

Optimize HBM Memory Load-Balancing for Scalable AI Frameworks
MAY 18, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
HBM Memory Optimization Background and AI Scalability Goals
High Bandwidth Memory (HBM) represents a revolutionary advancement in memory architecture, emerging from the critical need to address the growing memory bandwidth bottlenecks in high-performance computing applications. Originally developed through collaborative efforts between SK Hynix, AMD, and other industry leaders, HBM technology utilizes through-silicon via (TSV) technology and 3D stacking to achieve unprecedented memory bandwidth while maintaining compact form factors.
The evolution of HBM technology has progressed through multiple generations, with HBM3 currently delivering bandwidth capabilities exceeding 600 GB/s per stack. This dramatic improvement over traditional GDDR memory solutions has positioned HBM as the cornerstone memory technology for AI accelerators, graphics processing units, and high-performance computing systems. The technology's development trajectory reflects the industry's response to the exponential growth in computational demands driven by artificial intelligence workloads.
Modern AI frameworks face unprecedented scalability challenges as model complexity and dataset sizes continue to expand exponentially. Large language models, computer vision networks, and multimodal AI systems now require memory subsystems capable of supporting trillions of parameters while maintaining efficient data flow patterns. The traditional von Neumann architecture bottleneck becomes particularly pronounced in distributed AI training scenarios, where memory bandwidth limitations can severely constrain overall system performance.
The primary technical objective centers on developing intelligent load-balancing mechanisms that can dynamically distribute memory access patterns across multiple HBM stacks to maximize aggregate bandwidth utilization. This involves creating sophisticated algorithms that can predict memory access patterns, minimize bank conflicts, and optimize data placement strategies to reduce latency while maximizing throughput.
Scalability goals encompass both horizontal and vertical scaling dimensions. Horizontal scalability targets the seamless integration of multiple AI accelerators with coordinated HBM memory management, enabling efficient distributed training and inference across cluster environments. Vertical scalability focuses on maximizing the utilization efficiency of individual HBM stacks through advanced memory scheduling algorithms and predictive prefetching mechanisms.
The ultimate technical vision aims to achieve near-theoretical peak memory bandwidth utilization while maintaining deterministic performance characteristics essential for production AI deployments. This requires developing adaptive memory management frameworks that can automatically adjust to varying workload characteristics and system configurations.
The evolution of HBM technology has progressed through multiple generations, with HBM3 currently delivering bandwidth capabilities exceeding 600 GB/s per stack. This dramatic improvement over traditional GDDR memory solutions has positioned HBM as the cornerstone memory technology for AI accelerators, graphics processing units, and high-performance computing systems. The technology's development trajectory reflects the industry's response to the exponential growth in computational demands driven by artificial intelligence workloads.
Modern AI frameworks face unprecedented scalability challenges as model complexity and dataset sizes continue to expand exponentially. Large language models, computer vision networks, and multimodal AI systems now require memory subsystems capable of supporting trillions of parameters while maintaining efficient data flow patterns. The traditional von Neumann architecture bottleneck becomes particularly pronounced in distributed AI training scenarios, where memory bandwidth limitations can severely constrain overall system performance.
The primary technical objective centers on developing intelligent load-balancing mechanisms that can dynamically distribute memory access patterns across multiple HBM stacks to maximize aggregate bandwidth utilization. This involves creating sophisticated algorithms that can predict memory access patterns, minimize bank conflicts, and optimize data placement strategies to reduce latency while maximizing throughput.
Scalability goals encompass both horizontal and vertical scaling dimensions. Horizontal scalability targets the seamless integration of multiple AI accelerators with coordinated HBM memory management, enabling efficient distributed training and inference across cluster environments. Vertical scalability focuses on maximizing the utilization efficiency of individual HBM stacks through advanced memory scheduling algorithms and predictive prefetching mechanisms.
The ultimate technical vision aims to achieve near-theoretical peak memory bandwidth utilization while maintaining deterministic performance characteristics essential for production AI deployments. This requires developing adaptive memory management frameworks that can automatically adjust to varying workload characteristics and system configurations.
Market Demand for High-Performance AI Computing Infrastructure
The global AI computing infrastructure market is experiencing unprecedented growth driven by the exponential expansion of artificial intelligence applications across industries. Enterprise adoption of large language models, computer vision systems, and deep learning frameworks has created substantial demand for high-performance computing solutions capable of handling massive computational workloads. Organizations are increasingly recognizing that traditional computing architectures cannot adequately support the memory bandwidth and processing requirements of modern AI workloads.
