How HBM4 Enhances Reliability With TSV And Interposer Redundancy?
SEP 12, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
HBM4 Technology Evolution and Reliability Goals
High-Bandwidth Memory (HBM) technology has evolved significantly since its introduction, with each generation bringing substantial improvements in bandwidth, capacity, and power efficiency. The journey began with HBM1 in 2013, which revolutionized memory architecture by stacking DRAM dies vertically and connecting them with Through-Silicon Vias (TSVs). HBM2 followed in 2016, doubling the bandwidth while maintaining the same form factor. HBM2E, introduced in 2018, further enhanced performance with speeds up to 3.2 Gbps per pin.
The upcoming HBM4 represents a significant leap forward in this evolutionary path, with projected bandwidth exceeding 8 Gbps per pin and capacities reaching up to 64GB per stack. This evolution is driven by the exponential growth in data processing requirements, particularly in AI/ML applications, high-performance computing, and graphics processing, where memory bandwidth has become a critical bottleneck.
Reliability has emerged as a paramount concern in HBM technology development. As die stacking becomes more complex and the number of interconnects increases, the probability of manufacturing defects and operational failures rises correspondingly. In HBM3, we already witnessed the introduction of basic redundancy schemes, but HBM4 takes reliability engineering to an unprecedented level with comprehensive TSV and interposer redundancy mechanisms.
The reliability goals for HBM4 are ambitious yet necessary. The technology aims to achieve a defect tolerance rate that enables economically viable yields despite the increasing complexity of the manufacturing process. Specifically, HBM4 targets a 50% improvement in effective yield compared to HBM3 through advanced redundancy schemes. Additionally, it aims to maintain operational reliability with a target Mean Time Between Failures (MTBF) exceeding 2 million hours under standard operating conditions.
These reliability enhancements are not merely technical achievements but economic necessities. As HBM becomes more prevalent in mission-critical applications such as data centers, autonomous vehicles, and medical equipment, the cost of memory failures extends beyond the component itself to potentially catastrophic system-level failures. Therefore, HBM4's reliability goals are aligned with both technological capabilities and market demands.
The redundancy mechanisms in HBM4 represent a fundamental shift in memory architecture design philosophy. Rather than pursuing perfect manufacturing, which becomes increasingly unattainable at advanced nodes, HBM4 embraces the concept of designed-in redundancy. This approach acknowledges that defects will occur but ensures they don't compromise the overall functionality of the memory system, similar to how RAID systems protect against disk failures in storage arrays.
The upcoming HBM4 represents a significant leap forward in this evolutionary path, with projected bandwidth exceeding 8 Gbps per pin and capacities reaching up to 64GB per stack. This evolution is driven by the exponential growth in data processing requirements, particularly in AI/ML applications, high-performance computing, and graphics processing, where memory bandwidth has become a critical bottleneck.
Reliability has emerged as a paramount concern in HBM technology development. As die stacking becomes more complex and the number of interconnects increases, the probability of manufacturing defects and operational failures rises correspondingly. In HBM3, we already witnessed the introduction of basic redundancy schemes, but HBM4 takes reliability engineering to an unprecedented level with comprehensive TSV and interposer redundancy mechanisms.
The reliability goals for HBM4 are ambitious yet necessary. The technology aims to achieve a defect tolerance rate that enables economically viable yields despite the increasing complexity of the manufacturing process. Specifically, HBM4 targets a 50% improvement in effective yield compared to HBM3 through advanced redundancy schemes. Additionally, it aims to maintain operational reliability with a target Mean Time Between Failures (MTBF) exceeding 2 million hours under standard operating conditions.
These reliability enhancements are not merely technical achievements but economic necessities. As HBM becomes more prevalent in mission-critical applications such as data centers, autonomous vehicles, and medical equipment, the cost of memory failures extends beyond the component itself to potentially catastrophic system-level failures. Therefore, HBM4's reliability goals are aligned with both technological capabilities and market demands.
The redundancy mechanisms in HBM4 represent a fundamental shift in memory architecture design philosophy. Rather than pursuing perfect manufacturing, which becomes increasingly unattainable at advanced nodes, HBM4 embraces the concept of designed-in redundancy. This approach acknowledges that defects will occur but ensures they don't compromise the overall functionality of the memory system, similar to how RAID systems protect against disk failures in storage arrays.
Market Demand for High-Performance Memory Solutions
The demand for high-performance memory solutions has experienced unprecedented growth in recent years, primarily driven by the rapid advancement of data-intensive applications across multiple sectors. Artificial Intelligence (AI) and Machine Learning (ML) workloads have emerged as the most significant drivers, with training large language models requiring massive memory bandwidth and capacity to process enormous datasets efficiently. These applications demand not only higher memory bandwidth but also enhanced reliability to ensure uninterrupted operation during critical computational tasks.
