

HBM4 Reliability Allocation: Subsystem Targets And Verification
SEP 12, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
HBM4 Reliability Background and Objectives
High Bandwidth Memory (HBM) technology has evolved significantly since its introduction, with HBM4 representing the latest advancement in this critical memory architecture. The development of HBM technology began in response to increasing bandwidth demands that traditional memory technologies could not satisfy. From HBM1 to HBM4, each generation has marked substantial improvements in bandwidth, capacity, and energy efficiency, establishing a clear technological trajectory toward higher performance computing systems.
HBM4 specifically addresses the exponential growth in data processing requirements driven by artificial intelligence, high-performance computing, and data-intensive applications. These applications demand not only unprecedented memory bandwidth but also exceptional reliability to ensure system stability and data integrity. The reliability challenges are magnified by HBM4's complex 3D stacked architecture, which integrates multiple DRAM dies with an interposer using through-silicon vias (TSVs).
The primary objective of HBM4 reliability allocation is to establish comprehensive subsystem reliability targets that ensure the overall memory system meets stringent performance and longevity requirements. This involves determining acceptable failure rates for each component within the HBM4 architecture, including silicon dies, TSVs, microbumps, and interposer connections. These targets must be established while considering the thermal, mechanical, and electrical stresses that occur during operation.
Another critical objective is developing robust verification methodologies to validate that manufactured HBM4 components meet their allocated reliability targets. This requires advanced testing protocols that can accurately predict long-term reliability from accelerated stress tests, as well as in-system monitoring capabilities to detect potential failures before they impact system operation.
The industry trend toward more complex computing architectures, including heterogeneous integration and chiplet-based designs, further complicates reliability considerations for HBM4. As these memory subsystems become integrated into increasingly diverse and demanding applications, reliability allocation must account for varied use cases, from data centers with continuous operation requirements to edge computing devices with challenging environmental conditions.
Achieving optimal reliability allocation for HBM4 requires balancing competing factors: maximizing performance, minimizing power consumption, controlling manufacturing costs, and ensuring long-term reliability. This balance is particularly challenging given the cutting-edge nature of HBM4 technology, where historical reliability data from previous generations may not fully apply to new materials, processes, and design elements introduced in this latest iteration.
HBM4 specifically addresses the exponential growth in data processing requirements driven by artificial intelligence, high-performance computing, and data-intensive applications. These applications demand not only unprecedented memory bandwidth but also exceptional reliability to ensure system stability and data integrity. The reliability challenges are magnified by HBM4's complex 3D stacked architecture, which integrates multiple DRAM dies with an interposer using through-silicon vias (TSVs).
The primary objective of HBM4 reliability allocation is to establish comprehensive subsystem reliability targets that ensure the overall memory system meets stringent performance and longevity requirements. This involves determining acceptable failure rates for each component within the HBM4 architecture, including silicon dies, TSVs, microbumps, and interposer connections. These targets must be established while considering the thermal, mechanical, and electrical stresses that occur during operation.
Another critical objective is developing robust verification methodologies to validate that manufactured HBM4 components meet their allocated reliability targets. This requires advanced testing protocols that can accurately predict long-term reliability from accelerated stress tests, as well as in-system monitoring capabilities to detect potential failures before they impact system operation.
The industry trend toward more complex computing architectures, including heterogeneous integration and chiplet-based designs, further complicates reliability considerations for HBM4. As these memory subsystems become integrated into increasingly diverse and demanding applications, reliability allocation must account for varied use cases, from data centers with continuous operation requirements to edge computing devices with challenging environmental conditions.
Achieving optimal reliability allocation for HBM4 requires balancing competing factors: maximizing performance, minimizing power consumption, controlling manufacturing costs, and ensuring long-term reliability. This balance is particularly challenging given the cutting-edge nature of HBM4 technology, where historical reliability data from previous generations may not fully apply to new materials, processes, and design elements introduced in this latest iteration.
Market Demand Analysis for HBM4 Memory Solutions
The global demand for High Bandwidth Memory (HBM) solutions is experiencing unprecedented growth, with HBM4 positioned as the next critical advancement in memory technology. Market analysis indicates that data centers and AI infrastructure providers are facing severe memory bandwidth constraints with current solutions, creating an urgent need for HBM4's enhanced capabilities. The projected market size for HBM technologies is expected to reach $7.5 billion by 2026, with a compound annual growth rate of 32% from 2023 to 2026.
