

How to Develop Fault-Tolerant Microcontroller Systems
FEB 25, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Fault-Tolerant MCU System Background and Objectives
Fault-tolerant microcontroller systems represent a critical technological domain that has evolved significantly since the early days of embedded computing. Initially, microcontrollers were primarily designed for simple control applications where occasional failures could be tolerated. However, as these systems became integral to safety-critical applications such as automotive control, medical devices, aerospace systems, and industrial automation, the demand for reliability and continuous operation has intensified dramatically.
The evolution of fault-tolerant MCU systems can be traced through several key phases. Early implementations focused on basic watchdog timers and simple redundancy schemes. The advancement progressed through hardware-based error detection and correction mechanisms, leading to today's sophisticated multi-layered fault tolerance approaches that combine hardware redundancy, software-based error handling, and intelligent system monitoring capabilities.
Modern fault-tolerant microcontroller systems must address an increasingly complex array of failure modes. These include transient faults caused by electromagnetic interference, permanent hardware failures due to component aging or manufacturing defects, software errors resulting from design flaws or unexpected operating conditions, and system-level failures arising from environmental stresses such as temperature extremes, vibration, or radiation exposure.
The primary objective of developing fault-tolerant MCU systems is to ensure continuous system operation despite the occurrence of various types of faults. This encompasses maintaining functional safety standards, minimizing system downtime, preserving data integrity, and providing graceful degradation when complete fault recovery is not possible. Additionally, these systems must achieve fault tolerance while maintaining acceptable performance levels, power consumption constraints, and cost-effectiveness.
Contemporary development goals also emphasize the integration of predictive maintenance capabilities, enabling systems to anticipate potential failures before they occur. This proactive approach extends beyond traditional reactive fault tolerance to include intelligent health monitoring, prognostic algorithms, and adaptive system reconfiguration. The ultimate aim is to create resilient embedded systems that can autonomously detect, isolate, and recover from faults while maintaining mission-critical functionality across diverse application domains.
The evolution of fault-tolerant MCU systems can be traced through several key phases. Early implementations focused on basic watchdog timers and simple redundancy schemes. The advancement progressed through hardware-based error detection and correction mechanisms, leading to today's sophisticated multi-layered fault tolerance approaches that combine hardware redundancy, software-based error handling, and intelligent system monitoring capabilities.
Modern fault-tolerant microcontroller systems must address an increasingly complex array of failure modes. These include transient faults caused by electromagnetic interference, permanent hardware failures due to component aging or manufacturing defects, software errors resulting from design flaws or unexpected operating conditions, and system-level failures arising from environmental stresses such as temperature extremes, vibration, or radiation exposure.
The primary objective of developing fault-tolerant MCU systems is to ensure continuous system operation despite the occurrence of various types of faults. This encompasses maintaining functional safety standards, minimizing system downtime, preserving data integrity, and providing graceful degradation when complete fault recovery is not possible. Additionally, these systems must achieve fault tolerance while maintaining acceptable performance levels, power consumption constraints, and cost-effectiveness.
Contemporary development goals also emphasize the integration of predictive maintenance capabilities, enabling systems to anticipate potential failures before they occur. This proactive approach extends beyond traditional reactive fault tolerance to include intelligent health monitoring, prognostic algorithms, and adaptive system reconfiguration. The ultimate aim is to create resilient embedded systems that can autonomously detect, isolate, and recover from faults while maintaining mission-critical functionality across diverse application domains.
Market Demand for Reliable Embedded Systems
The global embedded systems market continues to experience robust growth driven by the proliferation of Internet of Things devices, autonomous vehicles, industrial automation, and smart infrastructure. This expansion has intensified the demand for reliable embedded systems that can operate continuously without failure, particularly in mission-critical applications where system downtime translates to significant economic losses or safety risks.
Automotive electronics represents one of the most demanding sectors for fault-tolerant microcontroller systems. Modern vehicles integrate hundreds of electronic control units managing everything from engine performance to advanced driver assistance systems. The transition toward autonomous driving has elevated reliability requirements to unprecedented levels, as sensor fusion, real-time decision-making, and safety-critical functions must operate flawlessly under diverse environmental conditions.
Industrial automation and manufacturing sectors demonstrate equally compelling demand patterns. Smart factories rely on distributed control systems where individual microcontroller failures can cascade into production line shutdowns, resulting in substantial operational disruptions. The integration of predictive maintenance, quality control systems, and supply chain optimization further amplifies the need for fault-tolerant embedded solutions that maintain operational continuity.
