

Compare VLSI and Parallel Computing in High Performance Tasks
MAR 7, 20268 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
VLSI vs Parallel Computing Background and Objectives
The evolution of high-performance computing has been fundamentally shaped by two distinct yet complementary paradigms: Very Large Scale Integration (VLSI) and parallel computing architectures. VLSI technology emerged in the late 1970s as a revolutionary approach to semiconductor design, enabling the integration of millions of transistors onto single chips. This miniaturization breakthrough laid the foundation for modern processors by dramatically increasing computational density while reducing power consumption and manufacturing costs.
Parallel computing, conversely, developed as a computational methodology focused on simultaneous execution of multiple processes across distributed resources. Beginning with early supercomputers in the 1960s and evolving through multi-core processors and distributed systems, parallel computing addresses performance limitations inherent in sequential processing architectures.
The convergence of these technologies has created unprecedented opportunities for high-performance task execution. VLSI advancements enable the fabrication of sophisticated parallel processing units, including multi-core CPUs, Graphics Processing Units (GPUs), and specialized accelerators like Tensor Processing Units (TPUs). Meanwhile, parallel computing algorithms and frameworks maximize the utilization of VLSI-enabled hardware resources.
Contemporary high-performance computing demands have intensified the symbiotic relationship between VLSI and parallel computing. Applications in artificial intelligence, scientific simulation, cryptography, and real-time data processing require both hardware-level optimization through advanced VLSI design and software-level parallelization strategies.
The primary objective of comparing these technologies lies in understanding their complementary roles in addressing computational bottlenecks. VLSI focuses on hardware-level optimization, transistor-level efficiency, and architectural innovations, while parallel computing emphasizes algorithmic decomposition, load balancing, and scalability across multiple processing elements.
This technological intersection presents critical design decisions for high-performance systems. Engineers must balance VLSI constraints such as power dissipation, thermal management, and manufacturing complexity against parallel computing challenges including synchronization overhead, communication latency, and algorithmic scalability limitations.
Parallel computing, conversely, developed as a computational methodology focused on simultaneous execution of multiple processes across distributed resources. Beginning with early supercomputers in the 1960s and evolving through multi-core processors and distributed systems, parallel computing addresses performance limitations inherent in sequential processing architectures.
The convergence of these technologies has created unprecedented opportunities for high-performance task execution. VLSI advancements enable the fabrication of sophisticated parallel processing units, including multi-core CPUs, Graphics Processing Units (GPUs), and specialized accelerators like Tensor Processing Units (TPUs). Meanwhile, parallel computing algorithms and frameworks maximize the utilization of VLSI-enabled hardware resources.
Contemporary high-performance computing demands have intensified the symbiotic relationship between VLSI and parallel computing. Applications in artificial intelligence, scientific simulation, cryptography, and real-time data processing require both hardware-level optimization through advanced VLSI design and software-level parallelization strategies.
The primary objective of comparing these technologies lies in understanding their complementary roles in addressing computational bottlenecks. VLSI focuses on hardware-level optimization, transistor-level efficiency, and architectural innovations, while parallel computing emphasizes algorithmic decomposition, load balancing, and scalability across multiple processing elements.
This technological intersection presents critical design decisions for high-performance systems. Engineers must balance VLSI constraints such as power dissipation, thermal management, and manufacturing complexity against parallel computing challenges including synchronization overhead, communication latency, and algorithmic scalability limitations.
Market Demand for High Performance Computing Solutions
The global high-performance computing market continues to experience robust growth driven by increasing computational demands across multiple industries. Scientific research institutions, financial services, healthcare organizations, and manufacturing companies are seeking more powerful computing solutions to handle complex simulations, data analytics, and modeling tasks that traditional computing architectures cannot efficiently process.
Enterprise demand for HPC solutions has intensified significantly as organizations recognize the competitive advantages of faster data processing and analysis capabilities. Financial institutions require ultra-low latency trading systems and risk modeling platforms, while pharmaceutical companies need accelerated drug discovery and molecular simulation capabilities. The automotive industry drives demand for crash simulation and autonomous vehicle development platforms.
Cloud-based HPC services have emerged as a major market segment, enabling smaller organizations to access high-performance computing resources without substantial capital investments. This democratization of HPC access has expanded the addressable market beyond traditional supercomputing centers to include mid-market enterprises and research institutions with limited budgets.
