HBM4 Monitoring And Telemetry: Error Logging And Thermal Sensing
SEP 12, 202510 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
HBM4 Technology Background and Objectives
High Bandwidth Memory (HBM) technology has evolved significantly since its introduction, with HBM4 representing the latest advancement in this critical memory architecture. HBM emerged as a response to the growing demand for higher memory bandwidth and capacity in data-intensive applications such as artificial intelligence, high-performance computing, and graphics processing. The development trajectory from HBM1 to HBM4 demonstrates a consistent focus on increasing bandwidth, reducing power consumption, and enhancing overall system performance.
HBM4 builds upon its predecessors by introducing substantial improvements in stack height, bandwidth per pin, and total capacity. While HBM3 offered up to 819 GB/s bandwidth per stack, HBM4 aims to deliver significantly higher performance, potentially exceeding 1.2 TB/s per stack. This evolution addresses the exponential growth in computational requirements driven by increasingly complex AI models and data processing needs.
The monitoring and telemetry capabilities in HBM4, particularly error logging and thermal sensing, represent critical advancements in memory system reliability and performance optimization. As memory densities increase and operating frequencies push higher, the probability of errors and thermal challenges grows proportionally. These monitoring systems aim to provide real-time visibility into memory health and performance, enabling proactive management of potential issues.
Error logging in HBM4 is designed to capture, categorize, and report various types of memory errors, from correctable single-bit errors to more serious multi-bit failures. This capability allows systems to implement advanced error correction techniques and predictive maintenance strategies, significantly improving overall system reliability and availability. The evolution of these error detection and correction mechanisms reflects the increasing importance of memory integrity in mission-critical applications.
Thermal sensing in HBM4 addresses one of the most significant challenges in high-density memory systems: heat management. As memory stacks become denser and operate at higher frequencies, thermal issues can severely impact both performance and reliability. Advanced thermal sensors distributed throughout the memory stack provide granular temperature data, enabling dynamic thermal management through techniques such as adaptive refresh rates and intelligent power management.
The primary objectives of HBM4's monitoring and telemetry systems are to enhance system reliability, optimize performance under varying workloads, extend memory lifespan, and provide valuable diagnostic information for system administrators and engineers. These capabilities are particularly crucial for enterprise and data center environments where downtime must be minimized and performance consistency is paramount.
Looking forward, the continued evolution of HBM technology will likely focus on further refinements to these monitoring systems, potentially incorporating machine learning algorithms for predictive analytics and more sophisticated error prevention strategies. The industry trajectory suggests increasing integration between memory subsystems and overall system management frameworks, creating more intelligent and self-optimizing computing platforms.
HBM4 builds upon its predecessors by introducing substantial improvements in stack height, bandwidth per pin, and total capacity. While HBM3 offered up to 819 GB/s bandwidth per stack, HBM4 aims to deliver significantly higher performance, potentially exceeding 1.2 TB/s per stack. This evolution addresses the exponential growth in computational requirements driven by increasingly complex AI models and data processing needs.
The monitoring and telemetry capabilities in HBM4, particularly error logging and thermal sensing, represent critical advancements in memory system reliability and performance optimization. As memory densities increase and operating frequencies push higher, the probability of errors and thermal challenges grows proportionally. These monitoring systems aim to provide real-time visibility into memory health and performance, enabling proactive management of potential issues.
Error logging in HBM4 is designed to capture, categorize, and report various types of memory errors, from correctable single-bit errors to more serious multi-bit failures. This capability allows systems to implement advanced error correction techniques and predictive maintenance strategies, significantly improving overall system reliability and availability. The evolution of these error detection and correction mechanisms reflects the increasing importance of memory integrity in mission-critical applications.
Thermal sensing in HBM4 addresses one of the most significant challenges in high-density memory systems: heat management. As memory stacks become denser and operate at higher frequencies, thermal issues can severely impact both performance and reliability. Advanced thermal sensors distributed throughout the memory stack provide granular temperature data, enabling dynamic thermal management through techniques such as adaptive refresh rates and intelligent power management.
