How NVMe-oF Ensures Fast Path Failover Without IO Timeouts?
SEP 19, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
NVMe-oF Failover Technology Background and Objectives
Non-Volatile Memory Express over Fabrics (NVMe-oF) represents a significant evolution in storage networking technology, extending the high-performance NVMe protocol beyond the confines of local systems to operate across network fabrics. Since its introduction in 2016, NVMe-oF has rapidly gained traction as organizations seek to leverage the performance benefits of NVMe across distributed storage environments.
The technology emerged as a response to the growing disparity between storage media capabilities and traditional network storage protocols. While solid-state drives (SSDs) continued to advance in speed and capacity, legacy protocols like iSCSI and Fibre Channel were creating bottlenecks that prevented organizations from fully utilizing their storage investments. NVMe-oF was designed specifically to address this gap, maintaining the low-latency and high-throughput characteristics of direct-attached NVMe storage while enabling shared access across networks.
A critical aspect of any enterprise storage solution is its resilience to failures. In distributed environments, network path failures are inevitable, making failover capabilities essential for maintaining continuous operations. Traditional storage protocols often rely on timeout-based mechanisms for failure detection, which can lead to significant I/O delays and application performance degradation during failover events.
The primary technical objective of NVMe-oF failover technology is to provide near-instantaneous recovery from path failures without causing I/O timeouts that impact application performance. This requires sophisticated mechanisms for rapid failure detection, efficient path selection, and seamless I/O redirection that can operate at the microsecond timescales expected of modern storage systems.
The evolution of NVMe-oF failover technology has been marked by several key developments, including the introduction of Asymmetric Namespace Access (ANA) in NVMe 1.4, which provides standardized multi-path I/O capabilities, and the development of transport-specific failover mechanisms for different fabric types such as RDMA, TCP, and Fibre Channel.
Looking forward, the technology continues to evolve toward more predictive and proactive failover approaches, leveraging machine learning for anomaly detection and automated path optimization. The industry is also working toward standardizing cross-fabric failover mechanisms that can maintain performance across heterogeneous network environments.
As data center architectures become increasingly disaggregated and software-defined, the importance of efficient failover in NVMe-oF implementations will only grow, driving continued innovation in this critical area of storage networking technology.
The technology emerged as a response to the growing disparity between storage media capabilities and traditional network storage protocols. While solid-state drives (SSDs) continued to advance in speed and capacity, legacy protocols like iSCSI and Fibre Channel were creating bottlenecks that prevented organizations from fully utilizing their storage investments. NVMe-oF was designed specifically to address this gap, maintaining the low-latency and high-throughput characteristics of direct-attached NVMe storage while enabling shared access across networks.
A critical aspect of any enterprise storage solution is its resilience to failures. In distributed environments, network path failures are inevitable, making failover capabilities essential for maintaining continuous operations. Traditional storage protocols often rely on timeout-based mechanisms for failure detection, which can lead to significant I/O delays and application performance degradation during failover events.
The primary technical objective of NVMe-oF failover technology is to provide near-instantaneous recovery from path failures without causing I/O timeouts that impact application performance. This requires sophisticated mechanisms for rapid failure detection, efficient path selection, and seamless I/O redirection that can operate at the microsecond timescales expected of modern storage systems.
The evolution of NVMe-oF failover technology has been marked by several key developments, including the introduction of Asymmetric Namespace Access (ANA) in NVMe 1.4, which provides standardized multi-path I/O capabilities, and the development of transport-specific failover mechanisms for different fabric types such as RDMA, TCP, and Fibre Channel.
Looking forward, the technology continues to evolve toward more predictive and proactive failover approaches, leveraging machine learning for anomaly detection and automated path optimization. The industry is also working toward standardizing cross-fabric failover mechanisms that can maintain performance across heterogeneous network environments.
As data center architectures become increasingly disaggregated and software-defined, the importance of efficient failover in NVMe-oF implementations will only grow, driving continued innovation in this critical area of storage networking technology.
