NVMe-oF In Kubernetes: CSI Integration, Node Affinity And Failure Domains
SEP 19, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
NVMe-oF Evolution and Integration Goals
NVMe over Fabrics (NVMe-oF) technology has evolved significantly since its introduction in 2016, transforming from a specialized storage protocol to a mainstream solution for disaggregated storage architectures. The initial NVMe specification focused on local PCIe-attached storage, but the industry quickly recognized the need to extend these benefits across network fabrics. This evolution was driven by the growing demand for high-performance, low-latency storage access in distributed computing environments.
The development trajectory of NVMe-oF has been marked by several key milestones. The first specification release supported RDMA transports (RoCE, iWARP, InfiniBand), followed by the addition of Fibre Channel transport in 2017, and TCP transport in 2018. Each iteration has expanded compatibility while maintaining the protocol's core benefits of reduced latency and increased throughput compared to traditional storage protocols like iSCSI or Fibre Channel.
In parallel with protocol development, the storage industry has been working toward seamless integration of NVMe-oF with container orchestration platforms, particularly Kubernetes. This integration represents a critical convergence of two transformative technologies in modern data centers: containerization and high-performance networked storage.
The primary integration goals for NVMe-oF in Kubernetes environments center around several key objectives. First, achieving transparent access to remote NVMe storage resources from containerized applications, making networked storage appear as local devices. Second, maintaining the performance advantages of NVMe while operating in distributed environments, ensuring minimal overhead from the network and orchestration layers.
Third, enabling dynamic provisioning and lifecycle management of NVMe-oF volumes through standardized interfaces like the Container Storage Interface (CSI). Fourth, implementing intelligent data placement strategies through node affinity rules to optimize performance and reliability. Finally, establishing robust failure domain awareness to maintain storage availability despite infrastructure failures.
These integration goals align with broader industry trends toward software-defined infrastructure, where storage resources are abstracted, pooled, and programmatically managed. The ultimate vision is to create a storage fabric that combines the performance of local NVMe with the flexibility and scalability of networked storage, all seamlessly orchestrated within Kubernetes environments.
As enterprises increasingly adopt containerized applications for production workloads, the demand for enterprise-grade storage features in these environments continues to grow. The integration of NVMe-oF with Kubernetes represents a response to this demand, aiming to bring the full capabilities of modern storage architectures to cloud-native applications.
The development trajectory of NVMe-oF has been marked by several key milestones. The first specification release supported RDMA transports (RoCE, iWARP, InfiniBand), followed by the addition of Fibre Channel transport in 2017, and TCP transport in 2018. Each iteration has expanded compatibility while maintaining the protocol's core benefits of reduced latency and increased throughput compared to traditional storage protocols like iSCSI or Fibre Channel.
In parallel with protocol development, the storage industry has been working toward seamless integration of NVMe-oF with container orchestration platforms, particularly Kubernetes. This integration represents a critical convergence of two transformative technologies in modern data centers: containerization and high-performance networked storage.
The primary integration goals for NVMe-oF in Kubernetes environments center around several key objectives. First, achieving transparent access to remote NVMe storage resources from containerized applications, making networked storage appear as local devices. Second, maintaining the performance advantages of NVMe while operating in distributed environments, ensuring minimal overhead from the network and orchestration layers.
Third, enabling dynamic provisioning and lifecycle management of NVMe-oF volumes through standardized interfaces like the Container Storage Interface (CSI). Fourth, implementing intelligent data placement strategies through node affinity rules to optimize performance and reliability. Finally, establishing robust failure domain awareness to maintain storage availability despite infrastructure failures.
These integration goals align with broader industry trends toward software-defined infrastructure, where storage resources are abstracted, pooled, and programmatically managed. The ultimate vision is to create a storage fabric that combines the performance of local NVMe with the flexibility and scalability of networked storage, all seamlessly orchestrated within Kubernetes environments.
As enterprises increasingly adopt containerized applications for production workloads, the demand for enterprise-grade storage features in these environments continues to grow. The integration of NVMe-oF with Kubernetes represents a response to this demand, aiming to bring the full capabilities of modern storage architectures to cloud-native applications.
