

Optimizing Brain-Computer Interface Library Integration for Faster Execution
MAR 5, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
BCI Library Integration Background and Objectives
Brain-Computer Interface technology has emerged as one of the most transformative fields in computational neuroscience, representing a convergence of neurobiology, signal processing, machine learning, and real-time computing systems. The evolution of BCI systems began in the 1970s with basic electroencephalography applications and has progressed through decades of advancement in neural signal acquisition, processing algorithms, and hardware miniaturization. Today's BCI landscape encompasses invasive and non-invasive approaches, spanning from research-grade systems requiring extensive computational resources to consumer-oriented devices demanding efficient, lightweight implementations.
The current technological trajectory reveals a critical bottleneck in BCI library integration and execution efficiency. Traditional BCI systems often rely on disparate software libraries, each optimized for specific functions such as signal acquisition, feature extraction, classification, or device control. This fragmented approach creates significant computational overhead, introduces latency issues, and complicates real-time performance requirements essential for practical BCI applications.
Modern BCI applications demand sub-millisecond response times for critical functions like motor control prosthetics, communication aids for paralyzed patients, and cognitive enhancement systems. However, existing library integration approaches frequently suffer from inefficient memory management, redundant computational processes, and suboptimal inter-library communication protocols. These limitations become particularly pronounced in resource-constrained environments such as embedded BCI devices, mobile platforms, and wearable neurotechnology systems.
The primary objective of optimizing BCI library integration centers on achieving seamless interoperability between diverse computational modules while minimizing execution latency and resource consumption. This involves developing unified frameworks that can efficiently coordinate signal processing pipelines, machine learning inference engines, and real-time control systems without compromising accuracy or reliability.
Key technical goals include establishing standardized interfaces for cross-library communication, implementing intelligent caching mechanisms for frequently accessed neural patterns, and developing adaptive resource allocation strategies that can dynamically optimize performance based on real-time system demands. Additionally, the integration framework must support scalable architectures capable of accommodating emerging BCI modalities and evolving algorithmic approaches.
The strategic importance of this optimization extends beyond immediate performance gains, positioning organizations to leverage next-generation BCI applications in healthcare, human augmentation, and brain-controlled computing interfaces. Success in this domain requires addressing fundamental challenges in parallel processing, memory optimization, and real-time system design while maintaining the flexibility necessary for rapid technological adaptation.
The current technological trajectory reveals a critical bottleneck in BCI library integration and execution efficiency. Traditional BCI systems often rely on disparate software libraries, each optimized for specific functions such as signal acquisition, feature extraction, classification, or device control. This fragmented approach creates significant computational overhead, introduces latency issues, and complicates real-time performance requirements essential for practical BCI applications.
Modern BCI applications demand sub-millisecond response times for critical functions like motor control prosthetics, communication aids for paralyzed patients, and cognitive enhancement systems. However, existing library integration approaches frequently suffer from inefficient memory management, redundant computational processes, and suboptimal inter-library communication protocols. These limitations become particularly pronounced in resource-constrained environments such as embedded BCI devices, mobile platforms, and wearable neurotechnology systems.
The primary objective of optimizing BCI library integration centers on achieving seamless interoperability between diverse computational modules while minimizing execution latency and resource consumption. This involves developing unified frameworks that can efficiently coordinate signal processing pipelines, machine learning inference engines, and real-time control systems without compromising accuracy or reliability.
Key technical goals include establishing standardized interfaces for cross-library communication, implementing intelligent caching mechanisms for frequently accessed neural patterns, and developing adaptive resource allocation strategies that can dynamically optimize performance based on real-time system demands. Additionally, the integration framework must support scalable architectures capable of accommodating emerging BCI modalities and evolving algorithmic approaches.
The strategic importance of this optimization extends beyond immediate performance gains, positioning organizations to leverage next-generation BCI applications in healthcare, human augmentation, and brain-controlled computing interfaces. Success in this domain requires addressing fundamental challenges in parallel processing, memory optimization, and real-time system design while maintaining the flexibility necessary for rapid technological adaptation.
Market Demand for High-Performance BCI Systems
The global brain-computer interface market is experiencing unprecedented growth driven by increasing demand for high-performance systems across multiple sectors. Healthcare applications represent the largest market segment, with neurological rehabilitation centers and hospitals seeking advanced BCI solutions for treating stroke patients, spinal cord injuries, and neurodegenerative diseases. The demand for faster execution speeds in therapeutic BCIs has become critical as real-time neural signal processing directly impacts treatment efficacy and patient outcomes.
