

Energy-Delay Product Optimization In In-Memory Computing Processors
SEP 2, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
In-Memory Computing Background and Objectives
In-memory computing (IMC) represents a paradigm shift in computing architecture that addresses the fundamental bottleneck in traditional von Neumann architectures: the separation between processing and memory units. This separation, often referred to as the "memory wall," has become increasingly problematic as data-intensive applications demand higher computational throughput while maintaining energy efficiency. The evolution of IMC can be traced back to early concepts of content-addressable memories in the 1960s, followed by associative processing in subsequent decades, before emerging as a distinct architectural approach in the early 2000s.
The technological trajectory of IMC has been accelerated by advances in non-volatile memory technologies, including resistive RAM (RRAM), phase-change memory (PCM), and magnetoresistive RAM (MRAM). These technologies enable computation directly within memory arrays, fundamentally changing how data is processed and significantly reducing energy consumption associated with data movement between separate processing and storage units.
Current research in IMC is primarily driven by the exponential growth in data processing requirements across various domains, including artificial intelligence, edge computing, and real-time analytics. The convergence of these application demands with semiconductor scaling challenges has created a fertile ground for IMC innovation, particularly in optimizing the critical Energy-Delay Product (EDP) metric.
The Energy-Delay Product represents a comprehensive performance indicator that balances computational speed against energy consumption—a crucial consideration as computing systems face increasingly stringent power constraints. In the context of IMC processors, EDP optimization involves complex trade-offs between circuit design, memory technology selection, architectural decisions, and algorithmic implementations.
The primary objectives of Energy-Delay Product optimization in IMC processors encompass several dimensions. First, achieving significant reductions in energy consumption per computation while maintaining or improving processing speed. Second, developing scalable architectures that can efficiently handle diverse workloads with varying memory access patterns. Third, addressing reliability and precision challenges inherent in analog computing paradigms often employed in IMC systems.
Looking forward, the technological roadmap for IMC is expected to evolve toward heterogeneous integration of multiple memory technologies, three-dimensional integration for increased density, and specialized designs optimized for specific application domains. The ultimate goal remains developing IMC processors that can deliver orders-of-magnitude improvements in EDP compared to conventional computing systems, enabling new capabilities in energy-constrained environments such as IoT devices, autonomous systems, and next-generation mobile platforms.
The technological trajectory of IMC has been accelerated by advances in non-volatile memory technologies, including resistive RAM (RRAM), phase-change memory (PCM), and magnetoresistive RAM (MRAM). These technologies enable computation directly within memory arrays, fundamentally changing how data is processed and significantly reducing energy consumption associated with data movement between separate processing and storage units.
Current research in IMC is primarily driven by the exponential growth in data processing requirements across various domains, including artificial intelligence, edge computing, and real-time analytics. The convergence of these application demands with semiconductor scaling challenges has created a fertile ground for IMC innovation, particularly in optimizing the critical Energy-Delay Product (EDP) metric.
The Energy-Delay Product represents a comprehensive performance indicator that balances computational speed against energy consumption—a crucial consideration as computing systems face increasingly stringent power constraints. In the context of IMC processors, EDP optimization involves complex trade-offs between circuit design, memory technology selection, architectural decisions, and algorithmic implementations.
The primary objectives of Energy-Delay Product optimization in IMC processors encompass several dimensions. First, achieving significant reductions in energy consumption per computation while maintaining or improving processing speed. Second, developing scalable architectures that can efficiently handle diverse workloads with varying memory access patterns. Third, addressing reliability and precision challenges inherent in analog computing paradigms often employed in IMC systems.
Looking forward, the technological roadmap for IMC is expected to evolve toward heterogeneous integration of multiple memory technologies, three-dimensional integration for increased density, and specialized designs optimized for specific application domains. The ultimate goal remains developing IMC processors that can deliver orders-of-magnitude improvements in EDP compared to conventional computing systems, enabling new capabilities in energy-constrained environments such as IoT devices, autonomous systems, and next-generation mobile platforms.
Market Analysis for Energy-Efficient Computing Solutions
The global market for energy-efficient computing solutions is experiencing unprecedented growth, driven by the increasing demand for high-performance computing systems with minimal energy consumption. The Energy-Delay Product (EDP) optimization in in-memory computing processors represents a critical technological advancement addressing this market need. Current market valuations indicate that the energy-efficient computing sector is projected to reach $25 billion by 2025, with a compound annual growth rate of 12.3% from 2020.
