

Reducing Computational Lithography Time with Parallel Processing
APR 24, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Computational Lithography Background and Processing Goals
Computational lithography has emerged as a critical technology in semiconductor manufacturing, representing the intersection of advanced mathematics, computer science, and precision engineering. This field encompasses the computational methods and algorithms used to optimize the lithographic process, which is fundamental to creating the intricate patterns on semiconductor wafers that define modern integrated circuits. As semiconductor devices continue to shrink beyond the physical limits of traditional optical lithography, computational techniques have become indispensable for achieving the required pattern fidelity and manufacturing yield.
The evolution of computational lithography traces back to the early 2000s when the semiconductor industry first encountered significant challenges in printing features smaller than the wavelength of light used in lithographic systems. Initially, simple geometric corrections and basic optical proximity corrections were sufficient. However, as technology nodes progressed from 180nm to 90nm and beyond, more sophisticated computational approaches became necessary. The introduction of resolution enhancement techniques, including optical proximity correction, phase-shift masks, and sub-resolution assist features, marked the beginning of computationally intensive lithographic processes.
The current technological landscape is dominated by extreme ultraviolet lithography and advanced computational techniques that enable the production of 5nm and 3nm process nodes. These cutting-edge manufacturing processes require unprecedented computational complexity, involving massive datasets and intricate mathematical models that simulate light-matter interactions at the nanoscale. The computational burden has grown exponentially, with modern lithographic simulations requiring thousands of CPU hours for a single mask layer optimization.
The primary technical objectives in computational lithography center on achieving optimal pattern transfer accuracy while maintaining acceptable processing times and manufacturing costs. Key goals include minimizing critical dimension variation across the wafer, reducing line edge roughness, maximizing process window margins, and ensuring robust manufacturability under various process conditions. These objectives must be balanced against the computational complexity and time constraints imposed by production schedules.
Contemporary challenges in computational lithography processing involve managing the trade-off between accuracy and computational efficiency. As pattern complexity increases and feature sizes decrease, the required computational resources grow exponentially, creating bottlenecks in the design-to-manufacturing flow. The industry faces mounting pressure to reduce mask preparation times while maintaining or improving pattern quality, driving the urgent need for innovative parallel processing solutions and algorithmic optimizations.
The evolution of computational lithography traces back to the early 2000s when the semiconductor industry first encountered significant challenges in printing features smaller than the wavelength of light used in lithographic systems. Initially, simple geometric corrections and basic optical proximity corrections were sufficient. However, as technology nodes progressed from 180nm to 90nm and beyond, more sophisticated computational approaches became necessary. The introduction of resolution enhancement techniques, including optical proximity correction, phase-shift masks, and sub-resolution assist features, marked the beginning of computationally intensive lithographic processes.
The current technological landscape is dominated by extreme ultraviolet lithography and advanced computational techniques that enable the production of 5nm and 3nm process nodes. These cutting-edge manufacturing processes require unprecedented computational complexity, involving massive datasets and intricate mathematical models that simulate light-matter interactions at the nanoscale. The computational burden has grown exponentially, with modern lithographic simulations requiring thousands of CPU hours for a single mask layer optimization.
The primary technical objectives in computational lithography center on achieving optimal pattern transfer accuracy while maintaining acceptable processing times and manufacturing costs. Key goals include minimizing critical dimension variation across the wafer, reducing line edge roughness, maximizing process window margins, and ensuring robust manufacturability under various process conditions. These objectives must be balanced against the computational complexity and time constraints imposed by production schedules.
Contemporary challenges in computational lithography processing involve managing the trade-off between accuracy and computational efficiency. As pattern complexity increases and feature sizes decrease, the required computational resources grow exponentially, creating bottlenecks in the design-to-manufacturing flow. The industry faces mounting pressure to reduce mask preparation times while maintaining or improving pattern quality, driving the urgent need for innovative parallel processing solutions and algorithmic optimizations.
