

Optimize Computational Lithography Algorithms for Faster Processing
APR 24, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Computational Lithography Background and Optimization Goals
Computational lithography has emerged as a critical enabling technology in semiconductor manufacturing, fundamentally transforming how integrated circuits are designed and fabricated. This field encompasses sophisticated mathematical algorithms and computational techniques that bridge the gap between circuit design intent and physical manufacturing reality. As semiconductor devices continue to scale toward increasingly smaller feature sizes, the wavelength of light used in photolithography has remained relatively constant, creating fundamental physical limitations that computational methods must overcome.
The evolution of computational lithography began in the 1990s when traditional optical proximity correction (OPC) techniques proved insufficient for sub-wavelength lithography. Early implementations focused on simple rule-based corrections, but the industry quickly recognized the need for model-based approaches that could accurately predict and compensate for optical and process effects. This transition marked the beginning of computationally intensive lithography workflows that have become standard practice in advanced semiconductor manufacturing.
Modern computational lithography encompasses multiple interconnected domains including optical proximity correction, phase shift mask optimization, source mask optimization (SMO), and inverse lithography technology (ILT). Each domain presents unique computational challenges, requiring sophisticated algorithms to solve complex optimization problems within practical timeframes. The computational burden has grown exponentially with each technology node, as the number of features requiring correction increases while the acceptable error margins decrease.
Current optimization goals center on achieving faster processing speeds without compromising accuracy or manufacturability. The primary objective involves developing algorithms that can handle full-chip layouts containing billions of features while maintaining sub-nanometer precision requirements. Processing time reduction targets typically aim for 2-10x improvements over existing methods, enabling practical implementation in production environments where turnaround time directly impacts product development cycles.
Secondary optimization goals include improving algorithm convergence rates, reducing memory footprint requirements, and enhancing parallel processing capabilities. These objectives address the practical constraints of computational infrastructure while ensuring scalability for future technology nodes. The ultimate goal involves creating adaptive algorithms that can automatically balance speed, accuracy, and resource utilization based on specific design requirements and manufacturing constraints.
The evolution of computational lithography began in the 1990s when traditional optical proximity correction (OPC) techniques proved insufficient for sub-wavelength lithography. Early implementations focused on simple rule-based corrections, but the industry quickly recognized the need for model-based approaches that could accurately predict and compensate for optical and process effects. This transition marked the beginning of computationally intensive lithography workflows that have become standard practice in advanced semiconductor manufacturing.
Modern computational lithography encompasses multiple interconnected domains including optical proximity correction, phase shift mask optimization, source mask optimization (SMO), and inverse lithography technology (ILT). Each domain presents unique computational challenges, requiring sophisticated algorithms to solve complex optimization problems within practical timeframes. The computational burden has grown exponentially with each technology node, as the number of features requiring correction increases while the acceptable error margins decrease.
Current optimization goals center on achieving faster processing speeds without compromising accuracy or manufacturability. The primary objective involves developing algorithms that can handle full-chip layouts containing billions of features while maintaining sub-nanometer precision requirements. Processing time reduction targets typically aim for 2-10x improvements over existing methods, enabling practical implementation in production environments where turnaround time directly impacts product development cycles.
Secondary optimization goals include improving algorithm convergence rates, reducing memory footprint requirements, and enhancing parallel processing capabilities. These objectives address the practical constraints of computational infrastructure while ensuring scalability for future technology nodes. The ultimate goal involves creating adaptive algorithms that can automatically balance speed, accuracy, and resource utilization based on specific design requirements and manufacturing constraints.
Market Demand for Advanced Lithography Processing Solutions
The semiconductor industry faces unprecedented demand for advanced lithography processing solutions driven by the relentless pursuit of smaller node technologies and higher chip performance. As device geometries continue to shrink below 7nm and approach 3nm processes, traditional lithography approaches encounter fundamental physical limitations that necessitate sophisticated computational solutions. The complexity of manufacturing at these scales has created an urgent market need for optimized computational lithography algorithms that can deliver faster processing without compromising accuracy.
Leading semiconductor manufacturers are experiencing significant bottlenecks in their production workflows due to the computational intensity of current lithography algorithms. These bottlenecks directly impact time-to-market for new products and increase manufacturing costs, creating substantial pressure for algorithmic improvements. The market demand is particularly acute among foundries serving high-volume applications such as mobile processors, graphics processing units, and artificial intelligence accelerators.
The emergence of extreme ultraviolet lithography and multi-patterning techniques has exponentially increased the computational requirements for mask optimization, optical proximity correction, and source mask optimization processes. Current processing times for complex designs can extend to weeks or months, creating unacceptable delays in product development cycles. This has generated strong market pull for algorithmic innovations that can reduce processing times by orders of magnitude while maintaining the precision required for advanced node manufacturing.
