NVMe-oF Transport Selection: RDMA, RoCE And TCP Latency Budgets
SEP 19, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
NVMe-oF Evolution and Objectives
NVMe over Fabrics (NVMe-oF) has emerged as a transformative technology in the storage industry, extending the high-performance capabilities of NVMe beyond direct-attached storage to networked environments. The evolution of NVMe-oF began in 2014 when the NVM Express organization initiated work on the specification, with the first official release in 2016 supporting RDMA transports. This marked a significant milestone in storage networking, enabling near-local performance for remote storage access.
The initial NVMe-oF specification focused primarily on RDMA-based transports, leveraging the low-latency characteristics of InfiniBand and RoCE (RDMA over Converged Ethernet). These transports offered substantial performance benefits by bypassing traditional networking stacks and enabling direct memory access between systems, significantly reducing CPU overhead and latency.
A pivotal development occurred in 2018 with the introduction of TCP transport support in NVMe-oF 1.1. This expansion democratized NVMe-oF adoption by enabling implementation over standard Ethernet networks without specialized hardware requirements, albeit with some performance trade-offs compared to RDMA-based solutions.
The technology has continued to evolve with subsequent releases addressing scalability, management, and security concerns. NVMe-oF 2.0, released in 2020, introduced enhanced discovery mechanisms, improved error handling, and better support for diverse deployment scenarios, from hyperscale data centers to edge computing environments.
The primary objective of NVMe-oF has consistently been to minimize the performance gap between local and remote storage access. This involves reducing latency overhead, maximizing throughput, and ensuring efficient resource utilization across different transport options. The technology aims to deliver microsecond-level latencies, approaching those of direct-attached NVMe devices, while maintaining the flexibility and scalability benefits of networked storage.
Current development efforts focus on optimizing transport selection mechanisms to match specific workload requirements with appropriate transport characteristics. This includes balancing the ultra-low latency of RDMA transports against the broader compatibility of TCP transport, with consideration for deployment constraints such as network infrastructure, distance limitations, and cost factors.
The long-term vision for NVMe-oF encompasses seamless integration with emerging technologies such as computational storage, persistent memory, and disaggregated infrastructure models. These advancements aim to further reduce the performance penalties of networked storage while enabling more flexible and efficient resource utilization in modern data centers.
The initial NVMe-oF specification focused primarily on RDMA-based transports, leveraging the low-latency characteristics of InfiniBand and RoCE (RDMA over Converged Ethernet). These transports offered substantial performance benefits by bypassing traditional networking stacks and enabling direct memory access between systems, significantly reducing CPU overhead and latency.
A pivotal development occurred in 2018 with the introduction of TCP transport support in NVMe-oF 1.1. This expansion democratized NVMe-oF adoption by enabling implementation over standard Ethernet networks without specialized hardware requirements, albeit with some performance trade-offs compared to RDMA-based solutions.
The technology has continued to evolve with subsequent releases addressing scalability, management, and security concerns. NVMe-oF 2.0, released in 2020, introduced enhanced discovery mechanisms, improved error handling, and better support for diverse deployment scenarios, from hyperscale data centers to edge computing environments.
The primary objective of NVMe-oF has consistently been to minimize the performance gap between local and remote storage access. This involves reducing latency overhead, maximizing throughput, and ensuring efficient resource utilization across different transport options. The technology aims to deliver microsecond-level latencies, approaching those of direct-attached NVMe devices, while maintaining the flexibility and scalability benefits of networked storage.
Current development efforts focus on optimizing transport selection mechanisms to match specific workload requirements with appropriate transport characteristics. This includes balancing the ultra-low latency of RDMA transports against the broader compatibility of TCP transport, with consideration for deployment constraints such as network infrastructure, distance limitations, and cost factors.
The long-term vision for NVMe-oF encompasses seamless integration with emerging technologies such as computational storage, persistent memory, and disaggregated infrastructure models. These advancements aim to further reduce the performance penalties of networked storage while enabling more flexible and efficient resource utilization in modern data centers.
