How In-Memory Computing Enhances Embedded IoT AI Workloads
SEP 12, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
In-Memory Computing Evolution and Objectives
In-memory computing has evolved significantly over the past two decades, transforming from a niche technology into a critical enabler for real-time data processing in embedded systems. The evolution began with simple on-chip memory architectures in the early 2000s, progressing through several key developmental phases that have dramatically expanded its capabilities and applications.
The initial phase focused primarily on reducing memory access latency through basic cache optimization techniques. By 2010, the second generation introduced more sophisticated memory hierarchies and the concept of processing-in-memory (PIM), which began to blur the traditional boundaries between storage and computation. The current generation, emerging around 2018, represents a paradigm shift with true computational memory that enables parallel processing directly within memory arrays.
This evolutionary trajectory has been driven by the fundamental von Neumann bottleneck—the performance limitation caused by the physical separation of processing and memory units. As IoT devices proliferate and AI workloads become increasingly complex, this bottleneck has become more pronounced, necessitating architectural innovations that bring computation closer to data.
The primary objective of modern in-memory computing is to enable efficient AI processing at the edge by minimizing data movement, which traditionally accounts for up to 90% of energy consumption in embedded systems. By performing computations where data resides, these architectures aim to achieve orders-of-magnitude improvements in energy efficiency while maintaining or enhancing computational throughput.
Secondary objectives include reducing system latency for time-critical IoT applications, enabling more sophisticated AI models to run on resource-constrained devices, and enhancing data security by minimizing the exposure of sensitive information during processing. These goals align with the broader industry trend toward distributed intelligence and edge computing.
From a technical perspective, current research focuses on developing specialized memory cells that can perform logical and arithmetic operations, creating efficient mapping techniques for neural network operations to memory arrays, and designing hybrid architectures that combine traditional processing with in-memory computing capabilities. The ultimate aim is to create a new computing paradigm where memory is not just a passive storage element but an active computational resource.
As IoT deployments scale to billions of devices and AI models grow more sophisticated, in-memory computing stands as a promising approach to overcome the fundamental limitations of conventional architectures, potentially enabling a new generation of intelligent, energy-efficient embedded systems capable of performing complex AI workloads with minimal resource requirements.
The initial phase focused primarily on reducing memory access latency through basic cache optimization techniques. By 2010, the second generation introduced more sophisticated memory hierarchies and the concept of processing-in-memory (PIM), which began to blur the traditional boundaries between storage and computation. The current generation, emerging around 2018, represents a paradigm shift with true computational memory that enables parallel processing directly within memory arrays.
This evolutionary trajectory has been driven by the fundamental von Neumann bottleneck—the performance limitation caused by the physical separation of processing and memory units. As IoT devices proliferate and AI workloads become increasingly complex, this bottleneck has become more pronounced, necessitating architectural innovations that bring computation closer to data.
The primary objective of modern in-memory computing is to enable efficient AI processing at the edge by minimizing data movement, which traditionally accounts for up to 90% of energy consumption in embedded systems. By performing computations where data resides, these architectures aim to achieve orders-of-magnitude improvements in energy efficiency while maintaining or enhancing computational throughput.
Secondary objectives include reducing system latency for time-critical IoT applications, enabling more sophisticated AI models to run on resource-constrained devices, and enhancing data security by minimizing the exposure of sensitive information during processing. These goals align with the broader industry trend toward distributed intelligence and edge computing.
From a technical perspective, current research focuses on developing specialized memory cells that can perform logical and arithmetic operations, creating efficient mapping techniques for neural network operations to memory arrays, and designing hybrid architectures that combine traditional processing with in-memory computing capabilities. The ultimate aim is to create a new computing paradigm where memory is not just a passive storage element but an active computational resource.
As IoT deployments scale to billions of devices and AI models grow more sophisticated, in-memory computing stands as a promising approach to overcome the fundamental limitations of conventional architectures, potentially enabling a new generation of intelligent, energy-efficient embedded systems capable of performing complex AI workloads with minimal resource requirements.
