

Seamless Rate vs Data Aggregation: Key Comparisons
MAR 2, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Seamless Rate vs Data Aggregation Background and Objectives
The telecommunications industry has witnessed unprecedented growth in data traffic and connectivity demands over the past decade, driven by the proliferation of mobile devices, IoT applications, and emerging technologies such as augmented reality and autonomous vehicles. This exponential increase has created critical challenges in network performance optimization, particularly in balancing seamless connectivity with efficient data management strategies.
Seamless rate technology focuses on maintaining continuous, uninterrupted data transmission across network boundaries and varying conditions. This approach prioritizes user experience by ensuring consistent connection quality during handovers, mobility scenarios, and network congestion periods. The technology encompasses advanced algorithms for dynamic bandwidth allocation, predictive resource management, and real-time quality of service adjustments.
Data aggregation represents a fundamentally different paradigm, emphasizing the collection, consolidation, and intelligent processing of information from multiple sources before transmission. This methodology aims to optimize network efficiency by reducing redundant data flows, minimizing bandwidth consumption, and enabling more sophisticated analytics capabilities at the network edge.
The evolution of these technologies has been shaped by distinct market drivers and technical requirements. Seamless rate solutions emerged from the need to support mobility-intensive applications and real-time services, while data aggregation technologies developed in response to the growing volume of sensor data and the need for intelligent network resource utilization.
Current industry trends indicate a convergence point where both approaches must coexist and complement each other. The advent of 5G networks, edge computing architectures, and massive IoT deployments has created scenarios where neither pure seamless connectivity nor simple data aggregation alone can address the complex requirements of modern communication systems.
The primary objective of this comparative analysis is to establish a comprehensive framework for evaluating the technical merits, implementation challenges, and strategic implications of seamless rate versus data aggregation approaches. This evaluation will encompass performance metrics, scalability considerations, cost-effectiveness analysis, and future technology roadmap alignment to provide actionable insights for strategic technology investment decisions.
Seamless rate technology focuses on maintaining continuous, uninterrupted data transmission across network boundaries and varying conditions. This approach prioritizes user experience by ensuring consistent connection quality during handovers, mobility scenarios, and network congestion periods. The technology encompasses advanced algorithms for dynamic bandwidth allocation, predictive resource management, and real-time quality of service adjustments.
Data aggregation represents a fundamentally different paradigm, emphasizing the collection, consolidation, and intelligent processing of information from multiple sources before transmission. This methodology aims to optimize network efficiency by reducing redundant data flows, minimizing bandwidth consumption, and enabling more sophisticated analytics capabilities at the network edge.
The evolution of these technologies has been shaped by distinct market drivers and technical requirements. Seamless rate solutions emerged from the need to support mobility-intensive applications and real-time services, while data aggregation technologies developed in response to the growing volume of sensor data and the need for intelligent network resource utilization.
Current industry trends indicate a convergence point where both approaches must coexist and complement each other. The advent of 5G networks, edge computing architectures, and massive IoT deployments has created scenarios where neither pure seamless connectivity nor simple data aggregation alone can address the complex requirements of modern communication systems.
The primary objective of this comparative analysis is to establish a comprehensive framework for evaluating the technical merits, implementation challenges, and strategic implications of seamless rate versus data aggregation approaches. This evaluation will encompass performance metrics, scalability considerations, cost-effectiveness analysis, and future technology roadmap alignment to provide actionable insights for strategic technology investment decisions.
Market Demand for Real-time Data Processing Solutions
The global demand for real-time data processing solutions has experienced unprecedented growth across multiple industries, driven by the increasing need for immediate insights and rapid decision-making capabilities. Organizations across sectors including financial services, telecommunications, e-commerce, and manufacturing are recognizing that traditional batch processing methods can no longer meet the velocity requirements of modern business operations.
Financial institutions represent one of the most significant market segments, where millisecond-level processing capabilities directly impact trading profitability, fraud detection accuracy, and customer experience quality. High-frequency trading platforms, risk management systems, and payment processing networks require seamless data flow with minimal latency, making the comparison between seamless rate optimization and data aggregation efficiency a critical consideration for technology selection.
The telecommunications industry demonstrates substantial appetite for real-time analytics solutions, particularly with the deployment of 5G networks and edge computing infrastructure. Network operators need immediate visibility into traffic patterns, service quality metrics, and security threats, creating demand for processing architectures that can handle massive data volumes while maintaining consistent throughput rates.
E-commerce and digital advertising platforms have emerged as major consumers of real-time processing technologies, where personalization engines, recommendation systems, and programmatic advertising require instantaneous data analysis. The ability to process user behavior data and deliver personalized content within hundreds of milliseconds has become a competitive differentiator, influencing purchasing decisions for data processing solutions.
