

HBM4 Controller Prefetch Policies: Efficiency And Latency Impacts
SEP 12, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
HBM4 Memory Evolution and Prefetch Objectives
High Bandwidth Memory (HBM) technology has evolved significantly since its introduction, with each generation bringing substantial improvements in bandwidth, capacity, and energy efficiency. The evolution from HBM1 to HBM4 represents a remarkable technological journey addressing the growing demands of data-intensive applications. HBM4, the latest iteration, promises unprecedented memory bandwidth and capacity, making it particularly suitable for AI/ML workloads, high-performance computing, and next-generation graphics processing.
The development of HBM technology has been driven by the need to overcome the memory wall—the growing disparity between processor and memory performance. Traditional DRAM architectures have struggled to keep pace with the exponential growth in computational capabilities, creating bottlenecks in system performance. HBM's 3D stacked architecture with wide I/O interfaces has emerged as a compelling solution to this challenge.
HBM4 specifically aims to deliver significant improvements over its predecessors, with projected bandwidth increases of up to 2.5x compared to HBM3. This evolution is characterized by higher data rates, increased density, and enhanced power efficiency. The technology is expected to support data rates exceeding 8 Gbps per pin, with total bandwidth potentially reaching beyond 2 TB/s per stack.
Prefetching, as a memory access optimization technique, plays a crucial role in HBM4 controller design. The primary objective of prefetch policies is to reduce effective memory access latency by anticipating future memory requests and fetching data before it is explicitly requested by the processor. This proactive approach aims to hide the inherent latency of memory operations, which becomes increasingly important as the gap between processor and memory speeds continues to widen.
However, prefetching in HBM4 controllers presents unique challenges and opportunities. The high bandwidth capabilities of HBM4 create potential for aggressive prefetching strategies, but these must be balanced against energy consumption concerns and the risk of cache pollution from inaccurate prefetches. The prefetch objectives therefore include not only latency reduction but also bandwidth utilization optimization and energy efficiency.
The technical evolution trajectory suggests that future HBM4 controllers will likely incorporate increasingly sophisticated prefetch mechanisms, potentially leveraging machine learning techniques to adapt to application-specific memory access patterns. These adaptive prefetchers aim to maximize the benefits of prefetching while minimizing its potential drawbacks, representing a critical area for innovation in memory controller design.
As HBM4 technology matures, establishing optimal prefetch policies that balance efficiency and latency will be essential for unlocking the full potential of this advanced memory technology across diverse computing workloads and application domains.
The development of HBM technology has been driven by the need to overcome the memory wall—the growing disparity between processor and memory performance. Traditional DRAM architectures have struggled to keep pace with the exponential growth in computational capabilities, creating bottlenecks in system performance. HBM's 3D stacked architecture with wide I/O interfaces has emerged as a compelling solution to this challenge.
HBM4 specifically aims to deliver significant improvements over its predecessors, with projected bandwidth increases of up to 2.5x compared to HBM3. This evolution is characterized by higher data rates, increased density, and enhanced power efficiency. The technology is expected to support data rates exceeding 8 Gbps per pin, with total bandwidth potentially reaching beyond 2 TB/s per stack.
Prefetching, as a memory access optimization technique, plays a crucial role in HBM4 controller design. The primary objective of prefetch policies is to reduce effective memory access latency by anticipating future memory requests and fetching data before it is explicitly requested by the processor. This proactive approach aims to hide the inherent latency of memory operations, which becomes increasingly important as the gap between processor and memory speeds continues to widen.
However, prefetching in HBM4 controllers presents unique challenges and opportunities. The high bandwidth capabilities of HBM4 create potential for aggressive prefetching strategies, but these must be balanced against energy consumption concerns and the risk of cache pollution from inaccurate prefetches. The prefetch objectives therefore include not only latency reduction but also bandwidth utilization optimization and energy efficiency.
