

HBM4 Integration With CXL: Memory Pooling And Bandwidth Utilization
SEP 12, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
HBM4 and CXL Technology Evolution and Objectives
High Bandwidth Memory (HBM) technology has evolved significantly since its introduction, with each generation bringing substantial improvements in bandwidth, capacity, and energy efficiency. The latest iteration, HBM4, represents a quantum leap in memory performance capabilities, designed to address the exponentially growing data processing demands of AI, high-performance computing, and data-intensive applications. Simultaneously, Compute Express Link (CXL) has emerged as a transformative interconnect technology that enables heterogeneous computing architectures with coherent memory access across CPUs, GPUs, and other accelerators.
The evolution of HBM technology began with HBM1 offering 128GB/s bandwidth, progressing through HBM2 (256GB/s) and HBM3 (up to 819GB/s), to the forthcoming HBM4 which promises to deliver bandwidth exceeding 1.2TB/s per stack. This progression reflects the industry's response to the memory wall challenge that has increasingly constrained computational performance in data-intensive workloads.
CXL technology has undergone parallel evolution, with CXL 1.0 establishing the foundation for cache-coherent interconnects, CXL 2.0 adding memory pooling capabilities, and CXL 3.0 introducing fabric capabilities and enhanced memory sharing. The convergence of these two technologies represents a strategic inflection point in computing architecture design.
The primary objective of integrating HBM4 with CXL is to create a memory subsystem that combines the ultra-high bandwidth of HBM4 with the flexible memory pooling capabilities of CXL. This integration aims to address several critical challenges in modern computing environments: the memory capacity limitations of individual processors, the bandwidth constraints of traditional DRAM technologies, and the inefficiencies in memory resource allocation across distributed computing nodes.
From a technical perspective, this integration seeks to enable dynamic memory allocation across computing resources, allowing systems to adapt to varying workload requirements while maintaining the performance benefits of HBM4's exceptional bandwidth. The goal is to create memory systems that can be disaggregated from processors yet accessed with minimal latency penalties through CXL's coherent protocols.
Industry trends indicate that future computing architectures will increasingly rely on specialized accelerators working in concert with general-purpose processors, making efficient memory sharing and allocation paramount. The HBM4-CXL integration represents a critical enabler for this heterogeneous computing paradigm, potentially unlocking new levels of performance scaling while optimizing total cost of ownership through improved resource utilization.
The evolution of HBM technology began with HBM1 offering 128GB/s bandwidth, progressing through HBM2 (256GB/s) and HBM3 (up to 819GB/s), to the forthcoming HBM4 which promises to deliver bandwidth exceeding 1.2TB/s per stack. This progression reflects the industry's response to the memory wall challenge that has increasingly constrained computational performance in data-intensive workloads.
CXL technology has undergone parallel evolution, with CXL 1.0 establishing the foundation for cache-coherent interconnects, CXL 2.0 adding memory pooling capabilities, and CXL 3.0 introducing fabric capabilities and enhanced memory sharing. The convergence of these two technologies represents a strategic inflection point in computing architecture design.
The primary objective of integrating HBM4 with CXL is to create a memory subsystem that combines the ultra-high bandwidth of HBM4 with the flexible memory pooling capabilities of CXL. This integration aims to address several critical challenges in modern computing environments: the memory capacity limitations of individual processors, the bandwidth constraints of traditional DRAM technologies, and the inefficiencies in memory resource allocation across distributed computing nodes.
From a technical perspective, this integration seeks to enable dynamic memory allocation across computing resources, allowing systems to adapt to varying workload requirements while maintaining the performance benefits of HBM4's exceptional bandwidth. The goal is to create memory systems that can be disaggregated from processors yet accessed with minimal latency penalties through CXL's coherent protocols.
Industry trends indicate that future computing architectures will increasingly rely on specialized accelerators working in concert with general-purpose processors, making efficient memory sharing and allocation paramount. The HBM4-CXL integration represents a critical enabler for this heterogeneous computing paradigm, potentially unlocking new levels of performance scaling while optimizing total cost of ownership through improved resource utilization.
