth utilization involves implementing intelligent memory access scheduling algorithms that prioritize critical operations and minimize conflicts. Techniques include request reordering to maximize row buffer hits, implementing quality-of-service mechanisms to ensure fair resource allocation, and utilizing multiple memory channels to increase aggregate bandwidth. Advanced memory controllers can employ predictive scheduling based on access patterns and application behavior. Bank-level parallelism can be exploited through careful mapping of data structures to different memory banks.
- Power-aware memory optimization strategies: Power-aware memory optimization focuses on reducing energy consumption while maintaining performance levels. This includes implementing dynamic voltage and frequency scaling for memory subsystems, utilizing low-power memory states during idle periods, and employing data migration strategies to consolidate active data in fewer memory modules. Thermal management techniques can be integrated to prevent hotspots and reduce cooling requirements. Adaptive power management policies can balance performance and energy efficiency based on workload characteristics and system constraints.
02 Cache optimization and memory hierarchy management
Optimizing cache performance and managing memory hierarchies effectively can significantly enhance active memory performance. This involves implementing multi-level caching strategies, cache prefetching mechanisms, and intelligent cache replacement policies. Techniques include optimizing data locality, reducing cache misses, and managing the interaction between different levels of memory hierarchy such as L1, L2, L3 caches and main memory. These approaches help minimize memory access latency and improve overall system throughput.Expand Specific Solutions03 Memory compression and deduplication technologies
Memory compression and deduplication techniques can effectively increase the available memory capacity without physical expansion. These technologies identify and eliminate redundant data in memory, compress frequently accessed data, and implement efficient encoding schemes. By reducing the memory footprint of applications and data structures, systems can accommodate more data in the same physical memory space, leading to improved performance and reduced hardware costs.Expand Specific Solutions04 Power-aware memory optimization strategies
Power-efficient memory optimization focuses on reducing energy consumption while maintaining performance. This includes implementing dynamic voltage and frequency scaling for memory components, power-gating unused memory regions, and optimizing memory access patterns to minimize power consumption. These strategies are particularly important for mobile devices and data centers where energy efficiency is critical. Techniques also involve thermal management and adaptive power modes based on workload characteristics.Expand Specific Solutions05 Virtual memory and address space optimization
Virtual memory optimization techniques enhance the efficiency of address translation and memory mapping. This includes optimizing page table structures, implementing efficient translation lookaside buffers, and managing virtual-to-physical address mappings. Advanced techniques involve huge page support, memory ballooning, and efficient handling of memory overcommitment scenarios. These optimizations reduce address translation overhead and improve memory access performance in virtualized and non-virtualized environments.Expand Specific Solutions
Key Players in Memory and Data Processing Industry
The active memory optimization for large data set processing market is experiencing rapid growth driven by increasing data volumes and computational demands across industries. The market demonstrates significant expansion potential as organizations require more efficient memory management solutions for big data analytics, AI/ML workloads, and real-time processing applications. Technology maturity varies considerably among market participants, with established players like ZTE Corp., China Mobile, and ICBC leveraging their extensive infrastructure and resources to develop comprehensive solutions. Academic institutions including Shanghai Jiao Tong University, Huazhong University of Science & Technology, and Institute of Software Chinese Academy of Sciences contribute fundamental research and innovation. Specialized technology companies such as Shanghai Biren Technology, Inspur, and Jiangsu Huacun Electronic Technology focus on hardware-software integration for memory optimization. The competitive landscape shows a mix of telecommunications giants, financial institutions, cloud service providers like Tianyi Cloud, and emerging startups, indicating broad industry adoption and diverse application scenarios for active memory optimization technologies.
Suzhou Inspur Intelligent Technology Co., Ltd.
Technical Solution: Inspur develops advanced memory optimization solutions for large-scale data processing through their intelligent computing platforms. Their technology focuses on dynamic memory allocation algorithms that can automatically adjust memory usage based on workload patterns. The system implements predictive caching mechanisms that pre-load frequently accessed data segments into active memory, reducing I/O bottlenecks by up to 40%. Their solution also incorporates memory compression techniques and intelligent data partitioning strategies to maximize memory utilization efficiency for big data analytics workloads.