Market Demand for Faster Semiconductor Manufacturing
The semiconductor industry faces unprecedented pressure to accelerate manufacturing processes as device complexity continues to escalate and market demands intensify. Modern integrated circuits require increasingly sophisticated lithographic processes, with feature sizes shrinking to nanometer scales and layer counts reaching hundreds in advanced processors and memory devices. This complexity directly translates to exponentially longer computational lithography processing times, creating significant bottlenecks in the manufacturing pipeline.
Global semiconductor demand has surged across multiple sectors, driven by artificial intelligence applications, autonomous vehicles, Internet of Things devices, and high-performance computing systems. Data centers require processors with enhanced computational capabilities, while mobile devices demand more efficient chips with greater functionality. This market expansion has created an urgent need for semiconductor manufacturers to increase production throughput while maintaining precision and yield rates.
Manufacturing facilities operating advanced lithography systems face substantial economic pressures from extended processing times. Each additional hour of computational lithography processing directly impacts facility utilization rates and production capacity. Leading foundries report that computational lithography can consume significant portions of their total manufacturing cycle time, particularly for advanced node processes below seven nanometers.
The competitive landscape demands faster time-to-market delivery for new semiconductor products. Companies developing cutting-edge processors, graphics chips, and specialized silicon must reduce development cycles to maintain market leadership. Extended computational lithography times create cascading delays throughout the product development pipeline, affecting everything from initial design verification to volume production ramp-up.
Cost optimization represents another critical driver for faster computational lithography solutions. Manufacturing facilities invest heavily in advanced lithography equipment and computational infrastructure. Reducing processing times enables better return on investment for these capital expenditures while lowering per-unit manufacturing costs. This economic imperative becomes particularly acute as wafer sizes increase and process complexity grows.
Quality requirements in modern semiconductor manufacturing demand sophisticated computational lithography techniques that traditionally require extensive processing time. Optical proximity correction, phase-shift mask optimization, and source-mask optimization algorithms must analyze millions of geometric features across entire chip layouts. Market demands for higher yields and improved device performance cannot compromise these quality standards, necessitating solutions that accelerate processing without sacrificing accuracy.
Global semiconductor demand has surged across multiple sectors, driven by artificial intelligence applications, autonomous vehicles, Internet of Things devices, and high-performance computing systems. Data centers require processors with enhanced computational capabilities, while mobile devices demand more efficient chips with greater functionality. This market expansion has created an urgent need for semiconductor manufacturers to increase production throughput while maintaining precision and yield rates.
Manufacturing facilities operating advanced lithography systems face substantial economic pressures from extended processing times. Each additional hour of computational lithography processing directly impacts facility utilization rates and production capacity. Leading foundries report that computational lithography can consume significant portions of their total manufacturing cycle time, particularly for advanced node processes below seven nanometers.
The competitive landscape demands faster time-to-market delivery for new semiconductor products. Companies developing cutting-edge processors, graphics chips, and specialized silicon must reduce development cycles to maintain market leadership. Extended computational lithography times create cascading delays throughout the product development pipeline, affecting everything from initial design verification to volume production ramp-up.
Cost optimization represents another critical driver for faster computational lithography solutions. Manufacturing facilities invest heavily in advanced lithography equipment and computational infrastructure. Reducing processing times enables better return on investment for these capital expenditures while lowering per-unit manufacturing costs. This economic imperative becomes particularly acute as wafer sizes increase and process complexity grows.
Quality requirements in modern semiconductor manufacturing demand sophisticated computational lithography techniques that traditionally require extensive processing time. Optical proximity correction, phase-shift mask optimization, and source-mask optimization algorithms must analyze millions of geometric features across entire chip layouts. Market demands for higher yields and improved device performance cannot compromise these quality standards, necessitating solutions that accelerate processing without sacrificing accuracy.
Current State and Bottlenecks in Lithography Computing
Computational lithography has evolved into a critical bottleneck in semiconductor manufacturing, particularly as the industry pushes toward advanced nodes below 7nm. Current lithography computing systems face unprecedented computational demands driven by the complexity of optical proximity correction (OPC), inverse lithography technology (ILT), and source mask optimization (SMO). These processes require extensive mathematical calculations involving electromagnetic field simulations, pattern corrections, and iterative optimization algorithms that can consume hundreds of CPU hours for a single mask layer.
