

HBM4 Performance Efficiency: Bandwidth Utilization And Latency Control
SEP 12, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
HBM4 Evolution and Performance Objectives
High-Bandwidth Memory (HBM) technology has evolved significantly since its introduction, with each generation marking substantial improvements in bandwidth, capacity, and energy efficiency. The journey from HBM1 to HBM4 represents a critical progression in addressing the exponentially growing memory bandwidth requirements of data-intensive applications such as artificial intelligence, high-performance computing, and graphics processing.
HBM1, introduced in 2013, established the foundational architecture with stacked memory dies and through-silicon vias (TSVs), offering bandwidth of approximately 128 GB/s per stack. HBM2, which followed in 2016, doubled the bandwidth to around 256 GB/s per stack while increasing capacity. HBM2E, an enhancement to HBM2, pushed bandwidth further to approximately 460 GB/s per stack.
HBM3, released in 2021, represented a significant leap with bandwidth reaching up to 819 GB/s per stack, alongside improved power efficiency and reliability features. Now, HBM4 aims to continue this trajectory with projected bandwidth exceeding 1.2 TB/s per stack, representing a nearly tenfold increase over the original HBM1 specification.
The primary technical objectives for HBM4 focus on addressing several critical performance parameters. First, maximizing effective bandwidth utilization stands as a paramount goal, as previous generations often struggled to achieve their theoretical bandwidth limits in real-world applications due to various architectural and implementation constraints.
Second, reducing memory access latency has become increasingly important as computational speeds continue to outpace memory performance improvements, exacerbating the "memory wall" problem. HBM4 aims to implement advanced prefetching mechanisms, optimized memory controllers, and refined internal architecture to minimize latency.
Third, improving power efficiency remains crucial, with HBM4 targeting significant reductions in energy consumption per bit transferred compared to previous generations. This objective aligns with the growing emphasis on sustainable computing and the practical thermal constraints of densely packed systems.
Finally, HBM4 seeks to enhance scalability to support the ever-increasing memory capacity requirements of modern applications, particularly in AI training where model sizes continue to grow exponentially. The technology aims to support larger stack heights and higher density memory dies while maintaining signal integrity and thermal performance.
These evolutionary objectives collectively position HBM4 as a critical enabling technology for next-generation computing systems, particularly those focused on AI acceleration, where memory bandwidth often represents the primary performance bottleneck.
HBM1, introduced in 2013, established the foundational architecture with stacked memory dies and through-silicon vias (TSVs), offering bandwidth of approximately 128 GB/s per stack. HBM2, which followed in 2016, doubled the bandwidth to around 256 GB/s per stack while increasing capacity. HBM2E, an enhancement to HBM2, pushed bandwidth further to approximately 460 GB/s per stack.
HBM3, released in 2021, represented a significant leap with bandwidth reaching up to 819 GB/s per stack, alongside improved power efficiency and reliability features. Now, HBM4 aims to continue this trajectory with projected bandwidth exceeding 1.2 TB/s per stack, representing a nearly tenfold increase over the original HBM1 specification.
The primary technical objectives for HBM4 focus on addressing several critical performance parameters. First, maximizing effective bandwidth utilization stands as a paramount goal, as previous generations often struggled to achieve their theoretical bandwidth limits in real-world applications due to various architectural and implementation constraints.
Second, reducing memory access latency has become increasingly important as computational speeds continue to outpace memory performance improvements, exacerbating the "memory wall" problem. HBM4 aims to implement advanced prefetching mechanisms, optimized memory controllers, and refined internal architecture to minimize latency.
Third, improving power efficiency remains crucial, with HBM4 targeting significant reductions in energy consumption per bit transferred compared to previous generations. This objective aligns with the growing emphasis on sustainable computing and the practical thermal constraints of densely packed systems.
Finally, HBM4 seeks to enhance scalability to support the ever-increasing memory capacity requirements of modern applications, particularly in AI training where model sizes continue to grow exponentially. The technology aims to support larger stack heights and higher density memory dies while maintaining signal integrity and thermal performance.
