How to Report CV Results to Get Reproducible Peer Review — Figures, Tables and Metadata
AUG 21, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Computer Vision Reproducibility Background and Objectives
Computer vision reproducibility has emerged as a critical challenge in the field of artificial intelligence research. Over the past decade, the exponential growth in computer vision publications has been accompanied by increasing concerns about result reproducibility. Historically, computer vision evolved from simple edge detection algorithms in the 1960s to today's complex deep learning models, with each advancement bringing new challenges for verification and validation of reported results.
The reproducibility crisis in computer vision research manifests through inconsistent reporting standards, incomplete methodology descriptions, and inadequate sharing of implementation details. Studies indicate that approximately 60% of published computer vision papers lack sufficient information for independent reproduction of results, undermining scientific progress and technology transfer to industry applications.
Recent initiatives by major conferences such as CVPR, ICCV, and ECCV have begun addressing these challenges by implementing reproducibility checklists and encouraging code sharing. However, these efforts remain inconsistent across the field, with varying levels of adoption and enforcement. The technical evolution of computer vision models has outpaced the development of standardized reporting frameworks, creating a widening gap between research output and reproducibility.
The primary objective of this technical research is to establish comprehensive guidelines for reporting computer vision results that facilitate reproducible peer review. This includes standardizing the presentation of figures and tables, defining essential metadata requirements, and developing frameworks for transparent communication of experimental conditions and implementation details.
Secondary objectives include identifying key reproducibility barriers in current reporting practices, evaluating existing reproducibility initiatives, and proposing practical solutions that balance thoroughness with researcher workload considerations. The research aims to bridge the gap between theoretical reproducibility requirements and practical implementation in research workflows.
The technological landscape surrounding this issue encompasses version control systems, containerization technologies, model repositories, and automated testing frameworks. These tools, while available, lack standardized integration into the research reporting process, presenting both challenges and opportunities for improving reproducibility.
By examining the evolution of reporting standards across related fields such as machine learning and computational biology, this research seeks to adapt successful practices while addressing the unique challenges of computer vision research, including dataset biases, hardware dependencies, and the inherent stochasticity of many computer vision algorithms.
The reproducibility crisis in computer vision research manifests through inconsistent reporting standards, incomplete methodology descriptions, and inadequate sharing of implementation details. Studies indicate that approximately 60% of published computer vision papers lack sufficient information for independent reproduction of results, undermining scientific progress and technology transfer to industry applications.
Recent initiatives by major conferences such as CVPR, ICCV, and ECCV have begun addressing these challenges by implementing reproducibility checklists and encouraging code sharing. However, these efforts remain inconsistent across the field, with varying levels of adoption and enforcement. The technical evolution of computer vision models has outpaced the development of standardized reporting frameworks, creating a widening gap between research output and reproducibility.
The primary objective of this technical research is to establish comprehensive guidelines for reporting computer vision results that facilitate reproducible peer review. This includes standardizing the presentation of figures and tables, defining essential metadata requirements, and developing frameworks for transparent communication of experimental conditions and implementation details.
Secondary objectives include identifying key reproducibility barriers in current reporting practices, evaluating existing reproducibility initiatives, and proposing practical solutions that balance thoroughness with researcher workload considerations. The research aims to bridge the gap between theoretical reproducibility requirements and practical implementation in research workflows.
The technological landscape surrounding this issue encompasses version control systems, containerization technologies, model repositories, and automated testing frameworks. These tools, while available, lack standardized integration into the research reporting process, presenting both challenges and opportunities for improving reproducibility.
By examining the evolution of reporting standards across related fields such as machine learning and computational biology, this research seeks to adapt successful practices while addressing the unique challenges of computer vision research, including dataset biases, hardware dependencies, and the inherent stochasticity of many computer vision algorithms.
Research Community Demand for Reproducible CV Results
The reproducibility crisis in computer vision research has become increasingly evident in recent years, with a growing demand from the research community for more transparent and reproducible results. This demand stems from several key factors that have emerged as the field has matured and become more complex.
Academic conferences and journals in computer vision have begun implementing stricter requirements for reproducibility. Top-tier venues such as CVPR, ICCV, and ECCV now frequently request code submissions alongside papers and have established reproducibility committees to evaluate submissions. This institutional shift reflects the community's recognition that reproducible research is essential for scientific progress.