Market research indicates that semiconductor companies are willing to invest substantially in computational lithography solutions that demonstrate measurable improvements in processing speed. The total addressable market encompasses not only major foundries but also integrated device manufacturers, mask shops, and electronic design automation companies that require faster turnaround times for their lithography-related workflows.
The demand extends beyond pure speed improvements to include enhanced scalability for handling increasingly complex designs with billions of features. Market requirements also emphasize the need for algorithms that can efficiently utilize modern high-performance computing architectures, including parallel processing capabilities and cloud-based computational resources. This multifaceted demand profile creates significant opportunities for algorithmic innovations that address the fundamental computational challenges in modern lithography processing.
Leading semiconductor manufacturers are experiencing significant bottlenecks in their production workflows due to the computational intensity of current lithography algorithms. These bottlenecks directly impact time-to-market for new products and increase manufacturing costs, creating substantial pressure for algorithmic improvements. The market demand is particularly acute among foundries serving high-volume applications such as mobile processors, graphics processing units, and artificial intelligence accelerators.
The emergence of extreme ultraviolet lithography and multi-patterning techniques has exponentially increased the computational requirements for mask optimization, optical proximity correction, and source mask optimization processes. Current processing times for complex designs can extend to weeks or months, creating unacceptable delays in product development cycles. This has generated strong market pull for algorithmic innovations that can reduce processing times by orders of magnitude while maintaining the precision required for advanced node manufacturing.
Market research indicates that semiconductor companies are willing to invest substantially in computational lithography solutions that demonstrate measurable improvements in processing speed. The total addressable market encompasses not only major foundries but also integrated device manufacturers, mask shops, and electronic design automation companies that require faster turnaround times for their lithography-related workflows.
The demand extends beyond pure speed improvements to include enhanced scalability for handling increasingly complex designs with billions of features. Market requirements also emphasize the need for algorithms that can efficiently utilize modern high-performance computing architectures, including parallel processing capabilities and cloud-based computational resources. This multifaceted demand profile creates significant opportunities for algorithmic innovations that address the fundamental computational challenges in modern lithography processing.
Current State and Performance Bottlenecks in Lithography Algorithms
Computational lithography algorithms currently face significant performance challenges that limit their effectiveness in modern semiconductor manufacturing. The primary bottleneck stems from the exponential increase in computational complexity as feature sizes shrink and design patterns become more intricate. Traditional optical proximity correction (OPC) algorithms require extensive iterative calculations to achieve acceptable pattern fidelity, often consuming several hours or even days for complex mask designs.
Memory bandwidth limitations represent another critical constraint in current lithography processing systems. The massive datasets required for full-chip simulation, including aerial image calculations and resist modeling, frequently exceed available memory capacity. This forces algorithms to rely on disk-based storage solutions, dramatically reducing processing speed and creating I/O bottlenecks that can account for up to 60% of total computation time.
Current inverse lithography technology (ILT) implementations suffer from convergence issues that significantly impact processing efficiency. The optimization algorithms used in ILT often require thousands of iterations to reach acceptable solutions, with each iteration involving complex mathematical operations across millions of pixels. The lack of efficient parallelization strategies further compounds these performance issues, as many existing algorithms were designed for sequential processing architectures.
Source mask optimization (SMO) algorithms present additional computational challenges due to their multi-variable optimization nature. Simultaneous optimization of source illumination patterns and mask designs requires sophisticated mathematical frameworks that are computationally intensive. Current SMO implementations typically consume 10-20 times more processing resources compared to traditional OPC methods, making them impractical for high-volume manufacturing environments.
The integration of machine learning approaches into lithography algorithms has introduced new performance considerations. While AI-based methods show promise for improving accuracy, they require extensive training datasets and significant computational resources for both training and inference phases. Current GPU-accelerated implementations still struggle with the massive scale of full-chip processing requirements.
Existing software architectures in computational lithography tools often lack scalability for modern multi-core and distributed computing environments. Legacy code bases, predominantly written in sequential programming paradigms, fail to leverage available hardware resources effectively. This architectural limitation prevents optimal utilization of modern high-performance computing systems and cloud-based processing platforms.
Memory bandwidth limitations represent another critical constraint in current lithography processing systems. The massive datasets required for full-chip simulation, including aerial image calculations and resist modeling, frequently exceed available memory capacity. This forces algorithms to rely on disk-based storage solutions, dramatically reducing processing speed and creating I/O bottlenecks that can account for up to 60% of total computation time.
