

HBM4 Reliability Screening: Burn-In Methods And Failure Analysis
SEP 12, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
HBM4 Reliability Background and Objectives
High Bandwidth Memory (HBM) technology has evolved significantly since its introduction, with HBM4 representing the latest advancement in this memory architecture. The development of HBM technology began in the early 2010s as a response to the increasing bandwidth demands of high-performance computing applications. HBM4 builds upon previous generations by offering substantial improvements in bandwidth, capacity, and energy efficiency, making it critical for next-generation AI accelerators, graphics processing, and data center applications.
The reliability of HBM4 has become a paramount concern as these memory modules are deployed in mission-critical systems where failures can result in significant financial losses or safety risks. Historical data from previous HBM generations indicates that early failure detection through effective screening methods is essential for maintaining system integrity and performance over time. The industry has witnessed a progressive evolution in reliability testing methodologies, moving from basic functional testing to sophisticated burn-in procedures that can identify latent defects before deployment.
Current reliability challenges for HBM4 stem from its complex 3D stacked architecture, which introduces unique failure mechanisms not present in traditional memory technologies. The increased density of interconnects, thinner silicon substrates, and higher operating temperatures all contribute to potential reliability issues that must be addressed through comprehensive screening methods. Additionally, the integration of HBM4 with advanced packaging technologies like silicon interposers creates new reliability concerns at the system level.
The primary objective of HBM4 reliability screening is to develop and implement effective burn-in methodologies that can accurately identify potential failures while maintaining testing efficiency and cost-effectiveness. These methods must be capable of detecting various failure modes including interconnect failures, silicon defects, and thermal-related degradation under accelerated stress conditions that simulate long-term operation.
Another critical goal is to establish standardized failure analysis protocols that can provide actionable insights into the root causes of HBM4 failures. This includes developing non-destructive inspection techniques, electrical characterization methods, and physical analysis procedures that can precisely locate and identify failure mechanisms within the complex 3D structure of HBM4 modules.
The technology trajectory suggests that as HBM4 adoption increases across various industries, reliability screening will need to evolve to address application-specific requirements while maintaining high throughput in manufacturing environments. Future developments will likely focus on integrating machine learning algorithms for predictive failure analysis and implementing adaptive burn-in procedures that optimize test coverage based on real-time data.
The reliability of HBM4 has become a paramount concern as these memory modules are deployed in mission-critical systems where failures can result in significant financial losses or safety risks. Historical data from previous HBM generations indicates that early failure detection through effective screening methods is essential for maintaining system integrity and performance over time. The industry has witnessed a progressive evolution in reliability testing methodologies, moving from basic functional testing to sophisticated burn-in procedures that can identify latent defects before deployment.
Current reliability challenges for HBM4 stem from its complex 3D stacked architecture, which introduces unique failure mechanisms not present in traditional memory technologies. The increased density of interconnects, thinner silicon substrates, and higher operating temperatures all contribute to potential reliability issues that must be addressed through comprehensive screening methods. Additionally, the integration of HBM4 with advanced packaging technologies like silicon interposers creates new reliability concerns at the system level.
The primary objective of HBM4 reliability screening is to develop and implement effective burn-in methodologies that can accurately identify potential failures while maintaining testing efficiency and cost-effectiveness. These methods must be capable of detecting various failure modes including interconnect failures, silicon defects, and thermal-related degradation under accelerated stress conditions that simulate long-term operation.
Another critical goal is to establish standardized failure analysis protocols that can provide actionable insights into the root causes of HBM4 failures. This includes developing non-destructive inspection techniques, electrical characterization methods, and physical analysis procedures that can precisely locate and identify failure mechanisms within the complex 3D structure of HBM4 modules.
The technology trajectory suggests that as HBM4 adoption increases across various industries, reliability screening will need to evolve to address application-specific requirements while maintaining high throughput in manufacturing environments. Future developments will likely focus on integrating machine learning algorithms for predictive failure analysis and implementing adaptive burn-in procedures that optimize test coverage based on real-time data.
Market Demand for Advanced Memory Solutions
The demand for High Bandwidth Memory (HBM) solutions has experienced unprecedented growth in recent years, primarily driven by the explosive expansion of data-intensive applications. The emergence of artificial intelligence, machine learning, high-performance computing, and advanced graphics processing has created substantial market pressure for memory technologies that can deliver superior bandwidth, reduced power consumption, and enhanced reliability.
