How to Minimize Downtime Using Adaptive Network Control
MAR 18, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Adaptive Network Control Background and Downtime Reduction Goals
Adaptive network control represents a paradigm shift in network management, evolving from traditional static configurations to dynamic, intelligent systems capable of real-time optimization. This technology emerged from the convergence of software-defined networking (SDN), machine learning algorithms, and advanced monitoring capabilities. The fundamental principle involves continuous assessment of network conditions, predictive analysis of potential failures, and automated adjustment of network parameters to maintain optimal performance.
The historical development of adaptive network control can be traced back to early quality of service (QoS) mechanisms in the 1990s, which provided basic traffic prioritization. However, modern adaptive systems incorporate artificial intelligence, enabling networks to learn from historical patterns, predict anomalies, and proactively implement corrective measures. This evolution has been driven by increasing network complexity, growing data volumes, and the critical need for uninterrupted connectivity in digital business operations.
Contemporary adaptive network control systems integrate multiple technologies including intent-based networking, network function virtualization (NFV), and edge computing. These systems continuously collect telemetry data from network devices, analyze traffic patterns, and identify potential bottlenecks or failure points before they impact service availability. The technology has matured to support real-time decision-making with microsecond-level response times.
The primary objective of implementing adaptive network control for downtime minimization centers on achieving near-zero service interruption through proactive network management. This involves establishing self-healing network architectures that can automatically reroute traffic, redistribute loads, and isolate problematic network segments without human intervention. The goal extends beyond simple fault tolerance to encompass predictive maintenance and optimization.
Key technical targets include reducing mean time to recovery (MTTR) from hours to minutes, increasing network availability to 99.99% or higher, and minimizing the impact radius of network failures. Additionally, adaptive systems aim to optimize resource utilization while maintaining service level agreements, ensuring that preventive measures do not compromise network performance. The ultimate vision encompasses fully autonomous networks capable of continuous self-optimization and instantaneous adaptation to changing conditions.
The historical development of adaptive network control can be traced back to early quality of service (QoS) mechanisms in the 1990s, which provided basic traffic prioritization. However, modern adaptive systems incorporate artificial intelligence, enabling networks to learn from historical patterns, predict anomalies, and proactively implement corrective measures. This evolution has been driven by increasing network complexity, growing data volumes, and the critical need for uninterrupted connectivity in digital business operations.
Contemporary adaptive network control systems integrate multiple technologies including intent-based networking, network function virtualization (NFV), and edge computing. These systems continuously collect telemetry data from network devices, analyze traffic patterns, and identify potential bottlenecks or failure points before they impact service availability. The technology has matured to support real-time decision-making with microsecond-level response times.
The primary objective of implementing adaptive network control for downtime minimization centers on achieving near-zero service interruption through proactive network management. This involves establishing self-healing network architectures that can automatically reroute traffic, redistribute loads, and isolate problematic network segments without human intervention. The goal extends beyond simple fault tolerance to encompass predictive maintenance and optimization.
Key technical targets include reducing mean time to recovery (MTTR) from hours to minutes, increasing network availability to 99.99% or higher, and minimizing the impact radius of network failures. Additionally, adaptive systems aim to optimize resource utilization while maintaining service level agreements, ensuring that preventive measures do not compromise network performance. The ultimate vision encompasses fully autonomous networks capable of continuous self-optimization and instantaneous adaptation to changing conditions.
Market Demand for High-Availability Network Solutions
The global market for high-availability network solutions has experienced unprecedented growth driven by the digital transformation accelerating across industries. Organizations increasingly recognize that network downtime directly translates to revenue loss, operational disruption, and reputational damage. This recognition has fundamentally shifted procurement priorities from cost-minimization to availability-maximization strategies.
Enterprise demand patterns reveal a strong preference for adaptive network control technologies that can automatically respond to failures without human intervention. Financial services, healthcare, manufacturing, and e-commerce sectors demonstrate the highest urgency for these solutions due to their mission-critical operations. These industries cannot tolerate even brief network interruptions, as they directly impact customer transactions, patient safety, production continuity, and service delivery.
