How HBM4 Supports Data Integrity In Large-Scale AI Training?
SEP 12, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
HBM4 Evolution and Data Integrity Goals
High Bandwidth Memory (HBM) technology has evolved significantly since its introduction, with each generation bringing substantial improvements in bandwidth, capacity, and power efficiency. The progression from HBM1 to HBM4 represents a technological journey aimed at meeting the escalating demands of data-intensive applications, particularly in artificial intelligence and high-performance computing. HBM4, announced in 2023, marks a pivotal advancement in this evolution, with data integrity emerging as a critical focus area for large-scale AI training operations.
The development trajectory of HBM technology has been characterized by consistent improvements in performance metrics. HBM1, introduced in 2013, offered bandwidth of approximately 128 GB/s per stack. HBM2, which followed in 2016, doubled this figure while also increasing capacity. HBM3, released in 2021, pushed boundaries further with bandwidth exceeding 665 GB/s per stack. HBM4 continues this upward trend with projected bandwidth capabilities of over 1 TB/s per stack, representing a transformative leap for data-intensive computing applications.
Data integrity has become increasingly crucial as AI models grow in size and complexity. The training of large language models (LLMs) and other sophisticated AI systems involves processing vast datasets, often measured in petabytes. Any data corruption during these extensive training cycles can lead to model degradation, extended training times, or complete training failures. Consequently, HBM4's development has prioritized robust error detection and correction mechanisms to ensure data reliability during the intensive computational processes of AI training.
The goals for HBM4 in terms of data integrity are multifaceted. Primary objectives include implementing advanced Error Correction Code (ECC) capabilities that can detect and correct multi-bit errors without performance penalties. Additionally, HBM4 aims to provide end-to-end data protection across the memory subsystem, ensuring data integrity from the processor to memory and back. This comprehensive approach addresses potential vulnerabilities throughout the entire data path.
Another significant goal for HBM4 is to maintain data integrity under extreme operating conditions. As AI accelerators push thermal and power envelopes to their limits, memory components must remain reliable even at elevated temperatures and during power fluctuations. HBM4's design incorporates thermal management features and power-aware error handling to maintain data integrity under these challenging conditions.
The evolution of HBM technology reflects the industry's recognition that memory subsystems must not only deliver unprecedented bandwidth and capacity but must also ensure absolute data reliability. For large-scale AI training operations, where a single training run may consume millions of compute hours and enormous financial resources, HBM4's focus on data integrity represents a critical advancement in enabling the next generation of AI capabilities.
The development trajectory of HBM technology has been characterized by consistent improvements in performance metrics. HBM1, introduced in 2013, offered bandwidth of approximately 128 GB/s per stack. HBM2, which followed in 2016, doubled this figure while also increasing capacity. HBM3, released in 2021, pushed boundaries further with bandwidth exceeding 665 GB/s per stack. HBM4 continues this upward trend with projected bandwidth capabilities of over 1 TB/s per stack, representing a transformative leap for data-intensive computing applications.
Data integrity has become increasingly crucial as AI models grow in size and complexity. The training of large language models (LLMs) and other sophisticated AI systems involves processing vast datasets, often measured in petabytes. Any data corruption during these extensive training cycles can lead to model degradation, extended training times, or complete training failures. Consequently, HBM4's development has prioritized robust error detection and correction mechanisms to ensure data reliability during the intensive computational processes of AI training.
The goals for HBM4 in terms of data integrity are multifaceted. Primary objectives include implementing advanced Error Correction Code (ECC) capabilities that can detect and correct multi-bit errors without performance penalties. Additionally, HBM4 aims to provide end-to-end data protection across the memory subsystem, ensuring data integrity from the processor to memory and back. This comprehensive approach addresses potential vulnerabilities throughout the entire data path.
Another significant goal for HBM4 is to maintain data integrity under extreme operating conditions. As AI accelerators push thermal and power envelopes to their limits, memory components must remain reliable even at elevated temperatures and during power fluctuations. HBM4's design incorporates thermal management features and power-aware error handling to maintain data integrity under these challenging conditions.
