

Using Data Augmentation in Virtual Reality Training
FEB 27, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
VR Training Data Augmentation Background and Objectives
Virtual reality training has emerged as a transformative technology across multiple industries, fundamentally changing how organizations approach skill development and knowledge transfer. From healthcare and aviation to manufacturing and military applications, VR training systems offer immersive, risk-free environments where learners can practice complex procedures and scenarios without real-world consequences. The technology has evolved from simple simulation tools to sophisticated platforms capable of delivering highly realistic, interactive training experiences that closely mirror actual working conditions.
The historical development of VR training can be traced back to early flight simulators in the 1960s, which laid the groundwork for immersive training methodologies. Over the past two decades, advances in computing power, display technologies, and motion tracking have dramatically improved the fidelity and accessibility of VR training systems. The integration of haptic feedback, spatial audio, and photorealistic graphics has created training environments that engage multiple senses, leading to enhanced learning outcomes and improved knowledge retention rates.
However, the effectiveness of VR training systems heavily depends on the quality and diversity of training scenarios available to learners. Traditional content creation methods for VR training are resource-intensive, requiring significant time, expertise, and financial investment to develop comprehensive training modules. This limitation has created a bottleneck in scaling VR training programs, particularly for organizations seeking to address diverse learning needs and rapidly evolving skill requirements.
Data augmentation techniques, originally developed for machine learning applications, present a promising solution to overcome these content creation challenges. By systematically generating variations of existing training scenarios, data augmentation can exponentially expand the available training content while maintaining educational effectiveness. This approach enables the creation of diverse training experiences from limited base scenarios, addressing the scalability issues that have historically constrained VR training implementations.
The primary objective of implementing data augmentation in VR training is to create scalable, cost-effective training solutions that can adapt to diverse learning requirements without compromising educational quality. This involves developing methodologies to automatically generate scenario variations, environmental conditions, and procedural complexities that challenge learners while maintaining pedagogical coherence. Additionally, the technology aims to personalize training experiences by generating content tailored to individual skill levels and learning preferences.
Furthermore, data augmentation in VR training seeks to address the challenge of rare event training, where critical scenarios occur infrequently in real-world settings but require extensive practice for competency development. By generating synthetic variations of these scenarios, training programs can ensure comprehensive preparation for low-probability, high-impact situations that are essential for professional competency but difficult to replicate through traditional training methods.
The historical development of VR training can be traced back to early flight simulators in the 1960s, which laid the groundwork for immersive training methodologies. Over the past two decades, advances in computing power, display technologies, and motion tracking have dramatically improved the fidelity and accessibility of VR training systems. The integration of haptic feedback, spatial audio, and photorealistic graphics has created training environments that engage multiple senses, leading to enhanced learning outcomes and improved knowledge retention rates.
However, the effectiveness of VR training systems heavily depends on the quality and diversity of training scenarios available to learners. Traditional content creation methods for VR training are resource-intensive, requiring significant time, expertise, and financial investment to develop comprehensive training modules. This limitation has created a bottleneck in scaling VR training programs, particularly for organizations seeking to address diverse learning needs and rapidly evolving skill requirements.
Data augmentation techniques, originally developed for machine learning applications, present a promising solution to overcome these content creation challenges. By systematically generating variations of existing training scenarios, data augmentation can exponentially expand the available training content while maintaining educational effectiveness. This approach enables the creation of diverse training experiences from limited base scenarios, addressing the scalability issues that have historically constrained VR training implementations.
The primary objective of implementing data augmentation in VR training is to create scalable, cost-effective training solutions that can adapt to diverse learning requirements without compromising educational quality. This involves developing methodologies to automatically generate scenario variations, environmental conditions, and procedural complexities that challenge learners while maintaining pedagogical coherence. Additionally, the technology aims to personalize training experiences by generating content tailored to individual skill levels and learning preferences.
Furthermore, data augmentation in VR training seeks to address the challenge of rare event training, where critical scenarios occur infrequently in real-world settings but require extensive practice for competency development. By generating synthetic variations of these scenarios, training programs can ensure comprehensive preparation for low-probability, high-impact situations that are essential for professional competency but difficult to replicate through traditional training methods.