The primary computational challenge stems from the exponential increase in pattern density and the shrinking critical dimensions that demand higher accuracy in modeling. Modern OPC engines must process millions of edge fragments simultaneously, each requiring complex calculations to predict and correct for optical and process effects. The computational load is further amplified by the need for full-chip simulations that account for long-range interactions and process variations across the entire wafer.
Memory bandwidth limitations represent another significant bottleneck in current lithography computing architectures. Traditional CPU-based systems struggle with the massive data movement requirements between memory and processing units, particularly when handling large design databases and intermediate calculation results. The sequential nature of many existing algorithms creates additional inefficiencies, as processing units remain idle while waiting for data transfers or dependent calculations to complete.
Current lithography software implementations predominantly rely on single-threaded or limited multi-threaded approaches that fail to fully exploit available hardware resources. Many legacy algorithms were designed for simpler technology nodes and lack the architectural flexibility needed for effective parallelization. This results in suboptimal utilization of modern multi-core processors and prevents scaling to distributed computing environments.
The integration complexity between different lithography tools creates additional computational overhead. Data format conversions, intermediate file I/O operations, and tool-specific optimizations contribute to extended processing times. Furthermore, the iterative nature of lithography optimization workflows, where multiple correction cycles are required to achieve acceptable results, multiplies these inefficiencies and extends overall turnaround times to levels that impact production schedules and time-to-market objectives.
The primary computational challenge stems from the exponential increase in pattern density and the shrinking critical dimensions that demand higher accuracy in modeling. Modern OPC engines must process millions of edge fragments simultaneously, each requiring complex calculations to predict and correct for optical and process effects. The computational load is further amplified by the need for full-chip simulations that account for long-range interactions and process variations across the entire wafer.
Memory bandwidth limitations represent another significant bottleneck in current lithography computing architectures. Traditional CPU-based systems struggle with the massive data movement requirements between memory and processing units, particularly when handling large design databases and intermediate calculation results. The sequential nature of many existing algorithms creates additional inefficiencies, as processing units remain idle while waiting for data transfers or dependent calculations to complete.
Current lithography software implementations predominantly rely on single-threaded or limited multi-threaded approaches that fail to fully exploit available hardware resources. Many legacy algorithms were designed for simpler technology nodes and lack the architectural flexibility needed for effective parallelization. This results in suboptimal utilization of modern multi-core processors and prevents scaling to distributed computing environments.
The integration complexity between different lithography tools creates additional computational overhead. Data format conversions, intermediate file I/O operations, and tool-specific optimizations contribute to extended processing times. Furthermore, the iterative nature of lithography optimization workflows, where multiple correction cycles are required to achieve acceptable results, multiplies these inefficiencies and extends overall turnaround times to levels that impact production schedules and time-to-market objectives.
Existing Parallel Computing Solutions for Lithography
01 Optimization algorithms for reducing computational lithography time
Various optimization algorithms and methods are employed to reduce the computational time required for lithography simulations. These approaches include machine learning techniques, parallel processing, and iterative optimization methods that balance accuracy with computational efficiency. Advanced algorithms can significantly decrease processing time while maintaining acceptable levels of precision in lithography pattern generation.- Optimization algorithms for reducing computational lithography time: Various optimization algorithms and methods are employed to reduce the computational time required for lithography simulations. These approaches include machine learning techniques, parallel processing, and iterative algorithms that converge faster. By optimizing the computational workflow, the time needed for optical proximity correction and mask synthesis can be significantly reduced while maintaining accuracy.
- Model-based approaches for accelerating lithography calculations: Model-based computational lithography techniques utilize simplified physical models and approximations to speed up calculations. These methods balance accuracy with computational efficiency by employing compact models, lookup tables, and analytical approximations. Such approaches enable faster turnaround times for mask design verification and optimization processes.
- Hardware acceleration and parallel computing architectures: Specialized hardware architectures including graphics processing units, field-programmable gate arrays, and multi-core processors are utilized to accelerate lithography computations. These parallel computing platforms enable simultaneous processing of multiple computational tasks, dramatically reducing the overall processing time for complex lithography simulations and corrections.
