

Racetrack Memory vs GPU Memory: Data Integrity Under Extreme Loads
MAY 14, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Racetrack vs GPU Memory Technology Background and Objectives
The evolution of memory technologies has been driven by the relentless demand for higher performance, greater capacity, and improved energy efficiency in computing systems. Traditional memory architectures face increasing challenges as data-intensive applications push the boundaries of existing solutions. The emergence of specialized memory technologies represents a critical response to these evolving computational demands.
Racetrack memory, developed by IBM, represents a revolutionary approach to data storage based on magnetic domain wall motion in nanowires. This technology leverages the principles of spintronics, where information is encoded in the magnetic orientation of domains within ferromagnetic nanowires. The fundamental innovation lies in its ability to achieve high density storage while maintaining non-volatility and potentially offering superior endurance compared to conventional memory technologies.
GPU memory systems have undergone significant transformation to support the exponential growth in parallel computing applications. Modern GPU architectures incorporate sophisticated memory hierarchies, including high-bandwidth memory (HBM) and graphics double data rate (GDDR) technologies. These systems are specifically optimized for massive parallel data processing, featuring wide memory buses and advanced error correction mechanisms to handle the intensive computational workloads characteristic of graphics rendering, machine learning, and scientific computing applications.
The primary objective of comparing these technologies under extreme load conditions centers on understanding their respective data integrity capabilities. Extreme loads encompass scenarios involving high-frequency read/write operations, elevated temperatures, electromagnetic interference, and sustained operational stress that can compromise data reliability. This analysis aims to evaluate how each technology maintains data coherence and accuracy when subjected to demanding operational environments.
Data integrity becomes paramount in mission-critical applications where memory corruption can lead to system failures, computational errors, or security vulnerabilities. The investigation seeks to establish performance benchmarks, identify failure modes, and determine the operational boundaries where each technology maintains acceptable error rates. Understanding these characteristics is essential for making informed decisions about memory technology deployment in high-performance computing environments, autonomous systems, and other applications where data reliability is non-negotiable.
Racetrack memory, developed by IBM, represents a revolutionary approach to data storage based on magnetic domain wall motion in nanowires. This technology leverages the principles of spintronics, where information is encoded in the magnetic orientation of domains within ferromagnetic nanowires. The fundamental innovation lies in its ability to achieve high density storage while maintaining non-volatility and potentially offering superior endurance compared to conventional memory technologies.
GPU memory systems have undergone significant transformation to support the exponential growth in parallel computing applications. Modern GPU architectures incorporate sophisticated memory hierarchies, including high-bandwidth memory (HBM) and graphics double data rate (GDDR) technologies. These systems are specifically optimized for massive parallel data processing, featuring wide memory buses and advanced error correction mechanisms to handle the intensive computational workloads characteristic of graphics rendering, machine learning, and scientific computing applications.
The primary objective of comparing these technologies under extreme load conditions centers on understanding their respective data integrity capabilities. Extreme loads encompass scenarios involving high-frequency read/write operations, elevated temperatures, electromagnetic interference, and sustained operational stress that can compromise data reliability. This analysis aims to evaluate how each technology maintains data coherence and accuracy when subjected to demanding operational environments.
Data integrity becomes paramount in mission-critical applications where memory corruption can lead to system failures, computational errors, or security vulnerabilities. The investigation seeks to establish performance benchmarks, identify failure modes, and determine the operational boundaries where each technology maintains acceptable error rates. Understanding these characteristics is essential for making informed decisions about memory technology deployment in high-performance computing environments, autonomous systems, and other applications where data reliability is non-negotiable.
Market Demand for High-Performance Memory Under Extreme Computing Loads
The global computing landscape is experiencing unprecedented demand for high-performance memory solutions capable of maintaining data integrity under extreme computational loads. This surge is primarily driven by the exponential growth in artificial intelligence workloads, high-performance computing applications, and real-time data processing requirements across multiple industries.
