

ROS 2 Node Lifecycle: Managed Nodes, Health And Supervisory Control
SEP 19, 202510 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
ROS 2 Lifecycle Management Evolution and Objectives
The evolution of ROS 2 lifecycle management represents a significant advancement from the original ROS framework, addressing critical limitations in system reliability and predictability. The Robot Operating System (ROS) initially lacked formal mechanisms for managing node states and transitions, resulting in unpredictable startup sequences and shutdown behaviors that compromised system stability in production environments. This deficiency became increasingly problematic as ROS applications expanded from research settings to industrial and safety-critical domains.
ROS 2 introduced the Node Lifecycle Management framework as a direct response to these challenges, implementing a formalized state machine approach based on established industry standards. Drawing inspiration from AUTOSAR (Automotive Open System Architecture) and other production-grade frameworks, ROS 2 adopted a deterministic lifecycle model that enables precise control over node initialization, operation, and termination processes.
The primary objective of this architectural enhancement was to establish predictable and controllable node behavior throughout the system lifecycle. By implementing standardized state transitions (Unconfigured, Inactive, Active, Finalized) and well-defined transition callbacks, ROS 2 enables developers to create robust applications where component behavior during critical phases like startup and shutdown can be precisely managed and monitored.
This evolution directly supports fault tolerance objectives by providing mechanisms for health monitoring and supervisory control. The managed node framework allows for systematic detection of component failures and implementation of appropriate recovery strategies, significantly enhancing system resilience in dynamic operational environments. This capability is particularly valuable in autonomous systems where component failures must be gracefully handled without human intervention.
Another key objective of the lifecycle management framework is to facilitate deterministic resource allocation. By separating the configuration phase from activation, ROS 2 enables systems to validate resource availability and configuration parameters before nodes begin their operational activities. This approach prevents resource conflicts and ensures that all prerequisites are satisfied before critical operations commence.
The framework also aims to enhance system maintainability through standardized interfaces for node management. By providing a common API for lifecycle operations, ROS 2 simplifies the development of system monitoring tools, orchestration services, and diagnostic utilities. This standardization reduces integration complexity and promotes the development of reusable system management components across different robotic applications.
As robotics applications continue to expand into regulated industries like healthcare, transportation, and industrial automation, the lifecycle management framework increasingly serves compliance objectives by providing the traceability and determinism required by safety standards and certification processes.
ROS 2 introduced the Node Lifecycle Management framework as a direct response to these challenges, implementing a formalized state machine approach based on established industry standards. Drawing inspiration from AUTOSAR (Automotive Open System Architecture) and other production-grade frameworks, ROS 2 adopted a deterministic lifecycle model that enables precise control over node initialization, operation, and termination processes.
The primary objective of this architectural enhancement was to establish predictable and controllable node behavior throughout the system lifecycle. By implementing standardized state transitions (Unconfigured, Inactive, Active, Finalized) and well-defined transition callbacks, ROS 2 enables developers to create robust applications where component behavior during critical phases like startup and shutdown can be precisely managed and monitored.
This evolution directly supports fault tolerance objectives by providing mechanisms for health monitoring and supervisory control. The managed node framework allows for systematic detection of component failures and implementation of appropriate recovery strategies, significantly enhancing system resilience in dynamic operational environments. This capability is particularly valuable in autonomous systems where component failures must be gracefully handled without human intervention.
Another key objective of the lifecycle management framework is to facilitate deterministic resource allocation. By separating the configuration phase from activation, ROS 2 enables systems to validate resource availability and configuration parameters before nodes begin their operational activities. This approach prevents resource conflicts and ensures that all prerequisites are satisfied before critical operations commence.
The framework also aims to enhance system maintainability through standardized interfaces for node management. By providing a common API for lifecycle operations, ROS 2 simplifies the development of system monitoring tools, orchestration services, and diagnostic utilities. This standardization reduces integration complexity and promotes the development of reusable system management components across different robotic applications.
As robotics applications continue to expand into regulated industries like healthcare, transportation, and industrial automation, the lifecycle management framework increasingly serves compliance objectives by providing the traceability and determinism required by safety standards and certification processes.