Market research indicates that the global HBM market is projected to grow at a compound annual growth rate exceeding 30% through 2028, with particular acceleration in sectors requiring massive parallel processing capabilities. Data centers, which form the backbone of cloud computing infrastructure, represent one of the largest consumer segments for advanced memory solutions, as they continuously seek to optimize performance while managing thermal constraints and energy costs.
The automotive industry has emerged as another significant market driver, particularly with the advancement of autonomous driving technologies. These systems require real-time processing of enormous datasets from multiple sensors, creating demand for memory solutions that can handle high-speed data transfers with exceptional reliability under varying environmental conditions.
Telecommunications infrastructure, especially with the ongoing global deployment of 5G networks and planning for 6G, constitutes another major market segment. Network equipment manufacturers are increasingly incorporating HBM to manage the exponential growth in data traffic while maintaining low latency requirements.
Consumer electronics manufacturers are also showing growing interest in HBM technologies for premium devices, as applications become increasingly sophisticated and memory-intensive. This trend is particularly evident in high-end gaming systems, professional workstations, and content creation platforms where performance expectations continue to rise.
The critical nature of reliability in these applications cannot be overstated. System failures in data centers can result in significant financial losses, while memory failures in automotive or medical applications could have life-threatening consequences. This has intensified market demand for advanced reliability screening methodologies, particularly for HBM4, which represents the cutting edge of memory technology.
Industry surveys reveal that customers are willing to pay premium prices for memory solutions with demonstrated reliability advantages, especially when supported by comprehensive burn-in testing and failure analysis protocols. This market dynamic has created strong economic incentives for memory manufacturers to invest in advanced reliability screening technologies, as improved failure rates directly translate to competitive advantages and premium pricing opportunities.
Market research indicates that the global HBM market is projected to grow at a compound annual growth rate exceeding 30% through 2028, with particular acceleration in sectors requiring massive parallel processing capabilities. Data centers, which form the backbone of cloud computing infrastructure, represent one of the largest consumer segments for advanced memory solutions, as they continuously seek to optimize performance while managing thermal constraints and energy costs.
The automotive industry has emerged as another significant market driver, particularly with the advancement of autonomous driving technologies. These systems require real-time processing of enormous datasets from multiple sensors, creating demand for memory solutions that can handle high-speed data transfers with exceptional reliability under varying environmental conditions.
Telecommunications infrastructure, especially with the ongoing global deployment of 5G networks and planning for 6G, constitutes another major market segment. Network equipment manufacturers are increasingly incorporating HBM to manage the exponential growth in data traffic while maintaining low latency requirements.
Consumer electronics manufacturers are also showing growing interest in HBM technologies for premium devices, as applications become increasingly sophisticated and memory-intensive. This trend is particularly evident in high-end gaming systems, professional workstations, and content creation platforms where performance expectations continue to rise.
The critical nature of reliability in these applications cannot be overstated. System failures in data centers can result in significant financial losses, while memory failures in automotive or medical applications could have life-threatening consequences. This has intensified market demand for advanced reliability screening methodologies, particularly for HBM4, which represents the cutting edge of memory technology.
Industry surveys reveal that customers are willing to pay premium prices for memory solutions with demonstrated reliability advantages, especially when supported by comprehensive burn-in testing and failure analysis protocols. This market dynamic has created strong economic incentives for memory manufacturers to invest in advanced reliability screening technologies, as improved failure rates directly translate to competitive advantages and premium pricing opportunities.
HBM4 Reliability Challenges and Technical Constraints
The reliability challenges of HBM4 (High Bandwidth Memory 4) represent significant technical constraints that must be addressed for successful implementation in high-performance computing systems. As HBM4 pushes the boundaries of memory density, bandwidth, and integration, it faces several critical reliability issues that exceed those of previous generations.
The most prominent challenge stems from the increased stack height and density of HBM4, which introduces thermal management complications. With more memory dies stacked vertically and operating at higher frequencies, heat dissipation becomes problematic, potentially leading to thermal-induced stress and premature failure. The temperature gradients within the stack can cause differential expansion, creating mechanical stress at interface points, particularly at the microbump connections between dies.
