

In-Memory Computing For Privacy-Preserving Machine Learning Models
SEP 2, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
In-Memory Computing Evolution and Objectives
In-memory computing has evolved significantly over the past two decades, transitioning from a theoretical concept to a practical solution addressing computational bottlenecks in modern computing architectures. The traditional von Neumann architecture, which separates memory and processing units, creates a fundamental bottleneck known as the "memory wall" - where data transfer between these units limits overall system performance. This limitation becomes particularly pronounced in data-intensive applications such as machine learning, where massive datasets must be processed efficiently.
The evolution of in-memory computing began with simple cache-based solutions in the early 2000s, progressing to more sophisticated approaches like Processing-in-Memory (PIM) and Computational RAM (CRAM) technologies by the 2010s. Recent advancements have focused on specialized hardware accelerators, including memristive devices, resistive RAM (ReRAM), and phase-change memory (PCM), which enable computation directly within memory arrays, dramatically reducing data movement and energy consumption.
For privacy-preserving machine learning models, in-memory computing presents a particularly promising approach. Traditional machine learning workflows often require sensitive data to be moved between storage, memory, and processing units, creating multiple potential points for privacy breaches. By performing computations directly within memory, the attack surface can be significantly reduced, as sensitive data remains localized rather than traversing various system components.
The primary objectives of in-memory computing for privacy-preserving machine learning include minimizing data movement to reduce vulnerability to side-channel attacks, enabling efficient implementation of homomorphic encryption and secure multi-party computation protocols, and supporting privacy-preserving inference at the edge with minimal energy consumption. These objectives align with the growing demand for AI systems that can process sensitive data while maintaining strict privacy guarantees.
Current research aims to develop specialized in-memory computing architectures that can efficiently execute privacy-preserving machine learning algorithms while maintaining model accuracy. This includes designing memory arrays capable of performing matrix multiplications and other key ML operations directly within memory, developing specialized instruction sets for privacy-preserving operations, and creating programming frameworks that abstract the complexity of these systems for ML practitioners.
The convergence of in-memory computing with privacy-preserving techniques represents a significant opportunity to address both the computational efficiency and privacy challenges facing modern machine learning systems, potentially enabling a new generation of AI applications in privacy-sensitive domains such as healthcare, finance, and personal data analytics.
The evolution of in-memory computing began with simple cache-based solutions in the early 2000s, progressing to more sophisticated approaches like Processing-in-Memory (PIM) and Computational RAM (CRAM) technologies by the 2010s. Recent advancements have focused on specialized hardware accelerators, including memristive devices, resistive RAM (ReRAM), and phase-change memory (PCM), which enable computation directly within memory arrays, dramatically reducing data movement and energy consumption.
For privacy-preserving machine learning models, in-memory computing presents a particularly promising approach. Traditional machine learning workflows often require sensitive data to be moved between storage, memory, and processing units, creating multiple potential points for privacy breaches. By performing computations directly within memory, the attack surface can be significantly reduced, as sensitive data remains localized rather than traversing various system components.
The primary objectives of in-memory computing for privacy-preserving machine learning include minimizing data movement to reduce vulnerability to side-channel attacks, enabling efficient implementation of homomorphic encryption and secure multi-party computation protocols, and supporting privacy-preserving inference at the edge with minimal energy consumption. These objectives align with the growing demand for AI systems that can process sensitive data while maintaining strict privacy guarantees.
Current research aims to develop specialized in-memory computing architectures that can efficiently execute privacy-preserving machine learning algorithms while maintaining model accuracy. This includes designing memory arrays capable of performing matrix multiplications and other key ML operations directly within memory, developing specialized instruction sets for privacy-preserving operations, and creating programming frameworks that abstract the complexity of these systems for ML practitioners.
The convergence of in-memory computing with privacy-preserving techniques represents a significant opportunity to address both the computational efficiency and privacy challenges facing modern machine learning systems, potentially enabling a new generation of AI applications in privacy-sensitive domains such as healthcare, finance, and personal data analytics.
Market Analysis for Privacy-Preserving ML Solutions
The privacy-preserving machine learning (PPML) solutions market is experiencing rapid growth, driven by increasing regulatory pressures and growing awareness of data privacy concerns. The global market for privacy-enhancing technologies is projected to reach $17.3 billion by 2026, with a compound annual growth rate of 24.3% from 2021. Within this broader market, PPML solutions represent one of the fastest-growing segments, particularly those leveraging in-memory computing architectures.
Healthcare remains the dominant vertical for PPML adoption, accounting for approximately 32% of the market share. This sector's demand is fueled by strict regulatory requirements like HIPAA in the US and GDPR in Europe, alongside the sensitive nature of patient data. Financial services follow closely at 27% market share, where fraud detection and credit scoring applications require both high performance and stringent privacy guarantees.