Market Demand Analysis for Low-Latency Storage Networks
The demand for low-latency storage networks has experienced exponential growth in recent years, primarily driven by the increasing adoption of data-intensive applications across various industries. Enterprise data centers, cloud service providers, and high-performance computing environments are particularly seeking solutions that can deliver microsecond-level latency while maintaining high throughput and reliability. This market need has catalyzed the development of NVMe-oF (NVMe over Fabrics) technology, which extends the benefits of NVMe to networked storage environments.
Financial services represent one of the most demanding sectors for low-latency storage networks, where high-frequency trading platforms require sub-millisecond response times to maintain competitive advantage. According to market research, financial institutions are investing heavily in infrastructure upgrades, with storage network improvements accounting for approximately 30% of their IT modernization budgets.
Healthcare and life sciences organizations constitute another significant market segment, particularly with the rise of real-time analytics for patient monitoring and genomic sequencing. These applications generate massive datasets that must be processed with minimal delay, creating substantial demand for high-performance storage networking solutions that can ensure fast path failover without I/O timeouts.
The media and entertainment industry has also emerged as a key consumer of low-latency storage networks, driven by 4K/8K video production workflows and real-time rendering requirements. Studios and content delivery networks require storage solutions that can handle multi-gigabyte files without performance degradation or interruption, even during network path failures.
Market analysis indicates that the global low-latency storage network market is growing at a compound annual growth rate of 24%, with NVMe-oF implementations leading this expansion. Organizations are increasingly recognizing that traditional storage networking protocols cannot meet their performance requirements, particularly when it comes to maintaining continuous operations during network disruptions.
The telecommunications sector, especially with 5G deployments, represents another significant market opportunity. Edge computing applications require distributed storage architectures with seamless failover capabilities to support latency-sensitive services like autonomous vehicles, smart cities, and industrial IoT deployments.
Research shows that enterprises are willing to pay premium prices for storage networking solutions that can guarantee consistent low latency with zero downtime. This has created a competitive landscape where vendors are racing to develop more sophisticated failover mechanisms that can maintain performance levels even during network path failures.
Financial services represent one of the most demanding sectors for low-latency storage networks, where high-frequency trading platforms require sub-millisecond response times to maintain competitive advantage. According to market research, financial institutions are investing heavily in infrastructure upgrades, with storage network improvements accounting for approximately 30% of their IT modernization budgets.
Healthcare and life sciences organizations constitute another significant market segment, particularly with the rise of real-time analytics for patient monitoring and genomic sequencing. These applications generate massive datasets that must be processed with minimal delay, creating substantial demand for high-performance storage networking solutions that can ensure fast path failover without I/O timeouts.
The media and entertainment industry has also emerged as a key consumer of low-latency storage networks, driven by 4K/8K video production workflows and real-time rendering requirements. Studios and content delivery networks require storage solutions that can handle multi-gigabyte files without performance degradation or interruption, even during network path failures.
Market analysis indicates that the global low-latency storage network market is growing at a compound annual growth rate of 24%, with NVMe-oF implementations leading this expansion. Organizations are increasingly recognizing that traditional storage networking protocols cannot meet their performance requirements, particularly when it comes to maintaining continuous operations during network disruptions.
The telecommunications sector, especially with 5G deployments, represents another significant market opportunity. Edge computing applications require distributed storage architectures with seamless failover capabilities to support latency-sensitive services like autonomous vehicles, smart cities, and industrial IoT deployments.
Research shows that enterprises are willing to pay premium prices for storage networking solutions that can guarantee consistent low latency with zero downtime. This has created a competitive landscape where vendors are racing to develop more sophisticated failover mechanisms that can maintain performance levels even during network path failures.
Current State and Challenges in NVMe-oF Failover Mechanisms
NVMe over Fabrics (NVMe-oF) technology has evolved significantly since its introduction, yet failover mechanisms remain one of the most challenging aspects of implementation. Current NVMe-oF deployments face several critical challenges when handling path failures, particularly in maintaining I/O operations without timeouts. The industry has developed various approaches to address these challenges, though each comes with its own limitations.