Signal integrity presents another significant constraint, as the higher operating frequencies of HBM4 (projected to exceed 4.8 Gbps per pin) make the system more susceptible to noise, crosstalk, and signal degradation. The reduced spacing between TSVs (Through-Silicon Vias) and microbumps increases the likelihood of electrical interference, potentially causing data corruption or system instability.
Power integrity challenges also emerge with HBM4's increased power density. The combination of higher operating frequencies and more memory layers results in greater power consumption within a confined space. This creates potential IR drop issues and power delivery network (PDN) constraints that can affect memory reliability and performance stability.
The manufacturing process for HBM4 introduces additional reliability concerns. The complexity of stacking more dies with finer interconnect pitches increases the probability of defects during assembly. Microbump failures, TSV defects, and die-to-die alignment issues become more prevalent as dimensions shrink and stack heights increase.
Environmental factors further compound these challenges. Temperature cycling, humidity, and mechanical shock can accelerate failure mechanisms in the complex HBM4 structure. The different coefficients of thermal expansion between materials used in the HBM4 stack (silicon, substrate materials, underfill, etc.) create reliability concerns over the product lifetime.
Testing and screening methodologies face limitations with HBM4 as well. Traditional burn-in methods may be insufficient for detecting early-life failures in such complex 3D structures. The high pin count and operating speeds make comprehensive testing more difficult, potentially allowing latent defects to escape detection during manufacturing qualification.
The most prominent challenge stems from the increased stack height and density of HBM4, which introduces thermal management complications. With more memory dies stacked vertically and operating at higher frequencies, heat dissipation becomes problematic, potentially leading to thermal-induced stress and premature failure. The temperature gradients within the stack can cause differential expansion, creating mechanical stress at interface points, particularly at the microbump connections between dies.
Signal integrity presents another significant constraint, as the higher operating frequencies of HBM4 (projected to exceed 4.8 Gbps per pin) make the system more susceptible to noise, crosstalk, and signal degradation. The reduced spacing between TSVs (Through-Silicon Vias) and microbumps increases the likelihood of electrical interference, potentially causing data corruption or system instability.
Power integrity challenges also emerge with HBM4's increased power density. The combination of higher operating frequencies and more memory layers results in greater power consumption within a confined space. This creates potential IR drop issues and power delivery network (PDN) constraints that can affect memory reliability and performance stability.
The manufacturing process for HBM4 introduces additional reliability concerns. The complexity of stacking more dies with finer interconnect pitches increases the probability of defects during assembly. Microbump failures, TSV defects, and die-to-die alignment issues become more prevalent as dimensions shrink and stack heights increase.
Environmental factors further compound these challenges. Temperature cycling, humidity, and mechanical shock can accelerate failure mechanisms in the complex HBM4 structure. The different coefficients of thermal expansion between materials used in the HBM4 stack (silicon, substrate materials, underfill, etc.) create reliability concerns over the product lifetime.
Testing and screening methodologies face limitations with HBM4 as well. Traditional burn-in methods may be insufficient for detecting early-life failures in such complex 3D structures. The high pin count and operating speeds make comprehensive testing more difficult, potentially allowing latent defects to escape detection during manufacturing qualification.
Current Burn-In Screening Techniques for HBM4
01 Thermal management for HBM4 reliability
Effective thermal management is crucial for ensuring the reliability of HBM4 memory systems. This includes implementing advanced cooling solutions, thermal sensors, and heat dissipation mechanisms to prevent overheating during high-bandwidth operations. Proper thermal management helps maintain stable performance, extends the lifespan of memory components, and prevents thermal-induced failures in HBM4 stacks, which are particularly susceptible to heat issues due to their dense 3D structure.- Thermal management for HBM4 reliability: Effective thermal management is crucial for ensuring the reliability of HBM4 memory systems. This includes implementing advanced cooling solutions, heat dissipation structures, and thermal interface materials to prevent overheating during high-bandwidth operations. Proper thermal management helps maintain stable performance, extends the lifespan of HBM4 components, and prevents thermal-induced failures in high-performance computing applications.