The primary objectives of HBM4's monitoring and telemetry systems are to enhance system reliability, optimize performance under varying workloads, extend memory lifespan, and provide valuable diagnostic information for system administrators and engineers. These capabilities are particularly crucial for enterprise and data center environments where downtime must be minimized and performance consistency is paramount.
Looking forward, the continued evolution of HBM technology will likely focus on further refinements to these monitoring systems, potentially incorporating machine learning algorithms for predictive analytics and more sophisticated error prevention strategies. The industry trajectory suggests increasing integration between memory subsystems and overall system management frameworks, creating more intelligent and self-optimizing computing platforms.
Market Demand Analysis for HBM4 Solutions
The demand for High Bandwidth Memory (HBM) solutions continues to surge dramatically, with HBM4 positioned as the next-generation standard poised to address increasingly complex data processing requirements. Market research indicates that the global HBM market is projected to grow at a compound annual growth rate exceeding 30% through 2028, driven primarily by artificial intelligence, high-performance computing, and data center applications.
The explosion of AI workloads represents the most significant driver for advanced memory solutions like HBM4. Large language models and generative AI applications require unprecedented memory bandwidth and capacity, with models growing exponentially in size. Training these models demands memory solutions that can efficiently handle massive parallel processing operations while maintaining thermal stability and error resilience.
Data center operators are expressing urgent demand for memory solutions with enhanced monitoring capabilities. As workloads become more mission-critical, the financial impact of system downtime has escalated dramatically. Advanced error logging and predictive failure analysis capabilities in HBM4 directly address this pain point, potentially saving millions in operational costs through preemptive maintenance rather than reactive troubleshooting.
The automotive and edge computing sectors represent emerging markets for HBM4 solutions with robust monitoring features. Autonomous driving systems require memory components that can operate reliably under variable environmental conditions, making thermal sensing capabilities particularly valuable. Market surveys indicate that automotive manufacturers are willing to pay premium prices for memory solutions that offer comprehensive telemetry data to ensure safety-critical system reliability.
Hyperscalers and cloud service providers are increasingly demanding memory solutions that contribute to overall data center efficiency. With power consumption becoming both an environmental and economic concern, the thermal sensing capabilities of HBM4 align perfectly with the market's push toward more energy-efficient computing. These providers seek solutions that can dynamically adjust performance based on thermal conditions to optimize power usage effectiveness.
The financial services sector represents another significant market segment, where the combination of high-frequency trading applications and regulatory requirements creates demand for memory solutions with comprehensive error logging. The ability to trace and document system behavior is becoming a compliance requirement in many jurisdictions, making HBM4's monitoring capabilities particularly attractive to this sector.
Geographic analysis reveals that North America currently leads demand for advanced HBM solutions, followed closely by Asia-Pacific, where rapid data center expansion is occurring. European markets show particular interest in energy-efficient computing solutions, making the thermal optimization capabilities of HBM4 especially relevant in this region.
The explosion of AI workloads represents the most significant driver for advanced memory solutions like HBM4. Large language models and generative AI applications require unprecedented memory bandwidth and capacity, with models growing exponentially in size. Training these models demands memory solutions that can efficiently handle massive parallel processing operations while maintaining thermal stability and error resilience.
Data center operators are expressing urgent demand for memory solutions with enhanced monitoring capabilities. As workloads become more mission-critical, the financial impact of system downtime has escalated dramatically. Advanced error logging and predictive failure analysis capabilities in HBM4 directly address this pain point, potentially saving millions in operational costs through preemptive maintenance rather than reactive troubleshooting.
The automotive and edge computing sectors represent emerging markets for HBM4 solutions with robust monitoring features. Autonomous driving systems require memory components that can operate reliably under variable environmental conditions, making thermal sensing capabilities particularly valuable. Market surveys indicate that automotive manufacturers are willing to pay premium prices for memory solutions that offer comprehensive telemetry data to ensure safety-critical system reliability.
Hyperscalers and cloud service providers are increasingly demanding memory solutions that contribute to overall data center efficiency. With power consumption becoming both an environmental and economic concern, the thermal sensing capabilities of HBM4 align perfectly with the market's push toward more energy-efficient computing. These providers seek solutions that can dynamically adjust performance based on thermal conditions to optimize power usage effectiveness.
