HBM4 Field Reliability: Duty Cycles, Thermal Events And Mitigation
SEP 12, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
HBM4 Technology Evolution and Reliability Objectives
High Bandwidth Memory (HBM) technology has evolved significantly since its inception, with each generation bringing substantial improvements in bandwidth, capacity, and energy efficiency. The evolution from HBM1 to HBM4 represents a remarkable technological journey addressing the growing demands of data-intensive applications such as artificial intelligence, high-performance computing, and graphics processing. HBM4, as the latest iteration, aims to push the boundaries of memory performance while maintaining reliability under increasingly demanding operational conditions.
The development of HBM technology began with the first generation introduced in 2013, offering stacked memory with through-silicon vias (TSVs) to achieve higher bandwidth than traditional DRAM. HBM2 followed in 2016 with doubled bandwidth and capacity, while HBM2E in 2018 further enhanced these capabilities. HBM3, released in 2021, delivered significant improvements with bandwidths exceeding 800 GB/s. Now, HBM4 represents the cutting edge with projected bandwidths approaching 1.6 TB/s and higher stack densities.
A critical aspect of HBM4's technological advancement is the focus on field reliability under various operational conditions. As computing systems become more powerful and densely packed, memory components face increasingly challenging thermal environments. The reliability objectives for HBM4 specifically address performance consistency during different duty cycles and the ability to withstand thermal events without degradation or failure.
Key reliability objectives for HBM4 include maintaining data integrity during thermal fluctuations, ensuring consistent performance across varying workloads, and extending operational lifespan despite higher operating temperatures. These objectives are particularly important as HBM4 is expected to operate in more demanding environments than its predecessors, with higher power densities and more complex thermal management challenges.
The industry has recognized that traditional reliability testing methodologies may not adequately capture real-world usage patterns. Therefore, HBM4 reliability objectives incorporate more sophisticated testing regimes that simulate actual field conditions, including variable duty cycles and thermal events that mimic those encountered in data centers, edge computing environments, and high-performance computing clusters.
Another significant reliability objective is the development of robust mitigation strategies for thermal events. These include advanced thermal throttling mechanisms, improved heat dissipation designs, and intelligent power management systems that can respond dynamically to changing thermal conditions without significantly impacting performance or data integrity.
The evolution of HBM technology and its reliability objectives reflect the industry's commitment to meeting the growing demands of next-generation computing applications while ensuring that memory systems remain stable, efficient, and durable under increasingly challenging operational conditions.
The development of HBM technology began with the first generation introduced in 2013, offering stacked memory with through-silicon vias (TSVs) to achieve higher bandwidth than traditional DRAM. HBM2 followed in 2016 with doubled bandwidth and capacity, while HBM2E in 2018 further enhanced these capabilities. HBM3, released in 2021, delivered significant improvements with bandwidths exceeding 800 GB/s. Now, HBM4 represents the cutting edge with projected bandwidths approaching 1.6 TB/s and higher stack densities.
A critical aspect of HBM4's technological advancement is the focus on field reliability under various operational conditions. As computing systems become more powerful and densely packed, memory components face increasingly challenging thermal environments. The reliability objectives for HBM4 specifically address performance consistency during different duty cycles and the ability to withstand thermal events without degradation or failure.
Key reliability objectives for HBM4 include maintaining data integrity during thermal fluctuations, ensuring consistent performance across varying workloads, and extending operational lifespan despite higher operating temperatures. These objectives are particularly important as HBM4 is expected to operate in more demanding environments than its predecessors, with higher power densities and more complex thermal management challenges.
The industry has recognized that traditional reliability testing methodologies may not adequately capture real-world usage patterns. Therefore, HBM4 reliability objectives incorporate more sophisticated testing regimes that simulate actual field conditions, including variable duty cycles and thermal events that mimic those encountered in data centers, edge computing environments, and high-performance computing clusters.
Another significant reliability objective is the development of robust mitigation strategies for thermal events. These include advanced thermal throttling mechanisms, improved heat dissipation designs, and intelligent power management systems that can respond dynamically to changing thermal conditions without significantly impacting performance or data integrity.
The evolution of HBM technology and its reliability objectives reflect the industry's commitment to meeting the growing demands of next-generation computing applications while ensuring that memory systems remain stable, efficient, and durable under increasingly challenging operational conditions.