- Hierarchical and multi-scale computational methods: Hierarchical computational strategies divide the lithography problem into multiple scales and levels of detail. Coarse calculations are performed initially across large areas, followed by fine-tuning in critical regions. This multi-resolution approach reduces unnecessary computations in non-critical areas while maintaining high accuracy where needed, resulting in substantial time savings.
- Adaptive sampling and selective computation techniques: Adaptive sampling methods intelligently select regions requiring detailed computational analysis while applying simplified calculations to less critical areas. These techniques use pattern recognition and criticality analysis to determine where computational resources should be focused. By avoiding redundant calculations and concentrating efforts on challenging features, overall lithography computation time is minimized.
02 Model-based computational lithography acceleration techniques
Model-based approaches utilize simplified physical models and approximations to accelerate lithography computations. These techniques involve creating efficient mathematical representations of optical and resist processes that can be computed more rapidly than full physical simulations. The methods enable faster turnaround times for mask design and verification while preserving essential accuracy requirements.Expand Specific Solutions03 Hardware acceleration and parallel computing for lithography
Hardware-based solutions including GPU acceleration, specialized processors, and distributed computing architectures are implemented to reduce lithography computation time. These systems leverage parallel processing capabilities to handle multiple calculations simultaneously, dramatically improving throughput for complex lithography simulations and mask optimization tasks.Expand Specific Solutions04 Hierarchical and adaptive computational methods
Hierarchical decomposition and adaptive sampling strategies are used to optimize computational resources in lithography processes. These methods intelligently allocate computational effort based on pattern complexity and criticality, performing detailed calculations only where necessary while using simplified approaches for less critical regions. This selective processing significantly reduces overall computation time.Expand Specific Solutions05 Fast simulation techniques using lookup tables and caching
Pre-computed lookup tables, caching mechanisms, and database-driven approaches are utilized to minimize redundant calculations in lithography simulations. By storing and reusing previously computed results for common patterns and configurations, these techniques eliminate repetitive calculations and substantially decrease overall processing time for mask synthesis and optical proximity correction.Expand Specific Solutions
Key Players in EDA and Lithography Software Industry
The computational lithography market is experiencing rapid growth driven by increasing demand for advanced semiconductor manufacturing, with the industry transitioning from mature planar technologies to cutting-edge 3D architectures requiring sophisticated parallel processing solutions. Market leaders like ASML Netherlands BV dominate EUV lithography systems, while Applied Materials and Tokyo Electron provide complementary processing equipment. Technology maturity varies significantly across segments, with established players like Canon, Intel, and Sony demonstrating proven capabilities in traditional lithography, whereas emerging companies such as ChangXin Memory Technologies and Circuit Fabology represent next-generation approaches. The competitive landscape shows strong consolidation among equipment manufacturers, with parallel processing becoming critical for meeting Moore's Law requirements and reducing computational bottlenecks in mask optimization and optical proximity correction workflows.
ASML Netherlands BV
Technical Solution: ASML has developed advanced computational lithography solutions that leverage massive parallel processing architectures to accelerate optical proximity correction (OPC) and source mask optimization (SMO) calculations. Their Tachyon platform utilizes distributed computing clusters with thousands of CPU cores working simultaneously to process complex lithography simulations. The system employs sophisticated load balancing algorithms to distribute computational tasks across multiple processing nodes, reducing overall processing time from weeks to days for advanced node lithography patterns. ASML's parallel processing approach includes GPU acceleration for specific computational kernels and optimized memory management to handle the massive datasets required for sub-7nm lithography processes.
Strengths: Industry-leading computational lithography expertise with proven scalability for advanced nodes. Weaknesses: High infrastructure costs and complexity in system integration.
Applied Materials, Inc.
