HBM4 Controller Architectures: Scheduling, Fairness And Arbitration
SEP 12, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
HBM4 Memory Evolution and Design Objectives
High Bandwidth Memory (HBM) technology has undergone significant evolution since its inception, with each generation bringing substantial improvements in bandwidth, capacity, and energy efficiency. The journey from HBM1 to HBM4 represents a continuous pursuit of addressing the growing memory demands of data-intensive applications such as artificial intelligence, high-performance computing, and graphics processing. HBM4, as the latest iteration, aims to overcome the limitations of its predecessors while establishing new benchmarks in memory performance.
The evolution of HBM technology has been driven by the exponential growth in data processing requirements. HBM1, introduced in 2013, offered a stacked DRAM solution with improved bandwidth compared to conventional DRAM. HBM2, released in 2016, doubled the bandwidth and capacity. HBM2E, an enhancement to HBM2, further increased bandwidth and capacity in 2018. HBM3, launched in 2021, provided significant improvements in bandwidth, capacity, and power efficiency.
HBM4, announced in 2023, represents the next frontier in high-bandwidth memory technology. It aims to deliver unprecedented memory bandwidth exceeding 8 TB/s, substantially higher than the 819 GB/s offered by HBM3. This dramatic increase is achieved through innovations in die stacking, interconnect technology, and signaling rates, enabling more efficient data transfer between memory and processing units.
The primary design objectives for HBM4 controllers focus on addressing the complex challenges of managing high-bandwidth memory systems. These objectives include maximizing effective bandwidth utilization, minimizing latency, ensuring fair resource allocation among competing requests, and maintaining power efficiency. The controller architecture must balance these often-conflicting requirements while supporting diverse workload characteristics.
Scheduling mechanisms in HBM4 controllers are designed to optimize memory access patterns, reducing bank conflicts and maximizing row buffer locality. This involves sophisticated algorithms that can predict and adapt to changing workload behaviors, prioritizing critical requests while ensuring system-wide performance optimization. The scheduling objectives extend beyond simple throughput maximization to include quality of service guarantees for latency-sensitive applications.
Fairness considerations in HBM4 controller design address the equitable distribution of memory resources among multiple processing elements or applications. As systems increasingly consolidate diverse workloads, preventing performance interference becomes crucial. HBM4 controllers aim to implement fairness policies that prevent resource starvation while maintaining overall system efficiency.
Arbitration mechanisms represent the decision-making core of HBM4 controllers, determining which memory requests are serviced at each cycle. These mechanisms must balance competing demands from various system components, implementing policies that reflect application priorities while maximizing memory subsystem utilization. Advanced arbitration schemes in HBM4 controllers incorporate machine learning techniques to adapt to dynamic workload characteristics.
The evolution of HBM technology has been driven by the exponential growth in data processing requirements. HBM1, introduced in 2013, offered a stacked DRAM solution with improved bandwidth compared to conventional DRAM. HBM2, released in 2016, doubled the bandwidth and capacity. HBM2E, an enhancement to HBM2, further increased bandwidth and capacity in 2018. HBM3, launched in 2021, provided significant improvements in bandwidth, capacity, and power efficiency.
HBM4, announced in 2023, represents the next frontier in high-bandwidth memory technology. It aims to deliver unprecedented memory bandwidth exceeding 8 TB/s, substantially higher than the 819 GB/s offered by HBM3. This dramatic increase is achieved through innovations in die stacking, interconnect technology, and signaling rates, enabling more efficient data transfer between memory and processing units.
The primary design objectives for HBM4 controllers focus on addressing the complex challenges of managing high-bandwidth memory systems. These objectives include maximizing effective bandwidth utilization, minimizing latency, ensuring fair resource allocation among competing requests, and maintaining power efficiency. The controller architecture must balance these often-conflicting requirements while supporting diverse workload characteristics.
Scheduling mechanisms in HBM4 controllers are designed to optimize memory access patterns, reducing bank conflicts and maximizing row buffer locality. This involves sophisticated algorithms that can predict and adapt to changing workload behaviors, prioritizing critical requests while ensuring system-wide performance optimization. The scheduling objectives extend beyond simple throughput maximization to include quality of service guarantees for latency-sensitive applications.
Fairness considerations in HBM4 controller design address the equitable distribution of memory resources among multiple processing elements or applications. As systems increasingly consolidate diverse workloads, preventing performance interference becomes crucial. HBM4 controllers aim to implement fairness policies that prevent resource starvation while maintaining overall system efficiency.
Arbitration mechanisms represent the decision-making core of HBM4 controllers, determining which memory requests are serviced at each cycle. These mechanisms must balance competing demands from various system components, implementing policies that reflect application priorities while maximizing memory subsystem utilization. Advanced arbitration schemes in HBM4 controllers incorporate machine learning techniques to adapt to dynamic workload characteristics.
