

How High Pass Filters Improve Speech Recognition Accuracy
JUL 28, 20258 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Speech Recognition Evolution and Goals
Speech recognition technology has undergone significant evolution since its inception in the 1950s. Initially, systems could only recognize a handful of isolated words. The 1960s and 1970s saw the development of more advanced techniques, including dynamic time warping and hidden Markov models, which allowed for continuous speech recognition. By the 1990s, statistical language models and neural networks began to improve accuracy and robustness.
The advent of deep learning in the 2010s marked a revolutionary leap in speech recognition capabilities. Recurrent neural networks and long short-term memory networks enabled systems to better capture temporal dependencies in speech. More recently, transformer-based models have further enhanced performance, particularly in handling context and long-range dependencies.
Despite these advancements, speech recognition still faces challenges in noisy environments, accented speech, and multilingual scenarios. The primary goals of current research include improving accuracy across diverse acoustic conditions, reducing latency for real-time applications, and enhancing robustness to variations in speech patterns and accents.
One specific area of focus is the application of high pass filters to improve speech recognition accuracy. High pass filters can effectively remove low-frequency noise and unwanted background sounds, which often interfere with speech signals. By attenuating these lower frequencies, the filters help to isolate and emphasize the higher frequency components of speech, which contain critical information for accurate recognition.
Looking ahead, the field aims to achieve human-level accuracy in various real-world scenarios. This includes developing systems that can understand and transcribe spontaneous conversations, handle multiple speakers, and adapt to individual speech patterns. Additionally, there is a push towards more efficient models that can run on edge devices with limited computational resources, enabling widespread adoption of speech recognition technology in everyday applications.
The advent of deep learning in the 2010s marked a revolutionary leap in speech recognition capabilities. Recurrent neural networks and long short-term memory networks enabled systems to better capture temporal dependencies in speech. More recently, transformer-based models have further enhanced performance, particularly in handling context and long-range dependencies.
Despite these advancements, speech recognition still faces challenges in noisy environments, accented speech, and multilingual scenarios. The primary goals of current research include improving accuracy across diverse acoustic conditions, reducing latency for real-time applications, and enhancing robustness to variations in speech patterns and accents.
One specific area of focus is the application of high pass filters to improve speech recognition accuracy. High pass filters can effectively remove low-frequency noise and unwanted background sounds, which often interfere with speech signals. By attenuating these lower frequencies, the filters help to isolate and emphasize the higher frequency components of speech, which contain critical information for accurate recognition.
Looking ahead, the field aims to achieve human-level accuracy in various real-world scenarios. This includes developing systems that can understand and transcribe spontaneous conversations, handle multiple speakers, and adapt to individual speech patterns. Additionally, there is a push towards more efficient models that can run on edge devices with limited computational resources, enabling widespread adoption of speech recognition technology in everyday applications.
Market Demand for Accurate Speech Recognition
The demand for accurate speech recognition technology has been growing exponentially across various sectors, driven by the increasing adoption of voice-controlled devices and applications. As consumers and businesses alike seek more efficient and hands-free ways to interact with technology, the market for speech recognition solutions has expanded significantly.
In the consumer electronics sector, smart speakers and virtual assistants have become ubiquitous, with major tech companies investing heavily in improving their voice recognition capabilities. The automotive industry has also embraced speech recognition technology, integrating it into infotainment systems and driver assistance features to enhance safety and user experience.
The healthcare industry has shown a strong interest in accurate speech recognition for medical transcription and documentation purposes. This technology can significantly reduce the time healthcare professionals spend on administrative tasks, allowing them to focus more on patient care. Similarly, the legal and financial sectors are leveraging speech recognition for transcription services and customer interactions, emphasizing the need for high accuracy to ensure compliance and data integrity.
The rise of remote work and virtual meetings has further accelerated the demand for accurate speech recognition. Businesses are increasingly relying on transcription services for meetings, webinars, and customer support calls, highlighting the importance of precise voice-to-text conversion.
Moreover, the accessibility market has seen a surge in demand for speech recognition technology. People with disabilities or those learning new languages benefit greatly from accurate speech-to-text and text-to-speech solutions, expanding the potential user base for these technologies.