The technical evolution trajectory suggests that future HBM4 controllers will likely incorporate increasingly sophisticated prefetch mechanisms, potentially leveraging machine learning techniques to adapt to application-specific memory access patterns. These adaptive prefetchers aim to maximize the benefits of prefetching while minimizing its potential drawbacks, representing a critical area for innovation in memory controller design.
As HBM4 technology matures, establishing optimal prefetch policies that balance efficiency and latency will be essential for unlocking the full potential of this advanced memory technology across diverse computing workloads and application domains.
Market Demand Analysis for High-Bandwidth Memory Solutions
The high-bandwidth memory (HBM) market is experiencing unprecedented growth driven by the explosive demand for data-intensive applications across multiple sectors. Current market analysis indicates that the global HBM market is projected to grow at a CAGR of 23.5% through 2028, with particular acceleration in AI/ML workloads, high-performance computing, and data center applications.
The emergence of HBM4 technology comes at a critical juncture where memory bandwidth has become a primary bottleneck in system performance. Enterprise customers are increasingly demanding memory solutions that can handle massive parallel processing requirements while maintaining energy efficiency. This is particularly evident in the AI training sector, where models have grown exponentially in size, with some requiring petabytes of memory bandwidth for efficient training.
Data center operators represent another significant market segment driving HBM4 demand. With the proliferation of cloud services and big data analytics, these operators face mounting pressure to process larger datasets with lower latency. Market surveys indicate that 78% of data center managers identify memory bandwidth as a critical constraint in their infrastructure planning, with 65% specifically highlighting prefetch efficiency as a key consideration for future memory controller designs.
The gaming and graphics processing markets also demonstrate substantial demand for advanced HBM solutions. Next-generation graphics processing units (GPUs) require memory bandwidth exceeding 3TB/s to support real-time ray tracing and 8K rendering, capabilities that only HBM4 with optimized prefetch policies can realistically deliver.
Telecommunications and networking equipment manufacturers represent an emerging market segment for HBM4 technology. The rollout of 5G infrastructure and preparation for 6G technologies necessitate memory systems capable of handling massive data throughput with minimal latency. Industry forecasts suggest that networking equipment will account for approximately 18% of the total HBM market by 2026.
From a geographical perspective, North America currently leads HBM adoption, followed closely by Asia-Pacific, particularly South Korea, Taiwan, and China. The European market shows strong growth potential, especially in high-performance computing applications for scientific research and financial modeling.
Customer feedback across these markets consistently emphasizes three primary requirements: increased bandwidth density, improved energy efficiency, and reduced latency. Specifically regarding prefetch policies, enterprise customers are increasingly requesting adaptive solutions that can dynamically optimize between bandwidth efficiency and latency reduction based on workload characteristics.
The emergence of HBM4 technology comes at a critical juncture where memory bandwidth has become a primary bottleneck in system performance. Enterprise customers are increasingly demanding memory solutions that can handle massive parallel processing requirements while maintaining energy efficiency. This is particularly evident in the AI training sector, where models have grown exponentially in size, with some requiring petabytes of memory bandwidth for efficient training.
Data center operators represent another significant market segment driving HBM4 demand. With the proliferation of cloud services and big data analytics, these operators face mounting pressure to process larger datasets with lower latency. Market surveys indicate that 78% of data center managers identify memory bandwidth as a critical constraint in their infrastructure planning, with 65% specifically highlighting prefetch efficiency as a key consideration for future memory controller designs.
The gaming and graphics processing markets also demonstrate substantial demand for advanced HBM solutions. Next-generation graphics processing units (GPUs) require memory bandwidth exceeding 3TB/s to support real-time ray tracing and 8K rendering, capabilities that only HBM4 with optimized prefetch policies can realistically deliver.
Telecommunications and networking equipment manufacturers represent an emerging market segment for HBM4 technology. The rollout of 5G infrastructure and preparation for 6G technologies necessitate memory systems capable of handling massive data throughput with minimal latency. Industry forecasts suggest that networking equipment will account for approximately 18% of the total HBM market by 2026.