Manufacturing and Industrial IoT applications are driving demand for edge-based real-time processing capabilities, where sensor data from production lines, quality control systems, and predictive maintenance applications must be processed with minimal delay. The choice between optimizing for seamless data rates versus implementing sophisticated aggregation strategies directly impacts operational efficiency and cost structures.
Cloud service providers are responding to this market demand by developing specialized real-time processing offerings, including managed streaming services, edge computing platforms, and hybrid architectures that balance processing speed with data consolidation requirements. The market shows clear preference for solutions that can dynamically adjust between seamless rate optimization and intelligent data aggregation based on specific use case requirements.
Enterprise adoption patterns indicate growing sophistication in evaluating real-time processing solutions, with organizations increasingly focused on total cost of ownership, scalability characteristics, and the ability to handle diverse data processing patterns within unified platforms.
Financial institutions represent one of the most significant market segments, where millisecond-level processing capabilities directly impact trading profitability, fraud detection accuracy, and customer experience quality. High-frequency trading platforms, risk management systems, and payment processing networks require seamless data flow with minimal latency, making the comparison between seamless rate optimization and data aggregation efficiency a critical consideration for technology selection.
The telecommunications industry demonstrates substantial appetite for real-time analytics solutions, particularly with the deployment of 5G networks and edge computing infrastructure. Network operators need immediate visibility into traffic patterns, service quality metrics, and security threats, creating demand for processing architectures that can handle massive data volumes while maintaining consistent throughput rates.
E-commerce and digital advertising platforms have emerged as major consumers of real-time processing technologies, where personalization engines, recommendation systems, and programmatic advertising require instantaneous data analysis. The ability to process user behavior data and deliver personalized content within hundreds of milliseconds has become a competitive differentiator, influencing purchasing decisions for data processing solutions.
Manufacturing and Industrial IoT applications are driving demand for edge-based real-time processing capabilities, where sensor data from production lines, quality control systems, and predictive maintenance applications must be processed with minimal delay. The choice between optimizing for seamless data rates versus implementing sophisticated aggregation strategies directly impacts operational efficiency and cost structures.
Cloud service providers are responding to this market demand by developing specialized real-time processing offerings, including managed streaming services, edge computing platforms, and hybrid architectures that balance processing speed with data consolidation requirements. The market shows clear preference for solutions that can dynamically adjust between seamless rate optimization and intelligent data aggregation based on specific use case requirements.
Enterprise adoption patterns indicate growing sophistication in evaluating real-time processing solutions, with organizations increasingly focused on total cost of ownership, scalability characteristics, and the ability to handle diverse data processing patterns within unified platforms.
Current State of Rate Control and Aggregation Technologies
Rate control technologies have evolved significantly over the past decade, with modern implementations focusing on adaptive algorithms that respond dynamically to network conditions. Current rate control mechanisms primarily utilize feedback-based approaches, including TCP congestion control variants such as BBR, CUBIC, and Reno. These protocols adjust transmission rates based on network feedback signals like round-trip time, packet loss, and bandwidth estimation. Advanced implementations incorporate machine learning algorithms to predict optimal transmission rates, with some systems achieving sub-millisecond response times to network changes.
Data aggregation technologies currently span multiple architectural approaches, from traditional batch processing systems to real-time streaming platforms. Apache Kafka, Apache Flink, and Apache Storm represent the mainstream solutions for high-throughput data aggregation, supporting millions of events per second. Modern aggregation systems employ distributed computing frameworks that partition data across multiple nodes, utilizing techniques like consistent hashing and data locality optimization. Edge computing has introduced new aggregation paradigms, where preliminary data processing occurs closer to data sources, reducing latency and bandwidth requirements.
The integration of rate control and data aggregation presents unique technical challenges in contemporary systems. Current hybrid approaches attempt to balance throughput optimization with data consistency requirements. Technologies like Apache Pulsar and Amazon Kinesis demonstrate sophisticated rate-aware aggregation capabilities, where aggregation windows dynamically adjust based on incoming data rates. These systems implement backpressure mechanisms that coordinate between rate control and aggregation components, preventing buffer overflow while maintaining data integrity.
Emerging technologies are addressing the convergence of rate control and aggregation through unified frameworks. Software-defined networking enables centralized rate management across distributed aggregation clusters, while container orchestration platforms like Kubernetes provide dynamic resource allocation based on real-time aggregation demands. Current research focuses on developing predictive models that anticipate aggregation requirements and preemptively adjust rate control parameters, potentially reducing system latency by up to 40% compared to reactive approaches.
The technological landscape shows increasing adoption of hybrid architectures that seamlessly integrate rate control mechanisms with aggregation pipelines, representing a significant shift from traditional isolated system designs toward more cohesive, performance-optimized solutions.
