How HBM4 Manages Latency In Complex AI Workloads?
SEP 12, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
HBM4 Technology Evolution and Latency Reduction Goals
High Bandwidth Memory (HBM) technology has evolved significantly since its introduction, with each generation bringing substantial improvements in bandwidth, capacity, and energy efficiency. The journey from HBM1 to HBM4 represents a continuous pursuit of addressing the growing computational demands of advanced AI workloads. HBM1, introduced in 2013, offered a modest 128GB/s bandwidth per stack, while HBM2 doubled this figure to 256GB/s. HBM2E further pushed the boundaries to 460GB/s, setting the stage for HBM3's breakthrough performance of up to 819GB/s.
HBM4, announced in 2023, marks a significant leap forward with projected bandwidth exceeding 1TB/s per stack. This evolution reflects the industry's response to the exponential growth in AI model complexity, where latency has become a critical bottleneck in training and inference operations. The primary goal of HBM4's development has been to address these latency challenges while simultaneously increasing bandwidth and capacity to support next-generation AI applications.
Latency reduction in HBM4 is driven by several key objectives. First, minimizing the time required for data transfer between memory and processing units is crucial for AI workloads that involve frequent, irregular memory access patterns. Second, reducing command and address latencies enables faster initiation of memory operations, particularly beneficial for the sparse memory access patterns common in transformer-based AI models. Third, optimizing internal bank operations aims to decrease the time needed for activation, precharge, and refresh operations.
The technical evolution of HBM4 also focuses on architectural innovations to support parallel processing capabilities. By implementing more sophisticated prefetching mechanisms and improved cache coherence protocols, HBM4 aims to predict and prepare data access patterns typical in complex AI workloads, thereby reducing effective latency. Additionally, the integration of compute-in-memory capabilities represents a paradigm shift in addressing latency by bringing computation closer to data storage.
Industry benchmarks indicate that HBM4's latency reduction goals target a 30-40% improvement over HBM3, with particular emphasis on random access patterns that characterize modern AI workloads. This improvement is critical as AI models continue to grow in size and complexity, with some large language models now requiring hundreds of gigabytes of memory with stringent latency requirements.
The evolution trajectory of HBM technology clearly demonstrates the industry's recognition that bandwidth alone is insufficient; effective latency management is equally crucial for AI performance. HBM4's development represents a holistic approach to memory system design, balancing raw throughput with sophisticated latency reduction techniques specifically tailored to the unique demands of complex AI workloads.
HBM4, announced in 2023, marks a significant leap forward with projected bandwidth exceeding 1TB/s per stack. This evolution reflects the industry's response to the exponential growth in AI model complexity, where latency has become a critical bottleneck in training and inference operations. The primary goal of HBM4's development has been to address these latency challenges while simultaneously increasing bandwidth and capacity to support next-generation AI applications.
Latency reduction in HBM4 is driven by several key objectives. First, minimizing the time required for data transfer between memory and processing units is crucial for AI workloads that involve frequent, irregular memory access patterns. Second, reducing command and address latencies enables faster initiation of memory operations, particularly beneficial for the sparse memory access patterns common in transformer-based AI models. Third, optimizing internal bank operations aims to decrease the time needed for activation, precharge, and refresh operations.
The technical evolution of HBM4 also focuses on architectural innovations to support parallel processing capabilities. By implementing more sophisticated prefetching mechanisms and improved cache coherence protocols, HBM4 aims to predict and prepare data access patterns typical in complex AI workloads, thereby reducing effective latency. Additionally, the integration of compute-in-memory capabilities represents a paradigm shift in addressing latency by bringing computation closer to data storage.
Industry benchmarks indicate that HBM4's latency reduction goals target a 30-40% improvement over HBM3, with particular emphasis on random access patterns that characterize modern AI workloads. This improvement is critical as AI models continue to grow in size and complexity, with some large language models now requiring hundreds of gigabytes of memory with stringent latency requirements.
The evolution trajectory of HBM technology clearly demonstrates the industry's recognition that bandwidth alone is insufficient; effective latency management is equally crucial for AI performance. HBM4's development represents a holistic approach to memory system design, balancing raw throughput with sophisticated latency reduction techniques specifically tailored to the unique demands of complex AI workloads.