The financial services sector represents another significant market segment, where the combination of high-frequency trading applications and regulatory requirements creates demand for memory solutions with comprehensive error logging. The ability to trace and document system behavior is becoming a compliance requirement in many jurisdictions, making HBM4's monitoring capabilities particularly attractive to this sector.
Geographic analysis reveals that North America currently leads demand for advanced HBM solutions, followed closely by Asia-Pacific, where rapid data center expansion is occurring. European markets show particular interest in energy-efficient computing solutions, making the thermal optimization capabilities of HBM4 especially relevant in this region.
Current State and Challenges in HBM4 Monitoring
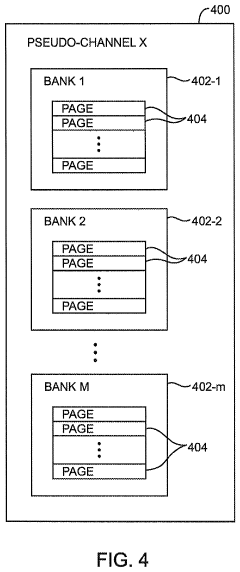
The current state of HBM4 monitoring and telemetry systems represents a significant advancement over previous generations, yet faces several critical challenges as data processing demands continue to escalate. HBM4 technology has implemented sophisticated error logging mechanisms capable of detecting and recording various types of memory errors with unprecedented granularity, including single-bit errors, multi-bit errors, and address-related failures. These systems now operate at the bank group level, allowing for more precise identification of problematic memory regions.
Thermal sensing in HBM4 has evolved to include distributed temperature sensors throughout the memory stack, with typical implementations featuring 4-8 sensors per stack. This represents an improvement over HBM3's more limited thermal monitoring capabilities. Current implementations can detect temperature variations across different layers of the memory stack with accuracy typically within ±1.5°C, enabling more responsive thermal management.
Despite these advancements, several significant challenges persist in HBM4 monitoring systems. Power consumption of the monitoring circuitry itself has become a concern, as these systems now consume approximately 2-3% of the total HBM power budget. This creates a design tension between comprehensive monitoring and energy efficiency goals, particularly in data center applications where power constraints are increasingly stringent.
Latency implications present another major challenge. Current monitoring systems introduce additional overhead to memory operations, with telemetry data collection adding approximately 3-5 nanoseconds to certain memory transactions. While this overhead is managed through parallel processing pathways, it remains a performance consideration for latency-sensitive applications.
Data volume management represents perhaps the most pressing challenge. Modern HBM4 stacks can generate up to 1GB of monitoring data per hour under high-stress workloads. Processing and storing this volume of telemetry data requires sophisticated data reduction algorithms and prioritization schemes that are still being optimized.
Integration complexity with host systems presents additional difficulties. Current HBM4 monitoring systems must interface with diverse host architectures, operating systems, and management software. The lack of fully standardized monitoring protocols across the industry has led to fragmented implementation approaches, complicating system integration and potentially limiting interoperability.
Security vulnerabilities in monitoring systems have also emerged as a concern. Recent research has demonstrated that telemetry data can potentially be exploited to extract information about memory access patterns, creating side-channel vulnerabilities that could compromise system security in certain applications.
Thermal sensing in HBM4 has evolved to include distributed temperature sensors throughout the memory stack, with typical implementations featuring 4-8 sensors per stack. This represents an improvement over HBM3's more limited thermal monitoring capabilities. Current implementations can detect temperature variations across different layers of the memory stack with accuracy typically within ±1.5°C, enabling more responsive thermal management.
Despite these advancements, several significant challenges persist in HBM4 monitoring systems. Power consumption of the monitoring circuitry itself has become a concern, as these systems now consume approximately 2-3% of the total HBM power budget. This creates a design tension between comprehensive monitoring and energy efficiency goals, particularly in data center applications where power constraints are increasingly stringent.