As artificial intelligence and machine learning continue to advance, there is a growing expectation for speech recognition systems to handle complex linguistic nuances, accents, and background noise more effectively. This has led to increased research and development efforts focused on improving accuracy through techniques such as high pass filtering.
The global speech and voice recognition market is projected to experience substantial growth in the coming years. Factors such as the integration of voice-controlled IoT devices, the expansion of voice commerce, and the increasing use of biometric authentication systems are expected to drive this growth further.
In the consumer electronics sector, smart speakers and virtual assistants have become ubiquitous, with major tech companies investing heavily in improving their voice recognition capabilities. The automotive industry has also embraced speech recognition technology, integrating it into infotainment systems and driver assistance features to enhance safety and user experience.
The healthcare industry has shown a strong interest in accurate speech recognition for medical transcription and documentation purposes. This technology can significantly reduce the time healthcare professionals spend on administrative tasks, allowing them to focus more on patient care. Similarly, the legal and financial sectors are leveraging speech recognition for transcription services and customer interactions, emphasizing the need for high accuracy to ensure compliance and data integrity.
The rise of remote work and virtual meetings has further accelerated the demand for accurate speech recognition. Businesses are increasingly relying on transcription services for meetings, webinars, and customer support calls, highlighting the importance of precise voice-to-text conversion.
Moreover, the accessibility market has seen a surge in demand for speech recognition technology. People with disabilities or those learning new languages benefit greatly from accurate speech-to-text and text-to-speech solutions, expanding the potential user base for these technologies.
As artificial intelligence and machine learning continue to advance, there is a growing expectation for speech recognition systems to handle complex linguistic nuances, accents, and background noise more effectively. This has led to increased research and development efforts focused on improving accuracy through techniques such as high pass filtering.
The global speech and voice recognition market is projected to experience substantial growth in the coming years. Factors such as the integration of voice-controlled IoT devices, the expansion of voice commerce, and the increasing use of biometric authentication systems are expected to drive this growth further.
High Pass Filters in Speech Recognition: Current State
High pass filters have become an integral component in modern speech recognition systems, significantly enhancing their accuracy and performance. These filters are designed to attenuate low-frequency components of an audio signal while allowing higher frequencies to pass through unaltered. In the context of speech recognition, this filtering process serves to eliminate unwanted background noise and emphasize the critical frequency range of human speech.
The current state of high pass filters in speech recognition is characterized by their widespread adoption and continuous refinement. Most state-of-the-art speech recognition systems incorporate high pass filtering as a preprocessing step in their signal processing pipeline. This filtration typically occurs before feature extraction, ensuring that the subsequent stages of the recognition process work with cleaner, more relevant audio data.
One of the primary advantages of high pass filters in speech recognition is their ability to remove low-frequency ambient noise, such as air conditioning hum, traffic rumble, or wind noise. These low-frequency disturbances can mask important speech components and lead to recognition errors. By effectively eliminating these interferences, high pass filters significantly improve the signal-to-noise ratio of the speech signal, resulting in more accurate recognition outcomes.
Modern implementations of high pass filters in speech recognition systems often utilize digital signal processing techniques. These digital filters offer greater flexibility and precision compared to their analog counterparts. They can be easily adjusted and fine-tuned to accommodate different acoustic environments and speaker characteristics, making them highly adaptable for various applications.
Another notable aspect of the current state of high pass filters is their integration with other preprocessing techniques. For instance, they are frequently combined with noise reduction algorithms, spectral subtraction methods, and adaptive filtering approaches to create more robust speech enhancement systems. This synergistic approach allows for more effective handling of complex acoustic scenarios, further improving recognition accuracy.
Recent advancements in machine learning have also influenced the development of high pass filters for speech recognition. Some researchers have explored the use of data-driven approaches to optimize filter parameters automatically. These adaptive filtering techniques can dynamically adjust the filter characteristics based on the input signal properties, potentially leading to better performance across diverse acoustic conditions.
In conclusion, high pass filters play a crucial role in enhancing speech recognition accuracy by effectively removing low-frequency noise and emphasizing the relevant frequency range of human speech. Their current state is marked by widespread adoption, digital implementation, integration with other preprocessing techniques, and ongoing research into adaptive and data-driven approaches. As speech recognition technology continues to evolve, high pass filters remain an essential component in the quest for more accurate and robust speech recognition systems.