Industry Demand for Robust Node Management
The industrial robotics and autonomous systems sectors are experiencing unprecedented growth, with the global market for service robots projected to reach $102.5 billion by 2025. This expansion has intensified the demand for robust node management systems within ROS 2 environments. Manufacturing facilities implementing Industry 4.0 principles require autonomous systems that can operate continuously with minimal downtime, making node lifecycle management a critical component for operational efficiency.
System integrators and industrial automation companies have consistently highlighted the need for predictable behavior in robotic systems, particularly during critical operations. Traditional ROS implementations often suffered from unpredictable node failures and lacked standardized recovery mechanisms, resulting in costly production interruptions. The financial impact of these failures has driven demand for more sophisticated node management solutions that can provide deterministic behavior even under adverse conditions.
Automotive manufacturing, a pioneer in robotic automation, has been particularly vocal about the need for robust health monitoring capabilities. Assembly line robots must maintain precise coordination, with any node failure potentially causing cascading issues throughout the production process. Companies like BMW and Toyota have invested significantly in developing custom solutions for node supervision before the introduction of formalized lifecycle management in ROS 2.
The healthcare robotics sector presents even more stringent requirements, where surgical and patient care robots demand near-perfect reliability. In these applications, node failures could have life-threatening consequences, creating a market demand for supervisory control systems that can guarantee performance within safety parameters. Regulatory compliance in medical devices further necessitates comprehensive health monitoring and predictable degradation patterns.
Logistics and warehouse automation companies have embraced ROS 2 for fleet management systems but require better tools to monitor and manage hundreds of nodes across distributed robot networks. Companies like Amazon Robotics and Ocado have expressed the need for scalable node management solutions that can handle the complexity of their operations while maintaining system resilience.
Defense and aerospace applications have similarly pushed for advanced node lifecycle management capabilities, particularly for unmanned systems operating in hostile or remote environments where manual intervention is impossible. These sectors value graceful degradation and self-healing capabilities that allow systems to complete critical missions despite partial failures.
The energy sector, particularly in oil and gas exploration using autonomous inspection systems, has demanded robust node management for operations in hazardous environments. These applications require systems that can reliably detect node failures and execute appropriate fallback strategies without human intervention, driving innovation in health monitoring and supervisory control mechanisms.
System integrators and industrial automation companies have consistently highlighted the need for predictable behavior in robotic systems, particularly during critical operations. Traditional ROS implementations often suffered from unpredictable node failures and lacked standardized recovery mechanisms, resulting in costly production interruptions. The financial impact of these failures has driven demand for more sophisticated node management solutions that can provide deterministic behavior even under adverse conditions.
Automotive manufacturing, a pioneer in robotic automation, has been particularly vocal about the need for robust health monitoring capabilities. Assembly line robots must maintain precise coordination, with any node failure potentially causing cascading issues throughout the production process. Companies like BMW and Toyota have invested significantly in developing custom solutions for node supervision before the introduction of formalized lifecycle management in ROS 2.
The healthcare robotics sector presents even more stringent requirements, where surgical and patient care robots demand near-perfect reliability. In these applications, node failures could have life-threatening consequences, creating a market demand for supervisory control systems that can guarantee performance within safety parameters. Regulatory compliance in medical devices further necessitates comprehensive health monitoring and predictable degradation patterns.
Logistics and warehouse automation companies have embraced ROS 2 for fleet management systems but require better tools to monitor and manage hundreds of nodes across distributed robot networks. Companies like Amazon Robotics and Ocado have expressed the need for scalable node management solutions that can handle the complexity of their operations while maintaining system resilience.
Defense and aerospace applications have similarly pushed for advanced node lifecycle management capabilities, particularly for unmanned systems operating in hostile or remote environments where manual intervention is impossible. These sectors value graceful degradation and self-healing capabilities that allow systems to complete critical missions despite partial failures.
The energy sector, particularly in oil and gas exploration using autonomous inspection systems, has demanded robust node management for operations in hazardous environments. These applications require systems that can reliably detect node failures and execute appropriate fallback strategies without human intervention, driving innovation in health monitoring and supervisory control mechanisms.