The standard NVMe-oF specification provides basic failover capabilities through Asynchronous Event Notifications (AENs), but these mechanisms often prove insufficient for enterprise-grade storage environments where zero downtime is expected. Traditional failover methods typically require 30 seconds or more to complete, resulting in application timeouts and potential data inconsistencies.
Multi-path solutions have emerged as the predominant approach, with NVMe Multipathing being widely adopted across the industry. However, current implementations struggle with coordinating path selection and failover across multiple hosts accessing the same storage resources. This coordination gap creates race conditions that can lead to I/O errors during failover events.
Another significant challenge is the lack of standardization in failover implementations. Different vendors have developed proprietary solutions, creating interoperability issues in heterogeneous environments. This fragmentation has slowed the broader adoption of NVMe-oF in mission-critical enterprise applications where reliability is paramount.
The current state of NVMe-oF failover also faces technical limitations in detecting path failures quickly and accurately. Traditional heartbeat mechanisms often introduce performance overhead, while more aggressive detection methods can trigger false positives during temporary network congestion. This detection sensitivity balance remains difficult to optimize across varied deployment scenarios.
Storage controllers in NVMe-oF environments face additional challenges during failover events, particularly in maintaining consistent namespace access across multiple paths. The atomicity of failover operations becomes critical when multiple hosts are accessing the same namespaces, yet current implementations struggle to provide this level of coordination without centralized management.
Recent developments have introduced more sophisticated approaches, including controller-based failover mechanisms that leverage NVMe-oF's inherent parallelism. These solutions aim to reduce failover times to milliseconds rather than seconds, though they require specialized hardware support and software integration that is not yet universally available.
The industry is actively working to address these challenges through standards bodies like NVM Express, with proposals for enhanced failover protocols that would provide more deterministic behavior during path failures. However, these standards are still evolving, and widespread implementation remains years away.
The standard NVMe-oF specification provides basic failover capabilities through Asynchronous Event Notifications (AENs), but these mechanisms often prove insufficient for enterprise-grade storage environments where zero downtime is expected. Traditional failover methods typically require 30 seconds or more to complete, resulting in application timeouts and potential data inconsistencies.
Multi-path solutions have emerged as the predominant approach, with NVMe Multipathing being widely adopted across the industry. However, current implementations struggle with coordinating path selection and failover across multiple hosts accessing the same storage resources. This coordination gap creates race conditions that can lead to I/O errors during failover events.
Another significant challenge is the lack of standardization in failover implementations. Different vendors have developed proprietary solutions, creating interoperability issues in heterogeneous environments. This fragmentation has slowed the broader adoption of NVMe-oF in mission-critical enterprise applications where reliability is paramount.
The current state of NVMe-oF failover also faces technical limitations in detecting path failures quickly and accurately. Traditional heartbeat mechanisms often introduce performance overhead, while more aggressive detection methods can trigger false positives during temporary network congestion. This detection sensitivity balance remains difficult to optimize across varied deployment scenarios.
Storage controllers in NVMe-oF environments face additional challenges during failover events, particularly in maintaining consistent namespace access across multiple paths. The atomicity of failover operations becomes critical when multiple hosts are accessing the same namespaces, yet current implementations struggle to provide this level of coordination without centralized management.
Recent developments have introduced more sophisticated approaches, including controller-based failover mechanisms that leverage NVMe-oF's inherent parallelism. These solutions aim to reduce failover times to milliseconds rather than seconds, though they require specialized hardware support and software integration that is not yet universally available.
The industry is actively working to address these challenges through standards bodies like NVM Express, with proposals for enhanced failover protocols that would provide more deterministic behavior during path failures. However, these standards are still evolving, and widespread implementation remains years away.