Healthcare and medical device markets present another significant growth area. Implantable devices, patient monitoring systems, and diagnostic equipment require exceptional reliability standards due to direct patient safety implications. Regulatory frameworks in these sectors mandate stringent fault tolerance capabilities, driving sustained demand for advanced microcontroller architectures with built-in redundancy and error correction mechanisms.
Aerospace and defense applications continue to push the boundaries of fault-tolerant system requirements. Satellite communications, navigation systems, and unmanned aerial vehicles operate in harsh environments where repair or replacement becomes impractical or impossible. These applications demand microcontroller systems capable of autonomous error detection, correction, and graceful degradation under extreme conditions.
The telecommunications infrastructure sector has emerged as a major demand driver, particularly with the global deployment of fifth-generation wireless networks. Base stations, network switches, and edge computing nodes require continuous operation with minimal maintenance windows. Service level agreements in telecommunications often specify uptime requirements exceeding traditional embedded system capabilities, necessitating advanced fault-tolerant designs.
Energy sector applications, including smart grid infrastructure and renewable energy systems, represent rapidly expanding market segments. Power generation facilities, distribution networks, and energy storage systems increasingly rely on embedded controllers that must maintain operational stability across varying load conditions and environmental factors while ensuring grid stability and preventing cascading failures.
Automotive electronics represents one of the most demanding sectors for fault-tolerant microcontroller systems. Modern vehicles integrate hundreds of electronic control units managing everything from engine performance to advanced driver assistance systems. The transition toward autonomous driving has elevated reliability requirements to unprecedented levels, as sensor fusion, real-time decision-making, and safety-critical functions must operate flawlessly under diverse environmental conditions.
Industrial automation and manufacturing sectors demonstrate equally compelling demand patterns. Smart factories rely on distributed control systems where individual microcontroller failures can cascade into production line shutdowns, resulting in substantial operational disruptions. The integration of predictive maintenance, quality control systems, and supply chain optimization further amplifies the need for fault-tolerant embedded solutions that maintain operational continuity.
Healthcare and medical device markets present another significant growth area. Implantable devices, patient monitoring systems, and diagnostic equipment require exceptional reliability standards due to direct patient safety implications. Regulatory frameworks in these sectors mandate stringent fault tolerance capabilities, driving sustained demand for advanced microcontroller architectures with built-in redundancy and error correction mechanisms.
Aerospace and defense applications continue to push the boundaries of fault-tolerant system requirements. Satellite communications, navigation systems, and unmanned aerial vehicles operate in harsh environments where repair or replacement becomes impractical or impossible. These applications demand microcontroller systems capable of autonomous error detection, correction, and graceful degradation under extreme conditions.
The telecommunications infrastructure sector has emerged as a major demand driver, particularly with the global deployment of fifth-generation wireless networks. Base stations, network switches, and edge computing nodes require continuous operation with minimal maintenance windows. Service level agreements in telecommunications often specify uptime requirements exceeding traditional embedded system capabilities, necessitating advanced fault-tolerant designs.
Energy sector applications, including smart grid infrastructure and renewable energy systems, represent rapidly expanding market segments. Power generation facilities, distribution networks, and energy storage systems increasingly rely on embedded controllers that must maintain operational stability across varying load conditions and environmental factors while ensuring grid stability and preventing cascading failures.
Current State and Challenges in MCU Fault Tolerance
The current landscape of microcontroller fault tolerance presents a complex array of technological achievements alongside persistent challenges. Modern MCU systems have evolved significantly from simple 8-bit architectures to sophisticated 32-bit and 64-bit platforms incorporating multiple layers of fault detection and mitigation mechanisms. However, the increasing complexity of applications and harsh operating environments continue to expose vulnerabilities that demand innovative solutions.
Hardware-level fault tolerance has made substantial progress through the implementation of Error Correcting Code (ECC) memory, redundant processing units, and built-in self-test capabilities. Leading semiconductor manufacturers have integrated watchdog timers, brown-out detection, and clock monitoring systems as standard features. Despite these advances, single points of failure remain problematic, particularly in cost-sensitive applications where full redundancy is economically unfeasible.
Software-based fault tolerance techniques have matured considerably, with established methodologies including N-version programming, recovery blocks, and checkpoint-restart mechanisms. Real-time operating systems now incorporate fault-tolerant scheduling algorithms and memory protection units. Nevertheless, the overhead associated with these techniques often conflicts with the stringent timing and resource constraints typical of embedded systems.
The integration of artificial intelligence and machine learning algorithms into MCU fault tolerance represents an emerging frontier, yet faces significant implementation challenges. While predictive fault detection shows promise, the computational requirements and power consumption often exceed the capabilities of resource-constrained microcontrollers. Additionally, the verification and validation of AI-based fault tolerance mechanisms remain complex and time-intensive processes.