Cloud migration trends have intensified the demand for sophisticated network resilience mechanisms. As organizations move critical workloads to hybrid and multi-cloud environments, they require network infrastructure capable of maintaining seamless connectivity across distributed systems. The complexity of modern network architectures necessitates intelligent control systems that can predict, prevent, and rapidly recover from various failure scenarios.
The emergence of edge computing and Internet of Things deployments has created new market segments demanding ultra-reliable network connectivity. Industrial automation, autonomous vehicles, smart cities, and remote healthcare applications require network solutions with near-zero tolerance for downtime. These applications often operate in challenging environments where traditional manual intervention approaches prove inadequate.
Market research indicates growing customer willingness to invest premium amounts for proven high-availability solutions. Organizations increasingly evaluate network infrastructure investments based on total cost of ownership calculations that factor in downtime costs, rather than focusing solely on initial capital expenditure. This shift has created substantial market opportunities for vendors offering adaptive network control technologies.
Regulatory compliance requirements across various industries further amplify demand for high-availability network solutions. Financial regulations, healthcare standards, and industrial safety requirements often mandate specific uptime thresholds and recovery time objectives. Organizations must demonstrate their network infrastructure can meet these stringent availability requirements through documented resilience capabilities.
The competitive landscape shows established networking vendors expanding their portfolios to include adaptive control features, while specialized startups focus exclusively on intelligent network resilience solutions. This dynamic creates a robust ecosystem where innovation thrives and customers benefit from diverse solution approaches tailored to specific industry requirements and deployment scenarios.
Enterprise demand patterns reveal a strong preference for adaptive network control technologies that can automatically respond to failures without human intervention. Financial services, healthcare, manufacturing, and e-commerce sectors demonstrate the highest urgency for these solutions due to their mission-critical operations. These industries cannot tolerate even brief network interruptions, as they directly impact customer transactions, patient safety, production continuity, and service delivery.
Cloud migration trends have intensified the demand for sophisticated network resilience mechanisms. As organizations move critical workloads to hybrid and multi-cloud environments, they require network infrastructure capable of maintaining seamless connectivity across distributed systems. The complexity of modern network architectures necessitates intelligent control systems that can predict, prevent, and rapidly recover from various failure scenarios.
The emergence of edge computing and Internet of Things deployments has created new market segments demanding ultra-reliable network connectivity. Industrial automation, autonomous vehicles, smart cities, and remote healthcare applications require network solutions with near-zero tolerance for downtime. These applications often operate in challenging environments where traditional manual intervention approaches prove inadequate.
Market research indicates growing customer willingness to invest premium amounts for proven high-availability solutions. Organizations increasingly evaluate network infrastructure investments based on total cost of ownership calculations that factor in downtime costs, rather than focusing solely on initial capital expenditure. This shift has created substantial market opportunities for vendors offering adaptive network control technologies.
Regulatory compliance requirements across various industries further amplify demand for high-availability network solutions. Financial regulations, healthcare standards, and industrial safety requirements often mandate specific uptime thresholds and recovery time objectives. Organizations must demonstrate their network infrastructure can meet these stringent availability requirements through documented resilience capabilities.
The competitive landscape shows established networking vendors expanding their portfolios to include adaptive control features, while specialized startups focus exclusively on intelligent network resilience solutions. This dynamic creates a robust ecosystem where innovation thrives and customers benefit from diverse solution approaches tailored to specific industry requirements and deployment scenarios.
Current Network Downtime Challenges and Control Limitations
Network downtime represents one of the most critical challenges facing modern enterprises, with studies indicating that unplanned outages cost organizations an average of $5,600 per minute. Traditional network architectures struggle to maintain continuous service availability due to their reactive nature and limited adaptability to dynamic conditions. The increasing complexity of distributed systems, cloud migrations, and hybrid infrastructures has amplified these challenges exponentially.