Current inverse lithography technology (ILT) implementations suffer from convergence issues that significantly impact processing efficiency. The optimization algorithms used in ILT often require thousands of iterations to reach acceptable solutions, with each iteration involving complex mathematical operations across millions of pixels. The lack of efficient parallelization strategies further compounds these performance issues, as many existing algorithms were designed for sequential processing architectures.
Source mask optimization (SMO) algorithms present additional computational challenges due to their multi-variable optimization nature. Simultaneous optimization of source illumination patterns and mask designs requires sophisticated mathematical frameworks that are computationally intensive. Current SMO implementations typically consume 10-20 times more processing resources compared to traditional OPC methods, making them impractical for high-volume manufacturing environments.
The integration of machine learning approaches into lithography algorithms has introduced new performance considerations. While AI-based methods show promise for improving accuracy, they require extensive training datasets and significant computational resources for both training and inference phases. Current GPU-accelerated implementations still struggle with the massive scale of full-chip processing requirements.
Existing software architectures in computational lithography tools often lack scalability for modern multi-core and distributed computing environments. Legacy code bases, predominantly written in sequential programming paradigms, fail to leverage available hardware resources effectively. This architectural limitation prevents optimal utilization of modern high-performance computing systems and cloud-based processing platforms.
Existing Algorithm Optimization and Acceleration Solutions
01 Parallel processing and GPU acceleration for lithography computations
Computational lithography algorithms can leverage parallel processing architectures and graphics processing units (GPUs) to significantly accelerate processing speed. By distributing computational tasks across multiple processing cores or GPU threads, complex lithography calculations such as optical proximity correction (OPC) and source mask optimization (SMO) can be executed simultaneously. This approach reduces overall computation time by orders of magnitude compared to sequential processing methods, enabling faster turnaround times for mask design and verification workflows.- Parallel processing and GPU acceleration for lithography computations: Computational lithography algorithms can leverage parallel processing architectures and graphics processing units (GPUs) to significantly accelerate processing speed. By distributing computational tasks across multiple processing cores or GPU threads, complex lithography calculations such as optical proximity correction (OPC) and source mask optimization (SMO) can be executed simultaneously. This approach reduces overall computation time by exploiting the inherent parallelism in lithography algorithms, enabling faster turnaround times for mask design and verification processes.
- Machine learning and neural network-based optimization: Advanced machine learning techniques and neural networks can be employed to optimize computational lithography algorithms and improve processing speed. These methods can learn patterns from historical lithography data and predict optimal solutions more quickly than traditional iterative approaches. By training models on large datasets of mask patterns and their corresponding wafer results, the algorithms can make faster decisions about corrections and optimizations, reducing the number of iterations required and accelerating the overall computational process.
- Hierarchical and multi-scale computational approaches: Implementing hierarchical and multi-scale computational strategies can enhance processing speed by breaking down complex lithography problems into manageable sub-problems. These approaches process different regions or scales of the design with varying levels of detail and computational intensity, focusing computational resources on critical areas while using simplified models for less critical regions. This selective allocation of computational effort optimizes the balance between accuracy and speed, enabling faster overall processing times without sacrificing quality in critical design areas.
- Algorithmic optimization and computational complexity reduction: Reducing the computational complexity of lithography algorithms through mathematical optimization and algorithmic improvements can directly enhance processing speed. This includes developing more efficient numerical methods, reducing the number of required calculations through smart approximations, and implementing fast Fourier transforms or other mathematical techniques that accelerate core computational operations. By streamlining the underlying algorithms and eliminating redundant calculations, the overall processing time can be significantly reduced while maintaining acceptable accuracy levels.
- Distributed computing and cloud-based processing infrastructure: Utilizing distributed computing frameworks and cloud-based infrastructure can dramatically improve computational lithography processing speed by scaling computational resources dynamically. This approach distributes lithography calculations across multiple servers or cloud instances, enabling massive parallelization of computational tasks. The elastic nature of cloud computing allows for on-demand allocation of resources based on workload requirements, facilitating faster processing of large-scale lithography projects and enabling efficient handling of peak computational demands without requiring permanent infrastructure investments.