Market Demand Analysis for High-Bandwidth Memory Solutions
The high-bandwidth memory (HBM) market is experiencing unprecedented growth driven by the explosive demand for data-intensive applications. Current market analysis indicates that the global HBM market is projected to reach $16 billion by 2027, with a compound annual growth rate exceeding 30% from 2022 to 2027. This remarkable expansion is primarily fueled by the rapid advancement of artificial intelligence, machine learning, high-performance computing, and data analytics applications that require massive memory bandwidth to process increasingly complex workloads.
The emergence of HBM4 technology comes at a critical juncture when existing memory solutions are struggling to meet the escalating performance requirements of next-generation computing systems. Data centers and cloud service providers are particularly driving this demand as they seek to optimize their infrastructure for AI training and inference workloads that process petabytes of data. Market research indicates that over 65% of enterprise organizations plan to significantly increase their investments in high-bandwidth memory solutions within the next three years.
The automotive and edge computing sectors represent rapidly growing market segments for HBM4 controllers. Advanced driver-assistance systems (ADAS) and autonomous driving technologies require real-time processing of sensor data with minimal latency, creating substantial demand for efficient memory controllers with sophisticated scheduling and arbitration capabilities. Industry forecasts suggest that automotive applications of HBM will grow at a rate of 40% annually through 2026.
From a geographical perspective, North America currently leads the HBM market with approximately 40% share, followed closely by Asia-Pacific at 35%. However, the Asia-Pacific region is expected to witness the highest growth rate due to increasing investments in AI research and semiconductor manufacturing capabilities in countries like China, South Korea, and Taiwan.
The demand for more sophisticated memory controller architectures is particularly evident in the hyperscaler segment, where companies are reporting memory bandwidth as a primary bottleneck in their AI infrastructure. Recent industry surveys reveal that 78% of data center operators consider memory bandwidth optimization a critical priority, with particular emphasis on fair resource allocation among competing workloads and intelligent scheduling algorithms.
Energy efficiency has emerged as another significant market driver, with data centers increasingly prioritizing performance-per-watt metrics. This trend is creating strong demand for HBM4 controllers that can intelligently manage power states while maintaining optimal performance through advanced arbitration techniques. Market analysis shows that solutions offering 25% better energy efficiency can command premium pricing of up to 20% in the current competitive landscape.
The emergence of HBM4 technology comes at a critical juncture when existing memory solutions are struggling to meet the escalating performance requirements of next-generation computing systems. Data centers and cloud service providers are particularly driving this demand as they seek to optimize their infrastructure for AI training and inference workloads that process petabytes of data. Market research indicates that over 65% of enterprise organizations plan to significantly increase their investments in high-bandwidth memory solutions within the next three years.
The automotive and edge computing sectors represent rapidly growing market segments for HBM4 controllers. Advanced driver-assistance systems (ADAS) and autonomous driving technologies require real-time processing of sensor data with minimal latency, creating substantial demand for efficient memory controllers with sophisticated scheduling and arbitration capabilities. Industry forecasts suggest that automotive applications of HBM will grow at a rate of 40% annually through 2026.
From a geographical perspective, North America currently leads the HBM market with approximately 40% share, followed closely by Asia-Pacific at 35%. However, the Asia-Pacific region is expected to witness the highest growth rate due to increasing investments in AI research and semiconductor manufacturing capabilities in countries like China, South Korea, and Taiwan.
The demand for more sophisticated memory controller architectures is particularly evident in the hyperscaler segment, where companies are reporting memory bandwidth as a primary bottleneck in their AI infrastructure. Recent industry surveys reveal that 78% of data center operators consider memory bandwidth optimization a critical priority, with particular emphasis on fair resource allocation among competing workloads and intelligent scheduling algorithms.
Energy efficiency has emerged as another significant market driver, with data centers increasingly prioritizing performance-per-watt metrics. This trend is creating strong demand for HBM4 controllers that can intelligently manage power states while maintaining optimal performance through advanced arbitration techniques. Market analysis shows that solutions offering 25% better energy efficiency can command premium pricing of up to 20% in the current competitive landscape.
Current HBM4 Controller Challenges and Limitations
Despite the significant advancements in HBM4 technology, current controller architectures face several critical challenges and limitations that impede optimal performance and efficiency. Memory access patterns in modern computing workloads, particularly in AI and high-performance computing applications, have become increasingly complex and unpredictable. This unpredictability creates substantial difficulties for traditional memory scheduling algorithms, which often struggle to maintain consistent performance across diverse workload scenarios.
One of the primary challenges lies in the memory request scheduling domain. As HBM4 supports higher bandwidth and increased channel parallelism, controllers must efficiently manage a much larger number of concurrent requests while maintaining low latency. Current scheduling mechanisms frequently encounter bottlenecks when handling mixed read/write operations or when dealing with varying request sizes, resulting in suboptimal memory utilization and increased access latency.
Fairness implementation represents another significant limitation in existing HBM4 controllers. With multiple processing cores, accelerators, and I/O devices competing for memory access, ensuring equitable resource allocation becomes increasingly difficult. Current fairness mechanisms often fail to properly balance the needs of latency-sensitive applications against bandwidth-intensive workloads, leading to potential starvation of certain requestors or inefficient bandwidth allocation.