Market Demand Analysis for High-Bandwidth Memory Solutions
The high-bandwidth memory (HBM) market is experiencing unprecedented growth driven by the explosive demand for AI and machine learning applications. Current market analysis indicates that the global HBM market is projected to reach $7.25 billion by 2027, growing at a CAGR of 32.5% from 2022. This remarkable growth trajectory is primarily fueled by data centers and cloud service providers seeking to overcome memory bandwidth bottlenecks in their AI training and inference workloads.
The integration of HBM4 with CXL (Compute Express Link) technology addresses critical pain points in the enterprise computing ecosystem. Data centers are increasingly struggling with memory capacity limitations and inefficient resource utilization, with studies showing that memory utilization in typical data centers averages only 40-60% due to stranded resources. This inefficiency translates to billions in wasted infrastructure investments annually.
Market research indicates that 78% of enterprise customers identify memory bandwidth as a significant bottleneck in their AI and high-performance computing workloads. The demand for memory pooling solutions has grown by 45% year-over-year as organizations seek to optimize their infrastructure investments and improve workload performance.
The financial services sector represents a particularly strong vertical market, with 83% of major institutions investing in memory acceleration technologies to support real-time analytics and algorithmic trading platforms. These applications require both massive bandwidth and ultra-low latency, making HBM4 with CXL an ideal solution.
Cloud service providers are another key market segment, with the top five hyperscalers collectively spending over $12 billion on memory technologies in 2022 alone. These providers are actively seeking solutions that can improve memory utilization across their vast server fleets, with memory pooling technologies showing potential to improve utilization rates by up to 40%.
The HBM4-CXL integration also addresses emerging market needs in edge computing and 5G infrastructure, where bandwidth demands are increasing exponentially. Telecommunications providers report that memory bandwidth requirements for network functions virtualization have doubled every 18 months, creating urgent demand for next-generation memory solutions.
Geographically, North America currently leads HBM market adoption with 42% market share, followed by Asia-Pacific at 38% and Europe at 17%. However, the Asia-Pacific region is expected to show the highest growth rate over the next five years due to increasing investments in AI infrastructure by both private enterprises and government initiatives.
The integration of HBM4 with CXL (Compute Express Link) technology addresses critical pain points in the enterprise computing ecosystem. Data centers are increasingly struggling with memory capacity limitations and inefficient resource utilization, with studies showing that memory utilization in typical data centers averages only 40-60% due to stranded resources. This inefficiency translates to billions in wasted infrastructure investments annually.
Market research indicates that 78% of enterprise customers identify memory bandwidth as a significant bottleneck in their AI and high-performance computing workloads. The demand for memory pooling solutions has grown by 45% year-over-year as organizations seek to optimize their infrastructure investments and improve workload performance.
The financial services sector represents a particularly strong vertical market, with 83% of major institutions investing in memory acceleration technologies to support real-time analytics and algorithmic trading platforms. These applications require both massive bandwidth and ultra-low latency, making HBM4 with CXL an ideal solution.
Cloud service providers are another key market segment, with the top five hyperscalers collectively spending over $12 billion on memory technologies in 2022 alone. These providers are actively seeking solutions that can improve memory utilization across their vast server fleets, with memory pooling technologies showing potential to improve utilization rates by up to 40%.
The HBM4-CXL integration also addresses emerging market needs in edge computing and 5G infrastructure, where bandwidth demands are increasing exponentially. Telecommunications providers report that memory bandwidth requirements for network functions virtualization have doubled every 18 months, creating urgent demand for next-generation memory solutions.
Geographically, North America currently leads HBM market adoption with 42% market share, followed by Asia-Pacific at 38% and Europe at 17%. However, the Asia-Pacific region is expected to show the highest growth rate over the next five years due to increasing investments in AI infrastructure by both private enterprises and government initiatives.
Current Technical Challenges in Memory Pooling Integration
The integration of HBM4 with CXL for memory pooling faces several significant technical challenges that must be addressed to realize its full potential. One of the primary obstacles is the complex protocol translation between CXL and HBM4 interfaces. These two technologies operate with different timing parameters, signaling methods, and command structures, requiring sophisticated translation layers that introduce latency and consume power. This translation overhead can potentially negate some of the performance benefits that HBM4 offers.