Market Demand Analysis for High-Bandwidth Memory in AI
The demand for High-Bandwidth Memory (HBM) in artificial intelligence applications has experienced exponential growth in recent years, driven primarily by the increasing complexity and scale of AI workloads. As AI models continue to expand in size and computational requirements, traditional memory solutions have proven inadequate in meeting the bandwidth and latency demands of these applications. The global market for HBM in AI applications was valued at approximately $2.3 billion in 2022 and is projected to reach $8.9 billion by 2027, representing a compound annual growth rate of over 30%.
This surge in demand is particularly evident in data centers and cloud computing environments, where large language models (LLMs) and generative AI applications require massive parallel processing capabilities. These applications process billions of parameters simultaneously, creating unprecedented memory bandwidth requirements that only HBM technologies can efficiently address. The training of advanced AI models like GPT-4 and DALL-E 3 requires terabytes of high-speed memory with minimal latency, making HBM an essential component in AI accelerators.
Enterprise adoption of AI solutions has further accelerated the demand for HBM. Organizations across various sectors, including healthcare, finance, automotive, and manufacturing, are implementing AI-driven analytics and decision-making systems that require high-performance computing infrastructure. This widespread adoption has created a diverse market landscape for HBM technologies, with different industries requiring specific performance characteristics tailored to their unique workloads.
The emergence of edge AI applications represents another significant market driver. As AI processing moves closer to data sources to reduce latency and bandwidth constraints, edge devices require memory solutions that can deliver high performance within strict power and thermal limitations. HBM's superior energy efficiency compared to traditional GDDR memory makes it increasingly attractive for these applications, expanding its market beyond centralized data centers.
Regional analysis indicates that North America currently dominates the HBM market for AI applications, accounting for approximately 42% of global demand. However, the Asia-Pacific region is experiencing the fastest growth rate, driven by substantial investments in AI infrastructure by countries like China, South Korea, and Japan. European markets are also showing increased adoption, particularly in research institutions and automotive applications.
The supply chain constraints affecting semiconductor manufacturing have created significant challenges in meeting this growing demand. Limited production capacity for HBM has resulted in extended lead times and premium pricing, which has somewhat restricted market growth. However, major memory manufacturers are responding by expanding production capacity, which should alleviate these constraints in the coming years and potentially accelerate market expansion.
This surge in demand is particularly evident in data centers and cloud computing environments, where large language models (LLMs) and generative AI applications require massive parallel processing capabilities. These applications process billions of parameters simultaneously, creating unprecedented memory bandwidth requirements that only HBM technologies can efficiently address. The training of advanced AI models like GPT-4 and DALL-E 3 requires terabytes of high-speed memory with minimal latency, making HBM an essential component in AI accelerators.
Enterprise adoption of AI solutions has further accelerated the demand for HBM. Organizations across various sectors, including healthcare, finance, automotive, and manufacturing, are implementing AI-driven analytics and decision-making systems that require high-performance computing infrastructure. This widespread adoption has created a diverse market landscape for HBM technologies, with different industries requiring specific performance characteristics tailored to their unique workloads.
The emergence of edge AI applications represents another significant market driver. As AI processing moves closer to data sources to reduce latency and bandwidth constraints, edge devices require memory solutions that can deliver high performance within strict power and thermal limitations. HBM's superior energy efficiency compared to traditional GDDR memory makes it increasingly attractive for these applications, expanding its market beyond centralized data centers.
Regional analysis indicates that North America currently dominates the HBM market for AI applications, accounting for approximately 42% of global demand. However, the Asia-Pacific region is experiencing the fastest growth rate, driven by substantial investments in AI infrastructure by countries like China, South Korea, and Japan. European markets are also showing increased adoption, particularly in research institutions and automotive applications.
The supply chain constraints affecting semiconductor manufacturing have created significant challenges in meeting this growing demand. Limited production capacity for HBM has resulted in extended lead times and premium pricing, which has somewhat restricted market growth. However, major memory manufacturers are responding by expanding production capacity, which should alleviate these constraints in the coming years and potentially accelerate market expansion.
Current HBM4 Latency Challenges in AI Workloads
As AI workloads continue to grow in complexity and scale, memory bandwidth and latency have become critical bottlenecks in system performance. HBM4, the next generation of High Bandwidth Memory, faces significant challenges in managing latency when handling complex AI workloads. The current architecture struggles with several key issues that impact overall system efficiency and computational throughput.