Geographic distribution of fault-tolerant MCU development reveals concentration in regions with strong semiconductor industries, particularly North America, Europe, and East Asia. However, standardization efforts across different regions remain fragmented, creating interoperability challenges for global deployment of fault-tolerant systems.
Current technical bottlenecks include the trade-offs between fault coverage and system performance, the difficulty in achieving comprehensive fault injection testing, and the challenge of maintaining fault tolerance across system updates and modifications. The emergence of Internet of Things applications has further complicated the landscape by introducing cybersecurity considerations that intersect with traditional fault tolerance requirements.
Hardware-level fault tolerance has made substantial progress through the implementation of Error Correcting Code (ECC) memory, redundant processing units, and built-in self-test capabilities. Leading semiconductor manufacturers have integrated watchdog timers, brown-out detection, and clock monitoring systems as standard features. Despite these advances, single points of failure remain problematic, particularly in cost-sensitive applications where full redundancy is economically unfeasible.
Software-based fault tolerance techniques have matured considerably, with established methodologies including N-version programming, recovery blocks, and checkpoint-restart mechanisms. Real-time operating systems now incorporate fault-tolerant scheduling algorithms and memory protection units. Nevertheless, the overhead associated with these techniques often conflicts with the stringent timing and resource constraints typical of embedded systems.
The integration of artificial intelligence and machine learning algorithms into MCU fault tolerance represents an emerging frontier, yet faces significant implementation challenges. While predictive fault detection shows promise, the computational requirements and power consumption often exceed the capabilities of resource-constrained microcontrollers. Additionally, the verification and validation of AI-based fault tolerance mechanisms remain complex and time-intensive processes.
Geographic distribution of fault-tolerant MCU development reveals concentration in regions with strong semiconductor industries, particularly North America, Europe, and East Asia. However, standardization efforts across different regions remain fragmented, creating interoperability challenges for global deployment of fault-tolerant systems.
Current technical bottlenecks include the trade-offs between fault coverage and system performance, the difficulty in achieving comprehensive fault injection testing, and the challenge of maintaining fault tolerance across system updates and modifications. The emergence of Internet of Things applications has further complicated the landscape by introducing cybersecurity considerations that intersect with traditional fault tolerance requirements.
Existing Fault Detection and Recovery Solutions
01 Redundant microcontroller architecture for fault tolerance
Implementing redundant microcontroller systems where multiple microcontrollers operate in parallel or standby configurations to ensure continuous operation in case of failure. This approach includes dual or triple modular redundancy where outputs are compared and voting mechanisms determine the correct output. The redundant architecture can detect faults through comparison and automatically switch to backup controllers when primary units fail.- Redundant microcontroller architecture for fault tolerance: Implementing redundant microcontroller systems where multiple microcontrollers operate in parallel or standby configurations to ensure continuous operation in case of failure. This approach includes dual or triple modular redundancy where outputs are compared and voting mechanisms determine the correct output. The redundant architecture can detect faults through comparison and switch to backup controllers automatically to maintain system reliability.
- Fault detection and diagnostic mechanisms: Integration of built-in self-test capabilities and diagnostic routines that continuously monitor microcontroller operations to detect anomalies, errors, or faults. These mechanisms include watchdog timers, memory integrity checks, and error detection codes that identify malfunctions in real-time. The diagnostic systems can trigger corrective actions or alerts when faults are detected to prevent system failures.
- Error correction and recovery techniques: Implementation of error correction codes and recovery protocols that enable microcontroller systems to correct detected errors and restore normal operation. These techniques include memory error correction, state recovery mechanisms, and checkpoint-restart capabilities that allow the system to roll back to a known good state after detecting faults. The recovery processes minimize downtime and maintain system integrity.
- Safety-critical microcontroller design for automotive and industrial applications: Specialized microcontroller architectures designed for safety-critical applications that require high reliability and fault tolerance. These designs incorporate safety features such as lockstep cores, memory protection units, and fail-safe mechanisms that comply with industry safety standards. The systems are designed to handle harsh operating conditions and ensure safe operation even in the presence of faults.
- Distributed and networked fault-tolerant microcontroller systems: Fault-tolerant architectures that utilize distributed microcontroller networks with communication protocols enabling fault detection and system reconfiguration. These systems employ multiple interconnected microcontrollers that can detect failures in peer nodes and redistribute tasks to maintain overall system functionality. The networked approach provides scalability and enhanced reliability through cooperative fault management.