These evolutionary objectives collectively position HBM4 as a critical enabling technology for next-generation computing systems, particularly those focused on AI acceleration, where memory bandwidth often represents the primary performance bottleneck.
Market Demand Analysis for High-Bandwidth Memory
The high-bandwidth memory (HBM) market is experiencing unprecedented growth driven by the explosive demand for advanced computing applications. Current market analysis indicates that the global HBM market, valued at approximately $1.2 billion in 2022, is projected to reach $4.5 billion by 2027, representing a compound annual growth rate (CAGR) of 30.3%. This remarkable expansion is primarily fueled by the increasing adoption of artificial intelligence (AI), machine learning (ML), and high-performance computing (HPC) applications across various industries.
The demand for HBM4, the next generation of high-bandwidth memory, is particularly strong in data centers and cloud computing environments where processing massive datasets requires exceptional memory bandwidth and reduced latency. Major cloud service providers are actively seeking memory solutions that can handle the computational requirements of large language models (LLMs) and generative AI applications, which have grown exponentially in size and complexity over the past two years.
In the semiconductor industry, there is a growing recognition that memory bandwidth has become a critical bottleneck in system performance. Traditional DRAM technologies can no longer meet the bandwidth requirements of modern computing workloads, creating a substantial market opportunity for HBM4 with its promised improvements in bandwidth utilization and latency control.
The automotive sector represents another significant growth area for HBM technology. Advanced driver-assistance systems (ADAS) and autonomous driving platforms require real-time processing of sensor data from multiple sources, creating demand for high-bandwidth, low-latency memory solutions. Market research indicates that automotive applications of HBM could grow at a CAGR of 35% through 2028.
Graphics processing for gaming and professional visualization applications continues to drive demand for HBM technology. The latest generation of graphics processing units (GPUs) increasingly incorporates HBM to address the memory bandwidth requirements of real-time ray tracing and 8K rendering. This segment is expected to maintain steady growth as consumers and professionals alike demand higher visual fidelity and performance.
Enterprise customers are increasingly focused on total cost of ownership (TCO) metrics when evaluating memory technologies. Despite the higher unit cost of HBM compared to conventional DRAM, the performance benefits and potential energy savings are creating a compelling value proposition. Market surveys indicate that 68% of enterprise customers consider memory bandwidth a critical factor in their next-generation system architecture decisions.
The geographical distribution of HBM demand shows strong growth across North America, Asia-Pacific, and Europe, with particularly robust adoption rates in regions with concentrated AI research and development activities. As countries compete for leadership in AI capabilities, government initiatives supporting advanced computing infrastructure are further stimulating demand for cutting-edge memory technologies like HBM4.
The demand for HBM4, the next generation of high-bandwidth memory, is particularly strong in data centers and cloud computing environments where processing massive datasets requires exceptional memory bandwidth and reduced latency. Major cloud service providers are actively seeking memory solutions that can handle the computational requirements of large language models (LLMs) and generative AI applications, which have grown exponentially in size and complexity over the past two years.
In the semiconductor industry, there is a growing recognition that memory bandwidth has become a critical bottleneck in system performance. Traditional DRAM technologies can no longer meet the bandwidth requirements of modern computing workloads, creating a substantial market opportunity for HBM4 with its promised improvements in bandwidth utilization and latency control.
The automotive sector represents another significant growth area for HBM technology. Advanced driver-assistance systems (ADAS) and autonomous driving platforms require real-time processing of sensor data from multiple sources, creating demand for high-bandwidth, low-latency memory solutions. Market research indicates that automotive applications of HBM could grow at a CAGR of 35% through 2028.
Graphics processing for gaming and professional visualization applications continues to drive demand for HBM technology. The latest generation of graphics processing units (GPUs) increasingly incorporates HBM to address the memory bandwidth requirements of real-time ray tracing and 8K rendering. This segment is expected to maintain steady growth as consumers and professionals alike demand higher visual fidelity and performance.