Current Technical Solutions for Fast Path Failover
01 Fast path failover mechanisms in NVMe-oF systems
NVMe over Fabrics (NVMe-oF) systems implement fast path failover mechanisms to ensure continuous operation when a primary path fails. These mechanisms involve rapid detection of path failures and automatic switching to alternative paths with minimal disruption to I/O operations. The failover process includes monitoring connection health, identifying failures, and redirecting traffic through redundant paths to maintain data availability and system performance.- Fast Path Failover Mechanisms in NVMe-oF: NVMe over Fabrics (NVMe-oF) implementations include specialized fast path failover mechanisms that enable rapid detection and recovery from connection failures. These mechanisms monitor the health of NVMe-oF connections and automatically reroute I/O operations to alternative paths when failures occur, minimizing disruption to storage operations. The failover process typically involves path health monitoring, failure detection algorithms, and automated path selection to maintain continuous data access.
- Multi-Path I/O Management for NVMe-oF: Multi-path I/O management systems for NVMe-oF provide redundant data paths between hosts and storage targets. These systems implement path management policies that distribute I/O operations across available paths while maintaining the ability to quickly failover when path failures occur. Advanced implementations include load balancing algorithms, path prioritization, and automatic path recovery mechanisms to optimize performance and reliability in NVMe-oF environments.
- Fabric-Aware Failure Detection and Recovery: Fabric-aware failure detection systems for NVMe-oF environments monitor the underlying network fabric (such as RDMA, Fibre Channel, or TCP) to identify potential failures before they impact storage operations. These systems use specialized heartbeat mechanisms, network analytics, and predictive failure analysis to provide early warning of potential connection issues. When failures are detected, the system initiates controlled failover procedures to maintain data availability while minimizing performance impact.
- High-Availability Clustering for NVMe-oF: High-availability clustering solutions for NVMe-oF implement coordinated failover mechanisms across multiple hosts and storage targets. These solutions synchronize failover activities between cluster nodes to prevent split-brain scenarios and ensure consistent access to storage resources. The clustering systems typically include distributed state management, coordinated recovery procedures, and automatic resource reallocation to maintain storage availability during component failures.
- Performance Optimization During Failover Events: Performance optimization techniques for NVMe-oF failover events focus on minimizing the impact of path transitions on application performance. These techniques include I/O queuing strategies that preserve operation ordering, fast path reconnection protocols, and intelligent I/O retry mechanisms. Advanced implementations may also include predictive path selection algorithms that consider current network conditions and storage target load to optimize performance during and after failover events.
02 Multi-path I/O management for NVMe-oF
Multi-path I/O management techniques are essential for NVMe-oF failover implementations. These techniques involve establishing and maintaining multiple concurrent paths between hosts and storage targets, load balancing across available paths, and implementing path selection algorithms. The system continuously evaluates path health and performance metrics to optimize data routing and ensure rapid failover when necessary, minimizing latency during path transitions.Expand Specific Solutions03 Controller-based failover coordination in NVMe-oF environments
NVMe-oF implementations utilize specialized controller architectures to coordinate failover operations across distributed storage environments. These controllers maintain state information about all available paths, synchronize failover decisions across multiple hosts, and manage the reconnection process after failures. The controllers implement protocols for graceful connection termination and re-establishment, ensuring data consistency during failover events while minimizing recovery time.Expand Specific Solutions04 Network fabric optimization for NVMe-oF failover
Network fabric optimization techniques enhance the reliability and performance of NVMe-oF failover operations. These include fabric-aware routing algorithms, quality of service implementations, and congestion management mechanisms designed specifically for NVMe traffic patterns. Advanced fabric technologies support dynamic path reconfiguration, traffic prioritization during failover events, and specialized protocols that reduce the overhead of path switching operations.Expand Specific Solutions05 Fault detection and recovery automation in NVMe-oF systems