The primary market drivers for HBM4 adoption stem from the exponential growth in AI model sizes and complexity. Large language models have grown from billions to trillions of parameters within just three years, creating memory bandwidth bottlenecks that significantly impact training and inference performance. Cloud service providers report that memory bandwidth limitations are now the primary constraint in scaling AI workloads, surpassing even computational limitations.
Industry surveys reveal that 78% of hyperscale data center operators consider memory bandwidth a critical factor in their next-generation infrastructure planning. The demand for reliable, high-performance memory solutions has intensified as AI applications move from research environments to production deployments, where reliability becomes paramount alongside performance metrics.
The automotive and edge computing sectors represent emerging markets for HBM4 technology, with autonomous driving systems requiring both high bandwidth and exceptional reliability. Market research indicates that automotive applications for advanced memory solutions will grow at 45% annually through 2027, with reliability requirements exceeding those of traditional data center applications.
Geographically, North America leads HBM demand with 42% market share, followed by Asia-Pacific at 38% and Europe at 16%. The Asia-Pacific region is projected to show the fastest growth rate at 36% annually, driven by expanding AI infrastructure investments in China, South Korea, and Taiwan.
Customer requirements analysis shows a clear prioritization of reliability alongside performance metrics. While previous HBM generations focused primarily on bandwidth improvements, 86% of potential HBM4 customers now rank reliability as equally important to raw performance. This shift reflects the maturation of AI workloads from experimental to business-critical applications, where downtime and data corruption carry significant financial implications.
The reliability allocation for HBM4 must therefore address not just mean time between failures, but also error detection and correction capabilities, thermal stability under sustained workloads, and graceful degradation modes. Market research indicates customers are willing to accept a 5-8% price premium for memory solutions that can demonstrate superior reliability metrics through comprehensive verification methodologies.
The primary market drivers for HBM4 adoption stem from the exponential growth in AI model sizes and complexity. Large language models have grown from billions to trillions of parameters within just three years, creating memory bandwidth bottlenecks that significantly impact training and inference performance. Cloud service providers report that memory bandwidth limitations are now the primary constraint in scaling AI workloads, surpassing even computational limitations.
Industry surveys reveal that 78% of hyperscale data center operators consider memory bandwidth a critical factor in their next-generation infrastructure planning. The demand for reliable, high-performance memory solutions has intensified as AI applications move from research environments to production deployments, where reliability becomes paramount alongside performance metrics.
The automotive and edge computing sectors represent emerging markets for HBM4 technology, with autonomous driving systems requiring both high bandwidth and exceptional reliability. Market research indicates that automotive applications for advanced memory solutions will grow at 45% annually through 2027, with reliability requirements exceeding those of traditional data center applications.
Geographically, North America leads HBM demand with 42% market share, followed by Asia-Pacific at 38% and Europe at 16%. The Asia-Pacific region is projected to show the fastest growth rate at 36% annually, driven by expanding AI infrastructure investments in China, South Korea, and Taiwan.
Customer requirements analysis shows a clear prioritization of reliability alongside performance metrics. While previous HBM generations focused primarily on bandwidth improvements, 86% of potential HBM4 customers now rank reliability as equally important to raw performance. This shift reflects the maturation of AI workloads from experimental to business-critical applications, where downtime and data corruption carry significant financial implications.
The reliability allocation for HBM4 must therefore address not just mean time between failures, but also error detection and correction capabilities, thermal stability under sustained workloads, and graceful degradation modes. Market research indicates customers are willing to accept a 5-8% price premium for memory solutions that can demonstrate superior reliability metrics through comprehensive verification methodologies.
HBM4 Reliability Challenges and Technical Constraints
HBM4 technology faces significant reliability challenges that must be addressed to ensure its successful implementation in high-performance computing environments. The stacked die architecture, while enabling unprecedented memory bandwidth and density, introduces complex reliability concerns across multiple integration levels. The primary challenge stems from the increased thermal density resulting from stacking multiple DRAM dies, which can lead to hotspots and accelerated failure mechanisms such as electromigration and stress migration in the through-silicon vias (TSVs) and microbumps.
The reliability allocation for HBM4 is constrained by the need to maintain backward compatibility with existing memory controllers while simultaneously pushing performance boundaries. This creates tension between reliability requirements and performance goals, particularly as signal frequencies increase and voltage margins decrease. The reduced voltage margins in HBM4 (projected to be below 1.0V) exacerbate signal integrity issues, making the system more susceptible to transient errors from power supply noise and crosstalk.