Current network control systems exhibit significant limitations in their ability to predict and prevent service disruptions. Most existing solutions rely on threshold-based monitoring that triggers alerts only after problems have already impacted user experience. This reactive approach creates substantial gaps between fault detection and remediation, often resulting in extended downtime periods that cascade across interconnected services.
The proliferation of microservices architectures and containerized deployments has introduced new failure modes that conventional network management tools cannot adequately address. Legacy control mechanisms lack the granular visibility required to monitor ephemeral workloads and dynamic service meshes. Additionally, the static nature of traditional routing protocols and load balancing algorithms fails to adapt quickly enough to changing network conditions or traffic patterns.
Scalability constraints further compound these challenges as network infrastructures grow in size and complexity. Manual intervention requirements for configuration changes and fault resolution create bottlenecks that extend recovery times. The lack of intelligent automation in current control systems means that network operators must rely on time-consuming manual processes to diagnose issues and implement corrective measures.
Geographic distribution of modern applications across multiple data centers and cloud regions introduces additional complexity layers that existing control frameworks struggle to manage effectively. Cross-region latency variations, bandwidth limitations, and regional service dependencies create intricate failure scenarios that require sophisticated coordination mechanisms beyond the capabilities of current network control solutions.
The emergence of edge computing and Internet of Things deployments has created unprecedented demands for network resilience and adaptive control capabilities. Traditional centralized management approaches cannot provide the real-time responsiveness required for edge environments, where network conditions can change rapidly and unpredictably. These limitations highlight the urgent need for more intelligent, adaptive network control mechanisms that can proactively minimize downtime through predictive analytics and automated response systems.
Current network control systems exhibit significant limitations in their ability to predict and prevent service disruptions. Most existing solutions rely on threshold-based monitoring that triggers alerts only after problems have already impacted user experience. This reactive approach creates substantial gaps between fault detection and remediation, often resulting in extended downtime periods that cascade across interconnected services.
The proliferation of microservices architectures and containerized deployments has introduced new failure modes that conventional network management tools cannot adequately address. Legacy control mechanisms lack the granular visibility required to monitor ephemeral workloads and dynamic service meshes. Additionally, the static nature of traditional routing protocols and load balancing algorithms fails to adapt quickly enough to changing network conditions or traffic patterns.
Scalability constraints further compound these challenges as network infrastructures grow in size and complexity. Manual intervention requirements for configuration changes and fault resolution create bottlenecks that extend recovery times. The lack of intelligent automation in current control systems means that network operators must rely on time-consuming manual processes to diagnose issues and implement corrective measures.
Geographic distribution of modern applications across multiple data centers and cloud regions introduces additional complexity layers that existing control frameworks struggle to manage effectively. Cross-region latency variations, bandwidth limitations, and regional service dependencies create intricate failure scenarios that require sophisticated coordination mechanisms beyond the capabilities of current network control solutions.
The emergence of edge computing and Internet of Things deployments has created unprecedented demands for network resilience and adaptive control capabilities. Traditional centralized management approaches cannot provide the real-time responsiveness required for edge environments, where network conditions can change rapidly and unpredictably. These limitations highlight the urgent need for more intelligent, adaptive network control mechanisms that can proactively minimize downtime through predictive analytics and automated response systems.
Existing Adaptive Control Solutions for Downtime Minimization
01 Redundancy and failover mechanisms for network continuity
Implementation of redundant network components and automatic failover systems to maintain network operations during component failures. These mechanisms detect failures in primary network paths or devices and automatically switch to backup systems, minimizing downtime. The approach includes redundant controllers, backup communication paths, and seamless transition protocols to ensure continuous network availability.- Redundancy and failover mechanisms for network continuity: Implementation of redundant network components and automatic failover systems to maintain network operations during component failures. These mechanisms detect failures in primary network paths or devices and automatically switch to backup systems, minimizing downtime. The approach includes redundant controllers, backup communication paths, and seamless transition protocols to ensure continuous network availability.
