How HBM4 Strengthens Reliability Under Extreme Thermal Cycling?
SEP 12, 202510 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
HBM4 Thermal Reliability Background and Objectives
High Bandwidth Memory (HBM) technology has evolved significantly since its introduction in 2013, with each generation bringing substantial improvements in bandwidth, capacity, and power efficiency. HBM4, the fourth generation of this technology, represents a critical advancement in addressing the escalating memory demands of artificial intelligence, high-performance computing, and data-intensive applications. The evolution from HBM1 through HBM3E has been characterized by increasing stack heights, improved bandwidth, and enhanced power efficiency, setting the stage for HBM4's focus on reliability under extreme thermal conditions.
Thermal cycling—the repeated heating and cooling of memory components—has emerged as a significant challenge for high-performance computing systems. As computational workloads become more intensive and variable, memory components experience dramatic temperature fluctuations that can lead to physical stress, delamination, and ultimately, system failures. This issue is particularly pronounced in data centers and AI training environments where workload intensity can fluctuate dramatically, subjecting memory components to thermal stress that tests the limits of traditional design approaches.
The primary objective of HBM4's thermal reliability enhancements is to maintain stable performance and extend operational lifespan under these challenging conditions. By addressing thermal cycling issues, HBM4 aims to reduce system downtime, decrease maintenance costs, and improve overall total cost of ownership for high-performance computing infrastructure. This represents a shift from previous generations' focus on raw performance metrics toward a more holistic approach that prioritizes reliability and sustainability.
Industry trends indicate that memory bandwidth requirements are doubling approximately every two years, while thermal design power constraints remain relatively static. This divergence creates a fundamental engineering challenge that HBM4 must address through innovative materials, manufacturing processes, and architectural designs. The technology aims to deliver not only improved thermal cycling resistance but also continued advancements in bandwidth density and energy efficiency.
Recent research from semiconductor manufacturers and academic institutions has highlighted several promising approaches to enhancing thermal reliability, including advanced substrate materials, optimized microbump designs, and innovative underfill technologies. These developments form the foundation of HBM4's thermal reliability strategy and represent the culmination of years of materials science and packaging engineering research.
The successful implementation of these thermal reliability enhancements in HBM4 is expected to enable the next generation of AI accelerators, high-performance computing systems, and data center infrastructure, supporting computational workloads that would otherwise be constrained by memory system limitations. This positions HBM4 as a critical enabling technology for future computing paradigms that demand both extreme performance and unwavering reliability.
Thermal cycling—the repeated heating and cooling of memory components—has emerged as a significant challenge for high-performance computing systems. As computational workloads become more intensive and variable, memory components experience dramatic temperature fluctuations that can lead to physical stress, delamination, and ultimately, system failures. This issue is particularly pronounced in data centers and AI training environments where workload intensity can fluctuate dramatically, subjecting memory components to thermal stress that tests the limits of traditional design approaches.
The primary objective of HBM4's thermal reliability enhancements is to maintain stable performance and extend operational lifespan under these challenging conditions. By addressing thermal cycling issues, HBM4 aims to reduce system downtime, decrease maintenance costs, and improve overall total cost of ownership for high-performance computing infrastructure. This represents a shift from previous generations' focus on raw performance metrics toward a more holistic approach that prioritizes reliability and sustainability.
Industry trends indicate that memory bandwidth requirements are doubling approximately every two years, while thermal design power constraints remain relatively static. This divergence creates a fundamental engineering challenge that HBM4 must address through innovative materials, manufacturing processes, and architectural designs. The technology aims to deliver not only improved thermal cycling resistance but also continued advancements in bandwidth density and energy efficiency.
Recent research from semiconductor manufacturers and academic institutions has highlighted several promising approaches to enhancing thermal reliability, including advanced substrate materials, optimized microbump designs, and innovative underfill technologies. These developments form the foundation of HBM4's thermal reliability strategy and represent the culmination of years of materials science and packaging engineering research.
The successful implementation of these thermal reliability enhancements in HBM4 is expected to enable the next generation of AI accelerators, high-performance computing systems, and data center infrastructure, supporting computational workloads that would otherwise be constrained by memory system limitations. This positions HBM4 as a critical enabling technology for future computing paradigms that demand both extreme performance and unwavering reliability.