Strengths: Strong enterprise-grade reliability and proven scalability in cloud environments. Weaknesses: Higher implementation complexity and resource overhead for smaller datasets.
China Mobile Communications Group Co., Ltd.
Technical Solution: China Mobile has developed a distributed memory management framework specifically designed for telecom big data processing. Their solution utilizes edge-cloud collaborative memory optimization, where active memory is intelligently distributed across multiple nodes based on data locality and access patterns. The system employs machine learning algorithms to predict memory usage trends and automatically scales memory allocation. Their technology includes real-time memory defragmentation and adaptive buffer management that can handle massive telecom data streams with minimal latency impact.
Strengths: Excellent performance in distributed environments and real-time processing capabilities. Weaknesses: Limited applicability outside telecom domain and requires specialized infrastructure.
Core Innovations in Memory Management Patents
Advanced memory management architecture for large data volumes
PatentInactiveUS7032088B2
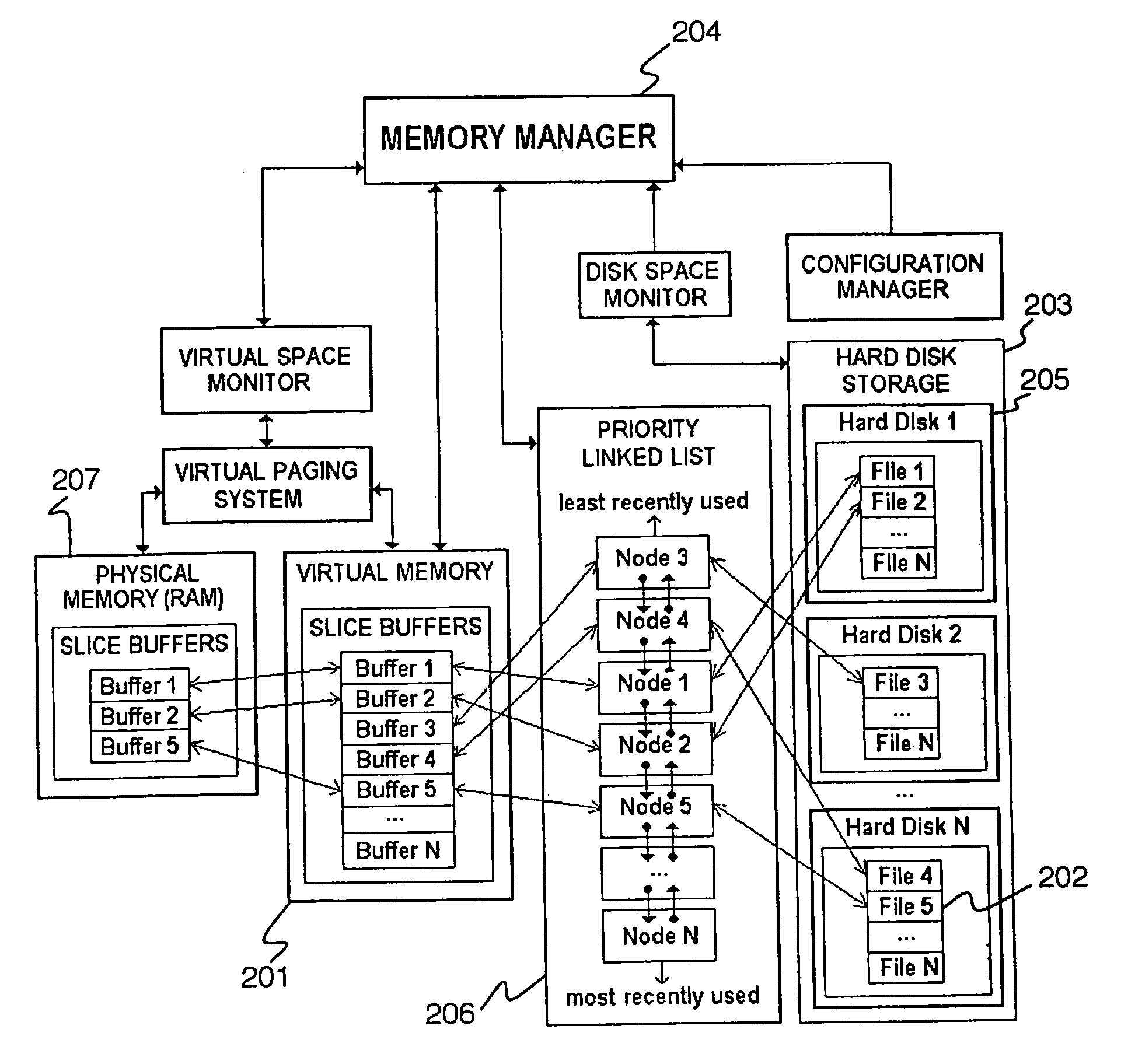
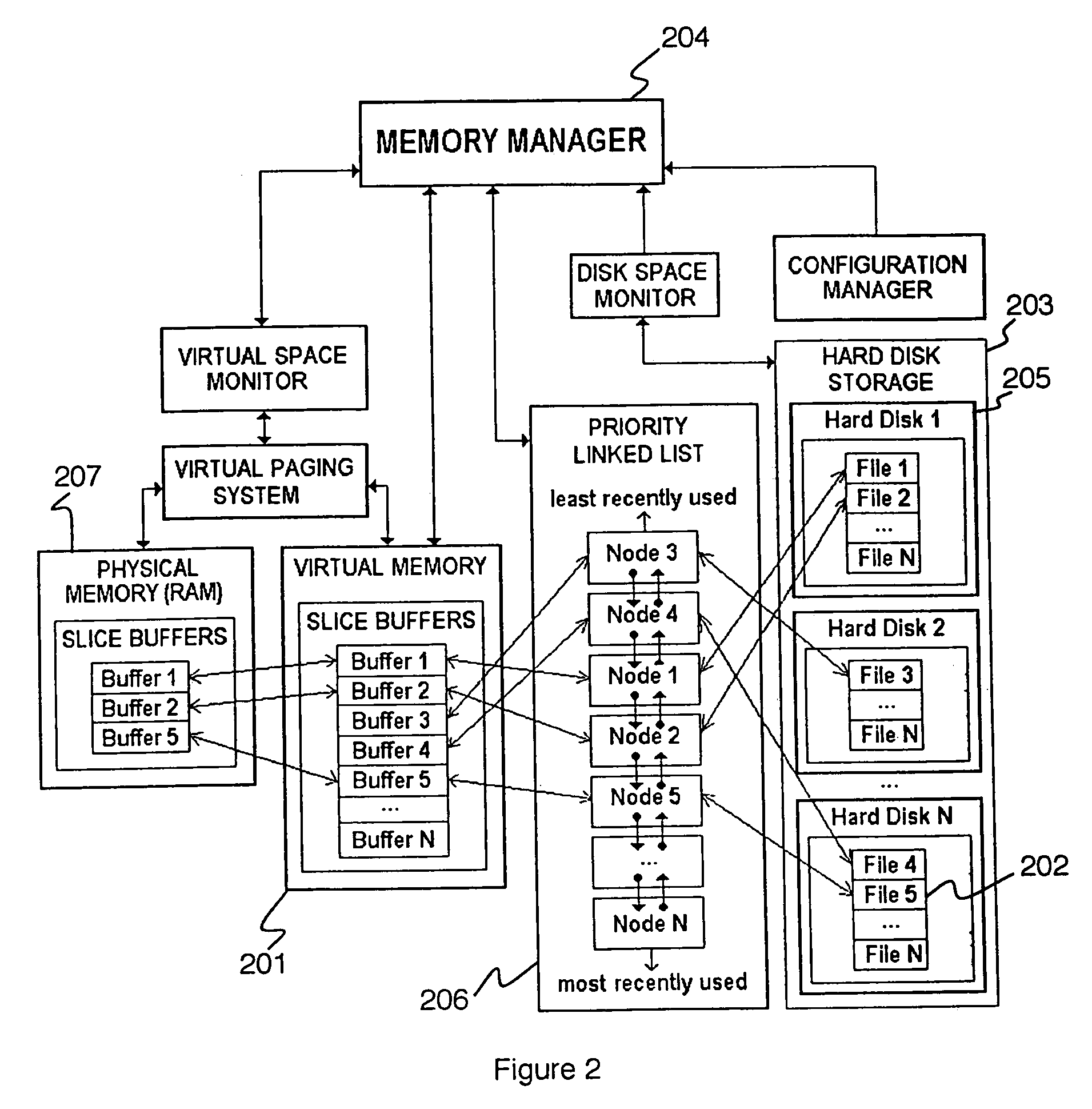
Innovation
- A central memory management system maintains a global priority list of memory buffers sorted by last access time, pages out least-recently used buffers to disk when memory is low, and shares data buffers among applications, using memory-mapped buffers and a linked-list to optimize memory usage and address handling.