Latency implications present another major challenge. Current monitoring systems introduce additional overhead to memory operations, with telemetry data collection adding approximately 3-5 nanoseconds to certain memory transactions. While this overhead is managed through parallel processing pathways, it remains a performance consideration for latency-sensitive applications.
Data volume management represents perhaps the most pressing challenge. Modern HBM4 stacks can generate up to 1GB of monitoring data per hour under high-stress workloads. Processing and storing this volume of telemetry data requires sophisticated data reduction algorithms and prioritization schemes that are still being optimized.
Integration complexity with host systems presents additional difficulties. Current HBM4 monitoring systems must interface with diverse host architectures, operating systems, and management software. The lack of fully standardized monitoring protocols across the industry has led to fragmented implementation approaches, complicating system integration and potentially limiting interoperability.
Security vulnerabilities in monitoring systems have also emerged as a concern. Recent research has demonstrated that telemetry data can potentially be exploited to extract information about memory access patterns, creating side-channel vulnerabilities that could compromise system security in certain applications.
Existing HBM4 Error Logging and Thermal Management Solutions
01 Error logging mechanisms in HBM4 memory systems
High Bandwidth Memory 4 (HBM4) systems incorporate advanced error logging mechanisms to detect, record, and manage memory errors. These mechanisms include error detection circuits that can identify various types of errors such as bit flips, parity errors, and ECC (Error Correction Code) failures. The logged error data can be stored in dedicated registers or memory areas for later analysis, helping system administrators and engineers diagnose issues and improve system reliability. These error logging capabilities are crucial for maintaining data integrity in high-performance computing environments that utilize HBM4 technology.- Error logging mechanisms in HBM4 memory systems: High Bandwidth Memory 4 (HBM4) systems incorporate advanced error logging mechanisms to detect, record, and manage memory errors. These systems can identify various types of errors including correctable and uncorrectable errors, and log detailed information about error occurrences. The error logging functionality enables system administrators to monitor memory health, diagnose issues, and take preventive actions before critical failures occur. These mechanisms often include error counters, status registers, and notification systems that can alert the host system when error thresholds are exceeded.
- Thermal sensing and management in HBM4 architecture: HBM4 memory systems incorporate sophisticated thermal sensing technologies to monitor temperature conditions across memory stacks. These thermal sensors are strategically placed to detect hotspots and provide real-time temperature data. The thermal management system uses this data to implement dynamic thermal management strategies, including throttling memory operations or adjusting refresh rates when temperatures approach critical thresholds. This helps maintain optimal performance while preventing thermal-related failures and extending the lifespan of the memory components.
- Integration of error logging with thermal data in HBM4: Advanced HBM4 memory systems feature integrated approaches that correlate error logging with thermal data. This integration enables systems to identify relationships between temperature fluctuations and error rates, providing valuable insights into memory behavior under various thermal conditions. The combined data helps in implementing predictive maintenance strategies and optimizing memory performance based on environmental conditions. These systems can dynamically adjust memory parameters based on both error patterns and thermal profiles to maintain system stability.
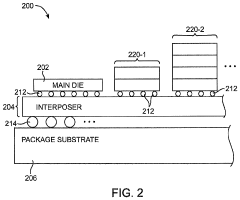
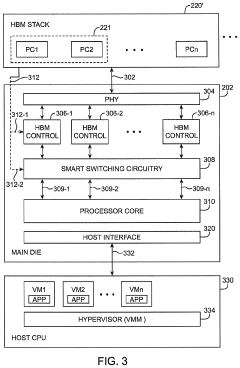
- HBM4 stack architecture with enhanced monitoring capabilities: HBM4 memory utilizes a stacked die architecture with integrated monitoring capabilities for both errors and thermal conditions. The stack design incorporates dedicated monitoring circuits within the logic layer that can track memory operations across multiple memory dies. This architecture enables comprehensive monitoring without significant performance overhead. The monitoring system can collect data from various points within the memory stack and provide aggregated information to the memory controller, facilitating efficient system management and troubleshooting.