Market Demand for High-Performance Storage Networks
The demand for high-performance storage networks has experienced exponential growth in recent years, driven primarily by data-intensive applications such as artificial intelligence, machine learning, big data analytics, and high-performance computing. These applications require not only massive storage capacity but also ultra-low latency and high throughput for data access, creating a substantial market need for advanced storage networking technologies like NVMe over Fabrics (NVMe-oF).
Enterprise data centers are rapidly transitioning from traditional storage architectures to disaggregated models where storage resources can be pooled and accessed over high-speed networks. According to market research, the global NVMe market is projected to grow at a CAGR of 29% through 2025, with the NVMe-oF segment showing even stronger growth rates due to its performance advantages.
Financial services organizations represent one of the largest market segments demanding high-performance storage networks. These institutions require microsecond-level latency for high-frequency trading platforms, risk analysis, and fraud detection systems. Even millisecond delays can translate to significant financial losses in these environments, making transport protocol selection critical.
Healthcare and life sciences organizations form another significant market segment, particularly with the rise of genomic sequencing, medical imaging, and personalized medicine. These applications generate petabytes of data that must be processed and analyzed quickly, creating demand for storage networks that can deliver both capacity and performance.
Cloud service providers constitute perhaps the most influential market segment driving innovation in storage networking. As they scale their infrastructure to support millions of customers, they require storage solutions that can deliver consistent performance while maximizing resource utilization and minimizing operational costs. This has led to increased interest in NVMe-oF with TCP transport, which offers a balance of performance and deployment simplicity.
Edge computing represents an emerging market for high-performance storage networks. As more data is generated and processed at the edge, there's growing demand for storage solutions that can deliver datacenter-like performance in distributed environments with varying network characteristics. This is driving interest in flexible transport options that can adapt to different deployment scenarios.
The market is increasingly segmented between performance-critical applications that demand the absolute lowest latency (favoring RDMA-based transports) and cost-sensitive deployments that prioritize operational simplicity and infrastructure compatibility (favoring TCP-based transports). This bifurcation is reshaping vendor strategies and product roadmaps across the storage industry.
Enterprise data centers are rapidly transitioning from traditional storage architectures to disaggregated models where storage resources can be pooled and accessed over high-speed networks. According to market research, the global NVMe market is projected to grow at a CAGR of 29% through 2025, with the NVMe-oF segment showing even stronger growth rates due to its performance advantages.
Financial services organizations represent one of the largest market segments demanding high-performance storage networks. These institutions require microsecond-level latency for high-frequency trading platforms, risk analysis, and fraud detection systems. Even millisecond delays can translate to significant financial losses in these environments, making transport protocol selection critical.
Healthcare and life sciences organizations form another significant market segment, particularly with the rise of genomic sequencing, medical imaging, and personalized medicine. These applications generate petabytes of data that must be processed and analyzed quickly, creating demand for storage networks that can deliver both capacity and performance.
Cloud service providers constitute perhaps the most influential market segment driving innovation in storage networking. As they scale their infrastructure to support millions of customers, they require storage solutions that can deliver consistent performance while maximizing resource utilization and minimizing operational costs. This has led to increased interest in NVMe-oF with TCP transport, which offers a balance of performance and deployment simplicity.
Edge computing represents an emerging market for high-performance storage networks. As more data is generated and processed at the edge, there's growing demand for storage solutions that can deliver datacenter-like performance in distributed environments with varying network characteristics. This is driving interest in flexible transport options that can adapt to different deployment scenarios.
The market is increasingly segmented between performance-critical applications that demand the absolute lowest latency (favoring RDMA-based transports) and cost-sensitive deployments that prioritize operational simplicity and infrastructure compatibility (favoring TCP-based transports). This bifurcation is reshaping vendor strategies and product roadmaps across the storage industry.
Current Transport Protocols and Technical Challenges
NVMe-oF currently supports multiple transport protocols, each with distinct characteristics and performance implications. RDMA (Remote Direct Memory Access) represents the original high-performance transport for NVMe-oF, offering extremely low latency by bypassing the operating system's networking stack and enabling direct memory access between systems. This protocol minimizes CPU overhead and delivers consistent performance with latencies typically under 10 microseconds in optimized environments.