- Predictive maintenance and fault detection systems: Advanced monitoring systems that analyze network performance metrics and predict potential failures before they occur. These systems use real-time data collection, pattern recognition, and anomaly detection to identify degrading components or network conditions. By proactively addressing issues, scheduled maintenance can be performed during planned downtime windows, reducing unexpected service interruptions.
- Dynamic resource allocation and load balancing: Adaptive systems that dynamically redistribute network traffic and resources based on current demand and system health. These solutions monitor network load in real-time and automatically adjust resource allocation to prevent overload conditions that could lead to downtime. The technology includes intelligent traffic routing, bandwidth management, and workload distribution across multiple network nodes.
- Automated recovery and self-healing network protocols: Self-healing network architectures that automatically detect, diagnose, and recover from failures without human intervention. These systems implement automated recovery procedures, configuration restoration, and service restart mechanisms. The technology reduces mean time to recovery by eliminating manual intervention requirements and implementing intelligent recovery algorithms that adapt to different failure scenarios.
- Network state preservation and rapid restoration: Technologies for capturing and preserving network state information to enable rapid restoration after downtime events. These solutions maintain snapshots of network configurations, active sessions, and operational parameters that can be quickly restored following interruptions. The approach minimizes service disruption by reducing the time required to return the network to its pre-failure operational state.
02 Predictive maintenance and fault detection systems
Advanced monitoring systems that analyze network performance metrics and predict potential failures before they occur. These systems use real-time data collection and analysis to identify degradation patterns, enabling proactive maintenance scheduling. By detecting anomalies early, network administrators can perform maintenance during planned windows, reducing unexpected downtime and improving overall network reliability.Expand Specific Solutions03 Dynamic resource allocation and load balancing
Adaptive systems that dynamically distribute network traffic and resources across available infrastructure to prevent overload conditions. These mechanisms monitor network utilization in real-time and automatically adjust resource allocation to maintain optimal performance. The technology helps prevent downtime caused by resource exhaustion and ensures efficient use of network capacity during varying demand conditions.Expand Specific Solutions04 Automated recovery and self-healing network protocols
Self-healing network architectures that automatically detect, diagnose, and recover from network failures without manual intervention. These systems implement automated recovery procedures that restore network functionality quickly after disruptions. The technology includes automatic reconfiguration capabilities, error correction mechanisms, and intelligent routing adjustments to minimize service interruption duration.Expand Specific Solutions05 Network state preservation and rapid restoration
Technologies for capturing and preserving network configuration states to enable rapid restoration after failures. These systems maintain snapshots of network settings, connection states, and operational parameters that can be quickly restored following downtime events. The approach reduces recovery time by eliminating the need for manual reconfiguration and ensures consistent network behavior after restoration.Expand Specific Solutions
Key Players in Network Infrastructure and Control Systems
The adaptive network control technology for minimizing downtime is experiencing rapid evolution, driven by the increasing demand for ultra-reliable network infrastructure across telecommunications and enterprise sectors. The market demonstrates significant growth potential as organizations prioritize network resilience and automated fault management. Technology maturity varies considerably among key players, with established telecommunications giants like Huawei Technologies, Ericsson, and Cisco Technology leading in comprehensive network automation solutions, while IBM and NEC Corp. contribute advanced AI-driven predictive analytics capabilities. Chinese carriers including China Mobile and China Telecom are actively implementing large-scale adaptive control systems, creating substantial market opportunities. Semiconductor companies like MediaTek and Samsung Electronics are developing specialized chipsets to support real-time network adaptation, indicating strong hardware-software integration trends in this evolving competitive landscape.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei implements Intent-Driven Network (IDN) architecture with AI-powered adaptive control systems that automatically detect network anomalies and perform real-time traffic rerouting to minimize service disruption. Their CloudFabric solution utilizes machine learning algorithms to predict potential failure points and proactively adjust network configurations, achieving 99.99% network availability. The system employs distributed control planes with automatic failover mechanisms and dynamic load balancing across multiple network paths to ensure continuous service delivery even during equipment failures or maintenance windows.
Strengths: Comprehensive AI-driven predictive analytics and extensive global deployment experience. Weaknesses: Limited interoperability with non-Huawei infrastructure components in heterogeneous environments.
