How do neuromorphic systems process sparse data efficiently?
SEP 3, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Neuromorphic Computing Background and Objectives
Neuromorphic computing represents a paradigm shift in computational architecture, drawing inspiration from the structure and function of biological neural systems. This field emerged in the late 1980s when Carver Mead coined the term "neuromorphic" to describe electronic systems that mimic neuro-biological architectures. Over the past three decades, neuromorphic computing has evolved from theoretical concepts to practical implementations, with significant advancements in hardware design, neural network algorithms, and application domains.
The evolution of neuromorphic systems has been driven by the limitations of traditional von Neumann architectures, particularly in handling complex cognitive tasks and processing massive amounts of data efficiently. Traditional computing architectures face fundamental bottlenecks in energy efficiency and processing speed when dealing with neural network computations, creating an imperative for alternative approaches that can better handle the parallel, distributed nature of brain-like processing.
Sparse data processing represents a critical aspect of neuromorphic computing's potential advantage. Biological neural systems excel at processing sparse information—where only a small fraction of possible inputs are active at any given time—with remarkable efficiency. This characteristic is particularly relevant in real-world scenarios where meaningful signals are often embedded within vast amounts of irrelevant data.
The primary technical objectives in neuromorphic computing for sparse data processing include developing architectures that can dynamically adapt to varying levels of sparsity, implementing efficient spike-based communication protocols, and creating hardware that minimizes energy consumption during periods of inactivity. These objectives align with the broader goals of achieving brain-like efficiency in artificial systems.
Recent technological trends in this domain include the integration of novel memory technologies such as memristors, spintronic devices, and phase-change materials that enable more efficient implementation of synaptic functions. Additionally, there has been significant progress in developing specialized neuromorphic hardware accelerators that leverage sparsity for improved performance and energy efficiency.
The convergence of neuromorphic computing with advances in machine learning, particularly in spiking neural networks (SNNs), has opened new avenues for processing sparse temporal data. This synergy promises to enable more efficient processing of sensor data in edge computing scenarios, real-time pattern recognition in noisy environments, and adaptive learning systems that can operate under severe power constraints.
The evolution of neuromorphic systems has been driven by the limitations of traditional von Neumann architectures, particularly in handling complex cognitive tasks and processing massive amounts of data efficiently. Traditional computing architectures face fundamental bottlenecks in energy efficiency and processing speed when dealing with neural network computations, creating an imperative for alternative approaches that can better handle the parallel, distributed nature of brain-like processing.
Sparse data processing represents a critical aspect of neuromorphic computing's potential advantage. Biological neural systems excel at processing sparse information—where only a small fraction of possible inputs are active at any given time—with remarkable efficiency. This characteristic is particularly relevant in real-world scenarios where meaningful signals are often embedded within vast amounts of irrelevant data.
The primary technical objectives in neuromorphic computing for sparse data processing include developing architectures that can dynamically adapt to varying levels of sparsity, implementing efficient spike-based communication protocols, and creating hardware that minimizes energy consumption during periods of inactivity. These objectives align with the broader goals of achieving brain-like efficiency in artificial systems.
Recent technological trends in this domain include the integration of novel memory technologies such as memristors, spintronic devices, and phase-change materials that enable more efficient implementation of synaptic functions. Additionally, there has been significant progress in developing specialized neuromorphic hardware accelerators that leverage sparsity for improved performance and energy efficiency.
The convergence of neuromorphic computing with advances in machine learning, particularly in spiking neural networks (SNNs), has opened new avenues for processing sparse temporal data. This synergy promises to enable more efficient processing of sensor data in edge computing scenarios, real-time pattern recognition in noisy environments, and adaptive learning systems that can operate under severe power constraints.
Market Analysis for Sparse Data Processing Solutions
The global market for sparse data processing solutions is experiencing significant growth, driven by the increasing volume of sparse data generated across various sectors. Current market estimates value this segment at approximately 3.5 billion USD in 2023, with projections indicating a compound annual growth rate of 24% through 2030. This growth trajectory is primarily fueled by applications in artificial intelligence, machine learning, computer vision, and natural language processing where efficient sparse data handling is critical.