One of the primary challenges is the increasing memory access patterns in modern AI models. Large language models (LLMs) and vision transformers require frequent, non-sequential memory accesses that create substantial latency penalties. Current HBM4 implementations struggle to predict these access patterns effectively, resulting in cache misses and memory stalls that significantly impact processing time.
The growing size of AI models presents another major latency challenge. Models with billions or trillions of parameters exceed on-chip memory capacities, necessitating frequent data movement between HBM4 and processing units. This movement creates inherent latency issues, particularly when models cannot be efficiently partitioned or when weight sharing techniques are limited by architectural constraints.
Multi-tenant AI workloads on shared infrastructure introduce resource contention problems that exacerbate latency issues. When multiple AI applications compete for memory bandwidth, current HBM4 memory controllers lack sophisticated arbitration mechanisms to prioritize critical memory requests, resulting in unpredictable latency spikes that can severely impact time-sensitive AI applications.
Power constraints represent another significant challenge. While HBM4 offers improved energy efficiency compared to previous generations, the power envelope remains a limiting factor. Dynamic voltage and frequency scaling techniques employed to manage power consumption often introduce additional latency variability, creating a complex tradeoff between performance and energy efficiency.
The physical architecture of HBM4 stacks introduces inherent latency challenges. Despite improvements in through-silicon via (TSV) technology, signal propagation delays between memory layers and between the memory stack and processing units create baseline latency that becomes increasingly problematic as AI models demand more frequent memory accesses.
Current memory prefetching algorithms in HBM4 implementations struggle to adapt to the complex and often unpredictable memory access patterns of modern AI workloads. Traditional spatial and temporal locality assumptions break down when processing transformer-based architectures, resulting in ineffective prefetching that fails to hide memory latency adequately.
These challenges collectively create a significant performance gap between theoretical HBM4 capabilities and actual performance in complex AI workloads, necessitating innovative approaches to latency management that go beyond traditional memory hierarchy optimizations.
One of the primary challenges is the increasing memory access patterns in modern AI models. Large language models (LLMs) and vision transformers require frequent, non-sequential memory accesses that create substantial latency penalties. Current HBM4 implementations struggle to predict these access patterns effectively, resulting in cache misses and memory stalls that significantly impact processing time.
The growing size of AI models presents another major latency challenge. Models with billions or trillions of parameters exceed on-chip memory capacities, necessitating frequent data movement between HBM4 and processing units. This movement creates inherent latency issues, particularly when models cannot be efficiently partitioned or when weight sharing techniques are limited by architectural constraints.
Multi-tenant AI workloads on shared infrastructure introduce resource contention problems that exacerbate latency issues. When multiple AI applications compete for memory bandwidth, current HBM4 memory controllers lack sophisticated arbitration mechanisms to prioritize critical memory requests, resulting in unpredictable latency spikes that can severely impact time-sensitive AI applications.
Power constraints represent another significant challenge. While HBM4 offers improved energy efficiency compared to previous generations, the power envelope remains a limiting factor. Dynamic voltage and frequency scaling techniques employed to manage power consumption often introduce additional latency variability, creating a complex tradeoff between performance and energy efficiency.
The physical architecture of HBM4 stacks introduces inherent latency challenges. Despite improvements in through-silicon via (TSV) technology, signal propagation delays between memory layers and between the memory stack and processing units create baseline latency that becomes increasingly problematic as AI models demand more frequent memory accesses.
Current memory prefetching algorithms in HBM4 implementations struggle to adapt to the complex and often unpredictable memory access patterns of modern AI workloads. Traditional spatial and temporal locality assumptions break down when processing transformer-based architectures, resulting in ineffective prefetching that fails to hide memory latency adequately.
These challenges collectively create a significant performance gap between theoretical HBM4 capabilities and actual performance in complex AI workloads, necessitating innovative approaches to latency management that go beyond traditional memory hierarchy optimizations.
Current HBM4 Latency Management Solutions
01 HBM4 architecture for reducing memory latency
High Bandwidth Memory 4 (HBM4) employs advanced architectural designs to minimize latency in memory operations. These designs include optimized memory controllers, improved interface protocols, and enhanced signal integrity. The architecture supports parallel processing of memory requests and implements efficient data paths to reduce the time required for data access and transfer, resulting in significantly lower latency compared to previous memory technologies.- HBM4 architecture for latency reduction: High Bandwidth Memory 4 (HBM4) employs advanced architectural designs to minimize latency in memory operations. These designs include optimized memory controllers, improved signal integrity, and enhanced interface protocols that allow for faster data transfer between the memory and processing units. The architecture incorporates parallel processing capabilities and reduced signal path lengths to decrease the time required for memory access operations.