Enterprise customers are increasingly focused on total cost of ownership (TCO) metrics when evaluating memory technologies. Despite the higher unit cost of HBM compared to conventional DRAM, the performance benefits and potential energy savings are creating a compelling value proposition. Market surveys indicate that 68% of enterprise customers consider memory bandwidth a critical factor in their next-generation system architecture decisions.
The geographical distribution of HBM demand shows strong growth across North America, Asia-Pacific, and Europe, with particularly robust adoption rates in regions with concentrated AI research and development activities. As countries compete for leadership in AI capabilities, government initiatives supporting advanced computing infrastructure are further stimulating demand for cutting-edge memory technologies like HBM4.
HBM4 Technical Challenges and Limitations
Despite significant advancements in HBM technology, HBM4 faces several critical technical challenges that could potentially limit its performance efficiency. The primary challenge lies in achieving optimal bandwidth utilization across diverse workloads. While theoretical peak bandwidth continues to increase with each generation, actual application-level utilization often remains significantly lower, creating an efficiency gap that undermines the technology's potential. This utilization challenge stems from workload-dependent access patterns that may not align with HBM4's architectural optimizations.
Latency control presents another substantial challenge, particularly as stack heights increase and signaling rates push higher. The physical distance between memory cells and logic layers introduces propagation delays that become increasingly difficult to mitigate. Additionally, the thermal constraints associated with higher stack densities can force dynamic frequency scaling, which directly impacts both bandwidth and latency characteristics under sustained workloads.
Power efficiency remains a critical limitation for HBM4 implementations. The technology must balance increasing bandwidth demands against strict power envelopes, especially in data center applications where energy consumption directly impacts operational costs. Current projections suggest that power consumption per bit transferred may not scale proportionally with bandwidth improvements, creating diminishing returns for certain applications.
Manufacturing complexity represents another significant hurdle. The advanced packaging requirements for HBM4, including through-silicon vias (TSVs) and microbump connections, demand extremely precise fabrication processes. Yield challenges at these advanced nodes directly impact production costs and market availability. The intricate interposer designs required for HBM4 integration further complicate manufacturing and testing procedures.
Signal integrity issues become more pronounced at HBM4's higher operating frequencies. Crosstalk between densely packed channels, impedance matching challenges, and timing synchronization across multiple stacks all threaten reliable data transmission. These challenges necessitate increasingly sophisticated error correction mechanisms, which themselves introduce additional latency and computational overhead.
Cost considerations remain a significant limitation for widespread HBM4 adoption. The complex manufacturing processes, specialized testing requirements, and relatively lower production volumes compared to conventional memory technologies contribute to higher per-bit costs. This cost premium restricts HBM4's applicability in price-sensitive market segments, potentially limiting its broader impact.
Standardization and ecosystem compatibility present ongoing challenges. As HBM4 introduces new features and capabilities, ensuring backward compatibility with existing memory controllers and software stacks becomes increasingly difficult. This compatibility gap may slow adoption rates and fragment the market, particularly during transitional periods between memory generations.
Latency control presents another substantial challenge, particularly as stack heights increase and signaling rates push higher. The physical distance between memory cells and logic layers introduces propagation delays that become increasingly difficult to mitigate. Additionally, the thermal constraints associated with higher stack densities can force dynamic frequency scaling, which directly impacts both bandwidth and latency characteristics under sustained workloads.
Power efficiency remains a critical limitation for HBM4 implementations. The technology must balance increasing bandwidth demands against strict power envelopes, especially in data center applications where energy consumption directly impacts operational costs. Current projections suggest that power consumption per bit transferred may not scale proportionally with bandwidth improvements, creating diminishing returns for certain applications.