Market Demand for Kubernetes Storage Solutions
The demand for advanced storage solutions in Kubernetes environments has experienced significant growth as organizations increasingly adopt containerized applications and microservices architectures. This market expansion is driven by the need for persistent storage that can match the agility and scalability of containerized workloads while maintaining enterprise-grade performance and reliability.
Enterprise customers are specifically seeking storage solutions that can handle stateful applications with high-performance requirements. Traditional storage approaches often create bottlenecks when deployed with Kubernetes, leading to a strong market pull for NVMe-based solutions that can deliver the necessary throughput and latency characteristics. According to industry research, the cloud-native storage market is projected to grow at a compound annual growth rate of 24% through 2026.
The integration of NVMe-oF (NVMe over Fabrics) technology with Kubernetes represents a response to this demand, as it enables disaggregated storage architectures while maintaining near-local storage performance. Organizations running data-intensive workloads such as databases, AI/ML training, and real-time analytics are particularly interested in these capabilities, creating a premium segment within the broader Kubernetes storage market.
Container Storage Interface (CSI) has become the standard method for integrating storage systems with Kubernetes, with adoption rates exceeding 85% among enterprise Kubernetes deployments. The market increasingly demands CSI drivers that can fully leverage NVMe-oF capabilities while providing seamless integration with Kubernetes' native scheduling and resilience features.
Failure domain awareness and intelligent data placement through node affinity rules have emerged as critical requirements, particularly for enterprises operating multi-zone or multi-region Kubernetes clusters. These capabilities ensure that storage resources are allocated optimally across the infrastructure to maintain both performance and availability.
Financial services, telecommunications, and media/entertainment verticals show the strongest demand for high-performance Kubernetes storage solutions, with healthcare and retail sectors following closely as they accelerate their digital transformation initiatives. These industries typically require storage solutions that can handle mixed workloads with varying performance profiles while maintaining strict data protection and availability requirements.
The market also shows increasing demand for storage solutions that can span hybrid and multi-cloud environments, reflecting the reality that most enterprises operate Kubernetes across diverse infrastructure footprints. This has created opportunities for storage vendors who can provide consistent experiences across on-premises data centers, edge locations, and multiple public clouds.
Enterprise customers are specifically seeking storage solutions that can handle stateful applications with high-performance requirements. Traditional storage approaches often create bottlenecks when deployed with Kubernetes, leading to a strong market pull for NVMe-based solutions that can deliver the necessary throughput and latency characteristics. According to industry research, the cloud-native storage market is projected to grow at a compound annual growth rate of 24% through 2026.
The integration of NVMe-oF (NVMe over Fabrics) technology with Kubernetes represents a response to this demand, as it enables disaggregated storage architectures while maintaining near-local storage performance. Organizations running data-intensive workloads such as databases, AI/ML training, and real-time analytics are particularly interested in these capabilities, creating a premium segment within the broader Kubernetes storage market.
Container Storage Interface (CSI) has become the standard method for integrating storage systems with Kubernetes, with adoption rates exceeding 85% among enterprise Kubernetes deployments. The market increasingly demands CSI drivers that can fully leverage NVMe-oF capabilities while providing seamless integration with Kubernetes' native scheduling and resilience features.
Failure domain awareness and intelligent data placement through node affinity rules have emerged as critical requirements, particularly for enterprises operating multi-zone or multi-region Kubernetes clusters. These capabilities ensure that storage resources are allocated optimally across the infrastructure to maintain both performance and availability.
Financial services, telecommunications, and media/entertainment verticals show the strongest demand for high-performance Kubernetes storage solutions, with healthcare and retail sectors following closely as they accelerate their digital transformation initiatives. These industries typically require storage solutions that can handle mixed workloads with varying performance profiles while maintaining strict data protection and availability requirements.
The market also shows increasing demand for storage solutions that can span hybrid and multi-cloud environments, reflecting the reality that most enterprises operate Kubernetes across diverse infrastructure footprints. This has created opportunities for storage vendors who can provide consistent experiences across on-premises data centers, edge locations, and multiple public clouds.
NVMe-oF in K8s: Technical Challenges
Implementing NVMe-oF (NVMe over Fabrics) in Kubernetes environments presents several significant technical challenges that must be addressed for successful deployment. The integration complexity begins with the fundamental architectural differences between traditional storage systems and the distributed nature of Kubernetes orchestration.