Artificial intelligence and machine learning workloads represent the fastest-growing segment within HPC demand. Deep learning model training, neural network optimization, and large-scale data processing require specialized computing architectures that can handle parallel processing efficiently. This trend has created substantial opportunities for both VLSI-based accelerators and parallel computing platforms.
The semiconductor industry itself generates significant HPC demand for electronic design automation, chip simulation, and verification processes. As chip designs become increasingly complex with advanced node technologies, the computational requirements for design validation and manufacturing optimization continue to escalate exponentially.
Government and defense sectors maintain steady demand for HPC solutions supporting national security applications, weather forecasting, and scientific research initiatives. These applications often require the highest levels of computational performance and specialized security features, driving premium market segments.
Energy sector applications including seismic data processing for oil exploration, renewable energy optimization, and smart grid management create additional market opportunities. These applications typically require sustained high-performance computing capabilities over extended periods, favoring solutions that balance performance with energy efficiency considerations.
Enterprise demand for HPC solutions has intensified significantly as organizations recognize the competitive advantages of faster data processing and analysis capabilities. Financial institutions require ultra-low latency trading systems and risk modeling platforms, while pharmaceutical companies need accelerated drug discovery and molecular simulation capabilities. The automotive industry drives demand for crash simulation and autonomous vehicle development platforms.
Cloud-based HPC services have emerged as a major market segment, enabling smaller organizations to access high-performance computing resources without substantial capital investments. This democratization of HPC access has expanded the addressable market beyond traditional supercomputing centers to include mid-market enterprises and research institutions with limited budgets.
Artificial intelligence and machine learning workloads represent the fastest-growing segment within HPC demand. Deep learning model training, neural network optimization, and large-scale data processing require specialized computing architectures that can handle parallel processing efficiently. This trend has created substantial opportunities for both VLSI-based accelerators and parallel computing platforms.
The semiconductor industry itself generates significant HPC demand for electronic design automation, chip simulation, and verification processes. As chip designs become increasingly complex with advanced node technologies, the computational requirements for design validation and manufacturing optimization continue to escalate exponentially.
Government and defense sectors maintain steady demand for HPC solutions supporting national security applications, weather forecasting, and scientific research initiatives. These applications often require the highest levels of computational performance and specialized security features, driving premium market segments.
Energy sector applications including seismic data processing for oil exploration, renewable energy optimization, and smart grid management create additional market opportunities. These applications typically require sustained high-performance computing capabilities over extended periods, favoring solutions that balance performance with energy efficiency considerations.
Current State and Challenges in VLSI and Parallel Systems
VLSI technology has reached remarkable maturity in recent decades, with semiconductor manufacturing processes advancing to sub-3nm nodes. Current state-of-the-art VLSI systems demonstrate exceptional performance in specialized computational tasks through dedicated hardware architectures. Leading foundries like TSMC and Samsung have achieved transistor densities exceeding 100 million transistors per square millimeter, enabling complex system-on-chip designs that integrate multiple processing units, memory hierarchies, and specialized accelerators on single dies.
Parallel computing systems have simultaneously evolved to leverage multi-core architectures, distributed computing frameworks, and heterogeneous processing units. Modern high-performance computing clusters incorporate thousands of processing nodes, while GPU-accelerated systems deliver petaflop-scale computational capabilities. The integration of CPU-GPU hybrid architectures has become standard practice, with platforms like NVIDIA's CUDA and AMD's ROCm enabling efficient parallel algorithm implementation across diverse application domains.
However, both technologies face significant scaling challenges that constrain their effectiveness in high-performance tasks. VLSI systems encounter fundamental physical limitations including quantum tunneling effects, thermal management complexities, and interconnect delays that increasingly dominate performance characteristics. Power density has become a critical bottleneck, with static power consumption growing exponentially as transistor dimensions shrink, leading to the breakdown of traditional Dennard scaling principles.
Parallel computing systems struggle with algorithmic limitations, particularly Amdahl's Law constraints that limit speedup potential for sequential code segments. Load balancing across heterogeneous processing units remains problematic, while communication overhead between distributed nodes creates scalability bottlenecks. Memory bandwidth limitations and cache coherency protocols introduce additional performance penalties that become more pronounced as system complexity increases.
The convergence of these technologies presents both opportunities and challenges. Emerging paradigms like neuromorphic computing and quantum-classical hybrid systems attempt to address fundamental limitations through novel architectural approaches. However, programming complexity, verification challenges, and manufacturing cost considerations continue to impede widespread adoption of advanced solutions in practical high-performance computing environments.