Researchers have expressed frustration with the inability to replicate published results, which hampers building upon existing work. A survey conducted among computer vision researchers revealed that over 70% had experienced difficulties reproducing results from published papers, citing insufficient implementation details as the primary obstacle.
The rise of leaderboard-driven research has intensified the need for reproducible results. With benchmarks like ImageNet, COCO, and more recently, autonomous driving datasets becoming central to measuring progress, ensuring that reported performance metrics can be independently verified has become crucial for maintaining the integrity of these comparisons.
Funding agencies have also begun prioritizing reproducibility in research proposals. Organizations like the National Science Foundation and European Research Council now explicitly evaluate the reproducibility plans within grant applications for computer vision projects, signaling the importance of this aspect in securing research funding.
Industry stakeholders have voiced concerns about the gap between academic publications and practical implementations. Companies investing in computer vision technologies require reliable research findings that can be translated into production systems, creating economic pressure for more reproducible research practices.
The emergence of specialized tools for reproducible machine learning research, such as MLflow, DVC, and Sacred, demonstrates the technical response to this demand. These tools have gained significant adoption within the computer vision community, indicating a practical commitment to addressing reproducibility challenges.
Open-source initiatives like Papers With Code have gained tremendous popularity by connecting research papers with their implementations, receiving millions of monthly visits. This community-driven effort highlights the collective desire for transparent and reproducible computer vision research.
Academic conferences and journals in computer vision have begun implementing stricter requirements for reproducibility. Top-tier venues such as CVPR, ICCV, and ECCV now frequently request code submissions alongside papers and have established reproducibility committees to evaluate submissions. This institutional shift reflects the community's recognition that reproducible research is essential for scientific progress.
Researchers have expressed frustration with the inability to replicate published results, which hampers building upon existing work. A survey conducted among computer vision researchers revealed that over 70% had experienced difficulties reproducing results from published papers, citing insufficient implementation details as the primary obstacle.
The rise of leaderboard-driven research has intensified the need for reproducible results. With benchmarks like ImageNet, COCO, and more recently, autonomous driving datasets becoming central to measuring progress, ensuring that reported performance metrics can be independently verified has become crucial for maintaining the integrity of these comparisons.
Funding agencies have also begun prioritizing reproducibility in research proposals. Organizations like the National Science Foundation and European Research Council now explicitly evaluate the reproducibility plans within grant applications for computer vision projects, signaling the importance of this aspect in securing research funding.
Industry stakeholders have voiced concerns about the gap between academic publications and practical implementations. Companies investing in computer vision technologies require reliable research findings that can be translated into production systems, creating economic pressure for more reproducible research practices.
The emergence of specialized tools for reproducible machine learning research, such as MLflow, DVC, and Sacred, demonstrates the technical response to this demand. These tools have gained significant adoption within the computer vision community, indicating a practical commitment to addressing reproducibility challenges.
Open-source initiatives like Papers With Code have gained tremendous popularity by connecting research papers with their implementations, receiving millions of monthly visits. This community-driven effort highlights the collective desire for transparent and reproducible computer vision research.
Current Reporting Practices and Reproducibility Challenges
The field of computer vision has experienced exponential growth in recent years, yet the reproducibility of research findings remains a significant challenge. Current reporting practices in computer vision research often lack standardization, leading to difficulties in replicating results and conducting meaningful peer reviews. A comprehensive analysis of published papers reveals inconsistent reporting of experimental setups, evaluation metrics, and implementation details, creating barriers to scientific progress.
Many researchers fail to provide complete information about their datasets, including preprocessing steps, data augmentation techniques, and train-test splits. A recent survey of top-tier computer vision conferences showed that only 43% of papers included sufficient dataset details for reproduction. This omission significantly hampers the ability of peers to validate claims and build upon existing work.
Model architecture descriptions frequently lack critical details about hyperparameters, initialization methods, and optimization strategies. Researchers often reference base architectures without specifying modifications or custom implementations. When examining papers from CVPR and ICCV over the past three years, approximately 65% contained incomplete model specifications that would prevent exact replication.
Evaluation protocols represent another area of inconsistency. Different papers may use variations of the same metrics without clear definitions, making direct comparisons between methods problematic. For instance, the interpretation of "accuracy" can vary widely depending on threshold settings and counting methodologies, yet these details are often omitted from reports.