The Container Storage Interface (CSI) integration for NVMe-oF requires careful consideration of the underlying transport protocols. While NVMe-oF supports multiple transports including RDMA, TCP, and Fibre Channel, each protocol introduces unique implementation challenges within Kubernetes. The TCP transport offers wider compatibility but may not deliver the performance benefits that make NVMe-oF attractive, while RDMA requires specialized hardware and driver support that may not be universally available across all nodes in a cluster.
Performance overhead becomes evident when implementing the CSI translation layer between Kubernetes volume abstractions and NVMe-oF commands. This translation process can introduce latency that partially negates the ultra-low latency benefits that NVMe-oF technology promises, particularly in high-throughput workloads where microseconds matter.
Node affinity configuration presents another layer of complexity. Ensuring that pods are scheduled on nodes with appropriate NVMe-oF connectivity requires sophisticated topology awareness. The CSI driver must accurately report node capabilities and maintain this information as cluster topology changes, which becomes increasingly difficult in dynamic environments with frequent scaling operations.
Failure domain management represents perhaps the most critical challenge. NVMe-oF connections must be properly monitored and managed to ensure rapid detection of transport failures. Unlike traditional storage protocols, NVMe-oF has different timeout and recovery mechanisms that must be properly integrated with Kubernetes' own failure detection systems to prevent split-brain scenarios or data corruption during network partitions.
Authentication and security implementations add further complexity. While NVMe-oF supports various authentication methods, integrating these securely within Kubernetes' secrets management framework requires careful design to avoid exposing credentials while maintaining performance.
Resource management also presents challenges as NVMe controllers and namespaces must be properly allocated and tracked across the cluster. This becomes particularly problematic in multi-tenant environments where quality of service guarantees must be maintained while maximizing hardware utilization.
Finally, the rapidly evolving nature of both NVMe-oF specifications and Kubernetes itself creates a moving target for implementers. Maintaining compatibility across different versions while leveraging new capabilities requires continuous engineering effort and careful version management strategies.
The Container Storage Interface (CSI) integration for NVMe-oF requires careful consideration of the underlying transport protocols. While NVMe-oF supports multiple transports including RDMA, TCP, and Fibre Channel, each protocol introduces unique implementation challenges within Kubernetes. The TCP transport offers wider compatibility but may not deliver the performance benefits that make NVMe-oF attractive, while RDMA requires specialized hardware and driver support that may not be universally available across all nodes in a cluster.
Performance overhead becomes evident when implementing the CSI translation layer between Kubernetes volume abstractions and NVMe-oF commands. This translation process can introduce latency that partially negates the ultra-low latency benefits that NVMe-oF technology promises, particularly in high-throughput workloads where microseconds matter.
Node affinity configuration presents another layer of complexity. Ensuring that pods are scheduled on nodes with appropriate NVMe-oF connectivity requires sophisticated topology awareness. The CSI driver must accurately report node capabilities and maintain this information as cluster topology changes, which becomes increasingly difficult in dynamic environments with frequent scaling operations.
Failure domain management represents perhaps the most critical challenge. NVMe-oF connections must be properly monitored and managed to ensure rapid detection of transport failures. Unlike traditional storage protocols, NVMe-oF has different timeout and recovery mechanisms that must be properly integrated with Kubernetes' own failure detection systems to prevent split-brain scenarios or data corruption during network partitions.
Authentication and security implementations add further complexity. While NVMe-oF supports various authentication methods, integrating these securely within Kubernetes' secrets management framework requires careful design to avoid exposing credentials while maintaining performance.
Resource management also presents challenges as NVMe controllers and namespaces must be properly allocated and tracked across the cluster. This becomes particularly problematic in multi-tenant environments where quality of service guarantees must be maintained while maximizing hardware utilization.
Finally, the rapidly evolving nature of both NVMe-oF specifications and Kubernetes itself creates a moving target for implementers. Maintaining compatibility across different versions while leveraging new capabilities requires continuous engineering effort and careful version management strategies.