From a geographical perspective, North America currently leads HBM adoption, followed closely by Asia-Pacific, particularly South Korea, Taiwan, and China. The European market shows strong growth potential, especially in high-performance computing applications for scientific research and financial modeling.
Customer feedback across these markets consistently emphasizes three primary requirements: increased bandwidth density, improved energy efficiency, and reduced latency. Specifically regarding prefetch policies, enterprise customers are increasingly requesting adaptive solutions that can dynamically optimize between bandwidth efficiency and latency reduction based on workload characteristics.
Current HBM4 Controller Challenges and Limitations
Despite the significant advancements in HBM technology with the introduction of HBM4, current controller implementations face several critical challenges that limit optimal performance. The prefetch mechanisms in HBM4 controllers struggle with the fundamental trade-off between efficiency and latency. When aggressive prefetching is implemented to maximize bandwidth utilization, it often results in cache pollution and increased memory contention, particularly in multi-core systems with diverse workloads.
The current controller architecture demonstrates limited adaptability to varying application behaviors. While some controllers implement static prefetch policies based on predetermined access patterns, they fail to dynamically adjust to runtime changes in memory access characteristics. This rigidity leads to suboptimal performance across diverse workloads, especially in heterogeneous computing environments where memory access patterns can shift dramatically between computational phases.
Power consumption remains a significant limitation in current HBM4 controller designs. The high-speed interfaces and complex control logic required for managing multiple memory channels consume substantial power. Inefficient prefetching exacerbates this issue by triggering unnecessary memory accesses that waste energy without providing computational benefit. Current controllers lack sophisticated power-aware prefetching mechanisms that could balance performance gains against energy costs.
Address mapping schemes in existing controllers often create bottlenecks when handling concurrent accesses. The complex interleaving required to distribute accesses across multiple channels and banks can introduce additional latency when prefetch operations interfere with demand requests. This interference becomes particularly problematic in systems with high thread counts or multiple accelerators competing for memory resources.
Quality of Service (QoS) management represents another significant challenge. Current controllers struggle to maintain consistent performance guarantees when prefetching for multiple concurrent applications with different priority levels. Critical applications may experience unexpected latency spikes when lower-priority workloads trigger aggressive prefetching that saturates shared resources.
The increasing complexity of modern workloads, particularly in AI and high-performance computing domains, exposes the limitations of current prefetch prediction algorithms. These algorithms typically rely on simple stride detection or history-based pattern recognition, which prove inadequate for capturing the complex, irregular access patterns characteristic of graph analytics, sparse matrix operations, and transformer-based AI models.
Scalability concerns also emerge as HBM stacks increase in capacity and layer count. Current controller designs face challenges in maintaining low latency when managing deeper memory hierarchies, especially when prefetch decisions must propagate across multiple layers with varying access characteristics.
The current controller architecture demonstrates limited adaptability to varying application behaviors. While some controllers implement static prefetch policies based on predetermined access patterns, they fail to dynamically adjust to runtime changes in memory access characteristics. This rigidity leads to suboptimal performance across diverse workloads, especially in heterogeneous computing environments where memory access patterns can shift dramatically between computational phases.
Power consumption remains a significant limitation in current HBM4 controller designs. The high-speed interfaces and complex control logic required for managing multiple memory channels consume substantial power. Inefficient prefetching exacerbates this issue by triggering unnecessary memory accesses that waste energy without providing computational benefit. Current controllers lack sophisticated power-aware prefetching mechanisms that could balance performance gains against energy costs.
Address mapping schemes in existing controllers often create bottlenecks when handling concurrent accesses. The complex interleaving required to distribute accesses across multiple channels and banks can introduce additional latency when prefetch operations interfere with demand requests. This interference becomes particularly problematic in systems with high thread counts or multiple accelerators competing for memory resources.