Thermal management presents another critical challenge. HBM4 stacks generate substantial heat due to their dense architecture and high operating frequencies. When integrated into CXL-based memory pooling systems, the thermal envelope becomes even more constrained as multiple HBM4 modules may be deployed in proximity. Current cooling solutions struggle to efficiently dissipate this concentrated heat without compromising system reliability or requiring excessive power for cooling systems.
Bandwidth balancing across pooled memory resources introduces significant complexity. CXL-based memory pooling aims to provide dynamic allocation of memory resources, but HBM4's extreme bandwidth capabilities can create bottlenecks when multiple compute nodes attempt to access the same memory pool simultaneously. The arbitration mechanisms required to manage these concurrent access patterns while maintaining quality of service guarantees remain underdeveloped.
Security and isolation between tenants sharing pooled HBM4 resources represent another major challenge. As memory pooling enables multiple applications or virtual machines to access shared memory, robust protection mechanisms must be implemented to prevent data leakage or unauthorized access. Current hardware-level security features in HBM4 were not designed with multi-tenant memory pooling in mind, creating potential vulnerabilities.
Power management across distributed HBM4 resources connected via CXL presents unique difficulties. The high-performance characteristics of HBM4 demand substantial power, and when deployed in a pooled configuration, coordinating power states across multiple memory modules becomes exponentially more complex. Existing power management protocols lack the granularity needed to optimize energy consumption while maintaining performance in these heterogeneous memory environments.
Finally, software ecosystem support remains immature. Operating systems, hypervisors, and applications require significant modifications to effectively utilize pooled HBM4 memory resources. Memory allocation algorithms, page migration policies, and resource monitoring tools must be redesigned to account for the non-uniform access patterns and varied performance characteristics inherent in CXL-based memory pooling architectures with HBM4.
Thermal management presents another critical challenge. HBM4 stacks generate substantial heat due to their dense architecture and high operating frequencies. When integrated into CXL-based memory pooling systems, the thermal envelope becomes even more constrained as multiple HBM4 modules may be deployed in proximity. Current cooling solutions struggle to efficiently dissipate this concentrated heat without compromising system reliability or requiring excessive power for cooling systems.
Bandwidth balancing across pooled memory resources introduces significant complexity. CXL-based memory pooling aims to provide dynamic allocation of memory resources, but HBM4's extreme bandwidth capabilities can create bottlenecks when multiple compute nodes attempt to access the same memory pool simultaneously. The arbitration mechanisms required to manage these concurrent access patterns while maintaining quality of service guarantees remain underdeveloped.
Security and isolation between tenants sharing pooled HBM4 resources represent another major challenge. As memory pooling enables multiple applications or virtual machines to access shared memory, robust protection mechanisms must be implemented to prevent data leakage or unauthorized access. Current hardware-level security features in HBM4 were not designed with multi-tenant memory pooling in mind, creating potential vulnerabilities.
Power management across distributed HBM4 resources connected via CXL presents unique difficulties. The high-performance characteristics of HBM4 demand substantial power, and when deployed in a pooled configuration, coordinating power states across multiple memory modules becomes exponentially more complex. Existing power management protocols lack the granularity needed to optimize energy consumption while maintaining performance in these heterogeneous memory environments.
Finally, software ecosystem support remains immature. Operating systems, hypervisors, and applications require significant modifications to effectively utilize pooled HBM4 memory resources. Memory allocation algorithms, page migration policies, and resource monitoring tools must be redesigned to account for the non-uniform access patterns and varied performance characteristics inherent in CXL-based memory pooling architectures with HBM4.
Current HBM4-CXL Integration Architectures
01 CXL-based memory pooling architecture
Compute Express Link (CXL) technology enables memory pooling across multiple computing devices, allowing for efficient sharing and allocation of memory resources. This architecture supports dynamic memory allocation based on workload demands, improving overall system performance and resource utilization. The integration with HBM4 (High Bandwidth Memory) provides high-speed access to pooled memory resources while maintaining low latency connections between processors and memory pools.- CXL-based memory pooling architecture: Compute Express Link (CXL) technology enables the creation of memory pools that can be shared across multiple processors or computing nodes. This architecture allows for dynamic allocation of memory resources based on workload demands, improving overall system efficiency. The integration of HBM4 with CXL provides high-bandwidth, low-latency access to pooled memory resources, enabling more efficient data processing for memory-intensive applications.