02 Machine learning and neural network-based optimization
Advanced machine learning techniques and neural networks can be employed to optimize lithography algorithms and improve processing speed. These methods can learn patterns from historical lithography data and predict optimal solutions more quickly than traditional iterative approaches. Deep learning models can be trained to approximate complex physical simulations, reducing the computational burden while maintaining accuracy. This approach enables real-time or near-real-time lithography corrections and significantly reduces the time required for mask optimization processes.Expand Specific Solutions03 Hierarchical and multi-scale computational methods
Hierarchical computational strategies divide lithography problems into multiple scales or levels of detail to improve processing efficiency. Coarse-level computations are performed first to identify critical areas, followed by fine-level analysis only where necessary. This multi-resolution approach reduces unnecessary calculations on non-critical regions while maintaining accuracy in areas that require detailed attention. Such methods can dramatically decrease overall computation time by focusing computational resources where they are most needed.Expand Specific Solutions04 Algorithmic optimization and computational complexity reduction
Fundamental algorithmic improvements can enhance processing speed by reducing computational complexity. This includes developing more efficient mathematical formulations, implementing fast Fourier transforms for convolution operations, and utilizing sparse matrix techniques. Advanced data structures and optimized code implementations can minimize memory access times and reduce redundant calculations. These algorithmic enhancements provide speed improvements that are independent of hardware upgrades and can be combined with other acceleration techniques for cumulative benefits.Expand Specific Solutions05 Distributed computing and cloud-based processing architectures
Distributed computing frameworks enable lithography computations to be spread across multiple machines or cloud computing resources. By partitioning large-scale lithography problems into smaller independent tasks, these systems can process multiple design regions simultaneously across a computing cluster. Cloud-based solutions provide scalable computational resources that can be dynamically allocated based on workload demands. This approach is particularly effective for handling large chip designs and enables significant reductions in total processing time through massive parallelization.Expand Specific Solutions
Key Players in EDA and Lithography Software Industry
The computational lithography optimization landscape represents a mature yet rapidly evolving sector within the semiconductor industry, driven by the relentless demand for smaller, more efficient chips. The market demonstrates substantial scale, supported by major foundries like SMIC, GlobalFoundries, and UMC requiring advanced lithography solutions for next-generation nodes. Technology maturity varies significantly across players: equipment leaders ASML and Applied Materials dominate with established EUV and advanced lithography systems, while software specialists like Synopsys and D2S provide critical computational optimization tools. Semiconductor giants Intel, Samsung, and NVIDIA drive innovation through internal algorithm development, complemented by emerging players like Groq focusing on AI-accelerated processing. Chinese entities including Shanghai Microelectronics and research institutions like Beijing Institute of Technology are rapidly advancing capabilities. The competitive dynamics reflect a consolidating market where hardware-software integration and AI-enhanced algorithms increasingly determine competitive advantage.
ASML Netherlands BV
Technical Solution: ASML has developed advanced computational lithography solutions integrated into their EUV and DUV lithography systems. Their approach combines machine learning algorithms with traditional optical proximity correction (OPC) techniques to optimize mask design and exposure parameters. The company utilizes GPU-accelerated computing platforms to reduce computational time for complex pattern corrections from days to hours. Their Brion division specializes in computational lithography software that employs advanced algorithms for source mask optimization (SMO), enabling simultaneous optimization of illumination source and mask patterns. ASML's solutions incorporate real-time feedback mechanisms that adjust exposure parameters based on wafer-level measurements, significantly improving pattern fidelity and reducing edge placement errors in advanced node manufacturing.
Strengths: Market leader with comprehensive end-to-end solutions, extensive R&D resources, strong integration with hardware systems. Weaknesses: High cost of implementation, dependency on proprietary platforms, limited flexibility for custom applications.
NVIDIA Corp.
Technical Solution: NVIDIA provides GPU-accelerated computing solutions specifically optimized for computational lithography workloads through their CUDA platform and specialized libraries. Their approach focuses on parallelizing computationally intensive algorithms such as aerial image simulation, resist modeling, and OPC calculations. NVIDIA has developed cuLitho, a computational lithography library that can accelerate lithography simulations by up to 40x compared to CPU-based solutions. The platform supports advanced algorithms including machine learning-based OPC, neural network-driven process modeling, and AI-enhanced defect prediction. Their solutions enable real-time optimization of lithography processes through high-performance computing clusters equipped with A100 and H100 GPUs. NVIDIA collaborates with major semiconductor manufacturers to optimize lithography workflows and reduce time-to-market for advanced node processes.
Strengths: Superior parallel computing performance, extensive AI/ML capabilities, strong ecosystem support. Weaknesses: Requires specialized programming expertise, high hardware costs, dependency on GPU architecture evolution.
Core Innovations in High-Performance Lithography Computing
Fast Freeform Source and Mask Co-Optimization Method
PatentActiveUS20110230999A1
Innovation
- A method that enables direct computation of the gradient of a cost function for simultaneous optimization of both source and mask, allowing for free-form optimization without constraints, and incorporates sub-resolution assist feature (SRAF) placement to improve manufacturability, thereby speeding up the convergence and improving the process window.