Market Demand Analysis for High-Bandwidth Memory Solutions
The high-bandwidth memory (HBM) market is experiencing unprecedented growth driven by the explosive demand for advanced computing applications. Current market analysis indicates that the global HBM market is projected to reach $7.6 billion by 2027, growing at a CAGR of approximately 32% from 2022. This remarkable expansion is primarily fueled by the increasing adoption of artificial intelligence, machine learning, and high-performance computing systems that require superior memory bandwidth and efficiency.
Data centers represent the largest market segment for HBM solutions, accounting for nearly 45% of the total demand. The exponential growth in cloud computing services and the deployment of AI-driven applications have created substantial demand for servers equipped with high-bandwidth memory capabilities. Major cloud service providers are actively upgrading their infrastructure to accommodate memory-intensive workloads, creating a sustained demand for advanced HBM solutions.
The emergence of HBM4 technology comes at a critical juncture when existing memory solutions are struggling to meet the performance requirements of next-generation AI training models. These models have grown from billions to trillions of parameters within just a few years, necessitating memory systems capable of delivering terabytes of data per second with minimal latency. Market research indicates that AI accelerator cards equipped with HBM4 could command premium pricing, with estimates suggesting a 30-40% price premium over previous-generation solutions.
Field reliability has emerged as a crucial market differentiator for HBM products. End users across various industries are increasingly prioritizing memory solutions that can maintain performance integrity under diverse operational conditions. A recent industry survey revealed that 78% of enterprise customers consider thermal management capabilities and reliability metrics as "very important" or "critical" factors in their HBM procurement decisions.
The automotive and edge computing sectors represent rapidly growing market segments for HBM solutions, with projected CAGRs of 41% and 37% respectively through 2027. These applications place unique demands on memory systems, requiring them to operate reliably under variable duty cycles and often challenging thermal environments. Automotive manufacturers developing advanced driver assistance systems and autonomous driving platforms are particularly concerned with memory reliability under extreme temperature conditions.
Geographic analysis shows that North America currently leads HBM adoption with approximately 42% market share, followed by Asia-Pacific at 38% and Europe at 16%. However, the Asia-Pacific region is expected to demonstrate the fastest growth rate over the next five years, driven by substantial investments in AI infrastructure and semiconductor manufacturing capabilities in countries like South Korea, Taiwan, and China.
Data centers represent the largest market segment for HBM solutions, accounting for nearly 45% of the total demand. The exponential growth in cloud computing services and the deployment of AI-driven applications have created substantial demand for servers equipped with high-bandwidth memory capabilities. Major cloud service providers are actively upgrading their infrastructure to accommodate memory-intensive workloads, creating a sustained demand for advanced HBM solutions.
The emergence of HBM4 technology comes at a critical juncture when existing memory solutions are struggling to meet the performance requirements of next-generation AI training models. These models have grown from billions to trillions of parameters within just a few years, necessitating memory systems capable of delivering terabytes of data per second with minimal latency. Market research indicates that AI accelerator cards equipped with HBM4 could command premium pricing, with estimates suggesting a 30-40% price premium over previous-generation solutions.
Field reliability has emerged as a crucial market differentiator for HBM products. End users across various industries are increasingly prioritizing memory solutions that can maintain performance integrity under diverse operational conditions. A recent industry survey revealed that 78% of enterprise customers consider thermal management capabilities and reliability metrics as "very important" or "critical" factors in their HBM procurement decisions.
The automotive and edge computing sectors represent rapidly growing market segments for HBM solutions, with projected CAGRs of 41% and 37% respectively through 2027. These applications place unique demands on memory systems, requiring them to operate reliably under variable duty cycles and often challenging thermal environments. Automotive manufacturers developing advanced driver assistance systems and autonomous driving platforms are particularly concerned with memory reliability under extreme temperature conditions.
Geographic analysis shows that North America currently leads HBM adoption with approximately 42% market share, followed by Asia-Pacific at 38% and Europe at 16%. However, the Asia-Pacific region is expected to demonstrate the fastest growth rate over the next five years, driven by substantial investments in AI infrastructure and semiconductor manufacturing capabilities in countries like South Korea, Taiwan, and China.