The evolution of HBM technology reflects the industry's recognition that memory subsystems must not only deliver unprecedented bandwidth and capacity but must also ensure absolute data reliability. For large-scale AI training operations, where a single training run may consume millions of compute hours and enormous financial resources, HBM4's focus on data integrity represents a critical advancement in enabling the next generation of AI capabilities.
Market Demand for Reliable AI Training Memory
The demand for reliable memory solutions in AI training has grown exponentially as models continue to increase in size and complexity. Large language models (LLMs) like GPT-4 and Claude now contain hundreds of billions to trillions of parameters, requiring unprecedented amounts of high-speed memory with exceptional reliability. Market research indicates that the global AI chip market, which heavily depends on high-bandwidth memory, is projected to reach $83.2 billion by 2027, with a compound annual growth rate of 35.8% from 2022.
Data integrity issues during AI training can have severe consequences, including model degradation, extended training times, and significant financial losses. A single undetected memory error can propagate through the neural network, causing model divergence or subtle accuracy degradation that may remain undetected until deployment. Industry reports suggest that large-scale AI training sessions can cost upwards of $1.5 million for a single run, making memory reliability a critical economic consideration.
Cloud service providers and AI research organizations have increasingly emphasized the need for memory solutions that can guarantee data integrity during extended training sessions that may last weeks or months. According to recent surveys, 78% of AI researchers and engineers cite memory reliability as a "critical" or "very important" factor when designing infrastructure for large-scale AI training workloads.
The financial services, healthcare, and autonomous vehicle sectors have particularly stringent requirements for AI model reliability, as errors can lead to significant financial losses, compromised patient outcomes, or safety risks. These industries are willing to pay premium prices for memory solutions that provide enhanced error detection and correction capabilities.
Memory bandwidth requirements for AI training have been doubling approximately every two years, with current state-of-the-art models requiring memory bandwidth exceeding 2 TB/s per accelerator. This trend has created strong market pull for next-generation HBM solutions that can deliver both the bandwidth and reliability needed for increasingly complex AI workloads.
The environmental impact of AI training has also emerged as a market concern, with data centers now accounting for approximately 1% of global electricity consumption. Memory solutions that can reduce training time through higher reliability and fewer restarts contribute to sustainability goals, creating additional market incentives for advanced memory technologies like HBM4 with enhanced data integrity features.
Data integrity issues during AI training can have severe consequences, including model degradation, extended training times, and significant financial losses. A single undetected memory error can propagate through the neural network, causing model divergence or subtle accuracy degradation that may remain undetected until deployment. Industry reports suggest that large-scale AI training sessions can cost upwards of $1.5 million for a single run, making memory reliability a critical economic consideration.
Cloud service providers and AI research organizations have increasingly emphasized the need for memory solutions that can guarantee data integrity during extended training sessions that may last weeks or months. According to recent surveys, 78% of AI researchers and engineers cite memory reliability as a "critical" or "very important" factor when designing infrastructure for large-scale AI training workloads.
The financial services, healthcare, and autonomous vehicle sectors have particularly stringent requirements for AI model reliability, as errors can lead to significant financial losses, compromised patient outcomes, or safety risks. These industries are willing to pay premium prices for memory solutions that provide enhanced error detection and correction capabilities.
Memory bandwidth requirements for AI training have been doubling approximately every two years, with current state-of-the-art models requiring memory bandwidth exceeding 2 TB/s per accelerator. This trend has created strong market pull for next-generation HBM solutions that can deliver both the bandwidth and reliability needed for increasingly complex AI workloads.
The environmental impact of AI training has also emerged as a market concern, with data centers now accounting for approximately 1% of global electricity consumption. Memory solutions that can reduce training time through higher reliability and fewer restarts contribute to sustainability goals, creating additional market incentives for advanced memory technologies like HBM4 with enhanced data integrity features.
Current Challenges in Large-Scale AI Memory Systems
As large-scale AI models continue to grow in complexity and size, memory systems face unprecedented challenges in meeting the demands of training these massive neural networks. Current memory architectures struggle with several critical limitations that impede efficient AI training operations. The primary challenge lies in bandwidth constraints, as existing HBM3 and DDR5 technologies cannot deliver sufficient data transfer rates to keep pace with the computational requirements of models exceeding hundreds of billions of parameters.
