

Optimizing RISC Processing Speed for High-Tech Fields
MAR 26, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
RISC Processing Speed Optimization Background and Objectives
RISC (Reduced Instruction Set Computer) architecture has emerged as a cornerstone of modern computing, fundamentally reshaping processor design philosophy since its inception in the 1980s. The evolution from complex instruction set computers (CISC) to RISC represented a paradigm shift toward simplified instruction sets that prioritize execution efficiency over instruction complexity. This architectural approach has proven particularly valuable in high-tech fields where computational demands continue to escalate exponentially.
The historical trajectory of RISC development began with pioneering research at UC Berkeley and Stanford University, leading to groundbreaking implementations like the SPARC and MIPS architectures. These early innovations established core principles including load-store architecture, fixed-length instructions, and extensive use of registers. The subsequent emergence of ARM processors revolutionized mobile computing, while RISC-V has recently introduced open-source flexibility to processor design.
Contemporary high-tech applications present unprecedented challenges for RISC processors. Artificial intelligence workloads demand massive parallel processing capabilities, while edge computing requires energy-efficient performance. Autonomous vehicles need real-time processing with ultra-low latency, and 5G infrastructure requires handling enormous data throughput. These applications expose current limitations in traditional RISC designs, particularly in specialized computational tasks and memory bandwidth utilization.
The primary technical objectives for RISC processing speed optimization encompass multiple dimensions. Performance enhancement targets include reducing instruction execution cycles, improving branch prediction accuracy, and optimizing cache hierarchies. Power efficiency remains crucial, especially for mobile and IoT applications where battery life directly impacts user experience. Scalability objectives focus on maintaining performance gains across varying workload types and system configurations.
Advanced optimization strategies must address both architectural and microarchitectural improvements. Superscalar execution, out-of-order processing, and speculative execution represent established techniques requiring refinement. Emerging approaches include heterogeneous computing integration, specialized accelerator units, and adaptive instruction scheduling mechanisms.
The ultimate goal involves achieving optimal balance between processing speed, energy consumption, and implementation complexity while maintaining RISC architecture's inherent advantages of simplicity and predictability. Success in these optimization efforts will determine RISC processors' continued relevance in next-generation high-tech applications.
The historical trajectory of RISC development began with pioneering research at UC Berkeley and Stanford University, leading to groundbreaking implementations like the SPARC and MIPS architectures. These early innovations established core principles including load-store architecture, fixed-length instructions, and extensive use of registers. The subsequent emergence of ARM processors revolutionized mobile computing, while RISC-V has recently introduced open-source flexibility to processor design.
Contemporary high-tech applications present unprecedented challenges for RISC processors. Artificial intelligence workloads demand massive parallel processing capabilities, while edge computing requires energy-efficient performance. Autonomous vehicles need real-time processing with ultra-low latency, and 5G infrastructure requires handling enormous data throughput. These applications expose current limitations in traditional RISC designs, particularly in specialized computational tasks and memory bandwidth utilization.
The primary technical objectives for RISC processing speed optimization encompass multiple dimensions. Performance enhancement targets include reducing instruction execution cycles, improving branch prediction accuracy, and optimizing cache hierarchies. Power efficiency remains crucial, especially for mobile and IoT applications where battery life directly impacts user experience. Scalability objectives focus on maintaining performance gains across varying workload types and system configurations.
Advanced optimization strategies must address both architectural and microarchitectural improvements. Superscalar execution, out-of-order processing, and speculative execution represent established techniques requiring refinement. Emerging approaches include heterogeneous computing integration, specialized accelerator units, and adaptive instruction scheduling mechanisms.
The ultimate goal involves achieving optimal balance between processing speed, energy consumption, and implementation complexity while maintaining RISC architecture's inherent advantages of simplicity and predictability. Success in these optimization efforts will determine RISC processors' continued relevance in next-generation high-tech applications.
Market Demand for High-Performance RISC Processors
The global semiconductor industry is experiencing unprecedented demand for high-performance RISC processors, driven by the rapid expansion of artificial intelligence, machine learning, and edge computing applications. Data centers worldwide are increasingly adopting RISC-V architectures to achieve superior performance-per-watt ratios, while maintaining cost efficiency compared to traditional x86 solutions. The automotive sector represents another significant growth driver, with autonomous vehicles requiring real-time processing capabilities that RISC processors can deliver through their streamlined instruction sets.
Cloud computing giants are actively transitioning toward custom RISC-based silicon to optimize their workloads and reduce dependency on proprietary architectures. This shift has created substantial market opportunities for companies developing specialized RISC processors tailored for specific computational tasks. The telecommunications industry, particularly with 5G infrastructure deployment, demands processors capable of handling massive data throughput with minimal latency, positioning high-performance RISC solutions as critical components.