Neuromorphic computing systems offer a particularly compelling value proposition in this market due to their inherent efficiency in processing sparse, event-driven data. Unlike traditional von Neumann architectures that process all data regardless of relevance, neuromorphic systems can selectively process only meaningful information, resulting in substantial energy savings and performance improvements for sparse data workloads.
The market demand is segmented across several key verticals. The healthcare sector represents approximately 28% of the market share, with applications in medical imaging analysis, patient monitoring systems, and drug discovery processes. Financial services follow at 22%, utilizing sparse data processing for fraud detection, algorithmic trading, and risk assessment models. Telecommunications and autonomous systems each account for approximately 18% of the market, with the remaining 14% distributed across various industrial applications.
Geographically, North America currently dominates with 42% market share, followed by Europe (27%), Asia-Pacific (23%), and rest of the world (8%). However, the Asia-Pacific region is demonstrating the fastest growth rate at 29% annually, driven by substantial investments in AI infrastructure and neuromorphic research initiatives in China, Japan, and South Korea.
Customer requirements are evolving rapidly, with increasing emphasis on energy efficiency, real-time processing capabilities, and seamless integration with existing systems. Organizations are particularly interested in solutions that can reduce computational costs while maintaining or improving accuracy for sparse data workloads. This has created a significant opportunity for neuromorphic computing systems that can deliver 10-100x improvements in energy efficiency compared to traditional computing architectures when processing sparse data.
Market barriers include high initial implementation costs, limited standardization across neuromorphic platforms, and the need for specialized programming expertise. Despite these challenges, the market is expected to accelerate as more commercial neuromorphic solutions become available and demonstrate clear return on investment through reduced computational infrastructure costs and improved performance on sparse data processing tasks.
Neuromorphic computing systems offer a particularly compelling value proposition in this market due to their inherent efficiency in processing sparse, event-driven data. Unlike traditional von Neumann architectures that process all data regardless of relevance, neuromorphic systems can selectively process only meaningful information, resulting in substantial energy savings and performance improvements for sparse data workloads.
The market demand is segmented across several key verticals. The healthcare sector represents approximately 28% of the market share, with applications in medical imaging analysis, patient monitoring systems, and drug discovery processes. Financial services follow at 22%, utilizing sparse data processing for fraud detection, algorithmic trading, and risk assessment models. Telecommunications and autonomous systems each account for approximately 18% of the market, with the remaining 14% distributed across various industrial applications.
Geographically, North America currently dominates with 42% market share, followed by Europe (27%), Asia-Pacific (23%), and rest of the world (8%). However, the Asia-Pacific region is demonstrating the fastest growth rate at 29% annually, driven by substantial investments in AI infrastructure and neuromorphic research initiatives in China, Japan, and South Korea.
Customer requirements are evolving rapidly, with increasing emphasis on energy efficiency, real-time processing capabilities, and seamless integration with existing systems. Organizations are particularly interested in solutions that can reduce computational costs while maintaining or improving accuracy for sparse data workloads. This has created a significant opportunity for neuromorphic computing systems that can deliver 10-100x improvements in energy efficiency compared to traditional computing architectures when processing sparse data.
Market barriers include high initial implementation costs, limited standardization across neuromorphic platforms, and the need for specialized programming expertise. Despite these challenges, the market is expected to accelerate as more commercial neuromorphic solutions become available and demonstrate clear return on investment through reduced computational infrastructure costs and improved performance on sparse data processing tasks.
Current Neuromorphic Systems and Technical Barriers
Current neuromorphic computing systems represent a significant departure from traditional von Neumann architectures, offering promising approaches for efficient sparse data processing. Leading implementations include IBM's TrueNorth, Intel's Loihi, and BrainChip's Akida, each employing different strategies to handle sparsity in neural networks. TrueNorth utilizes a crossbar architecture with 4,096 neurosynaptic cores, achieving energy efficiency through event-driven computation that activates only when necessary for sparse inputs.
