

HBM Memory vs Compute-In-Memory: Latency vs Bandwidth
MAY 18, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
HBM and CIM Technology Background and Objectives
High Bandwidth Memory (HBM) represents a revolutionary approach to memory architecture that emerged from the critical need to address the growing bandwidth bottleneck between processors and traditional memory systems. Originally developed through collaboration between SK Hynix and AMD in the early 2010s, HBM utilizes through-silicon via (TSV) technology and 3D stacking to achieve unprecedented memory bandwidth while maintaining a compact footprint. The technology has evolved through multiple generations, with HBM3 currently delivering bandwidth exceeding 600 GB/s per stack.
Compute-In-Memory (CIM) technology fundamentally reimagines the traditional von Neumann architecture by integrating computational capabilities directly within memory arrays. This paradigm shift eliminates the need for constant data movement between separate memory and processing units, addressing one of the most significant energy and latency bottlenecks in modern computing systems. CIM implementations span various memory technologies including SRAM, ReRAM, MRAM, and emerging non-volatile memory solutions.
The evolution of both technologies stems from the increasing demands of data-intensive applications such as artificial intelligence, machine learning, and high-performance computing workloads. Traditional memory hierarchies struggle to provide sufficient bandwidth while maintaining acceptable power consumption levels, particularly in edge computing and mobile applications where energy efficiency is paramount.
The primary objective of comparing HBM and CIM technologies centers on understanding their respective advantages in addressing the latency-bandwidth trade-off that defines modern computing performance. HBM excels in scenarios requiring massive data throughput with relatively predictable access patterns, making it ideal for graphics processing, scientific computing, and large-scale neural network training applications.
Conversely, CIM technology targets applications where frequent data access and processing occur simultaneously, such as real-time inference, pattern recognition, and edge AI applications. The objective is to determine optimal deployment scenarios for each technology based on specific performance requirements, power constraints, and cost considerations.
Future development objectives include hybrid architectures that potentially combine HBM's high-bandwidth capabilities with CIM's low-latency processing advantages, creating memory systems that can dynamically adapt to varying computational workloads while optimizing both performance and energy efficiency across diverse application domains.
Compute-In-Memory (CIM) technology fundamentally reimagines the traditional von Neumann architecture by integrating computational capabilities directly within memory arrays. This paradigm shift eliminates the need for constant data movement between separate memory and processing units, addressing one of the most significant energy and latency bottlenecks in modern computing systems. CIM implementations span various memory technologies including SRAM, ReRAM, MRAM, and emerging non-volatile memory solutions.
The evolution of both technologies stems from the increasing demands of data-intensive applications such as artificial intelligence, machine learning, and high-performance computing workloads. Traditional memory hierarchies struggle to provide sufficient bandwidth while maintaining acceptable power consumption levels, particularly in edge computing and mobile applications where energy efficiency is paramount.
The primary objective of comparing HBM and CIM technologies centers on understanding their respective advantages in addressing the latency-bandwidth trade-off that defines modern computing performance. HBM excels in scenarios requiring massive data throughput with relatively predictable access patterns, making it ideal for graphics processing, scientific computing, and large-scale neural network training applications.
Conversely, CIM technology targets applications where frequent data access and processing occur simultaneously, such as real-time inference, pattern recognition, and edge AI applications. The objective is to determine optimal deployment scenarios for each technology based on specific performance requirements, power constraints, and cost considerations.
Future development objectives include hybrid architectures that potentially combine HBM's high-bandwidth capabilities with CIM's low-latency processing advantages, creating memory systems that can dynamically adapt to varying computational workloads while optimizing both performance and energy efficiency across diverse application domains.
Market Demand for High-Performance Memory Solutions
The global semiconductor industry is experiencing unprecedented demand for high-performance memory solutions, driven by the exponential growth of artificial intelligence, machine learning, and high-performance computing applications. Data centers worldwide are grappling with the memory wall challenge, where traditional memory architectures struggle to keep pace with the computational demands of modern processors. This bottleneck has created a substantial market opportunity for advanced memory technologies that can deliver superior bandwidth and reduced latency.
Enterprise customers across cloud computing, autonomous vehicles, and scientific computing sectors are actively seeking memory solutions that can handle massive parallel workloads while maintaining energy efficiency. The proliferation of large language models and deep neural networks has intensified the need for memory systems capable of supporting trillion-parameter models with minimal data movement overhead. Traditional DDR memory architectures are proving inadequate for these demanding applications, creating a clear market gap.