02 Fault detection and diagnostic mechanisms
Integration of self-diagnostic capabilities and fault detection circuits within microcontroller systems to identify errors and malfunctions. These mechanisms include watchdog timers, memory integrity checks, periodic self-tests, and error detection codes. The system continuously monitors operational parameters and can trigger alerts or corrective actions when anomalies are detected, ensuring early identification of potential failures.Expand Specific Solutions03 Error correction and recovery techniques
Implementation of error correction codes and recovery protocols to maintain system integrity when faults occur. These techniques include memory error correction, data redundancy, checkpoint and rollback mechanisms, and graceful degradation strategies. The system can automatically correct single-bit errors and recover from transient faults without complete system shutdown, maintaining operational continuity.Expand Specific Solutions04 Safety-critical system design with fail-safe mechanisms
Design methodologies specifically for safety-critical applications where microcontroller failures could have severe consequences. This includes fail-safe default states, independent safety monitoring channels, diverse redundancy using different hardware or software implementations, and compliance with safety standards. The system ensures that any detected fault results in a safe state rather than unpredictable behavior.Expand Specific Solutions05 Distributed processing and fault isolation
Utilization of distributed microcontroller architectures where processing tasks are divided among multiple controllers with isolation boundaries to prevent fault propagation. This approach includes partitioning of critical and non-critical functions, communication protocols for inter-controller coordination, and containment strategies to isolate faulty components. The distributed nature allows the system to continue operating even when individual controllers experience failures.Expand Specific Solutions
Key Players in Fault-Tolerant MCU Industry
The fault-tolerant microcontroller systems market is experiencing rapid growth driven by increasing demands for reliability in critical applications across automotive, aerospace, and industrial sectors. The industry is in a mature development stage with established players like Texas Instruments, STMicroelectronics, Toshiba, and NEC leading hardware innovation, while technology giants such as IBM, Huawei, and Apple integrate fault-tolerance into broader system architectures. Academic institutions including Caltech, Technical University of Denmark, and various Chinese universities are advancing theoretical foundations and next-generation solutions. The technology demonstrates high maturity in traditional sectors but shows emerging potential in IoT and edge computing applications. Companies like Mitsubishi Electric and Honeywell are driving industrial automation integration, while automotive players like Renault are implementing safety-critical systems, indicating a competitive landscape characterized by both horizontal integration across industries and vertical specialization in mission-critical applications.
Toshiba Corp.
Technical Solution: Toshiba develops fault-tolerant microcontroller systems focusing on radiation-hardened designs and error-resilient architectures for aerospace and automotive applications. Their solution incorporates temporal and spatial redundancy techniques, including time-diverse software execution and hardware voting systems. Toshiba implements advanced error detection codes, memory interleaving, and fault-tolerant communication protocols. The system features automatic fault isolation and recovery mechanisms that can maintain critical functions even when multiple components fail. Their approach includes comprehensive built-in self-test (BIST) capabilities and real-time fault coverage analysis to ensure continuous system integrity assessment.
Strengths: Excellent radiation tolerance, comprehensive BIST capabilities, strong automotive heritage. Weaknesses: Limited to specialized applications, higher cost due to radiation-hardening requirements.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei implements fault-tolerant microcontroller systems using distributed redundancy and AI-enhanced error prediction algorithms. Their solution combines hardware redundancy with software-based fault detection mechanisms, including watchdog timers, memory scrubbing techniques, and real-time health monitoring. The system employs triple modular redundancy (TMR) for critical components and implements graceful degradation strategies when faults are detected. Huawei's approach integrates machine learning algorithms to predict potential failures before they occur, enabling proactive maintenance and system reconfiguration to maintain operational continuity in telecommunications and networking equipment.
Strengths: AI-enhanced predictive maintenance, robust TMR implementation, excellent for telecom applications. Weaknesses: Complex algorithm implementation, requires significant computational resources for ML processing.
Core Innovations in MCU Redundancy and Error Correction
Run-time Verification of CPU Operation
PatentInactiveUS20120066551A1
Innovation
- The use of debug and trace information from CPUs to generate and compare checksums, either within a single processor core or across multiple cores in a cluster, to verify correct operation, allowing for enhanced safety diagnostics and fault detection without the need for additional hardware or software-based lockstep solutions.




Dependable microcontroller, method for designing a dependable microcontroller and computer program product therefor
PatentActiveUS7472051B2
Innovation
- A microcontroller with a fault-tolerant processing unit that implements distributed fault-tolerant detection methods through suitable interfaces and hardware blocks, utilizing a Fault-Recognition Accelerator to monitor and manage faults, reducing area overhead and enabling low-latency fault control.