Parallel computing systems have simultaneously evolved to leverage multi-core architectures, distributed computing frameworks, and heterogeneous processing units. Modern high-performance computing clusters incorporate thousands of processing nodes, while GPU-accelerated systems deliver petaflop-scale computational capabilities. The integration of CPU-GPU hybrid architectures has become standard practice, with platforms like NVIDIA's CUDA and AMD's ROCm enabling efficient parallel algorithm implementation across diverse application domains.
However, both technologies face significant scaling challenges that constrain their effectiveness in high-performance tasks. VLSI systems encounter fundamental physical limitations including quantum tunneling effects, thermal management complexities, and interconnect delays that increasingly dominate performance characteristics. Power density has become a critical bottleneck, with static power consumption growing exponentially as transistor dimensions shrink, leading to the breakdown of traditional Dennard scaling principles.
Parallel computing systems struggle with algorithmic limitations, particularly Amdahl's Law constraints that limit speedup potential for sequential code segments. Load balancing across heterogeneous processing units remains problematic, while communication overhead between distributed nodes creates scalability bottlenecks. Memory bandwidth limitations and cache coherency protocols introduce additional performance penalties that become more pronounced as system complexity increases.
The convergence of these technologies presents both opportunities and challenges. Emerging paradigms like neuromorphic computing and quantum-classical hybrid systems attempt to address fundamental limitations through novel architectural approaches. However, programming complexity, verification challenges, and manufacturing cost considerations continue to impede widespread adoption of advanced solutions in practical high-performance computing environments.
Current VLSI and Parallel Computing Architectures
01 Parallel processing architectures for VLSI systems
Advanced parallel processing architectures are designed to enhance computational performance in VLSI systems. These architectures utilize multiple processing units working simultaneously to execute tasks, thereby improving throughput and reducing latency. The designs incorporate specialized interconnection networks and data flow mechanisms to optimize communication between processing elements. Such architectures are particularly effective for applications requiring high-speed data processing and complex computational operations.- Parallel processing architectures for VLSI systems: Advanced parallel processing architectures are designed to enhance computational performance in VLSI systems. These architectures utilize multiple processing units working simultaneously to execute tasks, thereby improving throughput and reducing latency. The designs incorporate specialized interconnection networks and data flow mechanisms to optimize communication between processing elements. Such architectures are particularly effective for applications requiring high-speed data processing and complex computational operations.
- Memory optimization techniques in parallel computing: Memory management and optimization strategies are crucial for improving performance in parallel computing systems. These techniques include hierarchical memory structures, cache optimization, and efficient data distribution methods across multiple processing units. Advanced memory access patterns and bandwidth optimization methods help reduce bottlenecks and improve overall system efficiency. The approaches enable better utilization of available memory resources while maintaining high-speed data access.
- Hardware acceleration and specialized processing units: Specialized hardware accelerators and processing units are integrated into VLSI designs to enhance parallel computing performance. These components include dedicated circuits for specific computational tasks, such as matrix operations, signal processing, or cryptographic functions. The hardware acceleration approach offloads intensive computations from general-purpose processors, resulting in significant performance improvements and reduced power consumption. Custom logic designs are optimized for specific application domains.
- Interconnection networks and communication protocols: Efficient interconnection networks and communication protocols are essential for coordinating multiple processing elements in parallel computing systems. These networks facilitate high-bandwidth, low-latency data transfer between processors and memory units. Advanced routing algorithms and network topologies are employed to minimize communication overhead and prevent congestion. The protocols ensure reliable data transmission while maintaining synchronization across distributed computing resources.
- Performance optimization through algorithmic and scheduling techniques: Algorithmic optimization and intelligent task scheduling methods are employed to maximize parallel computing performance in VLSI systems. These techniques include load balancing strategies, dynamic resource allocation, and adaptive scheduling algorithms that respond to varying workload conditions. The methods aim to minimize idle time, reduce synchronization overhead, and optimize resource utilization across multiple processing units. Advanced compiler techniques and runtime systems support efficient parallel execution.