Manufacturing complexity represents another significant hurdle. The advanced packaging requirements for HBM4, including through-silicon vias (TSVs) and microbump connections, demand extremely precise fabrication processes. Yield challenges at these advanced nodes directly impact production costs and market availability. The intricate interposer designs required for HBM4 integration further complicate manufacturing and testing procedures.
Signal integrity issues become more pronounced at HBM4's higher operating frequencies. Crosstalk between densely packed channels, impedance matching challenges, and timing synchronization across multiple stacks all threaten reliable data transmission. These challenges necessitate increasingly sophisticated error correction mechanisms, which themselves introduce additional latency and computational overhead.
Cost considerations remain a significant limitation for widespread HBM4 adoption. The complex manufacturing processes, specialized testing requirements, and relatively lower production volumes compared to conventional memory technologies contribute to higher per-bit costs. This cost premium restricts HBM4's applicability in price-sensitive market segments, potentially limiting its broader impact.
Standardization and ecosystem compatibility present ongoing challenges. As HBM4 introduces new features and capabilities, ensuring backward compatibility with existing memory controllers and software stacks becomes increasingly difficult. This compatibility gap may slow adoption rates and fragment the market, particularly during transitional periods between memory generations.
Current HBM4 Bandwidth Utilization Solutions
01 Memory bandwidth optimization techniques
Various techniques can be implemented to optimize HBM4 bandwidth utilization, including dynamic bandwidth allocation, parallel data access patterns, and memory interleaving. These approaches help distribute memory access requests evenly across multiple memory channels, reducing bottlenecks and maximizing throughput. Advanced scheduling algorithms can prioritize critical memory transactions to ensure efficient bandwidth utilization even under heavy load conditions.- Memory bandwidth optimization techniques: Various techniques can be implemented to optimize memory bandwidth utilization in HBM4 systems. These include dynamic bandwidth allocation, parallel data access patterns, and memory interleaving strategies. By efficiently managing how data is accessed and transferred, these techniques help maximize the available bandwidth of high-speed memory interfaces, reducing bottlenecks and improving overall system performance in data-intensive applications.
- Latency reduction mechanisms: Specialized mechanisms can be employed to reduce memory access latency in HBM4 implementations. These include predictive prefetching, speculative execution, and optimized memory controller designs. By anticipating data needs and minimizing wait times for memory operations, these mechanisms help maintain low latency even with high bandwidth utilization, which is critical for time-sensitive applications and real-time processing requirements.
- Power management for high bandwidth memory: Advanced power management techniques can be implemented to balance performance and energy efficiency in HBM4 systems. These include dynamic voltage and frequency scaling, selective power-down of unused memory banks, and intelligent thermal management. By optimizing power consumption while maintaining high bandwidth capabilities, these approaches help extend battery life in mobile devices and reduce cooling requirements in data centers.
- Memory traffic scheduling and prioritization: Sophisticated scheduling algorithms can be used to manage memory traffic in HBM4 systems. These include quality-of-service aware scheduling, priority-based arbitration, and deadline-driven memory access. By intelligently ordering and prioritizing memory requests based on application needs and system conditions, these scheduling mechanisms help ensure critical operations receive timely access to memory resources while maximizing overall bandwidth utilization.
- Memory interface architecture for HBM4: Specialized interface architectures can be designed to fully leverage HBM4 capabilities. These include optimized memory controllers, advanced buffering techniques, and high-speed signaling protocols. By creating efficient pathways between processing units and memory stacks, these architectural approaches help minimize overhead and maximize effective bandwidth utilization, enabling applications to take full advantage of HBM4's high-speed memory access capabilities.