Vector processing in an active memory device
PatentActiveUS9575755B2
Innovation
- The implementation of an active memory device with integrated processing elements that can perform vector processing autonomously, reducing the need for frequent data transfer between memory and the main processor by executing instructions and operations within the memory device itself, thereby minimizing latency and energy consumption.




Performance Benchmarking and Evaluation Metrics
Performance benchmarking for active memory optimization in large dataset processing requires comprehensive evaluation frameworks that capture both quantitative metrics and qualitative system behaviors. The primary performance indicators include memory throughput measured in gigabytes per second, latency characteristics under varying workload conditions, and memory utilization efficiency ratios. These metrics provide fundamental insights into how effectively the optimized active memory system handles massive data volumes compared to traditional storage hierarchies.
Memory access pattern analysis forms a critical component of the evaluation methodology. Sequential access patterns, random access distributions, and mixed workload scenarios must be systematically tested to understand performance variations across different data processing paradigms. Benchmark suites should incorporate realistic dataset characteristics including varying data sizes from terabytes to petabytes, different data types such as structured databases and unstructured multimedia content, and diverse access frequencies that mirror real-world application demands.
Scalability metrics represent another essential evaluation dimension, measuring how performance characteristics evolve as dataset sizes increase exponentially. Linear scalability coefficients, performance degradation thresholds, and resource utilization curves provide quantitative measures of system robustness. These assessments help determine optimal configuration parameters and identify potential bottlenecks before they impact production environments.
Energy efficiency evaluation has become increasingly important given the substantial power consumption associated with large-scale memory systems. Performance-per-watt ratios, thermal management effectiveness, and dynamic power scaling capabilities must be measured across different operational states. These metrics enable comprehensive cost-benefit analysis for enterprise deployments where operational expenses significantly impact total ownership costs.
Comparative benchmarking against established baseline systems provides contextual performance validation. Industry-standard benchmark suites like SPEC CPU, TPC-H for database workloads, and custom synthetic benchmarks designed specifically for large dataset processing scenarios offer standardized comparison frameworks. Multi-dimensional performance radar charts and statistical significance testing ensure robust evaluation conclusions that support informed technology adoption decisions.
Memory access pattern analysis forms a critical component of the evaluation methodology. Sequential access patterns, random access distributions, and mixed workload scenarios must be systematically tested to understand performance variations across different data processing paradigms. Benchmark suites should incorporate realistic dataset characteristics including varying data sizes from terabytes to petabytes, different data types such as structured databases and unstructured multimedia content, and diverse access frequencies that mirror real-world application demands.
Scalability metrics represent another essential evaluation dimension, measuring how performance characteristics evolve as dataset sizes increase exponentially. Linear scalability coefficients, performance degradation thresholds, and resource utilization curves provide quantitative measures of system robustness. These assessments help determine optimal configuration parameters and identify potential bottlenecks before they impact production environments.