Market Demand for Enhanced VR Training Solutions
The global virtual reality training market is experiencing unprecedented growth driven by organizations' increasing recognition of VR's transformative potential in skill development and knowledge transfer. Traditional training methodologies face significant limitations in providing safe, repeatable, and cost-effective learning environments, particularly in high-risk industries such as healthcare, aviation, manufacturing, and emergency response. These sectors demand training solutions that can simulate complex scenarios without exposing learners to actual dangers or incurring substantial operational costs.
Healthcare institutions represent one of the most promising market segments for enhanced VR training solutions. Medical professionals require extensive hands-on practice for surgical procedures, patient interaction, and emergency response protocols. Data augmentation techniques enable the creation of diverse patient scenarios, anatomical variations, and rare medical conditions that would be difficult to encounter consistently in traditional clinical training. This capability addresses the critical need for comprehensive medical education while reducing dependency on cadavers, live patients, and expensive medical equipment.
The aviation and aerospace industries demonstrate substantial demand for advanced VR training systems enhanced through data augmentation. Pilot training programs require exposure to numerous flight conditions, weather patterns, and emergency scenarios. Data augmentation allows training systems to generate virtually unlimited combinations of flight parameters, aircraft configurations, and environmental conditions, significantly expanding the scope of pilot preparation while reducing the costs associated with actual flight hours and aircraft maintenance.
Manufacturing and industrial sectors increasingly seek VR training solutions to address workforce development challenges and safety compliance requirements. Data augmentation enables the simulation of various equipment configurations, production scenarios, and safety incidents that workers might encounter throughout their careers. This approach addresses the growing skills gap in technical industries while ensuring consistent safety training across global operations.
Corporate training markets show rising interest in VR solutions for soft skills development, leadership training, and customer service preparation. Data augmentation techniques can generate diverse interpersonal scenarios, cultural contexts, and communication challenges that enhance the realism and effectiveness of virtual training environments. Organizations recognize the potential for improved employee engagement and retention through immersive learning experiences.
The defense and public safety sectors represent significant growth opportunities for enhanced VR training solutions. Military and law enforcement agencies require training systems capable of simulating diverse operational environments, threat scenarios, and tactical situations. Data augmentation enables the creation of comprehensive training libraries that adapt to evolving security challenges and operational requirements while maintaining cost efficiency and training effectiveness.
Healthcare institutions represent one of the most promising market segments for enhanced VR training solutions. Medical professionals require extensive hands-on practice for surgical procedures, patient interaction, and emergency response protocols. Data augmentation techniques enable the creation of diverse patient scenarios, anatomical variations, and rare medical conditions that would be difficult to encounter consistently in traditional clinical training. This capability addresses the critical need for comprehensive medical education while reducing dependency on cadavers, live patients, and expensive medical equipment.
The aviation and aerospace industries demonstrate substantial demand for advanced VR training systems enhanced through data augmentation. Pilot training programs require exposure to numerous flight conditions, weather patterns, and emergency scenarios. Data augmentation allows training systems to generate virtually unlimited combinations of flight parameters, aircraft configurations, and environmental conditions, significantly expanding the scope of pilot preparation while reducing the costs associated with actual flight hours and aircraft maintenance.
Manufacturing and industrial sectors increasingly seek VR training solutions to address workforce development challenges and safety compliance requirements. Data augmentation enables the simulation of various equipment configurations, production scenarios, and safety incidents that workers might encounter throughout their careers. This approach addresses the growing skills gap in technical industries while ensuring consistent safety training across global operations.
Corporate training markets show rising interest in VR solutions for soft skills development, leadership training, and customer service preparation. Data augmentation techniques can generate diverse interpersonal scenarios, cultural contexts, and communication challenges that enhance the realism and effectiveness of virtual training environments. Organizations recognize the potential for improved employee engagement and retention through immersive learning experiences.