The arbitration logic in contemporary HBM4 controllers also presents substantial challenges. As system complexity increases, arbitration decisions must consider numerous factors simultaneously, including quality of service requirements, power constraints, thermal considerations, and bank-level parallelism. Current arbitration schemes frequently employ oversimplified heuristics that cannot adequately address these multidimensional optimization problems.
Power management presents another critical limitation. While HBM4 offers improved energy efficiency compared to previous generations, the controller must still carefully balance performance demands against power constraints. Existing controllers often lack sophisticated dynamic power management capabilities, resulting in suboptimal energy consumption profiles during varying workload intensities.
Additionally, current HBM4 controllers face significant challenges in adapting to emerging computing paradigms such as near-memory processing and computational storage. These architectures fundamentally alter traditional memory access patterns and require more flexible, programmable controller designs that can dynamically adjust scheduling and arbitration policies based on workload characteristics.
Scalability remains a persistent concern as well. As HBM4 implementations grow in capacity and complexity, controllers must scale accordingly without introducing excessive latency or control overhead. Many existing controller architectures were not designed with such extreme scalability requirements in mind, creating potential bottlenecks in next-generation systems.
One of the primary challenges lies in the memory request scheduling domain. As HBM4 supports higher bandwidth and increased channel parallelism, controllers must efficiently manage a much larger number of concurrent requests while maintaining low latency. Current scheduling mechanisms frequently encounter bottlenecks when handling mixed read/write operations or when dealing with varying request sizes, resulting in suboptimal memory utilization and increased access latency.
Fairness implementation represents another significant limitation in existing HBM4 controllers. With multiple processing cores, accelerators, and I/O devices competing for memory access, ensuring equitable resource allocation becomes increasingly difficult. Current fairness mechanisms often fail to properly balance the needs of latency-sensitive applications against bandwidth-intensive workloads, leading to potential starvation of certain requestors or inefficient bandwidth allocation.
The arbitration logic in contemporary HBM4 controllers also presents substantial challenges. As system complexity increases, arbitration decisions must consider numerous factors simultaneously, including quality of service requirements, power constraints, thermal considerations, and bank-level parallelism. Current arbitration schemes frequently employ oversimplified heuristics that cannot adequately address these multidimensional optimization problems.
Power management presents another critical limitation. While HBM4 offers improved energy efficiency compared to previous generations, the controller must still carefully balance performance demands against power constraints. Existing controllers often lack sophisticated dynamic power management capabilities, resulting in suboptimal energy consumption profiles during varying workload intensities.
Additionally, current HBM4 controllers face significant challenges in adapting to emerging computing paradigms such as near-memory processing and computational storage. These architectures fundamentally alter traditional memory access patterns and require more flexible, programmable controller designs that can dynamically adjust scheduling and arbitration policies based on workload characteristics.
Scalability remains a persistent concern as well. As HBM4 implementations grow in capacity and complexity, controllers must scale accordingly without introducing excessive latency or control overhead. Many existing controller architectures were not designed with such extreme scalability requirements in mind, creating potential bottlenecks in next-generation systems.
State-of-the-Art Scheduling and Arbitration Techniques
01 Memory controller arbitration techniques
Various arbitration techniques are employed in memory controllers to manage access to HBM4 memory. These techniques include round-robin scheduling, priority-based arbitration, and weighted fair queuing to ensure efficient memory access. Advanced controllers implement adaptive arbitration algorithms that can adjust based on workload characteristics and system requirements, balancing between throughput and latency requirements for different memory access requests.- Memory controller arbitration techniques: Various arbitration techniques are implemented in memory controllers to manage access to High Bandwidth Memory (HBM). These techniques include round-robin scheduling, priority-based arbitration, and weighted fair queuing to ensure efficient memory access. The arbitration mechanisms help balance between different requestors and prevent starvation of lower priority requests while maintaining system performance.
- Fairness mechanisms in memory scheduling: Fairness mechanisms are incorporated into HBM controllers to ensure equitable access to memory resources among multiple competing agents. These mechanisms include credit-based systems, fairness counters, and dynamic bandwidth allocation algorithms that monitor and adjust access patterns. By implementing these fairness techniques, the controller prevents certain requestors from monopolizing memory bandwidth while maintaining overall system throughput.
- Quality of Service (QoS) in memory access: Memory controllers implement Quality of Service features to provide differentiated service levels for various memory access requests. These implementations include service level agreements, traffic classification, and bandwidth reservation mechanisms. The QoS features ensure critical applications receive necessary memory bandwidth while less time-sensitive applications receive appropriate service levels according to their requirements.
- Dynamic scheduling algorithms for memory access: Advanced scheduling algorithms are employed in HBM controllers to optimize memory access patterns. These include out-of-order execution, request reordering, and bank-aware scheduling techniques that maximize memory throughput while minimizing latency. The dynamic scheduling approaches adapt to changing workload characteristics and memory access patterns to maintain optimal performance under varying conditions.