International Business Machines Corp.
Technical Solution: IBM's Watson AIOps platform delivers adaptive network control through cognitive automation that combines real-time monitoring, predictive analytics, and automated incident response. The solution uses natural language processing to analyze network logs and correlate events across multiple systems, enabling proactive identification of potential issues before they cause service interruption. Their hybrid cloud networking approach provides automated failover between on-premises and cloud resources, with intelligent workload placement algorithms that optimize performance while minimizing downtime risks through redundant infrastructure utilization.
Strengths: Advanced AI capabilities with strong enterprise integration and hybrid cloud expertise. Weaknesses: Complex implementation requiring significant customization and integration efforts.
Core Innovations in Real-time Network Adaptation Patents
Minimization of network downtime
PatentActiveUS10601701B2
Innovation
- The system identifies paths connecting resource nodes to edge switches, calculates endpoint downtime costs, and determines candidate switches for redundancy by comparing costs, recommending an ordered sequence for switch upgrades to minimize network outages.




Traffic-adaptive network control systems and methods
PatentActiveUS10491501B2
Innovation
- A traffic-adaptive network control method that monitors network data, generates forecasts based on observed and external events, and orchestrates actions such as capacity recovery, reallocation, and addition using network applications to optimize resource utilization and minimize costs.
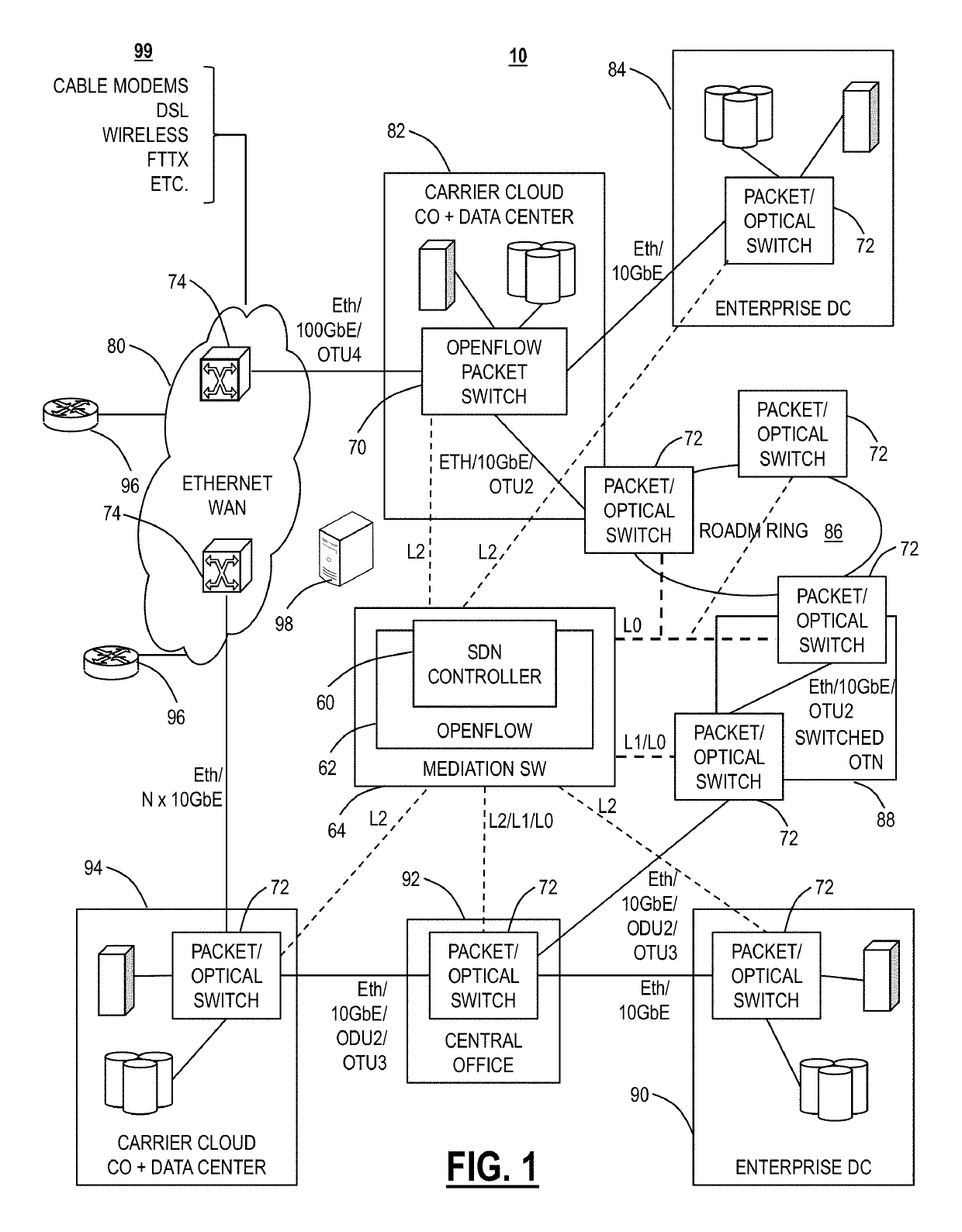
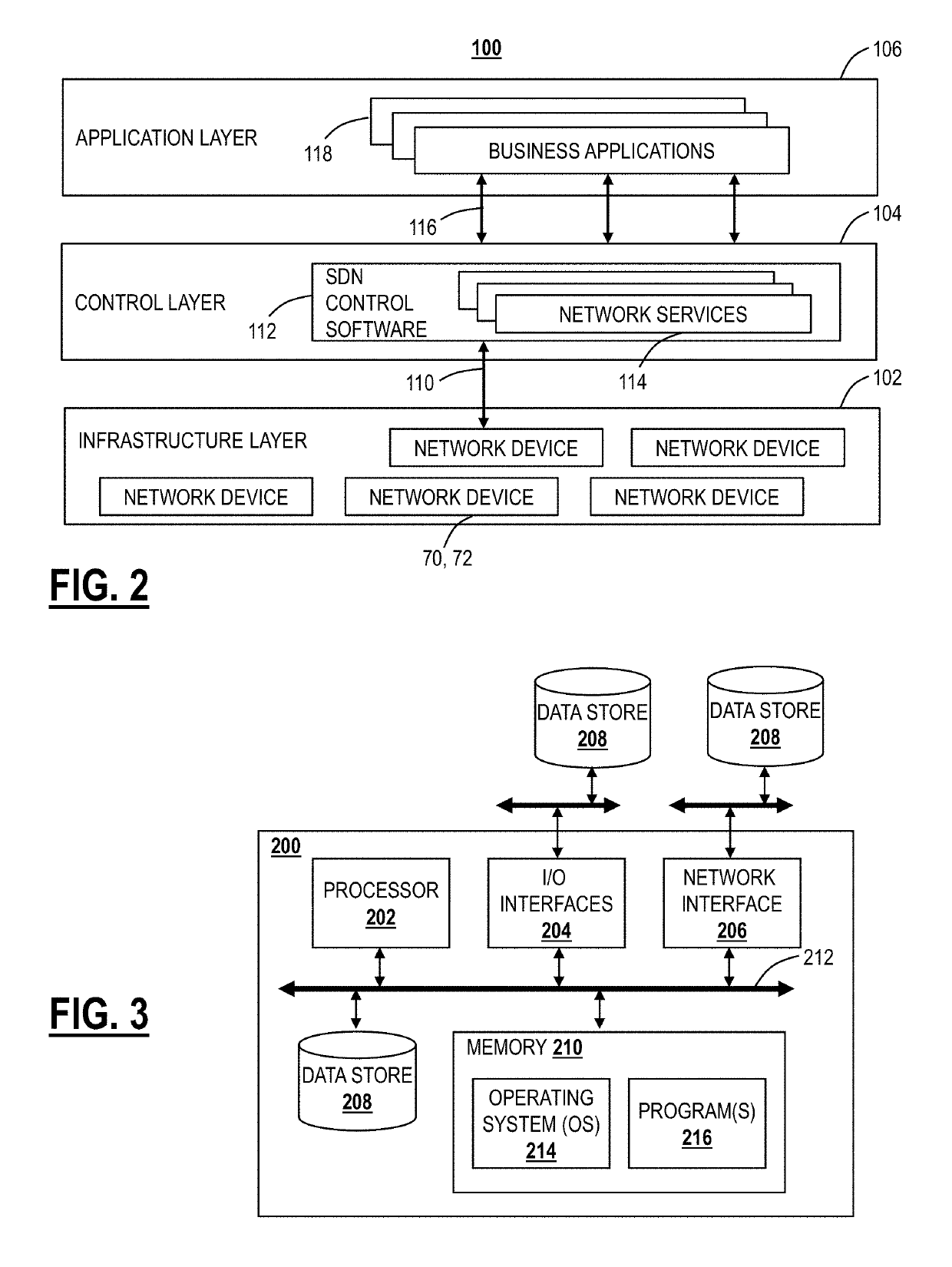


Network Resilience Standards and Compliance Requirements