High Bandwidth Memory has emerged as a critical solution for graphics processing units and accelerators, with major cloud service providers integrating HBM-enabled systems to support their AI infrastructure. The technology addresses the bandwidth limitations that constrain performance in memory-intensive applications, particularly in training and inference workloads where data throughput directly impacts computational efficiency.
Simultaneously, the market is witnessing growing interest in compute-in-memory architectures that promise to eliminate the von Neumann bottleneck by performing computations directly within memory arrays. This approach appeals to edge computing applications where power efficiency and reduced latency are paramount concerns. Industries developing autonomous systems, real-time analytics, and IoT devices are driving demand for memory solutions that can process data locally without frequent data transfers.
The convergence of these market forces has created a competitive landscape where memory vendors must balance bandwidth capabilities against latency optimization. Organizations are increasingly evaluating memory solutions based on total cost of ownership, including power consumption, thermal management, and integration complexity, rather than focusing solely on peak performance metrics.
Enterprise customers across cloud computing, autonomous vehicles, and scientific computing sectors are actively seeking memory solutions that can handle massive parallel workloads while maintaining energy efficiency. The proliferation of large language models and deep neural networks has intensified the need for memory systems capable of supporting trillion-parameter models with minimal data movement overhead. Traditional DDR memory architectures are proving inadequate for these demanding applications, creating a clear market gap.
High Bandwidth Memory has emerged as a critical solution for graphics processing units and accelerators, with major cloud service providers integrating HBM-enabled systems to support their AI infrastructure. The technology addresses the bandwidth limitations that constrain performance in memory-intensive applications, particularly in training and inference workloads where data throughput directly impacts computational efficiency.
Simultaneously, the market is witnessing growing interest in compute-in-memory architectures that promise to eliminate the von Neumann bottleneck by performing computations directly within memory arrays. This approach appeals to edge computing applications where power efficiency and reduced latency are paramount concerns. Industries developing autonomous systems, real-time analytics, and IoT devices are driving demand for memory solutions that can process data locally without frequent data transfers.
The convergence of these market forces has created a competitive landscape where memory vendors must balance bandwidth capabilities against latency optimization. Organizations are increasingly evaluating memory solutions based on total cost of ownership, including power consumption, thermal management, and integration complexity, rather than focusing solely on peak performance metrics.
Current HBM vs CIM Performance Challenges
HBM technology faces significant latency challenges despite its superior bandwidth capabilities. Current HBM implementations exhibit access latencies ranging from 200-300 nanoseconds, substantially higher than traditional DRAM's 50-100 nanoseconds. This latency penalty stems from the complex 3D stacking architecture and the need for through-silicon vias (TSVs) that introduce additional signal propagation delays. The multi-die configuration requires sophisticated timing coordination across vertical layers, creating bottlenecks in random access patterns.
Memory wall limitations persist as a fundamental challenge for HBM deployments. While HBM delivers exceptional sequential bandwidth exceeding 1TB/s in latest generations, the processor-memory interface still constrains overall system performance. The physical separation between compute units and memory creates inherent data movement overhead, consuming significant power and introducing unavoidable latency penalties that become more pronounced as computational demands increase.
Compute-in-Memory architectures confront distinct performance obstacles centered on computational precision and flexibility constraints. Current CIM implementations struggle with limited bit precision, typically supporting only 4-8 bit operations effectively. This restriction severely impacts applications requiring high-precision arithmetic, forcing developers to implement complex quantization schemes or hybrid processing approaches that compromise computational accuracy.
Scalability represents another critical challenge for CIM technologies. Existing analog CIM solutions suffer from process variation sensitivity and limited parallelism scaling. Digital CIM approaches, while more robust, face area efficiency challenges when implementing complex computational kernels. The integration of processing elements within memory arrays creates thermal management issues and complicates yield optimization across large-scale deployments.
Power efficiency trade-offs create additional complexity in both technologies. HBM's high-speed interfaces consume substantial static power even during idle periods, while CIM's analog processing circuits require careful power management to maintain computational accuracy. The energy overhead of data conversion between analog and digital domains in CIM systems often negates theoretical efficiency gains, particularly for workloads with frequent precision switching requirements.