RoCE (RDMA over Converged Ethernet) has emerged as a popular implementation that brings RDMA capabilities to standard Ethernet networks. RoCE v1 operates directly over Ethernet, while RoCE v2 runs over UDP/IP, providing greater routing flexibility. RoCE implementations can achieve latencies approaching native RDMA performance (15-30 microseconds) but require specialized network configurations including Priority Flow Control (PFC) and Explicit Congestion Notification (ECN) to maintain reliability.
TCP-based NVMe-oF transport, introduced in NVMe 1.4 specification, represents a significant advancement in accessibility. While exhibiting higher latencies (typically 50-100 microseconds) compared to RDMA-based options, TCP transport eliminates the need for specialized hardware and complex network configurations, substantially reducing implementation barriers and deployment costs.
The primary technical challenges across these transport protocols center around several critical factors. Latency consistency presents a significant challenge, particularly in congested networks where performance can degrade unpredictably. RDMA and RoCE are especially sensitive to network congestion, potentially experiencing dramatic performance drops without proper configuration.
Scalability remains another major hurdle, as many RDMA implementations face connection scaling limitations. Traditional RDMA requires maintaining connection state for each client-target pair, potentially overwhelming memory resources in large-scale deployments with thousands of connections.
Interoperability issues persist across vendor implementations, particularly with RoCE deployments where subtle differences in congestion management approaches can lead to compatibility problems. Additionally, security considerations vary significantly between transports, with TCP offering mature security mechanisms while RDMA-based protocols often require additional security layers.
Network infrastructure compatibility presents another challenge, as RDMA and RoCE typically require specialized network hardware and configurations that may not be universally available in existing data centers. This limitation often necessitates significant infrastructure investments when implementing these high-performance transports.
RoCE (RDMA over Converged Ethernet) has emerged as a popular implementation that brings RDMA capabilities to standard Ethernet networks. RoCE v1 operates directly over Ethernet, while RoCE v2 runs over UDP/IP, providing greater routing flexibility. RoCE implementations can achieve latencies approaching native RDMA performance (15-30 microseconds) but require specialized network configurations including Priority Flow Control (PFC) and Explicit Congestion Notification (ECN) to maintain reliability.
TCP-based NVMe-oF transport, introduced in NVMe 1.4 specification, represents a significant advancement in accessibility. While exhibiting higher latencies (typically 50-100 microseconds) compared to RDMA-based options, TCP transport eliminates the need for specialized hardware and complex network configurations, substantially reducing implementation barriers and deployment costs.
The primary technical challenges across these transport protocols center around several critical factors. Latency consistency presents a significant challenge, particularly in congested networks where performance can degrade unpredictably. RDMA and RoCE are especially sensitive to network congestion, potentially experiencing dramatic performance drops without proper configuration.
Scalability remains another major hurdle, as many RDMA implementations face connection scaling limitations. Traditional RDMA requires maintaining connection state for each client-target pair, potentially overwhelming memory resources in large-scale deployments with thousands of connections.
Interoperability issues persist across vendor implementations, particularly with RoCE deployments where subtle differences in congestion management approaches can lead to compatibility problems. Additionally, security considerations vary significantly between transports, with TCP offering mature security mechanisms while RDMA-based protocols often require additional security layers.
Network infrastructure compatibility presents another challenge, as RDMA and RoCE typically require specialized network hardware and configurations that may not be universally available in existing data centers. This limitation often necessitates significant infrastructure investments when implementing these high-performance transports.
Comparative Analysis of RDMA, RoCE, and TCP Implementations
01 RDMA-based transport protocols for NVMe-oF
Remote Direct Memory Access (RDMA) transport protocols like RoCE (RDMA over Converged Ethernet) and iWARP provide low-latency data transfer for NVMe over Fabrics by enabling direct memory access between hosts and storage devices without CPU involvement. These protocols significantly reduce communication overhead and latency by bypassing traditional networking stacks, making them ideal for high-performance storage applications requiring minimal latency.- Transport protocol comparison for NVMe-oF latency: Different transport protocols for NVMe over Fabrics (NVMe-oF) exhibit varying latency characteristics. RDMA-based protocols like RoCE and iWARP generally provide lower latency compared to TCP/IP-based implementations. The choice of transport protocol significantly impacts overall system performance, with some protocols offering sub-microsecond latency for storage operations while others trade latency for broader compatibility or simplified deployment.
