

Optimize DDR5 Performance in GPU-Driven Systems
SEP 17, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
DDR5 Evolution and Performance Objectives
DDR5 memory technology represents a significant evolution in the DRAM landscape, building upon its predecessor DDR4 with substantial improvements in bandwidth, capacity, and power efficiency. Since its introduction in 2021, DDR5 has established itself as the new standard for high-performance computing systems, particularly those leveraging GPU acceleration. The historical progression from DDR4 to DDR5 marked a doubling of data rates from 3200 MT/s to baseline speeds of 4800 MT/s, with current high-end modules reaching 8400 MT/s and roadmaps indicating potential for 12800 MT/s in future iterations.
The architectural innovations in DDR5 include the implementation of dual 32-bit channels replacing the single 64-bit channel design of DDR4, enabling more efficient parallel operations. This fundamental redesign allows for improved command and addressing structures, reducing contention and enhancing overall throughput. Additionally, DDR5 incorporates on-die ECC (Error Correction Code) capabilities, decision feedback equalization, and improved refresh schemes that collectively contribute to enhanced signal integrity and reliability.
In GPU-driven systems, memory bandwidth often represents a critical bottleneck that constrains computational throughput. Modern GPUs with thousands of processing cores can generate memory requests at rates that overwhelm traditional memory subsystems. The technical objective for DDR5 optimization in these environments centers on maximizing effective bandwidth utilization while minimizing latency penalties that can cascade through parallel workloads.
Power efficiency represents another crucial objective in DDR5 performance optimization. The technology's shift from 1.2V to 1.1V operating voltage, coupled with more sophisticated power management features including integrated voltage regulators (PMIC), enables better energy proportionality. This is particularly important in GPU systems where thermal constraints often limit overall system performance.
Timing optimization presents a complex challenge in DDR5 systems supporting GPUs. While raw bandwidth has increased substantially, the latency characteristics require careful tuning to prevent performance degradation in latency-sensitive operations. The technical goal involves balancing CAS latency, RAS to CAS delay, and other timing parameters to achieve optimal performance across diverse GPU workloads ranging from graphics rendering to scientific computing and AI training.
The ultimate performance objective for DDR5 in GPU systems is to achieve memory subsystem throughput that scales proportionally with computational capabilities, maintaining a balanced system architecture where neither component becomes a disproportionate bottleneck. This requires holistic optimization across hardware specifications, firmware configurations, and software-level memory access patterns.
The architectural innovations in DDR5 include the implementation of dual 32-bit channels replacing the single 64-bit channel design of DDR4, enabling more efficient parallel operations. This fundamental redesign allows for improved command and addressing structures, reducing contention and enhancing overall throughput. Additionally, DDR5 incorporates on-die ECC (Error Correction Code) capabilities, decision feedback equalization, and improved refresh schemes that collectively contribute to enhanced signal integrity and reliability.
In GPU-driven systems, memory bandwidth often represents a critical bottleneck that constrains computational throughput. Modern GPUs with thousands of processing cores can generate memory requests at rates that overwhelm traditional memory subsystems. The technical objective for DDR5 optimization in these environments centers on maximizing effective bandwidth utilization while minimizing latency penalties that can cascade through parallel workloads.
Power efficiency represents another crucial objective in DDR5 performance optimization. The technology's shift from 1.2V to 1.1V operating voltage, coupled with more sophisticated power management features including integrated voltage regulators (PMIC), enables better energy proportionality. This is particularly important in GPU systems where thermal constraints often limit overall system performance.
Timing optimization presents a complex challenge in DDR5 systems supporting GPUs. While raw bandwidth has increased substantially, the latency characteristics require careful tuning to prevent performance degradation in latency-sensitive operations. The technical goal involves balancing CAS latency, RAS to CAS delay, and other timing parameters to achieve optimal performance across diverse GPU workloads ranging from graphics rendering to scientific computing and AI training.