Interposer technology, which serves as the foundation for HBM4 integration, presents its own set of reliability challenges. The silicon interposer must maintain structural integrity under thermal cycling conditions while supporting thousands of interconnections between the HBM stack and the host processor. Coefficient of thermal expansion (CTE) mismatches between different materials in the assembly can induce mechanical stress, potentially leading to delamination or cracking at interface boundaries.
The reliability verification of HBM4 subsystems is further complicated by the difficulty in accessing internal nodes for testing and monitoring. Traditional reliability testing methodologies become inadequate when applied to such highly integrated 3D structures. This necessitates the development of built-in self-test (BIST) and built-in self-repair (BISR) capabilities, which themselves add complexity to the design and validation process.
From a system perspective, error correction code (ECC) implementation becomes more challenging as data rates increase. The ECC overhead must be balanced against performance requirements, creating a technical constraint that impacts overall system reliability. Advanced ECC schemes capable of handling multi-bit errors are necessary but require significant computational resources and sophisticated algorithms.
The manufacturing process for HBM4 introduces additional reliability concerns, particularly regarding known good die (KGD) testing and yield management. The economic viability of HBM4 depends on achieving acceptable yields across multiple dies in a stack, which becomes exponentially more difficult as the number of stacked layers increases. Current projections suggest HBM4 may feature up to 16 layers, compounding these yield challenges.
The reliability allocation for HBM4 is constrained by the need to maintain backward compatibility with existing memory controllers while simultaneously pushing performance boundaries. This creates tension between reliability requirements and performance goals, particularly as signal frequencies increase and voltage margins decrease. The reduced voltage margins in HBM4 (projected to be below 1.0V) exacerbate signal integrity issues, making the system more susceptible to transient errors from power supply noise and crosstalk.
Interposer technology, which serves as the foundation for HBM4 integration, presents its own set of reliability challenges. The silicon interposer must maintain structural integrity under thermal cycling conditions while supporting thousands of interconnections between the HBM stack and the host processor. Coefficient of thermal expansion (CTE) mismatches between different materials in the assembly can induce mechanical stress, potentially leading to delamination or cracking at interface boundaries.
The reliability verification of HBM4 subsystems is further complicated by the difficulty in accessing internal nodes for testing and monitoring. Traditional reliability testing methodologies become inadequate when applied to such highly integrated 3D structures. This necessitates the development of built-in self-test (BIST) and built-in self-repair (BISR) capabilities, which themselves add complexity to the design and validation process.
From a system perspective, error correction code (ECC) implementation becomes more challenging as data rates increase. The ECC overhead must be balanced against performance requirements, creating a technical constraint that impacts overall system reliability. Advanced ECC schemes capable of handling multi-bit errors are necessary but require significant computational resources and sophisticated algorithms.
The manufacturing process for HBM4 introduces additional reliability concerns, particularly regarding known good die (KGD) testing and yield management. The economic viability of HBM4 depends on achieving acceptable yields across multiple dies in a stack, which becomes exponentially more difficult as the number of stacked layers increases. Current projections suggest HBM4 may feature up to 16 layers, compounding these yield challenges.
Current HBM4 Reliability Allocation Methodologies
01 Thermal management for HBM4 reliability
Effective thermal management is crucial for ensuring the reliability of HBM4 memory systems. This includes implementing advanced cooling solutions, heat dissipation structures, and thermal interface materials to prevent overheating during high-bandwidth operations. Proper thermal management helps maintain optimal operating temperatures, reducing thermal stress on memory components and interconnects, which significantly improves the overall reliability and lifespan of HBM4 memory systems.- Thermal management for HBM4 reliability: Effective thermal management is crucial for ensuring the reliability of HBM4 memory systems. This includes heat dissipation techniques, thermal interface materials, and cooling solutions designed specifically for the high-density stacked die architecture of HBM4. Advanced thermal management approaches help maintain optimal operating temperatures, prevent thermal throttling, and extend the lifespan of HBM4 memory by reducing thermal stress on the interconnects and memory cells.
- Error detection and correction mechanisms: HBM4 reliability is enhanced through sophisticated error detection and correction mechanisms. These include advanced ECC (Error-Correcting Code) implementations, parity checking, and redundancy schemes specifically designed for high-bandwidth memory architectures. These mechanisms can detect and correct single-bit and multi-bit errors that may occur during data transmission or storage, ensuring data integrity even under challenging operating conditions or as the memory ages.