The defense and public safety sectors represent significant growth opportunities for enhanced VR training solutions. Military and law enforcement agencies require training systems capable of simulating diverse operational environments, threat scenarios, and tactical situations. Data augmentation enables the creation of comprehensive training libraries that adapt to evolving security challenges and operational requirements while maintaining cost efficiency and training effectiveness.
Current State and Challenges of VR Training Data
Virtual reality training has emerged as a transformative technology across multiple industries, from healthcare and aviation to manufacturing and military applications. However, the current state of VR training data presents significant limitations that constrain the full potential of these systems. Most existing VR training platforms rely on relatively static datasets that lack the diversity and complexity required to simulate real-world scenarios effectively.
The predominant approach in current VR training systems involves creating predefined scenarios with limited variability. These systems typically feature fixed environmental conditions, standardized procedural sequences, and predictable outcomes. While this approach ensures consistency in training delivery, it fails to adequately prepare trainees for the unpredictable nature of real-world situations they will encounter in their professional environments.
Data collection for VR training presents substantial challenges, particularly in specialized fields where expert knowledge and rare scenarios are difficult to capture. Traditional data gathering methods often require extensive time investments from subject matter experts, expensive motion capture equipment, and controlled laboratory environments. This results in datasets that are not only costly to produce but also limited in scope and representativeness.
The scalability issue represents another critical challenge in current VR training data management. As organizations seek to expand their training programs to accommodate larger numbers of trainees or cover broader skill sets, the linear relationship between data requirements and system costs becomes prohibitive. Each new training scenario typically demands separate data collection efforts, content creation processes, and validation procedures.
Quality assurance and standardization of VR training data remain inconsistent across different platforms and applications. The absence of industry-wide standards for data formats, interaction protocols, and performance metrics creates fragmentation that limits interoperability and knowledge transfer between systems. This fragmentation particularly affects organizations that utilize multiple VR training platforms or seek to integrate VR training with existing learning management systems.
Current VR training data also suffers from limited adaptability to individual learner needs and learning styles. Most systems employ one-size-fits-all approaches that do not account for varying skill levels, cultural backgrounds, or specific learning objectives. This limitation reduces training effectiveness and fails to optimize learning outcomes for diverse user populations.
The temporal aspect of data currency presents ongoing challenges, as many VR training systems struggle to incorporate updated procedures, regulations, or best practices. Manual updating processes are time-consuming and often result in outdated training content that may not reflect current industry standards or emerging technologies.
The predominant approach in current VR training systems involves creating predefined scenarios with limited variability. These systems typically feature fixed environmental conditions, standardized procedural sequences, and predictable outcomes. While this approach ensures consistency in training delivery, it fails to adequately prepare trainees for the unpredictable nature of real-world situations they will encounter in their professional environments.
Data collection for VR training presents substantial challenges, particularly in specialized fields where expert knowledge and rare scenarios are difficult to capture. Traditional data gathering methods often require extensive time investments from subject matter experts, expensive motion capture equipment, and controlled laboratory environments. This results in datasets that are not only costly to produce but also limited in scope and representativeness.
The scalability issue represents another critical challenge in current VR training data management. As organizations seek to expand their training programs to accommodate larger numbers of trainees or cover broader skill sets, the linear relationship between data requirements and system costs becomes prohibitive. Each new training scenario typically demands separate data collection efforts, content creation processes, and validation procedures.
Quality assurance and standardization of VR training data remain inconsistent across different platforms and applications. The absence of industry-wide standards for data formats, interaction protocols, and performance metrics creates fragmentation that limits interoperability and knowledge transfer between systems. This fragmentation particularly affects organizations that utilize multiple VR training platforms or seek to integrate VR training with existing learning management systems.
Current VR training data also suffers from limited adaptability to individual learner needs and learning styles. Most systems employ one-size-fits-all approaches that do not account for varying skill levels, cultural backgrounds, or specific learning objectives. This limitation reduces training effectiveness and fails to optimize learning outcomes for diverse user populations.
The temporal aspect of data currency presents ongoing challenges, as many VR training systems struggle to incorporate updated procedures, regulations, or best practices. Manual updating processes are time-consuming and often result in outdated training content that may not reflect current industry standards or emerging technologies.