- Multi-channel coordination and resource allocation: HBM controllers implement sophisticated coordination mechanisms across multiple memory channels to maximize bandwidth utilization. These include channel interleaving, load balancing across channels, and coordinated resource allocation strategies. By effectively distributing memory requests across available channels and managing shared resources, these techniques help achieve higher throughput and better overall system performance.
02 Fairness mechanisms in memory scheduling
Fairness mechanisms ensure that all requestors receive appropriate access to memory resources without starvation. These mechanisms include token-based allocation, deficit round-robin scheduling, and proportional share allocation. Memory controllers implement fairness policies that track historical access patterns and adjust scheduling decisions to maintain equitable resource distribution among competing processes, preventing any single process from monopolizing memory bandwidth.Expand Specific Solutions03 Quality of Service (QoS) in HBM controllers
HBM4 controllers implement Quality of Service features to guarantee performance levels for critical applications. These features include service level agreements, traffic classification, and bandwidth reservation mechanisms. The controllers can prioritize memory requests based on their urgency and importance, ensuring that time-sensitive applications receive the necessary memory bandwidth while maintaining overall system performance.Expand Specific Solutions04 Multi-channel memory access coordination
HBM4 memory controllers coordinate access across multiple channels to maximize bandwidth utilization. This involves techniques such as channel interleaving, request reordering, and load balancing across memory channels. Advanced controllers implement sophisticated algorithms to distribute memory requests optimally across available channels, reducing contention and improving overall memory subsystem performance through parallel access patterns.Expand Specific Solutions05 Dynamic scheduling adaptations for workload optimization
Memory controllers employ dynamic scheduling adaptations to optimize performance for different workloads. These adaptations include transaction reordering, request batching, and adaptive page policies. The controllers can analyze access patterns in real-time and adjust scheduling policies accordingly, switching between open-page and close-page policies or modifying request priorities based on detected access patterns to maximize memory throughput and minimize latency.Expand Specific Solutions
Leading HBM4 Controller Manufacturers and Ecosystem
The HBM4 Controller Architecture market is currently in an early growth phase, characterized by increasing demand for high-bandwidth memory solutions in AI, data centers, and high-performance computing applications. The competitive landscape features established semiconductor giants like Intel, NVIDIA, AMD, and Samsung Electronics leading technical innovation, with IBM and Qualcomm also making significant contributions to scheduling and arbitration technologies. The market is projected to expand rapidly as AI workloads drive demand for more efficient memory solutions. Technology maturity varies, with companies like NVIDIA and Samsung demonstrating advanced implementations, while Huawei, Intel, and AMD are accelerating development to close gaps in controller architecture optimization for fairness and scheduling efficiency across diverse workloads.
Intel Corp.
Technical Solution: Intel's approach to HBM4 controller architectures centers on their disaggregated memory architecture strategy. Their controllers implement a hierarchical scheduling system that categorizes memory requests based on urgency, data dependency, and application priority. Intel has developed proprietary arbitration algorithms that dynamically adjust to changing workload characteristics, particularly optimized for data center and high-performance computing environments. Their HBM4 controllers feature dedicated quality-of-service mechanisms that ensure critical applications receive guaranteed memory bandwidth while maintaining fair access for lower-priority tasks. Intel's architecture incorporates advanced power management features that selectively power down inactive memory channels and adjust refresh rates based on utilization patterns. The controllers also implement sophisticated error detection and correction mechanisms that maintain data integrity without significant performance penalties, critical for enterprise applications where reliability is paramount alongside performance considerations.
Strengths: Robust integration with Intel's CPU architectures providing optimized memory access patterns; strong focus on reliability and error correction suitable for enterprise deployments; power efficiency optimizations that balance performance and energy consumption. Weaknesses: Less optimized for graphics-intensive workloads compared to GPU-focused competitors; potentially higher latency in mixed workload scenarios; complex implementation that may require significant silicon area.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed innovative HBM4 controller architectures focused on telecommunications and cloud computing applications. Their controllers implement a quality-of-service driven scheduling system that categorizes memory requests based on application criticality and service-level agreements. Huawei's arbitration mechanisms incorporate sophisticated traffic shaping algorithms that prevent bandwidth hogging while ensuring deterministic performance for time-sensitive applications. Their HBM4 controllers feature dedicated hardware accelerators for common networking and telecommunications operations, reducing CPU overhead for packet processing and routing tasks. Huawei has implemented advanced virtualization support in their memory controllers, allowing for efficient resource partitioning across multiple tenants in cloud environments. Their architecture includes specialized handling for compressed data formats, reducing effective bandwidth requirements for certain workloads. The controllers also incorporate machine learning-based predictive scheduling that adapts to observed traffic patterns over time, continuously optimizing memory access efficiency based on workload characteristics.
Strengths: Excellent optimization for telecommunications and networking workloads; strong focus on virtualization and multi-tenant scenarios; sophisticated quality-of-service mechanisms ensuring deterministic performance. Weaknesses: Potentially less optimized for graphics and consumer applications; complex implementation requiring significant configuration for optimal performance; possible challenges with ecosystem integration outside of Huawei's own hardware platforms.