IoT Market Demand for Edge AI Solutions
The IoT market is experiencing a significant shift towards edge AI solutions, driven by the increasing need for real-time data processing and decision-making capabilities at the device level. This trend is particularly evident in industrial IoT applications, smart cities, healthcare, and consumer electronics, where latency-sensitive operations require immediate insights without relying on cloud connectivity.
Market research indicates that the global edge AI market is projected to grow substantially over the next five years, with IoT devices representing a major segment of this expansion. The primary market drivers include the proliferation of IoT devices, increasing data volumes, privacy concerns, and the need for reduced latency in critical applications.
Industrial IoT represents one of the largest market segments demanding edge AI solutions. Manufacturing facilities are increasingly deploying smart sensors and systems that require real-time anomaly detection, predictive maintenance, and process optimization. These applications cannot tolerate the delays associated with cloud processing, creating strong demand for in-memory computing solutions that can process AI workloads directly on embedded devices.
The healthcare sector presents another significant market opportunity, with edge AI enabling real-time patient monitoring, medical imaging analysis, and emergency response systems. These applications require processing sensitive data locally to ensure both privacy compliance and immediate response capabilities, further driving demand for efficient in-memory computing architectures.
Consumer IoT devices, including smart home systems, wearables, and personal assistants, are also fueling market growth. Consumers increasingly expect instantaneous responses from their devices, even in environments with limited connectivity. This expectation creates demand for devices capable of running sophisticated AI models locally, with minimal power consumption and form factor constraints.
Automotive and transportation sectors represent emerging high-value markets for edge AI solutions. Advanced driver-assistance systems (ADAS), autonomous vehicles, and smart traffic management systems all require ultra-low latency processing of sensor data, creating substantial demand for embedded AI acceleration technologies.
Market analysis reveals that organizations are increasingly prioritizing edge AI solutions that can deliver three key benefits: reduced operational costs through decreased cloud computing and bandwidth requirements; enhanced data security and privacy by minimizing data transmission; and improved reliability through continued operation during connectivity disruptions. In-memory computing architectures directly address these market requirements by enabling efficient AI processing directly on resource-constrained IoT devices.
Market research indicates that the global edge AI market is projected to grow substantially over the next five years, with IoT devices representing a major segment of this expansion. The primary market drivers include the proliferation of IoT devices, increasing data volumes, privacy concerns, and the need for reduced latency in critical applications.
Industrial IoT represents one of the largest market segments demanding edge AI solutions. Manufacturing facilities are increasingly deploying smart sensors and systems that require real-time anomaly detection, predictive maintenance, and process optimization. These applications cannot tolerate the delays associated with cloud processing, creating strong demand for in-memory computing solutions that can process AI workloads directly on embedded devices.
The healthcare sector presents another significant market opportunity, with edge AI enabling real-time patient monitoring, medical imaging analysis, and emergency response systems. These applications require processing sensitive data locally to ensure both privacy compliance and immediate response capabilities, further driving demand for efficient in-memory computing architectures.
Consumer IoT devices, including smart home systems, wearables, and personal assistants, are also fueling market growth. Consumers increasingly expect instantaneous responses from their devices, even in environments with limited connectivity. This expectation creates demand for devices capable of running sophisticated AI models locally, with minimal power consumption and form factor constraints.
Automotive and transportation sectors represent emerging high-value markets for edge AI solutions. Advanced driver-assistance systems (ADAS), autonomous vehicles, and smart traffic management systems all require ultra-low latency processing of sensor data, creating substantial demand for embedded AI acceleration technologies.
Market analysis reveals that organizations are increasingly prioritizing edge AI solutions that can deliver three key benefits: reduced operational costs through decreased cloud computing and bandwidth requirements; enhanced data security and privacy by minimizing data transmission; and improved reliability through continued operation during connectivity disruptions. In-memory computing architectures directly address these market requirements by enabling efficient AI processing directly on resource-constrained IoT devices.
Current Limitations in Embedded AI Processing
Despite the promising advancements in embedded AI for IoT applications, current implementations face significant limitations that hinder optimal performance. Traditional embedded systems utilize a von Neumann architecture where processing and memory units are physically separated, creating a fundamental bottleneck known as the "memory wall." This architecture forces constant data movement between storage and processing units, resulting in high energy consumption and processing delays—particularly problematic for resource-constrained IoT devices.