Data aggregation technologies currently span multiple architectural approaches, from traditional batch processing systems to real-time streaming platforms. Apache Kafka, Apache Flink, and Apache Storm represent the mainstream solutions for high-throughput data aggregation, supporting millions of events per second. Modern aggregation systems employ distributed computing frameworks that partition data across multiple nodes, utilizing techniques like consistent hashing and data locality optimization. Edge computing has introduced new aggregation paradigms, where preliminary data processing occurs closer to data sources, reducing latency and bandwidth requirements.
The integration of rate control and data aggregation presents unique technical challenges in contemporary systems. Current hybrid approaches attempt to balance throughput optimization with data consistency requirements. Technologies like Apache Pulsar and Amazon Kinesis demonstrate sophisticated rate-aware aggregation capabilities, where aggregation windows dynamically adjust based on incoming data rates. These systems implement backpressure mechanisms that coordinate between rate control and aggregation components, preventing buffer overflow while maintaining data integrity.
Emerging technologies are addressing the convergence of rate control and aggregation through unified frameworks. Software-defined networking enables centralized rate management across distributed aggregation clusters, while container orchestration platforms like Kubernetes provide dynamic resource allocation based on real-time aggregation demands. Current research focuses on developing predictive models that anticipate aggregation requirements and preemptively adjust rate control parameters, potentially reducing system latency by up to 40% compared to reactive approaches.
The technological landscape shows increasing adoption of hybrid architectures that seamlessly integrate rate control mechanisms with aggregation pipelines, representing a significant shift from traditional isolated system designs toward more cohesive, performance-optimized solutions.
Existing Rate Control vs Aggregation Solutions
01 Multi-source data aggregation and integration techniques
Systems and methods for aggregating data from multiple heterogeneous sources into a unified format. These techniques involve collecting data from various databases, sensors, or network nodes and consolidating them into a centralized repository. The aggregation process includes data normalization, transformation, and synchronization to ensure consistency across different data formats and protocols. Advanced algorithms are employed to handle real-time data streams and maintain data integrity during the aggregation process.- Multi-source data aggregation and integration techniques: Systems and methods for aggregating data from multiple heterogeneous sources into a unified format or platform. These techniques involve collecting, normalizing, and integrating data streams from various sources to enable seamless processing and analysis. The aggregation process includes data transformation, synchronization, and consolidation to ensure compatibility and consistency across different data formats and protocols.
- Rate control and bandwidth management in data transmission: Methods for controlling and optimizing data transmission rates to ensure seamless delivery of aggregated data. These approaches include dynamic rate adjustment, bandwidth allocation, and traffic shaping mechanisms that adapt to network conditions and system requirements. The techniques help maintain consistent data flow while preventing congestion and ensuring quality of service across different transmission channels.
- Real-time data streaming and continuous aggregation: Technologies for performing continuous aggregation of streaming data in real-time or near real-time scenarios. These solutions enable the processing of data as it arrives, supporting time-sensitive applications and analytics. The systems incorporate buffering, windowing, and incremental computation techniques to maintain seamless data flow while performing aggregation operations without significant latency.
- Distributed and parallel data aggregation architectures: Architectural frameworks for distributing data aggregation tasks across multiple nodes or processing units to achieve scalability and high throughput. These designs employ parallel processing, load balancing, and distributed computing principles to handle large-scale data aggregation efficiently. The architectures support seamless coordination between distributed components while maintaining data consistency and minimizing processing overhead.
- Adaptive aggregation with quality of service optimization: Intelligent systems that dynamically adjust aggregation parameters and strategies based on performance metrics and quality requirements. These methods incorporate feedback mechanisms, predictive algorithms, and adaptive policies to optimize the trade-off between aggregation rate, accuracy, and resource utilization. The techniques ensure seamless operation by automatically responding to changing conditions and maintaining desired service levels.