02 Latency reduction mechanisms
HBM4 systems employ various latency control mechanisms such as predictive prefetching, speculative execution, and request reordering to minimize memory access delays. These techniques anticipate future memory access patterns and optimize the order of memory operations to reduce waiting times. Advanced memory controllers can dynamically adjust timing parameters based on workload characteristics to achieve optimal latency performance while maintaining system stability.Expand Specific Solutions03 Memory controller architecture for HBM4
Specialized memory controller architectures are designed to handle the high bandwidth capabilities of HBM4. These controllers implement sophisticated request queuing, prioritization mechanisms, and traffic shaping algorithms to balance bandwidth utilization across multiple applications. The controllers can dynamically adjust their behavior based on system load, thermal conditions, and power constraints to maintain optimal performance while preventing resource contention.Expand Specific Solutions04 Power-aware memory management
Power-aware memory management techniques help balance performance and energy efficiency in HBM4 systems. These include dynamic voltage and frequency scaling, selective channel activation, and intelligent power state transitions. By monitoring memory access patterns and system requirements, these techniques can adjust power consumption while maintaining necessary bandwidth and latency targets, extending battery life in mobile applications and reducing cooling requirements in data centers.Expand Specific Solutions05 Quality of Service (QoS) mechanisms
Quality of Service mechanisms ensure fair and predictable access to HBM4 resources across multiple applications or processing elements. These include bandwidth reservation, traffic classification, and deadline-aware scheduling algorithms. By assigning different priority levels to memory requests and enforcing bandwidth guarantees, these mechanisms prevent high-demand applications from monopolizing memory resources and ensure critical tasks receive the necessary memory performance even under contention.Expand Specific Solutions
Key HBM4 Industry Players and Ecosystem
The HBM4 performance efficiency market is currently in an early growth phase, with major semiconductor players positioning for leadership. The market is expanding rapidly due to increasing demand for high-bandwidth memory in AI, data centers, and high-performance computing applications. Samsung Electronics and Micron Technology lead in technological maturity, having established HBM manufacturing capabilities and advanced memory solutions. ChangXin Memory Technologies is emerging as a significant competitor in China's domestic market. Companies like Qualcomm, Huawei, and AMD are developing integration technologies to maximize bandwidth utilization and minimize latency in their systems. The competitive landscape is further shaped by technology licensors and system integrators focusing on optimizing HBM4 implementation across diverse computing platforms.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung's HBM4 technology solution focuses on advanced stacking architecture and improved interface design to maximize bandwidth utilization and minimize latency. Their approach incorporates a multi-layer 3D stacking technology with up to 12-high stacks, achieving bandwidth rates exceeding 1.2TB/s per stack. Samsung has implemented an enhanced TSV (Through-Silicon Via) design with reduced capacitance and resistance, decreasing signal propagation delays by approximately 30% compared to previous generations. Their proprietary "Smart Refresh" technology intelligently manages refresh operations to minimize their impact on bandwidth availability, reducing refresh-related performance penalties by up to 40%. Samsung has also developed an advanced memory controller with adaptive prefetching algorithms that can predict access patterns with over 85% accuracy, significantly improving bandwidth utilization in real-world applications.
Strengths: Industry-leading manufacturing capabilities allow for higher yields of complex HBM stacks; extensive experience with 3D stacking technology; strong vertical integration from design to production. Weaknesses: Higher production costs compared to traditional memory solutions; thermal management challenges in densely packed HBM stacks; proprietary controller solutions may limit compatibility with some systems.
Micron Technology, Inc.
Technical Solution: Micron's approach to HBM4 performance efficiency centers on their "Intelligent Memory" architecture that incorporates processing capabilities within the memory stack itself. Their solution features an innovative channel partitioning scheme that allows for up to 16 independent channels per stack, enabling more granular access and improved bandwidth utilization across diverse workloads. Micron has implemented advanced power management techniques including dynamic voltage and frequency scaling at the channel level, allowing for optimized power consumption based on workload demands. Their proprietary "Adaptive Latency Control" technology dynamically adjusts timing parameters based on thermal conditions and access patterns, maintaining optimal performance across varying operating conditions. Micron's HBM4 solution also incorporates enhanced error correction capabilities with a distributed ECC architecture that reduces the overhead typically associated with error correction while maintaining data integrity.