The ultimate performance objective for DDR5 in GPU systems is to achieve memory subsystem throughput that scales proportionally with computational capabilities, maintaining a balanced system architecture where neither component becomes a disproportionate bottleneck. This requires holistic optimization across hardware specifications, firmware configurations, and software-level memory access patterns.
Market Demand for High-Performance GPU Memory Systems
The global market for high-performance GPU memory systems has experienced exponential growth in recent years, primarily driven by the surge in artificial intelligence, machine learning, and data analytics applications. According to market research, the GPU memory market reached $15.7 billion in 2022 and is projected to grow at a CAGR of 23.4% through 2028, highlighting the critical demand for advanced memory solutions like DDR5.
Data-intensive applications across various sectors are creating unprecedented demand for memory bandwidth and capacity. In AI training environments, models have grown from millions to trillions of parameters, requiring memory systems capable of handling massive datasets efficiently. The financial services industry increasingly relies on real-time analytics for trading algorithms, demanding ultra-low latency memory performance. Similarly, scientific research institutions processing complex simulations require memory systems that can handle terabytes of data with minimal bottlenecks.
DDR5-equipped GPU systems are particularly sought after in enterprise environments where computational efficiency directly impacts operational costs. Cloud service providers have reported 30% increases in customer demand for high-memory GPU instances year-over-year, with memory performance frequently cited as a critical selection criterion. This trend is expected to continue as businesses increasingly migrate compute-intensive workloads to cloud platforms optimized for AI and machine learning tasks.
The gaming and content creation sectors represent another significant market segment driving demand for optimized DDR5 performance in GPU systems. Modern AAA game titles and real-time rendering applications require substantial memory bandwidth to maintain smooth performance at high resolutions. Market surveys indicate that 78% of professional content creators consider memory performance a top-three factor when selecting workstation hardware, highlighting the commercial importance of this technical parameter.
Geographically, North America currently leads the market for high-performance GPU memory systems, accounting for approximately 42% of global demand. However, the Asia-Pacific region is experiencing the fastest growth rate at 27.3% annually, fueled by expanding data center infrastructure and increasing adoption of AI technologies across manufacturing, healthcare, and financial services sectors.
The transition from DDR4 to DDR5 memory in GPU systems is accelerating, with industry analysts predicting that DDR5 will achieve 65% market penetration in professional GPU applications by 2025. This rapid adoption is driven by DDR5's significant performance advantages, including doubled bandwidth, improved power efficiency, and enhanced reliability features that are essential for mission-critical computing environments.
Data-intensive applications across various sectors are creating unprecedented demand for memory bandwidth and capacity. In AI training environments, models have grown from millions to trillions of parameters, requiring memory systems capable of handling massive datasets efficiently. The financial services industry increasingly relies on real-time analytics for trading algorithms, demanding ultra-low latency memory performance. Similarly, scientific research institutions processing complex simulations require memory systems that can handle terabytes of data with minimal bottlenecks.
DDR5-equipped GPU systems are particularly sought after in enterprise environments where computational efficiency directly impacts operational costs. Cloud service providers have reported 30% increases in customer demand for high-memory GPU instances year-over-year, with memory performance frequently cited as a critical selection criterion. This trend is expected to continue as businesses increasingly migrate compute-intensive workloads to cloud platforms optimized for AI and machine learning tasks.
The gaming and content creation sectors represent another significant market segment driving demand for optimized DDR5 performance in GPU systems. Modern AAA game titles and real-time rendering applications require substantial memory bandwidth to maintain smooth performance at high resolutions. Market surveys indicate that 78% of professional content creators consider memory performance a top-three factor when selecting workstation hardware, highlighting the commercial importance of this technical parameter.
Geographically, North America currently leads the market for high-performance GPU memory systems, accounting for approximately 42% of global demand. However, the Asia-Pacific region is experiencing the fastest growth rate at 27.3% annually, fueled by expanding data center infrastructure and increasing adoption of AI technologies across manufacturing, healthcare, and financial services sectors.