02 Rate control and bandwidth management in data transmission
Methods for controlling the rate at which aggregated data is transmitted across networks to optimize bandwidth utilization. These approaches include adaptive rate adjustment based on network conditions, traffic prioritization, and congestion control mechanisms. The systems dynamically adjust transmission rates to prevent network overload while maintaining quality of service. Techniques involve monitoring network parameters and implementing feedback loops to ensure seamless data flow without packet loss or excessive latency.Expand Specific Solutions03 Seamless data synchronization and consistency maintenance
Technologies for maintaining data consistency and synchronization across distributed systems during aggregation processes. These solutions address challenges in ensuring that aggregated data remains accurate and up-to-date across multiple nodes or devices. Methods include conflict resolution algorithms, version control mechanisms, and distributed consensus protocols. The systems enable seamless updates and modifications to aggregated data while preventing data corruption or inconsistencies that may arise from concurrent access or network delays.Expand Specific Solutions04 Real-time data aggregation with low latency processing
Architectures and algorithms designed to perform data aggregation with minimal latency for time-sensitive applications. These systems employ parallel processing, edge computing, and optimized data structures to reduce processing delays. Techniques include stream processing frameworks that handle continuous data flows and provide near-instantaneous aggregation results. The solutions are particularly suited for applications requiring immediate insights from aggregated data, such as monitoring systems or real-time analytics platforms.Expand Specific Solutions05 Scalable aggregation frameworks for high-volume data