The current state of high pass filters in speech recognition is characterized by their widespread adoption and continuous refinement. Most state-of-the-art speech recognition systems incorporate high pass filtering as a preprocessing step in their signal processing pipeline. This filtration typically occurs before feature extraction, ensuring that the subsequent stages of the recognition process work with cleaner, more relevant audio data.
One of the primary advantages of high pass filters in speech recognition is their ability to remove low-frequency ambient noise, such as air conditioning hum, traffic rumble, or wind noise. These low-frequency disturbances can mask important speech components and lead to recognition errors. By effectively eliminating these interferences, high pass filters significantly improve the signal-to-noise ratio of the speech signal, resulting in more accurate recognition outcomes.
Modern implementations of high pass filters in speech recognition systems often utilize digital signal processing techniques. These digital filters offer greater flexibility and precision compared to their analog counterparts. They can be easily adjusted and fine-tuned to accommodate different acoustic environments and speaker characteristics, making them highly adaptable for various applications.
Another notable aspect of the current state of high pass filters is their integration with other preprocessing techniques. For instance, they are frequently combined with noise reduction algorithms, spectral subtraction methods, and adaptive filtering approaches to create more robust speech enhancement systems. This synergistic approach allows for more effective handling of complex acoustic scenarios, further improving recognition accuracy.
Recent advancements in machine learning have also influenced the development of high pass filters for speech recognition. Some researchers have explored the use of data-driven approaches to optimize filter parameters automatically. These adaptive filtering techniques can dynamically adjust the filter characteristics based on the input signal properties, potentially leading to better performance across diverse acoustic conditions.
In conclusion, high pass filters play a crucial role in enhancing speech recognition accuracy by effectively removing low-frequency noise and emphasizing the relevant frequency range of human speech. Their current state is marked by widespread adoption, digital implementation, integration with other preprocessing techniques, and ongoing research into adaptive and data-driven approaches. As speech recognition technology continues to evolve, high pass filters remain an essential component in the quest for more accurate and robust speech recognition systems.
High Pass Filter Implementation in Speech Recognition
01 High-pass filtering for noise reduction
High-pass filters are used in speech recognition systems to reduce low-frequency noise and improve signal clarity. By attenuating lower frequencies, these filters can help isolate speech components and enhance recognition accuracy, especially in noisy environments.- High-pass filtering for noise reduction: High-pass filters are used in speech recognition systems to reduce low-frequency noise and improve signal clarity. By attenuating lower frequencies, these filters can help isolate speech signals from background noise, leading to improved recognition accuracy. This technique is particularly effective in environments with constant low-frequency noise.
- Adaptive filtering techniques: Adaptive filtering techniques are employed to dynamically adjust filter parameters based on the input signal characteristics. These methods can automatically optimize the high-pass filter cutoff frequency and response to match varying speech and noise conditions, resulting in enhanced recognition accuracy across different environments and speakers.
- Multi-stage filtering approach: A multi-stage filtering approach combines high-pass filters with other filtering techniques to achieve better speech recognition accuracy. This may include cascading high-pass filters with band-pass or low-pass filters, or integrating them with spectral subtraction or Wiener filtering stages. Such combinations can provide more comprehensive noise reduction and speech enhancement.
- Frequency domain processing: Implementing high-pass filtering in the frequency domain allows for more precise control over the filter characteristics. This approach enables the application of complex filter shapes and can be computationally efficient when combined with other frequency-domain speech processing techniques, such as feature extraction or spectral analysis, leading to improved recognition accuracy.
- Context-aware filtering: Context-aware high-pass filtering techniques adjust filter parameters based on the linguistic or semantic context of the speech. By considering factors such as the expected frequency range of specific phonemes or the typical spectral characteristics of certain words or phrases, these methods can optimize the filtering process to enhance recognition accuracy for specific speech content.