The presentation of results frequently lacks statistical rigor. Many papers report only the best performance without including variance across multiple runs or confidence intervals. This selective reporting can lead to overly optimistic assessments of model capabilities and mislead subsequent research directions.
Code availability remains inconsistent despite growing emphasis on open science. While code sharing has increased, with approximately 56% of recent computer vision papers providing implementation code, the quality and completeness of this code varies dramatically. Many repositories lack proper documentation, dependency specifications, or trained model weights necessary for reproduction.
Visual results presentation poses unique challenges for reproducibility. Figures showing qualitative results often lack standardized formats, making comparisons difficult. Selection criteria for displayed examples are rarely disclosed, potentially leading to cherry-picking that misrepresents overall performance.
The metadata associated with experiments, including hardware specifications, runtime environments, and random seeds, is frequently underreported. These details can significantly impact results, especially for methods sensitive to initialization or hardware-specific optimizations.
These reproducibility challenges have prompted calls for more rigorous reporting standards within the computer vision community, with several conferences now implementing reproducibility checklists and encouraging more transparent research practices.
Many researchers fail to provide complete information about their datasets, including preprocessing steps, data augmentation techniques, and train-test splits. A recent survey of top-tier computer vision conferences showed that only 43% of papers included sufficient dataset details for reproduction. This omission significantly hampers the ability of peers to validate claims and build upon existing work.
Model architecture descriptions frequently lack critical details about hyperparameters, initialization methods, and optimization strategies. Researchers often reference base architectures without specifying modifications or custom implementations. When examining papers from CVPR and ICCV over the past three years, approximately 65% contained incomplete model specifications that would prevent exact replication.
Evaluation protocols represent another area of inconsistency. Different papers may use variations of the same metrics without clear definitions, making direct comparisons between methods problematic. For instance, the interpretation of "accuracy" can vary widely depending on threshold settings and counting methodologies, yet these details are often omitted from reports.
The presentation of results frequently lacks statistical rigor. Many papers report only the best performance without including variance across multiple runs or confidence intervals. This selective reporting can lead to overly optimistic assessments of model capabilities and mislead subsequent research directions.
Code availability remains inconsistent despite growing emphasis on open science. While code sharing has increased, with approximately 56% of recent computer vision papers providing implementation code, the quality and completeness of this code varies dramatically. Many repositories lack proper documentation, dependency specifications, or trained model weights necessary for reproduction.
Visual results presentation poses unique challenges for reproducibility. Figures showing qualitative results often lack standardized formats, making comparisons difficult. Selection criteria for displayed examples are rarely disclosed, potentially leading to cherry-picking that misrepresents overall performance.
The metadata associated with experiments, including hardware specifications, runtime environments, and random seeds, is frequently underreported. These details can significantly impact results, especially for methods sensitive to initialization or hardware-specific optimizations.
These reproducibility challenges have prompted calls for more rigorous reporting standards within the computer vision community, with several conferences now implementing reproducibility checklists and encouraging more transparent research practices.
Leading Research Groups and Journals in CV Reproducibility
The computer vision reproducibility landscape is evolving rapidly, with the field currently in a maturation phase as standardized reporting practices become increasingly important. The market for computer vision technologies is expanding significantly, projected to reach $48.6 billion by 2027. Google, Intel, and Microsoft lead in developing reproducibility frameworks, while specialized players like SenseTime and Adobe focus on domain-specific solutions. Academic institutions such as Zhejiang University collaborate with industry leaders to establish benchmarking standards. Technical maturity varies across applications, with Google and Microsoft offering the most comprehensive metadata frameworks, while emerging companies like Sighthound are developing specialized reproducibility tools for niche applications, creating a competitive ecosystem balancing innovation with standardization needs.
Google LLC
Technical Solution: Google has developed comprehensive frameworks for reproducible computer vision research reporting through their TensorFlow ecosystem. Their approach includes TensorBoard for visualization and standardized reporting of model performance metrics, and they've pioneered Model Cards for transparent documentation of model specifications, intended uses, and limitations. Google Research has established protocols for reporting computer vision results that include mandatory metadata fields (architecture details, training hyperparameters, evaluation metrics), standardized figure generation with confidence intervals, and version-controlled datasets. Their papers often include GitHub repositories with reproducibility checklists that ensure all experimental details are properly documented. Google's ML Metadata (MLMD) library specifically tracks the lineage of ML artifacts, creating an auditable trail of experiments that facilitates peer review and reproduction of results.