Network resilience standards and compliance requirements form the regulatory backbone for implementing adaptive network control systems designed to minimize downtime. These frameworks establish mandatory performance thresholds, operational protocols, and risk management procedures that organizations must adhere to when deploying automated network management solutions.
The telecommunications industry operates under stringent regulatory oversight, with standards such as ITU-T Y.1540 series defining network performance parameters including availability targets of 99.999% uptime for critical infrastructure. Similarly, the IEEE 802.1 standards family provides specifications for network redundancy and fault tolerance mechanisms that directly impact adaptive control system design. These standards mandate specific recovery time objectives, typically requiring network restoration within milliseconds to seconds depending on service classification.
Financial services and healthcare sectors face additional compliance burdens through regulations like SOX, HIPAA, and PCI-DSS, which impose strict data availability and network security requirements. These regulations necessitate continuous monitoring capabilities and automated failover mechanisms that adaptive network control systems must seamlessly integrate with existing compliance monitoring infrastructure.
International standards organizations have developed comprehensive frameworks addressing network resilience. ISO/IEC 27031 provides guidelines for business continuity and disaster recovery planning, while NIST Cybersecurity Framework offers structured approaches to network resilience assessment and improvement. These standards emphasize the importance of adaptive response capabilities and real-time threat mitigation, directly supporting the implementation of intelligent network control systems.