Current Challenges in HBM4 Field Reliability
HBM4 technology faces significant field reliability challenges that must be addressed for successful implementation in high-performance computing environments. The current generation of High Bandwidth Memory (HBM) already experiences reliability issues, and these are expected to intensify with HBM4's increased density, higher operating frequencies, and more complex integration requirements.
Thermal management represents one of the most critical challenges for HBM4 reliability. With operating frequencies potentially exceeding 8 Gbps and stack heights increasing to accommodate more memory capacity, heat dissipation becomes increasingly problematic. The compact 3D stacked design creates thermal hotspots that can lead to performance degradation, accelerated aging, and even catastrophic failure if not properly managed.
Signal integrity issues present another significant hurdle. As data rates increase, maintaining clean signal transmission between the memory controller and HBM4 becomes more difficult. The interposer technology used for connecting HBM4 to processors must evolve to handle these higher speeds while minimizing crosstalk, reflection, and other signal degradation factors that impact reliability.
Power integrity challenges are equally concerning. The higher bandwidth of HBM4 necessitates increased power consumption, creating potential voltage droop scenarios during high-activity periods. These power fluctuations can cause data corruption or system instability if not properly addressed through advanced power delivery networks and management techniques.
Duty cycle variations in real-world applications create additional reliability concerns. HBM4 memory must maintain stability across widely varying workloads, from sustained high-throughput computing to bursty, intermittent access patterns. Current testing methodologies often fail to accurately represent these diverse operational scenarios, potentially missing critical failure modes that only emerge under specific duty cycles.
Manufacturing process variations introduce further reliability challenges. As the manufacturing processes for HBM4 push toward finer geometries, the impact of process variations on individual memory cells increases. These variations can lead to inconsistent performance characteristics across different memory dies or even within the same stack.
Environmental factors such as temperature fluctuations, humidity, and mechanical stress also significantly impact HBM4 reliability. The complex package structure of HBM4, with numerous interconnects between stacked dies, is particularly vulnerable to coefficient of thermal expansion (CTE) mismatches that can lead to mechanical stress and eventual connection failure.
Effective error detection and correction mechanisms must evolve to address these challenges. Current ECC implementations may prove insufficient for the error rates anticipated in HBM4 deployments, necessitating more sophisticated approaches to maintain data integrity without excessive performance penalties.
Thermal management represents one of the most critical challenges for HBM4 reliability. With operating frequencies potentially exceeding 8 Gbps and stack heights increasing to accommodate more memory capacity, heat dissipation becomes increasingly problematic. The compact 3D stacked design creates thermal hotspots that can lead to performance degradation, accelerated aging, and even catastrophic failure if not properly managed.
Signal integrity issues present another significant hurdle. As data rates increase, maintaining clean signal transmission between the memory controller and HBM4 becomes more difficult. The interposer technology used for connecting HBM4 to processors must evolve to handle these higher speeds while minimizing crosstalk, reflection, and other signal degradation factors that impact reliability.
Power integrity challenges are equally concerning. The higher bandwidth of HBM4 necessitates increased power consumption, creating potential voltage droop scenarios during high-activity periods. These power fluctuations can cause data corruption or system instability if not properly addressed through advanced power delivery networks and management techniques.
Duty cycle variations in real-world applications create additional reliability concerns. HBM4 memory must maintain stability across widely varying workloads, from sustained high-throughput computing to bursty, intermittent access patterns. Current testing methodologies often fail to accurately represent these diverse operational scenarios, potentially missing critical failure modes that only emerge under specific duty cycles.
Manufacturing process variations introduce further reliability challenges. As the manufacturing processes for HBM4 push toward finer geometries, the impact of process variations on individual memory cells increases. These variations can lead to inconsistent performance characteristics across different memory dies or even within the same stack.
Environmental factors such as temperature fluctuations, humidity, and mechanical stress also significantly impact HBM4 reliability. The complex package structure of HBM4, with numerous interconnects between stacked dies, is particularly vulnerable to coefficient of thermal expansion (CTE) mismatches that can lead to mechanical stress and eventual connection failure.
Effective error detection and correction mechanisms must evolve to address these challenges. Current ECC implementations may prove insufficient for the error rates anticipated in HBM4 deployments, necessitating more sophisticated approaches to maintain data integrity without excessive performance penalties.