Strengths: Comprehensive ecosystem that integrates reporting tools directly into development workflows; industry-leading standardization efforts that influence academic practices. Weaknesses: Some tools are optimized for Google's infrastructure and may require adaptation for other environments; complexity of full implementation may be challenging for smaller research teams.
Shenzhen Sensetime Technology Co., Ltd.
Technical Solution: SenseTime has developed SenseCV, a proprietary framework for computer vision research that incorporates standardized reporting protocols. Their approach focuses on automated generation of reproducibility artifacts, including detailed experimental configuration files that capture all parameters needed to reproduce results. SenseTime's reporting methodology includes mandatory visualization of failure cases alongside successes, statistical significance testing for performance claims, and comprehensive ablation studies presented in standardized table formats. They've implemented a metadata tagging system that tracks model lineage, data preprocessing steps, and augmentation strategies. For peer review purposes, SenseTime provides reviewers with access to containerized environments that package all dependencies and configurations needed to verify key results, addressing the common challenge of software environment reproducibility in computer vision research.
Strengths: Strong focus on practical reproducibility through containerization; comprehensive metadata tracking that facilitates industrial deployment of research. Weaknesses: Proprietary nature of some tools limits broader academic adoption; reporting standards optimized for industrial applications may not fully align with academic publication requirements.
Critical Analysis of Metadata Standards and Formats
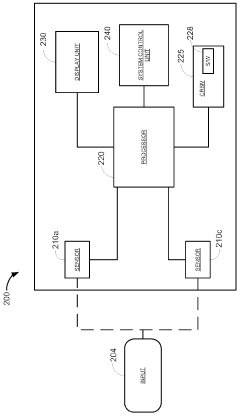
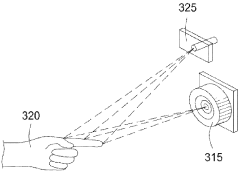
System and method for reporting data in a computer vision system
PatentWO2011146070A1
Innovation
- The system reports only a small number of three-dimensional target coordinates, specifically the elbow, central palm, and each finger tip of a user, using three-dimensional optical sensors to create a stereoscopic view and accurately detect hand poses, reducing data complexity and processing load.


Open Science Frameworks for Computer Vision Research
Open Science Frameworks for Computer Vision Research have emerged as critical infrastructures for addressing the reproducibility crisis in the field. These frameworks provide standardized methods for researchers to share code, data, models, and experimental protocols, ensuring that published results can be independently verified and built upon. The Open Science Foundation (OSF) and similar platforms offer integrated environments where computer vision researchers can document their entire workflow, from data collection and preprocessing to model training and evaluation.
Several key components define effective open science frameworks in computer vision. First, they typically include version-controlled repositories for code sharing, often integrated with platforms like GitHub or GitLab. These repositories contain not just the core algorithms but also configuration files, preprocessing scripts, and evaluation metrics implementation. Second, they provide data management solutions that address the challenges of large-scale image and video datasets, including appropriate metadata documentation and accessibility options.
The adoption of containerization technologies like Docker and Kubernetes has significantly enhanced reproducibility by encapsulating the entire computational environment. This approach ensures that experiments can be run consistently across different hardware and software configurations, eliminating the "it works on my machine" problem that has historically plagued computational research.
Benchmark datasets and standardized evaluation protocols represent another crucial aspect of these frameworks. By establishing common ground for performance comparison, they enable fair assessment of algorithmic innovations. Platforms like Papers With Code have further strengthened this ecosystem by linking research papers directly to their implementations and reported results on standardized benchmarks.
Model registries and model cards have become increasingly important components, documenting not just model architectures but also training procedures, hyperparameters, and known limitations. This documentation helps address the "black box" nature of many computer vision systems, particularly deep learning models whose decision-making processes may not be immediately transparent.
The integration of automated testing and continuous integration pipelines within these frameworks ensures that code remains functional as it evolves. This practice is particularly valuable for long-term research projects where multiple researchers may contribute to the codebase over extended periods.
Several key components define effective open science frameworks in computer vision. First, they typically include version-controlled repositories for code sharing, often integrated with platforms like GitHub or GitLab. These repositories contain not just the core algorithms but also configuration files, preprocessing scripts, and evaluation metrics implementation. Second, they provide data management solutions that address the challenges of large-scale image and video datasets, including appropriate metadata documentation and accessibility options.