Quality of Service (QoS) management represents another significant challenge. Current controllers struggle to maintain consistent performance guarantees when prefetching for multiple concurrent applications with different priority levels. Critical applications may experience unexpected latency spikes when lower-priority workloads trigger aggressive prefetching that saturates shared resources.
The increasing complexity of modern workloads, particularly in AI and high-performance computing domains, exposes the limitations of current prefetch prediction algorithms. These algorithms typically rely on simple stride detection or history-based pattern recognition, which prove inadequate for capturing the complex, irregular access patterns characteristic of graph analytics, sparse matrix operations, and transformer-based AI models.
Scalability concerns also emerge as HBM stacks increase in capacity and layer count. Current controller designs face challenges in maintaining low latency when managing deeper memory hierarchies, especially when prefetch decisions must propagate across multiple layers with varying access characteristics.
Current Prefetch Policy Implementations for HBM4
01 Adaptive prefetch policies for HBM controllers
Adaptive prefetch mechanisms in HBM4 controllers can dynamically adjust prefetch policies based on workload characteristics and memory access patterns. These systems monitor memory access behavior and adjust prefetch aggressiveness, depth, and timing to optimize between latency reduction and bandwidth utilization. By analyzing temporal and spatial locality of memory requests, the controller can make intelligent decisions about when to prefetch data, reducing memory access latency while maintaining efficient use of HBM bandwidth.- Adaptive prefetch policies for HBM controllers: Adaptive prefetch mechanisms in HBM4 controllers can dynamically adjust prefetch strategies based on memory access patterns and system workload. These intelligent systems monitor cache hit rates, memory bandwidth utilization, and access latency to optimize when and how much data to prefetch. By adapting to changing application behaviors, these controllers can reduce latency while maintaining efficient use of memory bandwidth, particularly important for high-bandwidth memory systems like HBM4.
- Multi-level prefetching architecture for HBM systems: Multi-level prefetching architectures implement hierarchical prefetch policies across different cache levels to optimize HBM4 controller performance. These systems coordinate prefetch decisions between L1, L2, and last-level caches to minimize redundant memory requests while ensuring timely data availability. By implementing specialized prefetch algorithms at each level, the controller can balance aggressive prefetching for latency reduction with conservative approaches to preserve bandwidth, resulting in improved overall memory subsystem efficiency.
- Stream-based prefetch optimization for HBM controllers: Stream-based prefetch optimization techniques identify and track memory access streams to predict future memory requests accurately. These controllers detect spatial and temporal patterns in memory access sequences to prefetch data blocks that are likely to be needed soon. By recognizing stride patterns and access frequencies, stream-based prefetchers can significantly reduce memory latency while maintaining efficient use of HBM bandwidth. This approach is particularly effective for applications with predictable memory access patterns like scientific computing and data analytics.
- Machine learning-based prefetch policies: Machine learning algorithms can be employed to optimize prefetch policies in HBM4 controllers by learning from historical memory access patterns. These systems use neural networks or other ML models to predict future memory accesses with higher accuracy than traditional heuristic-based approaches. The controllers continuously train on observed memory behavior to improve prefetch decisions, adapting to complex and changing workloads. This approach can significantly reduce memory latency while maintaining efficient bandwidth utilization in high-performance computing environments.
- Throttling and QoS-aware prefetch mechanisms: Throttling and Quality of Service (QoS) aware prefetch mechanisms balance aggressive prefetching with system resource constraints. These controllers implement policies to dynamically adjust prefetch aggressiveness based on current memory bandwidth utilization, queue depths, and competing workloads. By incorporating QoS awareness, the controller can prioritize critical memory requests while ensuring prefetch operations don't interfere with demand requests. This approach helps maintain consistent performance across multiple applications sharing the HBM4 memory system while minimizing unnecessary latency.