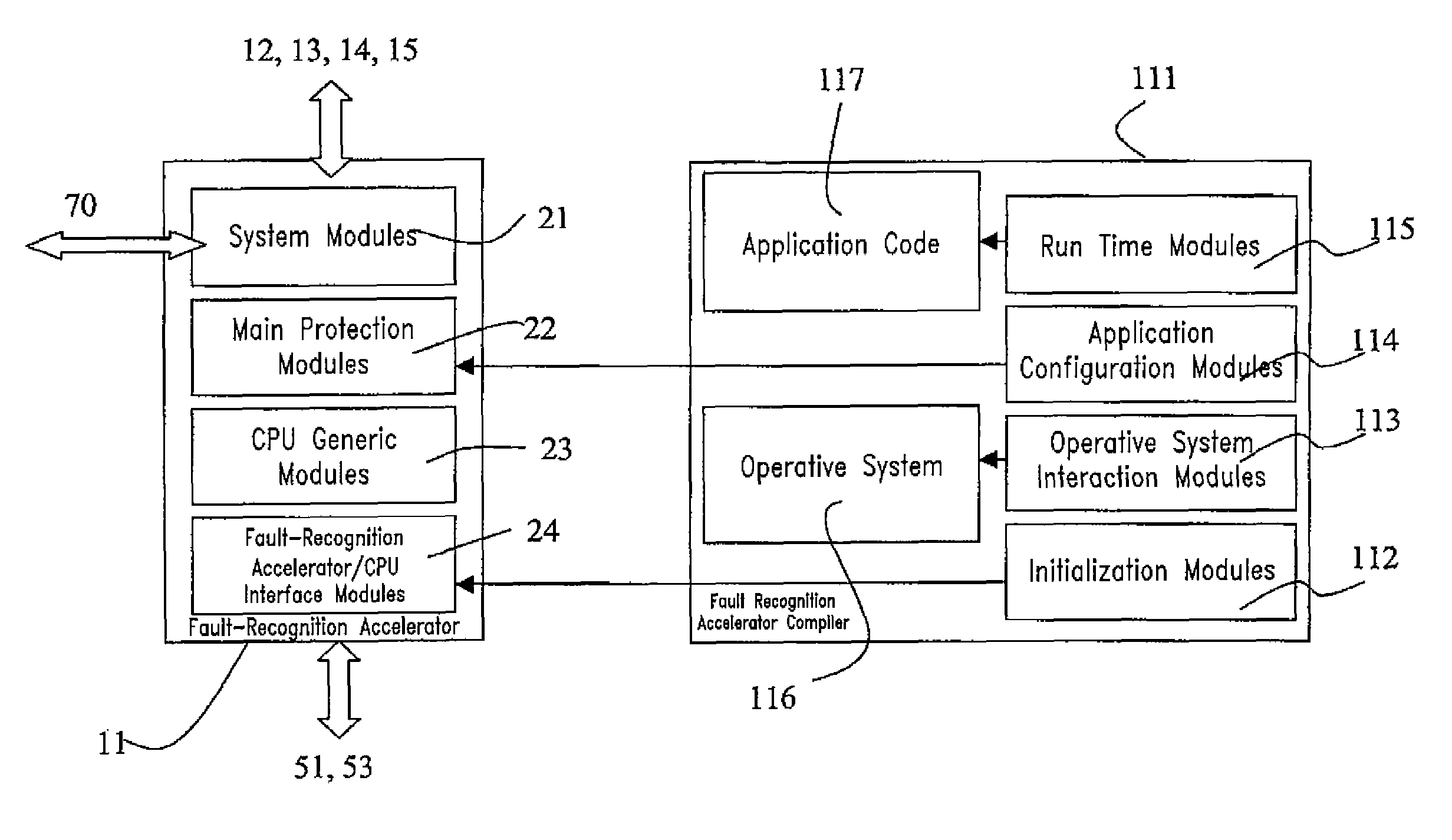
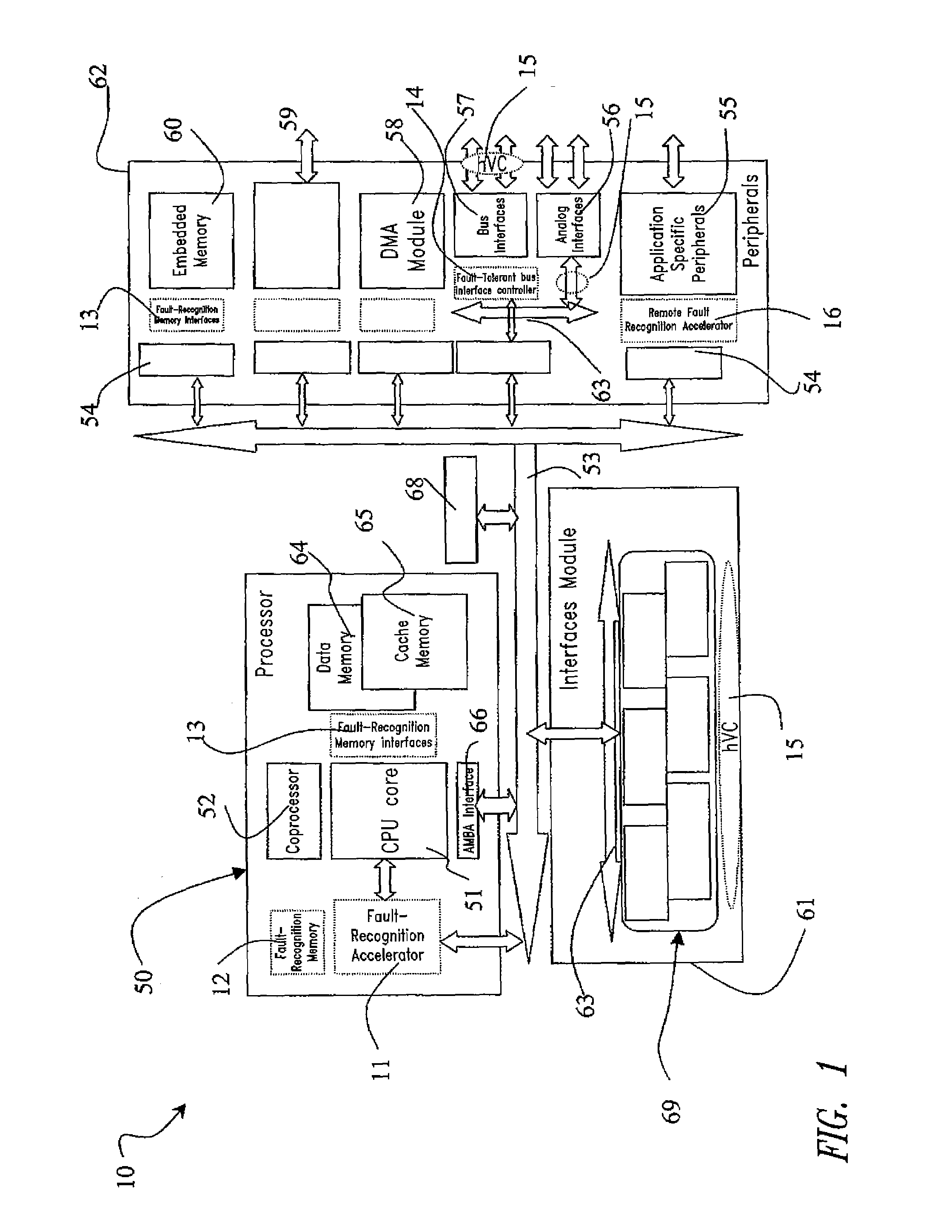
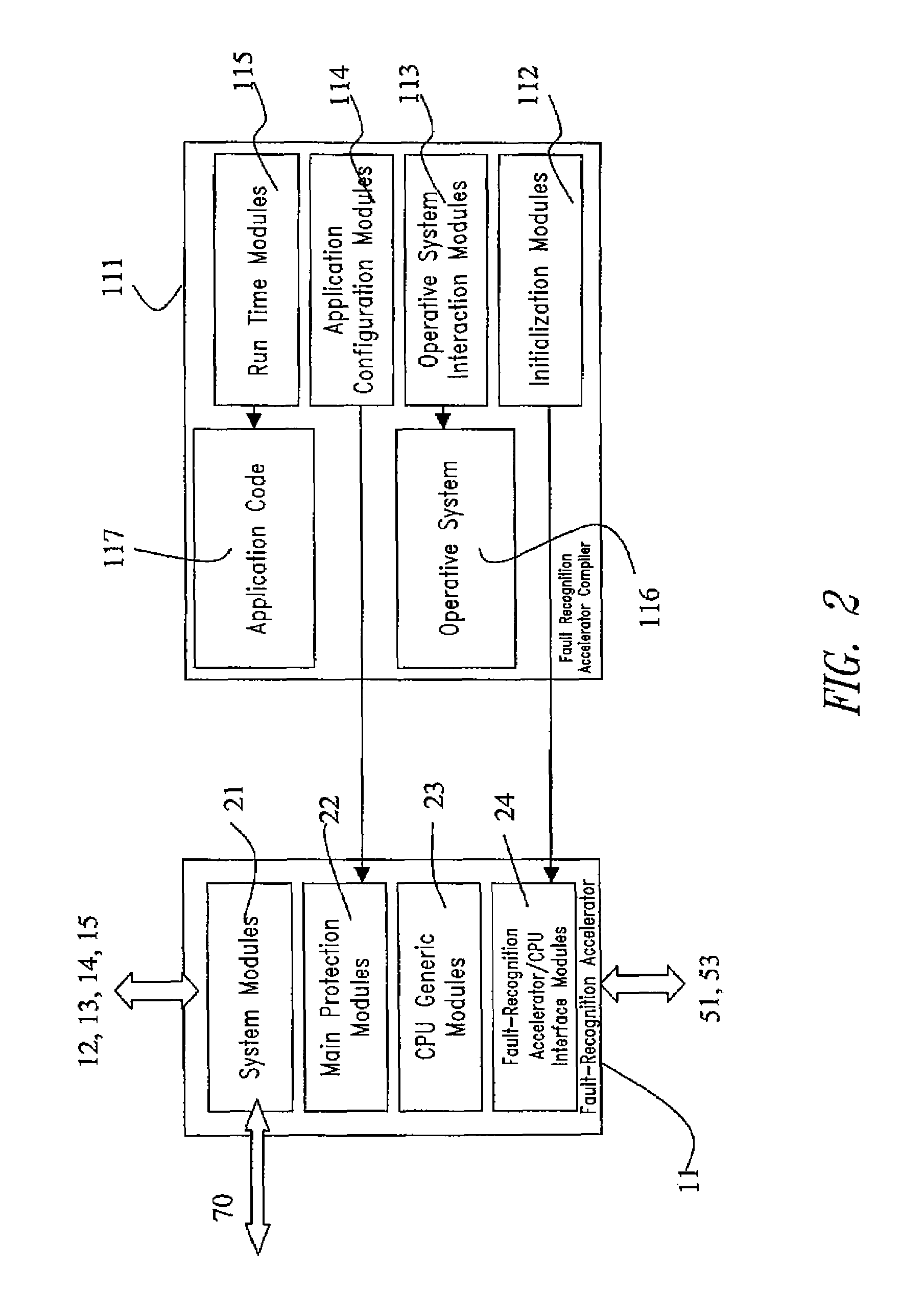

Safety Standards and Certification Requirements
Fault-tolerant microcontroller systems must comply with rigorous safety standards and certification requirements to ensure reliable operation in critical applications. The automotive industry primarily follows ISO 26262 (Functional Safety for Road Vehicles), which defines Automotive Safety Integrity Levels (ASIL) ranging from A to D, with ASIL D representing the highest safety requirements. This standard mandates comprehensive hazard analysis, risk assessment, and systematic verification processes throughout the development lifecycle.
In aerospace and defense applications, DO-178C (Software Considerations in Airborne Systems and Equipment Certification) serves as the primary guideline, establishing Design Assurance Levels (DAL) from A to E. Level A requires the most stringent verification and validation processes, including formal methods and exhaustive testing protocols. The standard emphasizes software reliability, traceability, and configuration management to prevent catastrophic failures in flight-critical systems.