Scalable architectures designed to handle large volumes of data during aggregation operations without performance degradation. These frameworks utilize distributed computing paradigms, load balancing techniques, and efficient data partitioning strategies. The systems can dynamically scale resources based on data volume and processing requirements, ensuring consistent performance as data grows. Implementation includes cloud-based solutions, clustered computing environments, and optimized storage mechanisms that support high-throughput data aggregation while maintaining seamless operation.Expand Specific Solutions
Major Players in Stream Processing and Data Analytics
The seamless rate vs data aggregation technology landscape represents a rapidly evolving sector within telecommunications and data processing industries. The market is experiencing significant growth driven by increasing demands for real-time data processing and network optimization. Key players demonstrate varying levels of technological maturity: established telecommunications giants like China Telecom Corp., ZTE Corp., and Alcatel-Lucent possess advanced infrastructure capabilities, while technology leaders such as IBM, Microsoft Technology Licensing, and Alibaba Cloud Computing offer sophisticated software solutions. Research institutions including Xi'an Jiaotong University, Nanjing University, and Fraunhofer-Gesellschaft contribute fundamental innovations. The competitive landscape shows a mature technology adoption phase among major corporations, with emerging companies like Hefei Klast Network Technology representing newer market entrants focusing on specialized applications.
China Telecom Corp. Ltd.