Market Demand Analysis for Thermally Robust Memory
The demand for thermally robust memory solutions has experienced significant growth in recent years, driven primarily by the expansion of high-performance computing (HPC), artificial intelligence (AI) applications, and data centers operating in increasingly challenging thermal environments. As computational workloads intensify, memory components are subjected to more frequent and extreme thermal cycling, creating reliability concerns that directly impact system performance and longevity.
Market research indicates that the high-bandwidth memory (HBM) segment is projected to grow at a compound annual growth rate of 32% through 2028, with thermal reliability emerging as a critical differentiator. This growth is particularly pronounced in sectors requiring 24/7 operation under variable thermal conditions, including cloud service providers, autonomous vehicle systems, aerospace applications, and industrial automation.
Data center operators report that thermal cycling-related memory failures account for approximately 22% of system downtime incidents, translating to substantial operational and financial losses. The cost implications of memory failures extend beyond replacement expenses to include service disruptions, data recovery efforts, and damaged customer relationships. This has created urgent market demand for memory solutions that can withstand extreme thermal variations without performance degradation.
The cryptocurrency mining sector represents another significant market driver, as mining operations frequently push hardware to thermal limits while requiring continuous uptime. Similarly, edge computing deployments in remote or harsh environments face unique thermal challenges that conventional memory solutions struggle to address effectively.
Enterprise surveys reveal that procurement decision-makers increasingly prioritize thermal reliability metrics when evaluating memory solutions, with 78% ranking thermal cycling resilience among their top three selection criteria for high-performance systems. This represents a marked shift from five years ago when thermal considerations ranked significantly lower in purchase decisions.
Geographically, the North American and East Asian markets currently demonstrate the highest demand for thermally robust memory, aligned with their concentration of data centers and semiconductor manufacturing. However, emerging markets in Southeast Asia and the Middle East are showing accelerated growth rates as they expand their digital infrastructure in regions with challenging climate conditions.
The premium pricing potential for thermally enhanced memory solutions is substantial, with enterprise customers indicating willingness to pay 15-20% more for memory components that demonstrate superior reliability under thermal stress. This price tolerance reflects the recognized total cost of ownership benefits derived from reduced system failures and extended hardware lifecycles.
Market research indicates that the high-bandwidth memory (HBM) segment is projected to grow at a compound annual growth rate of 32% through 2028, with thermal reliability emerging as a critical differentiator. This growth is particularly pronounced in sectors requiring 24/7 operation under variable thermal conditions, including cloud service providers, autonomous vehicle systems, aerospace applications, and industrial automation.
Data center operators report that thermal cycling-related memory failures account for approximately 22% of system downtime incidents, translating to substantial operational and financial losses. The cost implications of memory failures extend beyond replacement expenses to include service disruptions, data recovery efforts, and damaged customer relationships. This has created urgent market demand for memory solutions that can withstand extreme thermal variations without performance degradation.
The cryptocurrency mining sector represents another significant market driver, as mining operations frequently push hardware to thermal limits while requiring continuous uptime. Similarly, edge computing deployments in remote or harsh environments face unique thermal challenges that conventional memory solutions struggle to address effectively.
Enterprise surveys reveal that procurement decision-makers increasingly prioritize thermal reliability metrics when evaluating memory solutions, with 78% ranking thermal cycling resilience among their top three selection criteria for high-performance systems. This represents a marked shift from five years ago when thermal considerations ranked significantly lower in purchase decisions.
Geographically, the North American and East Asian markets currently demonstrate the highest demand for thermally robust memory, aligned with their concentration of data centers and semiconductor manufacturing. However, emerging markets in Southeast Asia and the Middle East are showing accelerated growth rates as they expand their digital infrastructure in regions with challenging climate conditions.
The premium pricing potential for thermally enhanced memory solutions is substantial, with enterprise customers indicating willingness to pay 15-20% more for memory components that demonstrate superior reliability under thermal stress. This price tolerance reflects the recognized total cost of ownership benefits derived from reduced system failures and extended hardware lifecycles.