Energy efficiency evaluation has become increasingly important given the substantial power consumption associated with large-scale memory systems. Performance-per-watt ratios, thermal management effectiveness, and dynamic power scaling capabilities must be measured across different operational states. These metrics enable comprehensive cost-benefit analysis for enterprise deployments where operational expenses significantly impact total ownership costs.
Comparative benchmarking against established baseline systems provides contextual performance validation. Industry-standard benchmark suites like SPEC CPU, TPC-H for database workloads, and custom synthetic benchmarks designed specifically for large dataset processing scenarios offer standardized comparison frameworks. Multi-dimensional performance radar charts and statistical significance testing ensure robust evaluation conclusions that support informed technology adoption decisions.
Energy Efficiency Considerations in Memory Design
Energy efficiency has emerged as a critical design consideration in active memory systems for large dataset processing, driven by escalating power consumption demands and environmental sustainability requirements. Modern data centers processing massive datasets face significant operational costs, with memory subsystems accounting for approximately 30-40% of total system power consumption. This energy burden becomes particularly pronounced when handling petabyte-scale datasets that require sustained high-bandwidth memory operations.
The relationship between memory performance and energy consumption presents complex trade-offs in large dataset processing scenarios. High-frequency memory operations necessary for real-time analytics and machine learning workloads generate substantial heat dissipation, requiring sophisticated thermal management solutions. Dynamic voltage and frequency scaling techniques have shown promise in reducing power consumption during low-intensity processing phases, while maintaining peak performance capabilities when handling computationally intensive operations.
Advanced memory architectures incorporate intelligent power management features specifically designed for large dataset applications. Near-data computing approaches minimize energy-intensive data movement by positioning processing elements closer to memory arrays. This architectural shift reduces the energy overhead associated with transferring massive datasets between memory hierarchies, achieving up to 60% reduction in memory-related power consumption for certain workload patterns.
Emerging memory technologies demonstrate significant energy efficiency improvements over traditional DRAM solutions. Processing-in-memory architectures eliminate redundant data transfers by performing computations directly within memory arrays, substantially reducing energy consumption for data-intensive operations. These innovations prove particularly valuable for applications involving large-scale pattern recognition, database queries, and scientific simulations where data movement traditionally dominates energy consumption.
Power-aware memory management algorithms play crucial roles in optimizing energy efficiency during large dataset processing. Adaptive memory allocation strategies dynamically adjust power states based on workload characteristics, enabling selective activation of memory banks while maintaining performance requirements. These approaches leverage workload prediction models to anticipate memory access patterns, allowing proactive power management decisions that balance performance objectives with energy constraints in large-scale data processing environments.
The relationship between memory performance and energy consumption presents complex trade-offs in large dataset processing scenarios. High-frequency memory operations necessary for real-time analytics and machine learning workloads generate substantial heat dissipation, requiring sophisticated thermal management solutions. Dynamic voltage and frequency scaling techniques have shown promise in reducing power consumption during low-intensity processing phases, while maintaining peak performance capabilities when handling computationally intensive operations.
Advanced memory architectures incorporate intelligent power management features specifically designed for large dataset applications. Near-data computing approaches minimize energy-intensive data movement by positioning processing elements closer to memory arrays. This architectural shift reduces the energy overhead associated with transferring massive datasets between memory hierarchies, achieving up to 60% reduction in memory-related power consumption for certain workload patterns.
Emerging memory technologies demonstrate significant energy efficiency improvements over traditional DRAM solutions. Processing-in-memory architectures eliminate redundant data transfers by performing computations directly within memory arrays, substantially reducing energy consumption for data-intensive operations. These innovations prove particularly valuable for applications involving large-scale pattern recognition, database queries, and scientific simulations where data movement traditionally dominates energy consumption.
Power-aware memory management algorithms play crucial roles in optimizing energy efficiency during large dataset processing. Adaptive memory allocation strategies dynamically adjust power states based on workload characteristics, enabling selective activation of memory banks while maintaining performance requirements. These approaches leverage workload prediction models to anticipate memory access patterns, allowing proactive power management decisions that balance performance objectives with energy constraints in large-scale data processing environments.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!