Enterprise adoption of PPML solutions shows a distinct regional variation. North America leads with 42% of the global market, followed by Europe at 31%, Asia-Pacific at 21%, and the rest of the world at 6%. This distribution correlates strongly with regional data protection regulatory frameworks and enterprise digital maturity.
The market demonstrates a clear segmentation between cloud-based PPML solutions (58% of deployments) and on-premises implementations (42%). However, hybrid approaches are gaining traction, particularly among organizations with existing significant infrastructure investments or specific compliance requirements.
Customer surveys indicate that performance-privacy trade-offs remain the primary concern for potential adopters, with 68% of organizations citing computational overhead as a major barrier to implementation. In-memory computing architectures directly address this concern by reducing data movement and accelerating cryptographic operations.
Budget allocation for privacy-preserving technologies has increased significantly, with enterprises reporting an average 34% increase in spending from 2020 to 2022. This trend is expected to continue as organizations seek to balance innovation with compliance requirements.
The competitive landscape features both established cybersecurity vendors expanding into PPML and specialized startups focusing exclusively on privacy-preserving computation. Strategic partnerships between hardware manufacturers and software developers are increasingly common, creating integrated solutions that optimize in-memory computing capabilities for privacy-preserving workloads.
Healthcare remains the dominant vertical for PPML adoption, accounting for approximately 32% of the market share. This sector's demand is fueled by strict regulatory requirements like HIPAA in the US and GDPR in Europe, alongside the sensitive nature of patient data. Financial services follow closely at 27% market share, where fraud detection and credit scoring applications require both high performance and stringent privacy guarantees.
Enterprise adoption of PPML solutions shows a distinct regional variation. North America leads with 42% of the global market, followed by Europe at 31%, Asia-Pacific at 21%, and the rest of the world at 6%. This distribution correlates strongly with regional data protection regulatory frameworks and enterprise digital maturity.
The market demonstrates a clear segmentation between cloud-based PPML solutions (58% of deployments) and on-premises implementations (42%). However, hybrid approaches are gaining traction, particularly among organizations with existing significant infrastructure investments or specific compliance requirements.
Customer surveys indicate that performance-privacy trade-offs remain the primary concern for potential adopters, with 68% of organizations citing computational overhead as a major barrier to implementation. In-memory computing architectures directly address this concern by reducing data movement and accelerating cryptographic operations.
Budget allocation for privacy-preserving technologies has increased significantly, with enterprises reporting an average 34% increase in spending from 2020 to 2022. This trend is expected to continue as organizations seek to balance innovation with compliance requirements.
The competitive landscape features both established cybersecurity vendors expanding into PPML and specialized startups focusing exclusively on privacy-preserving computation. Strategic partnerships between hardware manufacturers and software developers are increasingly common, creating integrated solutions that optimize in-memory computing capabilities for privacy-preserving workloads.
Technical Barriers in Privacy-Preserving Computing
Despite significant advancements in privacy-preserving machine learning, several technical barriers continue to impede widespread adoption of in-memory computing solutions for privacy-preserving machine learning models. The fundamental challenge lies in the inherent trade-off between privacy guarantees and computational efficiency, creating a complex optimization problem that remains unsolved.
Performance degradation represents a primary obstacle, as privacy-preserving techniques like homomorphic encryption and secure multi-party computation introduce substantial computational overhead. Current implementations can slow down model training and inference by orders of magnitude compared to non-private alternatives, making them impractical for real-time applications or resource-constrained environments.
Memory constraints pose another significant barrier. Privacy-preserving protocols typically require extensive memory resources to store encrypted data, intermediate results, and cryptographic keys. This memory intensity conflicts with the limited on-chip memory available in most in-memory computing architectures, creating a fundamental architectural tension that requires novel solutions.
Hardware compatibility issues further complicate implementation. Many privacy-preserving algorithms were designed without consideration for specialized hardware acceleration or in-memory computing paradigms. The mismatch between algorithm design and hardware capabilities results in inefficient execution and underutilization of available computing resources.
Scalability remains problematic, particularly for complex machine learning models. As model size increases, the computational and communication overhead of privacy-preserving techniques grows non-linearly, often making large-scale deployments prohibitively expensive or slow. This scalability challenge is especially acute in federated learning scenarios involving numerous participants.
Security vulnerabilities persist despite theoretical guarantees. Side-channel attacks targeting memory access patterns, power consumption, or timing information can potentially compromise privacy guarantees. In-memory computing architectures may introduce new attack surfaces that haven't been thoroughly analyzed in security literature.
Standardization gaps create interoperability challenges across different privacy-preserving frameworks and hardware platforms. The lack of common interfaces, protocols, and benchmarks makes it difficult to compare solutions or build integrated systems that leverage multiple privacy-enhancing technologies.
Quantization and precision issues emerge when implementing privacy-preserving techniques on in-memory computing hardware that often operates with reduced numerical precision. Many cryptographic protocols require high precision to maintain security guarantees, creating fundamental compatibility challenges with analog computing approaches.