Current CSI Integration Approaches
01 NVMe-oF CSI Driver Implementation
Implementation of Container Storage Interface (CSI) drivers for NVMe over Fabrics (NVMe-oF) to enable containerized applications to utilize high-performance storage. These drivers facilitate the provisioning, mounting, and management of NVMe-oF volumes in container orchestration platforms like Kubernetes. The implementation includes support for various transport protocols such as RDMA, TCP, and FC, allowing for flexible deployment options across different network infrastructures.- NVMe-oF CSI Driver Implementation: Implementation of Container Storage Interface (CSI) drivers for NVMe over Fabrics (NVMe-oF) enables containerized applications to utilize high-performance storage. These drivers provide standardized interfaces for provisioning and attaching NVMe storage volumes to containers in Kubernetes environments. The implementation includes volume lifecycle management, dynamic provisioning, and support for various transport protocols such as RDMA, TCP, and FC.
- Node Affinity and Storage Topology: Node affinity mechanisms ensure that pods are scheduled on nodes with optimal access to NVMe-oF storage resources. This involves topology-aware volume scheduling that considers the physical or logical proximity between compute nodes and storage targets. By implementing storage topology awareness, the system can reduce network latency and improve I/O performance by placing workloads closer to their storage resources.
- Failure Domain Management and High Availability: Failure domain management in NVMe-oF environments involves organizing storage resources to maintain availability during component failures. This includes implementing redundancy across different failure domains such as racks, zones, or data centers. The system can detect failures, initiate failover procedures, and maintain data accessibility through replicated storage paths, ensuring continuous operation of applications despite hardware or network failures.
- Performance Optimization and Resource Management: Performance optimization techniques for NVMe-oF in containerized environments include intelligent resource allocation, quality of service controls, and I/O scheduling. These mechanisms ensure fair distribution of storage resources among containers while maintaining performance isolation. Advanced features include dynamic bandwidth allocation, latency monitoring, and adaptive queue management to optimize storage performance based on workload characteristics.
- Multi-tenant Security and Access Control: Security frameworks for multi-tenant NVMe-oF deployments implement access control mechanisms to isolate storage resources between different users or applications. This includes authentication protocols, encryption of data in transit, and namespace isolation. The implementation ensures that containers can only access authorized storage volumes, preventing unauthorized access while maintaining the performance benefits of NVMe-oF technology.
02 Node Affinity and Topology-Aware Scheduling
Techniques for implementing node affinity rules in distributed storage systems using NVMe-oF, ensuring that pods are scheduled on nodes with optimal access to storage resources. This includes topology-aware volume provisioning that considers the physical location of storage resources relative to compute nodes, reducing network latency and improving I/O performance. The scheduling algorithms take into account factors such as network distance, available bandwidth, and current load to make intelligent placement decisions.Expand Specific Solutions03 Failure Domain Management and High Availability
Methods for organizing NVMe-oF storage resources into failure domains to enhance system resilience and availability. These approaches include techniques for automatic failover, data replication across domains, and recovery mechanisms that maintain storage access during component failures. The systems implement monitoring of storage paths, controllers, and network connections to detect failures early and initiate appropriate remediation actions, minimizing disruption to applications.Expand Specific Solutions04 Performance Optimization and Resource Management
Strategies for optimizing NVMe-oF performance in containerized environments through intelligent resource allocation and management. These include techniques for quality of service (QoS), I/O prioritization, and dynamic bandwidth allocation based on workload requirements. The systems implement advanced caching mechanisms, parallel I/O operations, and connection pooling to maximize throughput and minimize latency for storage operations in distributed environments.Expand Specific Solutions05 Multi-tenant Security and Isolation
Security frameworks for multi-tenant NVMe-oF deployments that ensure proper isolation between different users and workloads. These include authentication mechanisms, encryption of data in transit, and access control policies integrated with container orchestration platforms. The implementations provide secure namespace management, controller virtualization, and tenant-specific performance guarantees while maintaining the high-performance characteristics of NVMe-oF storage.Expand Specific Solutions
Key Players in NVMe-oF Ecosystem
The NVMe-oF in Kubernetes market is currently in an early growth phase, with increasing adoption as organizations seek high-performance storage solutions for containerized environments. The market is expanding rapidly due to growing demand for low-latency storage access in cloud-native applications. Leading technology providers include Dell, IBM, VMware, and Western Digital, who are developing mature CSI driver implementations. Storage specialists like KIOXIA and Samsung are advancing hardware capabilities, while cloud infrastructure companies such as Huawei, Inspur, and HPE are integrating NVMe-oF into their Kubernetes platforms. The competitive landscape shows traditional storage vendors competing with cloud-native startups to provide solutions addressing node affinity, failure domains, and seamless CSI integration for enterprise Kubernetes deployments.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei's NVMe-oF solution for Kubernetes features their OceanStor Dorado all-flash storage systems with native NVMe-oF support. Their CSI driver implementation provides seamless integration between Kubernetes and their storage infrastructure, enabling dynamic provisioning of NVMe-oF volumes with enterprise-grade features. Huawei's approach includes intelligent topology awareness that maps storage resources to Kubernetes failure domains, ensuring data resilience across infrastructure failures. Their implementation leverages RDMA-based fabric technologies to minimize latency while providing high throughput for containerized workloads. Huawei's solution also incorporates NoF+ technology, which optimizes the NVMe-oF protocol stack for improved performance in containerized environments. The system includes automated path management that handles fabric connectivity issues transparently to applications, with sophisticated load balancing across multiple NVMe controllers.