Existing Thermal Management Solutions for HBM4
01 Thermal management for HBM reliability
Effective thermal management is crucial for ensuring the field reliability of HBM4 memory systems. High-bandwidth memory generates significant heat during operation, which can lead to performance degradation and reduced lifespan if not properly managed. Advanced cooling solutions, including heat spreaders, thermal interface materials, and active cooling systems are implemented to maintain optimal operating temperatures. These thermal management techniques help prevent thermal-induced failures and ensure stable performance in field conditions.- Thermal management for HBM reliability: High Bandwidth Memory 4 (HBM4) systems require effective thermal management to ensure field reliability. As memory bandwidth increases, heat generation becomes a critical concern that can affect performance and lifespan. Advanced cooling solutions, including heat spreaders, thermal interface materials, and active cooling systems are implemented to maintain optimal operating temperatures. These thermal management techniques help prevent thermal-induced failures and ensure stable operation in various field conditions.
- Error detection and correction mechanisms: HBM4 implementations incorporate sophisticated error detection and correction mechanisms to enhance field reliability. These include advanced ECC (Error-Correcting Code) algorithms, parity checking, and redundancy schemes that can detect and repair memory errors during operation. Such mechanisms are crucial for maintaining data integrity in high-performance computing environments where memory failures could lead to significant system issues or data corruption.
- Power management and voltage regulation: Effective power management and voltage regulation are essential for HBM4 field reliability. Advanced power delivery networks ensure stable voltage supply to memory stacks, while dynamic voltage scaling helps optimize power consumption based on workload demands. These techniques prevent voltage fluctuations that could lead to memory errors or reduced lifespan, while also managing the increased power requirements of high-bandwidth memory operations.
- Testing and validation methodologies: Comprehensive testing and validation methodologies are implemented to ensure HBM4 field reliability. These include accelerated life testing, stress testing under extreme conditions, and in-field monitoring systems that can detect early signs of potential failures. Advanced diagnostic tools allow for real-time assessment of memory health and performance, enabling proactive maintenance and reducing the risk of unexpected failures in critical applications.
- 3D integration and packaging innovations: HBM4 reliability is significantly enhanced through innovations in 3D integration and packaging technologies. Through-silicon vias (TSVs), interposer designs, and advanced die stacking techniques improve signal integrity and reduce physical stress on memory components. These architectural improvements address potential failure points in the memory stack, enhancing overall durability and reliability in field conditions while enabling the higher bandwidth and capacity that HBM4 offers.
02 Error detection and correction mechanisms
HBM4 systems incorporate sophisticated error detection and correction mechanisms to enhance field reliability. These include advanced ECC (Error-Correcting Code) implementations, memory scrubbing techniques, and redundancy schemes that can detect and repair memory errors during operation. By continuously monitoring memory integrity and automatically correcting errors, these mechanisms significantly improve the resilience of HBM4 systems against both soft and hard errors that may occur in field deployments.Expand Specific Solutions03 Power management and voltage regulation
Effective power management and precise voltage regulation are essential for HBM4 field reliability. Advanced power delivery networks with stable voltage regulation minimize stress on memory cells and interconnects. Dynamic voltage and frequency scaling techniques allow the memory system to operate at optimal power levels based on workload demands, reducing unnecessary power consumption and heat generation. These power management strategies extend the operational lifespan of HBM4 memory in field applications.Expand Specific Solutions04 Testing and reliability validation methodologies
Comprehensive testing and reliability validation methodologies are implemented to ensure HBM4 field reliability. These include accelerated life testing, stress testing under extreme conditions, and statistical reliability modeling. Advanced built-in self-test (BIST) capabilities allow for continuous monitoring and diagnostics during field operation. These methodologies help identify potential failure modes early and enable manufacturers to implement design improvements that enhance the long-term reliability of HBM4 memory systems.Expand Specific Solutions05 3D integration and interconnect reliability
The reliability of 3D integration and interconnects is critical for HBM4 field performance. Through-silicon vias (TSVs) and microbumps used in HBM4 stacking are subject to mechanical stresses and potential failures. Advanced materials and manufacturing processes are employed to enhance the durability of these interconnects. Redundancy schemes and fault-tolerant designs are implemented to maintain system functionality even if individual interconnects fail. These approaches significantly improve the overall field reliability of HBM4 memory systems.Expand Specific Solutions
Key Industry Players in HBM4 Development and Manufacturing
The HBM4 Field Reliability market is currently in an early growth phase, characterized by increasing adoption of high-bandwidth memory technologies in data centers and AI applications. The global market size for HBM solutions is projected to reach approximately $4-5 billion by 2025, driven by escalating demands for high-performance computing. Technical maturity remains moderate, with leading semiconductor companies like Siemens AG and Toshiba Corp. focusing on thermal management solutions, while Harris Corp. and Shanghai Hugong Electric Group concentrate on duty cycle optimization. State Grid Corp. of China and Huazhong University of Science & Technology are advancing mitigation strategies for thermal events. The competitive landscape shows a mix of established semiconductor manufacturers and research institutions collaborating to address reliability challenges as HBM4 deployment accelerates across critical infrastructure applications.