Power constraints represent another critical limitation. Embedded IoT devices typically operate on limited power sources such as batteries or energy harvesting mechanisms. Complex AI workloads demand substantial computational resources, creating a challenging trade-off between AI capability and power efficiency. This constraint often forces developers to implement simplified AI models that sacrifice accuracy and functionality.
Memory capacity restrictions further complicate embedded AI deployment. Advanced neural networks and machine learning models require significant memory resources for both model storage and runtime operations. Most embedded systems offer limited on-device memory, restricting the complexity and size of deployable AI models. This limitation becomes particularly evident when implementing deep learning models that require substantial parameter storage.
Processing speed limitations also impede real-time AI applications in IoT environments. Many IoT use cases demand immediate responses to environmental changes or user inputs, yet embedded processors often lack the computational power to execute complex AI algorithms with acceptable latency. This limitation becomes particularly problematic in time-sensitive applications like industrial control systems or autonomous vehicles.
Thermal management presents additional challenges. Intensive computational tasks generate heat that must be dissipated effectively to prevent performance degradation and hardware damage. Many IoT form factors lack adequate cooling mechanisms, forcing systems to throttle performance or implement duty cycling, which further impacts AI workload execution efficiency.
Flexibility and adaptability constraints also exist in current embedded AI systems. Traditional hardware architectures are often optimized for specific workloads, limiting their ability to efficiently handle diverse AI tasks or adapt to evolving requirements. This rigidity complicates the deployment of multi-modal AI applications or the implementation of continuous learning capabilities in IoT environments.
Power constraints represent another critical limitation. Embedded IoT devices typically operate on limited power sources such as batteries or energy harvesting mechanisms. Complex AI workloads demand substantial computational resources, creating a challenging trade-off between AI capability and power efficiency. This constraint often forces developers to implement simplified AI models that sacrifice accuracy and functionality.
Memory capacity restrictions further complicate embedded AI deployment. Advanced neural networks and machine learning models require significant memory resources for both model storage and runtime operations. Most embedded systems offer limited on-device memory, restricting the complexity and size of deployable AI models. This limitation becomes particularly evident when implementing deep learning models that require substantial parameter storage.
Processing speed limitations also impede real-time AI applications in IoT environments. Many IoT use cases demand immediate responses to environmental changes or user inputs, yet embedded processors often lack the computational power to execute complex AI algorithms with acceptable latency. This limitation becomes particularly problematic in time-sensitive applications like industrial control systems or autonomous vehicles.
Thermal management presents additional challenges. Intensive computational tasks generate heat that must be dissipated effectively to prevent performance degradation and hardware damage. Many IoT form factors lack adequate cooling mechanisms, forcing systems to throttle performance or implement duty cycling, which further impacts AI workload execution efficiency.
Flexibility and adaptability constraints also exist in current embedded AI systems. Traditional hardware architectures are often optimized for specific workloads, limiting their ability to efficiently handle diverse AI tasks or adapt to evolving requirements. This rigidity complicates the deployment of multi-modal AI applications or the implementation of continuous learning capabilities in IoT environments.
Current IMC Architectures for IoT Workloads
01 Memory management optimization techniques
Various memory management techniques can be employed to enhance in-memory computing performance. These include efficient memory allocation, garbage collection optimization, and memory pooling strategies. By implementing advanced memory management algorithms, systems can reduce memory fragmentation, minimize overhead, and improve overall resource utilization. These optimizations help maintain high performance even under heavy computational loads by ensuring efficient use of available memory resources.- Memory Management Optimization: Efficient memory management techniques are crucial for enhancing in-memory computing performance. These include dynamic memory allocation, memory pooling, and garbage collection optimization. By implementing intelligent memory management algorithms, systems can reduce memory fragmentation, optimize cache utilization, and ensure efficient use of available memory resources, resulting in significant performance improvements for in-memory computing applications.