Emerging technologies such as Internet of Things devices, cryptocurrency mining, and high-frequency trading systems require processors that can execute instructions with maximum efficiency. RISC architectures inherently provide this advantage through their reduced instruction complexity, enabling higher clock frequencies and lower power consumption. The growing emphasis on energy efficiency in data centers has further accelerated adoption rates.
The mobile computing market continues expanding, with smartphones, tablets, and wearable devices requiring processors that balance performance with battery life. RISC processors excel in this domain due to their ability to deliver computational power while maintaining thermal efficiency. Additionally, the rise of edge AI applications in industrial automation, smart cities, and healthcare monitoring systems has created new market segments demanding specialized RISC processing solutions.
Market research indicates strong growth trajectories across multiple sectors, with particular emphasis on processors optimized for parallel processing, vector operations, and specialized workloads. The increasing complexity of software applications and the need for real-time processing capabilities continue driving demand for more sophisticated RISC processor designs that can handle diverse computational requirements efficiently.
Cloud computing giants are actively transitioning toward custom RISC-based silicon to optimize their workloads and reduce dependency on proprietary architectures. This shift has created substantial market opportunities for companies developing specialized RISC processors tailored for specific computational tasks. The telecommunications industry, particularly with 5G infrastructure deployment, demands processors capable of handling massive data throughput with minimal latency, positioning high-performance RISC solutions as critical components.
Emerging technologies such as Internet of Things devices, cryptocurrency mining, and high-frequency trading systems require processors that can execute instructions with maximum efficiency. RISC architectures inherently provide this advantage through their reduced instruction complexity, enabling higher clock frequencies and lower power consumption. The growing emphasis on energy efficiency in data centers has further accelerated adoption rates.
The mobile computing market continues expanding, with smartphones, tablets, and wearable devices requiring processors that balance performance with battery life. RISC processors excel in this domain due to their ability to deliver computational power while maintaining thermal efficiency. Additionally, the rise of edge AI applications in industrial automation, smart cities, and healthcare monitoring systems has created new market segments demanding specialized RISC processing solutions.
Market research indicates strong growth trajectories across multiple sectors, with particular emphasis on processors optimized for parallel processing, vector operations, and specialized workloads. The increasing complexity of software applications and the need for real-time processing capabilities continue driving demand for more sophisticated RISC processor designs that can handle diverse computational requirements efficiently.
Current RISC Architecture Limitations and Speed Bottlenecks
RISC architectures face several fundamental limitations that constrain their processing speed in high-tech applications. The most significant bottleneck stems from the instruction-per-clock (IPC) ceiling, where traditional RISC designs struggle to execute more than one instruction per cycle efficiently. This limitation becomes particularly pronounced in computationally intensive tasks such as artificial intelligence inference, real-time signal processing, and high-frequency trading systems.
Memory hierarchy inefficiencies represent another critical constraint. Current RISC implementations often suffer from cache miss penalties that can stall the processor for dozens of cycles. The growing disparity between processor speed and memory access latency, known as the memory wall, severely impacts performance in data-intensive applications. Load-store architectures, while conceptually elegant, create additional bottlenecks when handling complex data structures or performing memory-intensive operations.
Branch prediction accuracy remains a persistent challenge, particularly in applications with irregular control flow patterns. Mispredicted branches can flush the entire pipeline, resulting in significant performance penalties. Modern RISC processors typically achieve 85-95% branch prediction accuracy, but the remaining mispredictions can account for substantial performance degradation in certain workloads.
Pipeline depth optimization presents a fundamental trade-off between clock frequency and pipeline efficiency. Deeper pipelines enable higher clock speeds but increase branch misprediction penalties and complicate hazard detection. Conversely, shorter pipelines limit maximum operating frequencies, constraining overall throughput potential.
Instruction-level parallelism extraction capabilities in current RISC designs are often insufficient for modern workloads. Superscalar implementations face diminishing returns as issue width increases, due to register file complexity, instruction scheduling overhead, and limited parallelism in typical instruction streams. Out-of-order execution engines, while improving performance, introduce significant complexity and power consumption overhead.
Power efficiency constraints increasingly limit performance scaling opportunities. As transistor scaling benefits diminish, maintaining performance growth while adhering to thermal design power limits becomes increasingly challenging. Dynamic voltage and frequency scaling techniques help manage power consumption but often at the expense of peak performance capabilities.
Interconnect and communication bottlenecks between processor cores and specialized accelerators further constrain system-level performance. Traditional bus architectures and coherency protocols struggle to provide sufficient bandwidth for emerging applications requiring tight integration between general-purpose processing and specialized computational units.