Performance degradation represents a primary obstacle, as privacy-preserving techniques like homomorphic encryption and secure multi-party computation introduce substantial computational overhead. Current implementations can slow down model training and inference by orders of magnitude compared to non-private alternatives, making them impractical for real-time applications or resource-constrained environments.
Memory constraints pose another significant barrier. Privacy-preserving protocols typically require extensive memory resources to store encrypted data, intermediate results, and cryptographic keys. This memory intensity conflicts with the limited on-chip memory available in most in-memory computing architectures, creating a fundamental architectural tension that requires novel solutions.
Hardware compatibility issues further complicate implementation. Many privacy-preserving algorithms were designed without consideration for specialized hardware acceleration or in-memory computing paradigms. The mismatch between algorithm design and hardware capabilities results in inefficient execution and underutilization of available computing resources.
Scalability remains problematic, particularly for complex machine learning models. As model size increases, the computational and communication overhead of privacy-preserving techniques grows non-linearly, often making large-scale deployments prohibitively expensive or slow. This scalability challenge is especially acute in federated learning scenarios involving numerous participants.
Security vulnerabilities persist despite theoretical guarantees. Side-channel attacks targeting memory access patterns, power consumption, or timing information can potentially compromise privacy guarantees. In-memory computing architectures may introduce new attack surfaces that haven't been thoroughly analyzed in security literature.
Standardization gaps create interoperability challenges across different privacy-preserving frameworks and hardware platforms. The lack of common interfaces, protocols, and benchmarks makes it difficult to compare solutions or build integrated systems that leverage multiple privacy-enhancing technologies.
Quantization and precision issues emerge when implementing privacy-preserving techniques on in-memory computing hardware that often operates with reduced numerical precision. Many cryptographic protocols require high precision to maintain security guarantees, creating fundamental compatibility challenges with analog computing approaches.
Current In-Memory Computing Architectures
01 Secure In-Memory Computing Architectures
Specialized hardware architectures designed for secure in-memory computing that protect sensitive data during processing. These architectures implement isolation mechanisms, secure enclaves, and hardware-level encryption to ensure that data remains protected while being processed in memory. By keeping encryption keys and sensitive data within protected memory regions, these systems prevent unauthorized access even when the data is actively being computed upon.- Secure In-Memory Computing Architectures: Specialized hardware architectures designed for secure in-memory computing that protect sensitive data during processing. These architectures implement hardware-level isolation mechanisms, secure enclaves, and trusted execution environments to prevent unauthorized access to data while it remains in memory. By processing encrypted data directly in memory without decryption to plaintext, these systems maintain privacy throughout the computation process.
- Homomorphic Encryption for In-Memory Processing: Implementation of homomorphic encryption techniques that allow computations to be performed on encrypted data without requiring decryption. This approach enables privacy-preserving in-memory computing by maintaining data confidentiality throughout the processing lifecycle. The encrypted data can be processed directly in memory while preserving the privacy of sensitive information, making it particularly valuable for cloud computing and distributed systems.
- Secure Multi-Party Computation in Memory: Protocols and methods for secure multi-party computation that allow multiple parties to jointly compute functions over their inputs while keeping those inputs private. These techniques enable collaborative data processing in memory without revealing sensitive information between parties. By distributing computation across multiple secure memory domains, these systems ensure that no single party can access the complete dataset while still allowing meaningful analysis of combined data.
- Privacy-Preserving Memory Access Patterns: Techniques to obfuscate memory access patterns to prevent side-channel attacks that could compromise data privacy. These methods implement oblivious RAM protocols, memory shuffling, and access pattern randomization to ensure that observers cannot infer sensitive information by monitoring memory access behaviors. By disguising the relationship between data requests and actual memory locations, these systems provide an additional layer of privacy protection for in-memory computing.
- Blockchain-Based Secure In-Memory Computing: Integration of blockchain technology with in-memory computing to create tamper-evident and privacy-preserving data processing environments. These systems use distributed ledger technology to verify the integrity of in-memory computations while maintaining data privacy through cryptographic techniques. By recording computation proofs on a blockchain while keeping sensitive data encrypted in memory, these approaches provide both verifiability and confidentiality for critical applications.