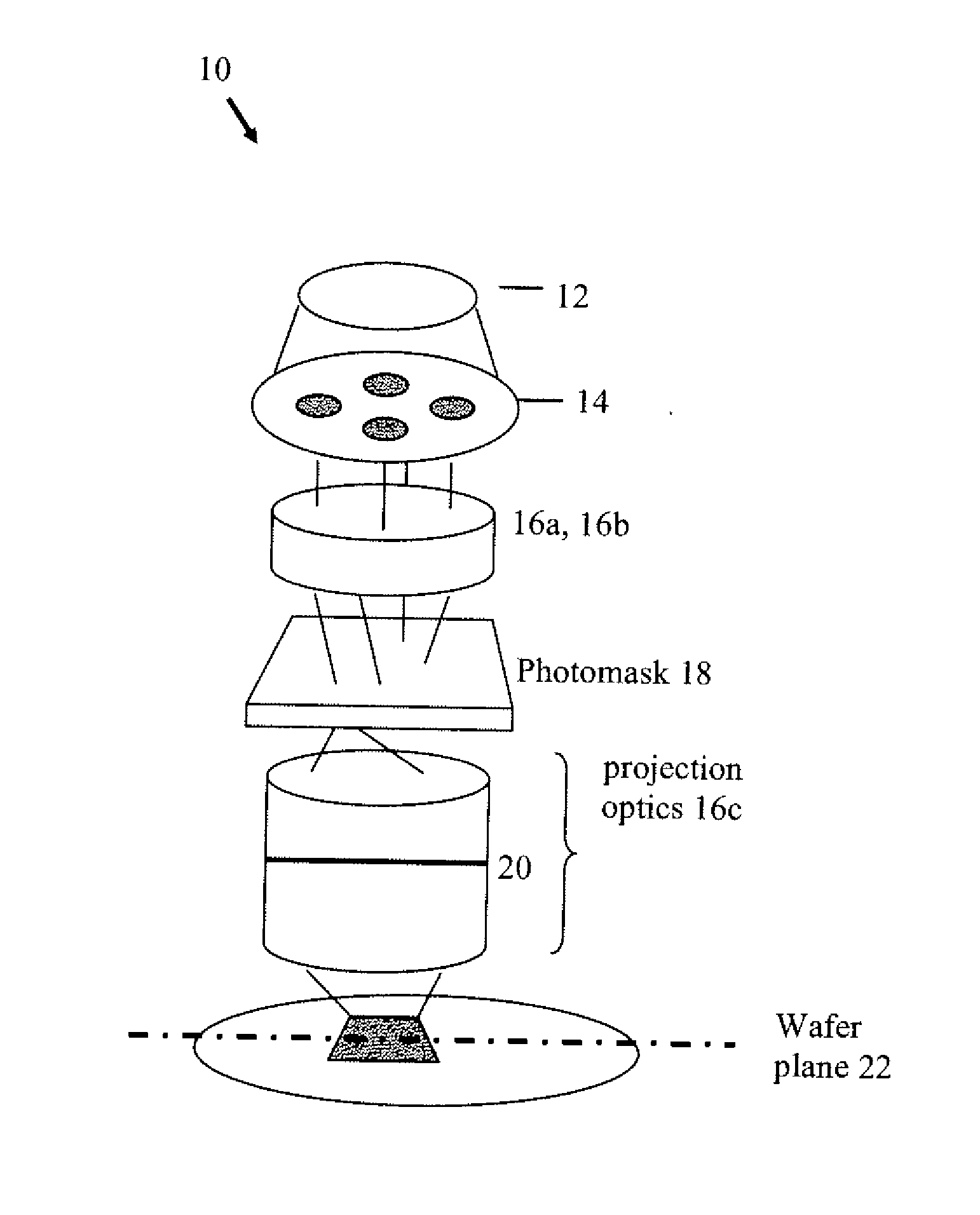
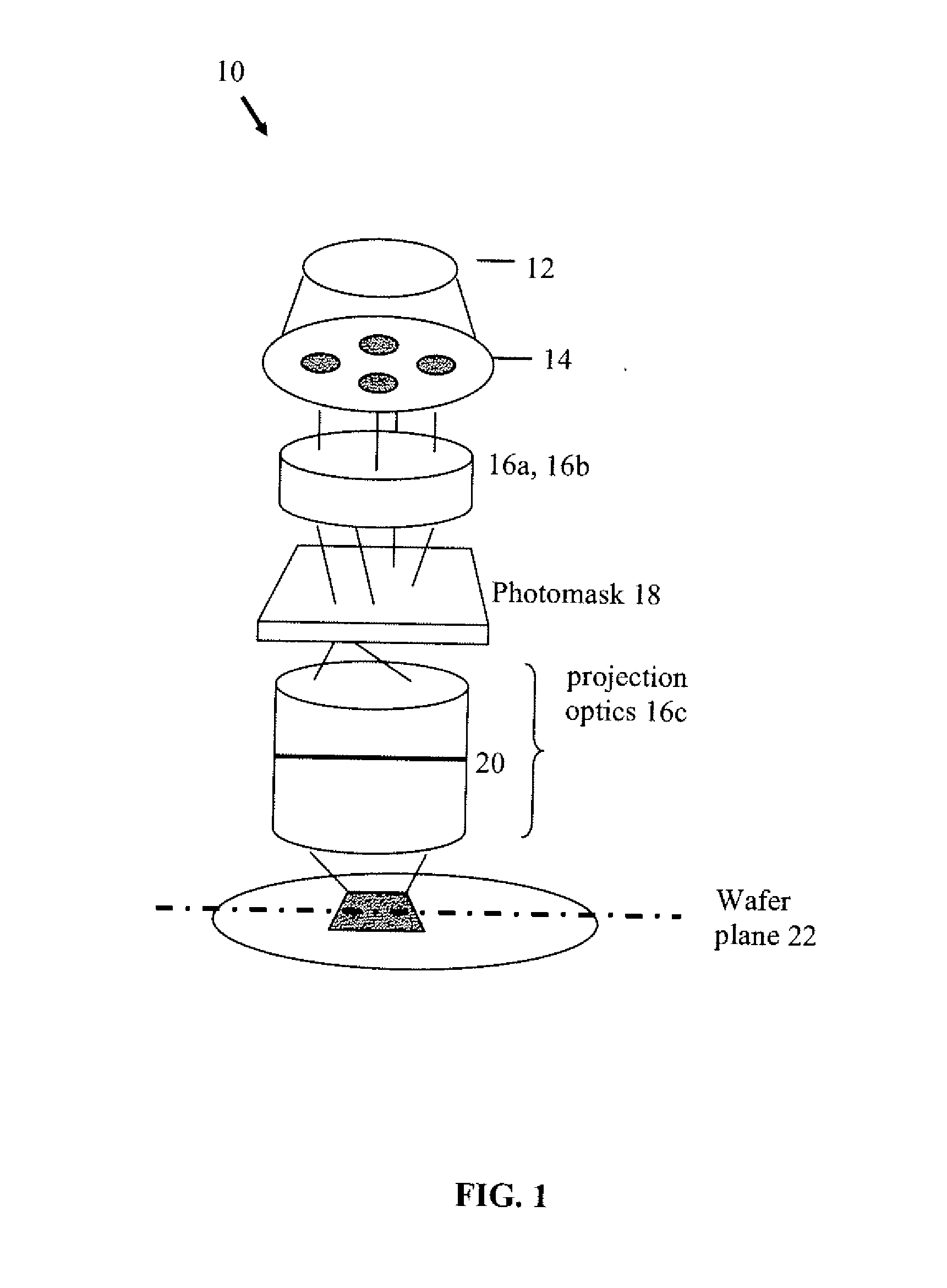
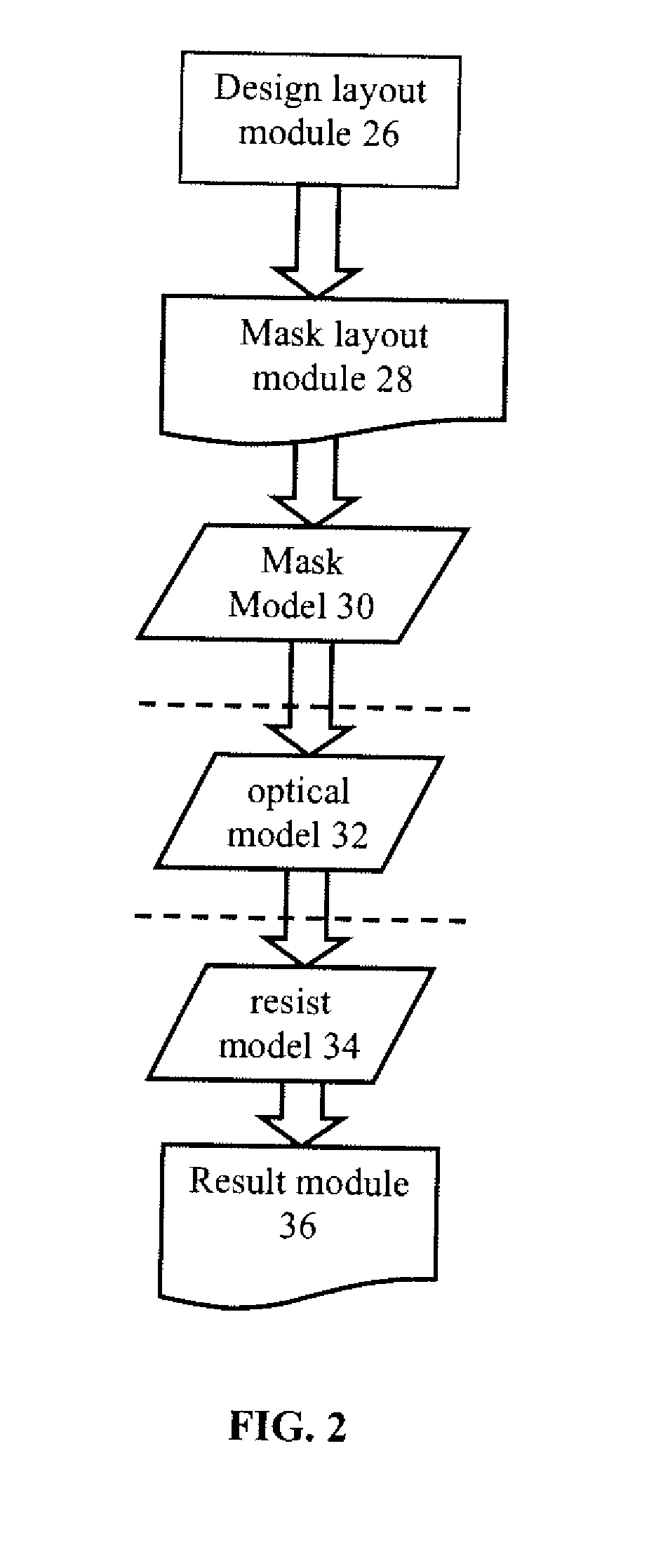

Large scale computational lithography using machine learning models
PatentActiveUS20220392191A1
Innovation
- The implementation of machine learning models to infer aerial images and resist profiles, using faster two-dimensional models and simplified exposure models, which are trained to mitigate accuracy losses and reduce computational costs.




Hardware Acceleration Technologies for Lithography Computing
Hardware acceleration technologies have emerged as critical enablers for computational lithography optimization, addressing the exponential growth in processing demands driven by advanced semiconductor manufacturing nodes. The transition from traditional CPU-based processing to specialized hardware architectures represents a fundamental shift in how lithography algorithms are executed and optimized.
Graphics Processing Units (GPUs) have become the primary acceleration platform for lithography computations due to their massive parallel processing capabilities. Modern GPU architectures featuring thousands of cores excel at handling the matrix operations and convolution calculations inherent in optical proximity correction and source mask optimization algorithms. Leading