Current Data Augmentation Methods for VR Training
01 Synthetic data generation for training machine learning models
Data augmentation techniques involve generating synthetic training data to expand limited datasets. This approach creates artificial samples by applying transformations, variations, or generative models to existing data. The synthetic data helps improve model robustness and generalization by providing diverse training examples that capture different variations and edge cases not present in the original dataset.- Synthetic data generation for training machine learning models: Data augmentation techniques involve generating synthetic training data to expand limited datasets. This approach creates artificial samples by applying transformations, variations, or generative models to existing data. The synthetic data helps improve model robustness and generalization by providing diverse training examples that capture different variations and edge cases not present in the original dataset.
- Image transformation and manipulation techniques: Various image processing methods are applied to augment visual data, including rotation, scaling, cropping, flipping, color adjustment, and noise injection. These transformations create multiple variations of original images while preserving essential features and labels. The augmented images help neural networks learn invariant representations and reduce overfitting in computer vision applications.
- Adversarial and generative augmentation methods: Advanced augmentation approaches utilize generative adversarial networks and other deep learning architectures to create realistic synthetic samples. These methods learn the underlying data distribution and generate new examples that maintain statistical properties of the original dataset. The technique is particularly effective for addressing class imbalance and creating rare event samples.
- Text and natural language data augmentation: Augmentation strategies for textual data include synonym replacement, back-translation, paraphrasing, and contextual word embedding techniques. These methods generate semantically similar text variations while preserving meaning and intent. The augmented text corpus enhances natural language processing model performance across various tasks including classification, sentiment analysis, and language understanding.
- Domain-specific and adaptive augmentation strategies: Specialized augmentation techniques are designed for specific domains such as medical imaging, speech recognition, or time-series data. These methods incorporate domain knowledge and constraints to generate meaningful augmented samples. Adaptive approaches automatically learn optimal augmentation policies based on the task and dataset characteristics, improving efficiency and effectiveness of the augmentation process.
02 Image transformation and manipulation techniques
Various image processing methods are applied to augment visual data, including rotation, scaling, cropping, flipping, color adjustment, and noise injection. These transformations create multiple variations of original images while preserving essential features and labels. Such techniques are particularly effective for computer vision applications where training data diversity is crucial for model performance.Expand Specific Solutions03 Neural network-based augmentation strategies
Advanced augmentation methods utilize neural networks and deep learning architectures to automatically learn and generate augmented data. These systems can identify optimal augmentation policies, generate realistic synthetic samples through adversarial networks, or apply learned transformations that maximize model performance. The approach adapts augmentation strategies based on the specific characteristics of the dataset and task requirements.Expand Specific Solutions04 Domain-specific data augmentation for specialized applications
Tailored augmentation techniques are developed for specific domains such as medical imaging, natural language processing, or time-series data. These methods consider domain-specific constraints and characteristics to generate meaningful augmented samples. The techniques may involve specialized transformations, context-aware modifications, or domain knowledge integration to ensure augmented data maintains semantic validity.Expand Specific Solutions05 Automated augmentation policy optimization
Systems and methods for automatically discovering and optimizing data augmentation strategies through search algorithms, reinforcement learning, or evolutionary approaches. These techniques systematically explore the space of possible augmentation operations and their parameters to identify the most effective combinations for specific tasks. The automated approach reduces manual effort and can discover novel augmentation strategies that outperform hand-crafted methods.Expand Specific Solutions
Key Players in VR Training and Data Augmentation
The virtual reality training market utilizing data augmentation is experiencing rapid growth, transitioning from early adoption to mainstream implementation across industries. The market demonstrates substantial expansion potential, driven by increasing demand for immersive, cost-effective training solutions in healthcare, automotive, and enterprise sectors. Technology maturity varies significantly among key players: established tech giants like IBM, Google, Microsoft Technology Licensing, and Adobe leverage robust AI and cloud infrastructures to integrate sophisticated data augmentation techniques. Specialized VR training companies such as FVRVS, EXO Insights, and XR Health IL represent emerging innovators focusing on niche applications. Traditional corporations including Audi, Hyundai AutoEver, and Honeywell International Technologies are integrating VR training into operational workflows. The competitive landscape shows convergence between hardware manufacturers like NEC and Omron, software developers, and industry-specific solution providers, indicating a maturing ecosystem with diverse technological approaches and implementation strategies.