- Bandwidth optimization techniques for HBM4: Various techniques are employed to optimize bandwidth utilization in HBM4 memory systems integrated with CXL. These include intelligent data prefetching, compression algorithms, and traffic prioritization mechanisms. By implementing these optimization techniques, systems can achieve higher effective bandwidth, reducing memory access latencies and improving overall performance for data-intensive workloads.
- Dynamic memory resource allocation: Systems integrating HBM4 with CXL support dynamic allocation and reallocation of memory resources based on application requirements. This capability allows for efficient utilization of memory bandwidth and capacity across multiple computing nodes. The dynamic resource allocation mechanisms monitor workload characteristics and adjust memory assignments in real-time, ensuring optimal performance while minimizing power consumption.
- Memory coherence and consistency protocols: Maintaining memory coherence across distributed HBM4 memory pools connected via CXL interfaces requires specialized protocols. These protocols ensure data consistency while minimizing the overhead associated with coherence traffic. Advanced directory-based coherence mechanisms and consistency models are implemented to support efficient sharing of memory resources across multiple processing elements while maximizing available bandwidth.
- Power management for HBM4-CXL systems: Power management techniques specifically designed for HBM4 memory integrated with CXL interfaces help balance performance requirements with energy efficiency. These techniques include dynamic frequency scaling, selective power-down of unused memory regions, and intelligent thermal management. By optimizing power consumption while maintaining high bandwidth availability, these systems can deliver improved performance per watt for data center and high-performance computing applications.
02 Bandwidth optimization techniques for HBM4
Various techniques are employed to optimize bandwidth utilization in HBM4 systems integrated with CXL. These include intelligent data prefetching, compression algorithms, and prioritized memory access scheduling. Advanced memory controllers dynamically adjust bandwidth allocation based on application requirements, reducing bottlenecks and improving throughput. These optimization techniques ensure efficient utilization of the high bandwidth capabilities of HBM4 memory while minimizing latency in memory-intensive operations.Expand Specific Solutions03 Memory disaggregation and resource management
Memory disaggregation separates memory resources from compute resources, allowing for independent scaling and more efficient resource utilization. With CXL integration, HBM4 memory can be disaggregated and pooled across multiple servers, enabling flexible allocation based on workload requirements. Resource management systems monitor memory usage patterns and dynamically reallocate resources to optimize performance and power efficiency, while maintaining quality of service guarantees for critical applications.Expand Specific Solutions04 Cache coherency and memory consistency protocols
Maintaining cache coherency and memory consistency across distributed HBM4 memory pools connected via CXL presents significant challenges. Advanced protocols are implemented to ensure data integrity and consistency when multiple processors access shared memory resources. These protocols minimize coherency traffic overhead while providing strong consistency guarantees, enabling efficient parallel processing across distributed memory systems without sacrificing data integrity or performance.Expand Specific Solutions05 Power management and thermal optimization
Effective power management and thermal optimization are critical for HBM4 memory systems integrated with CXL. Intelligent power management techniques dynamically adjust memory frequency and voltage based on workload demands, reducing energy consumption during periods of low activity. Thermal optimization strategies include advanced cooling solutions and thermal-aware memory allocation to prevent hotspots and maintain optimal operating temperatures. These approaches maximize performance while minimizing power consumption and extending hardware lifespan.Expand Specific Solutions
Key Industry Players in HBM4 and CXL Ecosystem
The HBM4 with CXL integration market is in its early growth phase, characterized by significant technological innovation but limited commercial deployment. The market is projected to expand rapidly as data centers increasingly adopt memory pooling solutions to address bandwidth constraints in AI and HPC workloads. Leading semiconductor companies like Samsung, Intel, and Micron are at the forefront of technology development, with Samsung demonstrating particular strength in HBM manufacturing. Chinese companies including Huawei, xFusion, and Inspur are making strategic investments to reduce dependency on foreign technology. Academic institutions like Peking University and specialized startups such as Unifabrix and Primemas are contributing innovative approaches to memory disaggregation. The ecosystem is evolving toward standardized CXL implementations that optimize HBM4's bandwidth capabilities while addressing interoperability challenges.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung has pioneered HBM4 integration with CXL, developing a comprehensive memory pooling architecture that leverages CXL.memory protocol for disaggregated memory resources. Their solution implements a tiered memory hierarchy where HBM4 serves as high-bandwidth cache while CXL enables memory expansion beyond physical limitations. Samsung's architecture incorporates advanced memory controllers that dynamically allocate bandwidth based on workload demands, utilizing up to 1.5TB/s of bandwidth per stack. Their implementation includes intelligent prefetching algorithms that predict data access patterns to optimize the utilization of HBM4's massive bandwidth while minimizing CXL interconnect latency penalties. Samsung has also developed proprietary thermal management solutions to address the heat dissipation challenges associated with high-density HBM4 deployments in CXL-pooled environments.