High Bandwidth Memory optimization has emerged as a critical bottleneck in AI infrastructure scalability. Current AI frameworks frequently encounter memory bandwidth limitations when processing large-scale neural networks, particularly in training scenarios involving transformer models and multi-modal AI systems. The inability to efficiently distribute memory loads across HBM modules results in underutilized computing resources and extended training times, directly impacting operational efficiency and cost-effectiveness.
Cloud service providers are experiencing significant pressure to deliver more efficient AI computing services as customer workloads become increasingly complex. Major hyperscale data centers report that memory bandwidth constraints represent one of the primary limiting factors in AI accelerator utilization rates. This challenge is particularly acute in multi-tenant environments where diverse AI workloads must share computing resources while maintaining performance isolation and predictable service levels.
The semiconductor industry has responded to these demands by developing advanced HBM technologies with higher bandwidth capabilities. However, the software infrastructure required to fully exploit these hardware improvements remains underdeveloped. Load-balancing optimization represents a crucial software innovation that can unlock the full potential of existing and future HBM implementations without requiring additional hardware investments.
Financial institutions, autonomous vehicle manufacturers, and pharmaceutical companies are driving demand for more sophisticated AI computing solutions that can handle real-time inference and continuous learning scenarios. These applications require consistent memory performance characteristics and cannot tolerate the performance variability associated with poorly balanced memory subsystems. The market opportunity for optimized HBM load-balancing solutions extends beyond traditional AI companies to encompass any organization implementing AI-driven decision-making systems.
Emerging edge computing applications further amplify the importance of memory optimization technologies. As AI inference moves closer to data sources, efficient memory utilization becomes essential for maintaining performance within power and thermal constraints typical of edge deployment environments.
High Bandwidth Memory optimization has emerged as a critical bottleneck in AI infrastructure scalability. Current AI frameworks frequently encounter memory bandwidth limitations when processing large-scale neural networks, particularly in training scenarios involving transformer models and multi-modal AI systems. The inability to efficiently distribute memory loads across HBM modules results in underutilized computing resources and extended training times, directly impacting operational efficiency and cost-effectiveness.
Cloud service providers are experiencing significant pressure to deliver more efficient AI computing services as customer workloads become increasingly complex. Major hyperscale data centers report that memory bandwidth constraints represent one of the primary limiting factors in AI accelerator utilization rates. This challenge is particularly acute in multi-tenant environments where diverse AI workloads must share computing resources while maintaining performance isolation and predictable service levels.
The semiconductor industry has responded to these demands by developing advanced HBM technologies with higher bandwidth capabilities. However, the software infrastructure required to fully exploit these hardware improvements remains underdeveloped. Load-balancing optimization represents a crucial software innovation that can unlock the full potential of existing and future HBM implementations without requiring additional hardware investments.
Financial institutions, autonomous vehicle manufacturers, and pharmaceutical companies are driving demand for more sophisticated AI computing solutions that can handle real-time inference and continuous learning scenarios. These applications require consistent memory performance characteristics and cannot tolerate the performance variability associated with poorly balanced memory subsystems. The market opportunity for optimized HBM load-balancing solutions extends beyond traditional AI companies to encompass any organization implementing AI-driven decision-making systems.
Emerging edge computing applications further amplify the importance of memory optimization technologies. As AI inference moves closer to data sources, efficient memory utilization becomes essential for maintaining performance within power and thermal constraints typical of edge deployment environments.
Current HBM Load-Balancing Challenges in AI Frameworks
High Bandwidth Memory (HBM) load-balancing in AI frameworks faces significant challenges that directly impact the scalability and performance of modern artificial intelligence systems. The primary issue stems from the inherent complexity of managing multiple HBM stacks while ensuring optimal data distribution across processing units. Current AI frameworks struggle with uneven memory access patterns, where certain HBM modules experience disproportionate workloads while others remain underutilized.
Memory bandwidth contention represents a critical bottleneck in existing implementations. When multiple GPU cores or AI accelerators attempt to access the same HBM stack simultaneously, severe performance degradation occurs due to queuing delays and increased latency. This problem becomes particularly acute in large-scale training scenarios where massive datasets require continuous memory transfers across distributed computing nodes.