- Communication protocols for HBM4 error and thermal data: HBM4 memory systems implement specialized communication protocols to efficiently transmit error logs and thermal sensing data to the host system. These protocols define standardized formats for error reporting and thermal data, enabling seamless integration with system management software. The communication channels are designed to minimize overhead while ensuring timely delivery of critical information. These protocols support various notification mechanisms, including interrupt-based alerts for critical conditions and periodic reporting for ongoing monitoring, allowing system software to respond appropriately to changing memory conditions.
02 Thermal sensing and management in HBM4 architecture
HBM4 memory systems incorporate sophisticated thermal sensing technologies to monitor and manage operating temperatures. These systems utilize integrated temperature sensors strategically placed throughout the memory stack to provide real-time temperature data. When temperatures approach critical thresholds, thermal management systems can initiate various cooling responses, including dynamic frequency scaling, workload redistribution, or activating additional cooling mechanisms. This thermal monitoring is essential for preventing overheating that could lead to performance degradation, data corruption, or physical damage to the memory components, while ensuring optimal performance under varying workload conditions.Expand Specific Solutions03 Integration of error logging with thermal data in HBM4
Advanced HBM4 memory systems feature integrated approaches that combine error logging with thermal sensing data. This integration allows systems to correlate memory errors with temperature fluctuations, providing valuable insights into the relationship between thermal conditions and memory reliability. When error rates increase at specific temperature thresholds, the system can implement adaptive measures such as adjusting refresh rates, modifying voltage levels, or redistributing memory access patterns. This holistic approach to monitoring both errors and temperature enables more effective predictive maintenance and can significantly improve the overall reliability and lifespan of HBM4 memory systems.Expand Specific Solutions04 Memory stack architecture optimizations for error handling and thermal management
HBM4 memory stack architectures incorporate specific design optimizations to enhance both error handling capabilities and thermal management. These include specialized interposer designs with integrated thermal dissipation pathways, strategically placed through-silicon vias (TSVs) that serve dual purposes for electrical connectivity and heat transfer, and buffer layers that improve thermal conductivity while maintaining signal integrity. The physical arrangement of memory dies within the stack can be optimized to distribute heat more evenly and reduce hotspots. These architectural innovations work together to minimize error rates related to thermal issues while maximizing data throughput and reliability in high-performance computing applications.Expand Specific Solutions05 Machine learning approaches for predictive error management in HBM4
Advanced HBM4 memory systems implement machine learning algorithms to analyze error logging and thermal sensing data for predictive maintenance. These systems collect historical data on error occurrences, temperature patterns, and system performance metrics to build predictive models that can anticipate potential memory failures before they occur. By identifying subtle patterns and correlations that might not be apparent through conventional monitoring, these AI-driven approaches enable proactive interventions such as workload redistribution, selective refresh operations, or scheduled maintenance. This predictive capability significantly reduces system downtime and extends the operational lifespan of HBM4 memory components in data-intensive applications.Expand Specific Solutions
Key Industry Players in HBM4 Ecosystem
The HBM4 Monitoring and Telemetry market is currently in an early growth phase, characterized by increasing adoption of high-bandwidth memory solutions in data centers and AI applications. The global market is projected to expand significantly as demand for advanced memory solutions with robust error logging and thermal management capabilities grows. Key players shaping this technological landscape include IBM, Taiwan Semiconductor Manufacturing Co. (TSMC), and Western Digital, who are developing sophisticated monitoring systems for memory performance and reliability. Samsung and SK Hynix, though not listed, remain influential manufacturers. The technology is approaching maturity in implementation but continues to evolve with companies like Global Unichip Corp. and Dell Products LP integrating advanced telemetry features to address thermal challenges and enhance system reliability in high-performance computing environments.
International Business Machines Corp.
Technical Solution: IBM has developed advanced HBM4 monitoring and telemetry systems focusing on comprehensive error logging and thermal sensing capabilities. Their solution implements a multi-layered approach to memory error detection and correction with real-time monitoring capabilities. The system features dedicated on-die sensors distributed across the HBM4 stack that continuously monitor thermal conditions at microsecond intervals, providing granular temperature data for each memory layer. IBM's implementation includes an enhanced error detection and correction (EDAC) mechanism that can identify, log, and correct single-bit errors while flagging multi-bit errors for system intervention. The telemetry data is processed through a dedicated controller that aggregates information from all sensors and error detection circuits, enabling system-level decisions for thermal management and error handling. IBM has also implemented machine learning algorithms that analyze historical error and thermal patterns to predict potential failures before they occur, allowing for proactive maintenance scheduling.