- Error detection and correction mechanisms: HBM4 reliability is enhanced through sophisticated error detection and correction mechanisms. These include advanced ECC (Error-Correcting Code) implementations, parity checking systems, and redundancy schemes designed specifically for high-bandwidth memory architectures. These mechanisms continuously monitor memory operations, detect potential errors, and apply corrections in real-time to maintain data integrity and system stability under various operating conditions.
- Power management and signal integrity: Optimized power management and signal integrity solutions are essential for HBM4 reliability. This involves implementing sophisticated power delivery networks, voltage regulation techniques, and signal conditioning circuits to maintain stable operation during high-speed data transfers. Advanced power management techniques help reduce power consumption while maintaining performance, and signal integrity solutions minimize interference and ensure accurate data transmission across the memory interface.
- Testing and validation methodologies: Comprehensive testing and validation methodologies are critical for ensuring HBM4 reliability. These include specialized burn-in procedures, accelerated life testing, and system-level reliability assessments that simulate extreme operating conditions. Advanced diagnostic tools and monitoring systems help identify potential failure modes early in the development cycle, allowing for design optimizations that enhance long-term reliability and performance consistency in field applications.
- Interface and interconnect reliability: The reliability of HBM4 memory systems heavily depends on robust interface and interconnect designs. This includes advanced TSV (Through-Silicon Via) technologies, interposer designs, and microbump connections that maintain signal integrity while providing mechanical stability. Innovations in packaging technology, such as enhanced silicon interposers and improved die-to-die connections, help reduce physical stress on interconnects and ensure reliable operation throughout the memory system's lifecycle.
02 Error detection and correction mechanisms
Advanced error detection and correction mechanisms are implemented in HBM4 to enhance reliability. These include ECC (Error-Correcting Code) memory, parity checking, and redundancy schemes that can detect and correct bit errors during data transmission. Such mechanisms are essential for maintaining data integrity in high-performance computing environments where HBM4 is deployed, helping to prevent system crashes and data corruption while improving overall system reliability.Expand Specific Solutions03 Power management and voltage stability
Effective power management and voltage stability systems are critical for HBM4 reliability. These include dynamic voltage scaling, power gating techniques, and advanced power delivery networks that ensure stable operation under varying workloads. By optimizing power consumption and maintaining voltage stability, these systems help prevent performance degradation, reduce the risk of electrical failures, and extend the operational lifespan of HBM4 memory components in high-performance computing applications.Expand Specific Solutions04 Interface and signal integrity improvements
Enhanced interface designs and signal integrity improvements are implemented in HBM4 to ensure reliable data transmission at high speeds. These include advanced SerDes (Serializer/Deserializer) circuits, equalization techniques, and improved TSV (Through-Silicon Via) designs that minimize signal degradation and interference. Such improvements help maintain data integrity across the high-speed interfaces between memory stacks and processors, reducing bit error rates and ensuring consistent performance in demanding computing environments.Expand Specific Solutions05 Testing and reliability validation methods
Comprehensive testing and reliability validation methods are essential for ensuring HBM4 memory quality. These include burn-in testing, accelerated life testing, and advanced fault simulation techniques that identify potential failure modes before deployment. By implementing rigorous testing protocols during manufacturing and system integration, manufacturers can identify and address reliability issues early, ensuring that HBM4 memory systems meet the stringent reliability requirements of data centers, AI applications, and other high-performance computing environments.Expand Specific Solutions
Leading HBM4 Manufacturers and Technology Providers
The HBM4 reliability screening market is currently in a growth phase, with increasing demand driven by advanced computing applications requiring high-bandwidth memory. The market size is expanding rapidly as data centers, AI systems, and high-performance computing adopt HBM technology. Technologically, the field is maturing but still evolving, with key players demonstrating varying levels of expertise. Micron Technology and Samsung lead in memory manufacturing capabilities, while IBM and Huawei contribute significant innovations in testing methodologies. TSMC provides critical foundry support, and AMD leverages HBM in their high-performance products. Academic institutions like Beihang University and University of Electronic Science & Technology of China are advancing fundamental research in reliability physics. The ecosystem shows a collaborative approach between memory manufacturers, semiconductor companies, and research institutions to address the complex challenges of HBM4 reliability screening.
Micron Technology, Inc.