Dynamic workload allocation poses another substantial challenge for current load-balancing mechanisms. Traditional static partitioning approaches fail to adapt to the varying computational demands of different AI model layers, resulting in suboptimal resource utilization. The temporal nature of neural network operations creates unpredictable memory access patterns that existing frameworks cannot efficiently predict or accommodate.
Interconnect topology limitations further complicate HBM load-balancing efforts. Current system architectures often lack sophisticated routing mechanisms to dynamically redirect memory traffic based on real-time utilization metrics. The rigid connection pathways between processing units and HBM stacks create artificial constraints that prevent optimal load distribution, particularly in multi-socket and multi-node configurations.
Synchronization overhead emerges as a significant performance impediment when attempting to implement coordinated load-balancing strategies. The computational cost of monitoring HBM utilization across multiple stacks and making real-time allocation decisions can offset the benefits of improved memory distribution. Current frameworks lack efficient mechanisms to balance the trade-off between monitoring granularity and system overhead.
Thermal management complications arise from uneven HBM utilization patterns, where heavily loaded memory modules generate excessive heat while others operate below optimal temperatures. This thermal imbalance not only affects performance through throttling mechanisms but also impacts system reliability and longevity, creating additional constraints for load-balancing algorithms to consider in their optimization strategies.
Memory bandwidth contention represents a critical bottleneck in existing implementations. When multiple GPU cores or AI accelerators attempt to access the same HBM stack simultaneously, severe performance degradation occurs due to queuing delays and increased latency. This problem becomes particularly acute in large-scale training scenarios where massive datasets require continuous memory transfers across distributed computing nodes.
Dynamic workload allocation poses another substantial challenge for current load-balancing mechanisms. Traditional static partitioning approaches fail to adapt to the varying computational demands of different AI model layers, resulting in suboptimal resource utilization. The temporal nature of neural network operations creates unpredictable memory access patterns that existing frameworks cannot efficiently predict or accommodate.
Interconnect topology limitations further complicate HBM load-balancing efforts. Current system architectures often lack sophisticated routing mechanisms to dynamically redirect memory traffic based on real-time utilization metrics. The rigid connection pathways between processing units and HBM stacks create artificial constraints that prevent optimal load distribution, particularly in multi-socket and multi-node configurations.
Synchronization overhead emerges as a significant performance impediment when attempting to implement coordinated load-balancing strategies. The computational cost of monitoring HBM utilization across multiple stacks and making real-time allocation decisions can offset the benefits of improved memory distribution. Current frameworks lack efficient mechanisms to balance the trade-off between monitoring granularity and system overhead.
Thermal management complications arise from uneven HBM utilization patterns, where heavily loaded memory modules generate excessive heat while others operate below optimal temperatures. This thermal imbalance not only affects performance through throttling mechanisms but also impacts system reliability and longevity, creating additional constraints for load-balancing algorithms to consider in their optimization strategies.
Existing HBM Load-Balancing Solutions for AI Workloads
01 Dynamic memory allocation and scheduling algorithms
Advanced scheduling algorithms are employed to dynamically allocate memory resources across multiple memory channels and stacks. These algorithms monitor memory access patterns and redistribute workloads in real-time to prevent bottlenecks and ensure optimal utilization of available bandwidth. The systems implement predictive models to anticipate memory demands and proactively adjust allocation strategies.- Dynamic memory allocation and load distribution algorithms: Advanced algorithms for dynamically distributing memory loads across multiple HBM channels and stacks to optimize performance. These methods involve real-time monitoring of memory usage patterns and automatically redistributing workloads to prevent bottlenecks and ensure balanced utilization across all available memory resources.
- Memory controller optimization for HBM load balancing: Specialized memory controller designs that implement intelligent scheduling and arbitration mechanisms to manage data flow across HBM memory interfaces. These controllers utilize predictive algorithms and priority-based scheduling to ensure optimal load distribution while maintaining high bandwidth utilization and low latency access patterns.
- Multi-channel memory access coordination: Techniques for coordinating memory access requests across multiple HBM channels to achieve balanced load distribution. These methods involve sophisticated request queuing, channel selection algorithms, and inter-channel communication protocols that prevent hotspots and ensure uniform utilization of all available memory channels.
- Bandwidth optimization and traffic management: Systems for optimizing memory bandwidth utilization through intelligent traffic management and data placement strategies. These approaches include adaptive bandwidth allocation, congestion control mechanisms, and data migration techniques that dynamically adjust to changing workload patterns to maintain optimal performance across the entire memory subsystem.