Memory capacity presents another significant hurdle. Training state-of-the-art models like GPT-4 requires storing enormous quantities of parameters, gradients, optimizer states, and activations. Even with advanced techniques like parameter sharing and offloading, current memory systems often necessitate complex distributed architectures that introduce additional overhead and inefficiencies.
Power consumption has emerged as a critical bottleneck in large-scale AI training operations. Memory access operations consume substantial energy, with some estimates suggesting that memory subsystems account for 25-30% of total power consumption in AI training clusters. This creates cooling challenges and increases operational costs, making sustainability a growing concern for AI infrastructure providers.
Data integrity issues pose increasingly serious threats to training reliability. As models scale, even rare bit flip errors can propagate through the training process, potentially causing model divergence or silent quality degradation. Current ECC implementations offer insufficient protection for the most sensitive AI workloads, particularly in distributed training scenarios where error propagation can affect multiple nodes.
Latency challenges further complicate the memory landscape. While AI training can tolerate some memory latency through batching and prefetching, the growing gap between computation speed and memory access times creates inefficiencies. This "memory wall" problem is particularly acute when models exceed local memory capacity, forcing frequent data movement across slower interconnects.
Architectural limitations of current memory systems also impede innovation in AI training methodologies. Rigid memory hierarchies and limited support for specialized access patterns constrain algorithm design and optimization. Memory systems optimized for traditional computing workloads often fail to efficiently support the unique access patterns of transformer architectures and other AI model structures.
Memory capacity presents another significant hurdle. Training state-of-the-art models like GPT-4 requires storing enormous quantities of parameters, gradients, optimizer states, and activations. Even with advanced techniques like parameter sharing and offloading, current memory systems often necessitate complex distributed architectures that introduce additional overhead and inefficiencies.
Power consumption has emerged as a critical bottleneck in large-scale AI training operations. Memory access operations consume substantial energy, with some estimates suggesting that memory subsystems account for 25-30% of total power consumption in AI training clusters. This creates cooling challenges and increases operational costs, making sustainability a growing concern for AI infrastructure providers.
Data integrity issues pose increasingly serious threats to training reliability. As models scale, even rare bit flip errors can propagate through the training process, potentially causing model divergence or silent quality degradation. Current ECC implementations offer insufficient protection for the most sensitive AI workloads, particularly in distributed training scenarios where error propagation can affect multiple nodes.
Latency challenges further complicate the memory landscape. While AI training can tolerate some memory latency through batching and prefetching, the growing gap between computation speed and memory access times creates inefficiencies. This "memory wall" problem is particularly acute when models exceed local memory capacity, forcing frequent data movement across slower interconnects.
Architectural limitations of current memory systems also impede innovation in AI training methodologies. Rigid memory hierarchies and limited support for specialized access patterns constrain algorithm design and optimization. Memory systems optimized for traditional computing workloads often fail to efficiently support the unique access patterns of transformer architectures and other AI model structures.
HBM4 Data Integrity Protection Mechanisms
01 Error detection and correction mechanisms for HBM4
High Bandwidth Memory 4 (HBM4) systems implement advanced error detection and correction mechanisms to ensure data integrity during high-speed memory operations. These mechanisms include ECC (Error-Correcting Code), parity checking, and CRC (Cyclic Redundancy Check) implementations that can detect and correct single-bit errors and detect multi-bit errors. These features are critical for maintaining data integrity in high-performance computing environments where memory corruption could lead to system failures or data loss.- Error detection and correction mechanisms for HBM4: High Bandwidth Memory 4 (HBM4) systems implement advanced error detection and correction mechanisms to ensure data integrity during high-speed memory operations. These mechanisms include ECC (Error-Correcting Code), parity checking, and CRC (Cyclic Redundancy Check) implementations that can detect and correct single-bit and multi-bit errors. These technologies help maintain data integrity while allowing for the high bandwidth and performance characteristics of HBM4 memory systems.