Technical Solution: Micron has developed a comprehensive HBM4 reliability screening approach that combines electrical and thermal stress testing methodologies. Their solution implements an advanced burn-in system specifically designed for high-bandwidth memory stacks, featuring multi-temperature testing capabilities ranging from -40°C to 125°C. The system applies targeted voltage and current stress patterns while monitoring real-time electrical parameters to detect early failure indicators. Micron's approach incorporates both static and dynamic burn-in methods: static testing applies constant bias voltages to identify oxide defects, while dynamic testing exercises memory cells through repeated read/write operations at elevated temperatures. Their proprietary failure analysis techniques include non-destructive imaging using acoustic microscopy and X-ray tomography to examine TSV (Through-Silicon Via) connections and microbump interfaces without damaging the HBM stack structure. For deeper analysis, they employ cross-sectional electron microscopy and energy-dispersive X-ray spectroscopy to characterize failure mechanisms at the atomic level.
Strengths: Micron's approach offers comprehensive coverage of potential failure modes through combined static/dynamic testing methodologies and advanced non-destructive imaging capabilities. Their multi-temperature testing range exceeds industry standards, enabling better identification of temperature-dependent failure mechanisms. Weaknesses: The extensive testing methodology likely increases manufacturing costs and time-to-market compared to less rigorous approaches, potentially affecting competitive pricing in cost-sensitive markets.
International Business Machines Corp.
Technical Solution: IBM has pioneered an integrated HBM4 reliability screening framework that combines traditional burn-in techniques with AI-powered predictive analytics. Their approach utilizes a distributed testing architecture where multiple HBM stacks undergo parallel stress testing under controlled environmental conditions. The system applies variable electrical stress patterns that simulate real-world workloads rather than just static voltage conditions, allowing for more realistic reliability assessment. IBM's solution incorporates in-situ monitoring capabilities that track electrical parameter shifts during burn-in, with proprietary algorithms that can detect subtle precursors to failure before catastrophic breakdown occurs. For failure analysis, IBM employs advanced imaging techniques including time-domain reflectometry for signal integrity analysis and nanoprobe testing for individual TSV characterization. Their methodology also includes accelerated life testing protocols that can estimate long-term reliability metrics from shorter-duration stress tests, using statistical models developed from extensive reliability databases. The system integrates with IBM's broader manufacturing quality control systems, enabling correlation between process parameters and reliability outcomes.
Strengths: IBM's AI-enhanced approach enables predictive failure analysis that can identify reliability issues before they manifest as functional failures. Their workload-based stress testing provides more realistic reliability assessment than conventional methods. Weaknesses: The sophisticated testing infrastructure requires significant capital investment and specialized expertise to implement and maintain, potentially limiting adoption to high-end applications where reliability justifies the additional cost.
Critical Failure Analysis Mechanisms and Methodologies
Interface testing method and device, processor and electronic equipment
PatentActiveCN112017727A
Innovation
- By repeatedly testing the high-bandwidth memory until the set conditions are reached, adjusting the target configuration parameters based on the current state of the test parameters, using the bisection method to update the read data path delay, reference voltage and address lines, combined with the transmit, read back and analysis modules, Implement quick diagnosis and tuning of interfaces.




Storage device and method for storage error management
PatentPendingCN119356934A
Innovation
- A memory device is designed, including multiple stacked integrated circuit dies, equipped with reliability circuitry, including backup memory and address tables, for detecting and correcting data errors and achieving fault tolerance of memory accesses through the backup memory.