International Business Machines Corp.
Technical Solution: IBM's Watson-powered VR training solutions utilize cognitive computing and advanced analytics to enhance data augmentation in virtual environments. Their approach combines natural language processing, computer vision, and predictive analytics to generate contextually relevant training scenarios. The system automatically creates variations in training content based on learner profiles, performance metrics, and industry-specific requirements, particularly strong in professional services and technical training applications.
Strengths: Advanced AI capabilities and enterprise-grade analytics integration. Weaknesses: Requires significant technical expertise for implementation and customization.
Google LLC
Technical Solution: Google has developed comprehensive VR training platforms that leverage advanced data augmentation techniques including procedural content generation, synthetic data creation, and machine learning-driven scenario variations. Their approach utilizes computer vision algorithms to automatically generate diverse training scenarios from limited base datasets, enabling scalable VR training experiences across multiple domains including medical simulation, industrial training, and educational applications.
Strengths: Robust AI infrastructure and extensive data processing capabilities. Weaknesses: Limited focus on specialized industry-specific training requirements.
Core Technologies in VR Training Data Enhancement
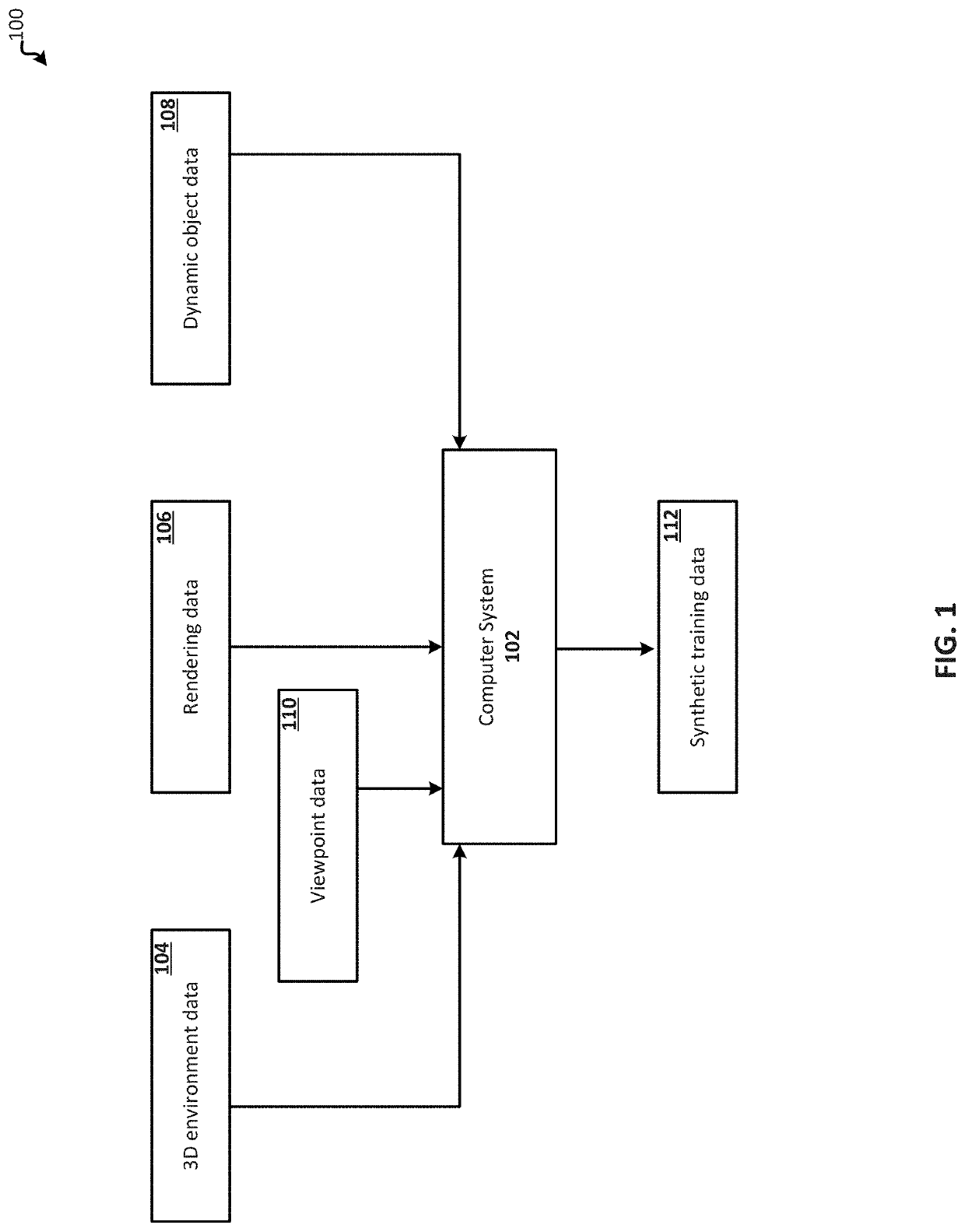
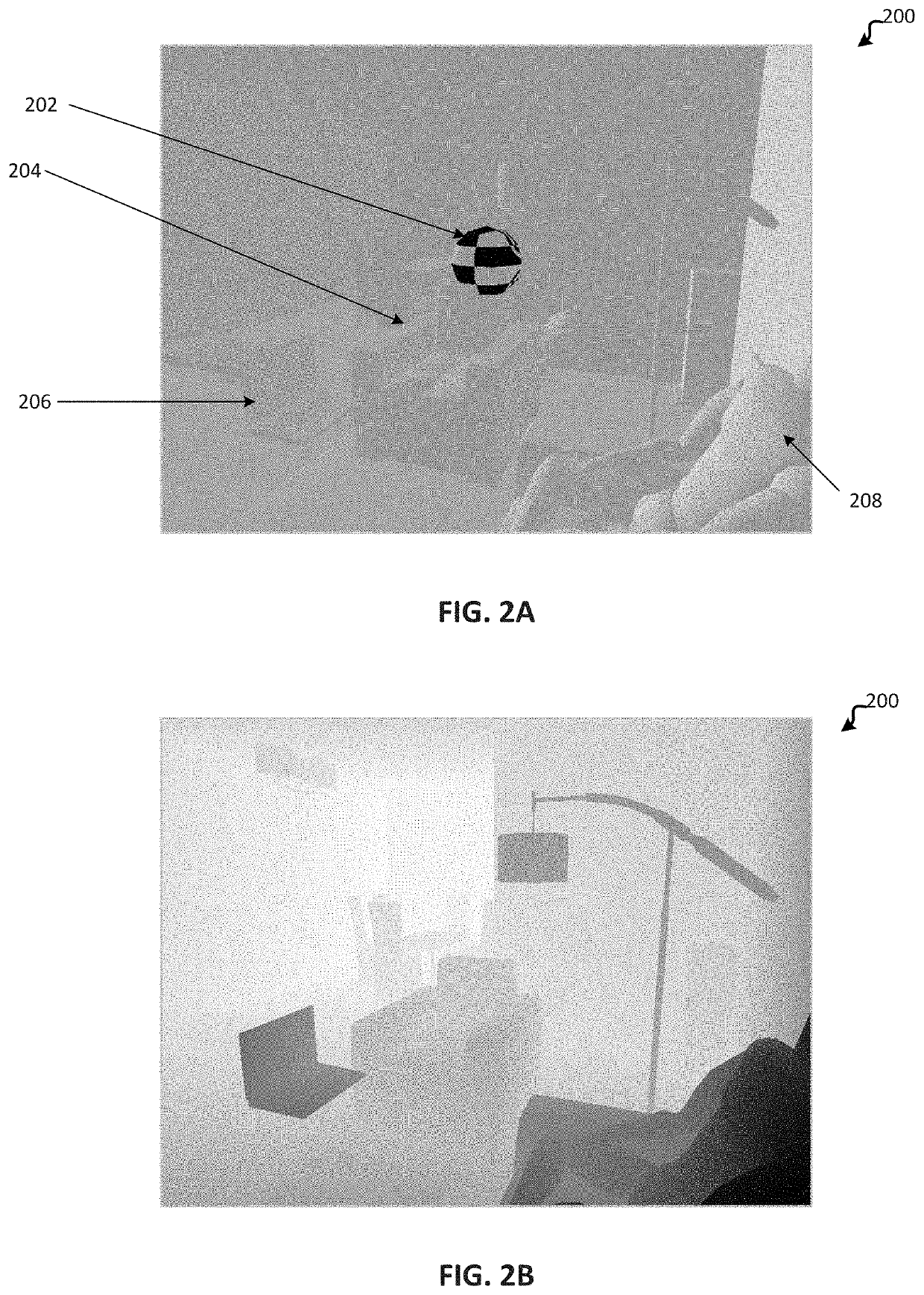
System and method for generation of simulated computer vision training data using a virtual reality engine
PatentWO2024192509A1
Innovation
- A system and method utilizing a Virtual Reality engine to generate synthetic training images using diffusion models, which receive textual descriptions and contour maps to create variant images with annotated bounding boxes and keypoints, allowing for rapid generation of diverse training data for dynamic objects.