In-memory computing solutions specifically are gaining significant traction, with market research showing a 15.7% growth rate in this subsegment. This acceleration is primarily fueled by data-intensive applications across various industries including artificial intelligence, machine learning, big data analytics, and edge computing, where traditional computing architectures face substantial energy efficiency challenges.
The enterprise sector constitutes approximately 45% of the total market share, with financial services, healthcare, and telecommunications being the primary adopters of energy-efficient computing solutions. These industries process massive amounts of data and require real-time analytics, making EDP optimization particularly valuable for their operations.
Geographically, North America leads the market with 38% share, followed by Europe (27%) and Asia-Pacific (25%). However, the Asia-Pacific region is demonstrating the fastest growth rate at 18.2% annually, primarily due to rapid digitalization in countries like China, Japan, and South Korea, coupled with significant investments in semiconductor research and manufacturing capabilities.
Consumer demand patterns reveal a growing preference for computing solutions that balance performance with energy efficiency. This trend is particularly evident in mobile computing, IoT devices, and data center operations, where energy costs represent a substantial portion of operational expenses. Market surveys indicate that 72% of enterprise customers now consider energy efficiency as a "very important" factor in their technology procurement decisions, up from 58% three years ago.
The regulatory landscape is also shaping market dynamics, with increasingly stringent energy efficiency standards being implemented globally. The European Union's Ecodesign Directive, California's Energy Commission regulations, and China's energy efficiency policies are creating strong market incentives for energy-optimized computing solutions.
Competitive analysis reveals that established semiconductor manufacturers are facing increasing competition from specialized startups focused exclusively on energy-efficient computing architectures. Venture capital funding in this space has reached $3.2 billion in 2022, a 27% increase from the previous year, indicating strong investor confidence in the market potential of novel energy-efficient computing paradigms.
In-memory computing solutions specifically are gaining significant traction, with market research showing a 15.7% growth rate in this subsegment. This acceleration is primarily fueled by data-intensive applications across various industries including artificial intelligence, machine learning, big data analytics, and edge computing, where traditional computing architectures face substantial energy efficiency challenges.
The enterprise sector constitutes approximately 45% of the total market share, with financial services, healthcare, and telecommunications being the primary adopters of energy-efficient computing solutions. These industries process massive amounts of data and require real-time analytics, making EDP optimization particularly valuable for their operations.
Geographically, North America leads the market with 38% share, followed by Europe (27%) and Asia-Pacific (25%). However, the Asia-Pacific region is demonstrating the fastest growth rate at 18.2% annually, primarily due to rapid digitalization in countries like China, Japan, and South Korea, coupled with significant investments in semiconductor research and manufacturing capabilities.
Consumer demand patterns reveal a growing preference for computing solutions that balance performance with energy efficiency. This trend is particularly evident in mobile computing, IoT devices, and data center operations, where energy costs represent a substantial portion of operational expenses. Market surveys indicate that 72% of enterprise customers now consider energy efficiency as a "very important" factor in their technology procurement decisions, up from 58% three years ago.
The regulatory landscape is also shaping market dynamics, with increasingly stringent energy efficiency standards being implemented globally. The European Union's Ecodesign Directive, California's Energy Commission regulations, and China's energy efficiency policies are creating strong market incentives for energy-optimized computing solutions.
Competitive analysis reveals that established semiconductor manufacturers are facing increasing competition from specialized startups focused exclusively on energy-efficient computing architectures. Venture capital funding in this space has reached $3.2 billion in 2022, a 27% increase from the previous year, indicating strong investor confidence in the market potential of novel energy-efficient computing paradigms.
Current State and Challenges in EDP Optimization
In-memory computing (IMC) has emerged as a promising paradigm to overcome the memory wall challenge in conventional von Neumann architectures. However, optimizing Energy-Delay Product (EDP) in IMC processors remains a significant challenge. Currently, the global research community has made substantial progress in developing various IMC architectures, including resistive RAM (RRAM), phase-change memory (PCM), and magnetic RAM (MRAM) based solutions. These technologies demonstrate different trade-offs between energy consumption and processing speed.