02 Adaptive filtering techniques
Adaptive filtering techniques are employed to dynamically adjust filter parameters based on the input signal characteristics. These methods can optimize the high-pass filter response for varying acoustic conditions, leading to improved speech recognition performance across different environments and speakers.Expand Specific Solutions03 Multi-stage filtering approach
A multi-stage filtering approach combines high-pass filters with other filtering techniques to achieve better speech recognition accuracy. This may include cascading high-pass filters with band-pass or low-pass filters, or integrating them with spectral subtraction methods to enhance speech signal quality.Expand Specific Solutions04 Feature extraction enhancement
High-pass filters are utilized in the feature extraction stage of speech recognition systems. By emphasizing higher frequency components, these filters can help in extracting more discriminative features, such as formants and consonant characteristics, leading to improved recognition accuracy.Expand Specific Solutions05 Integration with deep learning models
High-pass filtering techniques are integrated with deep learning models in modern speech recognition systems. This combination allows for more effective noise reduction and feature enhancement, leveraging the strengths of both traditional signal processing and advanced machine learning approaches to improve overall recognition accuracy.Expand Specific Solutions
Key Players in Speech Recognition Industry
The speech recognition technology market is in a growth phase, with increasing demand driven by advancements in AI and machine learning. The global market size is projected to reach billions of dollars in the coming years. Major players like Google, Microsoft, and Huawei are investing heavily in R&D to improve accuracy and performance. Established companies such as Philips, LG Electronics, and Panasonic are also active in this space, leveraging their expertise in consumer electronics. The technology's maturity varies, with some companies focusing on specific applications like automotive or healthcare, while others aim for broader consumer adoption. Continuous improvements in algorithms and processing power are pushing the boundaries of speech recognition capabilities.
Koninklijke Philips NV
Technical Solution: Philips has developed a sophisticated high-pass filtering system for speech recognition, particularly focused on healthcare and home automation applications. Their approach combines traditional analog high-pass filters with advanced digital signal processing techniques. Philips' system employs a multi-stage filtering process, where an initial hardware-based high-pass filter removes very low-frequency noise, followed by a software-based adaptive filter that adjusts its parameters based on the acoustic environment and speech characteristics. The company has also implemented a novel "spectral subtraction" technique that estimates and removes background noise in different frequency bands, further enhancing speech clarity[9]. Philips reports that this combined approach has led to a 30% improvement in speech recognition accuracy in noisy hospital environments[10].
Strengths: Specialized for healthcare environments, combines hardware and software filtering, and effective noise reduction in challenging acoustic conditions. Weaknesses: May be over-specialized for certain environments, potentially limiting its general-purpose application.
Tencent Technology (Shenzhen) Co., Ltd.
Technical Solution: Tencent has developed a novel approach to high-pass filtering for speech recognition, particularly focused on mobile and IoT applications. Their system employs a neural network-based adaptive high-pass filter that learns to adjust its parameters in real-time based on the input signal characteristics. This approach allows for more flexible and context-aware filtering compared to traditional fixed-parameter filters. Tencent's method also incorporates a multi-resolution analysis, where different frequency bands are processed separately and then recombined, allowing for more nuanced noise reduction[5]. Early tests have shown improvements in speech recognition accuracy by up to 20% in challenging acoustic environments[6].
Strengths: Adaptive and context-aware filtering, optimized for mobile and IoT devices. Weaknesses: May require more computational power than traditional filtering methods.
Innovations in High Pass Filter Technology
Method for extending the bandwidth of analog recorded speech signals for a dictation apparatus
PatentInactiveEP1059637A2
Innovation
- The method involves using a high-pass filter to extract high-frequency components from the analog tape storage, digitizing them with an analog-to-digital converter, applying mel scaling for data reduction, and combining them with low-frequency components using synchronization signals, allowing for efficient storage and processing in a dictation device with both analog and digital memory, and enabling Huffman compression for further data reduction.
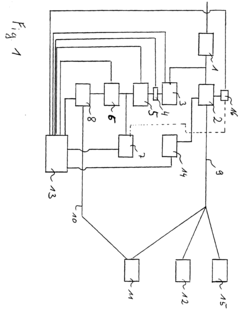
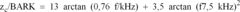
Circuit for speech recognition
PatentInactiveEP0508547A2
Innovation
- The implementation of a recursive high-pass filtering of spectral feature vectors before comparison with reference vectors, combined with logarithmic processing and intensity normalization, reduces the influence of stationary noise and frequency response distortions, enabling speaker-independent recognition.