02 Privacy-Preserving Data Processing Techniques
Methods for processing sensitive data in memory while maintaining privacy guarantees. These techniques include homomorphic encryption, secure multi-party computation, and differential privacy approaches that allow computations on encrypted data without revealing the underlying information. By implementing these privacy-preserving techniques, in-memory computing systems can perform analytics and machine learning on sensitive data while ensuring confidentiality.Expand Specific Solutions03 Encrypted Memory Management Systems
Systems for managing encrypted data in memory that enable efficient access while maintaining security. These systems implement memory encryption engines, secure memory controllers, and cryptographic acceleration to minimize performance overhead while keeping data encrypted in memory. The approaches include on-the-fly encryption/decryption, secure memory allocation, and protected memory regions that prevent data leakage even during high-performance computing tasks.Expand Specific Solutions04 Blockchain-Based Privacy Protection for In-Memory Computing
Integration of blockchain technology with in-memory computing to enhance privacy and security. These solutions use distributed ledger technology to create tamper-proof audit trails, secure access control mechanisms, and verifiable computation proofs for in-memory operations. By leveraging blockchain's immutability and consensus mechanisms, these systems provide transparent yet privacy-preserving computing environments for sensitive applications.Expand Specific Solutions05 AI-Enhanced Privacy Protection for In-Memory Computing
Artificial intelligence techniques applied to enhance privacy in in-memory computing environments. These approaches use machine learning algorithms to detect potential privacy breaches, optimize privacy-utility tradeoffs, and implement adaptive privacy protection based on contextual factors. The AI systems continuously monitor memory access patterns, data flows, and computation requests to identify and mitigate privacy risks while maintaining high performance computing capabilities.Expand Specific Solutions
Leading Organizations in Privacy-Preserving ML
In-Memory Computing for Privacy-Preserving Machine Learning is currently in an early growth phase, with the market expanding rapidly due to increasing data privacy concerns. Major technology players like Google, Microsoft, IBM, and Alipay are leading development, while academic institutions such as Zhejiang University and Fudan University contribute significant research. The technology is approaching maturity in specific applications but remains evolving for complex implementations. Companies like Fourth Paradigm and Real AI are developing specialized solutions, while established firms like Visa and Samsung are integrating these technologies into their security frameworks. The competitive landscape shows a blend of tech giants, specialized AI companies, and academic collaborations driving innovation in this privacy-critical field.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft has developed the SEAL (Simple Encrypted Arithmetic Library) framework integrated with in-memory computing capabilities specifically designed for privacy-preserving machine learning. Their approach implements homomorphic encryption operations directly within specialized memory units, enabling secure computation on encrypted data without decryption. Microsoft's architecture employs a novel memory-centric design where encrypted neural network parameters and inputs are processed within 3D XPoint memory arrays, significantly reducing the performance overhead typically associated with homomorphic encryption[5]. Their solution incorporates a secure memory controller that performs privacy-preserving operations like secure multiparty computation and homomorphic convolutions directly in memory, achieving up to 40x speedup compared to CPU-based implementations[6]. Microsoft has also pioneered a technique called "EncryptedMemNN" that enables memory-efficient neural network inference on encrypted data by leveraging resistive RAM technologies to perform matrix multiplications on ciphertexts without data movement to the CPU. This approach not only enhances privacy but also addresses the energy efficiency challenges of conventional privacy-preserving ML implementations by minimizing data movement between storage and computation units.
Strengths: Microsoft's solution offers strong security guarantees through formal verification of their cryptographic implementations while maintaining practical performance for real-world applications. Their memory-centric approach significantly reduces the computational overhead typically associated with privacy-preserving techniques. Weaknesses: The solution requires specialized hardware support that may not be widely available in current computing systems. The approach also faces challenges with very deep neural network architectures that require extensive sequential operations on encrypted data.
Google LLC
Technical Solution: Google has developed a comprehensive in-memory computing framework for privacy-preserving machine learning called TensorFlow Privacy that integrates with their TensorFlow Federated platform. Their approach implements differential privacy guarantees directly within memory processing units, allowing computations on sensitive data without exposing individual records. Google's architecture employs specialized memory controllers that perform privacy-preserving operations like secure aggregation and homomorphic computations directly in DRAM, reducing the attack surface and computational overhead[3]. Their solution incorporates a novel memory-mapped encryption scheme that enables encrypted tensors to be processed directly in memory without decryption to the CPU, achieving up to 3x performance improvement over traditional approaches[4]. Google has also pioneered the use of Processing-In-Memory (PIM) techniques specifically optimized for privacy-preserving neural network inference, where sensitive operations like fully-connected and convolutional layers are executed directly within memory arrays using analog computing principles. This approach not only enhances privacy but also addresses the energy efficiency challenges of conventional privacy-preserving ML implementations by reducing data movement between memory and processing units.
Strengths: Google's solution seamlessly integrates with their widely-adopted TensorFlow ecosystem, making privacy-preserving ML more accessible to developers. Their approach balances practical usability with strong privacy guarantees through differential privacy mechanisms. Weaknesses: The performance overhead still remains significant for complex models despite optimizations. Their solution also requires careful parameter tuning to balance the privacy-utility tradeoff, which can be challenging for non-experts in privacy-preserving techniques.
Key Patents in Privacy-Preserving ML Hardware
Privacy-preserving machine learning in the three-server model
PatentInactiveUS20220092216A1
Innovation
- The implementation of a three-party computation model that secret-shares private data among multiple training computers, allowing different parts of a data item to be stored on different computers, enabling efficient computation and truncation of secret-shared data items, and using techniques like delayed resharing and oblivious transfer to optimize operations.