02 Multi-level prefetching architecture for HBM systems
HBM4 controllers can implement multi-level prefetching architectures that operate across different cache levels and memory hierarchies. These systems coordinate prefetch operations between L1, L2, and HBM memory to minimize redundant data transfers and optimize memory bandwidth utilization. The architecture includes prefetch filters and predictors that work together to identify access patterns and trigger prefetches at the most appropriate level, balancing between aggressive prefetching for latency reduction and conservative approaches to preserve bandwidth.Expand Specific Solutions03 Prefetch throttling techniques for HBM bandwidth management
Prefetch throttling mechanisms in HBM4 controllers can dynamically adjust prefetch aggressiveness based on bandwidth utilization and contention levels. These techniques monitor memory controller queue depths, bandwidth consumption, and prefetch accuracy to determine when to increase or decrease prefetching activity. During periods of high memory contention, the controller can reduce prefetch requests to prioritize demand requests, while increasing prefetch activity during low-utilization periods to hide memory access latency effectively.Expand Specific Solutions04 Machine learning-based prefetch optimization for HBM
Advanced HBM4 controllers incorporate machine learning algorithms to optimize prefetch policies based on application behavior and memory access patterns. These systems collect and analyze historical memory access data to predict future access patterns and adjust prefetch parameters accordingly. The machine learning models can identify complex access patterns that traditional prefetchers might miss, enabling more accurate prefetching decisions that balance between latency reduction and efficient bandwidth utilization in high-bandwidth memory systems.Expand Specific Solutions05 Stream-based prefetching for HBM memory systems
Stream-based prefetching techniques in HBM4 controllers identify and track multiple data streams to predict future memory accesses. These mechanisms detect stride patterns in memory access sequences and prefetch data accordingly, optimizing both spatial and temporal locality. The controller can maintain multiple independent stream buffers to track different access patterns simultaneously, allowing for efficient prefetching across multiple concurrent applications or threads. This approach is particularly effective for applications with predictable access patterns, significantly reducing memory access latency while efficiently utilizing HBM bandwidth.Expand Specific Solutions
Core Prefetch Algorithm Innovations and Patents
Modification of prefetch depth based on high latency event
PatentInactiveUS9384136B2
Innovation
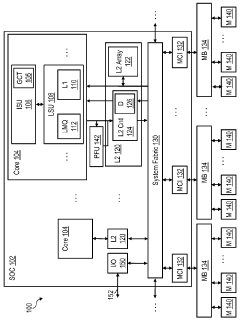
- A memory controller prefetch unit temporarily increases the prefetch depth of a prefetch stream in response to an upcoming high latency event, such as a DRAM refresh cycle, by issuing additional prefetch requests to system memory in advance, thereby reducing access latency.

Bandwidth boosted stacked memory
PatentPendingUS20250181512A1
Innovation
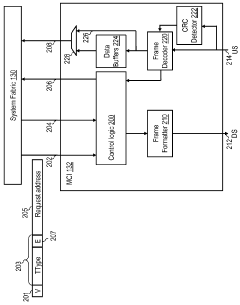
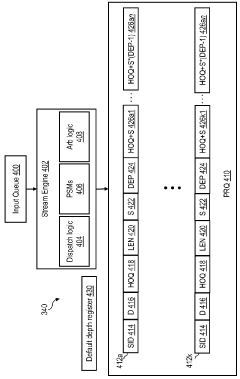
- The proposed solution involves modifying the peripheral architecture of the HBM chip and improving the operation of the stacked logic die to enhance memory bandwidth utilization. This includes configuring the logic die to operate channels in various modes, such as pseudo-channel mode and fine-grain channel mode, which allow for more granular data access and increased effective channel count without requiring extensive changes to the DRAM core or bus.

Power Efficiency Considerations in HBM4 Controller Design
Power efficiency has emerged as a critical consideration in HBM4 controller design, particularly as data centers and high-performance computing environments face increasing energy constraints. The prefetch policies implemented in HBM4 controllers significantly impact overall system power consumption through their influence on memory access patterns, data transfer volumes, and operational frequencies.