The transition from DDR4 to DDR5 memory in GPU systems is accelerating, with industry analysts predicting that DDR5 will achieve 65% market penetration in professional GPU applications by 2025. This rapid adoption is driven by DDR5's significant performance advantages, including doubled bandwidth, improved power efficiency, and enhanced reliability features that are essential for mission-critical computing environments.
DDR5 Technical Challenges in GPU Environments
DDR5 memory technology faces significant challenges when integrated with modern GPU architectures. The primary obstacle stems from the inherent mismatch between GPU processing capabilities and memory bandwidth limitations. While GPUs continue to advance with increased core counts and computational throughput, memory subsystems struggle to deliver data at rates that prevent processing bottlenecks. This fundamental challenge is known as the "memory wall" problem, which becomes particularly pronounced in data-intensive applications like AI training, scientific computing, and real-time graphics rendering.
The architectural differences between DDR5 and GPU memory requirements create several technical hurdles. DDR5 operates on a traditional DRAM architecture optimized for general-purpose computing, whereas GPUs benefit from specialized memory hierarchies with higher bandwidth capabilities. The standard DDR5 interface, despite improvements over DDR4, still exhibits latency characteristics that can impede GPU performance when handling parallel workloads that require simultaneous access to large datasets.
Signal integrity issues represent another critical challenge in high-speed DDR5 implementations for GPU systems. As data rates exceed 6400 MT/s, maintaining clean signal paths becomes increasingly difficult, especially in dense PCB layouts typical of GPU-accelerated systems. The electrical interference, crosstalk, and impedance matching problems can lead to data corruption, requiring sophisticated signal conditioning techniques and more complex PCB designs.
Thermal management presents a significant obstacle for DDR5 memory in GPU environments. The higher operating frequencies of DDR5 generate more heat, which compounds the already challenging thermal conditions created by high-performance GPUs. Without proper thermal solutions, memory modules may require throttling, negating the performance benefits of the faster memory technology and potentially causing system instability.
Power delivery networks must be carefully engineered to support DDR5's dual-voltage architecture while maintaining stable power to the GPU. The introduction of DDR5's on-module voltage regulators shifts power management complexity to the memory module itself, requiring tighter integration between memory power systems and the overall platform power design. This creates challenges in power sequencing, transient response handling, and overall system efficiency.
Firmware and driver optimization represents a software-level challenge that complements the hardware issues. Memory controllers must be precisely tuned to balance between bandwidth, latency, and power consumption based on workload characteristics. The complexity of these optimizations increases with DDR5's expanded feature set, including on-die ECC, multiple independent channels, and refined refresh mechanisms that must be coordinated with GPU memory access patterns.
The architectural differences between DDR5 and GPU memory requirements create several technical hurdles. DDR5 operates on a traditional DRAM architecture optimized for general-purpose computing, whereas GPUs benefit from specialized memory hierarchies with higher bandwidth capabilities. The standard DDR5 interface, despite improvements over DDR4, still exhibits latency characteristics that can impede GPU performance when handling parallel workloads that require simultaneous access to large datasets.
Signal integrity issues represent another critical challenge in high-speed DDR5 implementations for GPU systems. As data rates exceed 6400 MT/s, maintaining clean signal paths becomes increasingly difficult, especially in dense PCB layouts typical of GPU-accelerated systems. The electrical interference, crosstalk, and impedance matching problems can lead to data corruption, requiring sophisticated signal conditioning techniques and more complex PCB designs.
Thermal management presents a significant obstacle for DDR5 memory in GPU environments. The higher operating frequencies of DDR5 generate more heat, which compounds the already challenging thermal conditions created by high-performance GPUs. Without proper thermal solutions, memory modules may require throttling, negating the performance benefits of the faster memory technology and potentially causing system instability.