Programmability limitations further constrain CIM adoption in diverse application scenarios. Unlike traditional processors with flexible instruction sets, current CIM architectures support only specific computational patterns, primarily matrix operations and simple neural network primitives. This specialization restricts their applicability to broader computational workloads that require dynamic algorithm adaptation or complex control flow operations.
Memory wall limitations persist as a fundamental challenge for HBM deployments. While HBM delivers exceptional sequential bandwidth exceeding 1TB/s in latest generations, the processor-memory interface still constrains overall system performance. The physical separation between compute units and memory creates inherent data movement overhead, consuming significant power and introducing unavoidable latency penalties that become more pronounced as computational demands increase.
Compute-in-Memory architectures confront distinct performance obstacles centered on computational precision and flexibility constraints. Current CIM implementations struggle with limited bit precision, typically supporting only 4-8 bit operations effectively. This restriction severely impacts applications requiring high-precision arithmetic, forcing developers to implement complex quantization schemes or hybrid processing approaches that compromise computational accuracy.
Scalability represents another critical challenge for CIM technologies. Existing analog CIM solutions suffer from process variation sensitivity and limited parallelism scaling. Digital CIM approaches, while more robust, face area efficiency challenges when implementing complex computational kernels. The integration of processing elements within memory arrays creates thermal management issues and complicates yield optimization across large-scale deployments.
Power efficiency trade-offs create additional complexity in both technologies. HBM's high-speed interfaces consume substantial static power even during idle periods, while CIM's analog processing circuits require careful power management to maintain computational accuracy. The energy overhead of data conversion between analog and digital domains in CIM systems often negates theoretical efficiency gains, particularly for workloads with frequent precision switching requirements.
Programmability limitations further constrain CIM adoption in diverse application scenarios. Unlike traditional processors with flexible instruction sets, current CIM architectures support only specific computational patterns, primarily matrix operations and simple neural network primitives. This specialization restricts their applicability to broader computational workloads that require dynamic algorithm adaptation or complex control flow operations.
Existing Latency-Bandwidth Optimization Solutions
01 HBM memory architecture optimization for reduced latency
Advanced memory architectures that focus on optimizing the physical design and data pathways of high bandwidth memory systems to minimize access latency. These approaches include improved memory controller designs, enhanced data routing mechanisms, and optimized memory cell arrangements that reduce the time required for data retrieval and storage operations.- HBM memory architecture optimization for reduced latency: Advanced memory architectures that focus on optimizing the physical design and data pathways of high bandwidth memory systems to minimize access latency. These approaches include improved memory controller designs, enhanced data routing mechanisms, and optimized memory cell arrangements that reduce the time required for data retrieval and storage operations.
- Compute-in-memory processing units with integrated bandwidth management: Processing architectures that integrate computational capabilities directly within memory units to reduce data movement overhead and improve overall system bandwidth utilization. These systems feature specialized processing elements embedded in memory arrays that can perform operations on data without transferring it to separate processing units.
- Memory interface protocols for enhanced data throughput: Communication protocols and interface designs specifically developed to maximize data transfer rates between memory components and processing units. These protocols implement advanced signaling techniques, error correction mechanisms, and data compression methods to achieve higher effective bandwidth while maintaining data integrity.
- Dynamic memory scheduling and access optimization: Intelligent memory management systems that dynamically optimize memory access patterns and scheduling to minimize latency and maximize bandwidth utilization. These systems employ predictive algorithms, priority-based scheduling, and adaptive caching strategies to improve overall memory system performance under varying workload conditions.
- Power-efficient memory operations with performance optimization: Energy-efficient memory system designs that balance power consumption with performance requirements while maintaining high bandwidth and low latency characteristics. These approaches include voltage scaling techniques, power gating mechanisms, and adaptive frequency control methods that optimize energy usage without compromising system performance.