- Power-aware load balancing for HBM systems: Energy-efficient load balancing strategies that consider power consumption while distributing memory workloads across HBM stacks. These methods incorporate power management policies, thermal considerations, and performance-per-watt optimization to achieve balanced memory utilization while minimizing overall system power consumption and heat generation.
02 Multi-channel memory controller architecture
Specialized memory controller designs that manage multiple memory channels simultaneously to distribute memory requests evenly. These controllers implement sophisticated arbitration mechanisms and priority schemes to handle concurrent memory operations while maintaining data coherency and minimizing latency across all channels.Expand Specific Solutions03 Bandwidth monitoring and traffic management
Real-time monitoring systems that track memory bandwidth utilization and implement traffic shaping techniques to prevent congestion. These systems use performance counters and statistical analysis to identify hotspots and automatically redirect memory traffic to underutilized channels or memory regions.Expand Specific Solutions04 Address mapping and interleaving strategies
Sophisticated address translation and mapping schemes that distribute memory addresses across multiple memory stacks and channels. These strategies implement various interleaving patterns and hashing functions to ensure uniform distribution of memory accesses and prevent memory hotspots from forming.Expand Specific Solutions05 Cache coherency and data placement optimization
Advanced cache management systems that optimize data placement and maintain coherency across distributed memory architectures. These systems implement intelligent prefetching algorithms and data migration techniques to reduce memory access latency while ensuring balanced utilization of memory resources.Expand Specific Solutions
Key Players in HBM and AI Framework Industry
The HBM memory load-balancing optimization for scalable AI frameworks represents a rapidly evolving market segment within the broader AI infrastructure ecosystem. The industry is currently in a growth phase, driven by increasing demand for high-performance computing in AI applications. Market size is expanding significantly as enterprises adopt AI at scale, creating substantial opportunities for memory optimization solutions. Technology maturity varies across players, with established semiconductor giants like Samsung Electronics, Intel, and Huawei leading in HBM manufacturing and integration capabilities. Memory specialists such as ChangXin Memory Technologies and SanDisk Technologies focus on advanced storage solutions, while companies like Unifabrix and Expedera develop specialized memory fabric and neural processing technologies. Cloud providers including Microsoft, Salesforce, and Chinese firms like Inspur and UCloud drive demand through scalable AI platform requirements. The competitive landscape shows a mix of hardware manufacturers, software optimizers, and integrated solution providers, indicating a maturing but still fragmented market with significant consolidation potential.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung has developed advanced HBM memory architectures with intelligent load-balancing mechanisms for AI workloads. Their HBM3 solutions incorporate dynamic bandwidth allocation algorithms that monitor memory access patterns in real-time and redistribute data flows across multiple memory stacks to prevent bottlenecks. The technology includes adaptive prefetching mechanisms that predict AI model memory requirements and proactively balance loads across HBM channels. Samsung's approach utilizes hardware-level memory controllers with built-in load monitoring capabilities, enabling automatic adjustment of memory access scheduling to optimize throughput for large-scale AI training and inference tasks. Their solution supports up to 819GB/s bandwidth with intelligent traffic management across multiple HBM stacks.
Strengths: Leading HBM manufacturing capabilities with high bandwidth and capacity. Advanced hardware-level optimization. Weaknesses: Higher cost compared to traditional memory solutions, complex integration requirements.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed a comprehensive HBM load-balancing solution integrated with their Ascend AI processors and MindSpore framework. Their approach utilizes a hierarchical memory management system that dynamically allocates HBM resources based on AI model computational graphs and memory access patterns. The technology includes intelligent memory scheduling algorithms that analyze workload characteristics and automatically distribute data across multiple HBM stacks to maximize bandwidth utilization. Huawei's solution incorporates real-time load monitoring and adaptive rebalancing mechanisms that can handle varying AI workload demands while maintaining optimal memory performance across distributed computing environments.
Strengths: Integrated AI ecosystem with custom processors, strong performance optimization for AI workloads. Weaknesses: Limited global market access, ecosystem lock-in concerns, regulatory restrictions in some markets.
Core Innovations in HBM Memory Management Algorithms
System and method for modular HBM chiplet architecture
PatentPendingEP4621582A1
Innovation
- A modular HBM design utilizing daisy-chain and network-grid configurations to interconnect multiple HBM chiplets, allowing scalable memory bandwidth and capacity expansion.




