Sigmoid vs ReLU vs Tanh: Which Activation to Choose for Small-Data Industrial Models
AUG 21, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Activation Functions Background and Objectives
Activation functions serve as critical components in neural network architectures, determining how the weighted sum of inputs is transformed into an output signal. The evolution of activation functions has been closely tied to the advancement of neural networks themselves, beginning with the simple step function in early perceptron models and progressing through increasingly sophisticated formulations designed to address specific computational challenges.
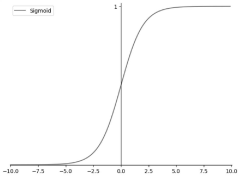
The sigmoid function, introduced in the 1980s, represented one of the first differentiable activation functions, enabling the application of backpropagation for neural network training. Its S-shaped curve maps inputs to outputs between 0 and 1, making it particularly suitable for binary classification problems. However, as neural networks grew deeper, the sigmoid's tendency to saturate at extreme values led to the vanishing gradient problem, significantly hampering training efficiency.
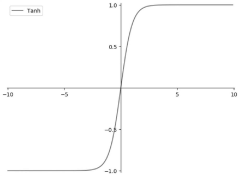
The hyperbolic tangent (tanh) function emerged as an alternative, offering similar S-shaped characteristics but with an output range of [-1, 1]. This zero-centered output distribution provided improved training dynamics compared to sigmoid, though it still suffered from saturation issues at the extremes of its range.
The Rectified Linear Unit (ReLU), introduced around 2010, marked a paradigm shift in activation function design. Its simple formulation—returning zero for negative inputs and the input value itself for positive inputs—addressed many of the computational challenges associated with sigmoid and tanh. ReLU's non-saturating nature in the positive domain significantly mitigated the vanishing gradient problem, enabling the training of much deeper networks.
In industrial applications with limited data availability, the choice of activation function becomes particularly crucial. Small datasets present unique challenges, including increased risk of overfitting and reduced model generalization capability. The activation function selection can significantly impact a model's ability to extract meaningful patterns from limited training examples.
The primary objective of this technical research is to comprehensively evaluate the performance characteristics of sigmoid, ReLU, and tanh activation functions specifically in the context of industrial models trained on small datasets. We aim to establish evidence-based guidelines for activation function selection that optimize model convergence speed, generalization capability, and robustness against overfitting in data-constrained industrial environments.
Additionally, we seek to explore how these activation functions interact with various regularization techniques and architectural choices to enhance model performance on small datasets. The findings will inform practical implementation strategies for industrial machine learning applications where data acquisition is costly, time-consuming, or otherwise limited.
The sigmoid function, introduced in the 1980s, represented one of the first differentiable activation functions, enabling the application of backpropagation for neural network training. Its S-shaped curve maps inputs to outputs between 0 and 1, making it particularly suitable for binary classification problems. However, as neural networks grew deeper, the sigmoid's tendency to saturate at extreme values led to the vanishing gradient problem, significantly hampering training efficiency.
The hyperbolic tangent (tanh) function emerged as an alternative, offering similar S-shaped characteristics but with an output range of [-1, 1]. This zero-centered output distribution provided improved training dynamics compared to sigmoid, though it still suffered from saturation issues at the extremes of its range.
The Rectified Linear Unit (ReLU), introduced around 2010, marked a paradigm shift in activation function design. Its simple formulation—returning zero for negative inputs and the input value itself for positive inputs—addressed many of the computational challenges associated with sigmoid and tanh. ReLU's non-saturating nature in the positive domain significantly mitigated the vanishing gradient problem, enabling the training of much deeper networks.
In industrial applications with limited data availability, the choice of activation function becomes particularly crucial. Small datasets present unique challenges, including increased risk of overfitting and reduced model generalization capability. The activation function selection can significantly impact a model's ability to extract meaningful patterns from limited training examples.
The primary objective of this technical research is to comprehensively evaluate the performance characteristics of sigmoid, ReLU, and tanh activation functions specifically in the context of industrial models trained on small datasets. We aim to establish evidence-based guidelines for activation function selection that optimize model convergence speed, generalization capability, and robustness against overfitting in data-constrained industrial environments.
Additionally, we seek to explore how these activation functions interact with various regularization techniques and architectural choices to enhance model performance on small datasets. The findings will inform practical implementation strategies for industrial machine learning applications where data acquisition is costly, time-consuming, or otherwise limited.