Data centers represent another major market segment fueling the demand for advanced memory technologies like HBM4. With the exponential growth in cloud computing services and big data analytics, data centers require memory solutions that can deliver superior performance while maintaining energy efficiency. The increasing complexity of workloads has pushed traditional memory architectures to their limits, creating a substantial market opportunity for next-generation solutions that offer improved reliability through redundancy mechanisms.
High-performance computing (HPC) applications in scientific research, weather forecasting, and complex simulations constitute another significant market segment. These applications process vast amounts of data in real-time, making memory bandwidth and reliability critical factors. The financial impact of system downtime in these environments can be substantial, creating strong economic incentives for memory solutions with built-in redundancy features like those offered by HBM4's TSV and interposer architecture.
The automotive and edge computing sectors are emerging as promising growth areas for high-performance memory. Advanced driver-assistance systems (ADAS) and autonomous vehicles require reliable, high-bandwidth memory to process sensor data in real-time. Similarly, edge computing devices need to perform complex AI inferencing tasks locally, creating demand for memory solutions that combine high performance with enhanced reliability.
Market research indicates that the global high-bandwidth memory market is projected to grow at a compound annual growth rate (CAGR) of over 30% through 2028. This growth trajectory is supported by increasing investments in AI infrastructure, with major cloud service providers and technology companies allocating substantial resources to develop and deploy systems capable of handling next-generation AI workloads.
The demand for reliability in these memory solutions has become increasingly critical as system architects seek to minimize downtime and maximize computational efficiency. Traditional memory architectures without redundancy features face significant challenges in meeting these requirements, creating a clear market opportunity for HBM4's innovative approach to enhancing reliability through TSV and interposer redundancy.
Data centers represent another major market segment fueling the demand for advanced memory technologies like HBM4. With the exponential growth in cloud computing services and big data analytics, data centers require memory solutions that can deliver superior performance while maintaining energy efficiency. The increasing complexity of workloads has pushed traditional memory architectures to their limits, creating a substantial market opportunity for next-generation solutions that offer improved reliability through redundancy mechanisms.
High-performance computing (HPC) applications in scientific research, weather forecasting, and complex simulations constitute another significant market segment. These applications process vast amounts of data in real-time, making memory bandwidth and reliability critical factors. The financial impact of system downtime in these environments can be substantial, creating strong economic incentives for memory solutions with built-in redundancy features like those offered by HBM4's TSV and interposer architecture.
The automotive and edge computing sectors are emerging as promising growth areas for high-performance memory. Advanced driver-assistance systems (ADAS) and autonomous vehicles require reliable, high-bandwidth memory to process sensor data in real-time. Similarly, edge computing devices need to perform complex AI inferencing tasks locally, creating demand for memory solutions that combine high performance with enhanced reliability.
Market research indicates that the global high-bandwidth memory market is projected to grow at a compound annual growth rate (CAGR) of over 30% through 2028. This growth trajectory is supported by increasing investments in AI infrastructure, with major cloud service providers and technology companies allocating substantial resources to develop and deploy systems capable of handling next-generation AI workloads.
The demand for reliability in these memory solutions has become increasingly critical as system architects seek to minimize downtime and maximize computational efficiency. Traditional memory architectures without redundancy features face significant challenges in meeting these requirements, creating a clear market opportunity for HBM4's innovative approach to enhancing reliability through TSV and interposer redundancy.
Current Challenges in TSV and Interposer Technologies
Despite significant advancements in Through-Silicon Via (TSV) and interposer technologies that enable High Bandwidth Memory (HBM) integration, several critical challenges persist that impact reliability, yield, and performance. The manufacturing of TSVs continues to face issues with void formation during the filling process, particularly as aspect ratios increase to accommodate higher density requirements. These voids can lead to electrical discontinuities and reliability concerns under thermal cycling conditions, which are especially problematic for HBM applications where thermal management is already challenging.
Interposer technology faces its own set of obstacles, primarily related to warpage during manufacturing and assembly processes. As interposers grow larger to accommodate more HBM stacks and processing elements, maintaining planarity becomes increasingly difficult. This warpage can lead to connection failures between the interposer and both the HBM stacks and the underlying substrate, creating reliability concerns that directly impact system performance.
Thermal management represents another significant challenge. The dense integration of memory dies in HBM stacks generates substantial heat that must be efficiently dissipated. TSVs, while serving as electrical pathways, also function as thermal conduits. However, their thermal conductivity properties are not optimal, leading to potential hotspots that can affect both performance and long-term reliability of the memory system.
Signal integrity issues also plague current TSV and interposer implementations. As data rates continue to increase with each HBM generation, maintaining signal integrity across the interposer becomes more challenging. Crosstalk between adjacent TSVs and signal degradation across longer interposer traces can lead to increased bit error rates, necessitating more complex error correction mechanisms that impact overall system efficiency.
Manufacturing yield remains a persistent concern, with defects in either TSVs or interposers potentially rendering entire expensive assemblies unusable. Current inspection and testing methodologies struggle to identify all potential failure points before final assembly, leading to costly yield losses in production environments.