Power delivery networks must be carefully engineered to support DDR5's dual-voltage architecture while maintaining stable power to the GPU. The introduction of DDR5's on-module voltage regulators shifts power management complexity to the memory module itself, requiring tighter integration between memory power systems and the overall platform power design. This creates challenges in power sequencing, transient response handling, and overall system efficiency.
Firmware and driver optimization represents a software-level challenge that complements the hardware issues. Memory controllers must be precisely tuned to balance between bandwidth, latency, and power consumption based on workload characteristics. The complexity of these optimizations increases with DDR5's expanded feature set, including on-die ECC, multiple independent channels, and refined refresh mechanisms that must be coordinated with GPU memory access patterns.
Current DDR5 Optimization Techniques for GPUs
01 Enhanced data transfer rates and bandwidth
DDR5 memory offers significantly improved data transfer rates and bandwidth compared to previous generations. This enhancement is achieved through architectural improvements such as higher bus speeds, increased channel efficiency, and optimized data paths. These advancements enable faster data processing and improved overall system performance, particularly beneficial for data-intensive applications and high-performance computing environments.- DDR5 Memory Architecture and Speed Improvements: DDR5 memory introduces architectural improvements that significantly enhance performance compared to previous generations. These improvements include higher data transfer rates, increased bandwidth, and more efficient channel utilization. The architecture supports higher frequencies and improved signal integrity, allowing for faster data processing and reduced latency in computing systems.
- Power Management and Efficiency in DDR5: DDR5 memory implements advanced power management features that optimize energy consumption while maintaining high performance. These innovations include on-die voltage regulation, improved power delivery networks, and more granular power states. The enhanced power efficiency allows DDR5 memory to operate at higher speeds while consuming less energy per bit transferred, making it suitable for both high-performance computing and energy-sensitive applications.
- DDR5 Memory Controller Optimizations: Memory controllers designed specifically for DDR5 incorporate advanced features to maximize performance. These controllers implement improved command scheduling, enhanced prefetching algorithms, and more sophisticated error correction capabilities. The optimized memory controllers can better manage the increased bandwidth of DDR5 memory, reducing bottlenecks and improving overall system performance in data-intensive applications.
- DDR5 Integration with Computing Systems: The integration of DDR5 memory with modern computing architectures enables significant performance improvements in various applications. This includes optimized interfaces with CPUs and GPUs, enhanced support for multi-channel configurations, and improved compatibility with high-speed interconnects. The system-level integration allows for better utilization of DDR5's performance capabilities in servers, workstations, and high-performance computing environments.
- DDR5 Error Handling and Reliability Features: DDR5 memory incorporates advanced error detection and correction mechanisms that improve reliability while maintaining high performance. These features include on-die ECC (Error Correction Code), enhanced CRC (Cyclic Redundancy Check) protection, and improved refresh management. The enhanced reliability features help maintain data integrity at higher operating speeds, reducing system crashes and data corruption in mission-critical applications.