Synthetic data generation for training a machine learning model for dynamic object compositing in scenes
PatentActiveUS20200175759A1
Innovation
- Generating synthetic training data to train a machine learning model that can automatically augment images or videos with dynamic objects by simulating their movement within 3D environments using physics simulators and rendering depth and surface normal maps from multiple viewpoints.


Privacy and Data Protection in VR Training Systems
The integration of data augmentation techniques in virtual reality training systems introduces significant privacy and data protection challenges that organizations must carefully address. VR training environments collect vast amounts of sensitive biometric and behavioral data, including eye tracking patterns, head movements, hand gestures, spatial positioning, and physiological responses. When combined with data augmentation processes, this information becomes even more complex to protect as synthetic variations of personal data are generated and stored across multiple systems.
Current regulatory frameworks such as GDPR in Europe and various state privacy laws in the United States impose strict requirements on how personal data collected during VR training sessions must be handled. Organizations must implement comprehensive consent mechanisms that clearly explain how original training data will be augmented, transformed, and utilized. The challenge intensifies when considering that augmented datasets may inadvertently reveal patterns or characteristics that could identify individuals even after anonymization attempts.
Data minimization principles require VR training systems to collect only the necessary information for training purposes, yet data augmentation often benefits from richer datasets. This creates a tension between privacy protection and training effectiveness that organizations must navigate through careful system design and policy implementation. Encryption protocols must be applied not only to original datasets but also to all augmented variations, ensuring end-to-end protection throughout the data lifecycle.