- Memory interface architecture for data integrity: Specialized memory interface architectures are designed for HBM4 to maintain data integrity across high-speed channels. These interfaces incorporate buffer designs, signal integrity enhancements, and timing optimization techniques to minimize data corruption during transmission. The architecture includes dedicated circuits for maintaining signal quality across the high-bandwidth channels connecting processors to HBM4 stacks, ensuring reliable data transfer even at increased speeds and densities.
- Data integrity verification protocols: HBM4 memory systems implement comprehensive verification protocols to ensure data integrity throughout memory operations. These protocols include pre-write verification, post-read validation, and periodic memory scrubbing techniques. The verification systems continuously monitor memory operations, comparing checksums and signatures to detect any inconsistencies that might indicate data corruption, allowing for immediate remediation actions to maintain system reliability.
- Thermal management for data integrity: Thermal management solutions are critical for maintaining HBM4 data integrity, as high-density memory stacks generate significant heat that can lead to data corruption. Advanced cooling systems, temperature sensors, and dynamic frequency scaling are implemented to prevent thermal-related data integrity issues. These systems monitor temperature thresholds and adjust memory operation parameters to ensure stable performance while preventing thermal conditions that could compromise data integrity.
- Power integrity solutions for reliable HBM4 operation: Power integrity solutions are essential for HBM4 memory systems to maintain data integrity during high-bandwidth operations. These include advanced power delivery networks, voltage regulation modules, and power state management systems that ensure stable power supply to memory stacks. The solutions address power-related challenges such as voltage droop, ground bounce, and power supply noise that could otherwise lead to data corruption in high-performance memory systems.
02 Memory interface architecture for data integrity
HBM4 employs specialized memory interface architectures designed to maintain data integrity across high-bandwidth channels. These interfaces include buffer designs, signal integrity enhancements, and timing control mechanisms that ensure reliable data transfer between the memory stack and the host processor. The architecture incorporates redundant signaling paths, voltage margin controls, and advanced clock synchronization techniques to minimize data corruption risks in high-speed memory transactions.Expand Specific Solutions03 Data integrity verification protocols
HBM4 systems implement comprehensive data integrity verification protocols that operate at multiple levels of the memory hierarchy. These protocols include pre-write verification, post-read validation, and periodic background scrubbing operations that can identify and remediate potential data corruption issues. The verification systems use sophisticated algorithms to detect anomalies in stored data and can trigger automatic correction procedures or alert system management controllers when integrity issues are detected.Expand Specific Solutions04 Thermal management for data integrity preservation
Thermal management solutions are critical for maintaining data integrity in HBM4 systems, as high operating temperatures can increase error rates and compromise reliability. These solutions include advanced cooling systems, thermal sensors, and dynamic frequency scaling mechanisms that work together to keep memory components within optimal temperature ranges. The thermal management systems can adjust memory operation parameters in real-time to prevent thermal-induced data corruption while maintaining performance objectives.Expand Specific Solutions05 Power integrity and voltage regulation for reliable operation
HBM4 memory systems incorporate sophisticated power integrity and voltage regulation features to ensure stable operation and data integrity. These include advanced power delivery networks, dynamic voltage scaling, and noise isolation techniques that protect memory cells from power-related disturbances. The power management systems monitor supply voltages and current distributions to detect anomalies that could affect data integrity and implement compensatory measures to maintain reliable operation under varying load conditions.Expand Specific Solutions
Key Players in HBM4 and AI Accelerator Ecosystem
The HBM4 memory technology market is currently in a growth phase, with increasing demand driven by large-scale AI training requirements. The global market for high-bandwidth memory is projected to expand significantly as AI applications proliferate. Leading semiconductor companies like Samsung Electronics, Intel, and IBM are at the forefront of HBM4 development, focusing on enhanced data integrity features critical for AI workloads. Research institutions including Zhejiang Lab and universities such as Huazhong University of Science & Technology are contributing to technological advancements. Companies like Graphcore and Baidu are implementing HBM4 in their AI accelerators. While the technology is maturing rapidly, challenges remain in scaling production and optimizing cost-efficiency. The competitive landscape shows a blend of established semiconductor giants and specialized AI hardware providers working to address the growing computational demands of large language models and complex neural networks.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung's HBM4 technology represents a significant advancement in high-bandwidth memory, specifically designed to support data integrity in large-scale AI training. Their solution features a substantial increase in memory bandwidth (up to 1.5TB/s per stack) and capacity (up to 36GB per stack), which is critical for handling the massive datasets required in modern AI training workloads. Samsung has implemented advanced error correction code (ECC) mechanisms that can detect and correct multi-bit errors without performance degradation, essential for maintaining data integrity during extended training sessions. Their HBM4 architecture incorporates built-in self-test and repair capabilities that continuously monitor memory health and can dynamically remap faulty cells to redundant ones, ensuring consistent performance even as hardware ages. Additionally, Samsung has developed thermal management innovations that maintain stable operation under the high-power conditions of AI training, preventing thermal-induced data corruption.