Harris Corp.
Technical Solution: Harris Corporation has developed a specialized HBM4 reliability solution targeting aerospace and defense applications where thermal management is particularly challenging. Their approach combines hardware and software elements to create a comprehensive duty cycle management system. The hardware component includes a distributed thermal sensor network that provides real-time temperature mapping across the entire memory subsystem, not just the HBM4 stacks themselves but also surrounding components that contribute to the thermal environment. This data feeds into Harris's proprietary memory controller firmware, which implements dynamic frequency scaling and workload distribution algorithms to prevent thermal hotspots. Their solution also features an innovative "thermal banking" system that temporarily powers down portions of memory during peak thermal loads while maintaining critical functionality. For mitigation of unavoidable thermal events, Harris has developed rapid recovery protocols that can preserve data integrity even during brief thermal excursions beyond normal operating parameters.
Strengths: Exceptional performance in high-reliability environments; comprehensive approach that addresses the entire thermal ecosystem around HBM4. Weaknesses: Solutions may be overdesigned for consumer applications; potentially higher implementation costs compared to commercial alternatives.
Siemens AG
Technical Solution: Siemens has developed a comprehensive HBM4 field reliability solution focusing on dynamic duty cycle management and thermal event prevention. Their approach integrates real-time monitoring systems that continuously track memory temperature, voltage fluctuations, and workload patterns to optimize duty cycles. The system employs predictive analytics to anticipate potential thermal events before they occur, automatically adjusting memory controller parameters to maintain optimal operating conditions. Siemens' solution includes a multi-tiered thermal management system with both passive cooling elements and active intervention mechanisms that can throttle memory operations when temperatures approach critical thresholds. Their technology incorporates specialized firmware that can redistribute workloads across memory stacks to prevent hotspots and extend overall memory lifespan. Additionally, Siemens has implemented advanced error correction and recovery protocols specifically designed for HBM4 architecture to maintain data integrity during thermal events.
Strengths: Superior integration with industrial control systems and power management infrastructure; extensive experience with high-reliability components in harsh environments. Weaknesses: Solution may be overengineered for consumer applications, potentially increasing costs and complexity for implementation in non-industrial settings.
Critical Patents and Research on Duty Cycle Optimization
Mitigating duty cycle distortion degradation due to device aging on high-bandwidth memory interface
PatentActiveUS20230162780A1
Innovation
- A dynamic multiplexing circuit that switches between inverted and non-inverted data paths within the memory device's delay lines, using swap pulses with controllable delay and pulse width to mitigate asymmetric aging by changing polarity during refresh commands, thereby preventing prolonged exposure to sequences of zero or one values.