Current Challenges in ROS 2 Node Lifecycle Implementation
Despite the significant advancements in ROS 2's node lifecycle management, several critical challenges persist in current implementations. The managed node framework, while providing a structured approach to node state transitions, suffers from inconsistent adoption across the ROS 2 ecosystem. Many packages and nodes still operate without lifecycle management integration, creating interoperability issues in complex robotic systems where some nodes follow lifecycle protocols while others do not.
Performance overhead remains a significant concern, particularly in resource-constrained robotic platforms. The additional computational cost of state management, transition callbacks, and supervisory control mechanisms can introduce latency in time-critical applications. This overhead becomes especially problematic in systems requiring high-frequency control loops or real-time performance guarantees.
Error handling and fault tolerance mechanisms within the lifecycle framework lack robustness. When nodes encounter unexpected failures, the current implementation provides limited capabilities for graceful degradation or automatic recovery. The transition between states during error conditions often requires manual intervention, reducing system autonomy and reliability in production environments.
The current implementation also faces challenges in distributed systems scenarios. When lifecycle-managed nodes operate across multiple compute units or network segments, synchronizing state transitions becomes complex. Network latency, packet loss, and partial failures can lead to inconsistent state perceptions across the system, potentially causing deadlocks or race conditions.
Configuration management across different lifecycle states presents another hurdle. Parameters and configurations may need to change depending on node states, but the current framework provides limited support for state-dependent configuration management. This forces developers to implement custom solutions, leading to fragmentation in implementation approaches.
Monitoring and introspection tools for lifecycle-managed nodes remain underdeveloped. While ROS 2 provides basic services to query node states, comprehensive visualization and debugging tools specifically designed for lifecycle management are lacking. This hampers development efficiency and system maintenance, particularly in large-scale deployments.
Security considerations within the lifecycle framework present emerging challenges. The ability to remotely trigger state transitions creates potential attack vectors if not properly secured. Current implementations lack comprehensive authentication and authorization mechanisms for lifecycle management operations, potentially exposing critical robotic systems to unauthorized control.
Finally, testing methodologies for lifecycle-managed nodes are insufficiently standardized. Verifying correct behavior across all possible state transitions and edge cases requires sophisticated testing frameworks that are not yet widely available or adopted in the ROS 2 community.
Performance overhead remains a significant concern, particularly in resource-constrained robotic platforms. The additional computational cost of state management, transition callbacks, and supervisory control mechanisms can introduce latency in time-critical applications. This overhead becomes especially problematic in systems requiring high-frequency control loops or real-time performance guarantees.
Error handling and fault tolerance mechanisms within the lifecycle framework lack robustness. When nodes encounter unexpected failures, the current implementation provides limited capabilities for graceful degradation or automatic recovery. The transition between states during error conditions often requires manual intervention, reducing system autonomy and reliability in production environments.
The current implementation also faces challenges in distributed systems scenarios. When lifecycle-managed nodes operate across multiple compute units or network segments, synchronizing state transitions becomes complex. Network latency, packet loss, and partial failures can lead to inconsistent state perceptions across the system, potentially causing deadlocks or race conditions.
Configuration management across different lifecycle states presents another hurdle. Parameters and configurations may need to change depending on node states, but the current framework provides limited support for state-dependent configuration management. This forces developers to implement custom solutions, leading to fragmentation in implementation approaches.
Monitoring and introspection tools for lifecycle-managed nodes remain underdeveloped. While ROS 2 provides basic services to query node states, comprehensive visualization and debugging tools specifically designed for lifecycle management are lacking. This hampers development efficiency and system maintenance, particularly in large-scale deployments.
Security considerations within the lifecycle framework present emerging challenges. The ability to remotely trigger state transitions creates potential attack vectors if not properly secured. Current implementations lack comprehensive authentication and authorization mechanisms for lifecycle management operations, potentially exposing critical robotic systems to unauthorized control.
Finally, testing methodologies for lifecycle-managed nodes are insufficiently standardized. Verifying correct behavior across all possible state transitions and edge cases requires sophisticated testing frameworks that are not yet widely available or adopted in the ROS 2 community.