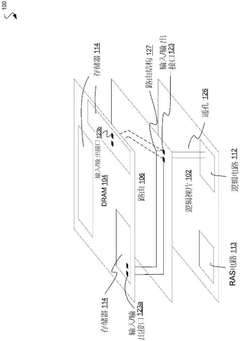
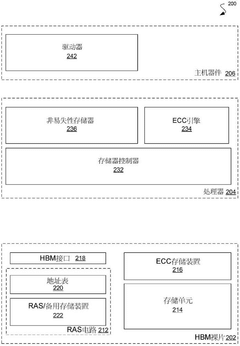
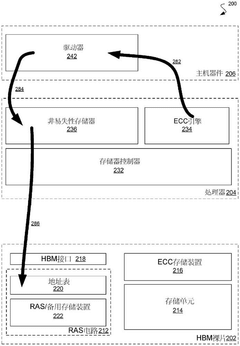
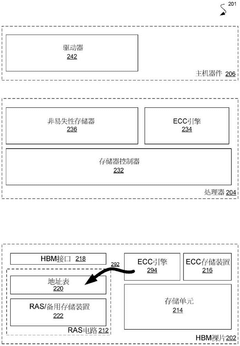
Thermal Management Considerations in HBM4 Testing
Thermal management represents a critical challenge in HBM4 reliability screening processes, particularly during burn-in testing where elevated temperatures are deliberately applied to accelerate potential failure mechanisms. The compact architecture of HBM4 memory, featuring stacked dies interconnected with through-silicon vias (TSVs), creates significant thermal density challenges that must be carefully managed to ensure effective testing without introducing thermal-induced failures that wouldn't occur under normal operating conditions.
During burn-in testing of HBM4 devices, temperature gradients across the stacked die structure can lead to differential thermal expansion, potentially stressing microbumps and TSV connections. Industry data indicates that temperature variations exceeding 15°C across the stack can significantly increase the risk of connection failures. This necessitates precise thermal control systems capable of maintaining temperature uniformity within ±5°C across the entire HBM4 package during testing procedures.
Advanced cooling solutions have emerged as essential components of HBM4 burn-in test equipment. Liquid cooling systems utilizing dielectric fluids have demonstrated superior performance compared to traditional forced-air cooling, achieving up to 40% better temperature uniformity across stacked dies. These systems typically incorporate microfluidic channels that enable targeted cooling of high-power density regions within the HBM4 structure.
Real-time thermal monitoring represents another critical aspect of HBM4 burn-in testing. Embedded thermal sensors within test sockets, combined with infrared thermography techniques, enable continuous monitoring of temperature distributions across the device under test. This data feeds into adaptive control systems that can dynamically adjust thermal conditions to maintain optimal test parameters while preventing thermal runaway scenarios that could lead to catastrophic failures.
The thermal interface between the HBM4 device and test equipment presents additional challenges. Advanced thermal interface materials (TIMs) with thermal conductivity exceeding 5 W/m·K have been developed specifically for HBM4 testing applications. These materials must maintain consistent performance across hundreds of test cycles while accommodating the unique physical characteristics of HBM4 packages, including their relatively fragile structure and exposed silicon edges.
Power delivery networks for HBM4 burn-in testing must be carefully designed to minimize localized heating effects. Distributed power delivery architectures that reduce current densities at connection points have shown promise in minimizing thermal hotspots. Additionally, pulsed power delivery techniques that alternate between high-power test conditions and cooling periods can effectively manage thermal accumulation during extended burn-in procedures.
During burn-in testing of HBM4 devices, temperature gradients across the stacked die structure can lead to differential thermal expansion, potentially stressing microbumps and TSV connections. Industry data indicates that temperature variations exceeding 15°C across the stack can significantly increase the risk of connection failures. This necessitates precise thermal control systems capable of maintaining temperature uniformity within ±5°C across the entire HBM4 package during testing procedures.
Advanced cooling solutions have emerged as essential components of HBM4 burn-in test equipment. Liquid cooling systems utilizing dielectric fluids have demonstrated superior performance compared to traditional forced-air cooling, achieving up to 40% better temperature uniformity across stacked dies. These systems typically incorporate microfluidic channels that enable targeted cooling of high-power density regions within the HBM4 structure.
Real-time thermal monitoring represents another critical aspect of HBM4 burn-in testing. Embedded thermal sensors within test sockets, combined with infrared thermography techniques, enable continuous monitoring of temperature distributions across the device under test. This data feeds into adaptive control systems that can dynamically adjust thermal conditions to maintain optimal test parameters while preventing thermal runaway scenarios that could lead to catastrophic failures.
The thermal interface between the HBM4 device and test equipment presents additional challenges. Advanced thermal interface materials (TIMs) with thermal conductivity exceeding 5 W/m·K have been developed specifically for HBM4 testing applications. These materials must maintain consistent performance across hundreds of test cycles while accommodating the unique physical characteristics of HBM4 packages, including their relatively fragile structure and exposed silicon edges.