Technical Solution: Applied Materials has implemented parallel processing solutions in their computational lithography workflow through their Advanced Patterning Film division. Their approach focuses on multi-threaded algorithms for mask synthesis and verification processes, utilizing high-performance computing clusters to accelerate time-intensive calculations such as lithography simulation and process window analysis. The company's parallel processing framework incorporates machine learning algorithms running on distributed systems to optimize lithography parameters in real-time. Their solution includes specialized hardware acceleration and optimized software libraries that can reduce computational time by up to 10x for complex patterning applications, particularly beneficial for memory and logic device manufacturing.
Strengths: Strong integration with manufacturing equipment and comprehensive process optimization capabilities. Weaknesses: Limited to specific application domains and requires significant computational resources.
Core Innovations in Parallel Lithography Algorithms
Parallel Image Processing System
PatentActiveUS20120262465A1
Innovation
- A parallel image processing system that processes graphical objects into convex polygons, distributes edge lists to multiple scan line image processing units, synchronizes operations using a sentinel, and balances load to maintain high throughput and reduce mask size requirements, enabling efficient application of mask data patterns to substrates.
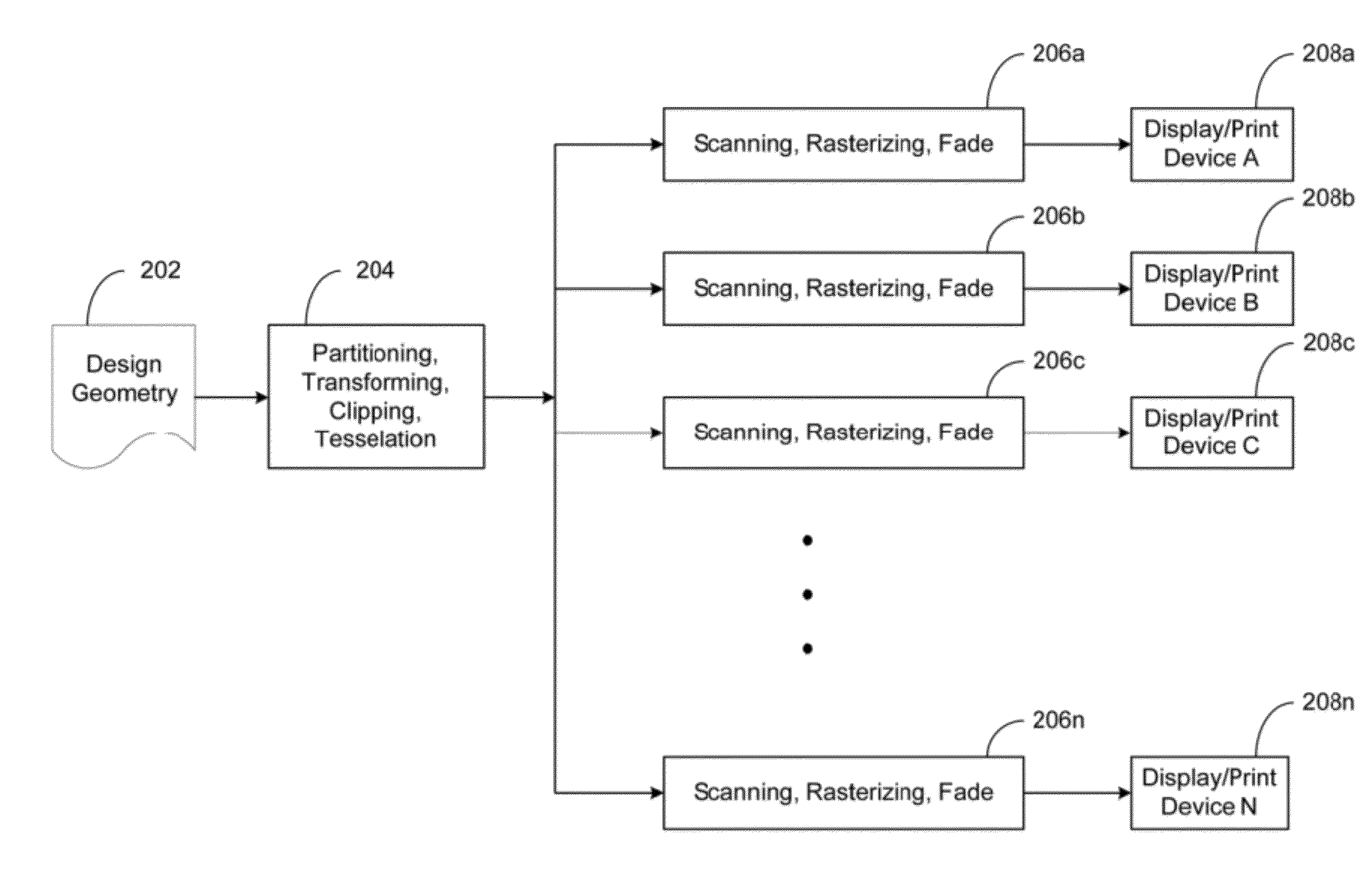
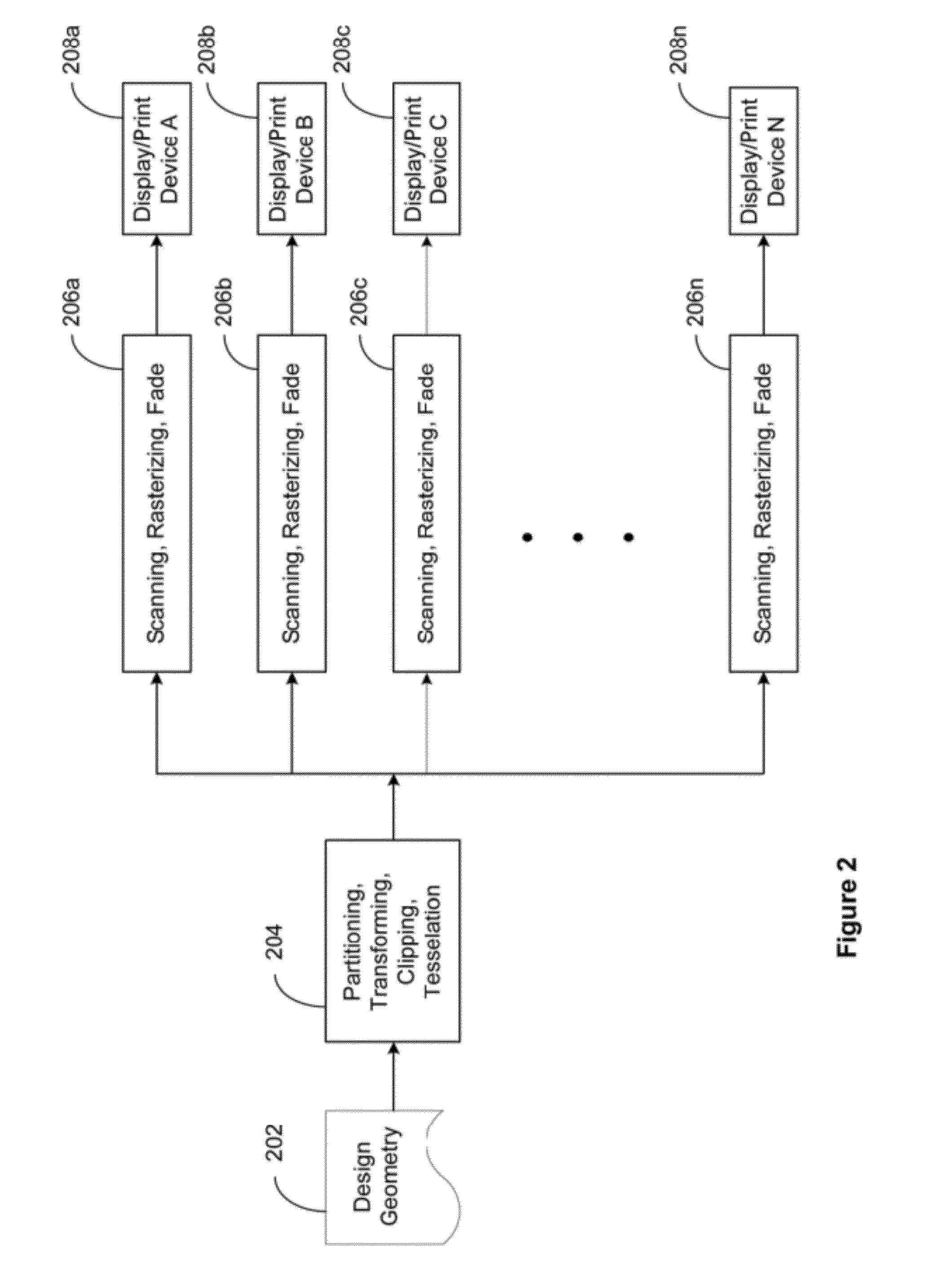

Determining contour edges for an image
PatentPendingUS20250238916A1
Innovation
- Utilizing a graphics processing unit (GPU) to perform contour edge determination and stitching in parallel by creating image cells, comparing pixel values to thresholds, and using a marching squares approach to improve performance.