Data centers worldwide are grappling with increasingly complex workloads that push memory systems to their operational limits. Machine learning training processes, particularly for large language models and deep neural networks, require sustained high-bandwidth memory access with zero tolerance for data corruption. Similarly, scientific computing applications in fields such as climate modeling, genomics research, and quantum simulations demand memory systems that can handle massive datasets while preserving data accuracy throughout extended processing cycles.
The automotive industry's transition toward autonomous vehicles has created substantial demand for memory solutions that can operate reliably under extreme environmental conditions while processing sensor data in real-time. These applications require memory systems that maintain data integrity despite temperature fluctuations, electromagnetic interference, and continuous high-throughput operations spanning years of deployment.
Financial services sector presents another critical market segment where memory reliability directly impacts business operations. High-frequency trading systems, risk analysis platforms, and blockchain processing require memory solutions that can handle intensive computational loads while ensuring absolute data accuracy. Any memory-related data corruption in these environments can result in significant financial losses and regulatory compliance issues.
Edge computing deployments are expanding rapidly across industrial IoT applications, smart city infrastructure, and telecommunications networks. These environments often subject memory systems to harsh operating conditions including extreme temperatures, vibration, and power fluctuations, while demanding consistent performance and data reliability.
The gaming and entertainment industry continues to push memory performance boundaries through increasingly sophisticated graphics rendering, virtual reality applications, and real-time content generation. These applications require memory systems capable of sustaining high bandwidth utilization while maintaining visual fidelity and preventing artifacts caused by data corruption.
Cloud service providers are actively seeking memory technologies that can deliver superior performance density while reducing total cost of ownership. The ability to maintain data integrity under extreme loads directly impacts service reliability, customer satisfaction, and operational efficiency across distributed computing environments.
Data centers worldwide are grappling with increasingly complex workloads that push memory systems to their operational limits. Machine learning training processes, particularly for large language models and deep neural networks, require sustained high-bandwidth memory access with zero tolerance for data corruption. Similarly, scientific computing applications in fields such as climate modeling, genomics research, and quantum simulations demand memory systems that can handle massive datasets while preserving data accuracy throughout extended processing cycles.
The automotive industry's transition toward autonomous vehicles has created substantial demand for memory solutions that can operate reliably under extreme environmental conditions while processing sensor data in real-time. These applications require memory systems that maintain data integrity despite temperature fluctuations, electromagnetic interference, and continuous high-throughput operations spanning years of deployment.
Financial services sector presents another critical market segment where memory reliability directly impacts business operations. High-frequency trading systems, risk analysis platforms, and blockchain processing require memory solutions that can handle intensive computational loads while ensuring absolute data accuracy. Any memory-related data corruption in these environments can result in significant financial losses and regulatory compliance issues.
Edge computing deployments are expanding rapidly across industrial IoT applications, smart city infrastructure, and telecommunications networks. These environments often subject memory systems to harsh operating conditions including extreme temperatures, vibration, and power fluctuations, while demanding consistent performance and data reliability.
The gaming and entertainment industry continues to push memory performance boundaries through increasingly sophisticated graphics rendering, virtual reality applications, and real-time content generation. These applications require memory systems capable of sustaining high bandwidth utilization while maintaining visual fidelity and preventing artifacts caused by data corruption.
Cloud service providers are actively seeking memory technologies that can deliver superior performance density while reducing total cost of ownership. The ability to maintain data integrity under extreme loads directly impacts service reliability, customer satisfaction, and operational efficiency across distributed computing environments.
Current State and Data Integrity Challenges in Memory Technologies
The contemporary memory technology landscape is characterized by the dominance of traditional solutions alongside emerging alternatives that promise revolutionary performance improvements. GPU memory systems, primarily based on High Bandwidth Memory (HBM) and Graphics Double Data Rate (GDDR) technologies, have established themselves as the cornerstone of high-performance computing applications. These systems deliver exceptional bandwidth capabilities, with HBM3 achieving up to 819 GB/s per stack and GDDR6X reaching speeds of 21 Gbps per pin.