Memory hierarchy inefficiencies represent another critical constraint. Current RISC implementations often suffer from cache miss penalties that can stall the processor for dozens of cycles. The growing disparity between processor speed and memory access latency, known as the memory wall, severely impacts performance in data-intensive applications. Load-store architectures, while conceptually elegant, create additional bottlenecks when handling complex data structures or performing memory-intensive operations.
Branch prediction accuracy remains a persistent challenge, particularly in applications with irregular control flow patterns. Mispredicted branches can flush the entire pipeline, resulting in significant performance penalties. Modern RISC processors typically achieve 85-95% branch prediction accuracy, but the remaining mispredictions can account for substantial performance degradation in certain workloads.
Pipeline depth optimization presents a fundamental trade-off between clock frequency and pipeline efficiency. Deeper pipelines enable higher clock speeds but increase branch misprediction penalties and complicate hazard detection. Conversely, shorter pipelines limit maximum operating frequencies, constraining overall throughput potential.
Instruction-level parallelism extraction capabilities in current RISC designs are often insufficient for modern workloads. Superscalar implementations face diminishing returns as issue width increases, due to register file complexity, instruction scheduling overhead, and limited parallelism in typical instruction streams. Out-of-order execution engines, while improving performance, introduce significant complexity and power consumption overhead.
Power efficiency constraints increasingly limit performance scaling opportunities. As transistor scaling benefits diminish, maintaining performance growth while adhering to thermal design power limits becomes increasingly challenging. Dynamic voltage and frequency scaling techniques help manage power consumption but often at the expense of peak performance capabilities.
Interconnect and communication bottlenecks between processor cores and specialized accelerators further constrain system-level performance. Traditional bus architectures and coherency protocols struggle to provide sufficient bandwidth for emerging applications requiring tight integration between general-purpose processing and specialized computational units.
Existing RISC Speed Optimization Solutions
01 Pipeline optimization and instruction execution efficiency
RISC processors can improve processing speed through optimized pipeline architectures that enable efficient instruction execution. Techniques include reducing pipeline stalls, implementing advanced branch prediction mechanisms, and optimizing instruction fetch and decode stages. These methods allow for higher instruction throughput and reduced cycle times, directly enhancing overall processing performance.- Pipeline optimization and instruction execution efficiency: RISC processors can improve processing speed through optimized pipeline architectures that enable efficient instruction execution. Techniques include reducing pipeline stalls, implementing advanced branch prediction mechanisms, and optimizing instruction fetch and decode stages. These methods minimize clock cycles per instruction and maximize throughput, resulting in faster overall processing performance.
- Parallel processing and multi-core architectures: Processing speed can be enhanced by implementing parallel execution units and multi-core designs in RISC processors. This approach allows multiple instructions or threads to be processed simultaneously, significantly increasing computational throughput. The architecture may include multiple execution pipelines, distributed processing units, and efficient inter-core communication mechanisms to maximize parallel processing capabilities.
- Cache memory optimization and memory hierarchy design: RISC processing speed can be improved through optimized cache memory systems and memory hierarchy designs. This includes implementing multi-level cache structures, improving cache hit rates, reducing memory access latency, and optimizing data prefetching strategies. Efficient memory management ensures that the processor has rapid access to frequently used data and instructions, minimizing wait times and improving overall performance.
- Instruction set architecture optimization and reduced instruction complexity: The fundamental RISC principle of simplified instruction sets contributes to processing speed by enabling faster instruction decode and execution. Optimizations include streamlining instruction formats, reducing instruction complexity, implementing fixed-length instructions, and minimizing the number of addressing modes. These design choices allow for faster clock speeds and more efficient hardware implementation.
- Clock frequency enhancement and power management: RISC processing speed can be increased through higher clock frequencies enabled by efficient circuit design and advanced semiconductor processes. This includes implementing dynamic voltage and frequency scaling, optimizing critical path delays, reducing power consumption to allow higher operating frequencies, and utilizing advanced fabrication technologies. Proper thermal management and power optimization allow sustained high-speed operation without compromising reliability.