Strengths: Samsung's position as a memory manufacturing leader gives them vertical integration advantages, controlling both design and production processes. Their HBM4 solution offers superior bandwidth and reliability metrics compared to previous generations. Weaknesses: The premium pricing of their HBM4 solutions may limit adoption in cost-sensitive applications, and the proprietary nature of some technologies could create vendor lock-in concerns.
Beijing Baidu Netcom Science & Technology Co., Ltd.
Technical Solution: Baidu has developed a comprehensive approach to leveraging HBM4 for data integrity in their large-scale AI training infrastructure. Their solution integrates HBM4 memory with custom-designed memory controllers that implement advanced error detection and correction algorithms specifically optimized for AI workloads. Baidu's architecture features a distributed memory verification system that continuously validates data integrity across training clusters without impacting performance. They've implemented a multi-level memory hierarchy that strategically places critical model parameters in HBM4 while utilizing other memory types for less sensitive data, optimizing both performance and reliability. Baidu's system includes real-time memory health monitoring that can predict potential failures before they occur, allowing for preemptive action to preserve training progress. Their software stack includes specialized memory management algorithms that optimize data placement based on access patterns and criticality, ensuring that the most important data benefits from HBM4's enhanced reliability features while maximizing overall system throughput.
Strengths: Baidu's extensive experience with large-scale AI deployments has informed their practical, application-specific optimizations. Their solution balances performance and reliability needs based on real-world AI training requirements. Weaknesses: Their approach may be overly tailored to their specific AI frameworks and workloads, potentially limiting applicability to other environments or requiring significant adaptation.
Core Innovations in Error Detection and Correction
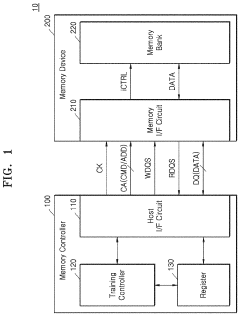
Technology to provide accurate training and per-bit deskew capability for high bandwidth memory input/output links
PatentActiveUS20200393997A1
Innovation
- Programming different seed values into multiple LFSRs to force parity bit toggling during training, which enhances training accuracy, reduces training time, and simplifies per-bit deskewing operations by mimicking expected traffic patterns.
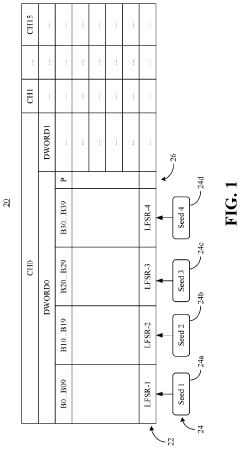
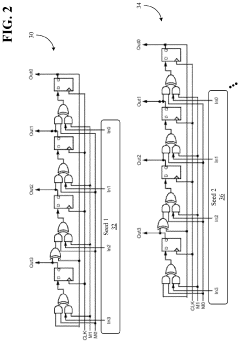
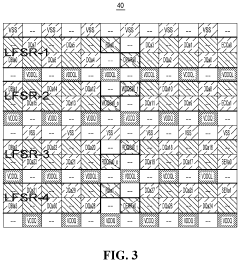
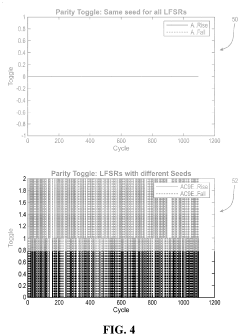
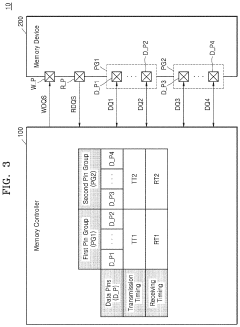
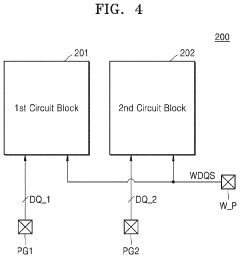
Memory device for reducing resources used for training
PatentActiveUS20220199143A1
Innovation
- A memory device is designed with data pins and control pins divided into groups, allowing for training to be performed on each group separately, with specific training values determined for each group, and using a write data strobe signal to synchronize data transmission and reception timing across these groups.