However, the relentless pursuit of higher performance and energy efficiency has exposed critical limitations in conventional memory architectures. Power consumption remains a significant concern, with GPU memory subsystems accounting for 20-40% of total system power draw during intensive workloads. Additionally, the physical constraints of DRAM scaling are becoming increasingly apparent as manufacturers approach the limits of process node miniaturization.
Racetrack memory represents a paradigm shift in non-volatile storage technology, leveraging magnetic domain walls in nanowires to achieve unprecedented density and speed characteristics. Current prototypes demonstrate access times in the sub-nanosecond range while maintaining non-volatility, positioning this technology as a potential bridge between traditional memory and storage hierarchies. The technology's ability to store multiple bits per device through domain wall manipulation offers theoretical storage densities exceeding conventional DRAM by orders of magnitude.
Data integrity challenges intensify significantly under extreme computational loads, where both memory technologies face distinct vulnerabilities. GPU memory systems encounter soft errors from cosmic radiation, thermal-induced bit flips, and voltage fluctuations that become more pronounced at higher operating frequencies. Error correction mechanisms, while effective, introduce latency penalties that can impact real-time processing requirements.
Racetrack memory confronts different integrity challenges, primarily related to domain wall stability and magnetic field interference. The technology's reliance on precise magnetic domain positioning makes it susceptible to external electromagnetic fields and thermal fluctuations that can cause domain wall drift or collapse. Current implementations require sophisticated error detection and correction algorithms specifically designed for magnetic storage anomalies.
The convergence of these technologies under extreme loads reveals fundamental trade-offs between performance, power efficiency, and data reliability that will shape future memory system architectures.
However, the relentless pursuit of higher performance and energy efficiency has exposed critical limitations in conventional memory architectures. Power consumption remains a significant concern, with GPU memory subsystems accounting for 20-40% of total system power draw during intensive workloads. Additionally, the physical constraints of DRAM scaling are becoming increasingly apparent as manufacturers approach the limits of process node miniaturization.
Racetrack memory represents a paradigm shift in non-volatile storage technology, leveraging magnetic domain walls in nanowires to achieve unprecedented density and speed characteristics. Current prototypes demonstrate access times in the sub-nanosecond range while maintaining non-volatility, positioning this technology as a potential bridge between traditional memory and storage hierarchies. The technology's ability to store multiple bits per device through domain wall manipulation offers theoretical storage densities exceeding conventional DRAM by orders of magnitude.
Data integrity challenges intensify significantly under extreme computational loads, where both memory technologies face distinct vulnerabilities. GPU memory systems encounter soft errors from cosmic radiation, thermal-induced bit flips, and voltage fluctuations that become more pronounced at higher operating frequencies. Error correction mechanisms, while effective, introduce latency penalties that can impact real-time processing requirements.
Racetrack memory confronts different integrity challenges, primarily related to domain wall stability and magnetic field interference. The technology's reliance on precise magnetic domain positioning makes it susceptible to external electromagnetic fields and thermal fluctuations that can cause domain wall drift or collapse. Current implementations require sophisticated error detection and correction algorithms specifically designed for magnetic storage anomalies.
The convergence of these technologies under extreme loads reveals fundamental trade-offs between performance, power efficiency, and data reliability that will shape future memory system architectures.
Existing Data Integrity Solutions for Extreme Load Scenarios
01 Error correction and detection mechanisms for memory systems
Implementation of advanced error correction codes and detection algorithms to ensure data integrity in high-speed memory architectures. These mechanisms include parity checking, cyclic redundancy checks, and multi-bit error correction techniques that can identify and correct data corruption in real-time during memory operations.- Error correction and detection mechanisms for memory systems: Implementation of advanced error correction codes and detection algorithms to maintain data integrity in high-speed memory architectures. These mechanisms include parity checking, cyclic redundancy checks, and multi-bit error correction techniques that can identify and correct data corruption in real-time during memory operations.
- Memory controller architectures for data protection: Specialized memory controller designs that incorporate built-in data integrity features for managing memory access patterns and ensuring reliable data storage and retrieval. These controllers implement sophisticated algorithms for memory management, wear leveling, and fault tolerance to prevent data loss and corruption.