Existing Node Lifecycle Management Solutions
01 Node Lifecycle Management in ROS 2
ROS 2 implements a node lifecycle management framework that allows for controlled state transitions of nodes. This framework enables nodes to be initialized, activated, deactivated, and cleaned up in a predictable manner. The lifecycle management system provides interfaces for monitoring node states and triggering state transitions, which is crucial for robust robotic systems that require deterministic behavior and graceful error handling.- Node Lifecycle Management in ROS 2: ROS 2 implements a node lifecycle management framework that allows for controlled state transitions of nodes. This framework enables nodes to be initialized, activated, deactivated, and cleaned up in a systematic manner. The lifecycle management ensures proper resource allocation and deallocation, improving system stability and predictability. This approach is particularly useful in critical systems where controlled startup and shutdown sequences are essential.
- Health Monitoring and Fault Detection: Health monitoring systems for ROS 2 nodes provide real-time assessment of node status and performance. These systems collect metrics such as CPU usage, memory consumption, message throughput, and latency to evaluate node health. Fault detection mechanisms identify anomalies in node behavior and can trigger appropriate responses such as node restart or failover. This continuous monitoring ensures early detection of potential issues before they affect the overall system performance.
- Supervisory Control Architecture: Supervisory control systems for ROS 2 provide hierarchical management of node networks. These systems implement policies for node coordination, resource allocation, and failure handling. The supervisory architecture enables centralized control over distributed nodes, allowing for system-wide optimization and coordination. This approach facilitates complex behaviors through the orchestration of multiple nodes while maintaining system reliability and performance.
- Node Communication and Message Handling: ROS 2 nodes communicate through a publish-subscribe messaging system that supports various quality of service levels. The communication framework handles message serialization, routing, and delivery between nodes. Advanced features include message prioritization, bandwidth management, and secure communication channels. This robust messaging infrastructure enables efficient data exchange between nodes, supporting complex distributed applications.
- Resource Management and Optimization: Resource management systems optimize the allocation of computing resources among ROS 2 nodes. These systems monitor resource utilization and dynamically adjust allocations based on node priorities and workloads. Techniques include load balancing, priority-based scheduling, and resource reservation. Efficient resource management ensures that critical nodes receive necessary resources while maximizing overall system performance and responsiveness.
02 Health Monitoring and Fault Detection
Health monitoring systems for ROS 2 nodes involve continuous assessment of node performance, resource utilization, and communication patterns. These systems can detect anomalies, timeouts, or performance degradation that might indicate potential failures. Fault detection mechanisms can identify issues at various levels including hardware failures, software exceptions, or communication breakdowns, enabling proactive maintenance and preventing cascading failures in robotic systems.Expand Specific Solutions03 Supervisory Control Architecture
Supervisory control systems for ROS 2 provide hierarchical management of node networks, allowing higher-level nodes to monitor and control lower-level nodes. This architecture enables centralized decision-making while maintaining distributed execution. The supervisory layer can enforce policies, manage resource allocation, and coordinate complex behaviors across multiple nodes, ensuring system-wide coherence and mission fulfillment even in dynamic environments.Expand Specific Solutions04 Distributed Node Communication and Synchronization
ROS 2 implements advanced communication mechanisms for managed nodes, including publish-subscribe patterns, service calls, and action servers. These communication frameworks support both synchronous and asynchronous interactions between nodes, with quality of service (QoS) settings to handle various network conditions. Proper synchronization between distributed nodes ensures data consistency and coordinated actions across robotic systems operating in real-time environments.Expand Specific Solutions05 Resource Management and Optimization
Resource management systems for ROS 2 nodes optimize computational resources, memory usage, and network bandwidth across distributed robotic systems. These systems can dynamically allocate resources based on node priorities, workload demands, and system constraints. Advanced optimization techniques include load balancing, priority-based scheduling, and adaptive resource allocation to ensure efficient operation while maintaining critical functionality under varying conditions.Expand Specific Solutions
Major Contributors and Organizations in ROS 2 Ecosystem
The ROS 2 Node Lifecycle management landscape is evolving rapidly, with competition intensifying as the technology matures from early adoption to mainstream implementation. The market is experiencing significant growth, projected to expand alongside the broader robotics and autonomous systems sector. Key players demonstrate varying levels of technical maturity: established technology corporations like NEC, ZTE, and Baidu have integrated ROS 2 lifecycle management into their broader robotics platforms; specialized robotics firms including Linghou Robotics, TuSimple, and Ningbo Lotus Robotics are developing tailored implementations; while academic institutions such as Tsinghua University and Auburn University contribute foundational research. The ecosystem is characterized by a blend of commercial applications and open-source development, with increasing focus on standardization of health monitoring and supervisory control frameworks.