GPU manufacturers have developed specialized libraries and frameworks specifically tailored for lithography applications, enabling significant performance improvements over conventional processing methods.
Field-Programmable Gate Arrays (FPGAs) offer another compelling acceleration approach, particularly for applications requiring ultra-low latency and deterministic processing times. FPGA-based solutions provide the flexibility to implement custom computational pipelines optimized for specific lithography algorithms, allowing for fine-tuned performance optimization that cannot be achieved with general-purpose processors. The reconfigurable nature of FPGAs enables rapid prototyping and deployment of new algorithmic approaches.
Application-Specific Integrated Circuits (ASICs) represent the ultimate hardware acceleration solution for high-volume lithography processing environments. Custom silicon designs can achieve unprecedented performance levels by implementing lithography-specific computational units directly in hardware. Several semiconductor equipment manufacturers have invested heavily in ASIC development for critical lithography operations, achieving processing speeds that are orders of magnitude faster than software-based implementations.
Emerging technologies such as quantum computing and neuromorphic processors are beginning to show promise for specific lithography optimization challenges. Quantum algorithms demonstrate potential advantages for certain optimization problems inherent in computational lithography, while neuromorphic architectures offer energy-efficient solutions for pattern recognition and defect detection applications.
The integration of these hardware acceleration technologies requires sophisticated software frameworks and middleware solutions that can effectively distribute computational workloads across heterogeneous processing environments, maximizing the utilization of available hardware resources while maintaining algorithmic accuracy and reliability.
Graphics Processing Units (GPUs) have become the primary acceleration platform for lithography computations due to their massive parallel processing capabilities. Modern GPU architectures featuring thousands of cores excel at handling the matrix operations and convolution calculations inherent in optical proximity correction and source mask optimization algorithms. Leading GPU manufacturers have developed specialized libraries and frameworks specifically tailored for lithography applications, enabling significant performance improvements over conventional processing methods.