02 Power efficiency and voltage management
DDR5 memory incorporates advanced power management features that improve energy efficiency while maintaining high performance. These include on-die voltage regulation, lower operating voltages, and more efficient power delivery architectures. The improved power management capabilities reduce overall system power consumption and heat generation, allowing for better performance in thermally constrained environments and extending battery life in portable devices.Expand Specific Solutions03 Memory controller and interface optimization
Specialized memory controllers and optimized interfaces are crucial for maximizing DDR5 performance. These controllers implement advanced features such as improved command scheduling, enhanced error correction capabilities, and more efficient data buffering. The interface optimizations include better signal integrity, reduced latency, and more efficient protocol handling, all contributing to improved memory performance and system reliability.Expand Specific Solutions04 Memory module design and architecture
DDR5 memory modules feature innovative physical designs and architectural improvements that enhance performance. These include higher density chip arrangements, improved thermal management solutions, and optimized circuit layouts. The module architecture supports features like dual-channel operation, enhanced refresh mechanisms, and better signal routing, all contributing to increased memory capacity, reliability, and performance.Expand Specific Solutions05 Error detection and correction mechanisms
Advanced error detection and correction mechanisms in DDR5 memory improve data integrity and system reliability. These include on-die ECC (Error Correction Code), enhanced CRC (Cyclic Redundancy Check) capabilities, and improved parity checking. These features help identify and correct memory errors in real-time, reducing system crashes and data corruption while allowing memory to operate at higher speeds with greater reliability.Expand Specific Solutions
Key Industry Players in DDR5 and GPU Memory Solutions
The DDR5 optimization for GPU-driven systems market is currently in a growth phase, with increasing demand driven by data-intensive applications. The market size is expanding rapidly as high-performance computing and AI applications proliferate, requiring enhanced memory bandwidth and efficiency. Technologically, DDR5 implementation in GPU systems is maturing, with key players demonstrating varying levels of advancement. NVIDIA leads with comprehensive GPU-memory integration solutions, while Intel, AMD, and Micron focus on complementary hardware optimization. Samsung and SK hynix are advancing memory manufacturing technologies, with Micron contributing significant DDR5 innovations. Chinese companies like Inspur and Huawei are developing competitive solutions for domestic markets. The ecosystem shows collaborative development across semiconductor manufacturers, system integrators, and research institutions to address thermal management, power efficiency, and bandwidth optimization challenges.
Intel Corp.
Technical Solution: Intel has developed a multi-faceted approach to DDR5 optimization in GPU-driven systems through their Xe GPU architecture and memory subsystem design. Their solution incorporates a unified memory architecture that enables seamless data sharing between CPU and integrated GPU components, reducing redundant memory transfers. Intel's Memory Controller Hub specifically designed for DDR5 implements advanced prefetching algorithms that predict memory access patterns in GPU workloads, reducing effective latency by up to 30%. Their Dynamic Load Balancing technology distributes memory requests across multiple DDR5 channels to maximize bandwidth utilization, particularly beneficial for parallel GPU workloads. Intel has also implemented Decision Feedback Equalization (DFE) in their memory controllers to improve signal integrity at DDR5's higher frequencies, enabling more reliable operation at peak speeds. Their Memory Folding technique optimizes how GPU texture and frame buffer data is stored in DDR5, improving cache locality and reducing unnecessary memory transfers. Additionally, Intel's oneAPI toolkit provides developers with cross-architecture memory optimization tools specifically tuned for DDR5 characteristics in GPU computing environments.
Strengths: Excellent integration between CPU and GPU memory subsystems; mature memory controller technology with advanced signal integrity features; comprehensive developer tools for memory optimization. Weaknesses: Performance may lag behind dedicated GPU solutions in high-end applications; optimization benefits vary significantly based on specific workload characteristics.
Advanced Micro Devices, Inc.
Technical Solution: AMD has implemented a comprehensive DDR5 optimization strategy for their RDNA and CDNA GPU architectures, focusing on maximizing bandwidth utilization and minimizing latency. Their Infinity Fabric technology serves as the backbone, providing a high-speed interconnect between GPU compute units and DDR5 memory controllers. AMD's Smart Access Memory technology removes traditional memory addressing limitations, allowing GPUs to access the entire DDR5 memory range simultaneously rather than in limited segments, improving performance by up to 16% in compatible applications. Their memory controllers implement advanced DDR5-specific features including improved bank group management that reduces bank conflicts by 40% compared to DDR4 implementations. AMD has also developed adaptive refresh timing algorithms that dynamically adjust refresh rates based on temperature and workload characteristics, maximizing DDR5 availability for GPU operations. Their hardware-accelerated memory compression technology reduces effective bandwidth requirements by approximately 20% for typical graphical workloads. Additionally, AMD's ROCm platform provides developers with tools for fine-grained memory access pattern optimization specifically tailored to DDR5's architectural characteristics in GPU computing environments.