02 Parallel processing and multi-core architectures
Processing speed in RISC systems can be significantly increased through parallel processing capabilities and multi-core designs. This involves implementing multiple execution units that can process instructions simultaneously, utilizing thread-level parallelism, and coordinating operations across multiple cores. Such architectures enable higher computational throughput by distributing workloads efficiently across available processing resources.Expand Specific Solutions03 Cache memory hierarchy and data access optimization
Enhanced cache memory systems and optimized data access patterns contribute to improved RISC processing speed. This includes implementing multi-level cache hierarchies, prefetching mechanisms, and intelligent cache management strategies that reduce memory access latency. By minimizing the time required to retrieve data and instructions, these techniques help maintain high execution speeds and reduce processor idle time.Expand Specific Solutions04 Dynamic frequency scaling and power management
RISC processor performance can be optimized through dynamic frequency and voltage scaling techniques that balance processing speed with power consumption. These methods involve adjusting clock frequencies and operating voltages based on workload demands, enabling processors to operate at higher speeds when needed while maintaining thermal efficiency. Advanced power management circuits monitor system conditions and automatically adjust performance parameters.Expand Specific Solutions05 Instruction set optimization and compiler techniques
Processing speed improvements can be achieved through optimized instruction set architectures and advanced compiler techniques specifically designed for RISC processors. This includes streamlining instruction formats, reducing instruction complexity, and implementing compiler optimizations that generate more efficient code sequences. These approaches minimize instruction count and execution time, resulting in faster program execution and improved overall system performance.Expand Specific Solutions
Key Players in RISC Processor and Architecture Industry
The RISC processing speed optimization landscape is experiencing rapid evolution as the industry transitions from early adoption to mainstream deployment across high-tech sectors. Market expansion is driven by growing demand for energy-efficient computing in AI, IoT, and edge applications, with the global RISC-V market projected to reach significant scale. Technology maturity varies considerably among key players: established giants like Intel, AMD, and Qualcomm leverage decades of processor expertise, while specialized firms such as Loongson Technology and PACT XPP Technologies focus on innovative RISC architectures. Companies like Synopsys provide critical EDA tools enabling RISC optimization, while manufacturers including GlobalFoundries and STMicroelectronics offer fabrication capabilities. The competitive landscape shows increasing collaboration between traditional semiconductor leaders and emerging RISC specialists, indicating technology convergence toward optimized, application-specific processing solutions that balance performance with power efficiency requirements.
Synopsys, Inc.
Technical Solution: Synopsys provides comprehensive RISC-V processor IP and optimization tools through their DesignWare portfolio, enabling semiconductor companies to accelerate RISC processing performance. Their solution includes advanced synthesis and place-and-route optimization specifically tuned for RISC architectures, along with verification tools that ensure optimal timing closure. Synopsys offers customizable RISC-V cores with configurable instruction sets and memory subsystems, allowing designers to optimize for specific high-tech applications. Their EDA tools provide automated optimization flows that can improve RISC processor performance by up to 30% while reducing power consumption.
Strengths: Comprehensive EDA toolchain and extensive RISC-V IP portfolio for rapid development. Weaknesses: Dependency on customer implementation expertise and limited direct hardware manufacturing capabilities.
QUALCOMM, Inc.
Technical Solution: Qualcomm's RISC processing optimization leverages their extensive mobile processor expertise to deliver high-performance RISC-V solutions for telecommunications and edge computing applications. Their approach emphasizes ultra-low latency instruction execution and specialized DSP integration for signal processing workloads. Qualcomm implements advanced heterogeneous computing architectures combining RISC cores with dedicated AI accelerators and modem processing units. Their optimization techniques include dynamic frequency scaling and intelligent workload distribution across multiple RISC cores to maximize throughput in 5G and IoT applications.
Strengths: Market-leading mobile and wireless technology integration capabilities. Weaknesses: Primary focus on mobile applications may limit adoption in server and desktop high-tech fields.
Core Innovations in RISC Performance Enhancement Patents
Reconfigurable reduced instruction set computer processor architecture with fractured cores
PatentPendingUS20220179823A1
Innovation
- A reconfigurable multi-core RISC processor architecture that can switch between control-centric and data-centric modes, allowing each core to operate in a streaming mode where data streams directly between cores and main memory, reducing the need for cache operations and enhancing data movement efficiency.