Intel's Loihi advances this concept with its hierarchical connectivity and on-chip learning capabilities, particularly excelling at processing temporal sparse data patterns through its time-multiplexed communication channels. The chip's sparse activity-dependent processing enables up to 1,000 times better energy efficiency compared to conventional GPUs when handling sparse workloads.
BrainChip's Akida focuses specifically on edge computing applications, implementing native sparse network processing through its event-based neural processing units that respond only to significant data changes, making it particularly suitable for sensor data processing where information arrives sporadically.
Despite these advancements, neuromorphic systems face substantial technical barriers in fully exploiting sparse data processing capabilities. A primary challenge lies in the hardware-software co-design complexity, where existing programming paradigms and algorithms developed for dense computing poorly translate to sparse, event-driven architectures. This creates a significant gap between theoretical capabilities and practical implementations.
Memory bandwidth limitations present another critical barrier, as even neuromorphic systems struggle with the efficient routing of sparse activations across large-scale networks. The irregular memory access patterns inherent in sparse processing create bottlenecks that current memory hierarchies cannot optimally handle.
Scaling challenges persist across all current implementations. As neuromorphic networks grow in size, maintaining efficient sparse data communication becomes exponentially more difficult, with current interconnect technologies unable to match the theoretical connectivity patterns of biological neural systems.
The lack of standardized benchmarks specifically designed for sparse data processing in neuromorphic contexts further impedes progress, making it difficult to objectively compare different architectural approaches and optimization techniques. Most performance metrics remain borrowed from conventional computing paradigms, failing to capture the unique advantages of neuromorphic sparse processing.
Energy efficiency, while improved compared to traditional architectures, still falls short of biological neural systems by several orders of magnitude, particularly when processing highly sparse, temporally distributed data patterns that characterize many real-world sensing applications.
Intel's Loihi advances this concept with its hierarchical connectivity and on-chip learning capabilities, particularly excelling at processing temporal sparse data patterns through its time-multiplexed communication channels. The chip's sparse activity-dependent processing enables up to 1,000 times better energy efficiency compared to conventional GPUs when handling sparse workloads.
BrainChip's Akida focuses specifically on edge computing applications, implementing native sparse network processing through its event-based neural processing units that respond only to significant data changes, making it particularly suitable for sensor data processing where information arrives sporadically.
Despite these advancements, neuromorphic systems face substantial technical barriers in fully exploiting sparse data processing capabilities. A primary challenge lies in the hardware-software co-design complexity, where existing programming paradigms and algorithms developed for dense computing poorly translate to sparse, event-driven architectures. This creates a significant gap between theoretical capabilities and practical implementations.
Memory bandwidth limitations present another critical barrier, as even neuromorphic systems struggle with the efficient routing of sparse activations across large-scale networks. The irregular memory access patterns inherent in sparse processing create bottlenecks that current memory hierarchies cannot optimally handle.
Scaling challenges persist across all current implementations. As neuromorphic networks grow in size, maintaining efficient sparse data communication becomes exponentially more difficult, with current interconnect technologies unable to match the theoretical connectivity patterns of biological neural systems.
The lack of standardized benchmarks specifically designed for sparse data processing in neuromorphic contexts further impedes progress, making it difficult to objectively compare different architectural approaches and optimization techniques. Most performance metrics remain borrowed from conventional computing paradigms, failing to capture the unique advantages of neuromorphic sparse processing.
Energy efficiency, while improved compared to traditional architectures, still falls short of biological neural systems by several orders of magnitude, particularly when processing highly sparse, temporally distributed data patterns that characterize many real-world sensing applications.