Compliance verification presents unique challenges for adaptive network control implementations. Traditional audit processes may struggle to evaluate dynamic, algorithm-driven network management decisions. Organizations must establish comprehensive logging and documentation procedures that capture automated decision-making processes, enabling regulatory bodies to assess compliance effectiveness. This requirement drives the need for transparent, auditable adaptive control algorithms that can demonstrate adherence to established performance and security standards while maintaining operational flexibility.
The telecommunications industry operates under stringent regulatory oversight, with standards such as ITU-T Y.1540 series defining network performance parameters including availability targets of 99.999% uptime for critical infrastructure. Similarly, the IEEE 802.1 standards family provides specifications for network redundancy and fault tolerance mechanisms that directly impact adaptive control system design. These standards mandate specific recovery time objectives, typically requiring network restoration within milliseconds to seconds depending on service classification.
Financial services and healthcare sectors face additional compliance burdens through regulations like SOX, HIPAA, and PCI-DSS, which impose strict data availability and network security requirements. These regulations necessitate continuous monitoring capabilities and automated failover mechanisms that adaptive network control systems must seamlessly integrate with existing compliance monitoring infrastructure.
International standards organizations have developed comprehensive frameworks addressing network resilience. ISO/IEC 27031 provides guidelines for business continuity and disaster recovery planning, while NIST Cybersecurity Framework offers structured approaches to network resilience assessment and improvement. These standards emphasize the importance of adaptive response capabilities and real-time threat mitigation, directly supporting the implementation of intelligent network control systems.