02 Hardware acceleration techniques for computational performance
Hardware acceleration methods are employed to boost the performance of computing systems by offloading specific tasks to dedicated hardware components. These techniques involve the use of specialized circuits and processing units that are optimized for particular operations, resulting in faster execution times compared to general-purpose processors. The implementation includes custom logic designs and optimized data paths that enable efficient parallel execution of computational tasks.Expand Specific Solutions03 Memory optimization and data management in parallel systems
Efficient memory management strategies are crucial for maximizing performance in parallel computing environments. These approaches focus on optimizing data access patterns, reducing memory latency, and improving bandwidth utilization. Techniques include hierarchical memory structures, cache optimization, and intelligent data distribution schemes that minimize communication overhead between processing elements. The methods ensure that data is available when needed while preventing bottlenecks in the memory subsystem.Expand Specific Solutions04 Scheduling and resource allocation algorithms
Advanced scheduling algorithms are developed to efficiently allocate computational resources in parallel processing systems. These algorithms determine the optimal assignment of tasks to processing units while considering factors such as load balancing, task dependencies, and resource constraints. The methods aim to maximize system utilization and minimize execution time by dynamically adjusting resource allocation based on workload characteristics and system state.Expand Specific Solutions05 Performance monitoring and optimization frameworks
Comprehensive frameworks for monitoring and optimizing performance in VLSI and parallel computing systems are essential for maintaining high efficiency. These frameworks provide real-time analysis of system behavior, identify performance bottlenecks, and implement adaptive optimization strategies. The solutions incorporate performance metrics collection, analysis tools, and automated tuning mechanisms that adjust system parameters to achieve optimal performance under varying workload conditions.Expand Specific Solutions
Major Players in VLSI and Parallel Computing Industry
The competitive landscape for VLSI versus parallel computing in high-performance tasks reflects a mature, rapidly evolving industry with significant market expansion driven by AI and data-intensive applications. The market demonstrates strong growth potential, particularly in GPU-accelerated computing and specialized processors. Technology maturity varies significantly across players: established leaders like NVIDIA, AMD, and IBM have achieved high sophistication in parallel processing architectures, while companies such as Xilinx and ARM excel in VLSI-based programmable solutions. Emerging players including Moore Threads, Biren Technology, and OneFlow represent growing regional competition, particularly from China. The industry shows clear segmentation between traditional VLSI approaches favored by companies like Qualcomm and NXP for embedded applications, versus parallel computing dominance by NVIDIA and AMD in high-performance scenarios, indicating complementary rather than purely competitive technological approaches.
International Business Machines Corp.
Technical Solution: IBM combines VLSI design expertise with parallel computing through their Power architecture and specialized processors. Their approach focuses on creating highly optimized VLSI circuits that support both symmetric multiprocessing and massively parallel processing architectures. IBM's designs emphasize reliability and scalability, incorporating advanced error correction, redundancy mechanisms, and sophisticated interconnect technologies within their VLSI implementations. The company's parallel computing solutions leverage custom silicon designs optimized for enterprise workloads, scientific computing, and AI applications. Their VLSI approach includes innovative packaging technologies, advanced cooling solutions, and power management techniques that enable sustained high-performance parallel processing. IBM's integration of VLSI and parallel computing demonstrates how traditional semiconductor design can be enhanced to support complex parallel algorithms and distributed computing paradigms.
Strengths: Enterprise-grade reliability, excellent scalability, strong research foundation in both domains. Weaknesses: Higher costs compared to commodity solutions, longer development cycles, limited consumer market presence.
NVIDIA Corp.
Technical Solution: NVIDIA leverages parallel computing architectures through CUDA cores and Tensor cores in their GPU designs, enabling massive parallelization for high-performance computing tasks. Their approach combines VLSI optimization with parallel processing capabilities, utilizing advanced semiconductor manufacturing processes to pack thousands of cores onto single chips. The company's architecture supports both traditional parallel computing workloads and specialized AI/ML tasks through dedicated tensor processing units. Their VLSI designs incorporate sophisticated memory hierarchies, high-bandwidth memory interfaces, and optimized data paths to minimize bottlenecks in parallel execution. NVIDIA's solutions demonstrate how modern VLSI techniques can be optimized specifically for parallel computing architectures, achieving superior performance in scientific computing, deep learning, and graphics rendering applications.
Strengths: Industry-leading parallel processing performance, mature CUDA ecosystem, excellent memory bandwidth optimization. Weaknesses: High power consumption, expensive manufacturing costs, limited flexibility for non-parallel workloads.