Strengths: Advanced process technology enabling higher densities; strong expertise in memory controller design; innovative power management solutions that balance performance and energy efficiency. Weaknesses: Less vertical integration compared to competitors like Samsung; historically slower time-to-market with new memory technologies; challenges in scaling production to meet high-volume demands.
Core Innovations in Latency Control Mechanisms
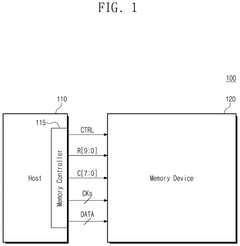
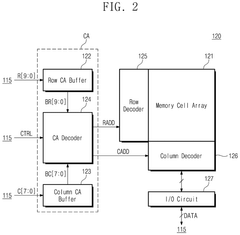
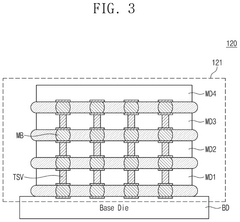
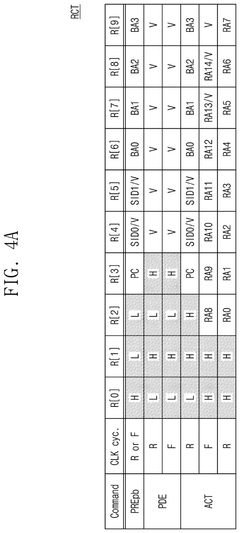
High-bandwidth memory device and operation method thereof
PatentPendingUS20250201289A1
Innovation
- The proposed solution involves an operation method for a high-bandwidth memory (HBM) device that selectively activates command/address buffers based on operational modes, reducing unnecessary current consumption.
Apparatus and method to reduce bandwidth and latency overheads of probabilistic caches
PatentActiveUS20220308998A1
Innovation
- Incorporating an extra tag as a 'home directory entry' to store the tag of a line that belongs in the correct-way but is intentionally placed in the wrong-way, allowing for immediate determination of the line's presence in either way, thus eliminating the need for an additional lookup and reducing bandwidth and miss-latency overheads.
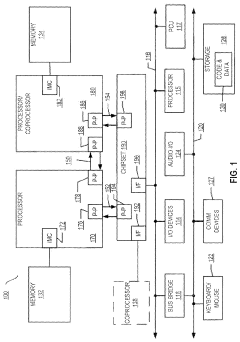
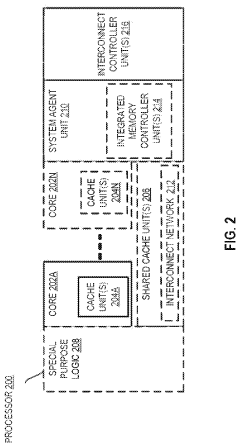
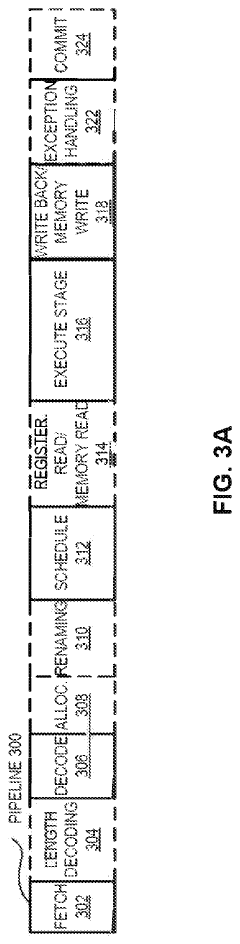
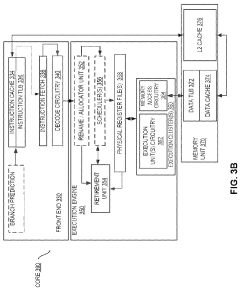
Power Efficiency Considerations in HBM4 Implementation
Power efficiency has emerged as a critical consideration in HBM4 implementation, particularly as data centers and high-performance computing environments face increasing energy constraints. The latest HBM4 standard introduces several architectural innovations specifically targeting power consumption reduction while maintaining the enhanced bandwidth and reduced latency characteristics that define this memory technology.