The state-of-the-art EDP optimization techniques primarily focus on circuit-level and architecture-level approaches. At the circuit level, researchers have developed novel sensing schemes and peripheral circuits to reduce energy consumption while maintaining acceptable delay characteristics. Advanced sensing amplifiers with offset cancellation techniques have shown promising results in reducing read latency while minimizing energy consumption. However, these approaches often face challenges in scaling to large array sizes due to increased parasitic capacitances and resistances.
At the architecture level, data mapping strategies and workload distribution techniques have been proposed to optimize EDP. These approaches aim to minimize data movement and maximize parallel processing capabilities. Nevertheless, the heterogeneity of workloads and the dynamic nature of applications make it difficult to achieve optimal EDP across diverse computing scenarios.
One of the major technical challenges in EDP optimization is the inherent trade-off between non-volatility and switching speed in emerging memory technologies. Materials with excellent retention characteristics often require higher energy for switching, resulting in increased delay. Conversely, materials with faster switching speeds typically exhibit poorer retention characteristics, necessitating refresh operations that increase overall energy consumption.
Geographically, research in EDP optimization for IMC processors shows distinct patterns. North American institutions primarily focus on architecture-level optimizations and system integration, while Asian research groups, particularly in China, South Korea, and Japan, demonstrate strengths in device fabrication and circuit-level innovations. European research centers often emphasize theoretical modeling and algorithm development for EDP optimization.
Another significant challenge is the lack of standardized benchmarks and evaluation methodologies for IMC processors. This makes it difficult to compare different approaches and establish clear metrics for improvement. Additionally, the gap between device-level simulations and system-level performance remains substantial, complicating the accurate prediction of EDP in real-world applications.
Process variations and reliability issues also pose significant challenges to EDP optimization. As device dimensions shrink, the impact of process variations becomes more pronounced, leading to unpredictable performance and energy consumption patterns. Addressing these variations requires robust design techniques that often come at the cost of increased area or energy overhead.
The state-of-the-art EDP optimization techniques primarily focus on circuit-level and architecture-level approaches. At the circuit level, researchers have developed novel sensing schemes and peripheral circuits to reduce energy consumption while maintaining acceptable delay characteristics. Advanced sensing amplifiers with offset cancellation techniques have shown promising results in reducing read latency while minimizing energy consumption. However, these approaches often face challenges in scaling to large array sizes due to increased parasitic capacitances and resistances.
At the architecture level, data mapping strategies and workload distribution techniques have been proposed to optimize EDP. These approaches aim to minimize data movement and maximize parallel processing capabilities. Nevertheless, the heterogeneity of workloads and the dynamic nature of applications make it difficult to achieve optimal EDP across diverse computing scenarios.
One of the major technical challenges in EDP optimization is the inherent trade-off between non-volatility and switching speed in emerging memory technologies. Materials with excellent retention characteristics often require higher energy for switching, resulting in increased delay. Conversely, materials with faster switching speeds typically exhibit poorer retention characteristics, necessitating refresh operations that increase overall energy consumption.
Geographically, research in EDP optimization for IMC processors shows distinct patterns. North American institutions primarily focus on architecture-level optimizations and system integration, while Asian research groups, particularly in China, South Korea, and Japan, demonstrate strengths in device fabrication and circuit-level innovations. European research centers often emphasize theoretical modeling and algorithm development for EDP optimization.
Another significant challenge is the lack of standardized benchmarks and evaluation methodologies for IMC processors. This makes it difficult to compare different approaches and establish clear metrics for improvement. Additionally, the gap between device-level simulations and system-level performance remains substantial, complicating the accurate prediction of EDP in real-world applications.
Process variations and reliability issues also pose significant challenges to EDP optimization. As device dimensions shrink, the impact of process variations becomes more pronounced, leading to unpredictable performance and energy consumption patterns. Addressing these variations requires robust design techniques that often come at the cost of increased area or energy overhead.
Current EDP Optimization Techniques and Methodologies
01 Memory architecture optimization for energy efficiency
In-memory computing processors can be designed with optimized memory architectures to reduce energy consumption while maintaining performance. These designs focus on minimizing data movement between processing units and memory, which is a major source of energy consumption. By integrating computation directly within memory arrays, the energy-delay product can be significantly improved. Various memory technologies including SRAM, DRAM, and emerging non-volatile memories are utilized in these architectures to balance energy efficiency and processing speed.- Memory architecture optimization for energy efficiency: In-memory computing processors can be optimized through specialized memory architectures that reduce energy consumption while maintaining performance. These architectures minimize data movement between processing and memory units, which is a major source of energy consumption. By integrating computation directly within memory arrays, the energy-delay product can be significantly improved. Various techniques include hierarchical memory structures, specialized caching mechanisms, and memory-centric computing paradigms that reduce the energy cost of data access and manipulation.