Critical Patents in HBM4 Controller Fairness Mechanisms
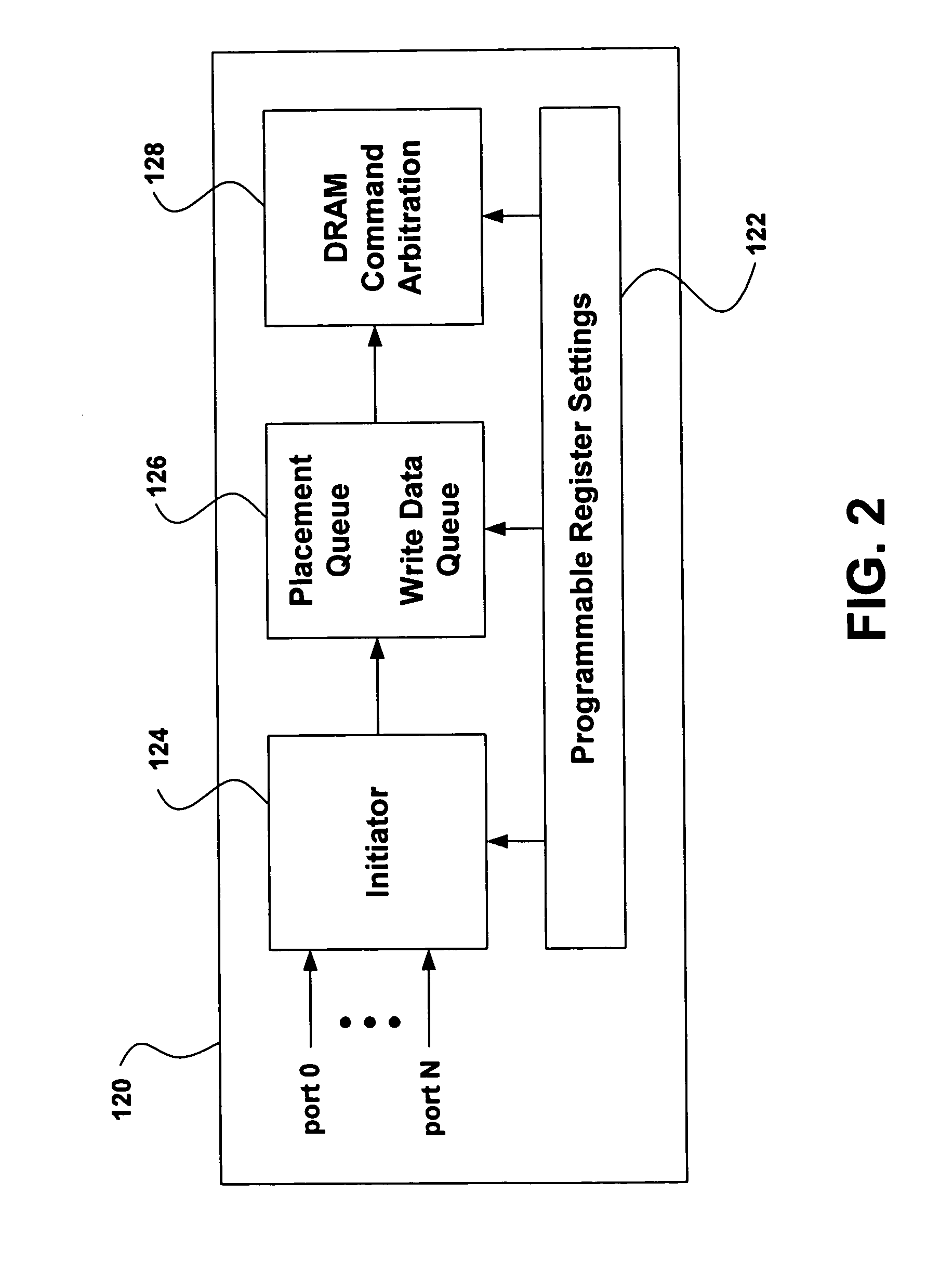
Memory controller with pseudo-channel support
PatentPendingUS20250061071A1
Innovation
- A memory controller architecture that includes separate pseudo-channel pipeline circuits for each pseudo channel, allowing for independent decoding, command queuing, and arbitration, thereby enabling efficient reordering and prioritization of accesses based on access patterns.