Power delivery networks for HBM4 burn-in testing must be carefully designed to minimize localized heating effects. Distributed power delivery architectures that reduce current densities at connection points have shown promise in minimizing thermal hotspots. Additionally, pulsed power delivery techniques that alternate between high-power test conditions and cooling periods can effectively manage thermal accumulation during extended burn-in procedures.
Industry Standards and Certification Requirements
The reliability screening of HBM4 memory modules is governed by a comprehensive set of industry standards and certification requirements that ensure consistent quality, performance, and interoperability across manufacturers. JEDEC (Joint Electron Device Engineering Council) serves as the primary standards organization for memory technologies, establishing the foundational specifications for HBM4 reliability testing. JEDEC standard JESD47 "Stress-Test-Driven Qualification of Integrated Circuits" provides the baseline requirements for burn-in testing methodologies, while JESD22-A108 specifically addresses high-temperature operational life testing critical for HBM4 reliability assessment.
For HBM4 memory intended for automotive applications, the AEC-Q100 (Automotive Electronics Council) qualification requirements impose more stringent reliability standards, including extended burn-in durations at elevated temperatures and additional environmental stress testing. These standards mandate specific failure rate targets, typically measured in defective parts per million (DPPM), with premium automotive-grade HBM4 requiring failure rates below 1 DPPM.
Military and aerospace applications follow MIL-STD-883 standards, which define rigorous screening procedures including 100% burn-in testing for all memory components. These standards specify precise temperature cycling profiles, electrical parameter verification, and detailed failure analysis protocols that must be documented throughout the screening process.
The International Electrotechnical Commission (IEC) provides complementary standards focusing on environmental testing (IEC 60068 series) that complement burn-in procedures with additional reliability verification methods. For HBM4 components used in data centers, the Open Compute Project (OCP) has developed supplementary reliability specifications that address the unique thermal and electrical stress conditions encountered in high-density computing environments.
Certification requirements also extend to the testing equipment used for HBM4 burn-in procedures. The equipment must be calibrated according to ISO/IEC 17025 standards, with documented traceability to national measurement standards. Test system accuracy and repeatability must be verified through gauge R&R (Repeatability and Reproducibility) studies following AIAG (Automotive Industry Action Group) guidelines.
Compliance with these standards requires comprehensive documentation of test conditions, failure modes, and corrective actions. Manufacturers must maintain detailed records of burn-in parameters including temperature profiles, voltage conditions, test patterns, and duration. Statistical process control (SPC) methodologies must be implemented to monitor drift in failure rates and identify potential reliability issues before they impact field performance.
For HBM4 memory intended for automotive applications, the AEC-Q100 (Automotive Electronics Council) qualification requirements impose more stringent reliability standards, including extended burn-in durations at elevated temperatures and additional environmental stress testing. These standards mandate specific failure rate targets, typically measured in defective parts per million (DPPM), with premium automotive-grade HBM4 requiring failure rates below 1 DPPM.
Military and aerospace applications follow MIL-STD-883 standards, which define rigorous screening procedures including 100% burn-in testing for all memory components. These standards specify precise temperature cycling profiles, electrical parameter verification, and detailed failure analysis protocols that must be documented throughout the screening process.
The International Electrotechnical Commission (IEC) provides complementary standards focusing on environmental testing (IEC 60068 series) that complement burn-in procedures with additional reliability verification methods. For HBM4 components used in data centers, the Open Compute Project (OCP) has developed supplementary reliability specifications that address the unique thermal and electrical stress conditions encountered in high-density computing environments.
Certification requirements also extend to the testing equipment used for HBM4 burn-in procedures. The equipment must be calibrated according to ISO/IEC 17025 standards, with documented traceability to national measurement standards. Test system accuracy and repeatability must be verified through gauge R&R (Repeatability and Reproducibility) studies following AIAG (Automotive Industry Action Group) guidelines.
Compliance with these standards requires comprehensive documentation of test conditions, failure modes, and corrective actions. Manufacturers must maintain detailed records of burn-in parameters including temperature profiles, voltage conditions, test patterns, and duration. Statistical process control (SPC) methodologies must be implemented to monitor drift in failure rates and identify potential reliability issues before they impact field performance.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!