Hardware Acceleration Technologies for Lithography
Hardware acceleration technologies have emerged as critical enablers for addressing the computational intensity challenges inherent in modern lithography processes. As semiconductor manufacturing nodes continue to shrink and design complexity increases exponentially, traditional CPU-based computational approaches have reached practical limitations in terms of processing speed and energy efficiency.
Graphics Processing Units (GPUs) represent the most widely adopted hardware acceleration solution for lithography computations. Modern GPU architectures, featuring thousands of parallel processing cores, excel at handling the massive matrix operations and convolution calculations required for optical proximity correction (OPC) and inverse lithography technology (ILT). Leading GPU manufacturers have developed specialized compute architectures optimized for double-precision floating-point operations, which are essential for maintaining the numerical accuracy required in lithography simulations.
Field-Programmable Gate Arrays (FPGAs) offer another compelling acceleration approach, particularly for specific algorithmic implementations in computational lithography. FPGAs provide the flexibility to implement custom processing pipelines tailored to lithography-specific operations such as aerial image simulation and resist modeling. The reconfigurable nature of FPGAs allows for optimization of data flow patterns and memory access, resulting in significant performance improvements for certain lithography algorithms.
Application-Specific Integrated Circuits (ASICs) represent the ultimate hardware acceleration solution for high-volume lithography processing environments. Custom silicon designs can achieve optimal performance and power efficiency by implementing lithography algorithms directly in hardware. Several semiconductor equipment manufacturers have developed proprietary ASIC solutions that integrate seamlessly with their lithography systems, delivering unprecedented computational throughput.
Emerging technologies such as quantum processing units and neuromorphic computing architectures are beginning to show promise for specific lithography applications. Quantum algorithms demonstrate potential advantages for certain optimization problems in mask synthesis, while neuromorphic processors offer energy-efficient solutions for pattern recognition tasks in lithography verification workflows.
The integration of these hardware acceleration technologies with advanced memory architectures, including high-bandwidth memory (HBM) and processing-in-memory solutions, further enhances computational performance by addressing memory bandwidth bottlenecks that traditionally limit lithography processing throughput.
Graphics Processing Units (GPUs) represent the most widely adopted hardware acceleration solution for lithography computations. Modern GPU architectures, featuring thousands of parallel processing cores, excel at handling the massive matrix operations and convolution calculations required for optical proximity correction (OPC) and inverse lithography technology (ILT). Leading GPU manufacturers have developed specialized compute architectures optimized for double-precision floating-point operations, which are essential for maintaining the numerical accuracy required in lithography simulations.
Field-Programmable Gate Arrays (FPGAs) offer another compelling acceleration approach, particularly for specific algorithmic implementations in computational lithography. FPGAs provide the flexibility to implement custom processing pipelines tailored to lithography-specific operations such as aerial image simulation and resist modeling. The reconfigurable nature of FPGAs allows for optimization of data flow patterns and memory access, resulting in significant performance improvements for certain lithography algorithms.
Application-Specific Integrated Circuits (ASICs) represent the ultimate hardware acceleration solution for high-volume lithography processing environments. Custom silicon designs can achieve optimal performance and power efficiency by implementing lithography algorithms directly in hardware. Several semiconductor equipment manufacturers have developed proprietary ASIC solutions that integrate seamlessly with their lithography systems, delivering unprecedented computational throughput.