Cross-border data transfer regulations present additional complexity when VR training data is processed across different jurisdictions. Organizations must establish clear data governance frameworks that define retention periods, deletion procedures, and access controls for both original and augmented training datasets. Regular privacy impact assessments become essential to identify potential risks introduced by new augmentation techniques.
The emergence of federated learning approaches in VR training systems offers promising solutions for privacy preservation, allowing data augmentation to occur locally while sharing only aggregated insights. However, implementation requires sophisticated technical infrastructure and ongoing monitoring to ensure compliance with evolving privacy regulations and industry standards.
Current regulatory frameworks such as GDPR in Europe and various state privacy laws in the United States impose strict requirements on how personal data collected during VR training sessions must be handled. Organizations must implement comprehensive consent mechanisms that clearly explain how original training data will be augmented, transformed, and utilized. The challenge intensifies when considering that augmented datasets may inadvertently reveal patterns or characteristics that could identify individuals even after anonymization attempts.
Data minimization principles require VR training systems to collect only the necessary information for training purposes, yet data augmentation often benefits from richer datasets. This creates a tension between privacy protection and training effectiveness that organizations must navigate through careful system design and policy implementation. Encryption protocols must be applied not only to original datasets but also to all augmented variations, ensuring end-to-end protection throughout the data lifecycle.