Dynamic object-level code transaction for improved performance of a computer
PatentInactiveUS7418580B1
Innovation
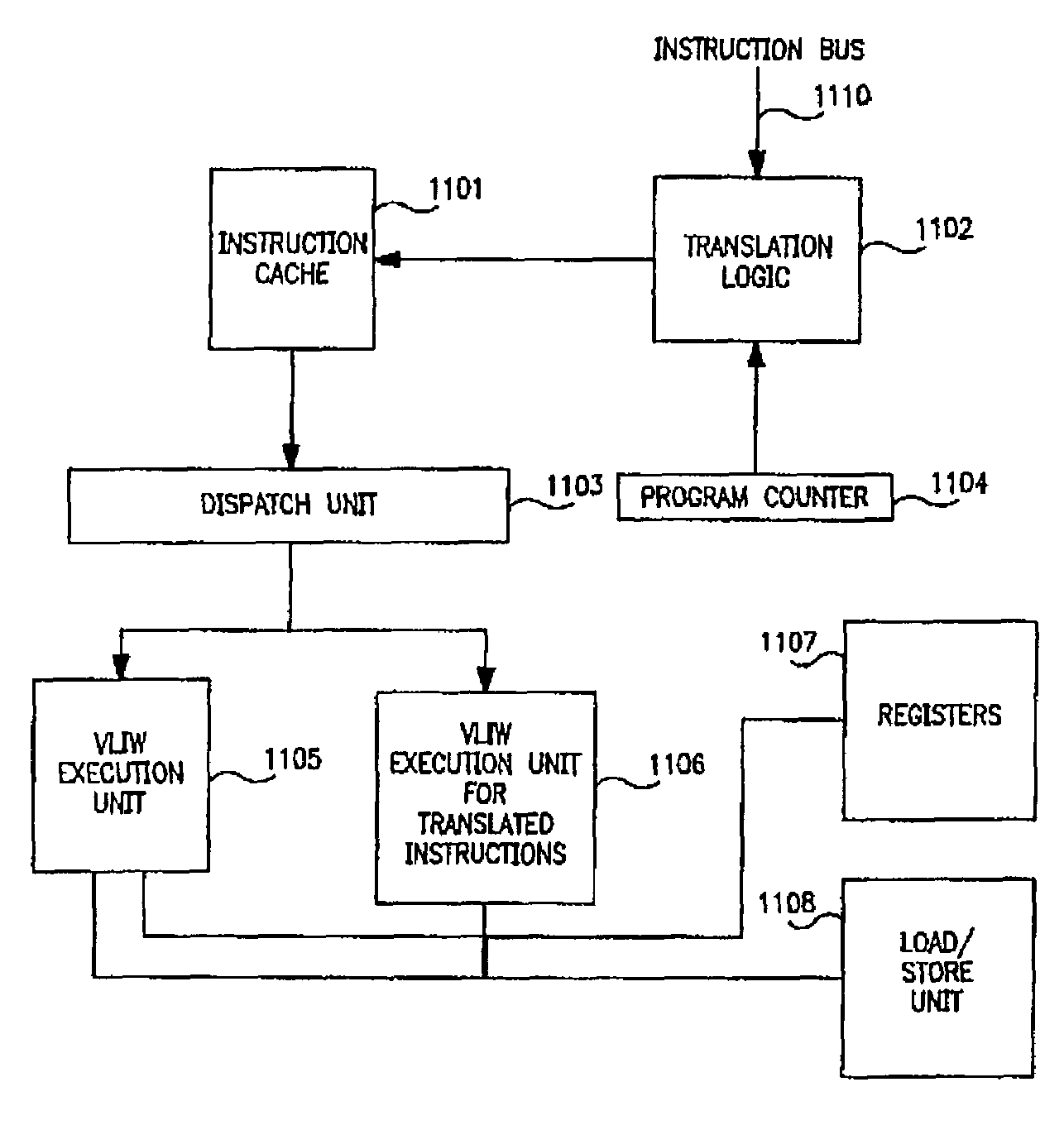
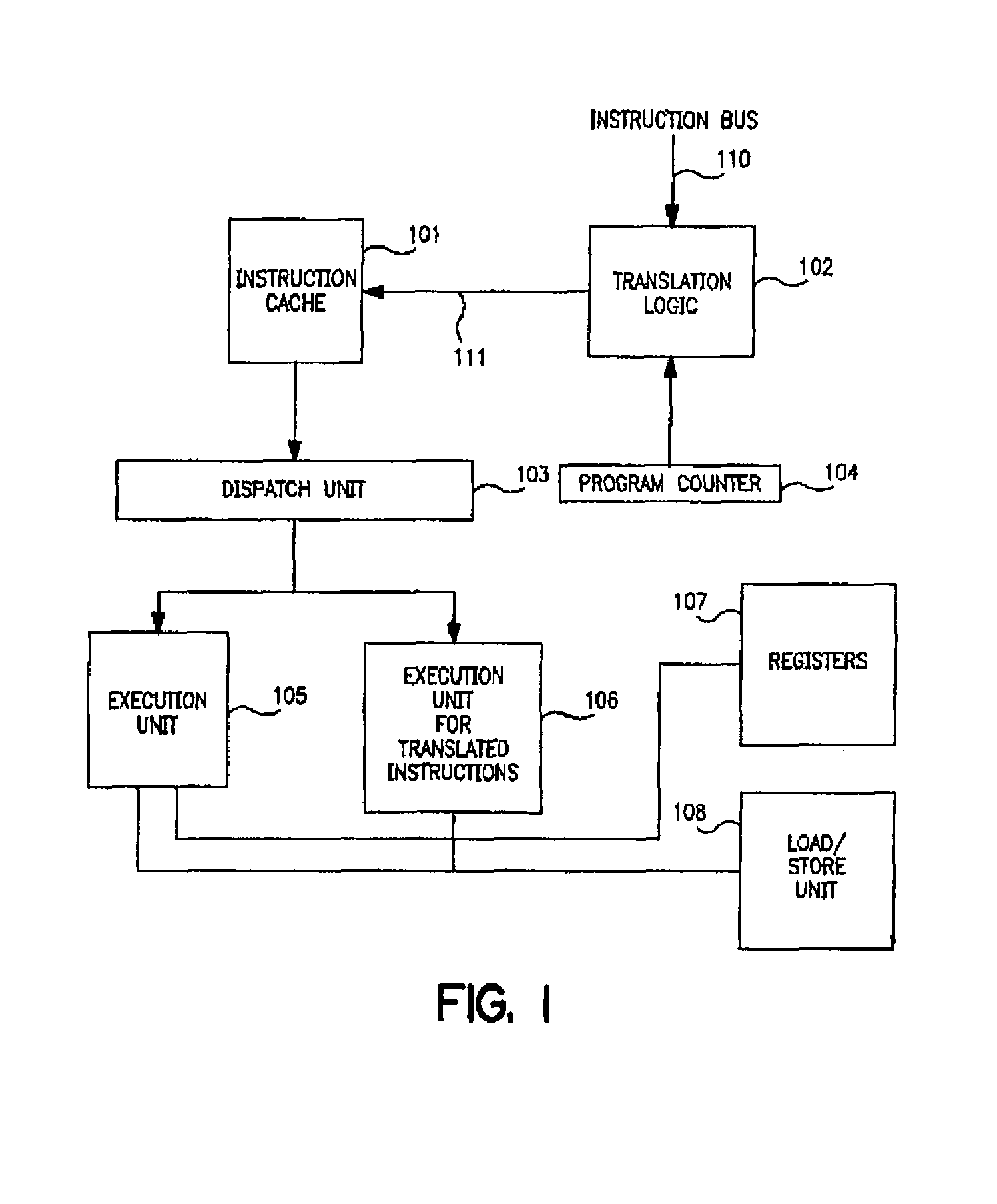
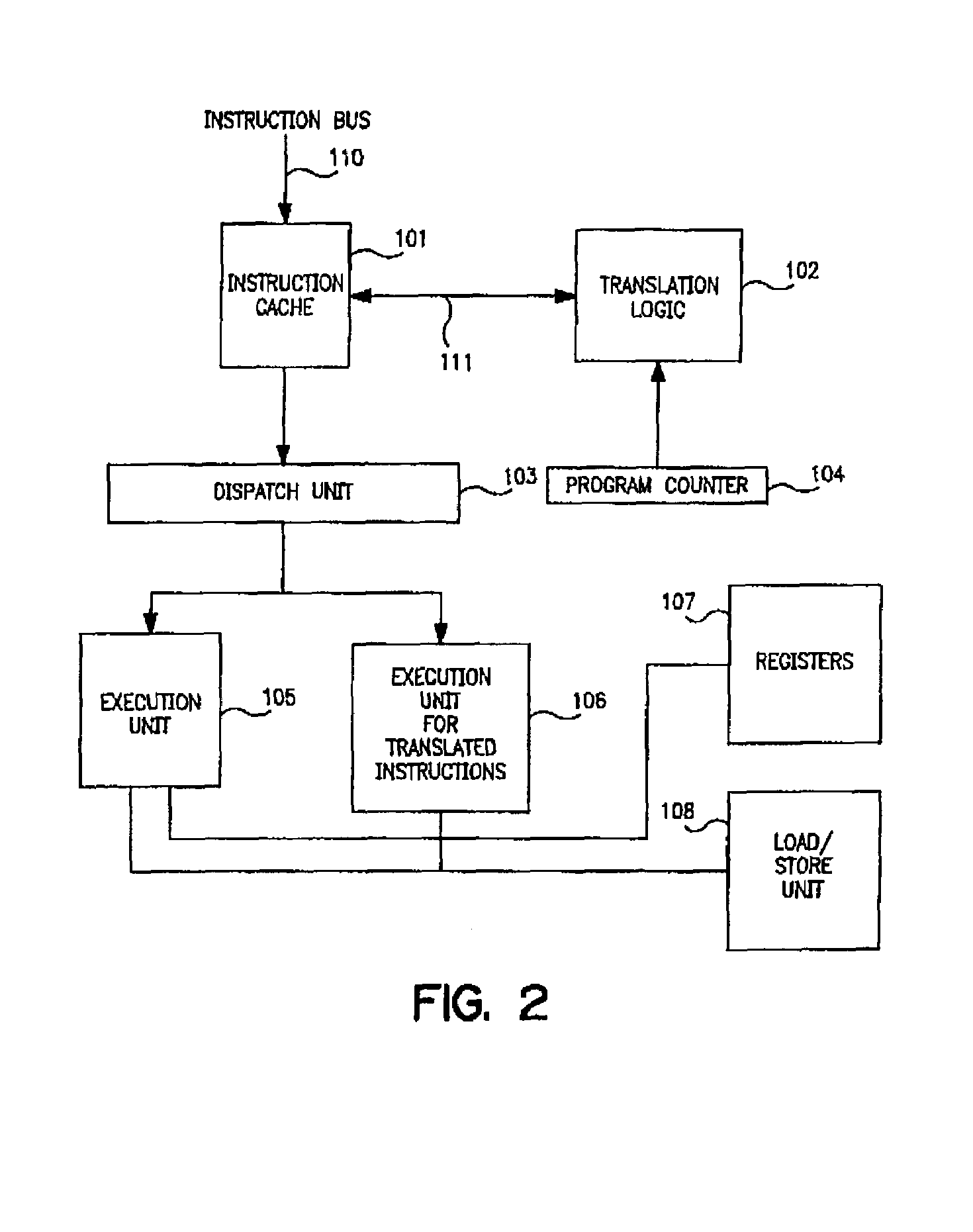
- A system and method that integrates translation logic into a computer processor to generate translated instructions by combining multiple object-level instructions into a single instruction, utilizing a translation table to detect qualifying instructions and replace them in the instruction stream, allowing for improved execution on upgraded architectures and enhanced security through decoding encoded instructions.

Power Efficiency Standards for High-Speed RISC Systems
Power efficiency has emerged as a critical design constraint for high-speed RISC systems, particularly as processing demands continue to escalate across high-tech applications. The establishment of comprehensive power efficiency standards becomes essential to balance performance optimization with energy consumption, ensuring sustainable operation in resource-constrained environments while maintaining competitive processing speeds.
Current industry standards for RISC power efficiency primarily focus on performance-per-watt metrics, with leading specifications targeting efficiency ratios exceeding 50 GOPS/W for general-purpose computing tasks. These benchmarks serve as fundamental guidelines for system designers, establishing minimum thresholds that high-speed RISC implementations must achieve to remain commercially viable in energy-sensitive applications.