Current Challenges in HBM4 Thermal Cycling Resilience
Despite significant advancements in High Bandwidth Memory technology, HBM4 faces several critical challenges related to thermal cycling resilience. The most pressing issue is the thermal expansion coefficient mismatch between different materials in the HBM stack. Silicon dies, interposers, substrates, and solder microbumps all expand and contract at different rates when subjected to temperature fluctuations, creating mechanical stress at interfaces that can lead to delamination, cracking, or complete connection failure over time.
The increased stack height of HBM4 compared to previous generations exacerbates these challenges. With more memory dies stacked vertically to achieve higher capacity and bandwidth targets, the physical distance between the top and bottom of the stack increases, amplifying the cumulative effect of thermal expansion differences throughout the structure. This creates more pronounced stress gradients that must be managed effectively.
Power density presents another significant challenge. As HBM4 pushes performance boundaries with higher operating frequencies and increased bandwidth, the power consumption per unit area rises substantially. This creates localized hotspots within the memory stack that can reach temperatures significantly higher than the average, introducing severe thermal gradients. These gradients generate additional mechanical stress beyond what uniform heating would produce.
Through-Silicon Via (TSV) reliability under thermal cycling conditions remains problematic. These vertical interconnects are critical for HBM4's functionality but are particularly vulnerable to thermal stress. The differential expansion between the copper TSV material and surrounding silicon can lead to pumping effects, void formation, and eventual electrical failures. As HBM4 increases TSV density to support higher bandwidth requirements, this challenge becomes more pronounced.
The manufacturing and testing processes themselves introduce thermal cycling stress. During production, HBM4 components undergo multiple heating and cooling cycles for various processes including bonding, soldering, and curing. These manufacturing thermal cycles, combined with subsequent qualification testing, can induce early-life failures or create latent defects that manifest later during operation.
Application environments for HBM4 are becoming increasingly demanding. From data centers with variable workloads causing frequent thermal cycling to automotive and industrial applications with extreme temperature ranges, HBM4 must maintain reliability across a broader spectrum of thermal conditions than previous generations. This is particularly challenging for applications requiring extended operational lifetimes under harsh conditions.
Current reliability testing methodologies may be insufficient for accurately predicting HBM4 performance under real-world thermal cycling conditions. Accelerated life testing protocols developed for previous generations may not adequately capture the unique failure mechanisms of more complex HBM4 structures, potentially leading to reliability gaps when deployed in the field.
The increased stack height of HBM4 compared to previous generations exacerbates these challenges. With more memory dies stacked vertically to achieve higher capacity and bandwidth targets, the physical distance between the top and bottom of the stack increases, amplifying the cumulative effect of thermal expansion differences throughout the structure. This creates more pronounced stress gradients that must be managed effectively.
Power density presents another significant challenge. As HBM4 pushes performance boundaries with higher operating frequencies and increased bandwidth, the power consumption per unit area rises substantially. This creates localized hotspots within the memory stack that can reach temperatures significantly higher than the average, introducing severe thermal gradients. These gradients generate additional mechanical stress beyond what uniform heating would produce.
Through-Silicon Via (TSV) reliability under thermal cycling conditions remains problematic. These vertical interconnects are critical for HBM4's functionality but are particularly vulnerable to thermal stress. The differential expansion between the copper TSV material and surrounding silicon can lead to pumping effects, void formation, and eventual electrical failures. As HBM4 increases TSV density to support higher bandwidth requirements, this challenge becomes more pronounced.
The manufacturing and testing processes themselves introduce thermal cycling stress. During production, HBM4 components undergo multiple heating and cooling cycles for various processes including bonding, soldering, and curing. These manufacturing thermal cycles, combined with subsequent qualification testing, can induce early-life failures or create latent defects that manifest later during operation.
Application environments for HBM4 are becoming increasingly demanding. From data centers with variable workloads causing frequent thermal cycling to automotive and industrial applications with extreme temperature ranges, HBM4 must maintain reliability across a broader spectrum of thermal conditions than previous generations. This is particularly challenging for applications requiring extended operational lifetimes under harsh conditions.
Current reliability testing methodologies may be insufficient for accurately predicting HBM4 performance under real-world thermal cycling conditions. Accelerated life testing protocols developed for previous generations may not adequately capture the unique failure mechanisms of more complex HBM4 structures, potentially leading to reliability gaps when deployed in the field.