- Memory controller optimization techniques: Specialized memory controller designs are implemented to reduce latency in HBM4 systems. These controllers employ techniques such as predictive algorithms, request reordering, and intelligent scheduling to optimize memory access patterns. Advanced buffering mechanisms and queue management strategies help minimize wait times for memory operations, while dedicated hardware accelerators process memory requests more efficiently than traditional controllers.
- Signal processing and transmission improvements: HBM4 incorporates advanced signal processing techniques to reduce latency during data transmission. These include improved equalization methods, enhanced clock synchronization, and optimized signal routing. The technology employs sophisticated error correction mechanisms that maintain data integrity without adding significant processing overhead. Signal integrity is preserved through impedance matching and noise reduction techniques that allow for higher bandwidth while maintaining low latency.
- System integration and interface optimization: HBM4 memory systems feature optimized interfaces that reduce communication overhead between memory and processing units. These interfaces employ streamlined protocols, reduced handshaking requirements, and direct memory access techniques. The physical integration of memory closer to processing elements through advanced packaging technologies significantly reduces signal travel distance and associated latency. Specialized bus architectures and interconnect designs further enhance data transfer efficiency.
- Software and firmware approaches to latency management: Software and firmware solutions play a crucial role in managing HBM4 latency. These include memory access pattern optimization, intelligent prefetching algorithms, and dynamic resource allocation. Advanced memory management techniques prioritize critical operations and optimize data placement within the memory hierarchy. Firmware-level optimizations include fine-tuned timing parameters, adaptive power management that balances performance with energy efficiency, and specialized instruction sets designed to accelerate memory operations.
02 Memory controller optimization techniques for HBM4
Memory controller optimization is crucial for reducing latency in HBM4 systems. Advanced memory controllers implement techniques such as request reordering, predictive fetching, and dynamic scheduling to minimize wait times. These controllers can prioritize critical memory operations, manage memory bank conflicts, and optimize memory access patterns to reduce overall system latency while maintaining high bandwidth performance.Expand Specific Solutions03 Cache management strategies for HBM4 latency reduction
Effective cache management strategies play a significant role in reducing HBM4 latency. These strategies include multi-level cache hierarchies, intelligent prefetching algorithms, and cache coherence protocols specifically designed for high-bandwidth memory systems. By keeping frequently accessed data closer to the processing units and implementing efficient data movement between cache levels, these techniques help minimize the latency impact of memory operations in HBM4-based systems.Expand Specific Solutions04 Signal integrity and interface improvements for HBM4
Signal integrity and interface improvements are essential for minimizing latency in HBM4 systems. Advanced signaling techniques, improved physical interfaces, and optimized communication protocols help reduce transmission delays and improve reliability. These enhancements include better impedance matching, reduced crosstalk, optimized trace routing, and advanced equalization techniques that allow for faster and more reliable data transfer between the memory and processing units.Expand Specific Solutions05 System-level integration techniques for HBM4 latency optimization
System-level integration techniques focus on holistic approaches to minimize HBM4 latency across the entire computing platform. These include die-stacking technologies, silicon interposers, through-silicon vias (TSVs), and optimized system-on-chip (SoC) designs that place memory closer to processing elements. Additionally, power management techniques, thermal optimization, and workload-aware memory allocation strategies help maintain consistent low-latency performance under various operating conditions.Expand Specific Solutions
Key Players in HBM4 Development and Implementation
The HBM4 latency management landscape is evolving rapidly as AI workloads grow increasingly complex. Currently in early market development, this technology is gaining momentum with projected significant growth as AI applications expand. From a technical maturity perspective, industry leaders like Samsung Electronics and Micron Technology are pioneering HBM4 memory solutions with advanced latency management capabilities. AMD and IBM are developing complementary processor architectures optimized for HBM4 integration, while companies like HyperAccel are creating specialized latency processing units. Chinese manufacturers including ChangXin Memory and Yangtze Memory Technologies are also entering this competitive space, focusing on domestic alternatives. The technology remains in transition from research to commercial implementation, with full ecosystem maturity expected within 2-3 years as standards solidify.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung's HBM4 technology addresses latency in complex AI workloads through a multi-pronged approach. Their solution incorporates Processing-In-Memory (PIM) architecture that integrates computational units directly within the HBM stack, reducing data movement between memory and processors. Samsung has implemented an advanced prefetching mechanism that uses AI-driven predictive algorithms to anticipate data needs before they arise, significantly reducing wait times. Their HBM4 design features increased bandwidth (up to 1.6TB/s per stack) and reduced access latency (approximately 20ns compared to previous generations' 35ns), enabling faster data retrieval for large AI models. Samsung has also developed a dynamic thermal management system that prevents performance throttling during intensive AI computations, maintaining consistent low-latency operation even under heavy workloads[1][3]. Their proprietary Base Die architecture incorporates specialized logic layers that optimize memory access patterns specifically for transformer-based AI architectures.