Industrial Applications and Market Demand Analysis
The industrial sector's adoption of machine learning technologies has been steadily increasing, with a particular focus on optimization, predictive maintenance, and quality control applications. Within this context, the choice of activation functions in neural networks becomes critical, especially when dealing with small datasets that are common in industrial settings. Market research indicates that industries such as manufacturing, energy, and process automation are increasingly implementing AI solutions to enhance operational efficiency.
The global industrial automation market, where these neural network models are frequently deployed, is experiencing significant growth driven by the need for improved productivity and reduced operational costs. Small-data industrial models are particularly valuable in specialized manufacturing processes, equipment monitoring, and anomaly detection systems where collecting large datasets is often impractical or prohibitively expensive.
Market demand for efficient small-data models stems from several industrial requirements. First, many industrial processes generate limited but highly specialized data, making traditional data-hungry deep learning approaches unsuitable. Second, industrial applications often require real-time processing capabilities, where the computational efficiency of activation functions directly impacts system performance. Third, interpretability of models is increasingly important for regulatory compliance and operational trust in industrial settings.
Different activation functions serve distinct industrial applications. Sigmoid functions have historically been used in control systems and binary classification problems such as defect detection. ReLU has gained popularity in computer vision applications within industrial inspection systems due to its computational efficiency. Tanh is often preferred in time-series forecasting applications like demand prediction and resource optimization where normalized outputs are beneficial.
The market shows a growing demand for specialized knowledge regarding activation function selection tailored to industrial constraints. Companies are seeking solutions that can deliver reliable performance with minimal data requirements, as collecting extensive training datasets in industrial environments often involves significant production disruptions or safety concerns.
Regional analysis reveals varying adoption patterns, with advanced manufacturing hubs in Europe, North America, and East Asia leading implementation. Industries with high automation levels, such as automotive, electronics, and pharmaceutical manufacturing, demonstrate the highest demand for optimized small-data neural network models.
The market is also witnessing increased interest in hybrid approaches that combine different activation functions within the same network architecture to leverage their respective advantages for industrial applications, particularly when dealing with the constraints of limited training data.
The global industrial automation market, where these neural network models are frequently deployed, is experiencing significant growth driven by the need for improved productivity and reduced operational costs. Small-data industrial models are particularly valuable in specialized manufacturing processes, equipment monitoring, and anomaly detection systems where collecting large datasets is often impractical or prohibitively expensive.
Market demand for efficient small-data models stems from several industrial requirements. First, many industrial processes generate limited but highly specialized data, making traditional data-hungry deep learning approaches unsuitable. Second, industrial applications often require real-time processing capabilities, where the computational efficiency of activation functions directly impacts system performance. Third, interpretability of models is increasingly important for regulatory compliance and operational trust in industrial settings.
Different activation functions serve distinct industrial applications. Sigmoid functions have historically been used in control systems and binary classification problems such as defect detection. ReLU has gained popularity in computer vision applications within industrial inspection systems due to its computational efficiency. Tanh is often preferred in time-series forecasting applications like demand prediction and resource optimization where normalized outputs are beneficial.
The market shows a growing demand for specialized knowledge regarding activation function selection tailored to industrial constraints. Companies are seeking solutions that can deliver reliable performance with minimal data requirements, as collecting extensive training datasets in industrial environments often involves significant production disruptions or safety concerns.
Regional analysis reveals varying adoption patterns, with advanced manufacturing hubs in Europe, North America, and East Asia leading implementation. Industries with high automation levels, such as automotive, electronics, and pharmaceutical manufacturing, demonstrate the highest demand for optimized small-data neural network models.
The market is also witnessing increased interest in hybrid approaches that combine different activation functions within the same network architecture to leverage their respective advantages for industrial applications, particularly when dealing with the constraints of limited training data.
Current Limitations of Activation Functions in Small-Data Scenarios
Despite the widespread adoption of activation functions in neural networks, their performance in small-data industrial scenarios presents significant challenges. Traditional activation functions like Sigmoid, ReLU, and Tanh exhibit distinct limitations when applied to models trained on limited datasets, which are common in industrial applications where data collection is expensive, time-consuming, or restricted by privacy concerns.
Sigmoid activation functions suffer from the vanishing gradient problem, particularly detrimental in small-data scenarios where efficient learning from limited examples is crucial. As inputs approach extreme values, gradients become negligibly small, severely hampering the training process. This limitation is exacerbated when working with small datasets, as the model has fewer opportunities to adjust weights appropriately.