Gaming and entertainment industries are emerging as significant demand drivers for high-performance BCI systems. Major gaming companies are investing heavily in neural interface technologies to create immersive experiences that respond to users' mental states and intentions. These applications require ultra-low latency processing capabilities, making library integration optimization essential for commercial viability. The consumer market expects seamless, responsive interactions that can only be achieved through highly optimized software architectures.
Military and defense sectors represent a specialized but lucrative market segment demanding the highest performance standards. Defense contractors require BCI systems capable of processing complex neural patterns in real-time for applications ranging from pilot assistance to prosthetic control for wounded veterans. These applications cannot tolerate processing delays, creating substantial demand for optimized library integration solutions that maximize computational efficiency.
Research institutions and universities constitute a growing market segment requiring flexible, high-performance BCI platforms for advancing neuroscience research. Academic researchers need systems capable of handling large-scale neural data processing while maintaining the flexibility to integrate various analysis libraries and algorithms. The demand for standardized, optimized integration frameworks has intensified as research complexity increases.
Industrial automation and assistive technology markets are expanding rapidly, driven by aging populations and workforce automation trends. Manufacturing companies are exploring BCI applications for hands-free equipment control, while assistive technology providers seek high-performance systems for individuals with mobility impairments. These applications require robust, reliable performance that depends heavily on optimized software integration.
The convergence of artificial intelligence and neurotechnology is creating new market opportunities that demand exceptional processing speeds. Machine learning applications in BCI systems require seamless integration of multiple computational libraries, making optimization crucial for market competitiveness and user adoption across all sectors.
Gaming and entertainment industries are emerging as significant demand drivers for high-performance BCI systems. Major gaming companies are investing heavily in neural interface technologies to create immersive experiences that respond to users' mental states and intentions. These applications require ultra-low latency processing capabilities, making library integration optimization essential for commercial viability. The consumer market expects seamless, responsive interactions that can only be achieved through highly optimized software architectures.
Military and defense sectors represent a specialized but lucrative market segment demanding the highest performance standards. Defense contractors require BCI systems capable of processing complex neural patterns in real-time for applications ranging from pilot assistance to prosthetic control for wounded veterans. These applications cannot tolerate processing delays, creating substantial demand for optimized library integration solutions that maximize computational efficiency.
Research institutions and universities constitute a growing market segment requiring flexible, high-performance BCI platforms for advancing neuroscience research. Academic researchers need systems capable of handling large-scale neural data processing while maintaining the flexibility to integrate various analysis libraries and algorithms. The demand for standardized, optimized integration frameworks has intensified as research complexity increases.
Industrial automation and assistive technology markets are expanding rapidly, driven by aging populations and workforce automation trends. Manufacturing companies are exploring BCI applications for hands-free equipment control, while assistive technology providers seek high-performance systems for individuals with mobility impairments. These applications require robust, reliable performance that depends heavily on optimized software integration.
The convergence of artificial intelligence and neurotechnology is creating new market opportunities that demand exceptional processing speeds. Machine learning applications in BCI systems require seamless integration of multiple computational libraries, making optimization crucial for market competitiveness and user adoption across all sectors.
Current BCI Library Performance Bottlenecks and Challenges
Brain-Computer Interface library integration faces significant computational bottlenecks that severely impact real-time performance requirements. The primary challenge stems from the inherent complexity of neural signal processing, where raw EEG, fMRI, or invasive electrode data must undergo multiple transformation stages before meaningful control signals can be extracted. Current BCI libraries often struggle with the computational overhead of simultaneous signal acquisition, preprocessing, feature extraction, and classification tasks, creating latency issues that compromise user experience and system reliability.
Signal preprocessing represents one of the most computationally intensive bottlenecks in existing BCI frameworks. Digital filtering operations, artifact removal algorithms, and noise reduction techniques require substantial processing power, particularly when handling high-resolution neural data streams. Many current libraries implement these operations sequentially rather than leveraging parallel processing capabilities, resulting in unnecessary delays that accumulate throughout the signal processing pipeline.