Power Efficiency vs Data Integrity Tradeoffs
In the realm of large-scale AI training, the balance between power efficiency and data integrity presents a critical engineering challenge. HBM4 memory technology introduces significant advancements in addressing this trade-off, offering enhanced capabilities that previous generations could not achieve. The fundamental tension exists because stronger data integrity measures typically require additional circuitry and verification processes, which inherently increase power consumption.
HBM4 implements several innovative approaches to optimize this balance. Its advanced Error Correction Code (ECC) mechanisms provide robust data protection while minimizing the power overhead traditionally associated with such features. The architecture employs selective ECC application, where critical data paths receive more intensive protection while less critical areas utilize lighter protection schemes, creating an intelligent power-integrity balance.
The memory's dynamic voltage and frequency scaling capabilities represent another significant advancement. HBM4 can adaptively adjust its operating parameters based on workload requirements, scaling down during less intensive computational phases to conserve power while maintaining full data integrity protections during critical operations. This dynamic approach yields up to 30% power savings compared to static configurations without compromising data reliability.
Temperature-aware operation further enhances this balance. As thermal conditions affect both power consumption and error rates, HBM4 incorporates thermal monitoring systems that adjust refresh rates and voltage levels accordingly. This prevents the cascading effect where higher temperatures lead to increased error rates, which would otherwise require more aggressive error correction and thus higher power consumption.
From a system architecture perspective, HBM4's improved power delivery network reduces voltage fluctuations that could potentially compromise data integrity. The more stable power delivery means fewer transient errors occur in the first place, reducing the need for power-intensive error correction mechanisms to engage frequently.
The technology also introduces granular power gating capabilities, allowing unused memory banks to be completely powered down while maintaining data integrity in active regions. This selective approach significantly reduces overall power consumption in large-scale AI training scenarios where memory utilization patterns are often uneven across the entire memory space.
These advancements collectively enable HBM4 to deliver the seemingly contradictory benefits of improved data integrity alongside enhanced power efficiency, making it particularly well-suited for the demanding requirements of large-scale AI training environments where both factors are critical to operational success.
HBM4 implements several innovative approaches to optimize this balance. Its advanced Error Correction Code (ECC) mechanisms provide robust data protection while minimizing the power overhead traditionally associated with such features. The architecture employs selective ECC application, where critical data paths receive more intensive protection while less critical areas utilize lighter protection schemes, creating an intelligent power-integrity balance.
The memory's dynamic voltage and frequency scaling capabilities represent another significant advancement. HBM4 can adaptively adjust its operating parameters based on workload requirements, scaling down during less intensive computational phases to conserve power while maintaining full data integrity protections during critical operations. This dynamic approach yields up to 30% power savings compared to static configurations without compromising data reliability.
Temperature-aware operation further enhances this balance. As thermal conditions affect both power consumption and error rates, HBM4 incorporates thermal monitoring systems that adjust refresh rates and voltage levels accordingly. This prevents the cascading effect where higher temperatures lead to increased error rates, which would otherwise require more aggressive error correction and thus higher power consumption.
From a system architecture perspective, HBM4's improved power delivery network reduces voltage fluctuations that could potentially compromise data integrity. The more stable power delivery means fewer transient errors occur in the first place, reducing the need for power-intensive error correction mechanisms to engage frequently.