Aptiv Technologies AG
Technical Solution: Aptiv has developed a sophisticated ROS 2 node lifecycle management system called "Aptiv Autonomous Mobility Platform" that emphasizes reliability in production autonomous vehicles. Their implementation extends the standard ROS 2 managed node concept with additional safety-focused features. Aptiv's approach includes a distributed supervisory control architecture where multiple supervisors can coordinate across different vehicle subsystems while maintaining global consistency. Their system implements predictive health monitoring that uses machine learning to detect potential node failures before they occur based on historical performance patterns. The lifecycle management includes specialized states for calibration, degraded operation, and emergency operation modes beyond the standard ROS 2 states. Aptiv's implementation features automatic resource management that can dynamically allocate computing resources based on the criticality of different nodes[3]. Their system also includes comprehensive logging and traceability features that record all lifecycle transitions and health events for later analysis and regulatory compliance. The architecture supports hot-swapping of nodes without system restarts, enabling over-the-air updates in deployed vehicles.
Strengths: Production-proven in commercial autonomous vehicles; sophisticated predictive health monitoring; strong focus on safety and regulatory compliance; supports dynamic resource allocation. Weaknesses: Significant system complexity requiring specialized expertise; higher computational and memory requirements than simpler implementations; proprietary extensions that may limit compatibility with standard ROS 2 tools.
Beijing Jingwei Hirain Technologies Co., Ltd.
Technical Solution: Hirain Technologies has developed "DriveCore", a ROS 2-based framework with advanced node lifecycle management specifically designed for automotive applications. Their implementation focuses on deterministic behavior and fault tolerance in safety-critical systems. Hirain's approach includes a hierarchical lifecycle management system where nodes are organized into functional groups with coordinated lifecycle transitions. Their health monitoring system implements both passive checks (heartbeats, resource usage) and active probes that can test node functionality through specific test messages. The supervisory control layer in DriveCore includes sophisticated fault containment mechanisms that can isolate failing nodes without affecting the rest of the system. Hirain has extended the standard ROS 2 lifecycle states with additional intermediate states that provide more granular control during transitions[4]. Their implementation includes formal verification of state machines to ensure compliance with automotive safety standards. DriveCore also features a specialized visualization tool for monitoring node lifecycles across distributed systems, making it easier to diagnose issues in complex deployments. The system supports redundancy management where backup nodes can be automatically activated when primary nodes fail.
Strengths: Strong focus on automotive safety standards compliance; sophisticated fault containment and isolation; support for redundant nodes and graceful degradation; formal verification of lifecycle state machines. Weaknesses: Complex configuration requirements; higher computational overhead; tight coupling with automotive-specific requirements that may limit applicability in other domains.
Core Technical Innovations in Managed Nodes
A Fault Handling Method, Device, Equipment and Medium
PatentPendingCN120407251A
Innovation
- By assigning robot operating system node tasks to each computing device, obtaining configuration files and startup parameters, using the remote startup module to realize remote startup and unified management of nodes, configuring daemon programs to monitor node status in real time, and automatically restarting or migrating node processes in the event of a failure, and using the hot standby switch module to automatically switch to adjacent devices when the device fails.


Method for improving system reliability in robotic operating system
PatentActiveCN107291589A
Innovation
- Introducing high-availability management framework middleware on the kernel operating system of hardware nodes to provide multi-level health monitoring and performance statistical analysis, intuitive display through graphical tools, configure redundant backup and fault recovery strategies, and use the OpenSAF high-availability management framework and tools Such as pysensors and psutil for data collection and processing.