- Latency optimization techniques in NVMe-oF systems: Various optimization techniques can be employed to reduce latency in NVMe-oF deployments. These include queue depth management, interrupt coalescing adjustments, and optimized driver implementations. Advanced techniques like direct memory access (DMA) offloading, zero-copy data transfers, and hardware acceleration can further minimize protocol processing overhead, resulting in improved end-to-end latency for storage operations across fabric networks.
- Fabric infrastructure impact on NVMe-oF latency: The underlying fabric infrastructure significantly affects NVMe-oF latency performance. Network topology, switch architecture, and link speeds all contribute to the overall latency profile. Congestion management, quality of service implementations, and buffer management within the fabric infrastructure play crucial roles in maintaining consistent low-latency performance, especially in multi-tenant environments or under heavy load conditions.
- Latency monitoring and analysis in NVMe-oF systems: Effective monitoring and analysis of latency in NVMe-oF deployments is essential for optimizing performance. Advanced telemetry systems can track latency across different components of the storage stack, from application to storage device. Machine learning algorithms can be employed to detect anomalies and predict performance degradation. Real-time latency monitoring enables dynamic adjustments to maintain service level objectives in enterprise storage environments.
- End-to-end latency considerations in NVMe-oF architectures: End-to-end latency in NVMe-oF systems encompasses multiple components beyond just the transport protocol. Host software stack, controller processing, fabric traversal, and target device performance all contribute to the overall latency experienced by applications. Architectural decisions such as disaggregation level, composability features, and storage tiering strategies must be carefully considered to achieve optimal latency while maintaining other system requirements like scalability, reliability, and cost-effectiveness.
02 TCP/IP transport protocol optimization for NVMe-oF
TCP/IP transport for NVMe-oF provides widespread compatibility across existing network infrastructures but typically introduces higher latency compared to RDMA protocols. Various optimization techniques can be implemented to reduce this latency, including TCP offload engines, optimized congestion control algorithms, and specialized packet processing to minimize protocol overhead while maintaining reliability for storage traffic across standard IP networks.Expand Specific Solutions03 Fabric switching architectures for NVMe-oF latency reduction
Specialized fabric switching architectures can significantly reduce latency in NVMe-oF deployments. These architectures include optimized routing algorithms, quality of service mechanisms, and traffic prioritization specifically designed for storage workloads. Advanced switching fabrics can provide deterministic latency, reduced congestion, and improved load balancing across multiple paths, ensuring consistent performance for NVMe storage traffic even under heavy network utilization.Expand Specific Solutions04 Protocol translation and gateway solutions for NVMe-oF
Protocol translation gateways enable NVMe-oF to operate across heterogeneous network environments while minimizing added latency. These solutions provide seamless conversion between different transport protocols (such as RDMA to TCP/IP) and can incorporate hardware acceleration to maintain low latency. Gateway architectures often include specialized buffering mechanisms, optimized protocol state machines, and intelligent routing to ensure efficient data transfer across diverse network infrastructures.Expand Specific Solutions05 End-to-end latency monitoring and optimization for NVMe-oF
Comprehensive latency monitoring and optimization systems for NVMe-oF environments provide real-time visibility into performance bottlenecks across the entire data path. These solutions incorporate telemetry collection, analytics, and automated tuning mechanisms to identify and address latency issues. Advanced implementations may include machine learning algorithms to predict performance degradation, dynamic path selection, and adaptive protocol parameter tuning to maintain optimal latency under changing workload conditions.Expand Specific Solutions
Key Industry Players and Ecosystem Analysis
The NVMe-oF transport selection market is currently in a growth phase, with increasing adoption across enterprise storage environments. The market size is expanding rapidly as organizations seek lower latency storage networking solutions, projected to reach significant scale by 2025. From a technical maturity perspective, RDMA implementations lead with the lowest latency profiles, followed by RoCE, while TCP-based transports offer broader compatibility at slightly higher latency costs. Key players shaping this competitive landscape include Mellanox Technologies (pioneering RDMA solutions), Cisco and Dell (offering comprehensive networking portfolios), Western Digital and Huawei (integrating NVMe-oF into storage platforms), while Oracle, Alibaba, and Inspur are advancing enterprise implementations. Cloud providers like Kingsoft Cloud are driving adoption through managed service offerings, with specialized networking companies like H3C and Vastai Technologies developing optimized transport solutions.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed an integrated NVMe-oF solution across their storage and networking portfolio with particular emphasis on optimizing transport selection for different deployment scenarios. Their approach includes intelligent transport selection algorithms that dynamically choose between RDMA, RoCE, and TCP based on network conditions and application requirements. For RoCE implementations, Huawei's technology incorporates advanced Priority Flow Control (PFC) and Explicit Congestion Notification (ECN) mechanisms that maintain consistent latency even under heavy network loads. Their TCP transport implementation features custom congestion control algorithms that reduce average latency by up to 25% compared to standard implementations. Huawei's storage systems leverage these transport optimizations to deliver end-to-end latency improvements across their distributed storage platforms.