The technology also introduces granular power gating capabilities, allowing unused memory banks to be completely powered down while maintaining data integrity in active regions. This selective approach significantly reduces overall power consumption in large-scale AI training scenarios where memory utilization patterns are often uneven across the entire memory space.
These advancements collectively enable HBM4 to deliver the seemingly contradictory benefits of improved data integrity alongside enhanced power efficiency, making it particularly well-suited for the demanding requirements of large-scale AI training environments where both factors are critical to operational success.
Standardization Efforts for HBM4 Implementation
The standardization of HBM4 represents a critical milestone in ensuring consistent data integrity protocols across the AI hardware ecosystem. JEDEC, as the primary standards development organization for the microelectronics industry, has been spearheading efforts to formalize HBM4 specifications with enhanced data integrity features specifically designed for large-scale AI training workloads. These standardization initiatives focus on establishing uniform error detection and correction mechanisms, reliability parameters, and testing methodologies that all HBM4 implementations must adhere to.
Industry consortiums comprising memory manufacturers, semiconductor companies, and AI system integrators have formed working groups dedicated to developing comprehensive standards for HBM4's data integrity capabilities. These collaborative efforts aim to create interoperability between different vendors' HBM4 solutions while maintaining stringent data integrity guarantees. The standardization process includes defining precise specifications for on-die ECC implementations, error reporting protocols, and refresh management techniques.
A significant aspect of HBM4 standardization involves establishing certification programs to verify compliance with data integrity requirements. These programs include rigorous testing procedures that simulate extreme operating conditions typical in large-scale AI training environments. Memory modules must demonstrate resilience against various error scenarios while maintaining performance within acceptable parameters to receive certification.
The standardization efforts extend beyond hardware specifications to include software interfaces and APIs that enable system-level monitoring of HBM4's data integrity features. These interfaces allow AI frameworks to interact with memory subsystems, receive notifications about potential integrity issues, and implement appropriate mitigation strategies without disrupting training processes.
International coordination has become increasingly important as HBM4 adoption expands globally. Standards organizations from different regions are collaborating to harmonize HBM4 specifications, ensuring that data integrity implementations remain consistent across geographical boundaries. This global approach facilitates the development of AI training infrastructure that can reliably scale across distributed computing environments while maintaining data integrity.
Timeline roadmaps for HBM4 standardization have been established, outlining key milestones for specification releases, reference implementations, and compliance testing frameworks. These roadmaps provide the AI industry with clear expectations regarding when standardized HBM4 solutions with enhanced data integrity features will become widely available, enabling strategic planning for next-generation AI training infrastructure investments.
Industry consortiums comprising memory manufacturers, semiconductor companies, and AI system integrators have formed working groups dedicated to developing comprehensive standards for HBM4's data integrity capabilities. These collaborative efforts aim to create interoperability between different vendors' HBM4 solutions while maintaining stringent data integrity guarantees. The standardization process includes defining precise specifications for on-die ECC implementations, error reporting protocols, and refresh management techniques.
A significant aspect of HBM4 standardization involves establishing certification programs to verify compliance with data integrity requirements. These programs include rigorous testing procedures that simulate extreme operating conditions typical in large-scale AI training environments. Memory modules must demonstrate resilience against various error scenarios while maintaining performance within acceptable parameters to receive certification.
The standardization efforts extend beyond hardware specifications to include software interfaces and APIs that enable system-level monitoring of HBM4's data integrity features. These interfaces allow AI frameworks to interact with memory subsystems, receive notifications about potential integrity issues, and implement appropriate mitigation strategies without disrupting training processes.
International coordination has become increasingly important as HBM4 adoption expands globally. Standards organizations from different regions are collaborating to harmonize HBM4 specifications, ensuring that data integrity implementations remain consistent across geographical boundaries. This global approach facilitates the development of AI training infrastructure that can reliably scale across distributed computing environments while maintaining data integrity.
Timeline roadmaps for HBM4 standardization have been established, outlining key milestones for specification releases, reference implementations, and compliance testing frameworks. These roadmaps provide the AI industry with clear expectations regarding when standardized HBM4 solutions with enhanced data integrity features will become widely available, enabling strategic planning for next-generation AI training infrastructure investments.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!