- Redundancy and backup systems for memory reliability: Implementation of redundant storage mechanisms and backup systems that create multiple copies of critical data across different memory locations or devices. These systems provide failover capabilities and automatic recovery procedures to maintain system operation even when individual memory components fail.
- Real-time monitoring and diagnostic systems: Advanced monitoring systems that continuously track memory performance metrics, detect anomalies, and provide early warning of potential failures. These diagnostic tools analyze memory access patterns, temperature variations, and electrical characteristics to predict and prevent data integrity issues before they occur.
- Adaptive memory management and optimization techniques: Dynamic memory management strategies that adapt to changing workload conditions and optimize data placement for maximum reliability and performance. These techniques include intelligent caching algorithms, predictive prefetching, and adaptive error correction strength based on memory usage patterns and environmental conditions.
02 Memory controller architectures for data integrity
Specialized memory controller designs that manage data flow and integrity verification between processing units and memory storage. These controllers implement sophisticated algorithms for data validation, redundancy management, and fault tolerance to maintain system reliability under various operating conditions.Expand Specific Solutions03 Redundant storage and backup systems
Implementation of redundant data storage mechanisms and backup systems that create multiple copies of critical data across different memory locations. These systems provide failover capabilities and data recovery options when primary storage experiences corruption or failure.Expand Specific Solutions04 Real-time monitoring and validation techniques
Continuous monitoring systems that perform real-time validation of data integrity through checksums, hash verification, and pattern analysis. These techniques enable immediate detection of data corruption and trigger corrective actions to maintain system stability and data accuracy.Expand Specific Solutions05 Power management and data preservation
Power management strategies specifically designed to preserve data integrity during power fluctuations, transitions, and failure scenarios. These approaches include capacitive backup systems, voltage regulation, and graceful shutdown procedures that prevent data loss during unexpected power events.Expand Specific Solutions
Key Players in Advanced Memory and GPU Industries
The racetrack memory versus GPU memory competition represents an emerging battleground in next-generation data storage and processing technologies. The industry is in its early developmental stage, with racetrack memory still largely in research phases while GPU memory technologies are commercially mature. Market dynamics show established players like NVIDIA, Samsung, and Micron dominating GPU memory solutions with proven high-bandwidth architectures, while companies such as IBM and research institutions like Max Planck Society are pioneering racetrack memory innovations. Technology maturity varies significantly - GPU memory benefits from decades of optimization by Intel, AMD, and TSMC, achieving robust data integrity under extreme computational loads. Conversely, racetrack memory technology remains experimental, with organizations like Qualcomm and GlobalFoundries exploring its potential for ultra-dense, low-power storage applications that could revolutionize data center architectures.
NVIDIA Corp.
Technical Solution: NVIDIA has developed comprehensive GPU memory integrity solutions including Error Correcting Code (ECC) memory technology across their data center and professional GPU lines. Their approach combines hardware-level ECC protection with advanced memory controllers that can detect and correct single-bit errors while detecting multi-bit errors. Under extreme computational loads, NVIDIA GPUs implement dynamic memory management with real-time error monitoring and correction capabilities. The company's latest Hopper and Ada Lovelace architectures feature enhanced memory subsystems with improved bandwidth and reliability mechanisms, including advanced thermal management and power delivery systems that maintain data integrity even during peak performance scenarios.
Strengths: Market-leading GPU technology with proven ECC implementation and extensive ecosystem support. Weaknesses: High power consumption and cost compared to traditional memory solutions, limited racetrack memory research.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung has been actively researching and developing racetrack memory technology as part of their next-generation memory solutions portfolio. Their approach focuses on spin-transfer torque mechanisms for data manipulation in magnetic nanowires, offering potential for ultra-high density storage with improved data integrity characteristics. Samsung's racetrack memory research emphasizes reducing power consumption while maintaining data reliability under extreme operational conditions. The company has demonstrated prototype devices that can withstand high-stress environments while preserving data integrity through advanced magnetic domain wall engineering and sophisticated error correction algorithms integrated at the device level.