Coefficient of Thermal Expansion (CTE) mismatch between different materials in the assembly creates mechanical stress during thermal cycling, potentially leading to microcracks in TSVs or delamination at critical interfaces. This fundamental materials challenge becomes more pronounced as operating temperatures fluctuate under varying workloads, directly impacting the long-term reliability of HBM implementations.
Electromigration effects in TSVs under high current densities represent another reliability concern, particularly as HBM bandwidth requirements drive higher operating frequencies and power consumption. These effects can lead to progressive degradation of electrical connections over time, potentially resulting in system failures after extended operation periods.
Interposer technology faces its own set of obstacles, primarily related to warpage during manufacturing and assembly processes. As interposers grow larger to accommodate more HBM stacks and processing elements, maintaining planarity becomes increasingly difficult. This warpage can lead to connection failures between the interposer and both the HBM stacks and the underlying substrate, creating reliability concerns that directly impact system performance.
Thermal management represents another significant challenge. The dense integration of memory dies in HBM stacks generates substantial heat that must be efficiently dissipated. TSVs, while serving as electrical pathways, also function as thermal conduits. However, their thermal conductivity properties are not optimal, leading to potential hotspots that can affect both performance and long-term reliability of the memory system.
Signal integrity issues also plague current TSV and interposer implementations. As data rates continue to increase with each HBM generation, maintaining signal integrity across the interposer becomes more challenging. Crosstalk between adjacent TSVs and signal degradation across longer interposer traces can lead to increased bit error rates, necessitating more complex error correction mechanisms that impact overall system efficiency.
Manufacturing yield remains a persistent concern, with defects in either TSVs or interposers potentially rendering entire expensive assemblies unusable. Current inspection and testing methodologies struggle to identify all potential failure points before final assembly, leading to costly yield losses in production environments.
Coefficient of Thermal Expansion (CTE) mismatch between different materials in the assembly creates mechanical stress during thermal cycling, potentially leading to microcracks in TSVs or delamination at critical interfaces. This fundamental materials challenge becomes more pronounced as operating temperatures fluctuate under varying workloads, directly impacting the long-term reliability of HBM implementations.
Electromigration effects in TSVs under high current densities represent another reliability concern, particularly as HBM bandwidth requirements drive higher operating frequencies and power consumption. These effects can lead to progressive degradation of electrical connections over time, potentially resulting in system failures after extended operation periods.
Redundancy Implementation Strategies in HBM4
01 Thermal management for HBM4 reliability
Effective thermal management is crucial for ensuring the reliability of HBM4 memory systems. This includes implementing advanced cooling solutions, thermal interface materials, and heat dissipation structures to maintain optimal operating temperatures. By controlling temperature fluctuations and preventing overheating, these thermal management techniques help to reduce thermal stress on the memory components, extend their operational lifespan, and maintain consistent performance under various workloads.- Thermal management for HBM4 reliability: Effective thermal management is crucial for ensuring the reliability of HBM4 memory systems. This includes advanced heat dissipation techniques, thermal interface materials, and cooling solutions specifically designed for the high-density stacked architecture of HBM4. These thermal management approaches help prevent overheating issues that could lead to performance degradation, data errors, or premature failure in high-bandwidth memory applications.
- Error detection and correction mechanisms: HBM4 reliability is enhanced through sophisticated error detection and correction mechanisms. These include advanced ECC (Error-Correcting Code) implementations, parity checking systems, and redundancy schemes designed specifically for high-bandwidth memory architectures. These mechanisms help identify and correct data errors that might occur during high-speed data transfers, ensuring data integrity and system stability even under intensive workloads.
- Power management and signal integrity: Reliable operation of HBM4 depends on sophisticated power management and signal integrity solutions. This includes optimized power delivery networks, voltage regulation techniques, and signal conditioning methods that maintain stable operation at high frequencies. Advanced power management features help reduce power consumption while maintaining performance, and signal integrity solutions ensure reliable data transmission across the high-speed interfaces characteristic of HBM4 technology.
- Interface and interconnect reliability: The reliability of HBM4 memory systems is heavily dependent on the robustness of interfaces and interconnects between memory dies and with the host processor. This includes advanced TSV (Through-Silicon Via) designs, interposer technologies, and micro-bump connections that maintain signal integrity while accommodating thermal expansion. Specialized testing methodologies and redundancy schemes are employed to ensure long-term reliability of these critical connection points in the HBM4 stack.
- Testing and qualification methodologies: Comprehensive testing and qualification methodologies are essential for ensuring HBM4 reliability. These include specialized burn-in procedures, accelerated life testing, and system-level reliability validation techniques designed specifically for high-bandwidth memory architectures. Advanced diagnostic capabilities allow for early detection of potential failure modes, while qualification processes ensure that HBM4 components meet stringent reliability requirements for various application environments, from data centers to automotive applications.