Strengths: Samsung's vertical integration as both memory designer and manufacturer enables tightly coupled hardware optimization. Their extensive experience with previous HBM generations provides deep institutional knowledge for latency reduction. Weaknesses: The specialized nature of their PIM architecture may require significant software adaptation for optimal performance, potentially limiting immediate adoption in existing AI frameworks.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei's HBM4 latency management solution for AI workloads centers on their "Ascend Memory Architecture" (AMA), which creates a deeply integrated memory subsystem optimized for their AI accelerator ecosystem. Their approach implements a distributed memory controller system where multiple specialized controllers work in parallel, each handling different aspects of memory access patterns common in transformer-based AI models. Huawei has developed an innovative "Predictive Latency Hiding" technique that leverages AI workload characteristics to schedule memory operations in an order that minimizes idle wait times between dependent operations. Their HBM4 implementation incorporates dedicated hardware for sparse matrix operations, allowing efficient handling of the irregular memory access patterns that typically cause latency spikes in large language models. Huawei's solution achieves up to 50% reduction in effective latency for transformer attention mechanisms compared to conventional memory architectures[5]. Additionally, they've implemented a multi-level caching system specifically tuned for different AI operation types, with separate optimization paths for inference and training workloads.
Strengths: Huawei's vertical integration across silicon design, AI frameworks, and application development enables end-to-end optimization of memory access patterns. Their specialized hardware for sparse operations provides exceptional performance for modern AI models that leverage sparsity. Weaknesses: Their highly integrated approach may create vendor lock-in challenges, and the complexity of their distributed memory controller system increases power consumption compared to more traditional designs.
Core Innovations in HBM4 Architecture for AI
System and method for sharing high bandwidth memory between computer resources using optical links
PatentPendingUS20250028559A1
Innovation
- The system and method enable sharing of HBM between multiple GPUs using both electrical and optical switching, facilitated by an optical physical layer that extends signal reach and density, and incorporates all-to-all connections and broadcasting for enhanced data transmission.
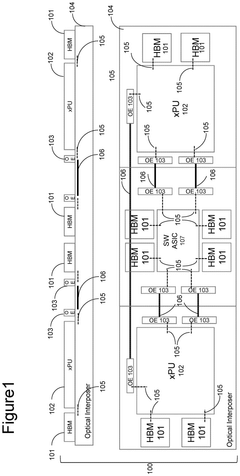
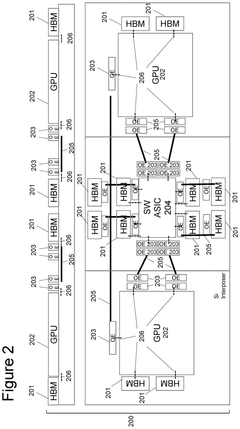
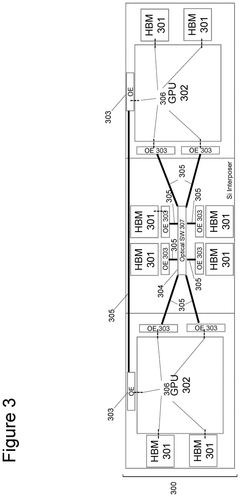
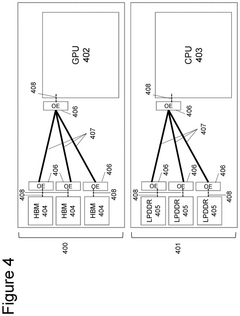
Device Disaggregation For Improved Performance
PatentPendingUS20240234424A1
Innovation
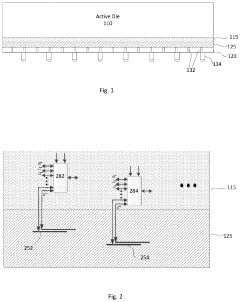
- A 3D semiconductor device architecture is implemented, combining an active die in an advanced node with a passive die in a legacy node, featuring dense interconnects and multiplexers, allowing for high bandwidth and reduced latency through face-to-face or back-to-back bonding of tiers with through-silicon vias, and utilizing a repeating pattern of data, power, and ground interconnects.