Industrial automation systems typically adhere to IEC 61508 (Functional Safety of Electrical/Electronic/Programmable Electronic Safety-related Systems), which provides a framework for Safety Integrity Levels (SIL 1-4). This standard addresses both hardware and software aspects of safety-critical systems, requiring probabilistic failure analysis and systematic capability assessment. Medical device applications must comply with IEC 62304 (Medical Device Software Life Cycle Processes), which categorizes software into three safety classes based on potential harm to patients.
The certification process involves multiple phases including design review, code inspection, testing validation, and third-party assessment. Regulatory bodies such as TÜV, UL, and national aviation authorities conduct thorough evaluations of system architecture, fault detection mechanisms, and recovery procedures. Documentation requirements are extensive, covering safety cases, hazard analyses, verification reports, and traceability matrices linking requirements to implementation and testing.
Emerging standards like ISO 21448 (Safety of the Intended Functionality) address challenges in autonomous systems where traditional fault models may not apply. These evolving requirements emphasize the importance of validation in real-world scenarios and continuous monitoring of system performance throughout operational life.
In aerospace and defense applications, DO-178C (Software Considerations in Airborne Systems and Equipment Certification) serves as the primary guideline, establishing Design Assurance Levels (DAL) from A to E. Level A requires the most stringent verification and validation processes, including formal methods and exhaustive testing protocols. The standard emphasizes software reliability, traceability, and configuration management to prevent catastrophic failures in flight-critical systems.
Industrial automation systems typically adhere to IEC 61508 (Functional Safety of Electrical/Electronic/Programmable Electronic Safety-related Systems), which provides a framework for Safety Integrity Levels (SIL 1-4). This standard addresses both hardware and software aspects of safety-critical systems, requiring probabilistic failure analysis and systematic capability assessment. Medical device applications must comply with IEC 62304 (Medical Device Software Life Cycle Processes), which categorizes software into three safety classes based on potential harm to patients.