Strengths: Leading memory manufacturer with strong R&D capabilities in emerging memory technologies and established manufacturing infrastructure. Weaknesses: Racetrack memory still in research phase with limited commercial availability and unproven scalability at industrial levels.
Core Innovations in Memory Error Correction and Reliability
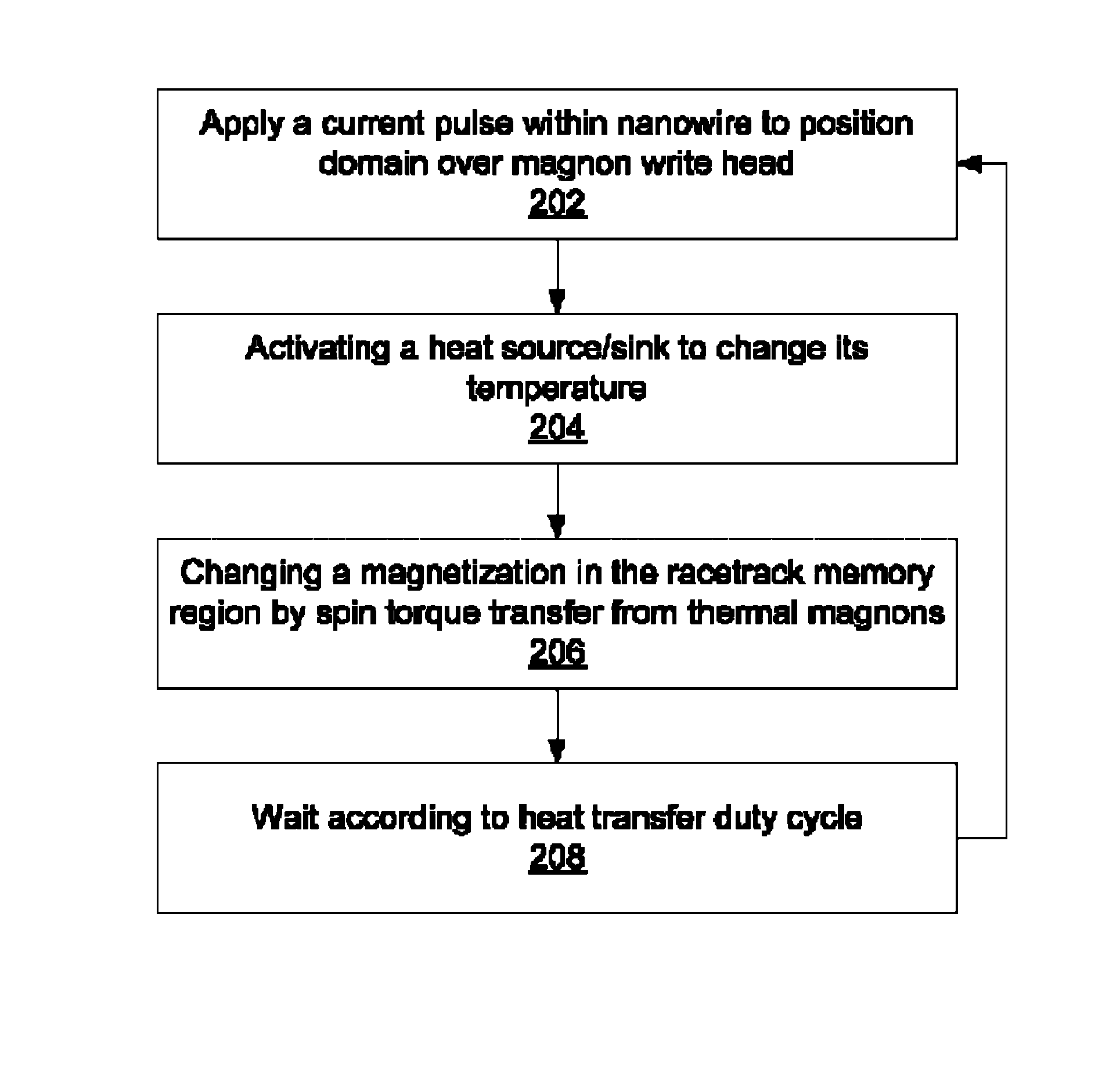