Strengths: Comprehensive end-to-end solution from storage to networking; strong optimization for datacenter-scale deployments; advanced congestion management for RoCE. Weaknesses: Less third-party ecosystem integration compared to some competitors; some advanced features limited to all-Huawei environments; higher implementation complexity.
Cisco Technology, Inc.
Technical Solution: Cisco has developed an architectural approach to NVMe-oF transport selection that leverages their networking expertise across data center environments. Their solution centers on the Nexus switching platform with specialized hardware offloads for both RoCE and TCP transports. For RoCE implementations, Cisco has developed enhanced Priority Flow Control (PFC) mechanisms with per-priority pause frames that reduce head-of-line blocking by up to 60% in congested networks. Their TCP transport optimization includes intelligent load balancing algorithms that distribute NVMe traffic across multiple network paths to maintain consistent latency. Cisco's Application Centric Infrastructure (ACI) provides policy-based transport selection that can automatically choose optimal protocols based on application requirements, network topology, and current utilization patterns.
Strengths: Exceptional network infrastructure integration; strong policy-based management capabilities; mature ecosystem for enterprise deployments. Weaknesses: Storage-side integration less developed than networking components; requires significant infrastructure investment for full benefits; complex configuration for optimal performance tuning.
Critical Latency Budget Optimization Techniques
Devices and methods for network message sequencing
PatentWO2022039834A1
Innovation
- Implementing programmable switches as in-network message sequencers that use topology-aware routing and buffering servers to reorder and retrieve missing messages, reducing out-of-order packets and eliminating the need for expensive DCB switches, thereby improving message sequencing and scalability.
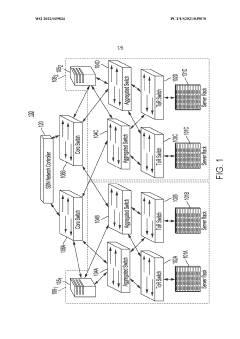
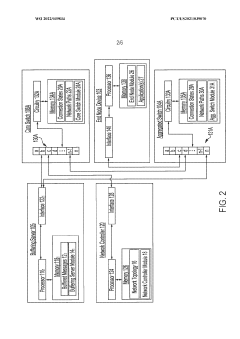
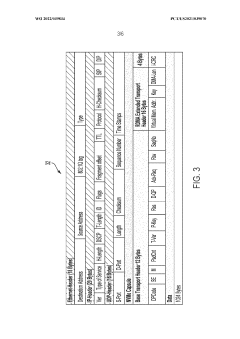
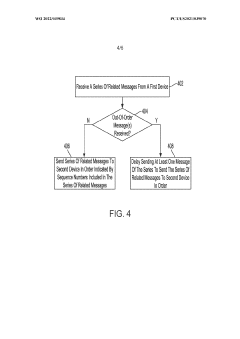
Remote direct memory access (RDMA) multipath
PatentActiveUS11909628B1
Innovation
- Implementing a multipath context that allows hardware to send packets with multiple routing parameters without software intervention, enabling the spreading of traffic across multiple routes transparently and monitoring congestion to optimize network utilization and provide fast recovery mechanisms.