A key power efficiency feature in HBM4 is the implementation of advanced power states with more granular control mechanisms. Unlike previous generations, HBM4 incorporates dynamic voltage and frequency scaling (DVFS) capabilities at the channel level, allowing for precise power adjustments based on workload demands. This represents a significant advancement over HBM3's more limited power management options and can yield up to 30% power savings during periods of fluctuating memory access patterns.
The redesigned I/O interfaces in HBM4 contribute substantially to power efficiency improvements. By utilizing lower swing differential signaling and optimized termination schemes, the power consumed per bit transferred has been reduced by approximately 25% compared to HBM3. Additionally, the implementation of more efficient serialization/deserialization (SerDes) circuits minimizes the energy overhead associated with data transmission across the high-speed interface.
Thermal management innovations also play a crucial role in HBM4's power efficiency profile. The standard incorporates enhanced thermal sensors with faster response times and more accurate temperature reporting. These improvements enable more aggressive thermal throttling algorithms that can precisely balance performance and power consumption, preventing unnecessary power expenditure while maintaining optimal operating conditions.
Memory refresh operations, traditionally a significant power drain in DRAM technologies, have been optimized in HBM4 through intelligent refresh scheduling. The implementation of variable refresh rates based on data retention characteristics and temperature conditions allows the system to minimize refresh power without compromising data integrity. Early benchmarks suggest this approach reduces refresh-related power consumption by up to 40% compared to fixed-interval refresh schemes.
The stacked die architecture of HBM4 has also been refined with power efficiency in mind. Improved through-silicon via (TSV) designs reduce parasitic capacitance, while shorter interconnect paths between dies minimize signal transmission losses. These architectural refinements contribute to an overall reduction in operational power requirements while supporting the increased bandwidth capabilities that define the HBM4 standard.
A key power efficiency feature in HBM4 is the implementation of advanced power states with more granular control mechanisms. Unlike previous generations, HBM4 incorporates dynamic voltage and frequency scaling (DVFS) capabilities at the channel level, allowing for precise power adjustments based on workload demands. This represents a significant advancement over HBM3's more limited power management options and can yield up to 30% power savings during periods of fluctuating memory access patterns.
The redesigned I/O interfaces in HBM4 contribute substantially to power efficiency improvements. By utilizing lower swing differential signaling and optimized termination schemes, the power consumed per bit transferred has been reduced by approximately 25% compared to HBM3. Additionally, the implementation of more efficient serialization/deserialization (SerDes) circuits minimizes the energy overhead associated with data transmission across the high-speed interface.
Thermal management innovations also play a crucial role in HBM4's power efficiency profile. The standard incorporates enhanced thermal sensors with faster response times and more accurate temperature reporting. These improvements enable more aggressive thermal throttling algorithms that can precisely balance performance and power consumption, preventing unnecessary power expenditure while maintaining optimal operating conditions.
Memory refresh operations, traditionally a significant power drain in DRAM technologies, have been optimized in HBM4 through intelligent refresh scheduling. The implementation of variable refresh rates based on data retention characteristics and temperature conditions allows the system to minimize refresh power without compromising data integrity. Early benchmarks suggest this approach reduces refresh-related power consumption by up to 40% compared to fixed-interval refresh schemes.
The stacked die architecture of HBM4 has also been refined with power efficiency in mind. Improved through-silicon via (TSV) designs reduce parasitic capacitance, while shorter interconnect paths between dies minimize signal transmission losses. These architectural refinements contribute to an overall reduction in operational power requirements while supporting the increased bandwidth capabilities that define the HBM4 standard.