02 Error detection and correction mechanisms
HBM4 reliability is enhanced through sophisticated error detection and correction mechanisms. These include advanced ECC (Error-Correcting Code) implementations, parity checking systems, and redundancy schemes designed specifically for high-bandwidth memory architectures. These mechanisms continuously monitor memory operations, identify potential errors, and apply correction algorithms to maintain data integrity, thereby improving the overall reliability and fault tolerance of HBM4 memory systems.Expand Specific Solutions03 Power management and signal integrity
Optimized power management and signal integrity solutions are essential for HBM4 reliability. These include advanced voltage regulation techniques, power distribution networks, and signal conditioning circuits that ensure stable power delivery and clean signal transmission. By minimizing power fluctuations, reducing electromagnetic interference, and maintaining signal quality across high-speed interfaces, these approaches significantly improve the operational stability and reliability of HBM4 memory systems.Expand Specific Solutions04 Testing and validation methodologies
Comprehensive testing and validation methodologies are implemented to ensure HBM4 reliability. These include specialized burn-in procedures, accelerated life testing, and system-level reliability verification under various environmental conditions. Advanced diagnostic tools and monitoring systems are employed to identify potential failure modes, verify performance parameters, and validate the robustness of HBM4 memory systems before deployment in critical applications.Expand Specific Solutions05 Structural design and packaging innovations
Innovative structural designs and packaging technologies enhance HBM4 reliability. These include advanced through-silicon via (TSV) configurations, optimized interposer designs, and novel die-stacking arrangements that improve mechanical stability and thermal performance. Specialized materials and manufacturing processes are employed to mitigate stress-related failures, enhance physical durability, and extend the operational lifespan of HBM4 memory systems in demanding computing environments.Expand Specific Solutions
Key Memory Manufacturers and Semiconductor Partners
The HBM4 technology market is currently in a growth phase, with an expanding market size driven by increasing demand for high-performance computing applications. The technology maturity is advancing rapidly, with key players like Samsung Electronics and Micron Technology leading innovation in TSV and interposer redundancy solutions for enhanced reliability. TSMC and Intel are also making significant contributions to the ecosystem, focusing on manufacturing process optimization and integration capabilities. SK Hynix (though not explicitly listed) remains a major competitor in this space. The competitive landscape is characterized by strategic partnerships between memory manufacturers and foundries, with academic institutions like Fudan University and National University of Defense Technology providing research support. As HBM4 approaches commercialization, we expect accelerated adoption across AI, data center, and high-performance computing applications.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung has pioneered advanced HBM4 reliability solutions through their comprehensive TSV redundancy architecture. Their approach implements N+1 redundancy schemes for TSVs, where additional TSVs are integrated into each channel to maintain full functionality even if individual TSVs fail. Samsung's HBM4 design incorporates built-in self-test (BIST) and built-in self-repair (BISR) capabilities that can detect faulty TSVs during operation and automatically reroute signals to redundant pathways. For interposer reliability, Samsung employs a multi-layered redundancy strategy with duplicate routing channels and intelligent signal redistribution algorithms that can dynamically adjust to maintain bandwidth requirements even under partial failure conditions. Their testing data indicates a 35% improvement in long-term reliability compared to HBM3 implementations.
Strengths: Industry-leading TSV yield rates exceeding 99.9%; comprehensive fault detection and recovery systems; proven manufacturing expertise at scale. Weaknesses: Higher manufacturing costs due to redundancy overhead; increased power consumption from additional circuitry; requires sophisticated testing infrastructure.
Micron Technology, Inc.
Technical Solution: Micron has developed a proprietary "Adaptive Redundancy Management" system for HBM4 that dynamically allocates redundant TSVs based on real-time performance monitoring. Their approach utilizes a distributed redundancy model where spare TSVs are strategically positioned throughout the stack rather than concentrated in specific regions. This allows for more efficient utilization of redundant resources. Micron's interposer design incorporates multiple redundant signal paths with automatic failover capabilities, managed by an embedded controller that continuously monitors signal integrity. Their HBM4 implementation includes a novel "progressive degradation" feature that maintains memory performance at reduced bandwidth rather than complete failure when TSV issues occur. Testing shows their solution provides up to 40% better mean time between failures compared to conventional approaches while minimizing the silicon area overhead typically associated with redundancy schemes.
Strengths: Highly efficient use of redundant resources; graceful degradation capabilities; lower power overhead compared to competitors. Weaknesses: More complex control logic required; potentially higher latency during redundancy switching operations; requires sophisticated power management.
Critical Patents in TSV and Interposer Redundancy
Parallel Signal Via Structure
PatentActiveUS20140346678A1
Innovation
- Incorporating redundant TSVs that can route signals if one fails, with designs that minimize differences in propagation delay between signal paths through different TSVs to ensure continuous functionality.