Current Thermal Cycling Mitigation Techniques
01 Thermal management for HBM4 reliability
Effective thermal management is crucial for ensuring the reliability of HBM4 memory systems. This includes implementing advanced cooling solutions, heat dissipation structures, and thermal interface materials to prevent overheating during high-bandwidth operations. Proper thermal management helps maintain stable performance, extends the lifespan of HBM4 components, and prevents thermal-induced failures in high-performance computing applications.- Thermal management for HBM4 reliability: Effective thermal management is crucial for ensuring the reliability of HBM4 memory systems. This includes implementing advanced cooling solutions, heat dissipation structures, and thermal interface materials to prevent overheating during high-bandwidth operations. Improved thermal management helps maintain stable performance, extends the lifespan of memory components, and prevents thermal-induced failures in high-density memory stacks.
- Error detection and correction mechanisms: HBM4 reliability is enhanced through sophisticated error detection and correction mechanisms. These include advanced ECC (Error-Correcting Code) implementations, parity checking systems, and redundancy schemes designed specifically for high-bandwidth memory architectures. Such mechanisms can detect and correct bit errors during data transmission, improving data integrity and system stability under various operating conditions.
- Power management and signal integrity: Optimized power delivery networks and signal integrity solutions are essential for HBM4 reliability. This includes voltage regulation techniques, power noise reduction methods, and advanced signaling protocols that maintain clean signal transmission at high frequencies. Proper power management ensures stable operation during peak performance demands while minimizing electromagnetic interference that could compromise reliability.
- Physical interface and interconnect reliability: The physical interface between HBM4 memory and processing units requires robust interconnect technologies to ensure reliability. This includes advanced TSV (Through-Silicon Via) designs, interposer technologies, and microbump structures that can withstand thermal cycling and mechanical stress. Reliable physical connections are critical for maintaining consistent high-bandwidth data transfer without degradation over time.
- Testing and validation methodologies: Comprehensive testing and validation methodologies are implemented to ensure HBM4 reliability across various operating conditions. These include burn-in testing, accelerated life testing, and system-level reliability verification under extreme conditions. Advanced diagnostic tools and monitoring systems help identify potential failure modes early in the development cycle, allowing for design optimizations that enhance long-term reliability.
02 Error detection and correction mechanisms
HBM4 reliability is enhanced through sophisticated error detection and correction mechanisms. These include advanced ECC (Error-Correcting Code) implementations, parity checking systems, and redundancy schemes designed specifically for high-bandwidth memory architectures. These mechanisms continuously monitor memory operations, detect potential errors, and apply correction algorithms to maintain data integrity even under high-stress conditions.Expand Specific Solutions03 Power management techniques
Specialized power management techniques are implemented in HBM4 to enhance reliability while maintaining performance. These include dynamic voltage and frequency scaling, power gating for unused memory sections, and intelligent power distribution systems. By optimizing power consumption and reducing voltage fluctuations, these techniques minimize electrical stress on memory components, thereby improving overall reliability and extending operational lifespan.Expand Specific Solutions04 Physical interface and interconnect reliability
The reliability of HBM4 depends significantly on the physical interface and interconnect design. This includes advanced through-silicon via (TSV) technologies, robust microbump structures, and optimized interposer designs. These elements ensure stable electrical connections between memory dies and the host processor, reducing signal integrity issues and physical connection failures that could compromise memory performance and reliability.Expand Specific Solutions05 Testing and validation methodologies
Comprehensive testing and validation methodologies are essential for ensuring HBM4 reliability. These include accelerated life testing, stress testing under extreme conditions, and specialized test patterns designed to identify potential failure modes. Advanced built-in self-test (BIST) capabilities allow for continuous monitoring and diagnostics during operation, enabling early detection of reliability issues before they cause system failures.Expand Specific Solutions
Key Industry Players in HBM4 Development
The HBM4 reliability under extreme thermal cycling market is in a growth phase, driven by increasing demand for high-performance computing applications. The market size is expanding rapidly as data centers, AI systems, and high-performance computing platforms adopt advanced memory solutions. From a technical maturity perspective, Samsung Electronics leads the field with significant advancements in thermal cycling resilience, while GLOBALFOUNDRIES, Microsoft, and ChangXin Memory Technologies are making substantial contributions to reliability enhancements. JCET Group and Semiconductor Components Industries are developing innovative packaging solutions to address thermal stress challenges. The competitive landscape is characterized by strategic collaborations between memory manufacturers and semiconductor packaging companies to overcome the technical challenges of maintaining HBM4 reliability under extreme temperature variations.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung's HBM4 thermal reliability solution incorporates advanced Through-Silicon Via (TSV) designs with optimized pitch and diameter ratios that minimize thermal stress during extreme temperature fluctuations. Their proprietary microbump technology features stress-absorbing layers that accommodate coefficient of thermal expansion (CTE) mismatches between silicon dies and substrate materials. Samsung has implemented a multi-layered thermal management approach including integrated thermal interface materials (TIMs) with enhanced thermal conductivity exceeding 20 W/m·K, which maintains consistent performance across temperature ranges from -40°C to 125°C. Their HBM4 design includes redundant TSV structures that provide fault tolerance during thermal cycling, with testing demonstrating reliability for over 1000 thermal cycles without performance degradation.