Technical Solution: China Telecom implements carrier-grade data aggregation platforms that handle massive subscriber data volumes with guaranteed service level agreements. Their solution combines network function virtualization with software-defined networking principles to create flexible data processing pipelines that can dynamically adjust collection rates based on network conditions and regulatory requirements. The system supports real-time billing data aggregation, network performance monitoring, and customer analytics with built-in redundancy and failover mechanisms for continuous operation.
Strengths: Extensive telecommunications infrastructure experience and proven scalability for millions of users. Weaknesses: Focus primarily on telecom applications and limited flexibility for non-carrier use cases.
ZTE Corp.
Technical Solution: ZTE develops telecommunications-focused data aggregation solutions specifically designed for 5G networks and IoT applications. Their technology emphasizes low-latency data collection with adaptive rate control mechanisms that respond to network congestion and device capabilities. The system implements hierarchical aggregation architectures with edge computing nodes that perform preliminary data processing before forwarding to central systems, enabling efficient bandwidth utilization and reduced transmission overhead in mobile network environments.
Strengths: Specialized expertise in telecommunications infrastructure and 5G network optimization. Weaknesses: Limited applicability outside telecommunications domain and dependency on specific network standards.
Core Technologies in Seamless Data Rate Management
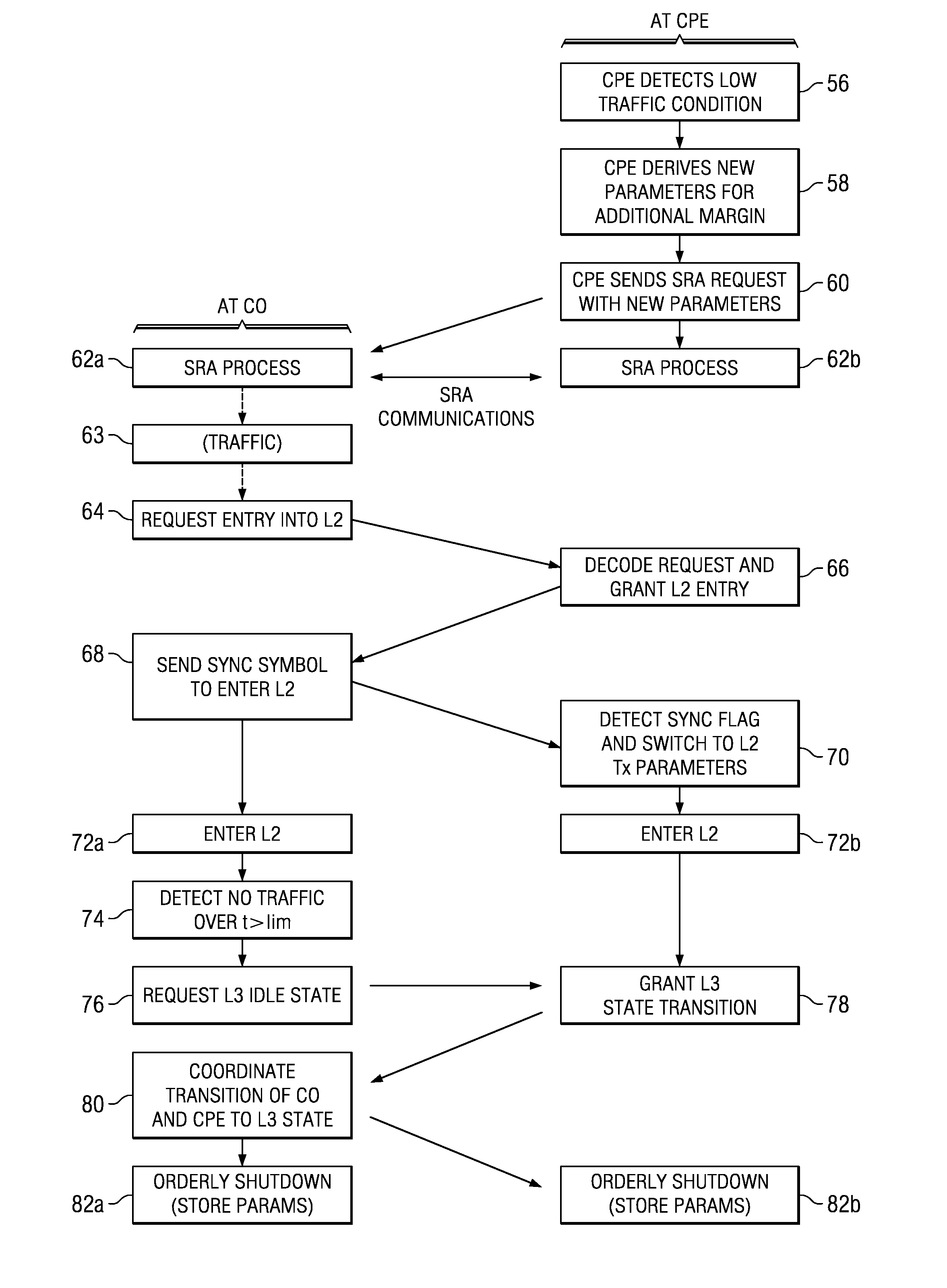
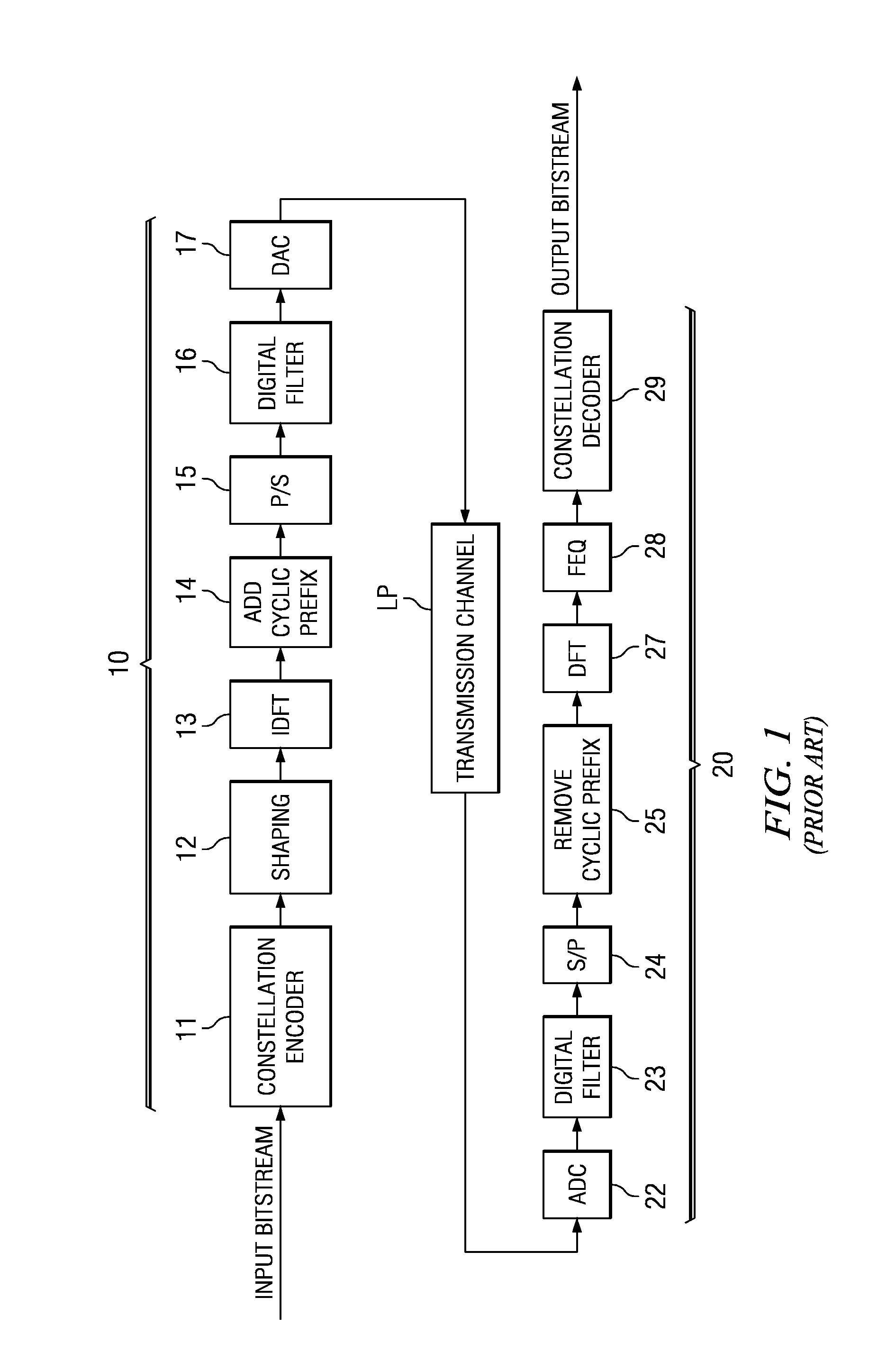
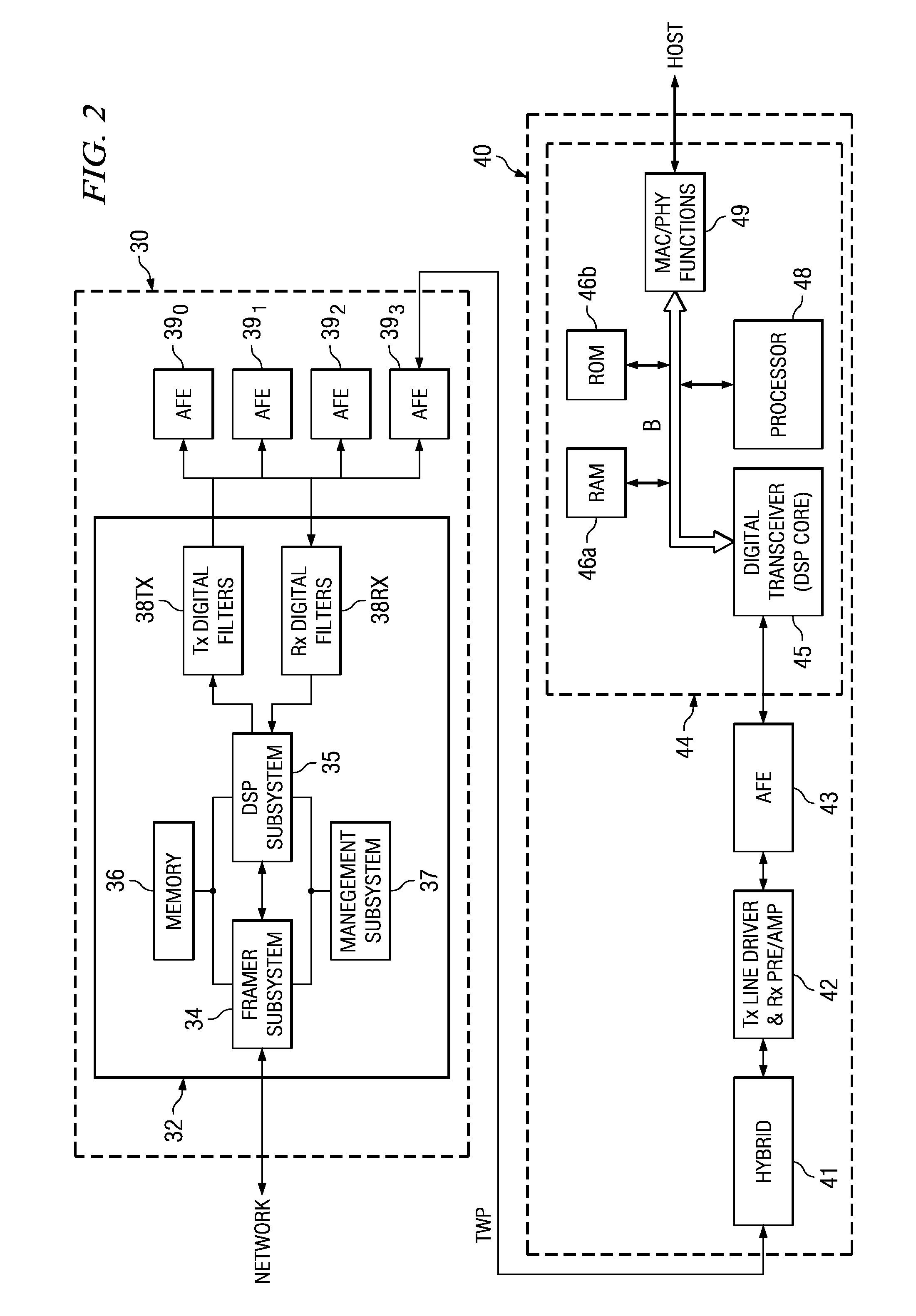
Error free dynamic rate change in a digital subscriber line DSL with constant delay
PatentActiveUS7457993B2
Innovation
- The method involves changing the interleaver depth proportionally with data rate changes to maintain constant delay, pausing transmission for a duration equal to the interleaver delay, and coordinating transmitter and receiver to prevent errors by flushing and refilling the interleaver, ensuring no interruption in service.