System and method for sharing high bandwidth memory between computer resources using optical links
PatentPendingUS20250028559A1
Innovation
- The system and method enable sharing of HBM between multiple GPUs using both electrical and optical switching, facilitated by an optical physical layer that extends signal reach and density, and incorporates all-to-all connections and broadcasting for enhanced data transmission.
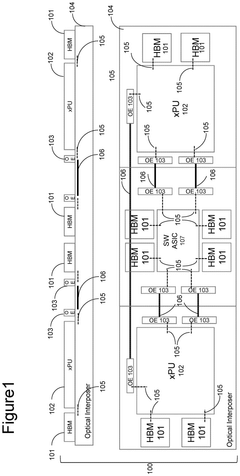
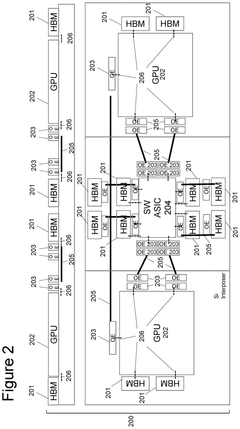
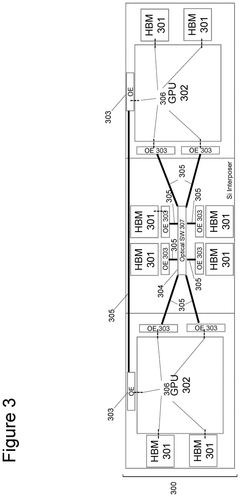
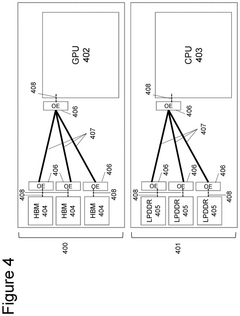
Energy Efficiency Considerations in HBM Optimization
Energy efficiency has emerged as a critical consideration in HBM optimization for scalable AI frameworks, driven by the exponential growth in computational demands and the associated power consumption challenges. As AI workloads continue to scale, the energy footprint of memory subsystems, particularly HBM implementations, represents a significant portion of total system power consumption, often accounting for 20-40% of overall energy usage in high-performance computing environments.
The relationship between load-balancing strategies and energy consumption in HBM architectures presents complex optimization challenges. Traditional load-balancing approaches that prioritize performance maximization may inadvertently increase power consumption through suboptimal memory access patterns, unnecessary data movement, and inefficient utilization of HBM channels. Dynamic voltage and frequency scaling techniques have shown promise in reducing energy consumption by up to 25% when integrated with intelligent load-balancing algorithms that consider both performance and power metrics.
Thermal management considerations play a crucial role in energy-efficient HBM optimization. Uneven memory access patterns can create thermal hotspots that trigger aggressive cooling mechanisms, significantly increasing overall system energy consumption. Advanced load-balancing strategies now incorporate thermal-aware scheduling algorithms that distribute memory operations to maintain optimal operating temperatures while minimizing cooling overhead.
Power-aware memory scheduling represents a frontier in HBM optimization, where algorithms dynamically adjust memory access patterns based on real-time power consumption monitoring. These approaches leverage predictive models to anticipate power spikes and proactively redistribute workloads across HBM stacks, achieving energy savings of 15-30% compared to conventional load-balancing methods.
The integration of machine learning techniques in energy-efficient load-balancing has demonstrated significant potential for adaptive power management. These systems learn from historical access patterns and power consumption data to optimize future memory allocation decisions, creating feedback loops that continuously improve energy efficiency while maintaining performance targets in scalable AI framework deployments.
The relationship between load-balancing strategies and energy consumption in HBM architectures presents complex optimization challenges. Traditional load-balancing approaches that prioritize performance maximization may inadvertently increase power consumption through suboptimal memory access patterns, unnecessary data movement, and inefficient utilization of HBM channels. Dynamic voltage and frequency scaling techniques have shown promise in reducing energy consumption by up to 25% when integrated with intelligent load-balancing algorithms that consider both performance and power metrics.