- Parallel Processing Architectures: Leveraging parallel processing architectures can substantially improve in-memory computing performance. This involves distributing computational tasks across multiple processing units that operate simultaneously on in-memory data. Techniques include multi-threading, vector processing, and SIMD (Single Instruction, Multiple Data) operations. These approaches maximize throughput by utilizing available hardware resources efficiently and reducing processing bottlenecks.
- Power Management Techniques: Advanced power management techniques are essential for optimizing in-memory computing performance while maintaining energy efficiency. These include dynamic voltage and frequency scaling, selective power-down of unused memory regions, and thermal management strategies. By intelligently managing power consumption, systems can achieve higher performance levels without excessive energy use or thermal issues, which is particularly important for large-scale in-memory computing deployments.
- Data Compression and Encoding: Implementing data compression and encoding techniques can significantly enhance in-memory computing performance. By reducing the memory footprint of stored data, these methods allow more information to be kept in memory, reducing costly disk I/O operations. Advanced compression algorithms specifically designed for in-memory systems can achieve high compression ratios while maintaining fast decompression speeds, enabling quicker data access and processing.
- Distributed In-Memory Computing: Distributed in-memory computing architectures distribute data and processing across multiple nodes in a network, enabling horizontal scalability and improved performance. These systems employ sophisticated data partitioning, replication, and synchronization mechanisms to maintain data consistency while maximizing throughput. By distributing the computational load and memory requirements across multiple machines, these architectures can handle larger datasets and more complex computations than single-node solutions.
02 Parallel processing and workload distribution
In-memory computing performance can be significantly enhanced through parallel processing techniques and intelligent workload distribution. By dividing computational tasks across multiple processing units and optimizing task scheduling, systems can achieve higher throughput and reduced latency. These approaches include multi-threading, task partitioning, and load balancing mechanisms that efficiently utilize available computing resources while minimizing bottlenecks in data processing pipelines.Expand Specific Solutions03 Data structure and algorithm optimization
Optimizing data structures and algorithms specifically for in-memory computing environments can substantially improve performance. This includes designing cache-friendly data layouts, implementing efficient indexing mechanisms, and utilizing specialized algorithms that minimize memory access patterns. By reducing memory access latency and improving data locality, these optimizations enable faster data processing and analysis, particularly for large-scale data operations common in in-memory computing applications.Expand Specific Solutions04 Hardware acceleration and specialized architectures
Leveraging specialized hardware and architectural designs can dramatically enhance in-memory computing performance. This includes utilizing GPUs, FPGAs, and custom ASICs for specific computational tasks, as well as implementing hardware-level optimizations for memory access. These approaches can significantly reduce processing time for data-intensive operations by exploiting hardware-specific features and parallelism capabilities, resulting in orders of magnitude performance improvements for suitable workloads.Expand Specific Solutions05 Power management and thermal optimization
Effective power management and thermal optimization strategies are crucial for sustaining high performance in in-memory computing systems. These include dynamic voltage and frequency scaling, intelligent power state management, and thermal-aware task scheduling. By optimizing energy consumption while maintaining processing capabilities, these techniques help prevent thermal throttling and ensure consistent performance, particularly in dense computing environments where heat dissipation is a significant challenge.Expand Specific Solutions
Key Industry Players in IMC and IoT AI
In-Memory Computing for IoT AI workloads is evolving rapidly, currently transitioning from early adoption to growth phase with an expanding market projected to reach significant scale as edge AI applications proliferate. The technology maturity varies across key players, with semiconductor leaders like Intel, Samsung, TSMC, and NXP driving hardware innovations while software integration advances through companies like IBM and SAP. Specialized memory solutions from Macronix and Infineon address power-performance challenges unique to embedded systems. Research institutions including Fuzhou University and Institute of Microelectronics of Chinese Academy of Sciences are accelerating innovation through novel architectures. The competitive landscape features both established semiconductor giants and emerging specialized players focusing on optimizing memory-compute integration for resource-constrained IoT environments.