Feature extraction algorithms pose another critical performance constraint, especially when implementing advanced machine learning techniques for pattern recognition. Traditional BCI libraries often rely on computationally expensive methods such as Common Spatial Pattern filtering, wavelet transforms, and spectral analysis, which can introduce significant latency when processing continuous data streams. The challenge is further compounded by the need to maintain classification accuracy while reducing computational complexity.
Memory management inefficiencies plague many existing BCI library implementations, particularly in handling large datasets and maintaining real-time data buffers. Poor memory allocation strategies, inadequate garbage collection mechanisms, and suboptimal data structure choices contribute to performance degradation and system instability during extended operation periods.
Inter-library communication overhead presents additional challenges when integrating multiple specialized BCI components. Data serialization and deserialization processes, network communication protocols, and API translation layers introduce latency that can be particularly problematic for time-sensitive applications requiring sub-millisecond response times.
Hardware abstraction layers in current BCI libraries often fail to fully exploit modern computing architectures, including GPU acceleration, multi-core processing, and specialized neural processing units. This limitation prevents optimal utilization of available computational resources and constrains overall system performance.
Scalability issues emerge when attempting to support multiple concurrent users or complex multi-modal BCI systems, as current library architectures were not designed to handle distributed processing requirements or dynamic resource allocation efficiently.
Signal preprocessing represents one of the most computationally intensive bottlenecks in existing BCI frameworks. Digital filtering operations, artifact removal algorithms, and noise reduction techniques require substantial processing power, particularly when handling high-resolution neural data streams. Many current libraries implement these operations sequentially rather than leveraging parallel processing capabilities, resulting in unnecessary delays that accumulate throughout the signal processing pipeline.
Feature extraction algorithms pose another critical performance constraint, especially when implementing advanced machine learning techniques for pattern recognition. Traditional BCI libraries often rely on computationally expensive methods such as Common Spatial Pattern filtering, wavelet transforms, and spectral analysis, which can introduce significant latency when processing continuous data streams. The challenge is further compounded by the need to maintain classification accuracy while reducing computational complexity.
Memory management inefficiencies plague many existing BCI library implementations, particularly in handling large datasets and maintaining real-time data buffers. Poor memory allocation strategies, inadequate garbage collection mechanisms, and suboptimal data structure choices contribute to performance degradation and system instability during extended operation periods.
Inter-library communication overhead presents additional challenges when integrating multiple specialized BCI components. Data serialization and deserialization processes, network communication protocols, and API translation layers introduce latency that can be particularly problematic for time-sensitive applications requiring sub-millisecond response times.
Hardware abstraction layers in current BCI libraries often fail to fully exploit modern computing architectures, including GPU acceleration, multi-core processing, and specialized neural processing units. This limitation prevents optimal utilization of available computational resources and constrains overall system performance.
Scalability issues emerge when attempting to support multiple concurrent users or complex multi-modal BCI systems, as current library architectures were not designed to handle distributed processing requirements or dynamic resource allocation efficiently.
Current BCI Library Integration and Optimization Methods
01 Hardware acceleration and parallel processing architectures
Brain-computer interface systems can achieve improved execution speed through specialized hardware architectures that enable parallel processing of neural signals. These implementations utilize dedicated processing units, multi-core processors, or field-programmable gate arrays (FPGAs) to handle multiple data streams simultaneously. Hardware acceleration techniques reduce computational latency and enable real-time processing of brain signals by distributing workloads across multiple processing elements.- Hardware acceleration and parallel processing architectures: Brain-computer interface systems can achieve improved execution speed through dedicated hardware acceleration units and parallel processing architectures. These implementations utilize specialized processors, GPU acceleration, and multi-core processing to handle the computationally intensive signal processing tasks required for real-time BCI operations. Hardware-level optimizations enable faster data throughput and reduced latency in neural signal interpretation.
- Optimized signal processing algorithms and machine learning models: Execution speed improvements can be achieved through algorithmic optimizations including streamlined feature extraction methods, efficient classification algorithms, and lightweight machine learning models. These approaches reduce computational complexity while maintaining accuracy, enabling faster processing of brain signals. Techniques include dimensionality reduction, optimized neural network architectures, and real-time adaptive algorithms that minimize processing overhead.
- Memory management and data buffering strategies: Enhanced library execution speed is achieved through intelligent memory allocation, efficient data buffering mechanisms, and optimized data structure implementations. These strategies minimize memory access latency and reduce data transfer bottlenecks between processing stages. Techniques include circular buffers, cache optimization, and pre-allocation of memory resources to ensure smooth real-time data flow in BCI systems.