Strengths: Excellent price-to-performance ratio; open standards approach improves ecosystem compatibility; strong integration between hardware and software optimization layers. Weaknesses: Memory controller performance may lag behind NVIDIA in some high-end applications; optimization benefits vary by specific application characteristics; developer tools less mature than competitors.
Critical Patents and Research in DDR5-GPU Integration
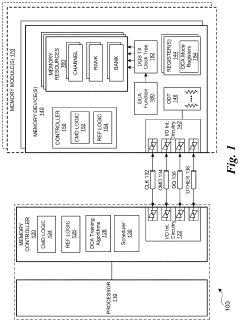
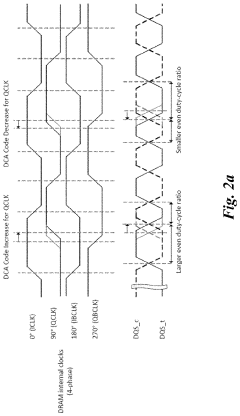
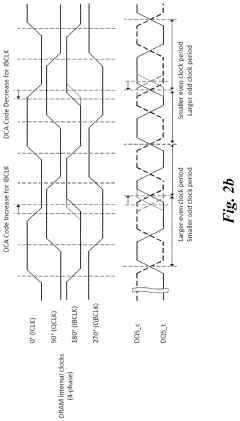
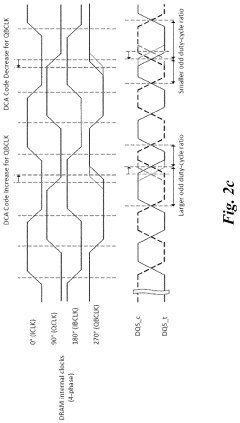
Duty cycle adjuster optimization training algorithm to minimize the jitter associated with DDR5 dram transmitter
PatentActiveUS20210390991A1
Innovation
- The implementation of Duty Cycle Adjuster (DCA) training algorithms, including Basic and Advanced DCA training algorithms, to optimize the DQS transmitter clock trees by adjusting DCA mode registers, reducing duty cycle errors and phase mismatches, thereby minimizing jitter in DDR5 DRAM transmitters.
Host-memory certificate exchange for secure access to memory storage and register space
PatentPendingUS20240320347A1
Innovation
- A memory subsystem that establishes a trusted communication channel between the memory controller and memory using certificate exchange for secure key verification, enabling encrypted or scrambled data transmission, which reduces the possibility of hacking and allows access to secure mode registers and error correction features.
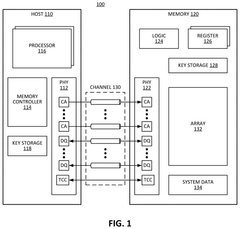
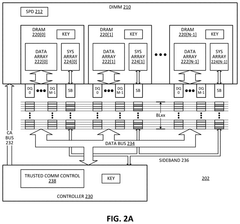
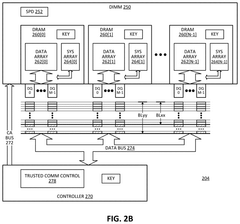
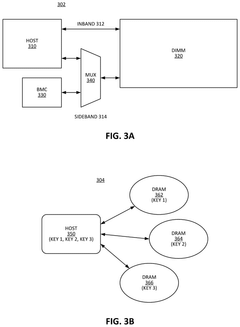
Thermal Management Solutions for DDR5 in GPU Systems
Thermal management has become a critical factor in optimizing DDR5 performance within GPU-driven systems. As DDR5 modules operate at higher frequencies and voltages compared to previous generations, they generate significantly more heat during intensive operations. This thermal challenge is particularly pronounced in GPU systems where both components compete for cooling resources within confined spaces.
Current thermal solutions for DDR5 in GPU environments can be categorized into passive and active approaches. Passive cooling methods include aluminum heat spreaders and thermal pads that facilitate heat dissipation without requiring additional power. These solutions are cost-effective but may prove insufficient for high-performance computing scenarios where GPUs and memory modules operate at maximum capacity for extended periods.