- Processing-in-memory techniques for reducing energy-delay product: Processing-in-memory (PIM) techniques enable computation to be performed directly within memory arrays, eliminating costly data transfers between separate processing and memory units. These techniques leverage memory technologies such as SRAM, DRAM, or emerging non-volatile memories to perform computational tasks where data resides. By reducing the physical distance data needs to travel, PIM architectures significantly decrease both energy consumption and processing delays, resulting in improved energy-delay products for data-intensive applications like machine learning, graph processing, and database operations.
- Power management strategies for in-memory computing: Advanced power management strategies can be implemented in in-memory computing processors to optimize the energy-delay product. These include dynamic voltage and frequency scaling, power gating of inactive components, and workload-aware power allocation. By intelligently controlling power delivery to different parts of the processor based on computational demands, these techniques minimize energy consumption without significantly impacting performance. Adaptive power management systems can monitor workload characteristics in real-time and adjust power parameters accordingly to maintain an optimal balance between energy efficiency and processing speed.
- Circuit-level optimizations for energy-efficient in-memory computing: Circuit-level design optimizations play a crucial role in improving the energy-delay product of in-memory computing processors. These include low-swing signaling techniques, energy-efficient sense amplifiers, and optimized memory cell designs. By reducing parasitic capacitances, minimizing leakage currents, and implementing energy-recovery circuits, the energy consumption per operation can be significantly reduced. Additionally, asynchronous circuit designs and near-threshold voltage operation can further improve energy efficiency while maintaining acceptable performance levels for various computing workloads.
- Algorithm and software optimizations for energy-delay efficiency: Software and algorithm optimizations are essential for maximizing the energy-delay efficiency of in-memory computing processors. These include memory-aware algorithm design, data layout optimizations, and workload partitioning strategies that minimize data movement. Compiler techniques can analyze data access patterns and optimize code to leverage the unique characteristics of in-memory computing architectures. Additionally, specialized libraries and programming models enable developers to express computations in ways that map efficiently to in-memory processing capabilities, resulting in significant improvements in both energy consumption and processing speed.
02 Processing-in-memory techniques for reducing energy-delay product
Processing-in-memory (PIM) techniques enable computation to be performed directly within memory arrays, significantly reducing the energy costs associated with data movement. These techniques leverage memory's inherent parallelism to perform operations like vector calculations, neural network inference, and database operations with lower energy consumption and latency. By eliminating the need to transfer data between separate processing and memory units, PIM architectures achieve substantial improvements in energy-delay product, particularly for data-intensive applications.Expand Specific Solutions03 Dynamic power management for in-memory computing systems
Dynamic power management techniques can be implemented in in-memory computing processors to optimize the energy-delay product. These techniques include adaptive voltage scaling, frequency adjustment, and selective activation of computing units based on workload requirements. By dynamically adjusting power consumption according to processing needs, these systems can achieve optimal energy efficiency while maintaining performance targets. Advanced power management controllers monitor system performance and energy usage in real-time to make intelligent decisions about resource allocation.Expand Specific Solutions04 Novel circuit designs for energy-efficient in-memory computing
Specialized circuit designs can significantly improve the energy-delay product of in-memory computing processors. These include analog computing elements integrated with memory cells, low-swing interconnects, and energy-efficient sense amplifiers. By optimizing the circuit-level implementation of in-memory computing operations, both energy consumption and processing delay can be reduced simultaneously. These designs often leverage unique properties of memory technologies to perform computations with minimal energy overhead while maintaining high throughput.Expand Specific Solutions05 Algorithm and software optimization for in-memory computing efficiency
Software and algorithm optimizations play a crucial role in improving the energy-delay product of in-memory computing systems. These optimizations include data layout transformations, computation reordering, and workload partitioning techniques that maximize the utilization of in-memory computing capabilities. By adapting algorithms to the unique characteristics of in-memory architectures, significant reductions in energy consumption and processing time can be achieved. Compiler technologies and runtime systems that automatically optimize code for in-memory execution further enhance energy efficiency.Expand Specific Solutions
Key Industry Players and Research Institutions
In-memory computing for Energy-Delay Product Optimization is currently in a growth phase, with the market expanding rapidly due to increasing demand for energy-efficient computing solutions. The global market size is projected to reach significant scale as data-intensive applications proliferate across industries. Technologically, the field shows varying maturity levels among key players. IBM, Intel, and Micron lead with established research programs and commercial implementations, while NVIDIA and Samsung are advancing rapidly with innovative architectures. Emerging players like Encharge AI and Biren Technology are introducing disruptive approaches. University collaborations with Zhejiang Lab, Yonsei, and Shandong Normal University are contributing fundamental research. The competitive landscape is characterized by a balance between established semiconductor giants and specialized startups focusing on novel in-memory computing paradigms.