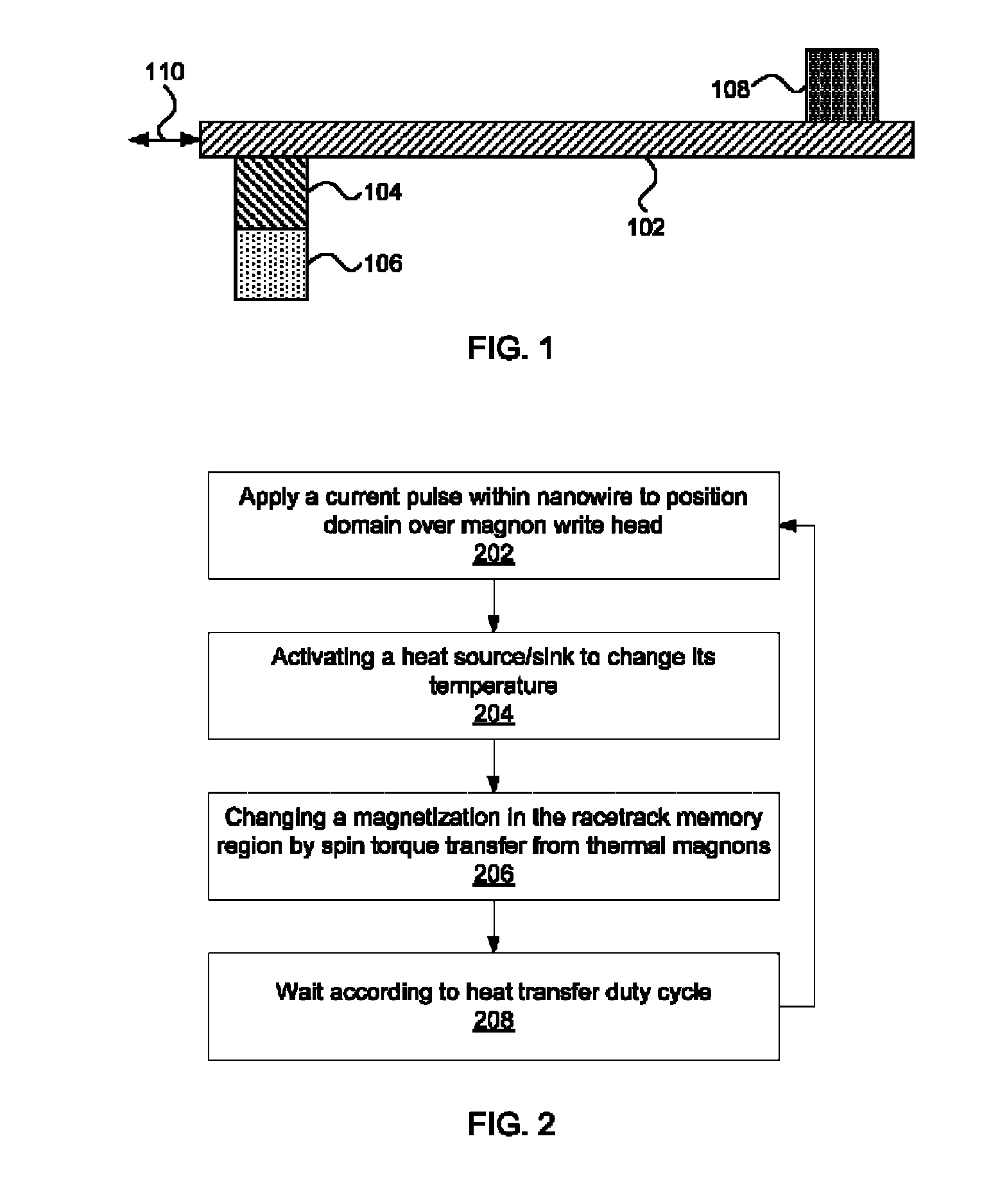
Racetrack memory with low-power write
PatentInactiveUS8750013B1
Innovation
- A racetrack memory unit utilizing a heat source/sink to generate magnons, which propagate and inject domain walls through spin torque transfer, reducing the need for high currents and enhancing the stability of the memory device.