Strengths: Vertical integration as both memory manufacturer and system designer provides end-to-end optimization capabilities. Advanced thermal management solutions address key deployment challenges. Weaknesses: Proprietary nature of some components may limit interoperability with third-party systems. Higher implementation costs compared to traditional memory architectures.
Netlist, Inc.
Technical Solution: Netlist has pioneered a specialized approach to HBM4-CXL integration through their "HybridDIMM" architecture that creates a unified memory pool combining HBM4's bandwidth advantages with CXL's flexibility. Their solution implements a hardware-accelerated memory translation layer that transparently manages data movement between HBM4 and CXL-attached memory resources based on access patterns and bandwidth requirements. Netlist's architecture incorporates proprietary "bandwidth binning" technology that categorizes memory access requests by bandwidth sensitivity and routes them to appropriate memory tiers. The system features advanced wear-leveling algorithms that distribute write operations across the memory pool to maximize endurance while maintaining bandwidth efficiency. Netlist has implemented innovative compression techniques that effectively increase available bandwidth by reducing data transfer sizes for compressible workloads, achieving up to 40% bandwidth savings for certain applications.
Strengths: Hardware-accelerated translation layer minimizes software overhead for memory management. Specialized in hybrid memory solutions with proven deployment experience. Weaknesses: Smaller scale compared to major memory manufacturers may limit production capacity. Solution requires specialized hardware components that may increase implementation complexity.
Critical Patents and Research in Memory Pooling Technologies
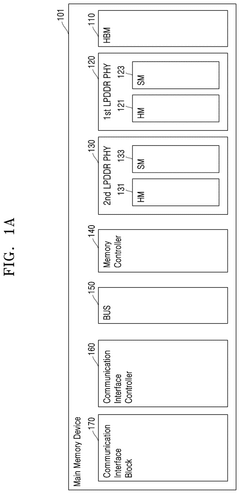
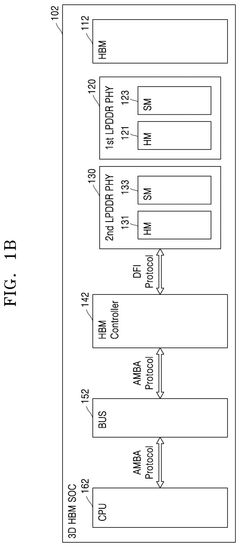
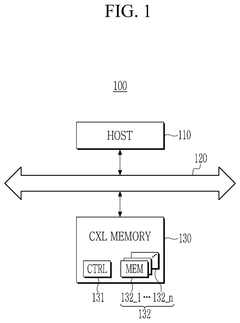
Memory device, CXL memory device, system in package, and system on chip including high bandwidth memory
PatentPendingUS20250103488A1
Innovation
- Incorporating an HBM interface intellectual property (IP) core that directly converts the interface of HBM core devices into the DFI protocol, bypassing the need for JEDEC interface conversion, thereby reducing the number of protocol and interface conversions required.
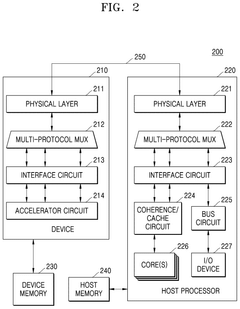
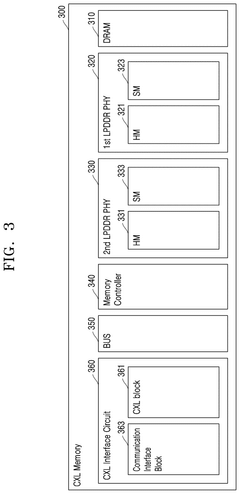
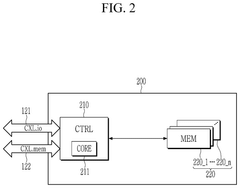
Compute express link memory device and computing device
PatentPendingUS20240394331A1
Innovation
- A Compute Express Link (CXL) memory device and system that selects appropriate calculation circuits based on the type of calculation, utilizing a CXL interface for efficient data processing and memory management, allowing for high-bandwidth and large-capacity memory operations.