Dynamic voltage and frequency scaling represents a cornerstone standard for power-efficient RISC operations. Modern specifications require systems to support multiple operating points, typically ranging from 0.8V to 1.2V supply voltages, with corresponding frequency adjustments from 500MHz to 3GHz. This adaptive approach enables real-time power optimization based on computational workload demands while preserving processing capability during peak performance requirements.
Clock gating and power island methodologies have become mandatory standards for high-speed RISC architectures. Industry specifications mandate that unused functional units must be capable of complete power shutdown within single clock cycles, achieving leakage current reductions of at least 90% during idle states. These standards ensure that power consumption scales proportionally with actual processing activity rather than maintaining constant high-power operation.
Thermal design power standards establish maximum heat dissipation limits for high-speed RISC systems, typically constraining total system power to 15-45 watts depending on application requirements. These specifications directly influence architectural decisions, requiring designers to implement sophisticated power management hierarchies that can dynamically redistribute computational loads across multiple processing cores to prevent thermal violations.
Advanced power efficiency standards increasingly incorporate machine learning-based prediction algorithms for workload-aware power management. These specifications require RISC systems to maintain historical performance data and predict future computational demands, enabling proactive power state transitions that minimize energy waste while avoiding performance degradation during critical processing phases.
Current industry standards for RISC power efficiency primarily focus on performance-per-watt metrics, with leading specifications targeting efficiency ratios exceeding 50 GOPS/W for general-purpose computing tasks. These benchmarks serve as fundamental guidelines for system designers, establishing minimum thresholds that high-speed RISC implementations must achieve to remain commercially viable in energy-sensitive applications.
Dynamic voltage and frequency scaling represents a cornerstone standard for power-efficient RISC operations. Modern specifications require systems to support multiple operating points, typically ranging from 0.8V to 1.2V supply voltages, with corresponding frequency adjustments from 500MHz to 3GHz. This adaptive approach enables real-time power optimization based on computational workload demands while preserving processing capability during peak performance requirements.