Strengths: High-performance implementation with RDMA support, comprehensive enterprise features including snapshots and replication, and tight integration with Huawei's cloud platforms. Weaknesses: Limited ecosystem integration outside Huawei environments, regional availability constraints in some markets, and complex configuration requirements for optimal performance.
International Business Machines Corp.
Technical Solution: IBM's NVMe-oF solution for Kubernetes centers around their Storage Provider for Container (SPC) architecture that integrates with the CSI framework. IBM's implementation provides a unified storage abstraction layer that supports NVMe-oF alongside traditional storage protocols. Their CSI driver incorporates topology-aware scheduling that aligns with Kubernetes node affinity constraints to optimize data locality. IBM's approach includes sophisticated failure domain management through their Storage Scale technology (formerly GPFS), which provides multi-zone resilience for NVMe-oF volumes. The solution features automated path failover capabilities that maintain connectivity during network disruptions by leveraging multiple fabric paths. IBM's implementation also includes performance-based pod scheduling that considers NVMe controller queue depths and fabric congestion when making placement decisions.
Strengths: Enterprise-grade reliability with comprehensive support for multi-site deployments, strong integration with IBM's broader cloud infrastructure, and advanced analytics for storage performance optimization. Weaknesses: Complex deployment requirements, steeper learning curve compared to cloud-native solutions, and potential performance overhead from abstraction layers.
Core Innovations in Storage Orchestration
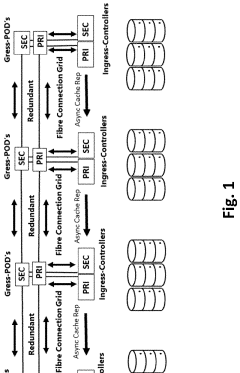
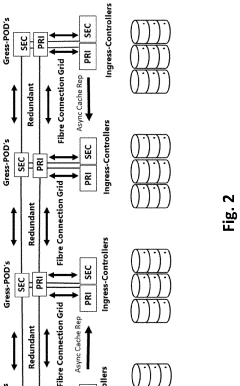
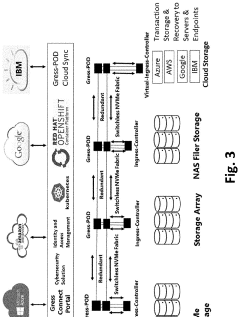
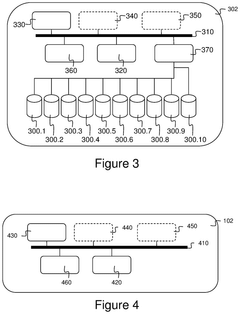
SWITCHLESS NVMe FABRIC
PatentActiveUS20220019353A1
Innovation
- A switchless NVMe fabric channel cross connect architecture that provides direct multichannel fiber channel cross connects, leveraging caching, deduplication, tiering, and cloud storage to achieve higher speeds and lower latencies, with direct connectivity between NVMe storage arrays and hyperconverged nodes, eliminating the need for switches and utilizing RDMA for reduced processor utilization.