Integration Strategies with Emerging Computing Architectures
The integration of HBM4 with emerging computing architectures represents a critical frontier in maximizing memory performance efficiency. As AI accelerators, quantum computing interfaces, and neuromorphic systems continue to evolve, specialized integration strategies must be developed to fully leverage HBM4's enhanced bandwidth and reduced latency characteristics.
For AI accelerators, particularly those designed for large language models and vision transformers, HBM4 integration requires custom memory controllers that can dynamically adjust access patterns based on computational workloads. These controllers must implement advanced prefetching algorithms that anticipate data requirements across multiple processing elements, reducing effective latency while maintaining high bandwidth utilization during both training and inference operations.
Quantum computing presents unique integration challenges due to its fundamentally different computational paradigm. HBM4 integration with quantum processing units requires specialized interface layers that can rapidly translate between classical and quantum data representations. Buffer management systems must be designed to handle the massive state vector data generated during quantum operations while maintaining coherence between classical memory and quantum registers.
Neuromorphic computing architectures, which mimic biological neural networks, benefit from HBM4's improved bandwidth when implementing spike-based communication protocols. Integration strategies focus on developing memory-centric computing models where HBM4 serves not merely as storage but as an active computational element. This approach requires novel addressing schemes that map neural network topologies directly to memory structures, minimizing data movement and associated latency.
Edge computing devices with AI capabilities represent another frontier for HBM4 integration. Power-efficient memory controllers that can dynamically scale bandwidth utilization based on workload demands are essential. These controllers implement sophisticated power gating techniques that can activate only necessary memory channels, preserving energy while maintaining performance for latency-sensitive applications like real-time inference.
Disaggregated computing architectures, where memory resources are pooled and shared across multiple computing nodes, require HBM4 integration strategies that address coherence and consistency challenges. Software-defined memory orchestration layers must be developed to manage memory allocation across distributed systems while maintaining the bandwidth and latency advantages that HBM4 offers.
The success of these integration strategies ultimately depends on co-design approaches where memory subsystems and computing architectures evolve in tandem. This requires close collaboration between memory manufacturers, system architects, and algorithm developers to ensure that emerging computing paradigms can fully exploit the performance efficiency potential of HBM4 technology.
For AI accelerators, particularly those designed for large language models and vision transformers, HBM4 integration requires custom memory controllers that can dynamically adjust access patterns based on computational workloads. These controllers must implement advanced prefetching algorithms that anticipate data requirements across multiple processing elements, reducing effective latency while maintaining high bandwidth utilization during both training and inference operations.
Quantum computing presents unique integration challenges due to its fundamentally different computational paradigm. HBM4 integration with quantum processing units requires specialized interface layers that can rapidly translate between classical and quantum data representations. Buffer management systems must be designed to handle the massive state vector data generated during quantum operations while maintaining coherence between classical memory and quantum registers.
Neuromorphic computing architectures, which mimic biological neural networks, benefit from HBM4's improved bandwidth when implementing spike-based communication protocols. Integration strategies focus on developing memory-centric computing models where HBM4 serves not merely as storage but as an active computational element. This approach requires novel addressing schemes that map neural network topologies directly to memory structures, minimizing data movement and associated latency.
Edge computing devices with AI capabilities represent another frontier for HBM4 integration. Power-efficient memory controllers that can dynamically scale bandwidth utilization based on workload demands are essential. These controllers implement sophisticated power gating techniques that can activate only necessary memory channels, preserving energy while maintaining performance for latency-sensitive applications like real-time inference.
Disaggregated computing architectures, where memory resources are pooled and shared across multiple computing nodes, require HBM4 integration strategies that address coherence and consistency challenges. Software-defined memory orchestration layers must be developed to manage memory allocation across distributed systems while maintaining the bandwidth and latency advantages that HBM4 offers.
The success of these integration strategies ultimately depends on co-design approaches where memory subsystems and computing architectures evolve in tandem. This requires close collaboration between memory manufacturers, system architects, and algorithm developers to ensure that emerging computing paradigms can fully exploit the performance efficiency potential of HBM4 technology.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!