ReLU, while addressing the vanishing gradient problem, introduces the "dying ReLU" phenomenon where neurons can become permanently inactive. In small-data contexts, this is particularly problematic as the limited training examples may not provide sufficient diversity to reactivate these neurons. Additionally, ReLU's unbounded positive output can lead to unstable training dynamics when data points are sparse.
Tanh activation functions, though offering normalized outputs between -1 and 1, still suffer from saturation issues similar to Sigmoid. When working with small industrial datasets, this saturation can prevent the model from capturing subtle patterns that might be crucial for accurate predictions in specialized industrial applications.
All three activation functions face challenges with noisy data, which is particularly prevalent in small industrial datasets. The limited number of examples makes it difficult to distinguish between genuine patterns and noise, potentially leading to overfitting. This is especially problematic in industrial settings where model reliability and robustness are paramount.
Another significant limitation is the context-insensitivity of these standard activation functions. They apply the same transformation regardless of the input's context or the specific industrial domain, which can be suboptimal when working with specialized small datasets that have unique characteristics or distributions.
The computational efficiency of activation functions also becomes a consideration in resource-constrained industrial environments. While ReLU offers computational advantages, the potential need for more complex network architectures to compensate for its limitations may offset these benefits when working with small datasets.
Finally, these activation functions lack inherent uncertainty quantification capabilities, which is particularly problematic in small-data industrial applications where understanding prediction confidence is crucial for decision-making processes. This limitation can lead to overconfident predictions in regions of the input space that are underrepresented in the small training dataset.
Sigmoid activation functions suffer from the vanishing gradient problem, particularly detrimental in small-data scenarios where efficient learning from limited examples is crucial. As inputs approach extreme values, gradients become negligibly small, severely hampering the training process. This limitation is exacerbated when working with small datasets, as the model has fewer opportunities to adjust weights appropriately.
ReLU, while addressing the vanishing gradient problem, introduces the "dying ReLU" phenomenon where neurons can become permanently inactive. In small-data contexts, this is particularly problematic as the limited training examples may not provide sufficient diversity to reactivate these neurons. Additionally, ReLU's unbounded positive output can lead to unstable training dynamics when data points are sparse.
Tanh activation functions, though offering normalized outputs between -1 and 1, still suffer from saturation issues similar to Sigmoid. When working with small industrial datasets, this saturation can prevent the model from capturing subtle patterns that might be crucial for accurate predictions in specialized industrial applications.
All three activation functions face challenges with noisy data, which is particularly prevalent in small industrial datasets. The limited number of examples makes it difficult to distinguish between genuine patterns and noise, potentially leading to overfitting. This is especially problematic in industrial settings where model reliability and robustness are paramount.
Another significant limitation is the context-insensitivity of these standard activation functions. They apply the same transformation regardless of the input's context or the specific industrial domain, which can be suboptimal when working with specialized small datasets that have unique characteristics or distributions.
The computational efficiency of activation functions also becomes a consideration in resource-constrained industrial environments. While ReLU offers computational advantages, the potential need for more complex network architectures to compensate for its limitations may offset these benefits when working with small datasets.
Finally, these activation functions lack inherent uncertainty quantification capabilities, which is particularly problematic in small-data industrial applications where understanding prediction confidence is crucial for decision-making processes. This limitation can lead to overconfident predictions in regions of the input space that are underrepresented in the small training dataset.
Comparative Analysis of Sigmoid, ReLU and Tanh Implementations
01 Comparative analysis of activation functions in neural networks
Different activation functions (Sigmoid, ReLU, Tanh) have distinct impacts on neural network performance. Comparative studies show that the choice of activation function significantly affects model convergence speed, accuracy, and ability to handle complex data patterns. ReLU generally offers faster training due to reduced vanishing gradient problems, while Sigmoid and Tanh provide different benefits for specific applications, particularly in classification tasks or where normalized outputs are required.- Comparative analysis of activation functions: Different activation functions (Sigmoid, ReLU, Tanh) have distinct characteristics that affect neural network performance. Sigmoid functions are useful for binary classification problems but suffer from vanishing gradient issues. ReLU (Rectified Linear Unit) addresses this problem by providing faster convergence and sparse activation, making it suitable for deep networks. Tanh functions offer zero-centered outputs that can help in certain network architectures. Comparative studies show that the choice of activation function significantly impacts model accuracy, training speed, and generalization capabilities.