Optimized short initialization after low power mode for digital subscriber line (DSL) communications
PatentActiveUS7782930B2
Innovation
- Implementing logic circuitry in DSL modems to sense low or no communications traffic and perform seamless rate adaptation, reducing the data rate before entering a low power or idle state, thereby storing communications parameters that can be used to resume sessions without the need for parameter exchange during short initialization.

Performance Benchmarking Standards and Metrics
Establishing robust performance benchmarking standards for seamless rate versus data aggregation systems requires a comprehensive framework that addresses both quantitative metrics and qualitative assessment criteria. The fundamental challenge lies in creating standardized measurement protocols that can accurately capture the trade-offs between transmission continuity and data consolidation efficiency across diverse network environments and application scenarios.
Throughput measurement standards form the cornerstone of performance evaluation, encompassing both peak data rates and sustained transmission capabilities. For seamless rate systems, benchmarking focuses on maintaining consistent bandwidth utilization under varying network conditions, while data aggregation systems require metrics that evaluate the efficiency of data compression, batching, and consolidation processes. Industry-standard measurement intervals typically range from millisecond-level granularity for real-time applications to minute-based assessments for batch processing scenarios.
Latency benchmarking presents distinct challenges for each approach, requiring differentiated measurement methodologies. Seamless rate systems demand end-to-end latency measurements that account for buffer management and flow control mechanisms, while data aggregation systems necessitate evaluation of processing delays introduced by consolidation algorithms. Standard benchmarking protocols establish baseline latency thresholds of sub-10ms for real-time applications and sub-100ms for interactive services.
Quality of Service metrics encompass packet loss rates, jitter measurements, and service availability indicators. Seamless rate systems typically target packet loss rates below 0.01% for premium services, while data aggregation approaches may tolerate higher instantaneous loss rates provided overall data integrity remains intact. Jitter measurements require specialized protocols that account for the buffering strategies employed by each system architecture.
Resource utilization benchmarking evaluates computational overhead, memory consumption, and network infrastructure requirements. Standardized testing environments must account for varying hardware configurations, from edge computing devices with limited resources to high-performance data center deployments. CPU utilization metrics typically target maximum 80% sustained load under peak traffic conditions, while memory efficiency benchmarks evaluate the scalability of buffering and caching mechanisms.
Scalability assessment protocols define performance degradation curves as system load increases, establishing clear breakpoints where performance characteristics fundamentally change. These benchmarks must account for both horizontal scaling across multiple processing nodes and vertical scaling within individual system components, providing comprehensive evaluation frameworks for enterprise deployment scenarios.
Throughput measurement standards form the cornerstone of performance evaluation, encompassing both peak data rates and sustained transmission capabilities. For seamless rate systems, benchmarking focuses on maintaining consistent bandwidth utilization under varying network conditions, while data aggregation systems require metrics that evaluate the efficiency of data compression, batching, and consolidation processes. Industry-standard measurement intervals typically range from millisecond-level granularity for real-time applications to minute-based assessments for batch processing scenarios.
Latency benchmarking presents distinct challenges for each approach, requiring differentiated measurement methodologies. Seamless rate systems demand end-to-end latency measurements that account for buffer management and flow control mechanisms, while data aggregation systems necessitate evaluation of processing delays introduced by consolidation algorithms. Standard benchmarking protocols establish baseline latency thresholds of sub-10ms for real-time applications and sub-100ms for interactive services.