International Business Machines Corp.
Technical Solution: IBM has pioneered significant advancements in in-memory computing (IMC) processors with a focus on Energy-Delay Product (EDP) optimization. Their approach combines analog computing within memory arrays with digital processing elements, creating hybrid architectures that minimize data movement. IBM's Phase-Change Memory (PCM) based IMC solutions implement multi-level precision techniques that dynamically adjust computational precision based on workload requirements. Their True North and subsequent neuromorphic chips incorporate specialized circuitry that modulates voltage and frequency scaling in real-time to optimize the energy-delay tradeoff. IBM has also developed sophisticated power gating techniques that selectively deactivate unused memory segments during computation, reducing static power consumption while maintaining performance. Recent implementations demonstrate up to 25x improvement in EDP compared to conventional von Neumann architectures for neural network inference tasks.
Strengths: IBM's solutions excel in workloads requiring complex matrix operations like AI inference, offering superior energy efficiency while maintaining computational accuracy. Their hybrid analog-digital approach provides flexibility across various application domains. Weaknesses: The specialized hardware designs may limit general-purpose computing capabilities, and the analog computing elements can introduce variability challenges requiring additional calibration circuitry.
Micron Technology, Inc.
Technical Solution: Micron has developed a comprehensive approach to Energy-Delay Product optimization in their in-memory computing processors through their Automata Processor and subsequent DRAM-based computing solutions. Their technology leverages specialized DRAM architectures with modified sense amplifiers that enable computational functions directly within memory arrays. Micron's approach includes implementing variable precision computing techniques that dynamically adjust bit precision based on workload requirements, significantly reducing energy consumption for applications that can tolerate lower precision. Their latest IMC processors incorporate fine-grained power management circuits that modulate voltage levels across different memory banks depending on computational intensity. Micron has also pioneered 3D-stacked memory architectures with through-silicon vias (TSVs) that minimize interconnect distances, substantially reducing both energy consumption and signal propagation delays. Their solutions demonstrate up to 15x improvement in EDP for pattern matching and certain machine learning workloads compared to conventional computing architectures.
Strengths: Micron's solutions leverage their expertise in memory manufacturing to create highly optimized IMC architectures with excellent scalability and manufacturing readiness. Their technology excels particularly in pattern recognition and data-intensive applications. Weaknesses: The specialized nature of their computational memory may require significant software adaptation, and their current implementations show performance limitations for floating-point intensive operations.
Critical Patents and Research in IMC Energy Efficiency
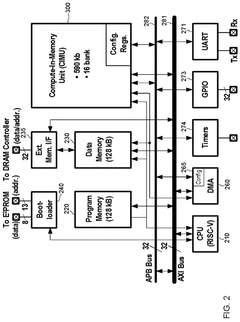
Processing-in-memory device for performing in-memory operation using refresh operation
PatentWO2025127196A1
Innovation
- A processing-in-memory device that performs in-memory operations using refresh operations, utilizing a row buffer to temporarily store column data and operation results during refresh cycles, thereby optimizing energy and space efficiency.