Emerging technologies such as quantum processing units and neuromorphic computing architectures are beginning to show promise for specific lithography applications. Quantum algorithms demonstrate potential advantages for certain optimization problems in mask synthesis, while neuromorphic processors offer energy-efficient solutions for pattern recognition tasks in lithography verification workflows.
The integration of these hardware acceleration technologies with advanced memory architectures, including high-bandwidth memory (HBM) and processing-in-memory solutions, further enhances computational performance by addressing memory bandwidth bottlenecks that traditionally limit lithography processing throughput.
Software Architecture Optimization Strategies
The optimization of software architecture for computational lithography parallel processing requires a multi-layered approach that addresses both computational efficiency and system scalability. Modern lithography simulation workloads demand sophisticated architectural patterns that can effectively distribute computational tasks across heterogeneous computing resources while maintaining data consistency and minimizing communication overhead.
Load balancing strategies form the cornerstone of effective parallel processing architectures in computational lithography. Dynamic load distribution algorithms must account for the varying computational complexity of different mask regions, ensuring that processing units receive workloads proportional to their computational capabilities. Adaptive partitioning schemes that analyze geometric complexity and adjust task granularity in real-time have demonstrated significant improvements in overall throughput compared to static distribution methods.
Memory hierarchy optimization plays a critical role in reducing computational bottlenecks. Implementing multi-level caching strategies with intelligent prefetching mechanisms can substantially reduce memory access latency. Cache-aware data structures specifically designed for lithography algorithms, combined with memory pool management techniques, help minimize garbage collection overhead and improve memory locality for frequently accessed simulation data.
Pipeline architecture design enables overlapping of different computational phases, maximizing resource utilization across the processing workflow. Asynchronous processing pipelines with configurable buffer sizes allow for continuous data flow while accommodating varying processing speeds of different algorithmic components. This approach is particularly effective when integrating optical proximity correction calculations with mask optimization routines.
Microservices architecture adoption facilitates modular deployment and independent scaling of different lithography processing components. Container-based deployment strategies enable dynamic resource allocation based on current workload demands, while service mesh implementations provide robust inter-service communication with built-in fault tolerance and monitoring capabilities.
Data flow optimization through streaming architectures reduces memory footprint and enables processing of large-scale lithography datasets that exceed available system memory. Implementing backpressure mechanisms and flow control protocols ensures system stability under varying computational loads while maintaining processing accuracy and numerical precision requirements essential for lithography applications.
Load balancing strategies form the cornerstone of effective parallel processing architectures in computational lithography. Dynamic load distribution algorithms must account for the varying computational complexity of different mask regions, ensuring that processing units receive workloads proportional to their computational capabilities. Adaptive partitioning schemes that analyze geometric complexity and adjust task granularity in real-time have demonstrated significant improvements in overall throughput compared to static distribution methods.
Memory hierarchy optimization plays a critical role in reducing computational bottlenecks. Implementing multi-level caching strategies with intelligent prefetching mechanisms can substantially reduce memory access latency. Cache-aware data structures specifically designed for lithography algorithms, combined with memory pool management techniques, help minimize garbage collection overhead and improve memory locality for frequently accessed simulation data.
Pipeline architecture design enables overlapping of different computational phases, maximizing resource utilization across the processing workflow. Asynchronous processing pipelines with configurable buffer sizes allow for continuous data flow while accommodating varying processing speeds of different algorithmic components. This approach is particularly effective when integrating optical proximity correction calculations with mask optimization routines.
Microservices architecture adoption facilitates modular deployment and independent scaling of different lithography processing components. Container-based deployment strategies enable dynamic resource allocation based on current workload demands, while service mesh implementations provide robust inter-service communication with built-in fault tolerance and monitoring capabilities.
Data flow optimization through streaming architectures reduces memory footprint and enables processing of large-scale lithography datasets that exceed available system memory. Implementing backpressure mechanisms and flow control protocols ensures system stability under varying computational loads while maintaining processing accuracy and numerical precision requirements essential for lithography applications.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!