- Software architecture and code optimization techniques: Library execution performance can be enhanced through modular software architectures, efficient code compilation, and runtime optimization techniques. These include the use of optimized programming languages, just-in-time compilation, code profiling and refactoring, and elimination of redundant operations. Software-level optimizations focus on reducing instruction cycles and improving overall computational efficiency of BCI processing pipelines.
- Real-time operating systems and task scheduling: Execution speed improvements are realized through implementation of real-time operating systems with deterministic task scheduling, priority-based processing, and interrupt handling mechanisms. These systems ensure timely execution of critical BCI processing tasks with minimal jitter and guaranteed response times. Scheduling optimizations include deadline-driven task management and resource allocation strategies specifically designed for time-critical neural signal processing applications.
02 Optimized signal processing algorithms
Execution speed can be enhanced through the implementation of optimized algorithms specifically designed for brain signal processing. These algorithms employ efficient mathematical operations, reduced computational complexity, and streamlined data processing pipelines. Techniques include fast Fourier transforms, adaptive filtering methods, and compressed sensing approaches that minimize processing time while maintaining signal quality and accuracy.Expand Specific Solutions03 Real-time data transmission and communication protocols
High-speed execution in brain-computer interface libraries relies on efficient data transmission mechanisms and optimized communication protocols. These systems implement low-latency data transfer methods, wireless communication standards, and buffering strategies that minimize delays between signal acquisition and processing. The protocols ensure rapid data flow between sensors, processing units, and output devices.Expand Specific Solutions04 Machine learning model optimization
Brain-computer interface execution speed benefits from optimized machine learning models that perform rapid classification and prediction of neural patterns. These approaches include model compression techniques, pruning strategies, quantization methods, and the use of lightweight neural networks. The optimization reduces inference time while maintaining classification accuracy for brain signal interpretation.Expand Specific Solutions05 Memory management and caching strategies
Efficient memory management techniques significantly impact the execution speed of brain-computer interface libraries. These strategies involve intelligent caching mechanisms, optimized memory allocation, and data structure designs that minimize access latency. Implementation of circular buffers, pre-fetching algorithms, and hierarchical memory systems ensures rapid data retrieval and processing during real-time operations.Expand Specific Solutions
Major BCI Platform and Library Providers Analysis
The brain-computer interface (BCI) library integration optimization field represents an emerging technology sector in its early growth phase, characterized by significant market potential but fragmented development across diverse applications. The market remains relatively nascent with substantial room for expansion, driven by increasing demand for neural interface solutions in healthcare, gaming, and assistive technologies. Technology maturity varies considerably among key players, with established semiconductor giants like Intel Corp., NVIDIA Corp., and Advanced Micro Devices leading in computational infrastructure and AI acceleration capabilities essential for BCI processing. Academic institutions including Columbia University, Tsinghua University, and Beihang University contribute foundational research, while specialized companies like Neurable focus specifically on BCI software development. The competitive landscape shows a convergence of hardware manufacturers, research institutions, and emerging BCI specialists working to address execution speed challenges through optimized library integration approaches.
Intel Corp.
Technical Solution: Intel's BCI optimization strategy centers on their neuromorphic computing architecture through the Loihi chip and Intel Neural Compute Stick. Their approach emphasizes low-power, event-driven processing that mimics biological neural networks for efficient BCI signal interpretation. The company has developed specialized instruction sets and compiler optimizations for neural signal processing workloads. Intel's OpenVINO toolkit provides optimized inference engines for BCI applications, enabling faster execution through model quantization and hardware-specific optimizations across their processor lineup.
Strengths: Comprehensive software stack and broad hardware compatibility across different computing platforms. Weaknesses: Limited specialized BCI hardware compared to dedicated neural processing solutions.
International Business Machines Corp.
Technical Solution: IBM's BCI integration approach leverages their Watson AI platform and neuromorphic computing research through TrueNorth chips. Their solution focuses on cloud-based neural signal analysis with optimized data pipelines that can process multiple BCI data streams simultaneously. The company has developed specialized algorithms for pattern recognition in neural signals using their quantum computing research insights. IBM's approach includes federated learning frameworks that enable collaborative BCI model training while maintaining data privacy and reducing individual computational requirements.