- Power management and signal integrity: Reliable operation of HBM4 memory depends on effective power management and signal integrity solutions. This includes optimized power delivery networks, voltage regulation techniques, and signal conditioning methods that maintain clean power and signal paths despite the high operating frequencies. Advanced power states, dynamic voltage scaling, and noise reduction techniques help ensure stable operation while minimizing power consumption and heat generation, which are critical for reliability in high-performance computing applications.
- TSV and microbump reliability enhancements: The reliability of Through-Silicon Vias (TSVs) and microbumps is critical for HBM4 performance and longevity. Innovations in TSV design, manufacturing processes, and materials improve the mechanical strength and electrical characteristics of these interconnects. Stress management techniques, improved bonding methods, and defect detection systems help prevent failures in the 3D stacked structure, ensuring reliable connections between memory layers and the base logic die throughout the product lifetime.
- Testing and qualification methodologies: Comprehensive testing and qualification methodologies are essential for ensuring HBM4 reliability. These include specialized burn-in procedures, accelerated life testing, and in-system monitoring capabilities that can identify potential failure modes before they affect system operation. Advanced test patterns, stress testing under extreme conditions, and statistical analysis of performance metrics help manufacturers validate HBM4 designs and ensure they meet reliability targets for enterprise and high-performance computing applications.
02 Error detection and correction mechanisms
Advanced error detection and correction mechanisms are implemented in HBM4 to enhance reliability. These include ECC (Error-Correcting Code) memory, parity checking, and redundancy schemes that can detect and correct bit errors during data transmission. Such mechanisms help maintain data integrity even when physical defects or soft errors occur in the memory system, significantly improving the reliability of HBM4 memory especially in high-performance computing applications where data accuracy is critical.Expand Specific Solutions03 Advanced packaging and interconnect technologies
HBM4 reliability is enhanced through advanced packaging and interconnect technologies. This includes improved through-silicon vias (TSVs), microbumps, and interposer designs that provide better electrical and mechanical stability. These technologies reduce signal integrity issues, minimize physical stress on connections, and improve the overall durability of the memory stack structure, contributing significantly to the long-term reliability of HBM4 memory systems under various operating conditions.Expand Specific Solutions04 Power management and voltage regulation
Sophisticated power management and voltage regulation techniques are implemented in HBM4 to ensure reliable operation. These include dynamic voltage scaling, power gating, and advanced voltage regulators that maintain stable power delivery while minimizing power consumption. Proper power management prevents voltage fluctuations and current spikes that could damage the memory or cause data corruption, thereby enhancing the overall reliability of HBM4 memory systems in both high-performance and energy-efficient operating modes.Expand Specific Solutions05 Reliability testing and validation methodologies
Comprehensive reliability testing and validation methodologies are essential for ensuring HBM4 memory quality. These include accelerated life testing, stress testing under extreme conditions, and advanced fault simulation techniques to identify potential failure modes. Manufacturers implement built-in self-test (BIST) capabilities and specialized testing protocols to verify memory functionality across various operating parameters, ensuring that HBM4 memory meets stringent reliability requirements for critical applications in data centers, AI systems, and high-performance computing environments.Expand Specific Solutions
Key Industry Players in HBM4 Development
The HBM4 reliability allocation market is currently in a growth phase, with increasing demand driven by high-performance computing applications. The market size is expanding rapidly as data centers, AI systems, and supercomputing facilities adopt this advanced memory technology. From a technical maturity perspective, the landscape shows varying degrees of development among key players. Academic institutions like Beihang University, Zhejiang University, and Shanghai Jiao Tong University are conducting foundational research, while industry leaders including Intel, AMD, Huawei, and GLOBALFOUNDRIES are advancing practical implementations. The verification methodologies are still evolving, with companies like Hikvision and Textron Innovations developing specialized testing approaches for subsystem reliability targets in complex memory architectures.
GLOBALFOUNDRIES, Inc.