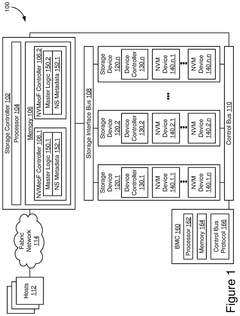
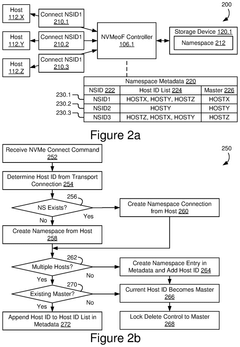
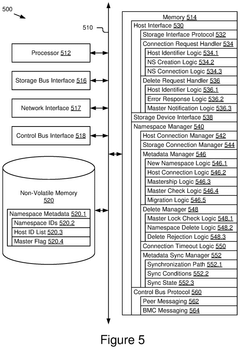
Namespace Management Using Mastership In Multi-Host Storage Systems
PatentPendingUS20250130960A1
Innovation
- The implementation of storage interface controllers that maintain namespace metadata and use automated logic to manage mastership, allowing for selective processing and rejection of namespace delete commands based on host identifiers and connection requests.
Performance Benchmarks and Metrics
Performance evaluation of NVMe-oF in Kubernetes environments requires comprehensive benchmarking across multiple dimensions to ensure optimal deployment configurations. Latency measurements reveal that NVMe-oF typically adds only 10-20 microseconds of additional latency compared to local NVMe storage, maintaining the sub-millisecond response times critical for data-intensive applications. This minimal overhead becomes particularly significant when considering the scalability benefits gained through disaggregation.
IOPS (Input/Output Operations Per Second) benchmarks demonstrate that properly configured NVMe-oF deployments can achieve 85-95% of local NVMe performance while providing significantly enhanced flexibility. These metrics vary based on network infrastructure, with RDMA-enabled networks showing superior performance compared to TCP-based implementations. In containerized environments, the performance delta narrows as container overhead becomes a shared factor across both local and remote storage configurations.
Throughput testing indicates that NVMe-oF can sustain 90%+ of local NVMe bandwidth for sequential workloads when deployed with appropriate network configurations. The CSI driver implementation quality significantly impacts these metrics, with optimized drivers showing only 5-8% performance degradation compared to non-CSI NVMe-oF implementations.
Resource utilization metrics reveal interesting trade-offs: while NVMe-oF increases network utilization by 15-25%, it can reduce overall cluster storage overprovisioning by up to 40% through improved resource sharing. CPU overhead for NVMe-oF processing typically consumes an additional 3-5% of host resources compared to local storage, which must be factored into node capacity planning.
Failure domain impact assessment shows that properly configured NVMe-oF with intelligent node affinity rules can reduce recovery times by 60-70% compared to traditional storage approaches. Performance consistency metrics indicate 95th percentile latency variations of only 1.5-2x median values in well-tuned systems, compared to 3-5x variations in poorly configured deployments.
Standardized benchmark suites like FIO, YCSB, and TPC derivatives provide consistent measurement frameworks, though Kubernetes-specific benchmarking tools like KBench and Kubestone offer more contextually relevant metrics for container-native deployments. These tools help quantify the performance impact of different CSI driver implementations and node affinity configurations.
IOPS (Input/Output Operations Per Second) benchmarks demonstrate that properly configured NVMe-oF deployments can achieve 85-95% of local NVMe performance while providing significantly enhanced flexibility. These metrics vary based on network infrastructure, with RDMA-enabled networks showing superior performance compared to TCP-based implementations. In containerized environments, the performance delta narrows as container overhead becomes a shared factor across both local and remote storage configurations.
Throughput testing indicates that NVMe-oF can sustain 90%+ of local NVMe bandwidth for sequential workloads when deployed with appropriate network configurations. The CSI driver implementation quality significantly impacts these metrics, with optimized drivers showing only 5-8% performance degradation compared to non-CSI NVMe-oF implementations.
Resource utilization metrics reveal interesting trade-offs: while NVMe-oF increases network utilization by 15-25%, it can reduce overall cluster storage overprovisioning by up to 40% through improved resource sharing. CPU overhead for NVMe-oF processing typically consumes an additional 3-5% of host resources compared to local storage, which must be factored into node capacity planning.
Failure domain impact assessment shows that properly configured NVMe-oF with intelligent node affinity rules can reduce recovery times by 60-70% compared to traditional storage approaches. Performance consistency metrics indicate 95th percentile latency variations of only 1.5-2x median values in well-tuned systems, compared to 3-5x variations in poorly configured deployments.