Strengths: Advanced AI capabilities and enterprise-scale infrastructure for complex BCI applications. Weaknesses: Primarily cloud-based solutions may introduce latency issues for real-time BCI applications.
Core Patents in BCI Performance Enhancement Technologies
Optimized learning model for brain computer interface
PatentPendingIN202441009019A
Innovation
- The Optimized Learning Model leverages deep learning algorithms, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs), combined with optimization techniques like stochastic gradient descent and adaptive learning rate methods, to automatically extract features from EEG data, enhance signal processing, and incorporate user feedback for personalized adaptation, improving accuracy and adaptability in BCI classification.
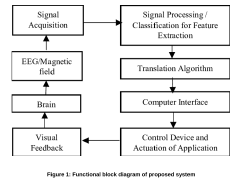
A method of processing brain signals in a brain-computer interface system
PatentWO2024167397A1
Innovation
- A method involving obtaining brain signals, analyzing them through clustering and matrix transposing, extracting features, dividing into slices, transforming into grayscale images, and classifying using a deep learning classifier to translate signals into commands, specifically employing gamma frequency signals and unsupervised learning to reduce artifacts and enhance information transfer.




Real-time Processing Requirements for BCI Applications
Real-time processing represents the cornerstone of effective brain-computer interface applications, where computational latency directly impacts system usability and user experience. Modern BCI systems must achieve processing delays of less than 100 milliseconds to maintain natural interaction patterns, with many applications requiring even tighter constraints below 50 milliseconds for optimal performance.
The temporal requirements vary significantly across different BCI application domains. Motor imagery-based control systems typically demand processing windows between 200-500 milliseconds to capture relevant neural patterns, while steady-state visual evoked potential applications require sub-100 millisecond response times to maintain synchronization with visual stimuli. Event-related potential detection systems present the most stringent requirements, often necessitating processing capabilities within 20-50 milliseconds to preserve signal integrity.
Signal acquisition rates fundamentally determine processing bandwidth requirements. Contemporary BCI systems operate with sampling frequencies ranging from 250 Hz to 2048 Hz, generating continuous data streams that must be processed without buffer overflow or sample loss. Higher sampling rates, while providing superior signal fidelity, exponentially increase computational demands and memory bandwidth requirements.
Computational complexity scales with the sophistication of signal processing algorithms employed. Basic filtering operations consume minimal processing resources, while advanced machine learning classification algorithms, particularly deep neural networks, can require substantial computational overhead. Feature extraction processes, including common spatial pattern analysis and spectral decomposition, introduce additional latency that must be carefully managed within real-time constraints.
Memory management becomes critical when handling continuous neural data streams. Circular buffer implementations and efficient memory allocation strategies are essential to prevent system bottlenecks. Cache optimization and data locality considerations significantly impact processing throughput, particularly when implementing complex signal processing pipelines.
Hardware acceleration through GPU computing and specialized digital signal processors offers pathways to meet stringent real-time requirements. Parallel processing architectures can distribute computational loads across multiple cores, enabling simultaneous execution of filtering, feature extraction, and classification operations while maintaining temporal constraints essential for responsive BCI applications.
The temporal requirements vary significantly across different BCI application domains. Motor imagery-based control systems typically demand processing windows between 200-500 milliseconds to capture relevant neural patterns, while steady-state visual evoked potential applications require sub-100 millisecond response times to maintain synchronization with visual stimuli. Event-related potential detection systems present the most stringent requirements, often necessitating processing capabilities within 20-50 milliseconds to preserve signal integrity.
Signal acquisition rates fundamentally determine processing bandwidth requirements. Contemporary BCI systems operate with sampling frequencies ranging from 250 Hz to 2048 Hz, generating continuous data streams that must be processed without buffer overflow or sample loss. Higher sampling rates, while providing superior signal fidelity, exponentially increase computational demands and memory bandwidth requirements.
Computational complexity scales with the sophistication of signal processing algorithms employed. Basic filtering operations consume minimal processing resources, while advanced machine learning classification algorithms, particularly deep neural networks, can require substantial computational overhead. Feature extraction processes, including common spatial pattern analysis and spectral decomposition, introduce additional latency that must be carefully managed within real-time constraints.
Memory management becomes critical when handling continuous neural data streams. Circular buffer implementations and efficient memory allocation strategies are essential to prevent system bottlenecks. Cache optimization and data locality considerations significantly impact processing throughput, particularly when implementing complex signal processing pipelines.