Infineon Technologies AG
Technical Solution: Infineon has developed specialized in-memory computing solutions for IoT applications through their AURIX and PSoC microcontroller families. Their approach integrates flash memory with dedicated hardware accelerators to enable efficient AI processing directly where data is stored. Infineon's XENSIV sensor solutions incorporate in-memory computing elements that perform preliminary data processing and feature extraction before transmitting results to the main system, significantly reducing power consumption in always-on IoT applications. Their OPTIGA Trust security solutions implement secure in-memory processing for sensitive AI operations, ensuring data privacy while maintaining computational efficiency. Infineon's memory-centric architecture for embedded AI workloads achieves up to 60% power reduction compared to traditional compute architectures by minimizing data movement between storage and processing units. Their development platform includes specialized tools for optimizing neural network models to leverage these in-memory computing capabilities, allowing developers to balance inference accuracy with memory constraints for specific IoT applications. Infineon's solutions are particularly focused on industrial IoT applications where reliability and long-term operation in harsh environments are critical requirements alongside AI processing capabilities.
Strengths: Industry-leading security features integrated directly into memory-compute architecture; exceptional reliability and quality standards suitable for mission-critical applications; strong focus on low-power operation for battery-powered IoT devices. Weaknesses: Less raw AI performance than solutions from companies focused primarily on high-performance computing; more limited software ecosystem compared to larger competitors; solutions optimized more for industrial than consumer applications.
Intel Corp.
Technical Solution: Intel has developed comprehensive in-memory computing solutions specifically for IoT edge devices through their Intel Movidius Neural Compute Stick and Intel Distribution of OpenVINO toolkit. Their approach integrates memory and processing units to minimize data movement, significantly reducing latency for AI workloads. Intel's Loihi neuromorphic chip represents their advanced research in this area, mimicking brain functions with in-memory computing principles to achieve 1000x better energy efficiency for certain AI tasks compared to conventional architectures. Their Optane DC persistent memory technology bridges the gap between DRAM and storage, providing high-capacity memory that maintains data even when powered off - crucial for IoT deployments with intermittent connectivity. Intel's solutions typically implement model compression techniques that allow complex AI models to run efficiently within the memory constraints of embedded devices while maintaining inference accuracy above 95% for most computer vision tasks.
Strengths: Comprehensive ecosystem of hardware and software tools specifically optimized for edge AI; mature development platform with extensive documentation and support; strong integration with existing enterprise systems. Weaknesses: Higher power consumption compared to some ARM-based competitors; solutions can be more expensive than alternatives from emerging players; some proprietary aspects limit flexibility for highly customized implementations.
Core IMC Technologies for Embedded Systems
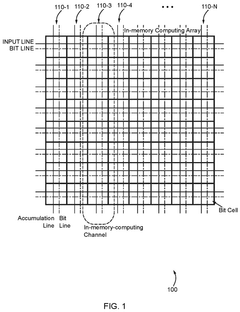
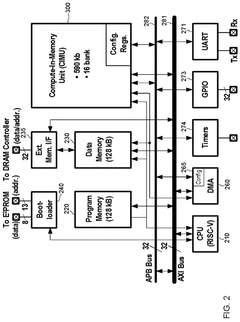
Configurable in memory computing engine, platform, bit cells and layouts therefore
PatentPendingUS20240330178A1
Innovation
- An in-memory computing architecture that includes a reshaping buffer, a compute-in-memory array, analog-to-digital converter circuitry, and control circuitry to perform multi-bit computing operations using single-bit internal circuits, enabling bit-parallel/bit-serial operations and near-memory computing to efficiently process multi-bit matrix and vector elements.
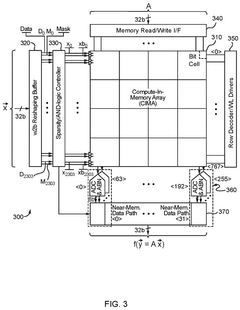
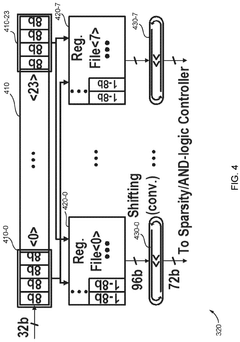
Embedded matrix-vector multiplication exploiting passive gain via mosfet capacitor for machine learning application
PatentWO2022232055A1
Innovation
- A charge-domain in-memory architecture using MOS capacitor-based digital-to-analog converters provides passive gain and supports multi-bit computations, enabling positive/negative/zero operands for Matrix-Vector Multiplication with a linear search ADC topology to enhance precision and reduce implementation costs.