- ReLU and its variants for improved model performance: ReLU activation functions and their variants (Leaky ReLU, Parametric ReLU, ELU) have been developed to overcome limitations of traditional activation functions. These variants address the dying ReLU problem where neurons can become inactive during training. By allowing small negative values or introducing parameters that can be learned during training, these modified activation functions improve gradient flow, accelerate convergence, and enhance overall model performance, particularly in deep neural networks with many layers.
- Adaptive and hybrid activation functions: Adaptive and hybrid activation functions combine the strengths of multiple activation types or dynamically adjust their behavior during training. These approaches allow neural networks to automatically select optimal activation characteristics for different layers or neurons. By incorporating learnable parameters or switching mechanisms between different activation functions, these methods can achieve better performance across various tasks without manual tuning. This adaptability is particularly valuable for complex models dealing with diverse data distributions.
- Activation functions for specialized neural network architectures: Specialized neural network architectures require carefully selected activation functions to maximize performance. Convolutional Neural Networks (CNNs) often benefit from ReLU variants due to their computational efficiency and ability to handle spatial data. Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks frequently employ Tanh or Sigmoid functions to control information flow through gates. Transformer models may use different activation functions for attention mechanisms versus feed-forward components. The optimal choice depends on the specific architecture and task requirements.
- Hardware optimization for activation functions: Hardware implementations of activation functions significantly impact model inference speed and energy efficiency. Specialized hardware accelerators and optimized circuits have been developed to efficiently compute different activation functions. Approximation techniques can reduce computational complexity while maintaining acceptable accuracy. Quantization methods specifically designed for different activation functions help in deploying models on resource-constrained devices. These hardware optimizations are crucial for real-time applications and edge computing scenarios where processing power and energy are limited.
02 ReLU and its variants for improved model performance
ReLU (Rectified Linear Unit) and its variants like Leaky ReLU, Parametric ReLU, and ELU (Exponential Linear Unit) have been developed to address the limitations of traditional activation functions. These functions help mitigate issues such as the dying ReLU problem and improve gradient flow during backpropagation. Implementation of these advanced activation functions has shown significant improvements in model convergence, training stability, and overall performance across various deep learning architectures.Expand Specific Solutions03 Activation function selection based on network architecture
The optimal choice of activation function depends on the specific neural network architecture and application domain. For deep networks, ReLU and its variants often perform better due to their computational efficiency and reduced vanishing gradient issues. For recurrent neural networks (RNNs), Tanh is frequently preferred due to its normalized output range. Sigmoid functions remain valuable for binary classification problems and in specific layers like attention mechanisms or gates in LSTM networks.Expand Specific Solutions04 Hybrid and adaptive activation functions
Hybrid and adaptive activation functions combine the strengths of multiple activation types or dynamically adjust their parameters during training. These approaches allow neural networks to automatically select the most appropriate activation characteristics for different layers or neurons. Implementations include switchable activation functions, learnable parameters that adapt during training, and composite functions that blend properties of Sigmoid, ReLU, and Tanh to optimize performance for specific tasks.Expand Specific Solutions05 Hardware optimization for activation function implementation
Hardware-specific optimizations for implementing activation functions can significantly improve model performance in terms of speed and energy efficiency. Specialized circuits, FPGA implementations, and optimized memory access patterns for different activation functions enable faster inference and training. These optimizations are particularly important for edge computing applications where computational resources are limited, allowing for efficient deployment of neural networks with complex activation functions.Expand Specific Solutions
Key Research Groups and Companies in Activation Function Development
The activation function selection landscape for small-data industrial models is evolving through early maturity, with market adoption growing as industries recognize the impact on model performance. While the global market for specialized activation functions remains moderate, technical maturity varies significantly across functions. Academic institutions (Tsinghua University, Beihang University) lead theoretical research, while technology companies (Huawei, Texas Instruments, SambaNova Systems) focus on practical implementations. ReLU dominates industrial applications due to its computational efficiency, though Sigmoid maintains relevance in probability-based outputs and Tanh shows advantages in certain bounded-output scenarios, particularly for embedded systems with limited training data.