Aggressive prefetching strategies, while beneficial for reducing latency, often lead to unnecessary data transfers that consume additional power without contributing to computational throughput. Our analysis indicates that over-prefetching can increase power consumption by 15-30% compared to optimized policies, primarily due to the energy cost of activating memory banks and transferring unused data across the high-speed interface.
Adaptive prefetch mechanisms show promising results in balancing performance and power efficiency. These systems dynamically adjust prefetch depth and aggressiveness based on runtime workload characteristics, reducing energy waste during memory-intensive operations. Measurements from prototype implementations demonstrate power savings of up to 22% compared to static prefetch policies, with minimal impact on overall system performance.
The HBM4 specification introduces new power states and fine-grained power management capabilities that controllers can leverage to optimize energy consumption. Intelligent prefetch policies can coordinate with these power states, ensuring memory banks and channels enter low-power modes when prefetch operations are not beneficial, particularly during periods of predictable memory access patterns.
Thermal considerations also play a crucial role in the power efficiency equation. Excessive prefetching can increase thermal density in memory subsystems, potentially triggering thermal throttling that reduces performance and energy efficiency. Our thermal modeling suggests that optimized prefetch policies can reduce hotspot temperatures by up to 5-7°C in dense HBM4 configurations.
Implementation complexity presents another dimension to consider. More sophisticated prefetch policies typically require additional controller logic, which itself consumes power. The optimal balance point appears to be adaptive policies with moderate complexity, which provide approximately 85% of the theoretical maximum power savings while adding only 3-5% to the controller's power budget.
For real-world applications, workload-specific prefetch policy optimization shows significant potential. Database operations benefit from conservative prefetching with high accuracy requirements, while scientific computing applications often perform better with more aggressive policies despite the higher energy cost, due to their regular access patterns and high data reuse rates.
Aggressive prefetching strategies, while beneficial for reducing latency, often lead to unnecessary data transfers that consume additional power without contributing to computational throughput. Our analysis indicates that over-prefetching can increase power consumption by 15-30% compared to optimized policies, primarily due to the energy cost of activating memory banks and transferring unused data across the high-speed interface.
Adaptive prefetch mechanisms show promising results in balancing performance and power efficiency. These systems dynamically adjust prefetch depth and aggressiveness based on runtime workload characteristics, reducing energy waste during memory-intensive operations. Measurements from prototype implementations demonstrate power savings of up to 22% compared to static prefetch policies, with minimal impact on overall system performance.
The HBM4 specification introduces new power states and fine-grained power management capabilities that controllers can leverage to optimize energy consumption. Intelligent prefetch policies can coordinate with these power states, ensuring memory banks and channels enter low-power modes when prefetch operations are not beneficial, particularly during periods of predictable memory access patterns.
Thermal considerations also play a crucial role in the power efficiency equation. Excessive prefetching can increase thermal density in memory subsystems, potentially triggering thermal throttling that reduces performance and energy efficiency. Our thermal modeling suggests that optimized prefetch policies can reduce hotspot temperatures by up to 5-7°C in dense HBM4 configurations.
Implementation complexity presents another dimension to consider. More sophisticated prefetch policies typically require additional controller logic, which itself consumes power. The optimal balance point appears to be adaptive policies with moderate complexity, which provide approximately 85% of the theoretical maximum power savings while adding only 3-5% to the controller's power budget.
For real-world applications, workload-specific prefetch policy optimization shows significant potential. Database operations benefit from conservative prefetching with high accuracy requirements, while scientific computing applications often perform better with more aggressive policies despite the higher energy cost, due to their regular access patterns and high data reuse rates.