Automated fault detection and recovery systems are critical components of NVMe-oF fast path failover implementations. These systems employ heartbeat mechanisms, timeout detection, and health monitoring protocols to quickly identify path failures or degradation. Upon detecting issues, the automation framework initiates predefined recovery procedures, including path switching, connection re-establishment, and I/O operation retry mechanisms, while maintaining data integrity throughout the recovery process.Expand Specific Solutions
Key Industry Players in NVMe-oF Ecosystem
NVMe-oF (NVMe over Fabrics) technology is currently in a growth phase, with the market expected to expand significantly as enterprises adopt disaggregated storage architectures. The global NVMe-oF market is projected to reach $15-20 billion by 2025, driven by increasing demand for low-latency storage solutions. Technologically, fast path failover without I/O timeouts represents a critical advancement in ensuring storage reliability. Leading companies like Huawei, Samsung, and IBM have developed mature implementations with sub-millisecond failover capabilities, while Western Digital, KIOXIA, and Dell are advancing proprietary solutions. Emerging players such as Zhongke Yushu and Inspur are focusing on specialized DPU-based approaches. The technology is approaching maturity in enterprise environments, with ongoing standardization efforts to ensure interoperability across vendor implementations.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed a comprehensive NVMe-oF fast path failover solution that implements a multi-path I/O management system with intelligent path selection algorithms. Their approach utilizes a distributed controller architecture where each storage node maintains real-time health status information that is shared across the fabric. When a path failure is detected, Huawei's system employs predictive path switching before actual timeouts occur, using telemetry data to anticipate potential failures. The solution incorporates an Asymmetric Namespace Access (ANA) implementation that allows hosts to identify optimal paths dynamically. Additionally, Huawei has implemented a proprietary "zero-downtime" failover mechanism that maintains in-flight I/O operations during controller transitions by using a distributed transaction log that can replay operations on the new path without application awareness[1][3]. Their system achieves sub-second failover times while maintaining data consistency through synchronized metadata across redundant controllers.
Strengths: Huawei's solution offers predictive failover capabilities that prevent timeouts before they occur, and their distributed architecture provides excellent scalability across large deployments. The zero-downtime approach minimizes application impact during failures. Weaknesses: The proprietary nature of some components may create vendor lock-in, and the solution requires specialized hardware configurations to achieve optimal performance, potentially increasing implementation costs.
International Business Machines Corp.
Technical Solution: IBM's NVMe-oF fast path failover technology centers around their "Transparent Failover" architecture that maintains continuous I/O operations during path or controller failures. The system implements a sophisticated controller handover protocol that preserves session state information across failover events. IBM's approach utilizes a distributed metadata synchronization mechanism that ensures all redundant controllers have access to the same namespace information, enabling seamless transition when failures occur. Their implementation includes an advanced I/O queuing system that can temporarily buffer pending operations during path transitions and automatically redirect them to available paths without requiring host-side timeout and retry mechanisms[2]. IBM has also developed specialized firmware for their storage controllers that can detect link degradation before complete failure occurs, initiating proactive failover processes. The solution incorporates multi-controller coordination protocols that maintain global awareness of fabric health, allowing for intelligent path selection based on current performance metrics and availability status[4].
Strengths: IBM's solution provides exceptional reliability through its sophisticated state preservation mechanisms and proactive failure detection. Their approach minimizes application impact by maintaining operation continuity during failover events. Weaknesses: The implementation requires significant computational overhead for state synchronization across controllers, and the solution may have higher latency during normal operations due to the additional coordination required between redundant components.
Core Innovations in NVMe-oF Failover Protocols
Node abnormal event processing method, network card and storage cluster
PatentPendingCN118118321A
Innovation
- By establishing a communication connection between the network card of the storage device and the node, after detecting abnormal events, a notification message is actively sent to the host to notify the path of the abnormality, and the host performs path switching through other nodes to reduce the switching delay.