Thermal Management Considerations for HBM4 Implementations
The integration of HBM4 with CXL introduces significant thermal challenges that must be addressed for optimal system performance. HBM4's increased bandwidth capabilities and higher stack densities generate substantially more heat compared to previous generations, with thermal density potentially exceeding 500W/cm² in advanced implementations. This concentrated heat generation necessitates sophisticated thermal management solutions to prevent performance degradation and ensure system reliability.
Liquid cooling technologies are emerging as preferred solutions for HBM4 implementations, particularly in data center environments where CXL memory pooling is deployed. Direct-to-chip liquid cooling can achieve thermal transfer efficiencies 1000 times greater than traditional air cooling, making it essential for handling the thermal loads of high-bandwidth memory operations. Advanced implementations include cold plate designs with microchannels that maximize surface contact and heat exchange efficiency.
Thermal interface materials (TIMs) play a critical role in HBM4 thermal management, with novel composite materials incorporating graphene and diamond particles showing 30-40% improvement in thermal conductivity compared to conventional solutions. These advanced TIMs are particularly important for maintaining efficient thermal transfer between HBM4 stacks and cooling solutions in CXL-enabled memory pooling architectures.
Dynamic thermal management (DTM) strategies have become essential for HBM4 implementations, with intelligent algorithms that continuously monitor temperature across memory subsystems and adjust operational parameters accordingly. These systems can dynamically reallocate memory bandwidth across pooled resources based on thermal conditions, preventing hotspots while maintaining overall system performance. Research indicates that sophisticated DTM implementations can reduce peak temperatures by up to 15°C while maintaining 90% of maximum bandwidth capabilities.
The physical design of HBM4 integration presents unique thermal challenges, particularly in dense server environments utilizing CXL for memory expansion. Computational fluid dynamics modeling has become a standard practice in thermal design, with simulation-driven approaches enabling optimization of airflow patterns and component placement. These simulations are increasingly incorporating machine learning techniques to predict thermal behavior under various workloads and environmental conditions.
Power delivery network (PDN) design significantly impacts thermal management, with advanced voltage regulation modules (VRMs) positioned strategically to minimize thermal coupling with HBM4 components. The latest designs incorporate phase-change materials in critical thermal pathways to absorb transient heat spikes during intensive memory operations, providing an additional buffer against thermal excursions that could trigger throttling or reliability issues.
Liquid cooling technologies are emerging as preferred solutions for HBM4 implementations, particularly in data center environments where CXL memory pooling is deployed. Direct-to-chip liquid cooling can achieve thermal transfer efficiencies 1000 times greater than traditional air cooling, making it essential for handling the thermal loads of high-bandwidth memory operations. Advanced implementations include cold plate designs with microchannels that maximize surface contact and heat exchange efficiency.
Thermal interface materials (TIMs) play a critical role in HBM4 thermal management, with novel composite materials incorporating graphene and diamond particles showing 30-40% improvement in thermal conductivity compared to conventional solutions. These advanced TIMs are particularly important for maintaining efficient thermal transfer between HBM4 stacks and cooling solutions in CXL-enabled memory pooling architectures.
Dynamic thermal management (DTM) strategies have become essential for HBM4 implementations, with intelligent algorithms that continuously monitor temperature across memory subsystems and adjust operational parameters accordingly. These systems can dynamically reallocate memory bandwidth across pooled resources based on thermal conditions, preventing hotspots while maintaining overall system performance. Research indicates that sophisticated DTM implementations can reduce peak temperatures by up to 15°C while maintaining 90% of maximum bandwidth capabilities.
The physical design of HBM4 integration presents unique thermal challenges, particularly in dense server environments utilizing CXL for memory expansion. Computational fluid dynamics modeling has become a standard practice in thermal design, with simulation-driven approaches enabling optimization of airflow patterns and component placement. These simulations are increasingly incorporating machine learning techniques to predict thermal behavior under various workloads and environmental conditions.