Device for data storage and processing, and method thereof
PatentWO2021019322A1
Innovation
- A novel non-volatile racetrack memory device that executes elementary logic functions internally, allowing parallel processing of data without additional circuits, using magnetic coupling between input and output magnetization regions to perform operations like NOR and NAND gates.




Industry Standards for Memory Reliability and Testing
Memory reliability standards have evolved significantly to address the growing demands of high-performance computing systems. The Joint Electron Device Engineering Council (JEDEC) serves as the primary standardization body, establishing fundamental specifications for memory devices including error correction capabilities, thermal management, and operational parameters. JEDEC standards such as JESD79 for DDR memory and JESD235 for High Bandwidth Memory define critical reliability metrics including bit error rates, retention times, and endurance cycles.
International standards organizations including IEEE and IEC have developed comprehensive testing methodologies for memory systems under extreme operational conditions. IEEE 1149.1 boundary scan testing enables comprehensive fault detection, while IEC 61508 functional safety standards provide frameworks for assessing memory reliability in safety-critical applications. These standards establish baseline requirements for data integrity verification across different memory technologies.
Industry-specific reliability testing protocols have emerged to address unique challenges in high-performance computing environments. The Storage Networking Industry Association (SNIA) has developed solid-state storage testing standards that evaluate performance degradation under sustained workloads. Similarly, the PCI Special Interest Group maintains specifications for memory interface reliability, particularly relevant for GPU memory systems operating at extreme bandwidths.
Emerging memory technologies like racetrack memory face standardization challenges due to their novel operational principles. Current testing methodologies primarily focus on traditional charge-based storage mechanisms, necessitating development of new evaluation frameworks for magnetic domain-based storage systems. The Magnetic Memory Technology Roadmap consortium has initiated efforts to establish reliability benchmarks specific to spintronic memory devices.
Accelerated aging tests and stress testing protocols form the cornerstone of memory reliability validation. Temperature cycling, voltage stress testing, and high-frequency operational testing simulate years of operational conditions within compressed timeframes. These methodologies enable comparative analysis between conventional GPU memory and emerging technologies like racetrack memory under equivalent stress conditions.
The integration of artificial intelligence in testing protocols represents a significant advancement in reliability assessment. Machine learning algorithms can identify subtle degradation patterns and predict failure modes that traditional testing might overlook, particularly crucial for evaluating data integrity under extreme computational loads where conventional testing approaches may prove insufficient.
International standards organizations including IEEE and IEC have developed comprehensive testing methodologies for memory systems under extreme operational conditions. IEEE 1149.1 boundary scan testing enables comprehensive fault detection, while IEC 61508 functional safety standards provide frameworks for assessing memory reliability in safety-critical applications. These standards establish baseline requirements for data integrity verification across different memory technologies.
Industry-specific reliability testing protocols have emerged to address unique challenges in high-performance computing environments. The Storage Networking Industry Association (SNIA) has developed solid-state storage testing standards that evaluate performance degradation under sustained workloads. Similarly, the PCI Special Interest Group maintains specifications for memory interface reliability, particularly relevant for GPU memory systems operating at extreme bandwidths.
Emerging memory technologies like racetrack memory face standardization challenges due to their novel operational principles. Current testing methodologies primarily focus on traditional charge-based storage mechanisms, necessitating development of new evaluation frameworks for magnetic domain-based storage systems. The Magnetic Memory Technology Roadmap consortium has initiated efforts to establish reliability benchmarks specific to spintronic memory devices.