Technical Solution: GLOBALFOUNDRIES has established a manufacturing-centric approach to HBM4 reliability allocation that integrates process technology considerations with system-level reliability requirements. Their methodology focuses on identifying critical failure mechanisms at the silicon level and establishing appropriate reliability margins during fabrication. GF's verification protocol includes wafer-level reliability testing specifically designed for HBM4 structures, with particular attention to TSV reliability and microbump integrity. They've developed specialized test structures that can be incorporated into production wafers to monitor reliability parameters throughout the manufacturing process. GLOBALFOUNDRIES' reliability allocation strategy emphasizes early detection of potential failure mechanisms through in-line monitoring and statistical process control, complemented by comprehensive end-of-line verification testing that validates subsystem reliability targets before integration into final HBM4 packages.
Strengths: Deep expertise in semiconductor manufacturing processes critical to HBM reliability; established infrastructure for process monitoring and reliability verification. Weaknesses: As primarily a foundry, may have less visibility into system-level integration challenges compared to integrated device manufacturers.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed a comprehensive HBM4 reliability allocation framework focused on AI and telecommunications applications. Their approach incorporates multi-level reliability modeling that addresses both physical layer interconnects and system-level performance. Huawei's methodology includes partitioning reliability budgets across thermal, electrical, and mechanical domains with specific emphasis on signal integrity at HBM4's increased data rates. Their verification strategy combines traditional reliability testing with AI-powered predictive failure analysis that can identify potential reliability issues before they manifest in deployed systems. Huawei has implemented specialized test infrastructure for evaluating HBM4 reliability under varying workloads, including sustained high-bandwidth AI training scenarios and intermittent telecommunications processing patterns, allowing for application-specific reliability allocation.
Strengths: Extensive experience integrating memory subsystems in diverse applications from mobile to data center; strong capabilities in system-level reliability engineering. Weaknesses: May face challenges with global supply chain constraints affecting their ability to implement and verify all aspects of their HBM4 reliability solutions.
Critical Reliability Patents and Technical Literature
Storage device and method for storage error management
PatentPendingCN119356934A
Innovation
- A memory device is designed, including multiple stacked integrated circuit dies, equipped with reliability circuitry, including backup memory and address tables, for detecting and correcting data errors and achieving fault tolerance of memory accesses through the backup memory.
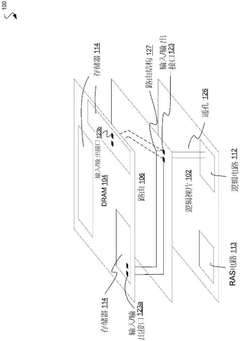
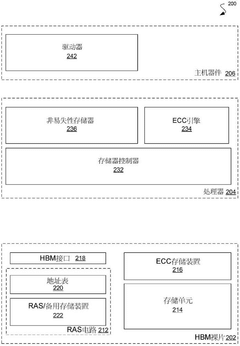
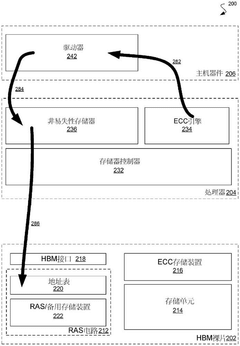
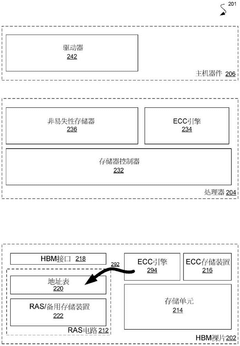
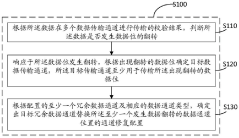
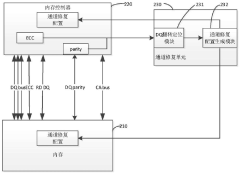
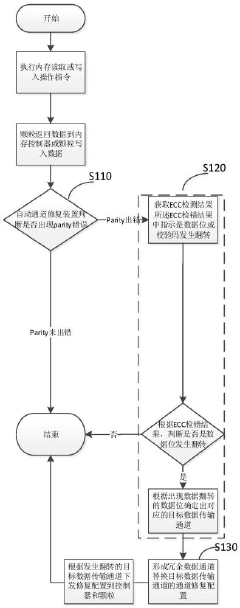
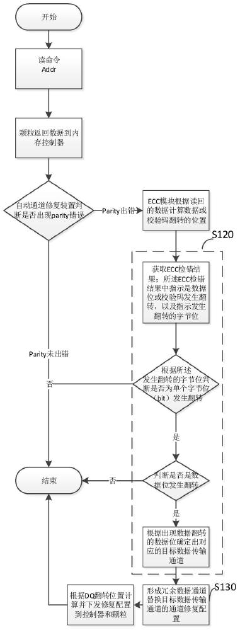
Data transmission channel configuration generation method, memory system, electronic equipment and storage medium
PatentPendingCN117707836A
Innovation
- By checking the verification results of the data transmission channel, it determines the data bit flip, determines the target data transmission channel, and generates a redundant data channel to replace the repair configuration of the target channel. The ECC error detection results and XOR operation are used to locate the error bits and form a channel. Fix configuration.