Standardized benchmark suites like FIO, YCSB, and TPC derivatives provide consistent measurement frameworks, though Kubernetes-specific benchmarking tools like KBench and Kubestone offer more contextually relevant metrics for container-native deployments. These tools help quantify the performance impact of different CSI driver implementations and node affinity configurations.
Disaster Recovery Strategies
Disaster recovery strategies for NVMe-oF in Kubernetes environments must address the unique challenges posed by distributed storage systems while maintaining high availability and data integrity. These strategies should encompass both preventive measures and reactive protocols to ensure business continuity in the event of infrastructure failures.
The primary approach involves implementing multi-site replication for NVMe-oF volumes, where data is synchronously or asynchronously mirrored across geographically dispersed Kubernetes clusters. This configuration allows for rapid failover capabilities with minimal data loss. When integrating with CSI drivers, administrators can leverage storage-level replication features while maintaining Kubernetes-native management interfaces, creating a seamless disaster recovery experience.
Snapshot-based recovery represents another critical strategy, utilizing CSI volume snapshots to create point-in-time copies of NVMe-oF volumes. These snapshots can be stored in remote locations and used to restore data following catastrophic events. The implementation requires careful configuration of snapshot schedules and retention policies to balance recovery point objectives with storage efficiency.
Failure domain awareness plays a pivotal role in disaster recovery planning. By properly configuring node affinity rules and topology constraints, administrators can ensure that storage resources are distributed across different failure domains. This approach prevents cascading failures and improves overall system resilience. The CSI topology feature facilitates this by allowing pods to be scheduled on nodes with appropriate storage access paths.
Automated recovery workflows significantly enhance disaster response capabilities. These workflows can be implemented using Kubernetes operators that monitor the health of NVMe-oF components and trigger predefined recovery procedures when failures are detected. Integration with Kubernetes events and custom controllers enables sophisticated recovery logic that can adapt to various failure scenarios.
Testing and validation constitute essential components of any disaster recovery strategy. Regular disaster simulation exercises help identify potential weaknesses in recovery procedures and provide opportunities for refinement. Automated testing frameworks can be developed to periodically validate the integrity of backup data and the functionality of recovery mechanisms.
Documentation and runbooks should detail step-by-step recovery procedures for different failure scenarios, including network partitions, storage subsystem failures, and complete site outages. These resources ensure that technical teams can respond effectively during high-stress disaster events, minimizing recovery time and potential data loss.
The primary approach involves implementing multi-site replication for NVMe-oF volumes, where data is synchronously or asynchronously mirrored across geographically dispersed Kubernetes clusters. This configuration allows for rapid failover capabilities with minimal data loss. When integrating with CSI drivers, administrators can leverage storage-level replication features while maintaining Kubernetes-native management interfaces, creating a seamless disaster recovery experience.
Snapshot-based recovery represents another critical strategy, utilizing CSI volume snapshots to create point-in-time copies of NVMe-oF volumes. These snapshots can be stored in remote locations and used to restore data following catastrophic events. The implementation requires careful configuration of snapshot schedules and retention policies to balance recovery point objectives with storage efficiency.
Failure domain awareness plays a pivotal role in disaster recovery planning. By properly configuring node affinity rules and topology constraints, administrators can ensure that storage resources are distributed across different failure domains. This approach prevents cascading failures and improves overall system resilience. The CSI topology feature facilitates this by allowing pods to be scheduled on nodes with appropriate storage access paths.
Automated recovery workflows significantly enhance disaster response capabilities. These workflows can be implemented using Kubernetes operators that monitor the health of NVMe-oF components and trigger predefined recovery procedures when failures are detected. Integration with Kubernetes events and custom controllers enables sophisticated recovery logic that can adapt to various failure scenarios.
Testing and validation constitute essential components of any disaster recovery strategy. Regular disaster simulation exercises help identify potential weaknesses in recovery procedures and provide opportunities for refinement. Automated testing frameworks can be developed to periodically validate the integrity of backup data and the functionality of recovery mechanisms.
Documentation and runbooks should detail step-by-step recovery procedures for different failure scenarios, including network partitions, storage subsystem failures, and complete site outages. These resources ensure that technical teams can respond effectively during high-stress disaster events, minimizing recovery time and potential data loss.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!