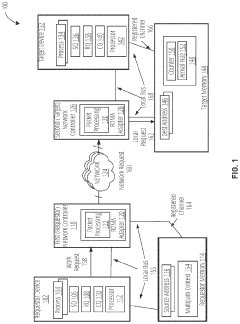
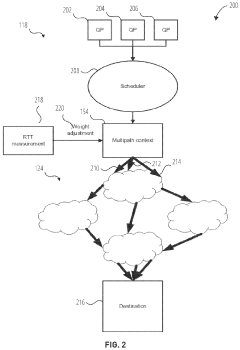
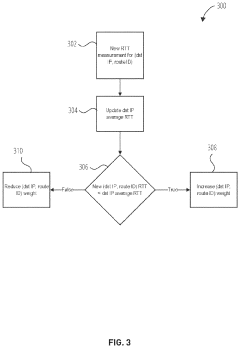

Performance Benchmarking Methodologies
To effectively evaluate NVMe-oF transport protocols, standardized performance benchmarking methodologies are essential. These methodologies must isolate the specific characteristics of RDMA, RoCE, and TCP implementations while maintaining consistency across test environments.
Benchmark design should incorporate both synthetic workloads and application-specific testing. Synthetic workloads focus on fundamental metrics like IOPS, throughput, and latency under controlled conditions, while application-specific tests evaluate real-world performance with actual workloads such as databases, virtualization platforms, and AI training frameworks.
The testing environment requires careful configuration of hardware parameters including network interface cards, switches, cables, and server specifications. Software configurations must standardize operating system settings, driver versions, and firmware revisions to ensure reproducible results. Particular attention should be paid to network stack tuning parameters which significantly impact transport protocol performance.
Measurement methodologies should capture comprehensive metrics beyond basic performance indicators. These include CPU utilization, memory bandwidth consumption, PCIe traffic patterns, and power efficiency. Latency measurements must be granular enough to identify specific bottlenecks within the protocol stack, with separate accounting for initiator processing, network transit time, and target processing delays.
Statistical rigor is paramount in benchmarking NVMe-oF transports. Tests should employ multiple iterations with appropriate warm-up periods to eliminate caching effects. Results should include not only average performance but also percentile distributions (particularly 99th and 99.9th percentiles) to characterize tail latency behavior which is critical for latency-sensitive applications.
Scalability testing represents another crucial dimension, evaluating how each transport protocol performs under increasing load conditions. This includes scaling the number of concurrent connections, queue depths, and I/O sizes to identify performance inflection points and maximum sustainable throughput before degradation occurs.
Cross-protocol comparative analysis requires normalizing results across different transport implementations. This involves establishing baseline performance metrics and calculating relative performance ratios rather than focusing solely on absolute numbers, which can be misleading due to implementation-specific optimizations.
AI-assisted benchmarking tools are emerging as valuable assets for identifying complex performance patterns and correlations between configuration parameters and observed results, enabling more sophisticated optimization of NVMe-oF deployments across different transport options.
Benchmark design should incorporate both synthetic workloads and application-specific testing. Synthetic workloads focus on fundamental metrics like IOPS, throughput, and latency under controlled conditions, while application-specific tests evaluate real-world performance with actual workloads such as databases, virtualization platforms, and AI training frameworks.
The testing environment requires careful configuration of hardware parameters including network interface cards, switches, cables, and server specifications. Software configurations must standardize operating system settings, driver versions, and firmware revisions to ensure reproducible results. Particular attention should be paid to network stack tuning parameters which significantly impact transport protocol performance.
Measurement methodologies should capture comprehensive metrics beyond basic performance indicators. These include CPU utilization, memory bandwidth consumption, PCIe traffic patterns, and power efficiency. Latency measurements must be granular enough to identify specific bottlenecks within the protocol stack, with separate accounting for initiator processing, network transit time, and target processing delays.
Statistical rigor is paramount in benchmarking NVMe-oF transports. Tests should employ multiple iterations with appropriate warm-up periods to eliminate caching effects. Results should include not only average performance but also percentile distributions (particularly 99th and 99.9th percentiles) to characterize tail latency behavior which is critical for latency-sensitive applications.
Scalability testing represents another crucial dimension, evaluating how each transport protocol performs under increasing load conditions. This includes scaling the number of concurrent connections, queue depths, and I/O sizes to identify performance inflection points and maximum sustainable throughput before degradation occurs.