Method and apparatus for multi-port memory controller
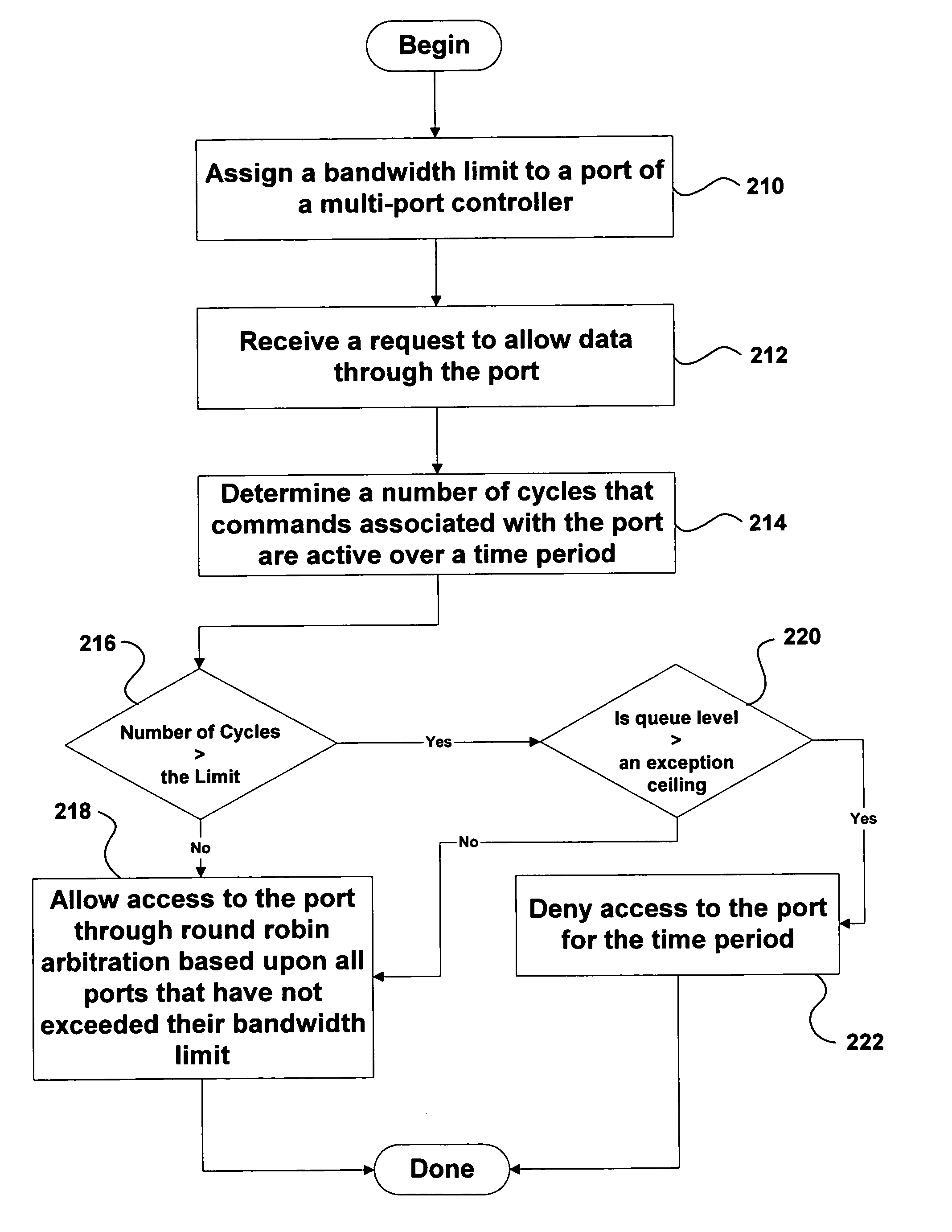
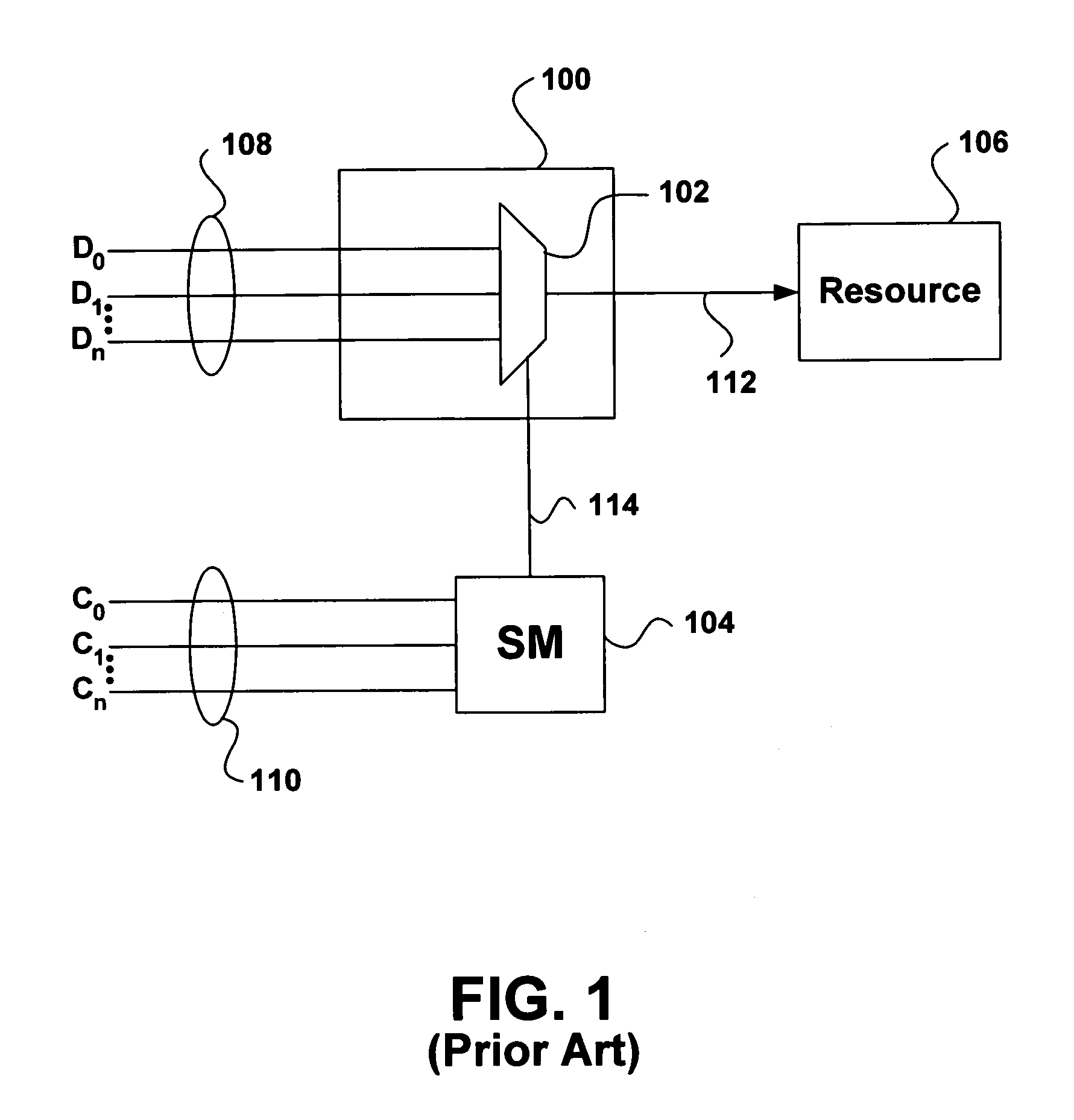
PatentInactiveUS7054968B2
Innovation
- Implementing a feedback mechanism in the arbitration scheme to consider both latency and bandwidth factors, allowing the state machine to select data based on past bandwidth usage and available bandwidth, thereby optimizing data transfer.

Power Efficiency Considerations in HBM4 Controller Design
Power efficiency has emerged as a critical consideration in HBM4 controller design, particularly as data centers and high-performance computing environments face increasing energy constraints. The HBM4 memory standard, with its significantly higher bandwidth capabilities compared to previous generations, introduces new power management challenges that must be addressed through innovative controller architectures.
The power consumption profile of HBM4 systems is dominated by three primary components: the controller logic itself, the physical interface (PHY), and the memory devices. Controller-level optimizations can yield substantial energy savings across the entire memory subsystem. Advanced power gating techniques have been developed specifically for HBM4 controllers, allowing for fine-grained deactivation of unused controller components during periods of low memory activity.
Dynamic voltage and frequency scaling (DVFS) mechanisms have been integrated into modern HBM4 controller designs, enabling runtime adjustments based on workload characteristics. These systems continuously monitor memory traffic patterns and can scale controller operating parameters to match current bandwidth requirements, significantly reducing power consumption during non-peak periods while maintaining performance guarantees when needed.
Request scheduling algorithms within HBM4 controllers have been enhanced with power-aware features that consider not only traditional metrics like latency and throughput but also energy consumption. These algorithms strategically batch memory operations to maximize the efficiency of power state transitions and reduce the energy overhead associated with frequent state changes.