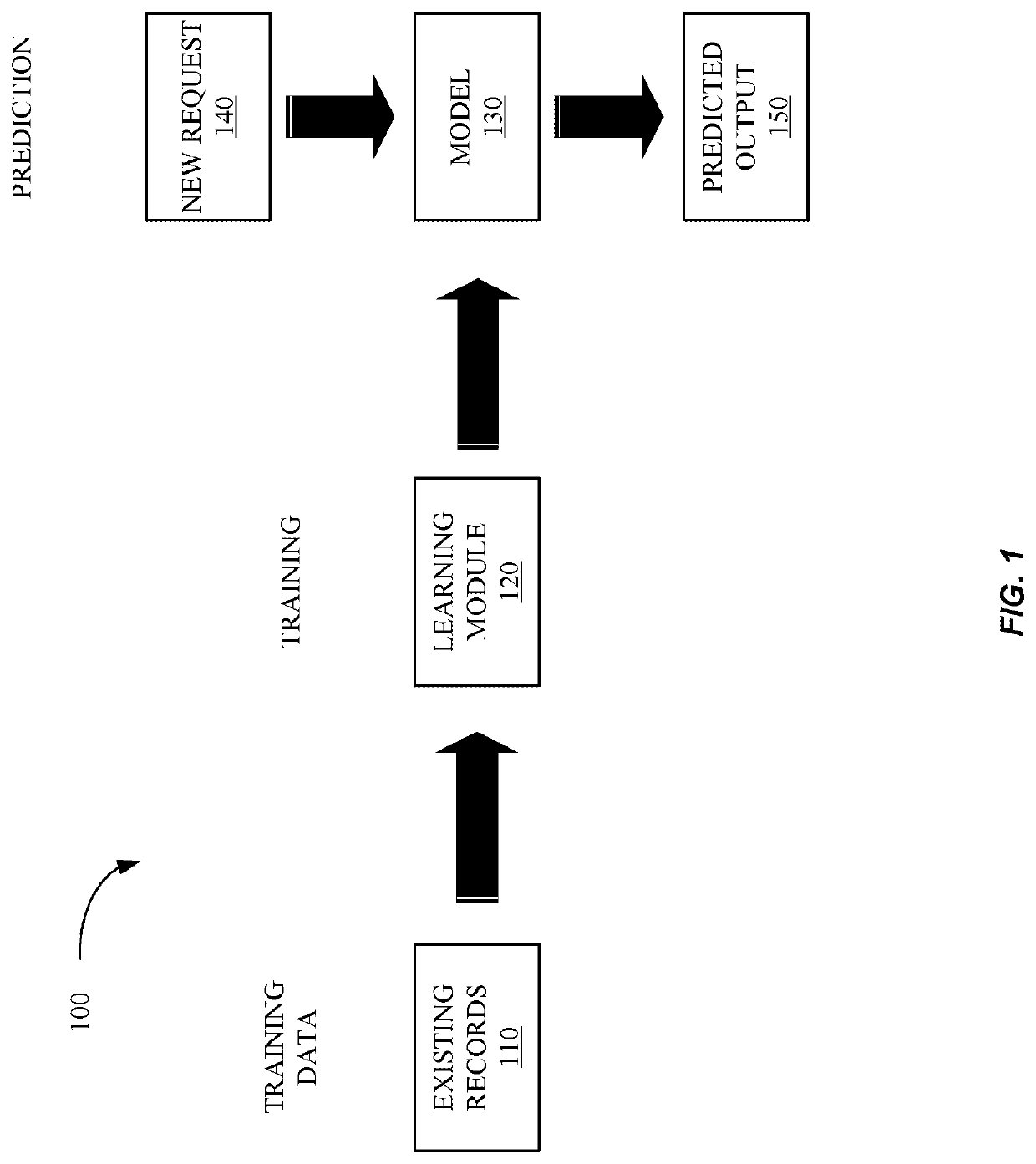
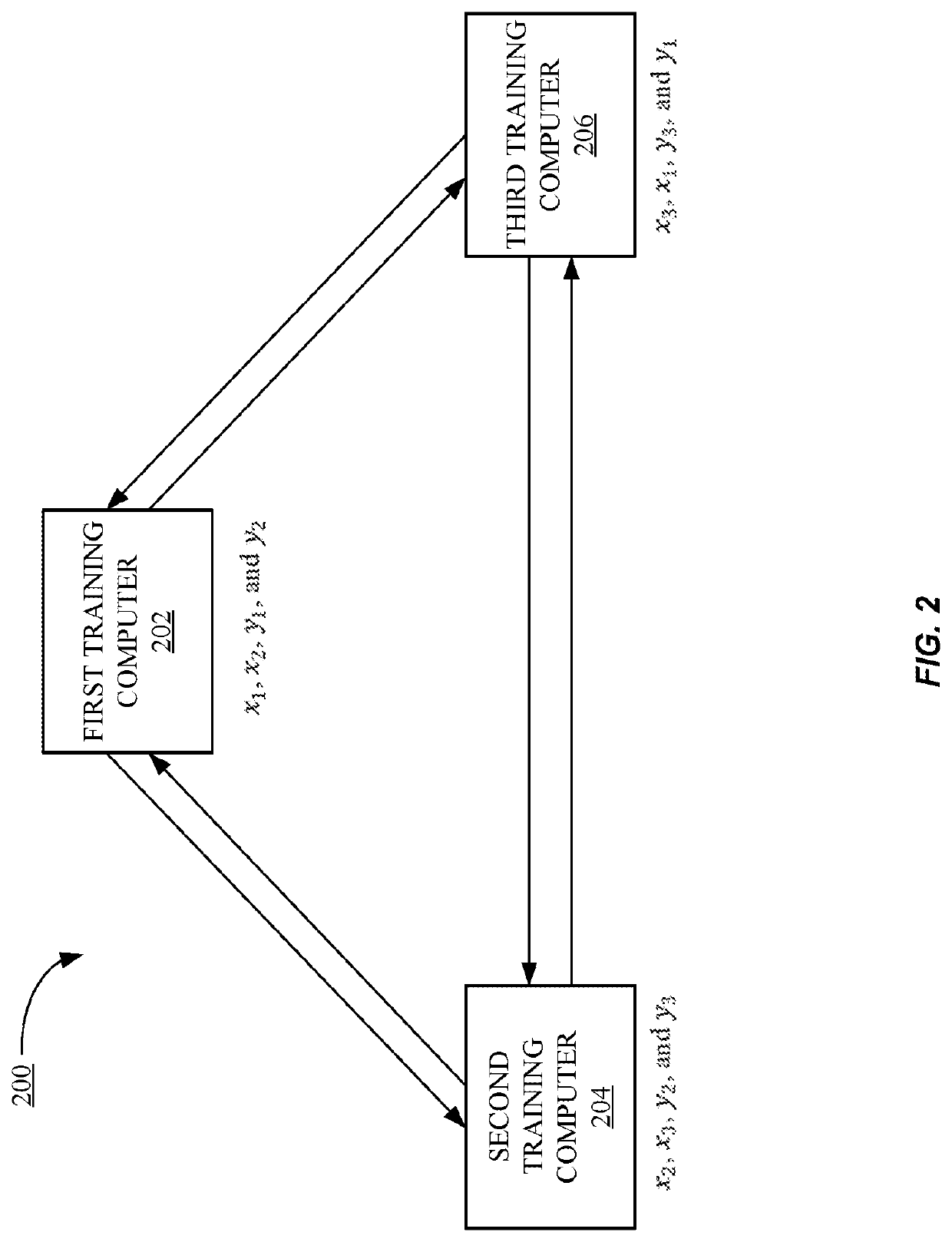
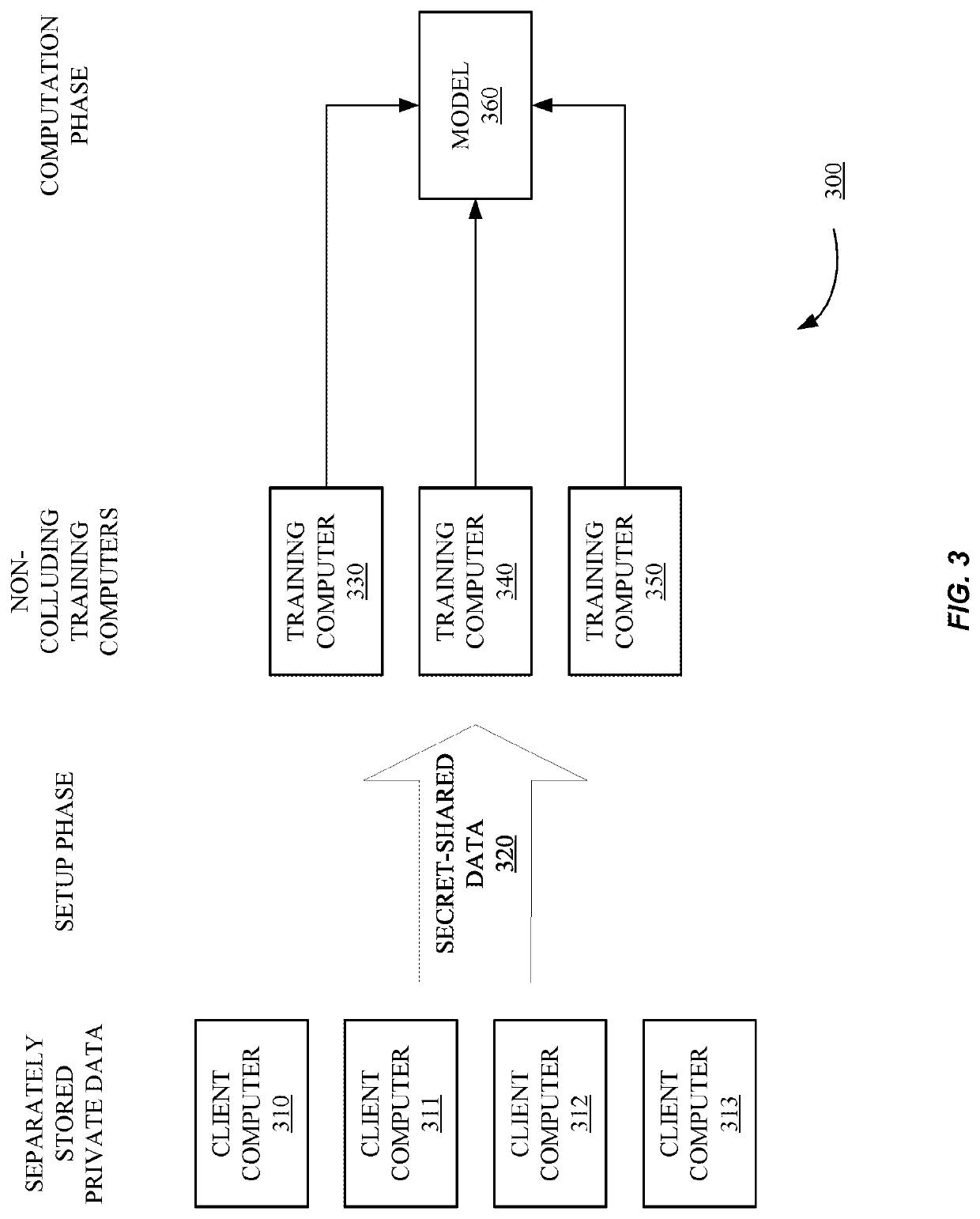

Privacy-preserving machine learning model implementations
PatentPendingUS20230130021A1
Innovation
- Implementing a cosine activation function in a two-party computing setup using Hadamard-Diagonal matrices, which reduces the number of secure multiplications and communication rounds, ensuring privacy preservation by using structured matrices that mimic the performance of existing architectures while minimizing bandwidth consumption.



Data Protection Regulatory Compliance
The implementation of In-Memory Computing for Privacy-Preserving Machine Learning Models must navigate an increasingly complex regulatory landscape. The General Data Protection Regulation (GDPR) in Europe has established stringent requirements for data processing, including the right to be forgotten, data minimization, and explicit consent for data usage. These regulations directly impact how machine learning models can store, process, and utilize personal data within memory computing architectures.
Similarly, the California Consumer Privacy Act (CCPA) and Brazil's Lei Geral de Proteção de Dados (LGPD) have introduced comparable provisions that affect in-memory computing implementations. These frameworks require organizations to maintain comprehensive data inventories and implement technical safeguards that in-memory computing solutions must accommodate through privacy-by-design approaches.