Power Efficiency Considerations for IoT Devices
Power efficiency stands as a critical factor in the implementation of in-memory computing for IoT AI workloads. IoT devices typically operate under strict power constraints, often relying on batteries or energy harvesting mechanisms with limited capacity. The integration of in-memory computing architectures significantly reduces power consumption by minimizing data movement between memory and processing units, which traditionally accounts for up to 90% of energy usage in conventional computing systems.
When evaluating in-memory computing solutions for IoT applications, several power efficiency metrics must be considered. The energy per operation (measured in picojoules) provides a fundamental benchmark, with leading in-memory computing implementations achieving sub-picojoule performance for basic operations. Standby power consumption is equally important, as IoT devices spend considerable time in idle states between active processing periods.
The choice of memory technology substantially impacts power profiles. Resistive RAM (ReRAM) and Magnetoresistive RAM (MRAM) demonstrate promising characteristics for in-memory computing in IoT contexts, offering non-volatility that eliminates standby power requirements for data retention. However, these technologies present different trade-offs in terms of write energy, endurance, and integration complexity.
Dynamic power management strategies play a crucial role in optimizing energy efficiency. Techniques such as voltage scaling, power gating, and adaptive precision computing can be implemented alongside in-memory architectures to further reduce energy consumption. For instance, precision scaling allows the system to dynamically adjust computational accuracy based on application requirements, potentially reducing power consumption by 30-60% during less demanding tasks.
Thermal considerations cannot be overlooked, particularly for edge IoT devices deployed in harsh environments. In-memory computing generates less heat compared to traditional architectures due to reduced data movement, but thermal management remains essential for ensuring reliable operation and preventing performance degradation in compact IoT form factors.
Recent advancements in ultra-low-power in-memory computing have demonstrated remarkable efficiency improvements. Research from MIT and Stanford has shown prototype systems capable of performing inference tasks at microwatt power levels, representing orders of magnitude improvement over conventional approaches. These developments make previously impractical AI capabilities viable for severely power-constrained IoT applications such as implantable medical devices and environmental sensors with multi-year deployment requirements.
The power efficiency advantages of in-memory computing must be balanced against other system requirements including computational throughput, memory capacity, and cost considerations. The optimal solution varies significantly based on specific IoT application domains and deployment scenarios.
When evaluating in-memory computing solutions for IoT applications, several power efficiency metrics must be considered. The energy per operation (measured in picojoules) provides a fundamental benchmark, with leading in-memory computing implementations achieving sub-picojoule performance for basic operations. Standby power consumption is equally important, as IoT devices spend considerable time in idle states between active processing periods.
The choice of memory technology substantially impacts power profiles. Resistive RAM (ReRAM) and Magnetoresistive RAM (MRAM) demonstrate promising characteristics for in-memory computing in IoT contexts, offering non-volatility that eliminates standby power requirements for data retention. However, these technologies present different trade-offs in terms of write energy, endurance, and integration complexity.
Dynamic power management strategies play a crucial role in optimizing energy efficiency. Techniques such as voltage scaling, power gating, and adaptive precision computing can be implemented alongside in-memory architectures to further reduce energy consumption. For instance, precision scaling allows the system to dynamically adjust computational accuracy based on application requirements, potentially reducing power consumption by 30-60% during less demanding tasks.
Thermal considerations cannot be overlooked, particularly for edge IoT devices deployed in harsh environments. In-memory computing generates less heat compared to traditional architectures due to reduced data movement, but thermal management remains essential for ensuring reliable operation and preventing performance degradation in compact IoT form factors.
Recent advancements in ultra-low-power in-memory computing have demonstrated remarkable efficiency improvements. Research from MIT and Stanford has shown prototype systems capable of performing inference tasks at microwatt power levels, representing orders of magnitude improvement over conventional approaches. These developments make previously impractical AI capabilities viable for severely power-constrained IoT applications such as implantable medical devices and environmental sensors with multi-year deployment requirements.