The certification process involves multiple phases including design review, code inspection, testing validation, and third-party assessment. Regulatory bodies such as TÜV, UL, and national aviation authorities conduct thorough evaluations of system architecture, fault detection mechanisms, and recovery procedures. Documentation requirements are extensive, covering safety cases, hazard analyses, verification reports, and traceability matrices linking requirements to implementation and testing.
Emerging standards like ISO 21448 (Safety of the Intended Functionality) address challenges in autonomous systems where traditional fault models may not apply. These evolving requirements emphasize the importance of validation in real-world scenarios and continuous monitoring of system performance throughout operational life.
Cost-Performance Trade-offs in Fault-Tolerant Design
The development of fault-tolerant microcontroller systems inherently involves complex trade-offs between cost and performance, requiring careful consideration of multiple factors that influence both system reliability and economic viability. These trade-offs become particularly critical when designing systems for applications where failure consequences vary significantly, from minor inconveniences to catastrophic outcomes.
Hardware redundancy represents one of the most fundamental cost-performance considerations in fault-tolerant design. Triple Modular Redundancy (TMR) systems provide excellent fault tolerance by implementing three parallel processing units with majority voting, but this approach triples hardware costs while consuming significantly more power. Dual Modular Redundancy (DMR) with comparison checking offers a middle ground, reducing hardware costs by approximately 33% compared to TMR while still providing robust error detection capabilities, though at the expense of automatic error correction.
Software-based fault tolerance techniques present attractive alternatives for cost-sensitive applications. Algorithm-Based Fault Tolerance (ABFT) and software-implemented hardware fault tolerance can achieve reasonable reliability improvements with minimal hardware overhead. However, these approaches typically introduce performance penalties ranging from 10% to 50% due to additional computational requirements for error detection and recovery operations.
Memory protection mechanisms illustrate another critical trade-off dimension. Error Correcting Code (ECC) memory provides single-bit error correction and double-bit error detection but increases memory costs by 12.5% for basic implementations. Advanced ECC schemes offering enhanced protection can increase costs by 25-40% while introducing latency penalties of 1-3 clock cycles per memory access.
Power consumption considerations significantly impact the cost-performance equation, particularly in battery-powered applications. Fault-tolerant designs typically consume 150-300% more power than non-redundant systems, directly affecting battery life and thermal management requirements. This increased power consumption translates to higher operational costs and potentially more expensive cooling solutions.
The selection of appropriate fault tolerance levels must align with application criticality and budget constraints. Safety-critical aerospace applications may justify TMR implementations despite 200-300% cost premiums, while consumer electronics might employ lightweight software-based approaches accepting 10-20% performance degradation to maintain cost competitiveness. Hybrid approaches combining selective hardware redundancy for critical components with software-based protection for less critical functions often provide optimal cost-performance balance for many applications.
Hardware redundancy represents one of the most fundamental cost-performance considerations in fault-tolerant design. Triple Modular Redundancy (TMR) systems provide excellent fault tolerance by implementing three parallel processing units with majority voting, but this approach triples hardware costs while consuming significantly more power. Dual Modular Redundancy (DMR) with comparison checking offers a middle ground, reducing hardware costs by approximately 33% compared to TMR while still providing robust error detection capabilities, though at the expense of automatic error correction.
Software-based fault tolerance techniques present attractive alternatives for cost-sensitive applications. Algorithm-Based Fault Tolerance (ABFT) and software-implemented hardware fault tolerance can achieve reasonable reliability improvements with minimal hardware overhead. However, these approaches typically introduce performance penalties ranging from 10% to 50% due to additional computational requirements for error detection and recovery operations.
Memory protection mechanisms illustrate another critical trade-off dimension. Error Correcting Code (ECC) memory provides single-bit error correction and double-bit error detection but increases memory costs by 12.5% for basic implementations. Advanced ECC schemes offering enhanced protection can increase costs by 25-40% while introducing latency penalties of 1-3 clock cycles per memory access.
Power consumption considerations significantly impact the cost-performance equation, particularly in battery-powered applications. Fault-tolerant designs typically consume 150-300% more power than non-redundant systems, directly affecting battery life and thermal management requirements. This increased power consumption translates to higher operational costs and potentially more expensive cooling solutions.
The selection of appropriate fault tolerance levels must align with application criticality and budget constraints. Safety-critical aerospace applications may justify TMR implementations despite 200-300% cost premiums, while consumer electronics might employ lightweight software-based approaches accepting 10-20% performance degradation to maintain cost competitiveness. Hybrid approaches combining selective hardware redundancy for critical components with software-based protection for less critical functions often provide optimal cost-performance balance for many applications.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!