Accelerated aging tests and stress testing protocols form the cornerstone of memory reliability validation. Temperature cycling, voltage stress testing, and high-frequency operational testing simulate years of operational conditions within compressed timeframes. These methodologies enable comparative analysis between conventional GPU memory and emerging technologies like racetrack memory under equivalent stress conditions.
The integration of artificial intelligence in testing protocols represents a significant advancement in reliability assessment. Machine learning algorithms can identify subtle degradation patterns and predict failure modes that traditional testing might overlook, particularly crucial for evaluating data integrity under extreme computational loads where conventional testing approaches may prove insufficient.
Thermal Management Impact on Memory Data Integrity
Thermal management represents a critical factor in maintaining data integrity for both racetrack memory and GPU memory systems under extreme computational loads. As processing demands intensify, heat generation becomes a primary concern that directly impacts the reliability and accuracy of stored data across different memory architectures.
Racetrack memory demonstrates unique thermal characteristics due to its magnetic domain wall manipulation mechanism. The current-driven domain wall motion generates localized heating effects that can alter magnetic properties and potentially corrupt stored information. Temperature fluctuations affect the magnetic anisotropy and coercivity of the ferromagnetic materials, leading to unpredictable domain wall behavior and increased error rates during read and write operations.
GPU memory systems, particularly high-bandwidth memory configurations, face distinct thermal challenges under extreme loads. Elevated temperatures cause increased leakage currents in DRAM cells, reducing charge retention times and compromising data stability. The proximity of memory dies in 3D-stacked architectures exacerbates thermal coupling effects, creating hotspots that disproportionately impact specific memory regions.
Temperature-induced timing variations present another significant concern for both memory types. Thermal expansion and contraction affect signal propagation delays, potentially causing setup and hold time violations that result in data corruption. These effects become particularly pronounced during rapid temperature transitions common in high-performance computing scenarios.
Effective thermal management strategies must address architecture-specific vulnerabilities while maintaining performance objectives. For racetrack memory, thermal solutions focus on minimizing current-induced heating through optimized pulse sequences and advanced heat dissipation techniques. GPU memory systems require sophisticated cooling solutions that address both individual die temperatures and thermal gradients across memory stacks.
The implementation of real-time thermal monitoring and adaptive control mechanisms becomes essential for preserving data integrity. Dynamic thermal throttling, temperature-aware error correction algorithms, and predictive thermal modeling contribute to maintaining reliable operation under varying thermal conditions while maximizing system performance capabilities.
Racetrack memory demonstrates unique thermal characteristics due to its magnetic domain wall manipulation mechanism. The current-driven domain wall motion generates localized heating effects that can alter magnetic properties and potentially corrupt stored information. Temperature fluctuations affect the magnetic anisotropy and coercivity of the ferromagnetic materials, leading to unpredictable domain wall behavior and increased error rates during read and write operations.
GPU memory systems, particularly high-bandwidth memory configurations, face distinct thermal challenges under extreme loads. Elevated temperatures cause increased leakage currents in DRAM cells, reducing charge retention times and compromising data stability. The proximity of memory dies in 3D-stacked architectures exacerbates thermal coupling effects, creating hotspots that disproportionately impact specific memory regions.
Temperature-induced timing variations present another significant concern for both memory types. Thermal expansion and contraction affect signal propagation delays, potentially causing setup and hold time violations that result in data corruption. These effects become particularly pronounced during rapid temperature transitions common in high-performance computing scenarios.
Effective thermal management strategies must address architecture-specific vulnerabilities while maintaining performance objectives. For racetrack memory, thermal solutions focus on minimizing current-induced heating through optimized pulse sequences and advanced heat dissipation techniques. GPU memory systems require sophisticated cooling solutions that address both individual die temperatures and thermal gradients across memory stacks.
The implementation of real-time thermal monitoring and adaptive control mechanisms becomes essential for preserving data integrity. Dynamic thermal throttling, temperature-aware error correction algorithms, and predictive thermal modeling contribute to maintaining reliable operation under varying thermal conditions while maximizing system performance capabilities.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!