Strengths: Superior integration with enterprise systems, particularly in data center environments; advanced predictive analytics for failure prevention; comprehensive error logging capabilities with detailed diagnostics. Weaknesses: Higher implementation complexity requiring specialized expertise; potentially higher power consumption due to extensive monitoring capabilities; may require significant system resources for full functionality.
Taiwan Semiconductor Manufacturing Co., Ltd.
Technical Solution: TSMC has engineered a sophisticated HBM4 monitoring and telemetry solution that integrates directly into their manufacturing process. Their approach embeds thermal sensors and error detection circuits directly during the fabrication of HBM4 stacks, creating a manufacturing-level solution for memory reliability. The system incorporates distributed thermal sensors with sub-100μs response times positioned strategically throughout the memory stack, particularly at known hotspot locations. TSMC's error logging infrastructure captures both correctable and uncorrectable errors with timestamp precision, storing this data in dedicated on-die registers that can be accessed via standardized interfaces. Their solution also features an innovative power-efficient monitoring mode that dynamically adjusts sensing frequency based on workload intensity and thermal conditions, optimizing power consumption while maintaining monitoring effectiveness. The telemetry data is transmitted through a dedicated low-latency channel that doesn't interfere with normal memory operations, ensuring continuous monitoring without performance penalties.
Strengths: Highly integrated solution with minimal additional components; manufacturing-level quality assurance; excellent power efficiency through adaptive monitoring. Weaknesses: Less flexibility for post-deployment customization; potentially higher initial implementation cost; requires close coordination between memory manufacturers and system integrators.
Core Technologies for HBM4 Monitoring and Telemetry
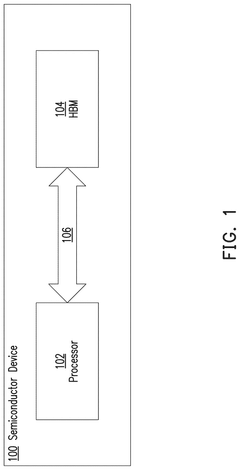
System for controlling temperatures of memory and method of operating same
PatentPendingUS20250266064A1
Innovation
- Implementing differentiated dynamic voltage and frequency scaling (DDVFS) that adjusts clock signals and power supply voltages at a granular level, such as bank-wide, group-wide, channel-wide, or core-wide, based on localized temperature and threshold voltage sensing, to efficiently control temperature variations within the HBM.
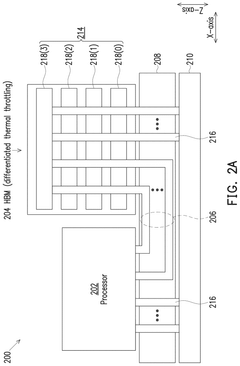
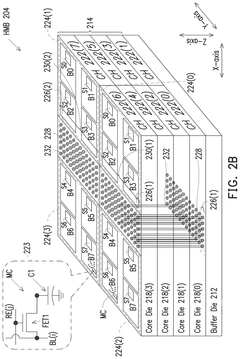
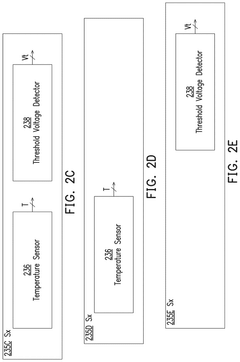
Methods and apparatus for managing thermal behavior in multichip packages
PatentActiveUS20220013505A1
Innovation
- A thermal controller circuit is implemented to monitor and manage temperature across multiple dies within a stack by selectively throttling access to hotter dies, rerouting traffic, and using address translation and smart switching techniques to maintain a balanced thermal profile, ensuring that colder dies are accessed more frequently and that temperature gradients are accurately estimated.