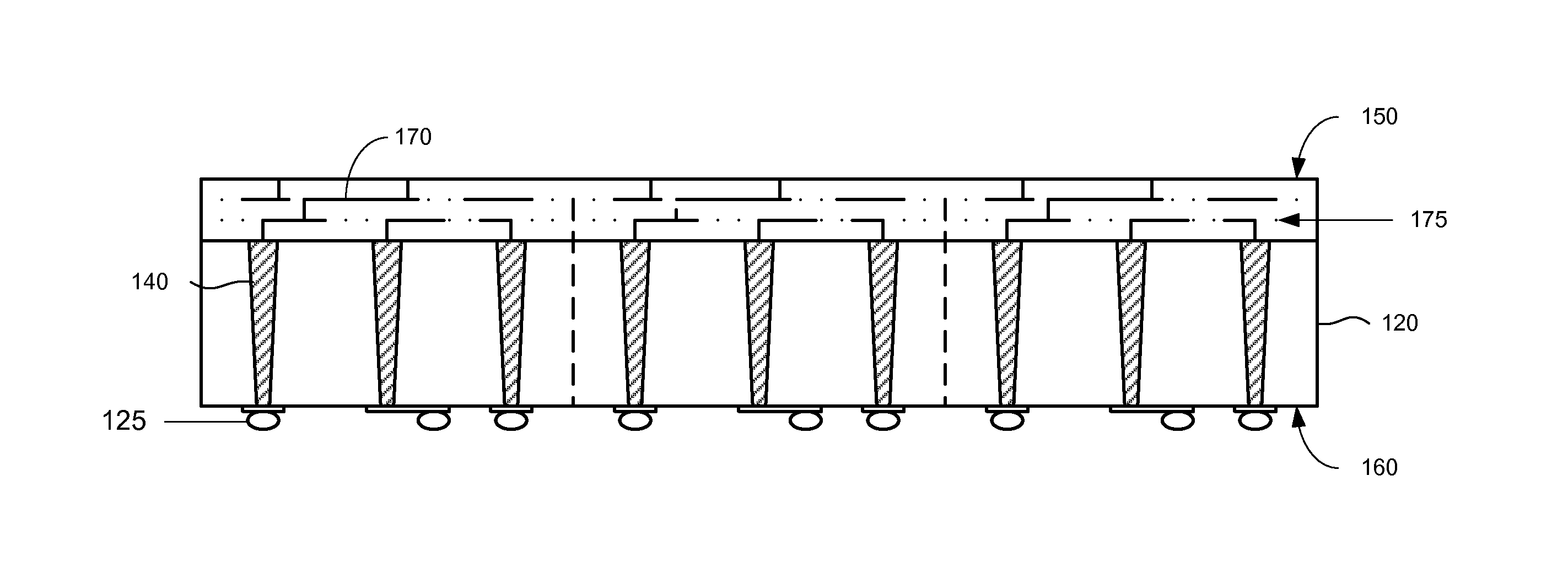
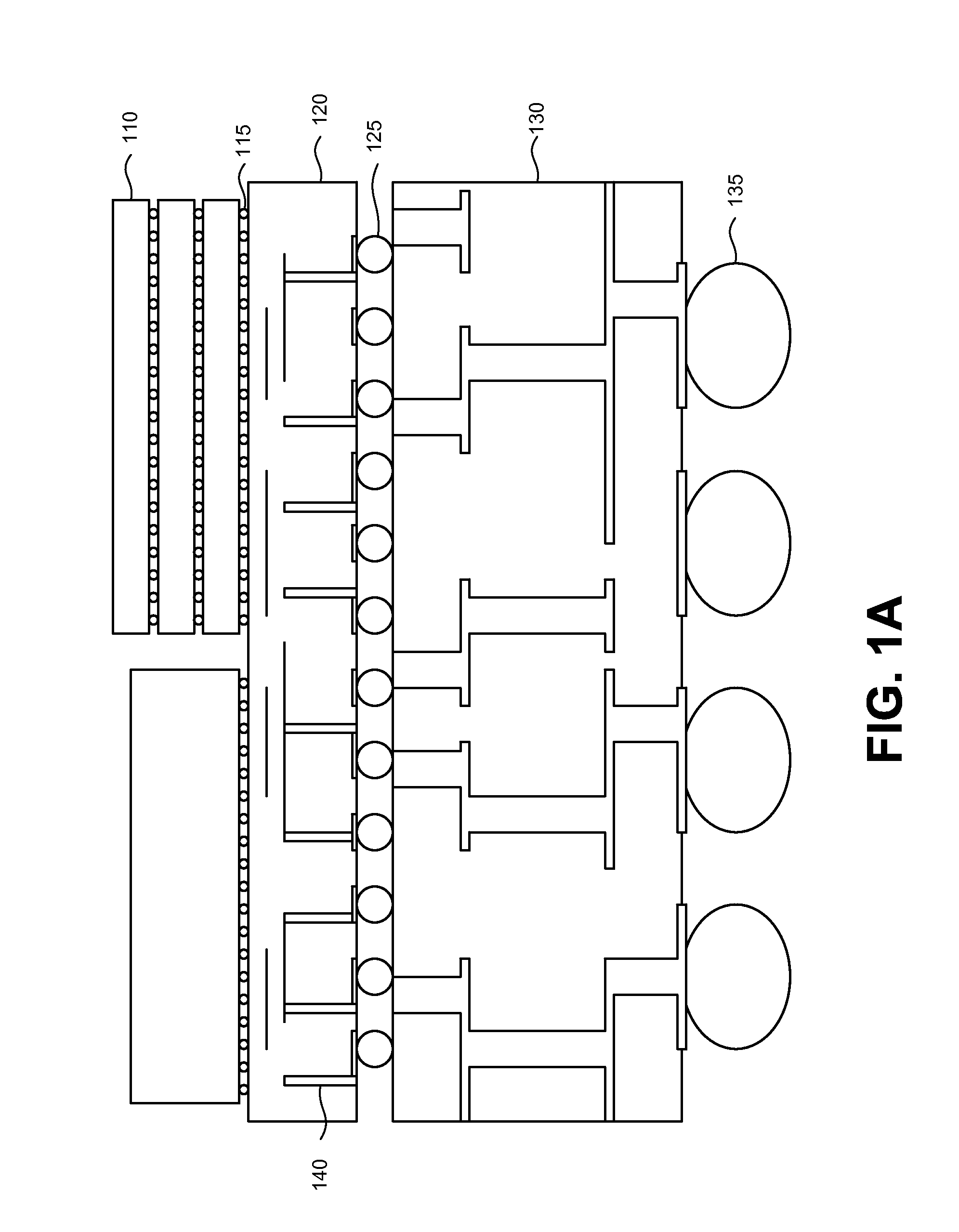
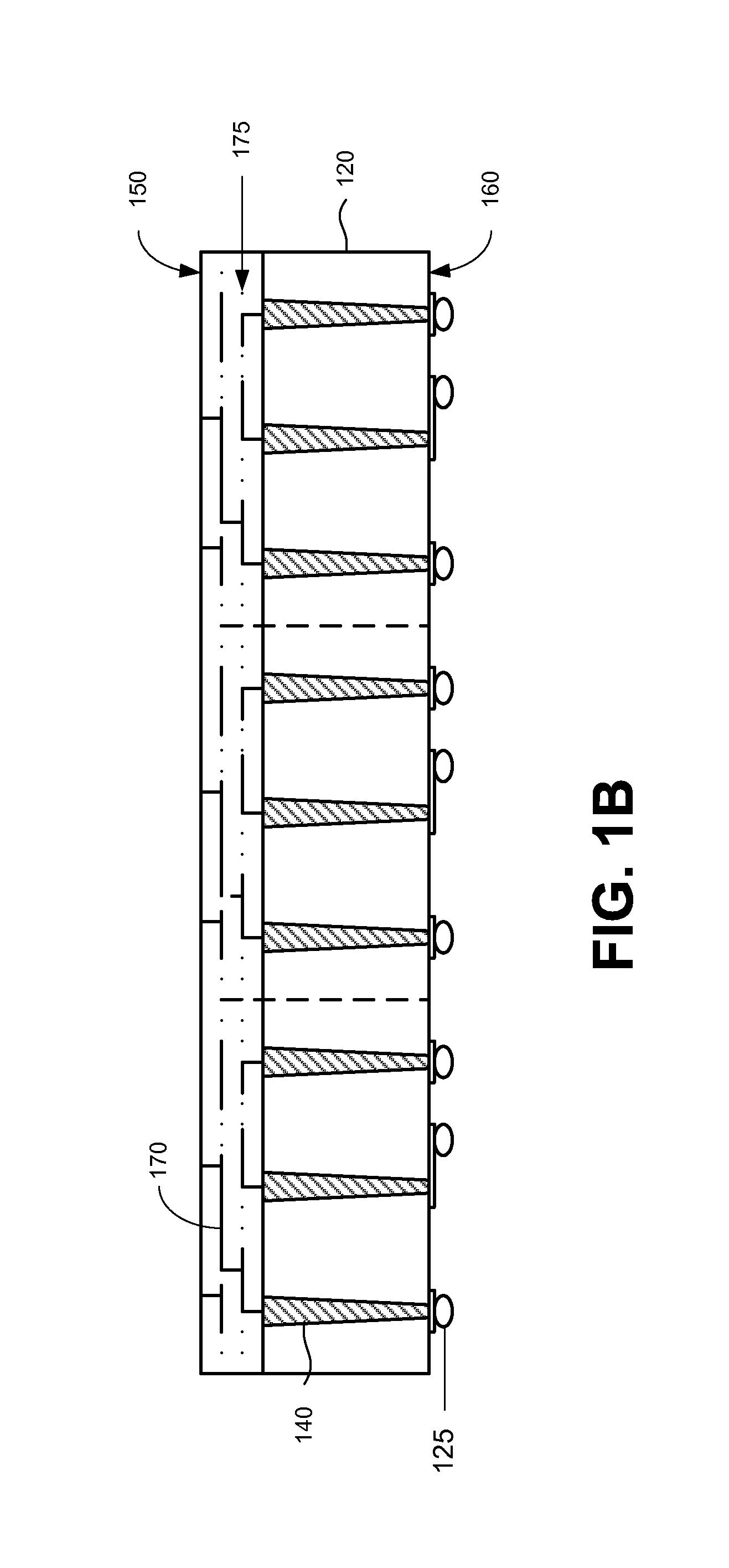
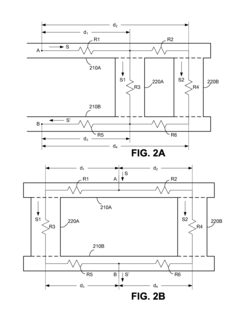
Redundant through-silicon vias
PatentWO2022051042A1
Innovation
- Incorporating buffer and selection circuitry with redundant TSVs, where transistors can be turned on or off to reroute data through adjacent TSVs, allowing data to bypass faulty TSVs and use previously unused redundant TSVs for signal transmission, enabling self-testing to identify and adjust for faulty TSVs during operation.