Thermal management has become increasingly sophisticated in HBM4 controller designs, with integrated thermal sensors and adaptive throttling mechanisms that prevent overheating while minimizing performance impact. The 3D stacked nature of HBM4 creates unique thermal challenges that controllers must actively manage to maintain both reliability and energy efficiency.
Low-power standby modes represent another significant advancement in HBM4 controller technology. These modes implement tiered power states with varying wake-up latencies, allowing systems to balance power savings against responsiveness requirements. Controllers can intelligently predict memory access patterns to determine the optimal standby state for current operating conditions.
The arbitration mechanisms in HBM4 controllers have also been redesigned with power efficiency in mind, incorporating awareness of the energy costs associated with different memory operations. This allows for intelligent scheduling decisions that minimize overall system power consumption while still meeting performance requirements and maintaining fairness between competing memory requests.
The power consumption profile of HBM4 systems is dominated by three primary components: the controller logic itself, the physical interface (PHY), and the memory devices. Controller-level optimizations can yield substantial energy savings across the entire memory subsystem. Advanced power gating techniques have been developed specifically for HBM4 controllers, allowing for fine-grained deactivation of unused controller components during periods of low memory activity.
Dynamic voltage and frequency scaling (DVFS) mechanisms have been integrated into modern HBM4 controller designs, enabling runtime adjustments based on workload characteristics. These systems continuously monitor memory traffic patterns and can scale controller operating parameters to match current bandwidth requirements, significantly reducing power consumption during non-peak periods while maintaining performance guarantees when needed.