Power Efficiency Considerations for HBM4 Monitoring
Power efficiency has emerged as a critical consideration in the design and implementation of HBM4 monitoring systems. As data centers continue to expand and high-performance computing applications proliferate, the energy consumption of memory subsystems represents an increasingly significant portion of overall system power usage. HBM4's monitoring capabilities, while essential for system reliability and performance optimization, introduce additional power requirements that must be carefully managed.
The monitoring circuits in HBM4 memory, particularly those dedicated to error logging and thermal sensing, consume power continuously during operation. These components include temperature sensors distributed across memory dies, error detection and correction circuits, and the communication pathways that transmit telemetry data. Without proper optimization, these monitoring systems could potentially offset the inherent power efficiency advantages that HBM4 architecture offers over previous generations.
Advanced power management techniques are being developed specifically for HBM4 monitoring systems. These include dynamic adjustment of monitoring frequencies based on workload characteristics and system conditions. For instance, during periods of low memory utilization or stable thermal conditions, the frequency of temperature sampling can be reduced, thereby decreasing power consumption without compromising system safety.
Architectural innovations in HBM4 monitoring circuits have focused on reducing static power consumption through improved transistor designs and voltage scaling techniques. Some implementations incorporate power gating for monitoring circuits during idle periods, effectively disconnecting them from power sources when their functionality is not required. This approach significantly reduces leakage current, which constitutes a substantial portion of power consumption in advanced semiconductor processes.
The integration of machine learning algorithms represents another frontier in power-efficient monitoring. These algorithms can predict thermal patterns and potential error occurrences based on historical data, allowing for more intelligent allocation of monitoring resources. By focusing monitoring activities on areas and times where issues are most likely to occur, overall power consumption can be reduced while maintaining or even improving system reliability.
Communication protocols for telemetry data transmission have also been optimized for energy efficiency. Newer implementations utilize serialization techniques and compressed data formats to minimize the number of active I/O lines and reduce transmission power requirements. Some designs incorporate local processing of monitoring data within the memory stack itself, reducing the volume of information that needs to be transmitted to the host processor.
Industry benchmarks suggest that these combined approaches can reduce the power overhead of HBM4 monitoring systems by up to 30% compared to naive implementations, while maintaining comprehensive coverage for error detection and thermal management. This improvement directly contributes to the overall energy efficiency of high-performance computing systems, data centers, and AI accelerators that increasingly rely on HBM4 technology.
The monitoring circuits in HBM4 memory, particularly those dedicated to error logging and thermal sensing, consume power continuously during operation. These components include temperature sensors distributed across memory dies, error detection and correction circuits, and the communication pathways that transmit telemetry data. Without proper optimization, these monitoring systems could potentially offset the inherent power efficiency advantages that HBM4 architecture offers over previous generations.
Advanced power management techniques are being developed specifically for HBM4 monitoring systems. These include dynamic adjustment of monitoring frequencies based on workload characteristics and system conditions. For instance, during periods of low memory utilization or stable thermal conditions, the frequency of temperature sampling can be reduced, thereby decreasing power consumption without compromising system safety.
Architectural innovations in HBM4 monitoring circuits have focused on reducing static power consumption through improved transistor designs and voltage scaling techniques. Some implementations incorporate power gating for monitoring circuits during idle periods, effectively disconnecting them from power sources when their functionality is not required. This approach significantly reduces leakage current, which constitutes a substantial portion of power consumption in advanced semiconductor processes.
The integration of machine learning algorithms represents another frontier in power-efficient monitoring. These algorithms can predict thermal patterns and potential error occurrences based on historical data, allowing for more intelligent allocation of monitoring resources. By focusing monitoring activities on areas and times where issues are most likely to occur, overall power consumption can be reduced while maintaining or even improving system reliability.
Communication protocols for telemetry data transmission have also been optimized for energy efficiency. Newer implementations utilize serialization techniques and compressed data formats to minimize the number of active I/O lines and reduce transmission power requirements. Some designs incorporate local processing of monitoring data within the memory stack itself, reducing the volume of information that needs to be transmitted to the host processor.