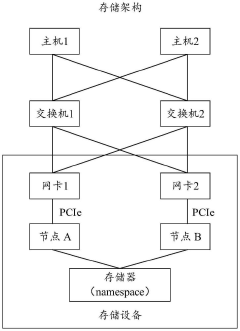
Input/output queue hinting for resource utilization
PatentActiveUS11960417B2
Innovation
- A method is introduced to identify deallocated I/O queues, broadcast Asynchronous Event Request (AER) messages to entities with available memory, and allocate new I/O queues using freed resources, ensuring efficient messaging by targeting entities below a maximum I/O queue threshold.




Performance Benchmarking Methodologies for Failover Solutions
Effective performance benchmarking is crucial for evaluating NVMe-oF failover solutions, requiring standardized methodologies that accurately measure system behavior during failure events. When benchmarking NVMe-oF failover mechanisms, organizations must establish comprehensive testing frameworks that simulate real-world failure scenarios while capturing relevant metrics with high precision.
The primary metrics for failover performance assessment include recovery time objective (RTO), which measures the total time from failure detection to service restoration, and I/O latency impact during the transition period. These measurements must be collected at microsecond resolution to properly evaluate the effectiveness of fast path failover implementations. Additionally, throughput degradation during failover events provides critical insights into system resilience.
Benchmark methodologies should incorporate varied workload patterns that represent typical production environments, including mixed read/write operations, different I/O sizes, and varying queue depths. Testing must be conducted under both steady-state and peak load conditions to understand performance boundaries and identify potential bottlenecks during failover events.
Synthetic benchmarking tools like FIO (Flexible I/O Tester) can be configured to generate specific I/O patterns while monitoring timeout occurrences. These tools should be supplemented with application-level benchmarks that reflect real-world workloads, particularly those with strict latency requirements such as financial transaction processing or database operations.
For comprehensive evaluation, benchmarking should include multiple failure scenarios: controller failures, network path disruptions, target subsystem failures, and namespace migrations. Each scenario requires specific instrumentation to capture precise timing information and correlate events across the storage stack.
Statistical analysis of collected data must account for performance variability, requiring multiple test iterations to establish confidence intervals. Results should be normalized against baseline performance to quantify the relative impact of failover events on application workloads.
Reporting frameworks should present both aggregate statistics and detailed time-series data, enabling both high-level performance assessment and granular analysis of system behavior during critical transition periods. This dual approach helps identify specific components in the failover path that may introduce latency or contribute to timeout conditions.
The primary metrics for failover performance assessment include recovery time objective (RTO), which measures the total time from failure detection to service restoration, and I/O latency impact during the transition period. These measurements must be collected at microsecond resolution to properly evaluate the effectiveness of fast path failover implementations. Additionally, throughput degradation during failover events provides critical insights into system resilience.
Benchmark methodologies should incorporate varied workload patterns that represent typical production environments, including mixed read/write operations, different I/O sizes, and varying queue depths. Testing must be conducted under both steady-state and peak load conditions to understand performance boundaries and identify potential bottlenecks during failover events.
Synthetic benchmarking tools like FIO (Flexible I/O Tester) can be configured to generate specific I/O patterns while monitoring timeout occurrences. These tools should be supplemented with application-level benchmarks that reflect real-world workloads, particularly those with strict latency requirements such as financial transaction processing or database operations.
For comprehensive evaluation, benchmarking should include multiple failure scenarios: controller failures, network path disruptions, target subsystem failures, and namespace migrations. Each scenario requires specific instrumentation to capture precise timing information and correlate events across the storage stack.
Statistical analysis of collected data must account for performance variability, requiring multiple test iterations to establish confidence intervals. Results should be normalized against baseline performance to quantify the relative impact of failover events on application workloads.
Reporting frameworks should present both aggregate statistics and detailed time-series data, enabling both high-level performance assessment and granular analysis of system behavior during critical transition periods. This dual approach helps identify specific components in the failover path that may introduce latency or contribute to timeout conditions.
Standardization Efforts in NVMe-oF Resilience
The NVMe-oF (NVMe over Fabrics) ecosystem has witnessed significant standardization efforts aimed at enhancing resilience and ensuring fast path failover without I/O timeouts. These initiatives are primarily driven by industry consortiums and standards bodies working collaboratively to establish robust frameworks for maintaining data integrity during network disruptions.