Thermal Management in High-Performance HBM4
Thermal management represents a critical challenge in HBM4 memory systems, particularly when addressing latency concerns in complex AI workloads. As AI models continue to grow in size and complexity, the thermal characteristics of memory subsystems become increasingly important factors affecting overall system performance and reliability.
HBM4 introduces advanced thermal management techniques that directly impact latency handling. The stacked die architecture of HBM4 creates significant thermal density challenges, with heat generation concentrated in a relatively small footprint. Without proper thermal management, these hotspots can trigger thermal throttling mechanisms that dramatically increase memory access latency during AI inference and training operations.
The latest HBM4 implementations incorporate integrated thermal sensors distributed throughout the memory stack, enabling real-time temperature monitoring at a granular level. This temperature-aware operation allows the memory controller to dynamically adjust refresh rates and access patterns based on thermal conditions, preventing performance degradation while maintaining data integrity.
Advanced cooling solutions specifically designed for HBM4 include improved thermal interface materials between dies and enhanced heat spreaders that efficiently channel heat away from critical components. Some implementations utilize liquid cooling solutions that make direct contact with the HBM4 package, significantly improving thermal conductivity compared to traditional air cooling methods.
Power management features in HBM4 work in conjunction with thermal management systems to optimize performance under varying workload conditions. Dynamic voltage and frequency scaling (DVFS) techniques allow the memory subsystem to adjust power consumption based on workload demands and thermal conditions, maintaining optimal latency characteristics while preventing thermal runaway scenarios.
The physical design of HBM4 packages has also evolved to address thermal concerns. Improved through-silicon via (TSV) designs not only enhance electrical performance but also serve as thermal conduits, helping to distribute heat more evenly throughout the memory stack. This reduces hotspots that could otherwise cause localized performance degradation and increased latency.
For AI accelerators utilizing HBM4, thermal management algorithms now incorporate workload-aware scheduling that considers both the computational intensity and memory access patterns of specific AI operations. This approach allows systems to predictively manage thermal conditions before they become problematic, maintaining consistent low-latency memory access even during sustained high-utilization periods.
HBM4 introduces advanced thermal management techniques that directly impact latency handling. The stacked die architecture of HBM4 creates significant thermal density challenges, with heat generation concentrated in a relatively small footprint. Without proper thermal management, these hotspots can trigger thermal throttling mechanisms that dramatically increase memory access latency during AI inference and training operations.
The latest HBM4 implementations incorporate integrated thermal sensors distributed throughout the memory stack, enabling real-time temperature monitoring at a granular level. This temperature-aware operation allows the memory controller to dynamically adjust refresh rates and access patterns based on thermal conditions, preventing performance degradation while maintaining data integrity.
Advanced cooling solutions specifically designed for HBM4 include improved thermal interface materials between dies and enhanced heat spreaders that efficiently channel heat away from critical components. Some implementations utilize liquid cooling solutions that make direct contact with the HBM4 package, significantly improving thermal conductivity compared to traditional air cooling methods.
Power management features in HBM4 work in conjunction with thermal management systems to optimize performance under varying workload conditions. Dynamic voltage and frequency scaling (DVFS) techniques allow the memory subsystem to adjust power consumption based on workload demands and thermal conditions, maintaining optimal latency characteristics while preventing thermal runaway scenarios.
The physical design of HBM4 packages has also evolved to address thermal concerns. Improved through-silicon via (TSV) designs not only enhance electrical performance but also serve as thermal conduits, helping to distribute heat more evenly throughout the memory stack. This reduces hotspots that could otherwise cause localized performance degradation and increased latency.