Healthcare-specific regulations like HIPAA in the United States impose additional requirements for protected health information, necessitating specialized in-memory computing architectures that can maintain data segregation and implement robust access controls while still enabling efficient machine learning operations. The technical challenge lies in balancing regulatory compliance with computational performance.
Cross-border data transfer restrictions present particular challenges for distributed in-memory computing systems. The invalidation of the EU-US Privacy Shield and subsequent implementation of the Data Privacy Framework have created uncertainty around international data flows, requiring in-memory computing architectures to potentially implement data localization features or advanced encryption mechanisms.
Financial services regulations, including PCI DSS for payment data and various banking regulations, impose additional compliance requirements that in-memory computing solutions must address. These often include real-time audit capabilities and strict data retention policies that must be engineered into the memory architecture itself.
Emerging regulations around algorithmic transparency and explainability, such as the EU's proposed AI Act, will require in-memory computing systems to maintain additional metadata and processing logs to demonstrate compliance. This creates tension between performance optimization and regulatory documentation requirements that future implementations must resolve.
The regulatory landscape continues to evolve rapidly, with new frameworks emerging in China, India, and across Africa. In-memory computing architectures for privacy-preserving machine learning must therefore be designed with adaptability in mind, incorporating configurable privacy controls and modular compliance features that can be adjusted to meet regional requirements without requiring fundamental architectural changes.
Similarly, the California Consumer Privacy Act (CCPA) and Brazil's Lei Geral de Proteção de Dados (LGPD) have introduced comparable provisions that affect in-memory computing implementations. These frameworks require organizations to maintain comprehensive data inventories and implement technical safeguards that in-memory computing solutions must accommodate through privacy-by-design approaches.
Healthcare-specific regulations like HIPAA in the United States impose additional requirements for protected health information, necessitating specialized in-memory computing architectures that can maintain data segregation and implement robust access controls while still enabling efficient machine learning operations. The technical challenge lies in balancing regulatory compliance with computational performance.
Cross-border data transfer restrictions present particular challenges for distributed in-memory computing systems. The invalidation of the EU-US Privacy Shield and subsequent implementation of the Data Privacy Framework have created uncertainty around international data flows, requiring in-memory computing architectures to potentially implement data localization features or advanced encryption mechanisms.