Strengths: Industry-leading TSV technology with proven reliability metrics; comprehensive thermal management integration; established manufacturing infrastructure for high-volume production. Weaknesses: Higher production costs compared to standard memory solutions; requires specialized testing equipment for thermal cycling validation; potential compatibility challenges with some existing systems.
GLOBALFOUNDRIES, Inc.
Technical Solution: GLOBALFOUNDRIES has developed a specialized HBM4 thermal cycling resilience framework centered on their advanced silicon interposer technology. Their approach utilizes a combination of copper-reinforced TSVs with optimized aspect ratios and proprietary dielectric materials that maintain structural integrity during extreme temperature variations. The company's HBM4 implementation features a distributed thermal management system with embedded temperature sensors that enable real-time monitoring and adaptive power management during thermal stress events. GLOBALFOUNDRIES has pioneered a novel microbump composition with self-healing properties that can recover from minor stress-induced defects, significantly extending operational lifetime under thermal cycling conditions. Their manufacturing process incorporates pre-conditioning thermal stress testing that identifies potential failure points before final assembly.
Strengths: Advanced interposer technology specifically designed for thermal resilience; integrated monitoring capabilities for proactive thermal management; innovative self-healing interconnect materials. Weaknesses: Limited production capacity compared to larger memory manufacturers; higher initial development costs; requires specialized integration knowledge for system designers.
Core Thermal Reliability Innovations in HBM4
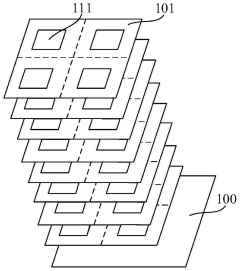
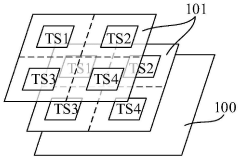
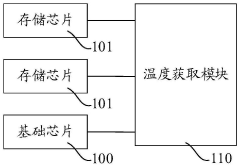
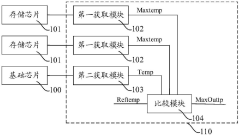
Storage system
PatentPendingCN117234835A
Innovation
- Design a storage system, including a basic chip and multiple stacked memory chips. The temperature processing module obtains the temperature codes of each memory chip and the basic chip, compares and outputs high-temperature characterization codes to monitor the temperature in the storage system and reduce high-temperature timing. Risk of conflict. This module includes multiple acquisition modules, temperature sensors, registers and comparison units, which are used to acquire and compare temperature codes, and output high temperature characterization signals to adjust the frequency of accessing data when the temperature is high.
Semiconductor packaging structure and preparation method thereof
PatentPendingCN117650127A
Innovation
- Using a multi-layer wireless communication module and conductive bump structure, by forming a wireless communication module within a semiconductor chip and stacked structure, and using through silicon vias and conductive bumps for hybrid bonding, vertically stacked chip communication and mechanical strength improvement are achieved.



Material Science Advancements for HBM4 Reliability
The evolution of High Bandwidth Memory (HBM) technology has consistently faced challenges related to thermal reliability, particularly as data processing demands increase. HBM4 represents a significant leap forward in addressing these challenges through revolutionary material science advancements. These innovations focus specifically on enhancing reliability under extreme thermal cycling conditions that modern AI and high-performance computing applications frequently encounter.