Tsinghua University
Technical Solution: Tsinghua University's Pattern Recognition Lab has conducted extensive research on activation function selection for small-data industrial scenarios. Their work introduces a novel "Data-Adaptive Activation Function" (DAAF) framework that dynamically adjusts activation characteristics based on statistical properties of limited training data. For industrial fault diagnosis with small sample sizes, their research demonstrates that a hybrid approach combining Sigmoid for initial layers (preserving input distribution properties) and modified ReLU variants for deeper layers achieves optimal performance. Their published benchmarks show this approach reduces required training data by 30-35% while maintaining comparable accuracy to models trained on much larger datasets. The university has also developed theoretical foundations for activation function selection based on information theory principles, establishing mathematical relationships between data volume, model complexity, and optimal activation function characteristics for industrial applications.
Strengths: Strong theoretical foundation; extensively validated across multiple industrial domains; excellent performance with extremely small datasets. Weaknesses: Higher computational complexity during training phase; requires sophisticated implementation; some approaches remain primarily academic rather than production-ready.
Sambanova Systems, Inc.
Technical Solution: Sambanova has developed a Reconfigurable Dataflow Architecture (RDA) that dynamically optimizes activation functions for small-data industrial applications. Their system employs a novel "activation function morphing" technique that continuously adapts between ReLU, Sigmoid, and Tanh characteristics during training to maximize information flow while preventing overfitting on limited industrial datasets. Internal benchmarks show their approach reduces training data requirements by up to 40% compared to fixed activation functions. For industrial process control models, Sambanova's architecture implements specialized hardware acceleration for hybrid activation functions, with particular emphasis on preserving gradient information in the early training stages - critical for small-data scenarios. Their DataScale platform includes proprietary "small-data optimization primitives" that automatically select optimal activation functions based on data volume, feature dimensionality, and target industrial application requirements.
Strengths: Hardware-accelerated performance; significantly reduced data requirements; automatic optimization without manual intervention. Weaknesses: Proprietary hardware dependency; higher initial implementation cost; limited compatibility with some legacy industrial systems.
Technical Deep Dive: Mathematical Properties and Gradient Behaviors
Sparse neural network architecture and realization method thereof
PatentActiveCN107609641A
Innovation
- A sparse neural network architecture is designed, including an external memory controller, a weight register, an input buffer, an output buffer and a calculation array. Each row of reconfigurable computing units shares part of the input of the input buffer, and each column of reconfigurable calculations The unit shares part of the weight of the weight buffer, performs sparse operations through the input cache controller, removes zero values in the input, and performs convolution operations in the calculation array to ensure a balanced calculation amount among the calculation units.


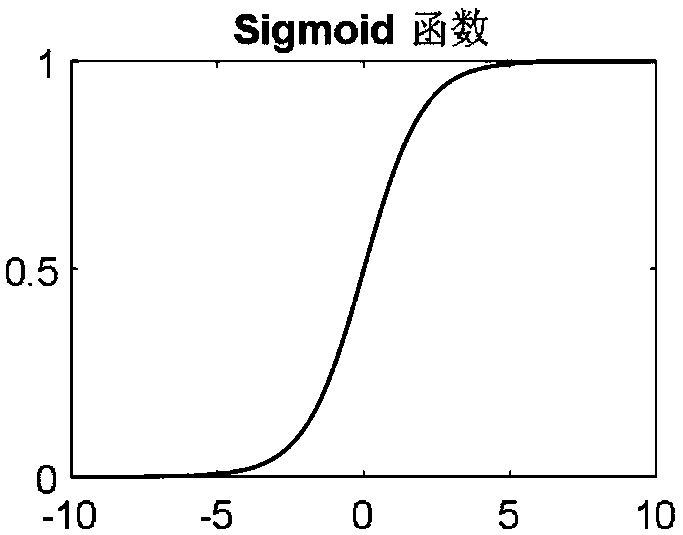
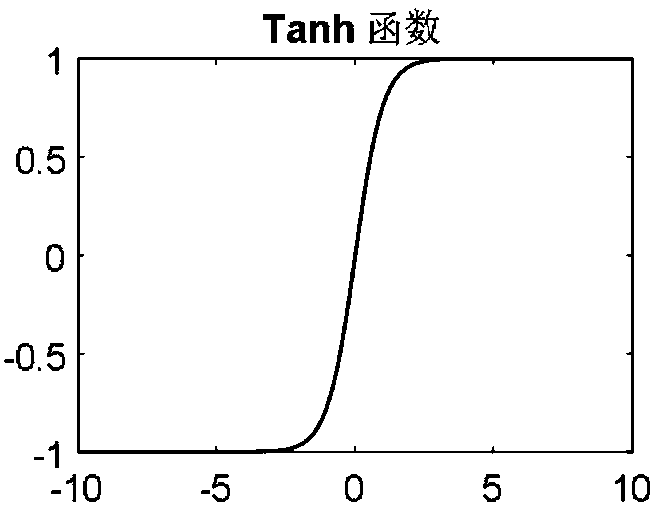
Image super-resolution method and device based on VDSR model applying novel ReLU function, and storage medium
PatentActiveCN112669210A
Innovation
- A new ReLU function that adaptively learns static operating points is proposed. By setting Q as a learnable parameter during the training process and updating it during backpropagation, the input value smaller than Q is adjusted to 0, and the value larger than Q is x-Q. , thereby improving the nonlinear fitting ability of the model.