Hardware acceleration through GPU computing and specialized digital signal processors offers pathways to meet stringent real-time requirements. Parallel processing architectures can distribute computational loads across multiple cores, enabling simultaneous execution of filtering, feature extraction, and classification operations while maintaining temporal constraints essential for responsive BCI applications.
Cross-Platform Compatibility in BCI Library Design
Cross-platform compatibility represents a fundamental architectural consideration in modern BCI library design, addressing the critical need for seamless operation across diverse computing environments. The heterogeneous nature of BCI deployment scenarios, spanning from Windows-based clinical workstations to Linux-embedded real-time systems and mobile platforms, necessitates sophisticated abstraction layers that can accommodate varying hardware architectures, operating system APIs, and runtime environments without compromising performance or functionality.
The primary challenge lies in reconciling the conflicting requirements of platform-specific optimizations with universal code maintainability. Different operating systems exhibit distinct memory management paradigms, threading models, and hardware access protocols, particularly relevant for BCI applications that demand low-latency neural signal processing and real-time feedback mechanisms. Windows systems typically rely on DirectX or proprietary driver frameworks, while Linux environments favor open-source alternatives like V4L2 for device interfacing, creating substantial integration complexity.
Contemporary BCI libraries employ several architectural strategies to achieve cross-platform compatibility. Abstract factory patterns enable runtime selection of platform-specific implementations, while standardized APIs like OpenCL and CUDA provide hardware-agnostic parallel processing capabilities essential for signal analysis algorithms. Container-based deployment strategies using Docker or similar technologies offer additional abstraction layers, though potentially introducing latency overhead that conflicts with real-time processing requirements.
Hardware abstraction layers constitute another critical component, particularly for interfacing with diverse neural acquisition devices. Modern BCI systems must accommodate various amplifier manufacturers, each with proprietary communication protocols and data formats. Successful cross-platform libraries implement plugin architectures that dynamically load device-specific drivers while maintaining consistent data pipeline interfaces, enabling seamless integration regardless of underlying hardware configurations.
The emergence of web-based BCI applications introduces additional complexity through browser compatibility requirements and JavaScript runtime limitations. WebAssembly technologies show promise for deploying computationally intensive signal processing algorithms across web platforms, though current implementations still face performance constraints compared to native code execution, particularly for real-time applications requiring sub-millisecond response times.
Future cross-platform compatibility strategies increasingly focus on cloud-native architectures and microservices patterns, enabling distributed BCI processing across heterogeneous infrastructure while maintaining consistent user experiences and API interfaces across all supported platforms.
The primary challenge lies in reconciling the conflicting requirements of platform-specific optimizations with universal code maintainability. Different operating systems exhibit distinct memory management paradigms, threading models, and hardware access protocols, particularly relevant for BCI applications that demand low-latency neural signal processing and real-time feedback mechanisms. Windows systems typically rely on DirectX or proprietary driver frameworks, while Linux environments favor open-source alternatives like V4L2 for device interfacing, creating substantial integration complexity.
Contemporary BCI libraries employ several architectural strategies to achieve cross-platform compatibility. Abstract factory patterns enable runtime selection of platform-specific implementations, while standardized APIs like OpenCL and CUDA provide hardware-agnostic parallel processing capabilities essential for signal analysis algorithms. Container-based deployment strategies using Docker or similar technologies offer additional abstraction layers, though potentially introducing latency overhead that conflicts with real-time processing requirements.
Hardware abstraction layers constitute another critical component, particularly for interfacing with diverse neural acquisition devices. Modern BCI systems must accommodate various amplifier manufacturers, each with proprietary communication protocols and data formats. Successful cross-platform libraries implement plugin architectures that dynamically load device-specific drivers while maintaining consistent data pipeline interfaces, enabling seamless integration regardless of underlying hardware configurations.
The emergence of web-based BCI applications introduces additional complexity through browser compatibility requirements and JavaScript runtime limitations. WebAssembly technologies show promise for deploying computationally intensive signal processing algorithms across web platforms, though current implementations still face performance constraints compared to native code execution, particularly for real-time applications requiring sub-millisecond response times.
Future cross-platform compatibility strategies increasingly focus on cloud-native architectures and microservices patterns, enabling distributed BCI processing across heterogeneous infrastructure while maintaining consistent user experiences and API interfaces across all supported platforms.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!