Request scheduling algorithms within HBM4 controllers have been enhanced with power-aware features that consider not only traditional metrics like latency and throughput but also energy consumption. These algorithms strategically batch memory operations to maximize the efficiency of power state transitions and reduce the energy overhead associated with frequent state changes.
Thermal management has become increasingly sophisticated in HBM4 controller designs, with integrated thermal sensors and adaptive throttling mechanisms that prevent overheating while minimizing performance impact. The 3D stacked nature of HBM4 creates unique thermal challenges that controllers must actively manage to maintain both reliability and energy efficiency.
Low-power standby modes represent another significant advancement in HBM4 controller technology. These modes implement tiered power states with varying wake-up latencies, allowing systems to balance power savings against responsiveness requirements. Controllers can intelligently predict memory access patterns to determine the optimal standby state for current operating conditions.
The arbitration mechanisms in HBM4 controllers have also been redesigned with power efficiency in mind, incorporating awareness of the energy costs associated with different memory operations. This allows for intelligent scheduling decisions that minimize overall system power consumption while still meeting performance requirements and maintaining fairness between competing memory requests.
Integration Strategies with AI and HPC Workloads
The integration of HBM4 memory controllers with AI and HPC workloads represents a critical frontier in high-performance computing architecture. As these workloads continue to demand unprecedented memory bandwidth and capacity, HBM4 controllers must be specifically optimized to handle their unique access patterns and requirements.
AI workloads, particularly deep learning training and inference, exhibit distinct memory access characteristics including high spatial locality during matrix operations and variable temporal locality depending on model architecture. Effective integration strategies must account for these patterns by implementing specialized scheduling policies that prioritize batch processing of related memory requests, thereby maximizing HBM4 row buffer utilization.
For HPC applications, which often involve complex scientific simulations and data analytics, memory access patterns tend to be more irregular and data-dependent. Integration approaches must therefore incorporate adaptive scheduling algorithms that can dynamically adjust to changing access patterns during execution phases. This adaptability is crucial for maintaining high memory throughput across diverse computational kernels.
Memory-centric computing paradigms offer promising integration pathways for both AI and HPC workloads. By implementing near-memory processing capabilities within the HBM4 stack or controller logic, certain operations can be offloaded directly to the memory subsystem, reducing data movement and improving energy efficiency. This approach is particularly beneficial for bandwidth-bound operations common in both domains.
Quality of Service (QoS) mechanisms represent another essential integration strategy. In multi-tenant environments where AI and HPC workloads may compete for memory resources, HBM4 controllers must implement sophisticated arbitration schemes that ensure fair resource allocation while maintaining performance guarantees for critical applications.
Software-hardware co-design approaches are increasingly important for optimal integration. Memory-aware compilers and runtime systems can work in concert with HBM4 controllers to optimize data placement and movement, potentially leveraging controller-exposed interfaces for application-specific memory management policies.
Looking forward, reconfigurable HBM4 controller architectures may emerge as a dominant integration strategy, allowing dynamic adaptation of scheduling and arbitration policies based on workload characteristics. Such flexibility would enable systems to seamlessly transition between AI training phases, inference operations, and various HPC computational patterns while maintaining optimal memory subsystem performance.
AI workloads, particularly deep learning training and inference, exhibit distinct memory access characteristics including high spatial locality during matrix operations and variable temporal locality depending on model architecture. Effective integration strategies must account for these patterns by implementing specialized scheduling policies that prioritize batch processing of related memory requests, thereby maximizing HBM4 row buffer utilization.
For HPC applications, which often involve complex scientific simulations and data analytics, memory access patterns tend to be more irregular and data-dependent. Integration approaches must therefore incorporate adaptive scheduling algorithms that can dynamically adjust to changing access patterns during execution phases. This adaptability is crucial for maintaining high memory throughput across diverse computational kernels.
Memory-centric computing paradigms offer promising integration pathways for both AI and HPC workloads. By implementing near-memory processing capabilities within the HBM4 stack or controller logic, certain operations can be offloaded directly to the memory subsystem, reducing data movement and improving energy efficiency. This approach is particularly beneficial for bandwidth-bound operations common in both domains.
Quality of Service (QoS) mechanisms represent another essential integration strategy. In multi-tenant environments where AI and HPC workloads may compete for memory resources, HBM4 controllers must implement sophisticated arbitration schemes that ensure fair resource allocation while maintaining performance guarantees for critical applications.
Software-hardware co-design approaches are increasingly important for optimal integration. Memory-aware compilers and runtime systems can work in concert with HBM4 controllers to optimize data placement and movement, potentially leveraging controller-exposed interfaces for application-specific memory management policies.
Looking forward, reconfigurable HBM4 controller architectures may emerge as a dominant integration strategy, allowing dynamic adaptation of scheduling and arbitration policies based on workload characteristics. Such flexibility would enable systems to seamlessly transition between AI training phases, inference operations, and various HPC computational patterns while maintaining optimal memory subsystem performance.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!