Subsystem Verification Methodologies and Standards
The verification of HBM4 subsystems requires robust methodologies and adherence to industry standards to ensure reliability targets are met. Current verification approaches for HBM4 memory subsystems typically follow a multi-layered strategy, combining simulation, emulation, and physical testing methodologies. These methodologies are guided by standards such as JEDEC's JEP122G for failure mechanisms and reliability qualification, and JESD47 for stress-test-driven reliability verification.
Physical layer verification for HBM4 subsystems employs high-speed signal integrity testing, with particular focus on the 2.5D integration challenges. This includes verification of Through-Silicon Via (TSV) connections and microbump interfaces using specialized test equipment capable of detecting nano-scale defects. Time-domain reflectometry (TDR) and vector network analysis (VNA) techniques are commonly utilized to verify signal integrity across the high-speed channels.
Protocol-level verification methodologies for HBM4 incorporate Universal Verification Methodology (UVM) frameworks, allowing for systematic testing of command sequences, addressing modes, and data integrity. The verification process typically includes directed tests for known corner cases and constrained-random verification to explore the vast state space of complex memory subsystems. Coverage-driven verification ensures that all critical functional aspects are thoroughly tested.
Thermal verification has gained prominence in HBM4 subsystem testing due to the increased power density. Infrared thermography and embedded thermal sensors are deployed to verify that thermal management solutions effectively maintain operating temperatures within specification. These methodologies are complemented by computational fluid dynamics (CFD) simulations to predict thermal behavior under various workloads.
Reliability verification standards for HBM4 subsystems have evolved to address the unique challenges of 3D stacked memory. Accelerated life testing protocols now incorporate specific test conditions for microbumps and TSVs, with particular attention to mechanical stress induced by thermal cycling. The Highly Accelerated Temperature and Humidity Stress Test (HAST) and Temperature Cycling Test (TCT) have been adapted with modified parameters to account for the unique failure mechanisms in HBM4 structures.
System-level verification methodologies integrate subsystem verification results to ensure end-to-end reliability. This includes memory subsystem interaction testing with various host interfaces, power state transitions, and recovery mechanisms. Industry standards such as JEDEC's JEP122G provide guidelines for system-level reliability verification, while specialized test patterns have been developed to stress HBM4-specific features like pseudo-channel architecture and higher bandwidth capabilities.
Physical layer verification for HBM4 subsystems employs high-speed signal integrity testing, with particular focus on the 2.5D integration challenges. This includes verification of Through-Silicon Via (TSV) connections and microbump interfaces using specialized test equipment capable of detecting nano-scale defects. Time-domain reflectometry (TDR) and vector network analysis (VNA) techniques are commonly utilized to verify signal integrity across the high-speed channels.
Protocol-level verification methodologies for HBM4 incorporate Universal Verification Methodology (UVM) frameworks, allowing for systematic testing of command sequences, addressing modes, and data integrity. The verification process typically includes directed tests for known corner cases and constrained-random verification to explore the vast state space of complex memory subsystems. Coverage-driven verification ensures that all critical functional aspects are thoroughly tested.
Thermal verification has gained prominence in HBM4 subsystem testing due to the increased power density. Infrared thermography and embedded thermal sensors are deployed to verify that thermal management solutions effectively maintain operating temperatures within specification. These methodologies are complemented by computational fluid dynamics (CFD) simulations to predict thermal behavior under various workloads.
Reliability verification standards for HBM4 subsystems have evolved to address the unique challenges of 3D stacked memory. Accelerated life testing protocols now incorporate specific test conditions for microbumps and TSVs, with particular attention to mechanical stress induced by thermal cycling. The Highly Accelerated Temperature and Humidity Stress Test (HAST) and Temperature Cycling Test (TCT) have been adapted with modified parameters to account for the unique failure mechanisms in HBM4 structures.