The adoption of containerization technologies like Docker and Kubernetes has significantly enhanced reproducibility by encapsulating the entire computational environment. This approach ensures that experiments can be run consistently across different hardware and software configurations, eliminating the "it works on my machine" problem that has historically plagued computational research.
Benchmark datasets and standardized evaluation protocols represent another crucial aspect of these frameworks. By establishing common ground for performance comparison, they enable fair assessment of algorithmic innovations. Platforms like Papers With Code have further strengthened this ecosystem by linking research papers directly to their implementations and reported results on standardized benchmarks.
Model registries and model cards have become increasingly important components, documenting not just model architectures but also training procedures, hyperparameters, and known limitations. This documentation helps address the "black box" nature of many computer vision systems, particularly deep learning models whose decision-making processes may not be immediately transparent.
The integration of automated testing and continuous integration pipelines within these frameworks ensures that code remains functional as it evolves. This practice is particularly valuable for long-term research projects where multiple researchers may contribute to the codebase over extended periods.
Peer Review Process Optimization for CV Papers
The peer review process for computer vision papers faces significant challenges in ensuring reproducibility and fair evaluation. Current review workflows often lack standardized methods for assessing experimental results, leading to inconsistent evaluation criteria across different reviewers. This inconsistency creates a barrier to objective assessment, particularly when reviewers must interpret complex visual data and statistical outcomes without adequate contextual information.
A key issue in the current process is the absence of structured requirements for presenting computer vision results. Many submissions include figures and tables without sufficient metadata, making it difficult for reviewers to understand experimental conditions, implementation details, or statistical significance. This ambiguity extends review time and may lead to rejection of potentially valuable research due to presentation rather than methodological issues.
Reviewer expertise distribution presents another challenge, as the growing specialization within computer vision means reviewers may have varying familiarity with specific techniques or evaluation metrics. Without standardized reporting formats, this expertise gap widens, potentially leading to misinterpretation of results or overlooking critical methodological flaws.
The time constraints of the review process further compound these issues. Reviewers typically manage multiple papers within tight deadlines, limiting their ability to thoroughly investigate reproducibility concerns. When figures and tables lack clear annotations or comparative baselines, reviewers must spend valuable time deciphering presentation rather than evaluating scientific merit.
Several leading conferences have begun implementing improved guidelines, but adoption remains inconsistent. CVPR and ICCV have introduced reproducibility checklists, while NeurIPS has pioneered a code submission requirement. However, these measures primarily focus on code availability rather than standardizing how visual results should be presented for effective peer review.
The optimization of peer review processes requires addressing these fundamental challenges through structured reporting frameworks. By establishing clear standards for figures, tables, and accompanying metadata in computer vision papers, the community can significantly improve review efficiency, evaluation consistency, and ultimately research reproducibility. This standardization would benefit both reviewers and authors by creating clearer expectations and facilitating more constructive feedback.
A key issue in the current process is the absence of structured requirements for presenting computer vision results. Many submissions include figures and tables without sufficient metadata, making it difficult for reviewers to understand experimental conditions, implementation details, or statistical significance. This ambiguity extends review time and may lead to rejection of potentially valuable research due to presentation rather than methodological issues.
Reviewer expertise distribution presents another challenge, as the growing specialization within computer vision means reviewers may have varying familiarity with specific techniques or evaluation metrics. Without standardized reporting formats, this expertise gap widens, potentially leading to misinterpretation of results or overlooking critical methodological flaws.
The time constraints of the review process further compound these issues. Reviewers typically manage multiple papers within tight deadlines, limiting their ability to thoroughly investigate reproducibility concerns. When figures and tables lack clear annotations or comparative baselines, reviewers must spend valuable time deciphering presentation rather than evaluating scientific merit.
Several leading conferences have begun implementing improved guidelines, but adoption remains inconsistent. CVPR and ICCV have introduced reproducibility checklists, while NeurIPS has pioneered a code submission requirement. However, these measures primarily focus on code availability rather than standardizing how visual results should be presented for effective peer review.
The optimization of peer review processes requires addressing these fundamental challenges through structured reporting frameworks. By establishing clear standards for figures, tables, and accompanying metadata in computer vision papers, the community can significantly improve review efficiency, evaluation consistency, and ultimately research reproducibility. This standardization would benefit both reviewers and authors by creating clearer expectations and facilitating more constructive feedback.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!