02 Compute-in-memory processing units with integrated bandwidth management
Processing architectures that integrate computational capabilities directly within memory units to reduce data movement overhead and improve overall system bandwidth utilization. These systems feature specialized processing elements embedded in memory arrays that can perform operations on data without transferring it to separate processing units.Expand Specific Solutions03 Latency reduction through advanced memory access scheduling
Sophisticated scheduling algorithms and hardware implementations that optimize the timing and sequencing of memory access operations to minimize overall system latency. These techniques include predictive caching, intelligent prefetching mechanisms, and dynamic priority-based access control systems that anticipate and prepare for future memory requests.Expand Specific Solutions04 Bandwidth optimization through parallel memory channel management
Multi-channel memory systems that maximize data throughput by implementing parallel data pathways and intelligent channel allocation strategies. These systems coordinate multiple memory channels simultaneously to achieve higher aggregate bandwidth while maintaining low latency through optimized channel arbitration and data distribution mechanisms.Expand Specific Solutions05 Hybrid memory-compute architectures for enhanced performance
Integrated systems that combine traditional memory functions with computational capabilities to create hybrid architectures optimized for both high bandwidth and low latency operations. These designs feature specialized interfaces and control mechanisms that seamlessly coordinate between memory storage and in-memory computation functions.Expand Specific Solutions
Leading HBM and CIM Technology Players
The HBM Memory vs Compute-In-Memory competitive landscape represents a rapidly evolving semiconductor sector at a critical inflection point. The industry is experiencing significant growth driven by AI and high-performance computing demands, with market size expanding substantially as data-intensive applications proliferate. Technology maturity varies significantly between established HBM solutions and emerging compute-in-memory architectures. Leading players like Samsung Electronics, Micron Technology, and Intel dominate traditional HBM development with proven manufacturing capabilities, while companies such as Graphcore, Expedera, and Shanghai Biren Technology are pioneering compute-in-memory innovations. The competitive dynamics show established memory giants leveraging manufacturing scale against innovative startups developing novel architectures, creating a bifurcated market where bandwidth-optimized HBM solutions compete with latency-focused compute-in-memory approaches for next-generation computing applications.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung has developed advanced HBM3E memory solutions offering up to 1.2TB/s bandwidth per stack with significantly reduced latency compared to traditional DRAM. Their HBM technology features through-silicon via (TSV) architecture enabling vertical stacking of memory dies, achieving higher bandwidth density while maintaining lower power consumption. Samsung's HBM solutions are optimized for AI accelerators and high-performance computing applications where memory bandwidth is critical. The company has also invested in processing-in-memory (PIM) technologies, integrating computational capabilities directly into memory arrays to reduce data movement overhead and improve overall system efficiency for specific workloads.
Strengths: Market-leading HBM production capacity, proven high-bandwidth memory solutions, strong manufacturing capabilities. Weaknesses: Higher cost per bit compared to conventional memory, limited compute-in-memory product portfolio.
Intel Corp.
Technical Solution: Intel has developed comprehensive solutions addressing both HBM integration and compute-in-memory architectures. Their Ponte Vecchio GPU utilizes HBM2E memory providing over 3.2TB/s of aggregate bandwidth with optimized memory controllers to minimize latency. Intel's approach focuses on heterogeneous computing architectures that combine high-bandwidth memory with near-data computing capabilities. They have also researched neuromorphic computing solutions like Loihi chips that implement compute-in-memory principles for ultra-low latency AI inference applications. Intel's memory-centric computing initiatives aim to bridge the gap between memory bandwidth and computational throughput through innovative packaging and interconnect technologies.
Strengths: Strong system-level integration expertise, comprehensive product portfolio spanning CPUs to accelerators, advanced packaging technologies. Weaknesses: Facing intense competition in GPU market, relatively newer to HBM compared to memory specialists.
Core Patents in HBM and CIM Technologies
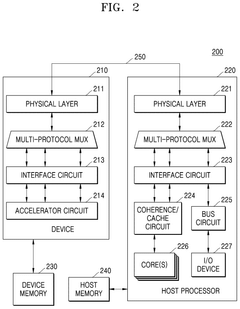
ISA extension for high-bandwidth memory
PatentActiveUS11940922B2
Innovation
- A system and method for processing in-memory commands in HBM systems, where a HBM memory controller sends Function-in-HBM (FIM) instructions to a logic component, which coordinates execution using an Arithmetic Logic Unit (ALU) and SRAM, enabling computational, data movement, and scratchpad operations within the HBM.