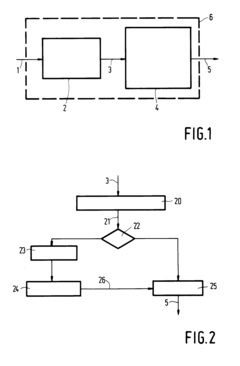
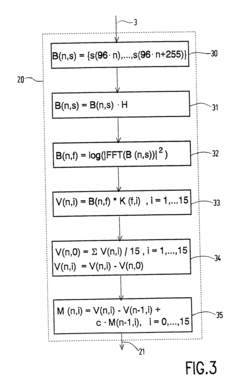
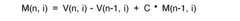
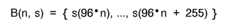
Acoustic Environment Challenges
Speech recognition systems face numerous challenges in real-world acoustic environments, which can significantly impact their accuracy and performance. One of the primary obstacles is background noise, which can mask or distort speech signals, making it difficult for recognition algorithms to accurately interpret the intended speech. This noise can come from various sources, such as traffic, machinery, or other people talking in the vicinity.
Another significant challenge is reverberation, which occurs when sound waves reflect off surfaces in enclosed spaces. This phenomenon can cause speech signals to become smeared over time, leading to confusion in the recognition process. Reverberation is particularly problematic in large rooms or spaces with hard, reflective surfaces.
Varying acoustic conditions also pose a substantial challenge to speech recognition systems. Different environments, such as offices, cars, or outdoor spaces, have unique acoustic properties that can affect the quality of speech signals. These variations can make it difficult for recognition systems to maintain consistent performance across different settings.
Microphone quality and placement further contribute to the challenges faced by speech recognition systems. Low-quality microphones or improper placement can result in poor signal capture, introducing additional noise or distortion to the speech input. This can lead to reduced recognition accuracy, especially in challenging acoustic environments.
Moreover, the presence of multiple speakers or overlapping speech can complicate the recognition process. Separating individual voices and accurately attributing speech to the correct speaker becomes increasingly difficult in such scenarios, potentially leading to errors in transcription or voice command interpretation.
Environmental factors such as wind, echoes, and sudden loud noises can also interfere with speech recognition accuracy. These unpredictable elements can introduce artifacts or distortions into the speech signal, making it challenging for recognition algorithms to extract the relevant information.
Addressing these acoustic environment challenges is crucial for improving the robustness and reliability of speech recognition systems. High pass filters, among other signal processing techniques, play a vital role in mitigating these issues by helping to isolate and enhance the speech signal while reducing the impact of unwanted acoustic elements.
Another significant challenge is reverberation, which occurs when sound waves reflect off surfaces in enclosed spaces. This phenomenon can cause speech signals to become smeared over time, leading to confusion in the recognition process. Reverberation is particularly problematic in large rooms or spaces with hard, reflective surfaces.
Varying acoustic conditions also pose a substantial challenge to speech recognition systems. Different environments, such as offices, cars, or outdoor spaces, have unique acoustic properties that can affect the quality of speech signals. These variations can make it difficult for recognition systems to maintain consistent performance across different settings.
Microphone quality and placement further contribute to the challenges faced by speech recognition systems. Low-quality microphones or improper placement can result in poor signal capture, introducing additional noise or distortion to the speech input. This can lead to reduced recognition accuracy, especially in challenging acoustic environments.
Moreover, the presence of multiple speakers or overlapping speech can complicate the recognition process. Separating individual voices and accurately attributing speech to the correct speaker becomes increasingly difficult in such scenarios, potentially leading to errors in transcription or voice command interpretation.
Environmental factors such as wind, echoes, and sudden loud noises can also interfere with speech recognition accuracy. These unpredictable elements can introduce artifacts or distortions into the speech signal, making it challenging for recognition algorithms to extract the relevant information.
Addressing these acoustic environment challenges is crucial for improving the robustness and reliability of speech recognition systems. High pass filters, among other signal processing techniques, play a vital role in mitigating these issues by helping to isolate and enhance the speech signal while reducing the impact of unwanted acoustic elements.