Thermal management considerations play a crucial role in energy-efficient HBM optimization. Uneven memory access patterns can create thermal hotspots that trigger aggressive cooling mechanisms, significantly increasing overall system energy consumption. Advanced load-balancing strategies now incorporate thermal-aware scheduling algorithms that distribute memory operations to maintain optimal operating temperatures while minimizing cooling overhead.
Power-aware memory scheduling represents a frontier in HBM optimization, where algorithms dynamically adjust memory access patterns based on real-time power consumption monitoring. These approaches leverage predictive models to anticipate power spikes and proactively redistribute workloads across HBM stacks, achieving energy savings of 15-30% compared to conventional load-balancing methods.
The integration of machine learning techniques in energy-efficient load-balancing has demonstrated significant potential for adaptive power management. These systems learn from historical access patterns and power consumption data to optimize future memory allocation decisions, creating feedback loops that continuously improve energy efficiency while maintaining performance targets in scalable AI framework deployments.
Hardware-Software Co-design for HBM Integration
Hardware-software co-design represents a paradigm shift in HBM integration for AI frameworks, where traditional boundaries between hardware architecture and software optimization dissolve to create unified solutions. This approach recognizes that optimal HBM memory load-balancing cannot be achieved through isolated hardware or software improvements alone, but requires deep integration and mutual adaptation between both layers.
The co-design methodology begins with hardware-aware software development, where AI framework architects design memory management systems with intimate knowledge of HBM's unique characteristics. This includes understanding HBM's multi-stack architecture, bandwidth asymmetries, and thermal constraints. Software schedulers are engineered to exploit HBM's parallel access patterns while avoiding hotspots that could trigger thermal throttling or bandwidth contention.
Conversely, hardware designers increasingly incorporate software feedback mechanisms into HBM controller designs. Modern HBM implementations feature programmable memory controllers that can adapt their behavior based on runtime workload characteristics detected by the software layer. These controllers implement dynamic voltage and frequency scaling, adaptive refresh scheduling, and intelligent prefetching based on AI workload patterns communicated from the software stack.
Memory mapping strategies exemplify successful co-design implementation, where hardware memory controllers and software memory allocators collaborate to optimize data placement. The hardware provides fine-grained performance counters and thermal sensors, while software uses this telemetry to make informed decisions about tensor placement and migration. This creates closed-loop optimization systems that continuously adapt to changing workload demands.
Interface standardization plays a crucial role in enabling effective co-design. Emerging standards like CXL and advanced memory management APIs provide standardized communication channels between hardware and software layers. These interfaces allow software frameworks to express memory access intentions and constraints to hardware, while hardware can communicate its current state and capabilities back to software optimizers.
The co-design approach also extends to compiler-level optimizations, where AI compilers generate code that explicitly considers HBM topology and performance characteristics. These compilers can insert memory prefetch instructions, optimize data layout for HBM access patterns, and generate adaptive code paths that respond to runtime memory performance feedback.
The co-design methodology begins with hardware-aware software development, where AI framework architects design memory management systems with intimate knowledge of HBM's unique characteristics. This includes understanding HBM's multi-stack architecture, bandwidth asymmetries, and thermal constraints. Software schedulers are engineered to exploit HBM's parallel access patterns while avoiding hotspots that could trigger thermal throttling or bandwidth contention.
Conversely, hardware designers increasingly incorporate software feedback mechanisms into HBM controller designs. Modern HBM implementations feature programmable memory controllers that can adapt their behavior based on runtime workload characteristics detected by the software layer. These controllers implement dynamic voltage and frequency scaling, adaptive refresh scheduling, and intelligent prefetching based on AI workload patterns communicated from the software stack.
Memory mapping strategies exemplify successful co-design implementation, where hardware memory controllers and software memory allocators collaborate to optimize data placement. The hardware provides fine-grained performance counters and thermal sensors, while software uses this telemetry to make informed decisions about tensor placement and migration. This creates closed-loop optimization systems that continuously adapt to changing workload demands.
Interface standardization plays a crucial role in enabling effective co-design. Emerging standards like CXL and advanced memory management APIs provide standardized communication channels between hardware and software layers. These interfaces allow software frameworks to express memory access intentions and constraints to hardware, while hardware can communicate its current state and capabilities back to software optimizers.
The co-design approach also extends to compiler-level optimizations, where AI compilers generate code that explicitly considers HBM topology and performance characteristics. These compilers can insert memory prefetch instructions, optimize data layout for HBM access patterns, and generate adaptive code paths that respond to runtime memory performance feedback.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!