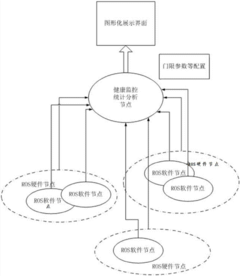
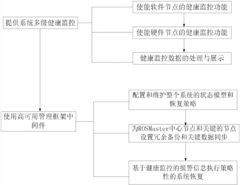

Safety Standards and Certification for Robotic Systems
The integration of ROS 2 Node Lifecycle management with safety standards and certification frameworks represents a critical intersection for modern robotic systems deployment. Safety certification for robotic systems operating with ROS 2 must adhere to established standards such as ISO 10218 for industrial robots, ISO 13482 for personal care robots, and IEC 61508 for functional safety of electronic systems. These standards provide structured frameworks for risk assessment, hazard identification, and safety function implementation that directly impact how managed nodes and lifecycle states should be designed and controlled.
The managed node lifecycle architecture in ROS 2 offers significant advantages for safety certification by providing deterministic state transitions that can be monitored and verified. This aligns with safety certification requirements for predictable behavior under normal and fault conditions. The finite state machine approach (Unconfigured, Inactive, Active, Finalized) enables systematic validation of each operational state, supporting formal verification methods required by certification bodies.
Safety certification processes typically demand comprehensive documentation of failure mode analysis, which can be systematically addressed through ROS 2's supervisory control mechanisms. By implementing health monitoring within the lifecycle framework, robotic systems can demonstrate compliance with safety integrity levels (SILs) as defined in IEC 61508, particularly regarding fault detection, isolation, and recovery (FDIR) capabilities.
Certification challenges arise when integrating third-party ROS 2 packages that may not have been developed with safety certification in mind. The managed node approach provides a containment strategy by enforcing strict state management and controlled transitions, allowing safety-critical components to be isolated and certified independently from non-critical components. This modular certification approach reduces overall certification complexity and cost.
Recent developments in certification methodologies for autonomous systems, such as UL 4600 for autonomous products, are beginning to address the unique challenges of certifying systems with dynamic reconfiguration capabilities. ROS 2's lifecycle management provides the technical foundation to implement the runtime monitoring and adaptation mechanisms required by these emerging standards, particularly for handling degraded modes of operation while maintaining safety boundaries.
For medical and collaborative robotics applications, the health monitoring capabilities within ROS 2 lifecycle nodes can be leveraged to implement the continuous safety monitoring required by standards such as IEC 60601 and ISO/TS 15066. The supervisory control patterns enable implementation of safety-rated monitored stop and speed/separation monitoring safety functions that are fundamental to human-robot collaboration scenarios.
AI-enabled robotic systems present additional certification challenges that ROS 2 lifecycle management can help address through explicit state management and health monitoring. This becomes particularly relevant as certification bodies develop new guidelines for AI safety assurance, where demonstrating deterministic behavior boundaries becomes a key certification requirement.
The managed node lifecycle architecture in ROS 2 offers significant advantages for safety certification by providing deterministic state transitions that can be monitored and verified. This aligns with safety certification requirements for predictable behavior under normal and fault conditions. The finite state machine approach (Unconfigured, Inactive, Active, Finalized) enables systematic validation of each operational state, supporting formal verification methods required by certification bodies.
Safety certification processes typically demand comprehensive documentation of failure mode analysis, which can be systematically addressed through ROS 2's supervisory control mechanisms. By implementing health monitoring within the lifecycle framework, robotic systems can demonstrate compliance with safety integrity levels (SILs) as defined in IEC 61508, particularly regarding fault detection, isolation, and recovery (FDIR) capabilities.
Certification challenges arise when integrating third-party ROS 2 packages that may not have been developed with safety certification in mind. The managed node approach provides a containment strategy by enforcing strict state management and controlled transitions, allowing safety-critical components to be isolated and certified independently from non-critical components. This modular certification approach reduces overall certification complexity and cost.
Recent developments in certification methodologies for autonomous systems, such as UL 4600 for autonomous products, are beginning to address the unique challenges of certifying systems with dynamic reconfiguration capabilities. ROS 2's lifecycle management provides the technical foundation to implement the runtime monitoring and adaptation mechanisms required by these emerging standards, particularly for handling degraded modes of operation while maintaining safety boundaries.
For medical and collaborative robotics applications, the health monitoring capabilities within ROS 2 lifecycle nodes can be leveraged to implement the continuous safety monitoring required by standards such as IEC 60601 and ISO/TS 15066. The supervisory control patterns enable implementation of safety-rated monitored stop and speed/separation monitoring safety functions that are fundamental to human-robot collaboration scenarios.