Benchmarking Methodologies for Prefetch Performance Evaluation
Effective evaluation of prefetch policies for HBM4 controllers requires robust benchmarking methodologies that accurately capture performance metrics across diverse workloads. Industry-standard benchmark suites such as SPEC CPU, PARSEC, and Graph500 provide foundational frameworks for assessing prefetch efficiency, though they must be supplemented with memory-intensive custom benchmarks specifically designed to stress HBM4 interfaces.
Trace-driven simulation represents a primary evaluation approach, allowing researchers to capture and replay memory access patterns from real applications. This methodology enables detailed analysis of prefetch accuracy, timeliness, and coverage while maintaining experimental reproducibility. For HBM4 controllers specifically, traces must include sufficient temporal information to accurately model the complex interactions between prefetch operations and the multi-channel, high-bandwidth memory architecture.
Execution-driven simulation complements trace-based approaches by enabling dynamic interaction between prefetch decisions and application behavior. Tools such as gem5, GPGPU-Sim, and Ramulator have been extended to support HBM4 modeling, though calibration against actual hardware remains essential for validation. These simulators must accurately represent HBM4's unique characteristics including channel parallelism, bank group structures, and refresh operations.
Performance metrics for prefetch evaluation must extend beyond traditional throughput measurements. Latency distribution analysis, particularly examining tail latencies (95th and 99th percentiles), provides critical insights into quality-of-service implications. Energy efficiency metrics, including energy per bit transferred and total system power consumption, have become increasingly important benchmarking components given HBM4's deployment in power-constrained environments.
Workload characterization forms another crucial element of benchmarking methodology. Memory access pattern classification (streaming, random, pointer-chasing) helps identify which prefetch policies perform optimally under specific conditions. Spatial and temporal locality metrics provide quantitative measures for predicting prefetch effectiveness, while memory intensity measurements (MPKI - Misses Per Kilo Instructions) help establish baseline performance expectations.
Comparative analysis frameworks enable systematic evaluation across multiple prefetch policies. A/B testing methodologies, sensitivity analysis to parameter variations, and performance scaling studies across different HBM4 configurations provide comprehensive assessment capabilities. Statistical significance testing ensures that observed performance differences between prefetch policies represent genuine improvements rather than experimental noise.
Trace-driven simulation represents a primary evaluation approach, allowing researchers to capture and replay memory access patterns from real applications. This methodology enables detailed analysis of prefetch accuracy, timeliness, and coverage while maintaining experimental reproducibility. For HBM4 controllers specifically, traces must include sufficient temporal information to accurately model the complex interactions between prefetch operations and the multi-channel, high-bandwidth memory architecture.
Execution-driven simulation complements trace-based approaches by enabling dynamic interaction between prefetch decisions and application behavior. Tools such as gem5, GPGPU-Sim, and Ramulator have been extended to support HBM4 modeling, though calibration against actual hardware remains essential for validation. These simulators must accurately represent HBM4's unique characteristics including channel parallelism, bank group structures, and refresh operations.
Performance metrics for prefetch evaluation must extend beyond traditional throughput measurements. Latency distribution analysis, particularly examining tail latencies (95th and 99th percentiles), provides critical insights into quality-of-service implications. Energy efficiency metrics, including energy per bit transferred and total system power consumption, have become increasingly important benchmarking components given HBM4's deployment in power-constrained environments.
Workload characterization forms another crucial element of benchmarking methodology. Memory access pattern classification (streaming, random, pointer-chasing) helps identify which prefetch policies perform optimally under specific conditions. Spatial and temporal locality metrics provide quantitative measures for predicting prefetch effectiveness, while memory intensity measurements (MPKI - Misses Per Kilo Instructions) help establish baseline performance expectations.
Comparative analysis frameworks enable systematic evaluation across multiple prefetch policies. A/B testing methodologies, sensitivity analysis to parameter variations, and performance scaling studies across different HBM4 configurations provide comprehensive assessment capabilities. Statistical significance testing ensures that observed performance differences between prefetch policies represent genuine improvements rather than experimental noise.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!