Compliance verification presents unique challenges for adaptive network control implementations. Traditional audit processes may struggle to evaluate dynamic, algorithm-driven network management decisions. Organizations must establish comprehensive logging and documentation procedures that capture automated decision-making processes, enabling regulatory bodies to assess compliance effectiveness. This requirement drives the need for transparent, auditable adaptive control algorithms that can demonstrate adherence to established performance and security standards while maintaining operational flexibility.
Economic Impact Assessment of Network Downtime Costs
Network downtime represents one of the most significant operational risks facing modern enterprises, with financial implications that extend far beyond immediate revenue losses. The economic impact of network outages encompasses direct costs, indirect consequences, and long-term strategic implications that collectively threaten organizational sustainability and competitive positioning.
Direct financial losses constitute the most immediately quantifiable impact of network downtime. Revenue disruption occurs when e-commerce platforms, transaction systems, or customer-facing services become unavailable, directly correlating downtime duration with lost sales opportunities. Industry studies indicate that large enterprises can experience hourly revenue losses ranging from $100,000 to over $1 million during critical system outages, depending on business model and operational scale.
Productivity degradation represents another substantial cost category, as employee efficiency plummets when essential digital tools and communication systems become inaccessible. Organizations typically experience 70-90% productivity reduction during network outages, translating to significant labor cost inefficiencies. Remote work environments amplify these impacts, as distributed teams become completely disconnected from collaborative platforms and shared resources.
Customer experience deterioration generates both immediate and long-term economic consequences. Service level agreement violations result in contractual penalties and potential customer churn, while brand reputation damage can persist long after technical issues are resolved. Research demonstrates that 25% of customers consider switching providers after experiencing a single significant service disruption, with acquisition costs for replacement customers typically exceeding retention investments by 5-25 times.
Operational recovery expenses extend beyond immediate technical remediation efforts. Emergency response procedures, overtime compensation, expedited vendor services, and system restoration activities generate substantial unplanned expenditures. Additionally, regulatory compliance violations during outages can trigger financial penalties and audit requirements, further escalating total cost impact.
The cumulative economic burden of network downtime creates compelling justification for investing in adaptive network control technologies. Organizations implementing proactive downtime minimization strategies typically achieve 60-80% reduction in outage frequency and duration, generating return on investment through avoided costs that significantly exceed initial technology deployment expenses.
Direct financial losses constitute the most immediately quantifiable impact of network downtime. Revenue disruption occurs when e-commerce platforms, transaction systems, or customer-facing services become unavailable, directly correlating downtime duration with lost sales opportunities. Industry studies indicate that large enterprises can experience hourly revenue losses ranging from $100,000 to over $1 million during critical system outages, depending on business model and operational scale.
Productivity degradation represents another substantial cost category, as employee efficiency plummets when essential digital tools and communication systems become inaccessible. Organizations typically experience 70-90% productivity reduction during network outages, translating to significant labor cost inefficiencies. Remote work environments amplify these impacts, as distributed teams become completely disconnected from collaborative platforms and shared resources.
Customer experience deterioration generates both immediate and long-term economic consequences. Service level agreement violations result in contractual penalties and potential customer churn, while brand reputation damage can persist long after technical issues are resolved. Research demonstrates that 25% of customers consider switching providers after experiencing a single significant service disruption, with acquisition costs for replacement customers typically exceeding retention investments by 5-25 times.
Operational recovery expenses extend beyond immediate technical remediation efforts. Emergency response procedures, overtime compensation, expedited vendor services, and system restoration activities generate substantial unplanned expenditures. Additionally, regulatory compliance violations during outages can trigger financial penalties and audit requirements, further escalating total cost impact.
The cumulative economic burden of network downtime creates compelling justification for investing in adaptive network control technologies. Organizations implementing proactive downtime minimization strategies typically achieve 60-80% reduction in outage frequency and duration, generating return on investment through avoided costs that significantly exceed initial technology deployment expenses.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!