The power efficiency advantages of in-memory computing must be balanced against other system requirements including computational throughput, memory capacity, and cost considerations. The optimal solution varies significantly based on specific IoT application domains and deployment scenarios.
Security Implications of In-Memory AI Processing
In-memory computing architectures fundamentally alter the security landscape for IoT AI workloads by eliminating traditional data movement between storage and processing units. This architectural shift creates both unique security advantages and novel vulnerabilities that must be carefully considered in embedded system design.
The proximity of processing and data in memory computing creates an inherent security advantage by reducing the attack surface associated with data in transit. Traditional computing architectures expose data to potential interception during transfers between memory and processing units, whereas in-memory computing significantly minimizes this vulnerability window. This is particularly valuable for sensitive IoT applications in healthcare, industrial control systems, and smart infrastructure where data confidentiality is paramount.
However, in-memory AI processing introduces new security challenges. The concentration of both data and processing in a single component creates a potential single point of failure. If compromised, attackers gain simultaneous access to both the AI algorithms and the data they process. This risk is amplified in resource-constrained IoT devices that may lack robust security features found in larger systems.
Side-channel attacks represent a significant threat to in-memory AI processing. The close coupling of memory and computation can leak information through power consumption patterns, electromagnetic emissions, and timing variations. These physical signals may reveal sensitive information about the AI models or the data being processed, potentially exposing proprietary algorithms or personal information without directly breaching digital security measures.
Memory integrity becomes a critical security concern as in-memory computing systems must ensure that data cannot be maliciously altered during processing. The dynamic nature of memory contents during AI workload execution creates challenges for implementing traditional integrity verification mechanisms without introducing performance penalties that would negate the speed advantages of in-memory processing.
Secure boot and runtime attestation mechanisms must be adapted for in-memory computing architectures to verify that only authorized AI models and firmware are executed. This is particularly challenging in IoT environments where devices may operate for extended periods without supervision and must maintain security integrity throughout their operational lifecycle.
Encryption strategies for in-memory computing present unique challenges, as encrypting data within active processing memory can introduce significant performance overhead. Researchers are exploring specialized hardware-based encryption techniques that can secure data while maintaining the performance benefits of in-memory processing, including homomorphic encryption approaches that allow computation on encrypted data without decryption.
The proximity of processing and data in memory computing creates an inherent security advantage by reducing the attack surface associated with data in transit. Traditional computing architectures expose data to potential interception during transfers between memory and processing units, whereas in-memory computing significantly minimizes this vulnerability window. This is particularly valuable for sensitive IoT applications in healthcare, industrial control systems, and smart infrastructure where data confidentiality is paramount.
However, in-memory AI processing introduces new security challenges. The concentration of both data and processing in a single component creates a potential single point of failure. If compromised, attackers gain simultaneous access to both the AI algorithms and the data they process. This risk is amplified in resource-constrained IoT devices that may lack robust security features found in larger systems.
Side-channel attacks represent a significant threat to in-memory AI processing. The close coupling of memory and computation can leak information through power consumption patterns, electromagnetic emissions, and timing variations. These physical signals may reveal sensitive information about the AI models or the data being processed, potentially exposing proprietary algorithms or personal information without directly breaching digital security measures.
Memory integrity becomes a critical security concern as in-memory computing systems must ensure that data cannot be maliciously altered during processing. The dynamic nature of memory contents during AI workload execution creates challenges for implementing traditional integrity verification mechanisms without introducing performance penalties that would negate the speed advantages of in-memory processing.
Secure boot and runtime attestation mechanisms must be adapted for in-memory computing architectures to verify that only authorized AI models and firmware are executed. This is particularly challenging in IoT environments where devices may operate for extended periods without supervision and must maintain security integrity throughout their operational lifecycle.
Encryption strategies for in-memory computing present unique challenges, as encrypting data within active processing memory can introduce significant performance overhead. Researchers are exploring specialized hardware-based encryption techniques that can secure data while maintaining the performance benefits of in-memory processing, including homomorphic encryption approaches that allow computation on encrypted data without decryption.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!