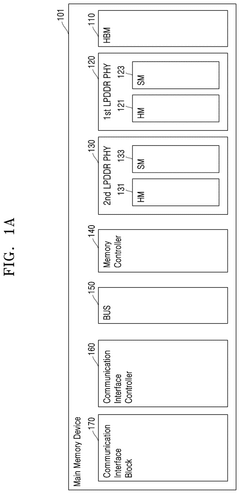
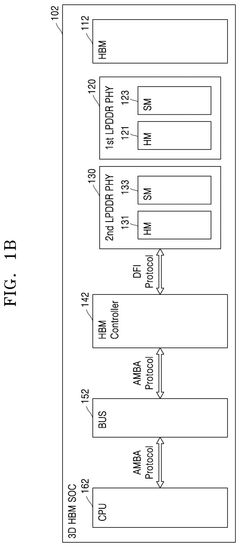
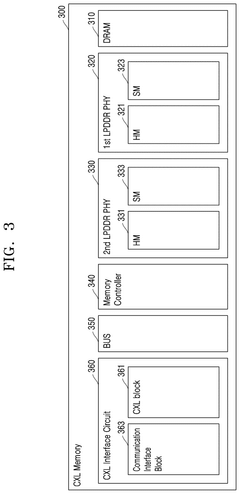
Memory device, CXL memory device, system in package, and system on chip including high bandwidth memory
PatentPendingUS20250103488A1
Innovation
- Incorporating an HBM interface intellectual property (IP) core that directly converts the interface of HBM core devices into the DFI protocol, bypassing the need for JEDEC interface conversion, thereby reducing the number of protocol and interface conversions required.
AI Workload Impact on Memory Requirements
The proliferation of artificial intelligence applications has fundamentally transformed memory system requirements, creating unprecedented demands that challenge traditional memory architectures. Modern AI workloads exhibit distinct characteristics that significantly impact both memory capacity and performance specifications, driving the evolution from conventional memory solutions toward specialized architectures like High Bandwidth Memory and Compute-In-Memory technologies.
Deep learning models, particularly large language models and computer vision networks, demonstrate exponentially growing parameter counts that directly translate to substantial memory footprint requirements. Contemporary transformer-based models can exceed hundreds of billions of parameters, with each parameter typically requiring 16 to 32 bits of storage. This scaling trend necessitates memory systems capable of accommodating terabytes of data while maintaining efficient access patterns for both training and inference operations.
AI workloads exhibit unique memory access patterns characterized by high temporal locality and sequential data streaming requirements. Training operations involve iterative forward and backward propagation phases that demand consistent high-bandwidth memory access to weight matrices, activation maps, and gradient computations. These access patterns favor memory architectures optimized for sustained throughput rather than random access latency, influencing the preference for HBM solutions in GPU-accelerated AI systems.
Inference workloads present different memory requirements compared to training scenarios, often prioritizing energy efficiency and latency optimization over raw bandwidth. Edge AI applications particularly emphasize memory solutions that minimize data movement overhead, making Compute-In-Memory architectures attractive for scenarios where computational operations can be performed directly within memory arrays, reducing the traditional von Neumann bottleneck.
The batch processing nature of AI workloads creates memory utilization patterns that benefit from parallel memory access capabilities. Multiple data samples processed simultaneously require memory systems capable of supporting concurrent read and write operations across different memory banks. This requirement aligns well with HBM's multi-channel architecture, which provides independent access paths for parallel data streams.
Memory bandwidth requirements scale proportionally with model complexity and batch sizes, creating scenarios where traditional DDR memory solutions become inadequate. Modern AI accelerators demand memory bandwidth exceeding several terabytes per second, driving adoption of specialized memory technologies that can sustain these throughput requirements while maintaining reasonable power consumption profiles for both datacenter and edge deployment scenarios.
Deep learning models, particularly large language models and computer vision networks, demonstrate exponentially growing parameter counts that directly translate to substantial memory footprint requirements. Contemporary transformer-based models can exceed hundreds of billions of parameters, with each parameter typically requiring 16 to 32 bits of storage. This scaling trend necessitates memory systems capable of accommodating terabytes of data while maintaining efficient access patterns for both training and inference operations.
AI workloads exhibit unique memory access patterns characterized by high temporal locality and sequential data streaming requirements. Training operations involve iterative forward and backward propagation phases that demand consistent high-bandwidth memory access to weight matrices, activation maps, and gradient computations. These access patterns favor memory architectures optimized for sustained throughput rather than random access latency, influencing the preference for HBM solutions in GPU-accelerated AI systems.
Inference workloads present different memory requirements compared to training scenarios, often prioritizing energy efficiency and latency optimization over raw bandwidth. Edge AI applications particularly emphasize memory solutions that minimize data movement overhead, making Compute-In-Memory architectures attractive for scenarios where computational operations can be performed directly within memory arrays, reducing the traditional von Neumann bottleneck.