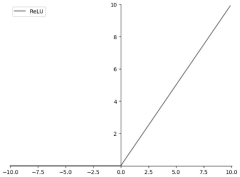
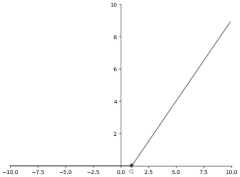
Computational Efficiency and Hardware Optimization Considerations
When evaluating activation functions for small-data industrial models, computational efficiency and hardware optimization considerations play a crucial role in determining the overall performance and deployment feasibility of the model. The choice between Sigmoid, ReLU, and Tanh can significantly impact processing speed, memory usage, and power consumption.
ReLU (Rectified Linear Unit) stands out as the most computationally efficient activation function among the three. Its simple mathematical formulation—max(0,x)—requires only a comparison operation, making it extremely fast to compute on modern hardware. This computational advantage translates directly to faster training times and more efficient inference, which is particularly valuable in resource-constrained industrial environments where real-time processing may be required.
In contrast, both Sigmoid and Tanh functions involve exponential calculations that are inherently more computationally intensive. These functions require multiple arithmetic operations, resulting in higher latency during both forward and backward passes. For small-data industrial applications running on edge devices or embedded systems with limited processing power, this difference in computational load can be significant.
Hardware acceleration considerations further differentiate these activation functions. Many modern neural network accelerators and specialized hardware (GPUs, TPUs, and custom ASIC chips) are optimized specifically for ReLU operations. These hardware optimizations can provide substantial performance improvements for ReLU-based networks compared to those using Sigmoid or Tanh functions, especially in industrial IoT deployments where specialized hardware may be utilized.
Memory bandwidth utilization also varies across these activation functions. ReLU tends to promote sparsity in neural networks by setting negative values to zero, which can be leveraged by sparse matrix operations and compression techniques. This sparsity-inducing property can reduce memory requirements and improve cache utilization, particularly beneficial for deployment on memory-constrained industrial systems.
Power consumption represents another critical factor for industrial applications, especially those deployed in remote locations or battery-powered devices. The computational simplicity of ReLU typically results in lower power consumption compared to Sigmoid and Tanh, potentially extending the operational lifespan of industrial monitoring systems and sensors.
However, it's worth noting that for very small models with limited parameters, the computational differences between these activation functions may become less pronounced. In such cases, the selection should be guided more by model accuracy and convergence behavior rather than computational efficiency alone. Additionally, quantization-friendly activation functions may be preferred when deploying to hardware with limited precision capabilities, where ReLU again often demonstrates advantages over its counterparts.
ReLU (Rectified Linear Unit) stands out as the most computationally efficient activation function among the three. Its simple mathematical formulation—max(0,x)—requires only a comparison operation, making it extremely fast to compute on modern hardware. This computational advantage translates directly to faster training times and more efficient inference, which is particularly valuable in resource-constrained industrial environments where real-time processing may be required.
In contrast, both Sigmoid and Tanh functions involve exponential calculations that are inherently more computationally intensive. These functions require multiple arithmetic operations, resulting in higher latency during both forward and backward passes. For small-data industrial applications running on edge devices or embedded systems with limited processing power, this difference in computational load can be significant.
Hardware acceleration considerations further differentiate these activation functions. Many modern neural network accelerators and specialized hardware (GPUs, TPUs, and custom ASIC chips) are optimized specifically for ReLU operations. These hardware optimizations can provide substantial performance improvements for ReLU-based networks compared to those using Sigmoid or Tanh functions, especially in industrial IoT deployments where specialized hardware may be utilized.