Quality of Service metrics encompass packet loss rates, jitter measurements, and service availability indicators. Seamless rate systems typically target packet loss rates below 0.01% for premium services, while data aggregation approaches may tolerate higher instantaneous loss rates provided overall data integrity remains intact. Jitter measurements require specialized protocols that account for the buffering strategies employed by each system architecture.
Resource utilization benchmarking evaluates computational overhead, memory consumption, and network infrastructure requirements. Standardized testing environments must account for varying hardware configurations, from edge computing devices with limited resources to high-performance data center deployments. CPU utilization metrics typically target maximum 80% sustained load under peak traffic conditions, while memory efficiency benchmarks evaluate the scalability of buffering and caching mechanisms.
Scalability assessment protocols define performance degradation curves as system load increases, establishing clear breakpoints where performance characteristics fundamentally change. These benchmarks must account for both horizontal scaling across multiple processing nodes and vertical scaling within individual system components, providing comprehensive evaluation frameworks for enterprise deployment scenarios.
Scalability Challenges in Distributed Data Systems
Distributed data systems face unprecedented scalability challenges when balancing seamless data rate processing with efficient data aggregation mechanisms. As data volumes continue to grow exponentially, traditional centralized architectures struggle to maintain performance while ensuring data consistency across multiple nodes. The fundamental tension between achieving high throughput rates and maintaining coherent aggregated views creates complex engineering trade-offs that significantly impact system scalability.
The primary scalability bottleneck emerges from the inherent conflict between real-time data streaming requirements and the computational overhead of continuous aggregation operations. When systems prioritize seamless rate processing, they often sacrifice aggregation accuracy due to network latency and synchronization delays across distributed nodes. Conversely, systems optimized for precise data aggregation typically experience reduced throughput rates as they allocate substantial resources to coordination protocols and consistency maintenance.
Network bandwidth limitations compound these challenges, particularly in geographically distributed deployments where inter-node communication latency can reach hundreds of milliseconds. The CAP theorem fundamentally constrains system design choices, forcing architects to choose between consistency, availability, and partition tolerance. This constraint becomes especially pronounced when implementing real-time aggregation functions across multiple data centers or cloud regions.
Memory management presents another critical scalability constraint in distributed aggregation scenarios. As the number of concurrent aggregation operations increases, each node must maintain larger state information, leading to memory exhaustion and garbage collection overhead. The challenge intensifies when supporting sliding window aggregations or complex analytical queries that require historical data retention across the distributed infrastructure.
Load balancing complexity increases exponentially with system scale, as uneven data distribution can create hotspots that severely impact both rate processing and aggregation performance. Dynamic partitioning strategies must continuously adapt to changing data patterns while maintaining aggregation correctness, requiring sophisticated coordination mechanisms that themselves become scalability bottlenecks.
Fault tolerance mechanisms further complicate scalability considerations, as systems must replicate both streaming data and intermediate aggregation states across multiple nodes. The overhead of maintaining consistency during node failures or network partitions can dramatically reduce overall system throughput, particularly when implementing strong consistency guarantees for critical aggregation operations.
The primary scalability bottleneck emerges from the inherent conflict between real-time data streaming requirements and the computational overhead of continuous aggregation operations. When systems prioritize seamless rate processing, they often sacrifice aggregation accuracy due to network latency and synchronization delays across distributed nodes. Conversely, systems optimized for precise data aggregation typically experience reduced throughput rates as they allocate substantial resources to coordination protocols and consistency maintenance.
Network bandwidth limitations compound these challenges, particularly in geographically distributed deployments where inter-node communication latency can reach hundreds of milliseconds. The CAP theorem fundamentally constrains system design choices, forcing architects to choose between consistency, availability, and partition tolerance. This constraint becomes especially pronounced when implementing real-time aggregation functions across multiple data centers or cloud regions.
Memory management presents another critical scalability constraint in distributed aggregation scenarios. As the number of concurrent aggregation operations increases, each node must maintain larger state information, leading to memory exhaustion and garbage collection overhead. The challenge intensifies when supporting sliding window aggregations or complex analytical queries that require historical data retention across the distributed infrastructure.
Load balancing complexity increases exponentially with system scale, as uneven data distribution can create hotspots that severely impact both rate processing and aggregation performance. Dynamic partitioning strategies must continuously adapt to changing data patterns while maintaining aggregation correctness, requiring sophisticated coordination mechanisms that themselves become scalability bottlenecks.
Fault tolerance mechanisms further complicate scalability considerations, as systems must replicate both streaming data and intermediate aggregation states across multiple nodes. The overhead of maintaining consistency during node failures or network partitions can dramatically reduce overall system throughput, particularly when implementing strong consistency guarantees for critical aggregation operations.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!