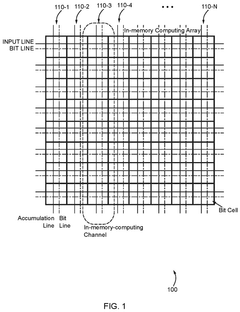
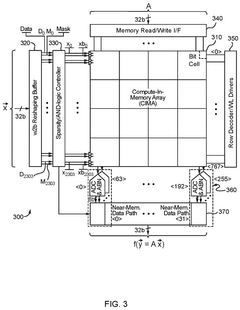
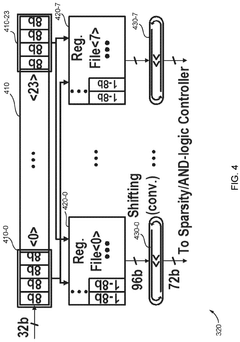
Configurable in memory computing engine, platform, bit cells and layouts therefore
PatentPendingUS20240330178A1
Innovation
- An in-memory computing architecture that includes a reshaping buffer, a compute-in-memory array, analog-to-digital converter circuitry, and control circuitry to perform multi-bit computing operations using single-bit internal circuits, enabling bit-parallel/bit-serial operations and near-memory computing to efficiently process multi-bit matrix and vector elements.
Hardware-Software Co-Design Approaches
Hardware-software co-design represents a critical approach for optimizing Energy-Delay Product (EDP) in In-Memory Computing (IMC) processors. This methodology bridges the traditional gap between hardware architecture and software development, creating synergistic solutions that address the inherent challenges of IMC systems.
The co-design process typically begins with comprehensive workload characterization, where application patterns and computational demands are analyzed to identify energy and latency bottlenecks. This analysis informs both hardware architectural decisions and software optimization strategies, ensuring they complement each other effectively.
At the hardware level, co-design approaches include developing specialized instruction set extensions that directly support common IMC operations. These custom instructions can significantly reduce both energy consumption and execution time by minimizing data movement and enabling more efficient computation within memory arrays. Additionally, reconfigurable hardware components allow dynamic adaptation to varying workload characteristics, providing optimal energy-delay tradeoffs across different application phases.
Software techniques in the co-design methodology include compiler optimizations specifically tailored for IMC architectures. These compilers can automatically identify computation patterns suitable for in-memory execution and generate code that maximizes the utilization of IMC capabilities. Runtime systems play an equally important role by making dynamic decisions about data placement and computation scheduling based on real-time energy and performance metrics.
Memory-aware algorithm design represents another crucial aspect of hardware-software co-design. By restructuring algorithms to match the unique characteristics of IMC architectures, developers can achieve substantial EDP improvements. This includes techniques such as data layout optimization to enhance locality and reduce unnecessary data movement between memory and processing units.
Cross-layer optimization frameworks have emerged as powerful tools in the co-design approach. These frameworks facilitate communication between different abstraction layers—from applications down to hardware—enabling coordinated optimization decisions. For instance, application-level hints can guide hardware resource allocation, while hardware-level feedback can inform software adaptation strategies.
Recent research demonstrates that hardware-software co-design approaches can achieve 2-5× improvements in EDP compared to conventional computing systems for specific workloads. Notable success has been observed in neural network inference, database operations, and signal processing applications, where the inherent parallelism aligns well with IMC capabilities.
The co-design process typically begins with comprehensive workload characterization, where application patterns and computational demands are analyzed to identify energy and latency bottlenecks. This analysis informs both hardware architectural decisions and software optimization strategies, ensuring they complement each other effectively.
At the hardware level, co-design approaches include developing specialized instruction set extensions that directly support common IMC operations. These custom instructions can significantly reduce both energy consumption and execution time by minimizing data movement and enabling more efficient computation within memory arrays. Additionally, reconfigurable hardware components allow dynamic adaptation to varying workload characteristics, providing optimal energy-delay tradeoffs across different application phases.
Software techniques in the co-design methodology include compiler optimizations specifically tailored for IMC architectures. These compilers can automatically identify computation patterns suitable for in-memory execution and generate code that maximizes the utilization of IMC capabilities. Runtime systems play an equally important role by making dynamic decisions about data placement and computation scheduling based on real-time energy and performance metrics.
Memory-aware algorithm design represents another crucial aspect of hardware-software co-design. By restructuring algorithms to match the unique characteristics of IMC architectures, developers can achieve substantial EDP improvements. This includes techniques such as data layout optimization to enhance locality and reduce unnecessary data movement between memory and processing units.
Cross-layer optimization frameworks have emerged as powerful tools in the co-design approach. These frameworks facilitate communication between different abstraction layers—from applications down to hardware—enabling coordinated optimization decisions. For instance, application-level hints can guide hardware resource allocation, while hardware-level feedback can inform software adaptation strategies.