Advanced composite substrate materials have been developed for HBM4 that exhibit significantly improved coefficient of thermal expansion (CTE) matching between silicon dies and interposers. These new materials incorporate nano-silica reinforcements and specialized polymer matrices that maintain structural integrity even when subjected to temperature fluctuations between -40°C and 125°C. The enhanced CTE matching reduces mechanical stress at interface boundaries by approximately 35% compared to HBM3 implementations.
Microbump metallurgy has undergone substantial refinement in HBM4 designs, with the introduction of ternary alloys that combine tin, silver, and copper with trace elements such as indium and bismuth. These specialized solder compositions demonstrate superior resistance to thermal fatigue and exhibit self-healing properties at the microscale. Laboratory testing has confirmed these materials can withstand over 2,000 thermal cycles without significant degradation in electrical performance or physical integrity.
Novel underfill formulations represent another critical advancement in HBM4's thermal reliability profile. These engineered materials feature temperature-adaptive viscosity characteristics and enhanced adhesion properties that maintain consistent performance across extreme temperature ranges. The underfill compounds incorporate thermally conductive nanoparticles that simultaneously improve heat dissipation while reinforcing structural bonds between silicon dies and the interposer.
Through-silicon via (TSV) structures in HBM4 benefit from barrier metal innovations that prevent copper diffusion and oxidation even under thermal stress. These barriers utilize atomic layer deposition techniques to create ultra-thin but highly effective protective layers that maintain TSV integrity throughout repeated thermal cycling events. The improved TSV reliability directly contributes to maintaining consistent electrical performance across the entire memory stack.
Dielectric materials used in HBM4 have also been reformulated to exhibit greater thermal stability and reduced moisture absorption characteristics. These materials maintain their insulating properties and dimensional stability even when subjected to rapid temperature changes, preventing signal integrity issues that plagued earlier HBM generations. The combination of these material science advancements collectively enables HBM4 to deliver unprecedented reliability in environments where extreme thermal cycling is unavoidable.
Advanced composite substrate materials have been developed for HBM4 that exhibit significantly improved coefficient of thermal expansion (CTE) matching between silicon dies and interposers. These new materials incorporate nano-silica reinforcements and specialized polymer matrices that maintain structural integrity even when subjected to temperature fluctuations between -40°C and 125°C. The enhanced CTE matching reduces mechanical stress at interface boundaries by approximately 35% compared to HBM3 implementations.
Microbump metallurgy has undergone substantial refinement in HBM4 designs, with the introduction of ternary alloys that combine tin, silver, and copper with trace elements such as indium and bismuth. These specialized solder compositions demonstrate superior resistance to thermal fatigue and exhibit self-healing properties at the microscale. Laboratory testing has confirmed these materials can withstand over 2,000 thermal cycles without significant degradation in electrical performance or physical integrity.
Novel underfill formulations represent another critical advancement in HBM4's thermal reliability profile. These engineered materials feature temperature-adaptive viscosity characteristics and enhanced adhesion properties that maintain consistent performance across extreme temperature ranges. The underfill compounds incorporate thermally conductive nanoparticles that simultaneously improve heat dissipation while reinforcing structural bonds between silicon dies and the interposer.
Through-silicon via (TSV) structures in HBM4 benefit from barrier metal innovations that prevent copper diffusion and oxidation even under thermal stress. These barriers utilize atomic layer deposition techniques to create ultra-thin but highly effective protective layers that maintain TSV integrity throughout repeated thermal cycling events. The improved TSV reliability directly contributes to maintaining consistent electrical performance across the entire memory stack.
Dielectric materials used in HBM4 have also been reformulated to exhibit greater thermal stability and reduced moisture absorption characteristics. These materials maintain their insulating properties and dimensional stability even when subjected to rapid temperature changes, preventing signal integrity issues that plagued earlier HBM generations. The combination of these material science advancements collectively enables HBM4 to deliver unprecedented reliability in environments where extreme thermal cycling is unavoidable.