System-level verification methodologies integrate subsystem verification results to ensure end-to-end reliability. This includes memory subsystem interaction testing with various host interfaces, power state transitions, and recovery mechanisms. Industry standards such as JEDEC's JEP122G provide guidelines for system-level reliability verification, while specialized test patterns have been developed to stress HBM4-specific features like pseudo-channel architecture and higher bandwidth capabilities.
Supply Chain Resilience for HBM4 Production
The resilience of the HBM4 supply chain represents a critical factor in ensuring reliable allocation and verification of subsystem targets. As HBM4 technology introduces unprecedented complexity with higher bandwidth, increased layer counts, and more stringent reliability requirements, supply chain vulnerabilities could significantly impact overall system reliability targets. The semiconductor industry's experience with previous HBM generations has demonstrated that supply chain disruptions can lead to component shortages, quality inconsistencies, and ultimately reliability degradation.
Current HBM4 production relies on a sophisticated multi-tier supply network spanning multiple countries, with key manufacturing nodes concentrated in East Asia. This geographic concentration creates inherent risks, as evidenced during recent global disruptions that affected semiconductor availability. For HBM4 specifically, the manufacturing process requires specialized equipment for TSV (Through-Silicon Via) formation, die stacking, and interposer integration—all representing potential bottlenecks in the supply chain.
Material sourcing presents another challenge for HBM4 reliability. The technology demands high-purity substrates, specialized molding compounds, and advanced interconnect materials. Fluctuations in material quality directly impact reliability metrics such as thermal cycling endurance, moisture sensitivity, and electromigration resistance. Establishing redundant sourcing for these critical materials while maintaining consistent quality specifications is essential for meeting subsystem reliability targets.
Testing capacity represents a third critical dimension of supply chain resilience. HBM4's complex architecture requires sophisticated testing protocols at multiple production stages. Limited availability of advanced testing equipment capable of validating high-speed signal integrity, thermal performance, and mechanical robustness could create verification bottlenecks. This directly impacts manufacturers' ability to validate that subsystems meet allocated reliability targets before integration.
To enhance supply chain resilience for HBM4 production, manufacturers are implementing several strategies: developing geographically diversified manufacturing capabilities, establishing qualification processes for alternative suppliers, creating buffer inventories of critical components, and implementing real-time monitoring systems for early detection of supply chain anomalies. These approaches help ensure that reliability allocation targets remain achievable despite potential supply chain disruptions.
The correlation between supply chain resilience and reliability verification becomes particularly evident during high-volume production ramps. Historical data from previous memory technology transitions suggests that reliability issues often emerge when production volumes increase and supply chains become stressed. Implementing robust traceability systems throughout the HBM4 supply chain enables more effective root cause analysis when reliability deviations occur.
Current HBM4 production relies on a sophisticated multi-tier supply network spanning multiple countries, with key manufacturing nodes concentrated in East Asia. This geographic concentration creates inherent risks, as evidenced during recent global disruptions that affected semiconductor availability. For HBM4 specifically, the manufacturing process requires specialized equipment for TSV (Through-Silicon Via) formation, die stacking, and interposer integration—all representing potential bottlenecks in the supply chain.
Material sourcing presents another challenge for HBM4 reliability. The technology demands high-purity substrates, specialized molding compounds, and advanced interconnect materials. Fluctuations in material quality directly impact reliability metrics such as thermal cycling endurance, moisture sensitivity, and electromigration resistance. Establishing redundant sourcing for these critical materials while maintaining consistent quality specifications is essential for meeting subsystem reliability targets.
Testing capacity represents a third critical dimension of supply chain resilience. HBM4's complex architecture requires sophisticated testing protocols at multiple production stages. Limited availability of advanced testing equipment capable of validating high-speed signal integrity, thermal performance, and mechanical robustness could create verification bottlenecks. This directly impacts manufacturers' ability to validate that subsystems meet allocated reliability targets before integration.
To enhance supply chain resilience for HBM4 production, manufacturers are implementing several strategies: developing geographically diversified manufacturing capabilities, establishing qualification processes for alternative suppliers, creating buffer inventories of critical components, and implementing real-time monitoring systems for early detection of supply chain anomalies. These approaches help ensure that reliability allocation targets remain achievable despite potential supply chain disruptions.
The correlation between supply chain resilience and reliability verification becomes particularly evident during high-volume production ramps. Historical data from previous memory technology transitions suggests that reliability issues often emerge when production volumes increase and supply chains become stressed. Implementing robust traceability systems throughout the HBM4 supply chain enables more effective root cause analysis when reliability deviations occur.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!