Industry benchmarks suggest that these combined approaches can reduce the power overhead of HBM4 monitoring systems by up to 30% compared to naive implementations, while maintaining comprehensive coverage for error detection and thermal management. This improvement directly contributes to the overall energy efficiency of high-performance computing systems, data centers, and AI accelerators that increasingly rely on HBM4 technology.
Reliability Standards and Testing Methodologies
Reliability standards for HBM4 memory systems are governed by several key industry bodies, including JEDEC, which has established comprehensive specifications for high-bandwidth memory technologies. These standards define the minimum requirements for error detection, correction capabilities, and thermal management that HBM4 implementations must meet to ensure operational reliability in high-performance computing environments.
The testing methodologies for HBM4 monitoring and telemetry systems typically involve multi-phase validation processes. Initial qualification testing subjects memory modules to extreme conditions, including temperature cycling between -40°C and 125°C, to verify the accuracy of thermal sensors across the operational spectrum. Error logging mechanisms undergo rigorous verification through fault injection techniques, where deliberate errors are introduced to confirm proper detection and reporting functionality.
Industry-standard reliability metrics such as Mean Time Between Failures (MTBF) and Failures In Time (FIT) are applied specifically to HBM4 memory stacks, with expected MTBF values typically exceeding 1.5 million hours for enterprise-grade implementations. The testing protocols also include accelerated life testing methodologies that simulate years of operation within compressed timeframes to identify potential long-term reliability issues.
Compliance with JEDEC JESD79-5 and related standards requires HBM4 devices to maintain error logging capabilities even during power fluctuations, necessitating testing under various power state transitions. The thermal sensing elements must demonstrate accuracy within ±1.5°C across the operational temperature range, with calibration procedures verified through standardized thermal chamber testing.
Electromagnetic Interference (EMI) and Electromagnetic Compatibility (EMC) testing has become increasingly important for HBM4 monitoring systems, as the high-speed signaling can potentially introduce noise that affects telemetry accuracy. Specialized test chambers are employed to verify that monitoring circuits maintain accuracy even under electromagnetic stress conditions.
Reliability qualification for HBM4 also includes specific tests for the telemetry interfaces, ensuring that error logs and thermal data can be accurately transmitted to host systems under various operating conditions. This includes verification of interface timing parameters and signal integrity across temperature and voltage variations, with particular attention to maintaining communication reliability during thermal throttling events.
The testing methodologies for HBM4 monitoring and telemetry systems typically involve multi-phase validation processes. Initial qualification testing subjects memory modules to extreme conditions, including temperature cycling between -40°C and 125°C, to verify the accuracy of thermal sensors across the operational spectrum. Error logging mechanisms undergo rigorous verification through fault injection techniques, where deliberate errors are introduced to confirm proper detection and reporting functionality.
Industry-standard reliability metrics such as Mean Time Between Failures (MTBF) and Failures In Time (FIT) are applied specifically to HBM4 memory stacks, with expected MTBF values typically exceeding 1.5 million hours for enterprise-grade implementations. The testing protocols also include accelerated life testing methodologies that simulate years of operation within compressed timeframes to identify potential long-term reliability issues.
Compliance with JEDEC JESD79-5 and related standards requires HBM4 devices to maintain error logging capabilities even during power fluctuations, necessitating testing under various power state transitions. The thermal sensing elements must demonstrate accuracy within ±1.5°C across the operational temperature range, with calibration procedures verified through standardized thermal chamber testing.
Electromagnetic Interference (EMI) and Electromagnetic Compatibility (EMC) testing has become increasingly important for HBM4 monitoring systems, as the high-speed signaling can potentially introduce noise that affects telemetry accuracy. Specialized test chambers are employed to verify that monitoring circuits maintain accuracy even under electromagnetic stress conditions.
Reliability qualification for HBM4 also includes specific tests for the telemetry interfaces, ensuring that error logs and thermal data can be accurately transmitted to host systems under various operating conditions. This includes verification of interface timing parameters and signal integrity across temperature and voltage variations, with particular attention to maintaining communication reliability during thermal throttling events.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!