Clock gating and power island methodologies have become mandatory standards for high-speed RISC architectures. Industry specifications mandate that unused functional units must be capable of complete power shutdown within single clock cycles, achieving leakage current reductions of at least 90% during idle states. These standards ensure that power consumption scales proportionally with actual processing activity rather than maintaining constant high-power operation.
Thermal design power standards establish maximum heat dissipation limits for high-speed RISC systems, typically constraining total system power to 15-45 watts depending on application requirements. These specifications directly influence architectural decisions, requiring designers to implement sophisticated power management hierarchies that can dynamically redistribute computational loads across multiple processing cores to prevent thermal violations.
Advanced power efficiency standards increasingly incorporate machine learning-based prediction algorithms for workload-aware power management. These specifications require RISC systems to maintain historical performance data and predict future computational demands, enabling proactive power state transitions that minimize energy waste while avoiding performance degradation during critical processing phases.
Thermal Management Considerations in RISC Speed Optimization
Thermal management represents one of the most critical bottlenecks in achieving optimal RISC processor performance, particularly as clock frequencies and transistor densities continue to escalate in high-tech applications. The fundamental challenge lies in the exponential relationship between processing speed and heat generation, where increased computational throughput directly correlates with elevated thermal output that can compromise system reliability and performance sustainability.
Modern RISC architectures face significant thermal constraints when operating at peak performance levels. As processing speeds increase, the power density within silicon substrates rises dramatically, creating localized hotspots that can exceed safe operating temperatures. These thermal phenomena manifest most prominently in compute-intensive applications such as artificial intelligence inference, real-time signal processing, and high-frequency trading systems where sustained peak performance is essential.
The thermal design power envelope becomes increasingly restrictive as RISC processors push toward higher frequencies. Traditional cooling solutions often prove inadequate for maintaining optimal operating temperatures during sustained high-performance workloads. This limitation forces processors to implement dynamic thermal throttling mechanisms that automatically reduce clock speeds when temperature thresholds are exceeded, directly undermining the speed optimization objectives.
Advanced thermal management strategies have emerged as essential enablers for RISC speed optimization. Dynamic voltage and frequency scaling techniques allow processors to modulate power consumption in real-time based on thermal feedback, maintaining performance within safe operating parameters. Sophisticated on-die thermal sensors provide granular temperature monitoring across different processor regions, enabling precise thermal control algorithms.
Innovative cooling architectures specifically designed for high-performance RISC systems include advanced heat spreader designs, liquid cooling integration, and thermal interface material optimization. These solutions focus on maximizing heat dissipation efficiency while minimizing thermal resistance between the processor die and cooling infrastructure.
The integration of thermal-aware scheduling algorithms represents another crucial consideration, where workload distribution across processor cores is optimized based on real-time thermal profiles. This approach enables sustained high-performance operation by preventing thermal accumulation in specific processor regions while maintaining overall system throughput objectives.
Modern RISC architectures face significant thermal constraints when operating at peak performance levels. As processing speeds increase, the power density within silicon substrates rises dramatically, creating localized hotspots that can exceed safe operating temperatures. These thermal phenomena manifest most prominently in compute-intensive applications such as artificial intelligence inference, real-time signal processing, and high-frequency trading systems where sustained peak performance is essential.
The thermal design power envelope becomes increasingly restrictive as RISC processors push toward higher frequencies. Traditional cooling solutions often prove inadequate for maintaining optimal operating temperatures during sustained high-performance workloads. This limitation forces processors to implement dynamic thermal throttling mechanisms that automatically reduce clock speeds when temperature thresholds are exceeded, directly undermining the speed optimization objectives.
Advanced thermal management strategies have emerged as essential enablers for RISC speed optimization. Dynamic voltage and frequency scaling techniques allow processors to modulate power consumption in real-time based on thermal feedback, maintaining performance within safe operating parameters. Sophisticated on-die thermal sensors provide granular temperature monitoring across different processor regions, enabling precise thermal control algorithms.
Innovative cooling architectures specifically designed for high-performance RISC systems include advanced heat spreader designs, liquid cooling integration, and thermal interface material optimization. These solutions focus on maximizing heat dissipation efficiency while minimizing thermal resistance between the processor die and cooling infrastructure.
The integration of thermal-aware scheduling algorithms represents another crucial consideration, where workload distribution across processor cores is optimized based on real-time thermal profiles. This approach enables sustained high-performance operation by preventing thermal accumulation in specific processor regions while maintaining overall system throughput objectives.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!