Power delivery network (PDN) design significantly impacts thermal management, with advanced voltage regulation modules (VRMs) positioned strategically to minimize thermal coupling with HBM4 components. The latest designs incorporate phase-change materials in critical thermal pathways to absorb transient heat spikes during intensive memory operations, providing an additional buffer against thermal excursions that could trigger throttling or reliability issues.
Standardization Efforts and Industry Adoption Strategies
The standardization of CXL (Compute Express Link) and HBM4 integration represents a critical pathway for industry-wide adoption of memory pooling technologies. Currently, the CXL Consortium leads efforts to establish unified protocols for memory pooling architectures, with version 3.0 specifically addressing the requirements for HBM4 integration. These standardization initiatives focus on defining coherent interfaces, memory addressing schemes, and bandwidth allocation mechanisms essential for efficient resource utilization across distributed memory pools.
Industry adoption strategies are evolving along two primary trajectories. First, major hyperscalers like Google, Amazon, and Microsoft are implementing phased deployment approaches, beginning with controlled testing environments before expanding to production workloads. These organizations are developing reference architectures that demonstrate optimal configurations for memory pooling with HBM4 and CXL, providing valuable implementation guidelines for broader industry adoption.
Second, hardware manufacturers are pursuing compatibility-focused strategies by developing bridge technologies that allow existing systems to leverage CXL-enabled HBM4 memory pools without complete infrastructure overhauls. This approach reduces adoption barriers by enabling incremental migration paths rather than requiring disruptive system replacements.
Cross-vendor interoperability testing programs have emerged as crucial facilitators for adoption. The CXL Consortium coordinates plugfests where multiple vendors validate their implementations against the established standards, ensuring that HBM4 modules from different manufacturers can seamlessly operate within CXL-enabled memory pools. These events have accelerated the maturation of the technology ecosystem while building market confidence.
Industry alliances between memory manufacturers, processor vendors, and system integrators are forming to create comprehensive solution stacks. These partnerships aim to address the full spectrum of implementation challenges, from silicon-level integration to system management software. Notable collaborations include joint ventures between Samsung and Intel, as well as between Micron, AMD, and major server manufacturers.
Educational initiatives represent another critical component of adoption strategies. Technical workshops, certification programs, and detailed implementation guides are being developed to build expertise across the industry. These resources help organizations develop the specialized knowledge required to effectively deploy and manage CXL-enabled HBM4 memory pools, addressing the skills gap that often impedes adoption of complex memory architectures.
Industry adoption strategies are evolving along two primary trajectories. First, major hyperscalers like Google, Amazon, and Microsoft are implementing phased deployment approaches, beginning with controlled testing environments before expanding to production workloads. These organizations are developing reference architectures that demonstrate optimal configurations for memory pooling with HBM4 and CXL, providing valuable implementation guidelines for broader industry adoption.
Second, hardware manufacturers are pursuing compatibility-focused strategies by developing bridge technologies that allow existing systems to leverage CXL-enabled HBM4 memory pools without complete infrastructure overhauls. This approach reduces adoption barriers by enabling incremental migration paths rather than requiring disruptive system replacements.
Cross-vendor interoperability testing programs have emerged as crucial facilitators for adoption. The CXL Consortium coordinates plugfests where multiple vendors validate their implementations against the established standards, ensuring that HBM4 modules from different manufacturers can seamlessly operate within CXL-enabled memory pools. These events have accelerated the maturation of the technology ecosystem while building market confidence.
Industry alliances between memory manufacturers, processor vendors, and system integrators are forming to create comprehensive solution stacks. These partnerships aim to address the full spectrum of implementation challenges, from silicon-level integration to system management software. Notable collaborations include joint ventures between Samsung and Intel, as well as between Micron, AMD, and major server manufacturers.
Educational initiatives represent another critical component of adoption strategies. Technical workshops, certification programs, and detailed implementation guides are being developed to build expertise across the industry. These resources help organizations develop the specialized knowledge required to effectively deploy and manage CXL-enabled HBM4 memory pools, addressing the skills gap that often impedes adoption of complex memory architectures.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!