Active cooling technologies represent a more robust approach, incorporating dedicated fans, liquid cooling loops, or vapor chambers specifically designed for memory modules. Recent innovations include integrated cooling solutions that address both GPU and DDR5 thermal management simultaneously, optimizing airflow patterns and heat dissipation pathways throughout the system.
Material science advancements have introduced new thermal interface materials (TIMs) with enhanced conductivity properties. Graphene-based thermal pads and phase-change materials demonstrate up to 35% improvement in heat transfer efficiency compared to conventional solutions, enabling DDR5 modules to maintain optimal operating temperatures even under extreme workloads.
Temperature monitoring and dynamic frequency scaling have emerged as intelligent approaches to thermal management. Modern DDR5 modules incorporate temperature sensors that communicate with system management controllers, allowing for real-time adjustments to memory timing and refresh rates based on thermal conditions. This adaptive approach prevents thermal throttling while maximizing performance within safe operating parameters.
System-level design considerations have also evolved to address DDR5 thermal challenges in GPU environments. Optimized motherboard layouts now feature strategic placement of memory slots relative to GPU components, creating thermal zones that minimize heat transfer between high-temperature components. Chassis designs increasingly incorporate dedicated airflow channels for memory cooling, independent of GPU cooling solutions.
For next-generation systems, emerging technologies such as microfluidic cooling channels embedded directly within DDR5 modules show promising results in laboratory testing, potentially enabling sustained operation at frequencies exceeding 6400MT/s without thermal constraints.
Current thermal solutions for DDR5 in GPU environments can be categorized into passive and active approaches. Passive cooling methods include aluminum heat spreaders and thermal pads that facilitate heat dissipation without requiring additional power. These solutions are cost-effective but may prove insufficient for high-performance computing scenarios where GPUs and memory modules operate at maximum capacity for extended periods.
Active cooling technologies represent a more robust approach, incorporating dedicated fans, liquid cooling loops, or vapor chambers specifically designed for memory modules. Recent innovations include integrated cooling solutions that address both GPU and DDR5 thermal management simultaneously, optimizing airflow patterns and heat dissipation pathways throughout the system.
Material science advancements have introduced new thermal interface materials (TIMs) with enhanced conductivity properties. Graphene-based thermal pads and phase-change materials demonstrate up to 35% improvement in heat transfer efficiency compared to conventional solutions, enabling DDR5 modules to maintain optimal operating temperatures even under extreme workloads.
Temperature monitoring and dynamic frequency scaling have emerged as intelligent approaches to thermal management. Modern DDR5 modules incorporate temperature sensors that communicate with system management controllers, allowing for real-time adjustments to memory timing and refresh rates based on thermal conditions. This adaptive approach prevents thermal throttling while maximizing performance within safe operating parameters.
System-level design considerations have also evolved to address DDR5 thermal challenges in GPU environments. Optimized motherboard layouts now feature strategic placement of memory slots relative to GPU components, creating thermal zones that minimize heat transfer between high-temperature components. Chassis designs increasingly incorporate dedicated airflow channels for memory cooling, independent of GPU cooling solutions.
For next-generation systems, emerging technologies such as microfluidic cooling channels embedded directly within DDR5 modules show promising results in laboratory testing, potentially enabling sustained operation at frequencies exceeding 6400MT/s without thermal constraints.
Power Efficiency Strategies for DDR5-GPU Architectures
Power efficiency has become a critical consideration in modern DDR5-GPU architectures, especially as computational demands continue to escalate. The integration of DDR5 memory with high-performance GPUs presents unique challenges and opportunities for power optimization that must be strategically addressed to maximize system efficiency.