Field-Programmable Gate Arrays (FPGAs) offer another compelling acceleration approach, particularly for applications requiring ultra-low latency and deterministic processing times. FPGA-based solutions provide the flexibility to implement custom computational pipelines optimized for specific lithography algorithms, allowing for fine-tuned performance optimization that cannot be achieved with general-purpose processors. The reconfigurable nature of FPGAs enables rapid prototyping and deployment of new algorithmic approaches.
Application-Specific Integrated Circuits (ASICs) represent the ultimate hardware acceleration solution for high-volume lithography processing environments. Custom silicon designs can achieve unprecedented performance levels by implementing lithography-specific computational units directly in hardware. Several semiconductor equipment manufacturers have invested heavily in ASIC development for critical lithography operations, achieving processing speeds that are orders of magnitude faster than software-based implementations.
Emerging technologies such as quantum computing and neuromorphic processors are beginning to show promise for specific lithography optimization challenges. Quantum algorithms demonstrate potential advantages for certain optimization problems inherent in computational lithography, while neuromorphic architectures offer energy-efficient solutions for pattern recognition and defect detection applications.
The integration of these hardware acceleration technologies requires sophisticated software frameworks and middleware solutions that can effectively distribute computational workloads across heterogeneous processing environments, maximizing the utilization of available hardware resources while maintaining algorithmic accuracy and reliability.
AI-Driven Optimization Approaches in Computational Lithography
Artificial intelligence has emerged as a transformative force in computational lithography optimization, offering unprecedented capabilities to address the increasing complexity and performance demands of modern semiconductor manufacturing. Machine learning algorithms, particularly deep neural networks, have demonstrated remarkable potential in accelerating traditional lithography processes that previously relied on computationally intensive iterative methods.
Deep learning approaches have shown significant promise in optical proximity correction (OPC) optimization, where convolutional neural networks can predict mask corrections with substantially reduced computational overhead compared to conventional model-based approaches. These AI-driven methods leverage pattern recognition capabilities to identify optimal correction strategies based on training datasets derived from extensive lithographic simulations and empirical manufacturing data.
Reinforcement learning algorithms represent another breakthrough direction, enabling adaptive optimization strategies that can dynamically adjust lithographic parameters based on real-time feedback mechanisms. These approaches treat the lithography optimization process as a sequential decision-making problem, where intelligent agents learn optimal policies through interaction with simulation environments, potentially achieving superior performance compared to traditional gradient-based optimization methods.
Generative adversarial networks (GANs) have demonstrated exceptional capabilities in inverse lithography technology (ILT), where the objective involves designing optimal mask patterns to achieve desired wafer patterns. The adversarial training framework enables the generation of high-quality mask solutions while significantly reducing computational time through learned approximations of complex physical lithographic processes.
Hybrid AI approaches combining multiple machine learning paradigms show particular promise for comprehensive lithography optimization. These integrated frameworks leverage the strengths of different AI methodologies, such as combining neural network-based pattern prediction with evolutionary algorithms for global optimization, creating robust solutions that can handle diverse lithographic challenges while maintaining computational efficiency and manufacturing feasibility constraints.
Deep learning approaches have shown significant promise in optical proximity correction (OPC) optimization, where convolutional neural networks can predict mask corrections with substantially reduced computational overhead compared to conventional model-based approaches. These AI-driven methods leverage pattern recognition capabilities to identify optimal correction strategies based on training datasets derived from extensive lithographic simulations and empirical manufacturing data.
Reinforcement learning algorithms represent another breakthrough direction, enabling adaptive optimization strategies that can dynamically adjust lithographic parameters based on real-time feedback mechanisms. These approaches treat the lithography optimization process as a sequential decision-making problem, where intelligent agents learn optimal policies through interaction with simulation environments, potentially achieving superior performance compared to traditional gradient-based optimization methods.
Generative adversarial networks (GANs) have demonstrated exceptional capabilities in inverse lithography technology (ILT), where the objective involves designing optimal mask patterns to achieve desired wafer patterns. The adversarial training framework enables the generation of high-quality mask solutions while significantly reducing computational time through learned approximations of complex physical lithographic processes.
Hybrid AI approaches combining multiple machine learning paradigms show particular promise for comprehensive lithography optimization. These integrated frameworks leverage the strengths of different AI methodologies, such as combining neural network-based pattern prediction with evolutionary algorithms for global optimization, creating robust solutions that can handle diverse lithographic challenges while maintaining computational efficiency and manufacturing feasibility constraints.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!