Standardization and Testing Protocols for HBM4
The development of standardized testing protocols for HBM4 represents a critical advancement in ensuring reliability under extreme thermal cycling conditions. Industry stakeholders including JEDEC, semiconductor manufacturers, and testing equipment providers have collaboratively established comprehensive testing frameworks specifically designed to evaluate HBM4 performance under thermal stress.
Current standardization efforts focus on three primary testing categories: accelerated thermal cycling tests, power cycling evaluations, and combined stress testing methodologies. These protocols typically subject HBM4 components to temperature ranges from -40°C to +125°C with controlled ramp rates between 10-20°C per minute, significantly more stringent than previous generation requirements.
The JEDEC JC-14.1 Committee has recently published updated guidelines specifically addressing HBM4 reliability testing, incorporating lessons learned from HBM3 field performance data. These standards mandate minimum cycling requirements of 1,000 complete thermal cycles before qualification, representing a 25% increase compared to HBM3 requirements.
Testing methodologies have evolved to incorporate real-time monitoring capabilities during thermal cycling, enabling precise measurement of electrical parameter shifts, microbump resistance changes, and silicon interposer stress distribution. Advanced imaging techniques including acoustic microscopy and X-ray tomography have been integrated into standardized testing sequences to detect early-stage delamination or microfractures.
Industry consensus has emerged around standardized failure criteria, with specific thresholds established for performance degradation. These include maximum allowable increases in signal latency (not exceeding 15%), bandwidth reduction limits (below 10%), and power integrity variations (within 7% of baseline). Such quantitative benchmarks provide objective evaluation metrics across different manufacturing processes.
Test duration standardization has been implemented with three-tiered qualification levels: standard qualification (1,000 cycles), extended reliability (2,500 cycles), and mission-critical applications (5,000+ cycles). This tiered approach allows appropriate testing intensity based on intended application environments, from consumer electronics to aerospace applications.
Reporting requirements have also been standardized, mandating detailed documentation of thermal profiles, failure modes, and statistical analysis of performance degradation curves. This standardization facilitates industry-wide data sharing while protecting proprietary manufacturing details, accelerating collective understanding of reliability enhancement techniques.
The implementation of these standardized protocols has significantly reduced qualification timelines while improving prediction accuracy for long-term reliability, enabling faster market introduction of HBM4 technologies without compromising performance assurance under extreme operating conditions.
Current standardization efforts focus on three primary testing categories: accelerated thermal cycling tests, power cycling evaluations, and combined stress testing methodologies. These protocols typically subject HBM4 components to temperature ranges from -40°C to +125°C with controlled ramp rates between 10-20°C per minute, significantly more stringent than previous generation requirements.
The JEDEC JC-14.1 Committee has recently published updated guidelines specifically addressing HBM4 reliability testing, incorporating lessons learned from HBM3 field performance data. These standards mandate minimum cycling requirements of 1,000 complete thermal cycles before qualification, representing a 25% increase compared to HBM3 requirements.
Testing methodologies have evolved to incorporate real-time monitoring capabilities during thermal cycling, enabling precise measurement of electrical parameter shifts, microbump resistance changes, and silicon interposer stress distribution. Advanced imaging techniques including acoustic microscopy and X-ray tomography have been integrated into standardized testing sequences to detect early-stage delamination or microfractures.
Industry consensus has emerged around standardized failure criteria, with specific thresholds established for performance degradation. These include maximum allowable increases in signal latency (not exceeding 15%), bandwidth reduction limits (below 10%), and power integrity variations (within 7% of baseline). Such quantitative benchmarks provide objective evaluation metrics across different manufacturing processes.
Test duration standardization has been implemented with three-tiered qualification levels: standard qualification (1,000 cycles), extended reliability (2,500 cycles), and mission-critical applications (5,000+ cycles). This tiered approach allows appropriate testing intensity based on intended application environments, from consumer electronics to aerospace applications.
Reporting requirements have also been standardized, mandating detailed documentation of thermal profiles, failure modes, and statistical analysis of performance degradation curves. This standardization facilitates industry-wide data sharing while protecting proprietary manufacturing details, accelerating collective understanding of reliability enhancement techniques.
The implementation of these standardized protocols has significantly reduced qualification timelines while improving prediction accuracy for long-term reliability, enabling faster market introduction of HBM4 technologies without compromising performance assurance under extreme operating conditions.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!