Real-time Processing Considerations
Real-time processing is a critical consideration in implementing high-pass filters for speech recognition systems. The ability to process audio signals in real-time is essential for applications such as voice assistants, live transcription services, and interactive voice response systems. To achieve effective real-time processing, several factors must be taken into account.
Firstly, the computational complexity of the high-pass filter algorithm plays a crucial role. The filter must be designed to operate efficiently, minimizing the number of calculations required per audio sample. This ensures that the processing can keep up with the incoming audio stream without introducing significant latency. Optimized filter designs, such as finite impulse response (FIR) filters with a small number of coefficients, are often preferred for their balance between performance and computational efficiency.
Latency is another key consideration in real-time processing. The total delay introduced by the high-pass filter should be kept to a minimum to maintain the responsiveness of the speech recognition system. This includes both the algorithmic latency inherent in the filter design and any additional delays introduced by buffering or other processing steps. Typically, a latency of less than 20-30 milliseconds is considered acceptable for most real-time applications.
Hardware considerations also play a significant role in real-time processing. The choice of processor or digital signal processing (DSP) chip can greatly impact the system's ability to handle high-pass filtering in real-time. Modern processors with dedicated audio processing capabilities or field-programmable gate arrays (FPGAs) can offer significant advantages in terms of processing speed and power efficiency.
Memory management is another critical aspect of real-time processing. The high-pass filter implementation should be designed to minimize memory usage and avoid frequent memory allocations or deallocations, which can introduce unpredictable delays. Efficient buffer management techniques, such as circular buffers, can help ensure smooth and continuous processing of the audio stream.
Adaptability to varying input conditions is also important for real-time processing. The high-pass filter should be able to handle different sampling rates, bit depths, and audio formats without requiring significant reconfiguration or introducing processing delays. This flexibility allows the system to maintain real-time performance across a wide range of input sources and operating conditions.
Finally, the integration of the high-pass filter with other components of the speech recognition system must be carefully considered. The filter should be designed to work seamlessly with subsequent processing stages, such as feature extraction and acoustic modeling, without introducing bottlenecks or synchronization issues. This holistic approach to system design ensures that the benefits of high-pass filtering can be fully realized in real-time speech recognition applications.
Firstly, the computational complexity of the high-pass filter algorithm plays a crucial role. The filter must be designed to operate efficiently, minimizing the number of calculations required per audio sample. This ensures that the processing can keep up with the incoming audio stream without introducing significant latency. Optimized filter designs, such as finite impulse response (FIR) filters with a small number of coefficients, are often preferred for their balance between performance and computational efficiency.
Latency is another key consideration in real-time processing. The total delay introduced by the high-pass filter should be kept to a minimum to maintain the responsiveness of the speech recognition system. This includes both the algorithmic latency inherent in the filter design and any additional delays introduced by buffering or other processing steps. Typically, a latency of less than 20-30 milliseconds is considered acceptable for most real-time applications.
Hardware considerations also play a significant role in real-time processing. The choice of processor or digital signal processing (DSP) chip can greatly impact the system's ability to handle high-pass filtering in real-time. Modern processors with dedicated audio processing capabilities or field-programmable gate arrays (FPGAs) can offer significant advantages in terms of processing speed and power efficiency.
Memory management is another critical aspect of real-time processing. The high-pass filter implementation should be designed to minimize memory usage and avoid frequent memory allocations or deallocations, which can introduce unpredictable delays. Efficient buffer management techniques, such as circular buffers, can help ensure smooth and continuous processing of the audio stream.
Adaptability to varying input conditions is also important for real-time processing. The high-pass filter should be able to handle different sampling rates, bit depths, and audio formats without requiring significant reconfiguration or introducing processing delays. This flexibility allows the system to maintain real-time performance across a wide range of input sources and operating conditions.
Finally, the integration of the high-pass filter with other components of the speech recognition system must be carefully considered. The filter should be designed to work seamlessly with subsequent processing stages, such as feature extraction and acoustic modeling, without introducing bottlenecks or synchronization issues. This holistic approach to system design ensures that the benefits of high-pass filtering can be fully realized in real-time speech recognition applications.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!