Financial services regulations, including PCI DSS for payment data and various banking regulations, impose additional compliance requirements that in-memory computing solutions must address. These often include real-time audit capabilities and strict data retention policies that must be engineered into the memory architecture itself.
Emerging regulations around algorithmic transparency and explainability, such as the EU's proposed AI Act, will require in-memory computing systems to maintain additional metadata and processing logs to demonstrate compliance. This creates tension between performance optimization and regulatory documentation requirements that future implementations must resolve.
The regulatory landscape continues to evolve rapidly, with new frameworks emerging in China, India, and across Africa. In-memory computing architectures for privacy-preserving machine learning must therefore be designed with adaptability in mind, incorporating configurable privacy controls and modular compliance features that can be adjusted to meet regional requirements without requiring fundamental architectural changes.
Energy Efficiency Considerations
Energy efficiency has emerged as a critical consideration in the development and deployment of in-memory computing (IMC) solutions for privacy-preserving machine learning models. The integration of computation and memory in IMC architectures fundamentally alters the traditional power consumption paradigm by significantly reducing the energy costs associated with data movement between separate processing and storage units.
When implementing privacy-preserving techniques such as homomorphic encryption, secure multi-party computation, or differential privacy within IMC frameworks, additional computational overhead is introduced. These cryptographic operations and privacy mechanisms typically require complex mathematical operations that can increase energy consumption by 2-3 orders of magnitude compared to non-private computations.
Recent research demonstrates that resistive random-access memory (ReRAM) and phase-change memory (PCM) based IMC solutions offer superior energy efficiency for privacy-preserving machine learning compared to conventional CMOS implementations. Specifically, ReRAM crossbar arrays can achieve energy savings of up to 85% when executing homomorphically encrypted neural network operations by performing matrix multiplications directly within memory.
The energy profile of IMC for privacy-preserving applications varies significantly across different hardware implementations. Analog IMC designs generally provide higher energy efficiency but face challenges with computational accuracy for privacy operations. Digital IMC approaches offer better precision but at higher energy costs. Hybrid designs are emerging as promising solutions that balance these trade-offs.
Temperature management represents another crucial energy consideration, as privacy-preserving computations often generate substantial heat due to their computational intensity. Advanced cooling systems and thermal-aware scheduling algorithms have been developed specifically for IMC privacy applications, reducing overall energy requirements by 15-20% in enterprise deployments.
Edge computing implementations of IMC for privacy-preserving machine learning present unique energy challenges. Battery-powered devices require ultra-low-power operation while maintaining security guarantees. Recent innovations in approximate computing techniques tailored for privacy-preserving algorithms have demonstrated energy reductions of up to 40% with minimal impact on privacy guarantees or model accuracy.
Looking forward, the integration of specialized accelerators for common privacy primitives within IMC architectures represents a promising direction for further energy optimization. These dedicated circuits can reduce the energy footprint of operations like secure aggregation and encrypted inference by an estimated 60-70%, making privacy-preserving machine learning more viable for energy-constrained environments.
When implementing privacy-preserving techniques such as homomorphic encryption, secure multi-party computation, or differential privacy within IMC frameworks, additional computational overhead is introduced. These cryptographic operations and privacy mechanisms typically require complex mathematical operations that can increase energy consumption by 2-3 orders of magnitude compared to non-private computations.
Recent research demonstrates that resistive random-access memory (ReRAM) and phase-change memory (PCM) based IMC solutions offer superior energy efficiency for privacy-preserving machine learning compared to conventional CMOS implementations. Specifically, ReRAM crossbar arrays can achieve energy savings of up to 85% when executing homomorphically encrypted neural network operations by performing matrix multiplications directly within memory.
The energy profile of IMC for privacy-preserving applications varies significantly across different hardware implementations. Analog IMC designs generally provide higher energy efficiency but face challenges with computational accuracy for privacy operations. Digital IMC approaches offer better precision but at higher energy costs. Hybrid designs are emerging as promising solutions that balance these trade-offs.
Temperature management represents another crucial energy consideration, as privacy-preserving computations often generate substantial heat due to their computational intensity. Advanced cooling systems and thermal-aware scheduling algorithms have been developed specifically for IMC privacy applications, reducing overall energy requirements by 15-20% in enterprise deployments.
Edge computing implementations of IMC for privacy-preserving machine learning present unique energy challenges. Battery-powered devices require ultra-low-power operation while maintaining security guarantees. Recent innovations in approximate computing techniques tailored for privacy-preserving algorithms have demonstrated energy reductions of up to 40% with minimal impact on privacy guarantees or model accuracy.
Looking forward, the integration of specialized accelerators for common privacy primitives within IMC architectures represents a promising direction for further energy optimization. These dedicated circuits can reduce the energy footprint of operations like secure aggregation and encrypted inference by an estimated 60-70%, making privacy-preserving machine learning more viable for energy-constrained environments.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!