AI-enabled robotic systems present additional certification challenges that ROS 2 lifecycle management can help address through explicit state management and health monitoring. This becomes particularly relevant as certification bodies develop new guidelines for AI safety assurance, where demonstrating deterministic behavior boundaries becomes a key certification requirement.
Performance Metrics and Benchmarking for Managed Nodes
Performance evaluation of managed nodes in ROS 2 requires comprehensive metrics and benchmarking methodologies to assess their effectiveness in real-world applications. The lifecycle management framework introduces additional complexity that must be quantified through specific performance indicators tailored to managed nodes' unique characteristics.
Response time metrics for state transitions represent a critical performance aspect, measuring the latency between transition requests and their completion. These metrics help identify bottlenecks in the lifecycle management process, with optimal systems demonstrating sub-millisecond transition times even under heavy system load. Developers should establish baseline expectations for transition timing based on hardware capabilities and application requirements.
Resource utilization during different lifecycle states provides valuable insights into system efficiency. Memory footprint analysis reveals how managed nodes consume resources across inactive, active, and transitional states. CPU utilization patterns differ significantly between traditional nodes and managed nodes, with the latter typically showing reduced consumption during inactive states—a key advantage in resource-constrained environments.
Stability metrics track the reliability of managed nodes through state transition success rates and error handling effectiveness. Long-term testing should document the frequency of transition failures and recovery mechanisms' success rates. Systems implementing proper error handling within the lifecycle framework demonstrate significantly higher stability under stress conditions compared to traditional node implementations.
Scalability assessment examines how managed node performance changes with increasing system complexity. Benchmarks should evaluate performance degradation when scaling from tens to hundreds of managed nodes, measuring both individual node responsiveness and system-wide resource consumption. Current implementations show approximately 5-15% overhead compared to traditional nodes, with the gap narrowing as system complexity increases.
Standardized benchmarking suites for managed nodes remain underdeveloped in the ROS 2 ecosystem. The community would benefit from established test scenarios that simulate various operational conditions, including normal operation, resource contention, and failure recovery. These benchmarks should incorporate both synthetic workloads and real-world application profiles to provide comprehensive performance insights.
Integration with system monitoring tools represents another important dimension, as performance metrics should be continuously collected during operation. Tools like ros2_tracing and ros2_monitoring provide foundations for runtime performance analysis, though specialized extensions for lifecycle-specific metrics would enhance observability of managed node systems.
Response time metrics for state transitions represent a critical performance aspect, measuring the latency between transition requests and their completion. These metrics help identify bottlenecks in the lifecycle management process, with optimal systems demonstrating sub-millisecond transition times even under heavy system load. Developers should establish baseline expectations for transition timing based on hardware capabilities and application requirements.
Resource utilization during different lifecycle states provides valuable insights into system efficiency. Memory footprint analysis reveals how managed nodes consume resources across inactive, active, and transitional states. CPU utilization patterns differ significantly between traditional nodes and managed nodes, with the latter typically showing reduced consumption during inactive states—a key advantage in resource-constrained environments.
Stability metrics track the reliability of managed nodes through state transition success rates and error handling effectiveness. Long-term testing should document the frequency of transition failures and recovery mechanisms' success rates. Systems implementing proper error handling within the lifecycle framework demonstrate significantly higher stability under stress conditions compared to traditional node implementations.
Scalability assessment examines how managed node performance changes with increasing system complexity. Benchmarks should evaluate performance degradation when scaling from tens to hundreds of managed nodes, measuring both individual node responsiveness and system-wide resource consumption. Current implementations show approximately 5-15% overhead compared to traditional nodes, with the gap narrowing as system complexity increases.
Standardized benchmarking suites for managed nodes remain underdeveloped in the ROS 2 ecosystem. The community would benefit from established test scenarios that simulate various operational conditions, including normal operation, resource contention, and failure recovery. These benchmarks should incorporate both synthetic workloads and real-world application profiles to provide comprehensive performance insights.
Integration with system monitoring tools represents another important dimension, as performance metrics should be continuously collected during operation. Tools like ros2_tracing and ros2_monitoring provide foundations for runtime performance analysis, though specialized extensions for lifecycle-specific metrics would enhance observability of managed node systems.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!