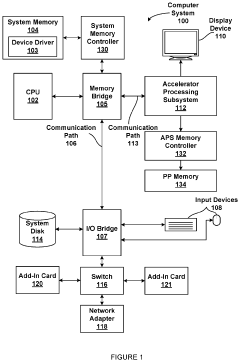
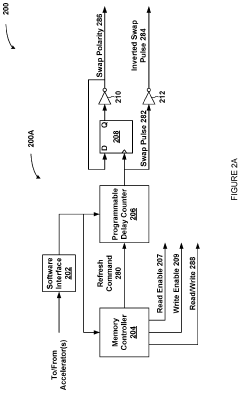
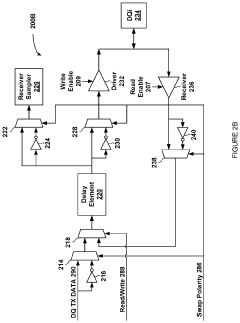
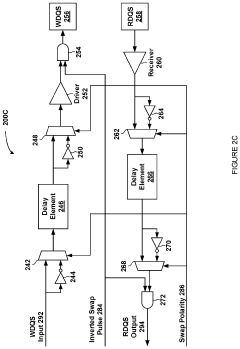
Storage system
PatentPendingCN117234835A
Innovation
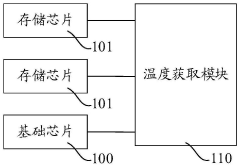
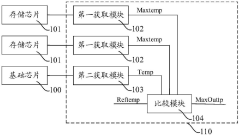
- Design a storage system, including a basic chip and multiple stacked memory chips. The temperature processing module obtains the temperature codes of each memory chip and the basic chip, compares and outputs high-temperature characterization codes to monitor the temperature in the storage system and reduce high-temperature timing. Risk of conflict. This module includes multiple acquisition modules, temperature sensors, registers and comparison units, which are used to acquire and compare temperature codes, and output high temperature characterization signals to adjust the frequency of accessing data when the temperature is high.
Supply Chain Resilience for HBM4 Production
The resilience of the HBM4 supply chain represents a critical factor in ensuring field reliability, particularly when considering duty cycles and thermal event mitigation. Current HBM4 production relies on a complex global network of suppliers spanning semiconductor fabrication, advanced packaging, and testing facilities. This interdependence creates potential vulnerabilities that could impact the availability and quality of HBM4 components during high-demand periods.
Material sourcing presents a significant challenge, as HBM4 requires specialized silicon substrates, interposers, and rare earth elements for manufacturing. Geopolitical tensions affecting key production regions such as Taiwan, South Korea, and China introduce additional uncertainty into the supply chain. Recent disruptions have demonstrated that concentrated manufacturing capabilities can lead to extended lead times and price volatility when thermal reliability issues emerge in deployed systems.
Manufacturing capacity constraints further complicate supply chain resilience. The production of HBM4 memory requires advanced process nodes (typically 4-5nm) and sophisticated packaging technologies like through-silicon vias (TSVs). Limited facilities worldwide possess these capabilities, creating potential bottlenecks that could impede rapid response to field reliability issues. When thermal events occur in deployed systems, the ability to quickly produce replacement components becomes essential.
Quality control across the supply chain directly impacts field reliability metrics. Inconsistent manufacturing processes can introduce variability in thermal performance characteristics, affecting duty cycle capabilities and thermal event frequency. Establishing robust supplier qualification programs and standardized testing protocols helps ensure consistent performance across production batches, reducing the likelihood of thermal-related failures.
Inventory management strategies must evolve to address HBM4's unique reliability considerations. Traditional just-in-time approaches may prove insufficient when field data reveals unexpected thermal behavior requiring component replacement. Strategic buffer inventories of critical components, particularly those with long lead times, can mitigate disruption risks while enabling rapid response to thermal events in deployed systems.
Diversification of supplier relationships represents a key strategy for enhancing supply chain resilience. Developing secondary sources for critical components reduces dependency on single suppliers and geographic regions. This approach requires significant investment in supplier qualification but provides valuable redundancy when addressing field reliability concerns related to thermal performance limitations.
Material sourcing presents a significant challenge, as HBM4 requires specialized silicon substrates, interposers, and rare earth elements for manufacturing. Geopolitical tensions affecting key production regions such as Taiwan, South Korea, and China introduce additional uncertainty into the supply chain. Recent disruptions have demonstrated that concentrated manufacturing capabilities can lead to extended lead times and price volatility when thermal reliability issues emerge in deployed systems.
Manufacturing capacity constraints further complicate supply chain resilience. The production of HBM4 memory requires advanced process nodes (typically 4-5nm) and sophisticated packaging technologies like through-silicon vias (TSVs). Limited facilities worldwide possess these capabilities, creating potential bottlenecks that could impede rapid response to field reliability issues. When thermal events occur in deployed systems, the ability to quickly produce replacement components becomes essential.
Quality control across the supply chain directly impacts field reliability metrics. Inconsistent manufacturing processes can introduce variability in thermal performance characteristics, affecting duty cycle capabilities and thermal event frequency. Establishing robust supplier qualification programs and standardized testing protocols helps ensure consistent performance across production batches, reducing the likelihood of thermal-related failures.