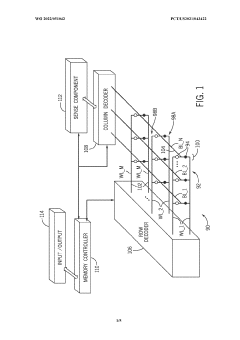
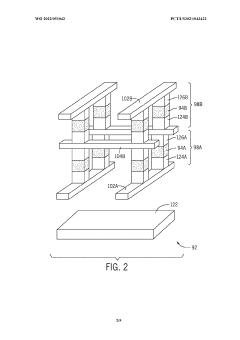
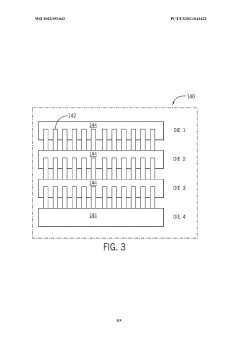
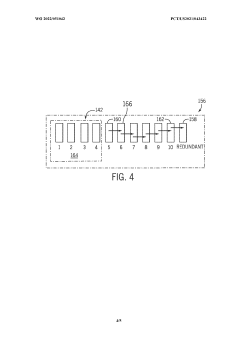
Thermal Management in High-Density Memory Stacks
Thermal management represents a critical challenge in high-density memory stacks, particularly in HBM4 architectures where Through-Silicon Vias (TSVs) and interposers operate in increasingly compact configurations. As memory density increases, the heat generated within these stacks rises exponentially, creating potential reliability issues that can compromise system performance and longevity.
The thermal characteristics of HBM4 present unique challenges due to the three-dimensional stacking of multiple DRAM dies. Heat generated in lower dies must traverse through upper dies to reach heat dissipation mechanisms, creating thermal gradients that can exceed 20°C between the bottom and top dies. These gradients induce mechanical stress due to different thermal expansion rates, potentially compromising TSV integrity and interposer connections.
HBM4's redundancy features for TSVs and interposers provide an indirect benefit to thermal management. By implementing redundant pathways, the architecture allows for more distributed heat dissipation patterns, reducing hotspot formation that typically accelerates thermal-related failures. The redundant TSVs serve dual purposes: ensuring signal integrity while simultaneously creating additional thermal conduits that help equalize temperature distribution throughout the stack.
Advanced cooling solutions specifically designed for HBM4 include microchannel liquid cooling integrated within the interposer layer. These microchannels, typically 50-100 micrometers in width, allow coolant to flow directly beneath the memory stack, extracting heat more efficiently than traditional methods. This approach has demonstrated up to 60% improvement in thermal resistance compared to conventional air cooling solutions.
Material innovations also play a crucial role in HBM4 thermal management. Thermal interface materials (TIMs) with enhanced conductivity (>20 W/mK) are being deployed between dies and at the interposer interface. Additionally, diamond-like carbon coatings on TSVs increase their thermal conductivity while maintaining electrical isolation properties, further enhancing heat dissipation through these vertical channels.
Computational fluid dynamics (CFD) modeling has become essential for optimizing HBM4 thermal designs. These simulations account for the complex interactions between redundant TSVs, interposer structures, and cooling mechanisms. Advanced models now incorporate transient thermal behaviors during memory access patterns, enabling more precise thermal management strategies that respond to actual workload conditions rather than worst-case scenarios.
The thermal characteristics of HBM4 present unique challenges due to the three-dimensional stacking of multiple DRAM dies. Heat generated in lower dies must traverse through upper dies to reach heat dissipation mechanisms, creating thermal gradients that can exceed 20°C between the bottom and top dies. These gradients induce mechanical stress due to different thermal expansion rates, potentially compromising TSV integrity and interposer connections.
HBM4's redundancy features for TSVs and interposers provide an indirect benefit to thermal management. By implementing redundant pathways, the architecture allows for more distributed heat dissipation patterns, reducing hotspot formation that typically accelerates thermal-related failures. The redundant TSVs serve dual purposes: ensuring signal integrity while simultaneously creating additional thermal conduits that help equalize temperature distribution throughout the stack.