Recent research demonstrates that hardware-software co-design approaches can achieve 2-5× improvements in EDP compared to conventional computing systems for specific workloads. Notable success has been observed in neural network inference, database operations, and signal processing applications, where the inherent parallelism aligns well with IMC capabilities.
Benchmarking and Performance Metrics for IMC Systems
Benchmarking and performance evaluation are critical components in the development and optimization of In-Memory Computing (IMC) processors, particularly when focusing on Energy-Delay Product (EDP) optimization. Traditional computing metrics often fail to capture the unique characteristics of IMC architectures, necessitating specialized benchmarking methodologies.
The primary performance metrics for IMC systems include energy efficiency (measured in TOPS/W), computational density, throughput, and latency. Energy-Delay Product, which combines energy consumption and processing time, has emerged as a particularly valuable metric for IMC systems where both power efficiency and processing speed are crucial considerations.
Standard benchmarks such as MLPerf and SPEC have been adapted for IMC architectures, but these adaptations often inadequately address the unique processing paradigm of IMC. Industry leaders have developed specialized benchmarks that better reflect real-world IMC workloads, particularly for applications in neural network inference, sparse matrix operations, and signal processing.
When evaluating EDP optimization in IMC processors, researchers typically employ a multi-level benchmarking approach. At the circuit level, metrics focus on memory cell characteristics such as read/write energy and delay. At the architecture level, benchmarks measure data movement costs, parallel processing efficiency, and the impact of precision scaling on both energy consumption and computational accuracy.
Workload-specific benchmarking has proven essential, as EDP optimization strategies vary significantly across different application domains. For instance, IMC systems optimized for convolutional neural networks exhibit different EDP characteristics compared to those designed for transformer models or graph processing applications.
Recent advancements in IMC benchmarking include the development of simulation frameworks that accurately model the energy-delay tradeoffs across various IMC architectures. These frameworks incorporate detailed power models that account for both dynamic and static power consumption in memory arrays, peripheral circuits, and interconnects.
Comparative analysis across different IMC technologies (ReRAM, SRAM, MRAM, etc.) reveals that each technology presents unique EDP optimization opportunities and challenges. Benchmark results indicate that while ReRAM-based IMC systems often achieve superior energy efficiency, SRAM-based solutions may offer better delay characteristics for certain workloads.
Standardization efforts are underway to establish consistent benchmarking methodologies specifically for IMC systems, with particular emphasis on metrics that accurately capture the energy-delay tradeoffs that define the performance envelope of these novel computing architectures.
The primary performance metrics for IMC systems include energy efficiency (measured in TOPS/W), computational density, throughput, and latency. Energy-Delay Product, which combines energy consumption and processing time, has emerged as a particularly valuable metric for IMC systems where both power efficiency and processing speed are crucial considerations.
Standard benchmarks such as MLPerf and SPEC have been adapted for IMC architectures, but these adaptations often inadequately address the unique processing paradigm of IMC. Industry leaders have developed specialized benchmarks that better reflect real-world IMC workloads, particularly for applications in neural network inference, sparse matrix operations, and signal processing.
When evaluating EDP optimization in IMC processors, researchers typically employ a multi-level benchmarking approach. At the circuit level, metrics focus on memory cell characteristics such as read/write energy and delay. At the architecture level, benchmarks measure data movement costs, parallel processing efficiency, and the impact of precision scaling on both energy consumption and computational accuracy.
Workload-specific benchmarking has proven essential, as EDP optimization strategies vary significantly across different application domains. For instance, IMC systems optimized for convolutional neural networks exhibit different EDP characteristics compared to those designed for transformer models or graph processing applications.
Recent advancements in IMC benchmarking include the development of simulation frameworks that accurately model the energy-delay tradeoffs across various IMC architectures. These frameworks incorporate detailed power models that account for both dynamic and static power consumption in memory arrays, peripheral circuits, and interconnects.
Comparative analysis across different IMC technologies (ReRAM, SRAM, MRAM, etc.) reveals that each technology presents unique EDP optimization opportunities and challenges. Benchmark results indicate that while ReRAM-based IMC systems often achieve superior energy efficiency, SRAM-based solutions may offer better delay characteristics for certain workloads.
Standardization efforts are underway to establish consistent benchmarking methodologies specifically for IMC systems, with particular emphasis on metrics that accurately capture the energy-delay tradeoffs that define the performance envelope of these novel computing architectures.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!