For AI accelerators utilizing HBM4, thermal management algorithms now incorporate workload-aware scheduling that considers both the computational intensity and memory access patterns of specific AI operations. This approach allows systems to predictively manage thermal conditions before they become problematic, maintaining consistent low-latency memory access even during sustained high-utilization periods.
Power Efficiency vs Latency Trade-offs in HBM4
The optimization of HBM4 memory systems presents a critical balancing act between power efficiency and latency requirements, particularly in the context of increasingly complex AI workloads. HBM4 introduces several architectural innovations that directly address this trade-off, implementing sophisticated power management techniques while maintaining acceptable latency profiles.
At the core of HBM4's approach is dynamic voltage and frequency scaling (DVFS), which allows memory subsystems to adjust their operational parameters based on workload demands. During computation-intensive phases of AI training or inference, the memory system can operate at higher frequencies with corresponding voltage levels to minimize latency. Conversely, during less demanding phases, power consumption can be reduced by scaling down both frequency and voltage.
HBM4 implements fine-grained power states with rapid transition capabilities, enabling microsecond-level switching between performance and power-saving modes. This granularity represents a significant advancement over HBM3, which featured more limited power state options and slower transition times. The result is a more responsive memory system that can adapt to the bursty nature of AI workloads without incurring substantial latency penalties.
Channel-level power gating represents another significant innovation in HBM4's power-latency management strategy. By selectively powering down inactive channels while maintaining full performance in active ones, HBM4 achieves substantial power savings without compromising overall system responsiveness. This approach is particularly effective for AI workloads with uneven memory access patterns across different data structures.
Thermal considerations also play a crucial role in this trade-off equation. HBM4 incorporates advanced thermal management techniques, including distributed thermal sensors and intelligent throttling algorithms. These features prevent thermal-induced performance degradation while maintaining optimal power efficiency, ensuring consistent latency characteristics even under sustained high-performance operation.
The memory controller in HBM4 systems employs predictive access scheduling, which anticipates memory access patterns based on historical data and workload characteristics. This capability allows the system to preemptively adjust power states before access requests arrive, minimizing the latency impact of power state transitions while maximizing energy efficiency during idle periods.
Ultimately, HBM4's approach to the power-latency trade-off represents a sophisticated multi-variable optimization problem, where workload characteristics, thermal constraints, and performance requirements must be continuously balanced. The architecture's flexibility in managing these competing demands makes it particularly well-suited for next-generation AI systems, where both computational efficiency and response time are critical success factors.
At the core of HBM4's approach is dynamic voltage and frequency scaling (DVFS), which allows memory subsystems to adjust their operational parameters based on workload demands. During computation-intensive phases of AI training or inference, the memory system can operate at higher frequencies with corresponding voltage levels to minimize latency. Conversely, during less demanding phases, power consumption can be reduced by scaling down both frequency and voltage.
HBM4 implements fine-grained power states with rapid transition capabilities, enabling microsecond-level switching between performance and power-saving modes. This granularity represents a significant advancement over HBM3, which featured more limited power state options and slower transition times. The result is a more responsive memory system that can adapt to the bursty nature of AI workloads without incurring substantial latency penalties.
Channel-level power gating represents another significant innovation in HBM4's power-latency management strategy. By selectively powering down inactive channels while maintaining full performance in active ones, HBM4 achieves substantial power savings without compromising overall system responsiveness. This approach is particularly effective for AI workloads with uneven memory access patterns across different data structures.
Thermal considerations also play a crucial role in this trade-off equation. HBM4 incorporates advanced thermal management techniques, including distributed thermal sensors and intelligent throttling algorithms. These features prevent thermal-induced performance degradation while maintaining optimal power efficiency, ensuring consistent latency characteristics even under sustained high-performance operation.
The memory controller in HBM4 systems employs predictive access scheduling, which anticipates memory access patterns based on historical data and workload characteristics. This capability allows the system to preemptively adjust power states before access requests arrive, minimizing the latency impact of power state transitions while maximizing energy efficiency during idle periods.
Ultimately, HBM4's approach to the power-latency trade-off represents a sophisticated multi-variable optimization problem, where workload characteristics, thermal constraints, and performance requirements must be continuously balanced. The architecture's flexibility in managing these competing demands makes it particularly well-suited for next-generation AI systems, where both computational efficiency and response time are critical success factors.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!