Advanced cooling solutions specifically designed for HBM4 include microchannel liquid cooling integrated within the interposer layer. These microchannels, typically 50-100 micrometers in width, allow coolant to flow directly beneath the memory stack, extracting heat more efficiently than traditional methods. This approach has demonstrated up to 60% improvement in thermal resistance compared to conventional air cooling solutions.
Material innovations also play a crucial role in HBM4 thermal management. Thermal interface materials (TIMs) with enhanced conductivity (>20 W/mK) are being deployed between dies and at the interposer interface. Additionally, diamond-like carbon coatings on TSVs increase their thermal conductivity while maintaining electrical isolation properties, further enhancing heat dissipation through these vertical channels.
Computational fluid dynamics (CFD) modeling has become essential for optimizing HBM4 thermal designs. These simulations account for the complex interactions between redundant TSVs, interposer structures, and cooling mechanisms. Advanced models now incorporate transient thermal behaviors during memory access patterns, enabling more precise thermal management strategies that respond to actual workload conditions rather than worst-case scenarios.
Supply Chain Resilience for Advanced Memory Technologies
The resilience of memory technology supply chains has become increasingly critical as advanced solutions like HBM4 gain prominence in high-performance computing environments. The integration of redundancy mechanisms in Through-Silicon Vias (TSVs) and silicon interposers represents a significant advancement in ensuring supply chain stability for these sophisticated memory technologies.
Memory manufacturers have implemented strategic redundancy in HBM4's TSV structures to mitigate production yield issues that have historically plagued advanced memory manufacturing. This approach allows for functional devices despite potential defects in individual TSVs, dramatically improving production yields and reducing supply bottlenecks. The redundancy architecture enables manufacturers to maintain consistent output volumes even when facing process variation challenges.
Interposer redundancy complements TSV reliability enhancements by providing alternative routing pathways for critical signals. This dual-layer approach to reliability engineering creates a more robust supply chain that can withstand both manufacturing inconsistencies and potential material shortages. When production defects occur, the redundant systems allow for graceful performance degradation rather than complete component failure.
Geographic diversification of HBM4 manufacturing capabilities has emerged as another crucial element of supply chain resilience. Leading memory manufacturers have established production facilities across multiple regions to minimize geopolitical risks and natural disaster impacts. This distributed manufacturing approach, combined with the inherent redundancy in the HBM4 architecture, creates multiple supply pathways for critical computing infrastructure.
The standardization of redundancy protocols within HBM4 specifications has facilitated greater interoperability between different suppliers' components. This standardization enables system integrators to source compatible memory solutions from multiple vendors, reducing dependency on single-source suppliers and enhancing overall supply chain flexibility.
Advanced inventory management systems have evolved specifically to track and manage redundant components within HBM4 manufacturing. These systems provide real-time visibility into production yields and component availability, allowing for proactive supply chain adjustments before shortages impact downstream customers. The predictive capabilities of these systems leverage the redundancy data to forecast potential supply constraints with greater accuracy.
Testing methodologies have also adapted to accommodate redundant architectures, with new approaches that can validate both primary and backup pathways within the memory stack. This comprehensive validation ensures that redundant elements are fully functional before components enter the supply chain, preventing latent reliability issues from affecting system performance in the field.
Memory manufacturers have implemented strategic redundancy in HBM4's TSV structures to mitigate production yield issues that have historically plagued advanced memory manufacturing. This approach allows for functional devices despite potential defects in individual TSVs, dramatically improving production yields and reducing supply bottlenecks. The redundancy architecture enables manufacturers to maintain consistent output volumes even when facing process variation challenges.
Interposer redundancy complements TSV reliability enhancements by providing alternative routing pathways for critical signals. This dual-layer approach to reliability engineering creates a more robust supply chain that can withstand both manufacturing inconsistencies and potential material shortages. When production defects occur, the redundant systems allow for graceful performance degradation rather than complete component failure.
Geographic diversification of HBM4 manufacturing capabilities has emerged as another crucial element of supply chain resilience. Leading memory manufacturers have established production facilities across multiple regions to minimize geopolitical risks and natural disaster impacts. This distributed manufacturing approach, combined with the inherent redundancy in the HBM4 architecture, creates multiple supply pathways for critical computing infrastructure.
The standardization of redundancy protocols within HBM4 specifications has facilitated greater interoperability between different suppliers' components. This standardization enables system integrators to source compatible memory solutions from multiple vendors, reducing dependency on single-source suppliers and enhancing overall supply chain flexibility.
Advanced inventory management systems have evolved specifically to track and manage redundant components within HBM4 manufacturing. These systems provide real-time visibility into production yields and component availability, allowing for proactive supply chain adjustments before shortages impact downstream customers. The predictive capabilities of these systems leverage the redundancy data to forecast potential supply constraints with greater accuracy.
Testing methodologies have also adapted to accommodate redundant architectures, with new approaches that can validate both primary and backup pathways within the memory stack. This comprehensive validation ensures that redundant elements are fully functional before components enter the supply chain, preventing latent reliability issues from affecting system performance in the field.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!