Core Technologies in High Performance Task Processing
Circuit, parallel computing device, computer system and computer readable storage medium
PatentActiveUS9984026B2
Innovation
- A miniaturized HXNet VLSI circuit with additional buffer memories allows for data transfer between desired PEs by implementing m2 PEs and m3 buffer memories, enabling the combination of multiple VLSI circuits to form a parallel computing system with reduced bus usage and scalability, facilitating data transfer between PEs across multiple circuits.




Method for use in a parallel computing system based on message passing for distributing a workload
PatentWO2025131314A1
Innovation
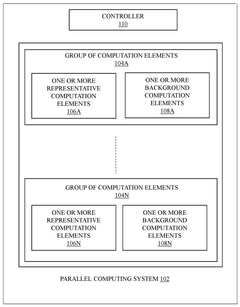
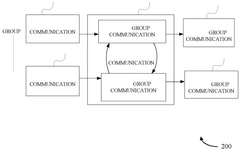
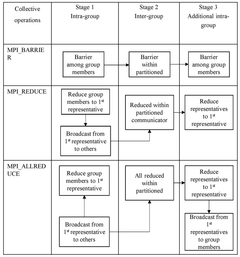
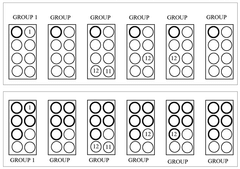
- The method involves partitioning communication tasks among groups of computation elements, where each group has representative computation elements that communicate only with a subset of other representatives, optimizing collective operations and minimizing latency.
Power Efficiency Standards for HPC Systems
Power efficiency has emerged as a critical performance metric in high-performance computing systems, fundamentally reshaping how VLSI and parallel computing architectures are evaluated and designed. Traditional performance metrics focused primarily on computational throughput and latency, but the exponential growth in energy consumption has necessitated comprehensive power efficiency standards that directly impact the comparison between VLSI-based accelerators and parallel computing systems.
The Green500 list represents the most influential power efficiency standard in HPC, measuring performance per watt through the LINPACK benchmark. This standard has driven significant architectural innovations in both VLSI and parallel computing domains. VLSI-based solutions, particularly GPU accelerators and specialized processors, consistently demonstrate superior power efficiency ratios, often achieving 10-20 GFLOPS per watt compared to traditional CPU-based parallel systems that typically deliver 2-5 GFLOPS per watt.
Energy Star specifications for enterprise servers have established baseline power management requirements that affect both VLSI and parallel computing implementations. These standards mandate dynamic voltage and frequency scaling capabilities, idle state power management, and thermal design power limitations. VLSI architectures inherently excel in meeting these requirements through dedicated power management units and fine-grained clock gating mechanisms.
The IEEE 1621 standard for power efficiency measurement provides standardized methodologies for comparing different computing architectures under various workload conditions. This standard emphasizes the importance of measuring power consumption across different operational states, including peak performance, typical workloads, and idle conditions. Parallel computing systems often struggle with idle power consumption due to distributed memory hierarchies and interconnect overhead.
Power Usage Effectiveness (PUE) standards, while primarily focused on data center infrastructure, significantly influence the design choices between VLSI and parallel computing solutions. VLSI-based accelerators typically generate higher heat density but offer better computational density, potentially improving overall PUE metrics when properly cooled. Parallel computing systems distribute heat more evenly but may require more extensive cooling infrastructure.
Emerging standards like the SPECpower benchmark suite provide workload-specific power efficiency measurements that reveal the contextual advantages of different architectures. These standards demonstrate that VLSI solutions excel in compute-intensive tasks with regular data patterns, while parallel computing systems maintain efficiency advantages in memory-intensive and irregular workloads where distributed processing reduces data movement overhead.
The Green500 list represents the most influential power efficiency standard in HPC, measuring performance per watt through the LINPACK benchmark. This standard has driven significant architectural innovations in both VLSI and parallel computing domains. VLSI-based solutions, particularly GPU accelerators and specialized processors, consistently demonstrate superior power efficiency ratios, often achieving 10-20 GFLOPS per watt compared to traditional CPU-based parallel systems that typically deliver 2-5 GFLOPS per watt.
Energy Star specifications for enterprise servers have established baseline power management requirements that affect both VLSI and parallel computing implementations. These standards mandate dynamic voltage and frequency scaling capabilities, idle state power management, and thermal design power limitations. VLSI architectures inherently excel in meeting these requirements through dedicated power management units and fine-grained clock gating mechanisms.