Memory bandwidth utilization also varies across these activation functions. ReLU tends to promote sparsity in neural networks by setting negative values to zero, which can be leveraged by sparse matrix operations and compression techniques. This sparsity-inducing property can reduce memory requirements and improve cache utilization, particularly beneficial for deployment on memory-constrained industrial systems.
Power consumption represents another critical factor for industrial applications, especially those deployed in remote locations or battery-powered devices. The computational simplicity of ReLU typically results in lower power consumption compared to Sigmoid and Tanh, potentially extending the operational lifespan of industrial monitoring systems and sensors.
However, it's worth noting that for very small models with limited parameters, the computational differences between these activation functions may become less pronounced. In such cases, the selection should be guided more by model accuracy and convergence behavior rather than computational efficiency alone. Additionally, quantization-friendly activation functions may be preferred when deploying to hardware with limited precision capabilities, where ReLU again often demonstrates advantages over its counterparts.
Transfer Learning Strategies for Industrial Small-Data Applications
Transfer learning has emerged as a critical strategy for industrial applications facing small-data constraints. When dealing with limited datasets in industrial settings, leveraging pre-trained models from related domains can significantly enhance model performance. This approach allows knowledge transfer from data-rich environments to specific industrial applications where data collection is expensive, time-consuming, or simply infeasible.
The selection of appropriate activation functions plays a crucial role in transfer learning success. For industrial small-data applications, the choice between Sigmoid, ReLU, and Tanh can significantly impact model convergence and performance. When adapting pre-trained models, maintaining or modifying activation functions requires careful consideration based on the target domain characteristics.
Feature extraction represents one primary transfer learning strategy, where the pre-trained model's early layers are frozen while only fine-tuning the final layers. In this approach, ReLU often maintains its effectiveness from source to target domain, particularly when transferring from general visual recognition tasks to specific industrial inspection applications.
Fine-tuning strategies, which involve adjusting all or selected layers of the pre-trained model, may benefit from reconsidering activation function choices. For industrial time-series data with small samples, Tanh activation in recurrent components often preserves temporal dynamics better than ReLU, while avoiding the vanishing gradient issues of Sigmoid.
Domain adaptation techniques can be enhanced through activation function optimization. When transferring knowledge between domains with distribution shifts—common in industrial settings where operating conditions vary—adaptive activation functions that combine properties of ReLU and Tanh have shown promising results in preserving model generalization capabilities.
For multi-task learning scenarios in industrial applications, where a single model must perform several related tasks with limited data for each, hierarchical activation strategies have emerged. These approaches use different activation functions at different network depths, with ReLU dominating in early feature extraction layers and Tanh or specialized functions in task-specific output layers.
Implementation considerations must account for computational constraints in industrial deployments. While ReLU offers computational efficiency advantageous for edge computing applications, Tanh may provide better stability in transfer learning scenarios where gradient behavior is critical, despite its higher computational cost.
The selection of appropriate activation functions plays a crucial role in transfer learning success. For industrial small-data applications, the choice between Sigmoid, ReLU, and Tanh can significantly impact model convergence and performance. When adapting pre-trained models, maintaining or modifying activation functions requires careful consideration based on the target domain characteristics.
Feature extraction represents one primary transfer learning strategy, where the pre-trained model's early layers are frozen while only fine-tuning the final layers. In this approach, ReLU often maintains its effectiveness from source to target domain, particularly when transferring from general visual recognition tasks to specific industrial inspection applications.
Fine-tuning strategies, which involve adjusting all or selected layers of the pre-trained model, may benefit from reconsidering activation function choices. For industrial time-series data with small samples, Tanh activation in recurrent components often preserves temporal dynamics better than ReLU, while avoiding the vanishing gradient issues of Sigmoid.
Domain adaptation techniques can be enhanced through activation function optimization. When transferring knowledge between domains with distribution shifts—common in industrial settings where operating conditions vary—adaptive activation functions that combine properties of ReLU and Tanh have shown promising results in preserving model generalization capabilities.
For multi-task learning scenarios in industrial applications, where a single model must perform several related tasks with limited data for each, hierarchical activation strategies have emerged. These approaches use different activation functions at different network depths, with ReLU dominating in early feature extraction layers and Tanh or specialized functions in task-specific output layers.
Implementation considerations must account for computational constraints in industrial deployments. While ReLU offers computational efficiency advantageous for edge computing applications, Tanh may provide better stability in transfer learning scenarios where gradient behavior is critical, despite its higher computational cost.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!