The NVM Express organization has played a pivotal role in developing specifications that address failover mechanisms. The NVMe-oF 1.1 specification introduced the Asymmetric Namespace Access (ANA) feature, which provides standardized multipathing capabilities essential for resilient storage architectures. This specification defines how storage targets can communicate path states to hosts, enabling intelligent routing decisions during path failures.
SNIA (Storage Networking Industry Association) has contributed substantially through its NVMe Technical Work Group, focusing on standardizing controller-based failover protocols. Their work includes defining consistent behavior patterns for controllers during network disruptions and establishing uniform recovery procedures that minimize or eliminate I/O timeouts.
The DMTF (Distributed Management Task Force) has complemented these efforts through its Redfish specification extensions for NVMe management, which incorporate standardized monitoring and alerting mechanisms for path health. These standards enable proactive failover before complete path failure occurs, significantly reducing the likelihood of I/O timeouts.
Industry-specific initiatives have emerged within telecommunications and financial sectors, where zero-downtime requirements are particularly stringent. The Open Compute Project (OCP) has developed reference architectures incorporating NVMe-oF resilience patterns that have been widely adopted across hyperscale environments.
Recent standardization work has focused on the Transport Disconnect event handling, with the NVMe 2.0 specification introducing more granular control over reconnection attempts and timeout behaviors. This includes standardized mechanisms for connection reestablishment that operate below application-visible timeout thresholds.
Cross-industry collaboration between fabric providers (InfiniBand Trade Association, Fibre Channel Industry Association, and Ethernet technology groups) and the NVMe community has resulted in transport-specific resilience extensions that maintain consistency across different fabric types while leveraging unique capabilities of each transport technology.
These standardization efforts collectively establish a comprehensive framework for NVMe-oF implementations to achieve fast path failover without exposing I/O timeouts to applications, ensuring that storage remains highly available even in dynamic network environments with potential path disruptions.
The NVM Express organization has played a pivotal role in developing specifications that address failover mechanisms. The NVMe-oF 1.1 specification introduced the Asymmetric Namespace Access (ANA) feature, which provides standardized multipathing capabilities essential for resilient storage architectures. This specification defines how storage targets can communicate path states to hosts, enabling intelligent routing decisions during path failures.
SNIA (Storage Networking Industry Association) has contributed substantially through its NVMe Technical Work Group, focusing on standardizing controller-based failover protocols. Their work includes defining consistent behavior patterns for controllers during network disruptions and establishing uniform recovery procedures that minimize or eliminate I/O timeouts.
The DMTF (Distributed Management Task Force) has complemented these efforts through its Redfish specification extensions for NVMe management, which incorporate standardized monitoring and alerting mechanisms for path health. These standards enable proactive failover before complete path failure occurs, significantly reducing the likelihood of I/O timeouts.
Industry-specific initiatives have emerged within telecommunications and financial sectors, where zero-downtime requirements are particularly stringent. The Open Compute Project (OCP) has developed reference architectures incorporating NVMe-oF resilience patterns that have been widely adopted across hyperscale environments.
Recent standardization work has focused on the Transport Disconnect event handling, with the NVMe 2.0 specification introducing more granular control over reconnection attempts and timeout behaviors. This includes standardized mechanisms for connection reestablishment that operate below application-visible timeout thresholds.
Cross-industry collaboration between fabric providers (InfiniBand Trade Association, Fibre Channel Industry Association, and Ethernet technology groups) and the NVMe community has resulted in transport-specific resilience extensions that maintain consistency across different fabric types while leveraging unique capabilities of each transport technology.
These standardization efforts collectively establish a comprehensive framework for NVMe-oF implementations to achieve fast path failover without exposing I/O timeouts to applications, ensuring that storage remains highly available even in dynamic network environments with potential path disruptions.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!