Cross-border data transfer regulations present additional complexity when VR training data is processed across different jurisdictions. Organizations must establish clear data governance frameworks that define retention periods, deletion procedures, and access controls for both original and augmented training datasets. Regular privacy impact assessments become essential to identify potential risks introduced by new augmentation techniques.
The emergence of federated learning approaches in VR training systems offers promising solutions for privacy preservation, allowing data augmentation to occur locally while sharing only aggregated insights. However, implementation requires sophisticated technical infrastructure and ongoing monitoring to ensure compliance with evolving privacy regulations and industry standards.
Performance Metrics for VR Training Effectiveness
Establishing comprehensive performance metrics for VR training effectiveness requires a multi-dimensional evaluation framework that captures both quantitative and qualitative aspects of learning outcomes. Traditional assessment methods must be adapted to leverage the unique capabilities of virtual environments while maintaining scientific rigor in measurement approaches.
Learning retention metrics serve as fundamental indicators of training effectiveness, typically measured through pre-training and post-training assessments conducted at multiple intervals. Knowledge retention rates are evaluated at 24 hours, one week, one month, and three months post-training to establish decay curves and long-term learning persistence. Skill transfer assessments measure the ability to apply learned concepts in real-world scenarios, often quantified through practical demonstrations or simulations that mirror actual work environments.
Behavioral analytics within VR environments provide rich datasets for performance evaluation. Eye-tracking metrics reveal attention patterns and visual focus areas, indicating comprehension levels and identifying potential confusion points. Hand movement precision and reaction times offer insights into motor skill development and procedural learning effectiveness. Navigation efficiency through virtual spaces demonstrates spatial understanding and task completion competency.
Engagement metrics capture learner motivation and immersion levels, critical factors for training success. Time-on-task measurements, voluntary replay rates, and completion percentages indicate intrinsic motivation levels. Physiological indicators such as heart rate variability and galvanic skin response can reveal stress levels and emotional engagement during training scenarios.
Comparative effectiveness studies benchmark VR training against traditional methods using standardized learning outcome measures. Cost-per-learner metrics evaluate economic efficiency, incorporating development costs, hardware requirements, and scalability factors. Error reduction rates in subsequent real-world performance provide concrete evidence of training impact and safety improvements.
Advanced analytics leverage machine learning algorithms to identify predictive patterns in learner behavior, enabling personalized training adaptations. Competency progression tracking maps individual learning trajectories, identifying optimal pacing and content sequencing for different learner profiles.
Learning retention metrics serve as fundamental indicators of training effectiveness, typically measured through pre-training and post-training assessments conducted at multiple intervals. Knowledge retention rates are evaluated at 24 hours, one week, one month, and three months post-training to establish decay curves and long-term learning persistence. Skill transfer assessments measure the ability to apply learned concepts in real-world scenarios, often quantified through practical demonstrations or simulations that mirror actual work environments.
Behavioral analytics within VR environments provide rich datasets for performance evaluation. Eye-tracking metrics reveal attention patterns and visual focus areas, indicating comprehension levels and identifying potential confusion points. Hand movement precision and reaction times offer insights into motor skill development and procedural learning effectiveness. Navigation efficiency through virtual spaces demonstrates spatial understanding and task completion competency.
Engagement metrics capture learner motivation and immersion levels, critical factors for training success. Time-on-task measurements, voluntary replay rates, and completion percentages indicate intrinsic motivation levels. Physiological indicators such as heart rate variability and galvanic skin response can reveal stress levels and emotional engagement during training scenarios.
Comparative effectiveness studies benchmark VR training against traditional methods using standardized learning outcome measures. Cost-per-learner metrics evaluate economic efficiency, incorporating development costs, hardware requirements, and scalability factors. Error reduction rates in subsequent real-world performance provide concrete evidence of training impact and safety improvements.
Advanced analytics leverage machine learning algorithms to identify predictive patterns in learner behavior, enabling personalized training adaptations. Competency progression tracking maps individual learning trajectories, identifying optimal pacing and content sequencing for different learner profiles.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!