The IEEE 1621 standard for power efficiency measurement provides standardized methodologies for comparing different computing architectures under various workload conditions. This standard emphasizes the importance of measuring power consumption across different operational states, including peak performance, typical workloads, and idle conditions. Parallel computing systems often struggle with idle power consumption due to distributed memory hierarchies and interconnect overhead.
Power Usage Effectiveness (PUE) standards, while primarily focused on data center infrastructure, significantly influence the design choices between VLSI and parallel computing solutions. VLSI-based accelerators typically generate higher heat density but offer better computational density, potentially improving overall PUE metrics when properly cooled. Parallel computing systems distribute heat more evenly but may require more extensive cooling infrastructure.
Emerging standards like the SPECpower benchmark suite provide workload-specific power efficiency measurements that reveal the contextual advantages of different architectures. These standards demonstrate that VLSI solutions excel in compute-intensive tasks with regular data patterns, while parallel computing systems maintain efficiency advantages in memory-intensive and irregular workloads where distributed processing reduces data movement overhead.
Scalability Considerations in HPC Architecture Design
Scalability represents the fundamental challenge in designing high-performance computing architectures that effectively leverage both VLSI and parallel computing paradigms. The architectural decisions made at the design phase directly impact system performance, cost-effectiveness, and long-term viability in handling increasingly complex computational workloads.
VLSI-based HPC architectures face unique scalability constraints primarily related to physical limitations and manufacturing complexities. As transistor density increases following Moore's law, power consumption and heat dissipation become critical bottlenecks. Advanced VLSI designs must incorporate sophisticated power management techniques, including dynamic voltage scaling and clock gating mechanisms. The interconnect delays within VLSI chips also present significant challenges, as signal propagation time increases with chip size, potentially limiting the maximum achievable clock frequencies and overall system performance.
Parallel computing architectures address scalability through distributed processing approaches, enabling horizontal scaling by adding more processing units. However, this approach introduces communication overhead and synchronization challenges that can severely impact performance. The scalability of parallel systems depends heavily on the interconnection network topology, memory hierarchy design, and load balancing mechanisms. Network congestion and bandwidth limitations become increasingly problematic as the number of processing nodes grows exponentially.
Hybrid architectures combining VLSI and parallel computing elements require careful consideration of heterogeneous resource allocation and workload distribution strategies. The scalability of such systems depends on the ability to efficiently partition computational tasks between specialized VLSI accelerators and general-purpose parallel processors. Memory bandwidth and latency mismatches between different architectural components can create performance bottlenecks that limit overall system scalability.
Future HPC architecture designs must address scalability through innovative approaches including near-data computing, advanced packaging technologies like 3D integration, and novel interconnect solutions such as photonic networks. These emerging technologies promise to overcome traditional scalability limitations while maintaining energy efficiency and cost-effectiveness in large-scale deployments.
VLSI-based HPC architectures face unique scalability constraints primarily related to physical limitations and manufacturing complexities. As transistor density increases following Moore's law, power consumption and heat dissipation become critical bottlenecks. Advanced VLSI designs must incorporate sophisticated power management techniques, including dynamic voltage scaling and clock gating mechanisms. The interconnect delays within VLSI chips also present significant challenges, as signal propagation time increases with chip size, potentially limiting the maximum achievable clock frequencies and overall system performance.
Parallel computing architectures address scalability through distributed processing approaches, enabling horizontal scaling by adding more processing units. However, this approach introduces communication overhead and synchronization challenges that can severely impact performance. The scalability of parallel systems depends heavily on the interconnection network topology, memory hierarchy design, and load balancing mechanisms. Network congestion and bandwidth limitations become increasingly problematic as the number of processing nodes grows exponentially.
Hybrid architectures combining VLSI and parallel computing elements require careful consideration of heterogeneous resource allocation and workload distribution strategies. The scalability of such systems depends on the ability to efficiently partition computational tasks between specialized VLSI accelerators and general-purpose parallel processors. Memory bandwidth and latency mismatches between different architectural components can create performance bottlenecks that limit overall system scalability.
Future HPC architecture designs must address scalability through innovative approaches including near-data computing, advanced packaging technologies like 3D integration, and novel interconnect solutions such as photonic networks. These emerging technologies promise to overcome traditional scalability limitations while maintaining energy efficiency and cost-effectiveness in large-scale deployments.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!