The batch processing nature of AI workloads creates memory utilization patterns that benefit from parallel memory access capabilities. Multiple data samples processed simultaneously require memory systems capable of supporting concurrent read and write operations across different memory banks. This requirement aligns well with HBM's multi-channel architecture, which provides independent access paths for parallel data streams.
Memory bandwidth requirements scale proportionally with model complexity and batch sizes, creating scenarios where traditional DDR memory solutions become inadequate. Modern AI accelerators demand memory bandwidth exceeding several terabytes per second, driving adoption of specialized memory technologies that can sustain these throughput requirements while maintaining reasonable power consumption profiles for both datacenter and edge deployment scenarios.
Energy Efficiency in Advanced Memory Systems
Energy efficiency has emerged as a critical differentiator between High Bandwidth Memory (HBM) and Compute-In-Memory (CIM) architectures, fundamentally reshaping the landscape of advanced memory systems. The energy consumption patterns of these technologies reveal distinct advantages and trade-offs that directly impact their deployment in data-intensive applications.
HBM systems demonstrate superior energy efficiency in bandwidth-intensive scenarios through their optimized data transfer mechanisms. The 3D stacked architecture minimizes the physical distance data must travel, reducing transmission energy by approximately 40-60% compared to traditional GDDR configurations. However, HBM's energy profile becomes less favorable when considering idle power consumption, as the complex interface circuitry maintains baseline power draw even during low-utilization periods.
Compute-In-Memory architectures present a fundamentally different energy paradigm by eliminating data movement between processing units and memory arrays. This approach can achieve energy reductions of 10-100x for specific computational workloads, particularly matrix operations and neural network inference. The energy savings stem from avoiding the costly data shuttling that typically dominates power consumption in conventional von Neumann architectures.
The energy efficiency comparison becomes nuanced when examining workload characteristics. HBM excels in scenarios requiring high-throughput data streaming with minimal computational overhead, such as graphics rendering and large-scale data analytics. Conversely, CIM technologies demonstrate superior efficiency in compute-heavy applications where the same data undergoes multiple processing operations, including AI inference and signal processing tasks.
Dynamic power scaling capabilities further differentiate these technologies. Advanced HBM implementations incorporate sophisticated power management features, including selective bank activation and adaptive voltage scaling, enabling energy consumption to scale proportionally with utilization. CIM systems achieve energy efficiency through computational density, performing multiple operations simultaneously within memory cells while maintaining lower overall power envelopes.
The thermal implications of energy efficiency also influence system-level design considerations. HBM's concentrated heat generation requires robust cooling solutions, potentially offsetting some energy gains at the system level. CIM architectures distribute computational heat across larger memory arrays, often resulting in more manageable thermal profiles and reduced cooling requirements.
HBM systems demonstrate superior energy efficiency in bandwidth-intensive scenarios through their optimized data transfer mechanisms. The 3D stacked architecture minimizes the physical distance data must travel, reducing transmission energy by approximately 40-60% compared to traditional GDDR configurations. However, HBM's energy profile becomes less favorable when considering idle power consumption, as the complex interface circuitry maintains baseline power draw even during low-utilization periods.
Compute-In-Memory architectures present a fundamentally different energy paradigm by eliminating data movement between processing units and memory arrays. This approach can achieve energy reductions of 10-100x for specific computational workloads, particularly matrix operations and neural network inference. The energy savings stem from avoiding the costly data shuttling that typically dominates power consumption in conventional von Neumann architectures.
The energy efficiency comparison becomes nuanced when examining workload characteristics. HBM excels in scenarios requiring high-throughput data streaming with minimal computational overhead, such as graphics rendering and large-scale data analytics. Conversely, CIM technologies demonstrate superior efficiency in compute-heavy applications where the same data undergoes multiple processing operations, including AI inference and signal processing tasks.
Dynamic power scaling capabilities further differentiate these technologies. Advanced HBM implementations incorporate sophisticated power management features, including selective bank activation and adaptive voltage scaling, enabling energy consumption to scale proportionally with utilization. CIM systems achieve energy efficiency through computational density, performing multiple operations simultaneously within memory cells while maintaining lower overall power envelopes.
The thermal implications of energy efficiency also influence system-level design considerations. HBM's concentrated heat generation requires robust cooling solutions, potentially offsetting some energy gains at the system level. CIM architectures distribute computational heat across larger memory arrays, often resulting in more manageable thermal profiles and reduced cooling requirements.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!