Cross-protocol comparative analysis requires normalizing results across different transport implementations. This involves establishing baseline performance metrics and calculating relative performance ratios rather than focusing solely on absolute numbers, which can be misleading due to implementation-specific optimizations.
AI-assisted benchmarking tools are emerging as valuable assets for identifying complex performance patterns and correlations between configuration parameters and observed results, enabling more sophisticated optimization of NVMe-oF deployments across different transport options.
Datacenter Infrastructure Requirements and Considerations
The implementation of NVMe-oF in datacenter environments requires careful consideration of infrastructure requirements to ensure optimal performance, scalability, and reliability. Modern datacenters deploying NVMe-oF solutions must address several critical infrastructure considerations regardless of the chosen transport protocol.
Network infrastructure forms the foundation of any NVMe-oF deployment. For RDMA-based transports (RoCE, InfiniBand), the network must support lossless operation through Priority Flow Control (PFC) and Explicit Congestion Notification (ECN). This necessitates datacenter-grade switches with advanced Quality of Service (QoS) capabilities and sufficient buffer capacity to handle microbursts of traffic.
Power and cooling systems must be dimensioned appropriately to support the increased computational density that NVMe-oF enables. The consolidation of storage resources often leads to higher power consumption in specific racks, requiring targeted cooling solutions and potentially higher power delivery capabilities per rack unit.
Physical space planning becomes crucial as organizations transition to disaggregated storage architectures. NVMe-oF allows for the separation of compute and storage resources, which may necessitate redesigning datacenter layouts to optimize for reduced latency between these components while maintaining flexibility for future scaling.
Cable management represents another significant consideration, particularly for high-density deployments. The choice between copper and optical interconnects impacts not only performance and distance capabilities but also affects airflow management and overall datacenter design. Structured cabling systems that support future growth without requiring major reconfiguration are essential.
Redundancy and fault tolerance must be built into the infrastructure at multiple levels. This includes redundant network paths, power supplies, and cooling systems. The network topology should eliminate single points of failure while maintaining the low-latency characteristics required for NVMe-oF performance.
Management infrastructure must support comprehensive monitoring of both storage and network components. Integration with existing datacenter management systems is critical for operational efficiency, requiring compatible APIs and protocols across the infrastructure stack.
Scalability considerations should address both horizontal (adding more nodes) and vertical (increasing capacity of existing nodes) scaling approaches. The infrastructure must accommodate growth without requiring forklift upgrades or introducing performance bottlenecks as the deployment expands.
Network infrastructure forms the foundation of any NVMe-oF deployment. For RDMA-based transports (RoCE, InfiniBand), the network must support lossless operation through Priority Flow Control (PFC) and Explicit Congestion Notification (ECN). This necessitates datacenter-grade switches with advanced Quality of Service (QoS) capabilities and sufficient buffer capacity to handle microbursts of traffic.
Power and cooling systems must be dimensioned appropriately to support the increased computational density that NVMe-oF enables. The consolidation of storage resources often leads to higher power consumption in specific racks, requiring targeted cooling solutions and potentially higher power delivery capabilities per rack unit.
Physical space planning becomes crucial as organizations transition to disaggregated storage architectures. NVMe-oF allows for the separation of compute and storage resources, which may necessitate redesigning datacenter layouts to optimize for reduced latency between these components while maintaining flexibility for future scaling.
Cable management represents another significant consideration, particularly for high-density deployments. The choice between copper and optical interconnects impacts not only performance and distance capabilities but also affects airflow management and overall datacenter design. Structured cabling systems that support future growth without requiring major reconfiguration are essential.
Redundancy and fault tolerance must be built into the infrastructure at multiple levels. This includes redundant network paths, power supplies, and cooling systems. The network topology should eliminate single points of failure while maintaining the low-latency characteristics required for NVMe-oF performance.
Management infrastructure must support comprehensive monitoring of both storage and network components. Integration with existing datacenter management systems is critical for operational efficiency, requiring compatible APIs and protocols across the infrastructure stack.
Scalability considerations should address both horizontal (adding more nodes) and vertical (increasing capacity of existing nodes) scaling approaches. The infrastructure must accommodate growth without requiring forklift upgrades or introducing performance bottlenecks as the deployment expands.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!