Inventory management strategies must evolve to address HBM4's unique reliability considerations. Traditional just-in-time approaches may prove insufficient when field data reveals unexpected thermal behavior requiring component replacement. Strategic buffer inventories of critical components, particularly those with long lead times, can mitigate disruption risks while enabling rapid response to thermal events in deployed systems.
Diversification of supplier relationships represents a key strategy for enhancing supply chain resilience. Developing secondary sources for critical components reduces dependency on single suppliers and geographic regions. This approach requires significant investment in supplier qualification but provides valuable redundancy when addressing field reliability concerns related to thermal performance limitations.
Power Efficiency Considerations for HBM4 Implementation
Power efficiency has emerged as a critical consideration in HBM4 implementation, particularly when addressing field reliability concerns related to duty cycles and thermal events. The latest HBM4 standard introduces significant improvements in bandwidth capabilities, reaching up to 3.2 Gbps per pin, which inevitably increases power consumption challenges. This necessitates sophisticated power management strategies to ensure reliable operation under various workload conditions.
The power consumption profile of HBM4 memory systems exhibits distinct characteristics during different operational phases. During active periods, the power draw can spike significantly, especially when handling data-intensive applications such as AI training workloads or high-performance computing tasks. Conversely, idle states present opportunities for power conservation through intelligent power gating techniques and voltage scaling mechanisms.
Thermal considerations directly impact the power efficiency equation for HBM4 implementations. The dense 3D stacking architecture creates inherent thermal challenges, with heat dissipation becoming increasingly difficult as stack heights increase. Advanced cooling solutions, including integrated liquid cooling channels and thermally conductive materials between layers, are being developed to address these challenges while maintaining power efficiency targets.
Dynamic voltage and frequency scaling (DVFS) represents a promising approach for optimizing HBM4 power consumption based on workload demands. By intelligently adjusting operating parameters in response to changing computational requirements, DVFS can significantly reduce power consumption during periods of lower memory bandwidth demand, thereby extending the operational lifespan of HBM4 components and improving overall system reliability.
The integration of dedicated power management units (PMUs) within HBM4 stacks offers another avenue for enhancing power efficiency. These specialized circuits can monitor thermal conditions in real-time and implement appropriate mitigation strategies, such as selective throttling or workload redistribution, to prevent thermal events while maintaining optimal performance levels within power constraints.
Industry benchmarks indicate that power efficiency improvements in HBM4 implementations can yield substantial benefits for total cost of ownership (TCO) in data center environments. Estimates suggest that a 15-20% reduction in memory subsystem power consumption can translate to 5-7% savings in overall system power requirements, representing significant operational cost reductions at scale while simultaneously enhancing reliability metrics related to thermal management.
The power consumption profile of HBM4 memory systems exhibits distinct characteristics during different operational phases. During active periods, the power draw can spike significantly, especially when handling data-intensive applications such as AI training workloads or high-performance computing tasks. Conversely, idle states present opportunities for power conservation through intelligent power gating techniques and voltage scaling mechanisms.
Thermal considerations directly impact the power efficiency equation for HBM4 implementations. The dense 3D stacking architecture creates inherent thermal challenges, with heat dissipation becoming increasingly difficult as stack heights increase. Advanced cooling solutions, including integrated liquid cooling channels and thermally conductive materials between layers, are being developed to address these challenges while maintaining power efficiency targets.
Dynamic voltage and frequency scaling (DVFS) represents a promising approach for optimizing HBM4 power consumption based on workload demands. By intelligently adjusting operating parameters in response to changing computational requirements, DVFS can significantly reduce power consumption during periods of lower memory bandwidth demand, thereby extending the operational lifespan of HBM4 components and improving overall system reliability.
The integration of dedicated power management units (PMUs) within HBM4 stacks offers another avenue for enhancing power efficiency. These specialized circuits can monitor thermal conditions in real-time and implement appropriate mitigation strategies, such as selective throttling or workload redistribution, to prevent thermal events while maintaining optimal performance levels within power constraints.
Industry benchmarks indicate that power efficiency improvements in HBM4 implementations can yield substantial benefits for total cost of ownership (TCO) in data center environments. Estimates suggest that a 15-20% reduction in memory subsystem power consumption can translate to 5-7% savings in overall system power requirements, representing significant operational cost reductions at scale while simultaneously enhancing reliability metrics related to thermal management.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!