Dynamic voltage and frequency scaling (DVFS) represents one of the most effective approaches for DDR5-GPU power management. This technique allows for real-time adjustment of memory and GPU operating parameters based on workload requirements. Advanced implementations incorporate machine learning algorithms to predict optimal voltage-frequency settings, potentially reducing power consumption by 15-30% compared to static configurations while maintaining performance targets.
Memory traffic optimization techniques significantly impact power efficiency in DDR5-GPU systems. Intelligent data placement strategies that minimize cross-die communication and maximize data locality can reduce unnecessary memory transactions. Compression algorithms specifically designed for GPU memory traffic patterns can decrease bandwidth requirements by 20-40%, directly translating to power savings through reduced memory bus activity.
Thermal management innovations play a crucial role in DDR5-GPU power efficiency. Advanced cooling solutions incorporating phase-change materials and microfluidic channels enable more efficient heat dissipation from both memory and GPU components. Temperature-aware scheduling algorithms can dynamically distribute computational loads to prevent hotspots while maintaining optimal performance levels.
Power-aware memory controllers represent another frontier in DDR5-GPU efficiency. These controllers intelligently manage refresh rates, self-refresh modes, and power-down states based on access patterns and thermal conditions. Some implementations incorporate predictive bank management that pre-emptively activates or deactivates memory banks based on anticipated GPU access patterns, reducing overall power consumption by 10-25%.
Architectural innovations at the DDR5-GPU interface level offer substantial efficiency improvements. Techniques such as near-memory computing offload specific operations directly to processing elements adjacent to memory banks, reducing data movement energy costs. Similarly, 3D-stacked memory configurations with optimized through-silicon vias (TSVs) minimize interconnect distances and associated power losses.
Industry benchmarks indicate that comprehensive implementation of these strategies can achieve 30-50% improvement in performance-per-watt metrics for DDR5-GPU systems. As AI and high-performance computing workloads continue to drive memory bandwidth demands, these power efficiency techniques will become increasingly critical for sustainable system design and operation.
Dynamic voltage and frequency scaling (DVFS) represents one of the most effective approaches for DDR5-GPU power management. This technique allows for real-time adjustment of memory and GPU operating parameters based on workload requirements. Advanced implementations incorporate machine learning algorithms to predict optimal voltage-frequency settings, potentially reducing power consumption by 15-30% compared to static configurations while maintaining performance targets.
Memory traffic optimization techniques significantly impact power efficiency in DDR5-GPU systems. Intelligent data placement strategies that minimize cross-die communication and maximize data locality can reduce unnecessary memory transactions. Compression algorithms specifically designed for GPU memory traffic patterns can decrease bandwidth requirements by 20-40%, directly translating to power savings through reduced memory bus activity.
Thermal management innovations play a crucial role in DDR5-GPU power efficiency. Advanced cooling solutions incorporating phase-change materials and microfluidic channels enable more efficient heat dissipation from both memory and GPU components. Temperature-aware scheduling algorithms can dynamically distribute computational loads to prevent hotspots while maintaining optimal performance levels.
Power-aware memory controllers represent another frontier in DDR5-GPU efficiency. These controllers intelligently manage refresh rates, self-refresh modes, and power-down states based on access patterns and thermal conditions. Some implementations incorporate predictive bank management that pre-emptively activates or deactivates memory banks based on anticipated GPU access patterns, reducing overall power consumption by 10-25%.
Architectural innovations at the DDR5-GPU interface level offer substantial efficiency improvements. Techniques such as near-memory computing offload specific operations directly to processing elements adjacent to memory banks, reducing data movement energy costs. Similarly, 3D-stacked memory configurations with optimized through-silicon vias (TSVs) minimize interconnect distances and associated power losses.
Industry benchmarks indicate that comprehensive implementation of these strategies can achieve 30-50% improvement in performance-per-watt metrics for DDR5-GPU systems. As AI and high-performance computing workloads continue to drive memory bandwidth demands, these power efficiency techniques will become increasingly critical for sustainable system design and operation.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!