Current Sparse Data Processing Methodologies
01 Energy-efficient neuromorphic hardware architectures
Neuromorphic systems can achieve higher energy efficiency through specialized hardware architectures that mimic biological neural networks. These architectures include low-power analog circuits, memristive devices, and optimized digital designs that reduce computational overhead. By implementing brain-inspired processing elements that operate in parallel with minimal energy consumption, these systems can perform complex cognitive tasks while maintaining power efficiency.- Energy-efficient neuromorphic hardware architectures: Neuromorphic systems can achieve higher energy efficiency through specialized hardware architectures that mimic biological neural networks. These architectures include low-power analog circuits, memristive devices, and optimized digital designs that reduce computational overhead. By implementing brain-inspired computing principles directly in hardware, these systems can perform complex cognitive tasks with significantly lower power consumption compared to traditional computing approaches.
- Spike-based processing and communication: Neuromorphic systems that utilize spike-based processing and communication protocols can achieve substantial efficiency improvements. These systems transmit information through discrete events (spikes) rather than continuous signals, reducing energy consumption during periods of inactivity. Spike-timing-dependent plasticity (STDP) and other biologically-inspired learning mechanisms enable these systems to adapt and learn from input patterns while maintaining low power requirements.
- Memory-compute integration techniques: Integrating memory and computing elements in neuromorphic systems eliminates the energy costs associated with data movement between separate memory and processing units. These architectures use in-memory computing approaches where computational operations occur directly within memory arrays. Techniques such as resistive RAM (RRAM), phase-change memory (PCM), and other non-volatile memory technologies enable efficient implementation of neural network weights and synaptic connections, significantly reducing energy consumption.
- Optimization algorithms for neuromorphic efficiency: Various optimization algorithms can enhance the efficiency of neuromorphic systems. These include sparse coding techniques, pruning methods that remove unnecessary connections, and quantization approaches that reduce precision requirements. Advanced training methodologies specifically designed for neuromorphic hardware can optimize network topologies and parameters to maximize energy efficiency while maintaining computational performance for specific applications.
- Application-specific neuromorphic designs: Tailoring neuromorphic systems for specific applications can significantly improve efficiency. By designing hardware and algorithms optimized for particular tasks such as computer vision, speech recognition, or sensor processing, unnecessary computational elements can be eliminated. These application-specific neuromorphic systems incorporate domain knowledge into their architecture, resulting in highly efficient solutions that outperform general-purpose designs in terms of energy consumption and processing speed.
02 Spike-based processing for power optimization
Spike-based neural processing models significantly improve energy efficiency in neuromorphic systems by transmitting information only when necessary. This event-driven approach reduces power consumption compared to traditional computing paradigms that operate continuously. Spiking Neural Networks (SNNs) process data asynchronously, allowing for sparse computations that activate only when input changes occur, thereby minimizing energy usage while maintaining computational capabilities.Expand Specific Solutions03 Memory-compute integration techniques
Integrating memory and computing elements in neuromorphic systems eliminates the energy costs associated with data movement between separate processing and storage units. This approach, often called compute-in-memory or processing-in-memory, uses novel device technologies such as resistive RAM, phase change memory, or other non-volatile memory elements to perform computations directly where data is stored, significantly reducing power consumption and increasing processing speed.Expand Specific Solutions04 Algorithm-hardware co-optimization strategies
Efficiency in neuromorphic systems can be substantially improved through co-optimization of algorithms and hardware. This approach involves designing neural network algorithms specifically tailored to the constraints and capabilities of neuromorphic hardware, including quantization techniques, pruning methods, and sparse coding. By jointly optimizing both the computational models and the physical implementation, these systems achieve better energy efficiency without sacrificing performance.Expand Specific Solutions05 Novel materials and fabrication techniques
Advanced materials and fabrication techniques enable the development of more efficient neuromorphic systems. These include emerging nanomaterials, 3D integration technologies, and novel semiconductor processes that support the creation of dense, low-power neural circuits. Such materials can exhibit properties similar to biological synapses and neurons, allowing for more efficient implementation of neuromorphic functions while reducing the energy required for computation and communication between neural elements.Expand Specific Solutions
Leading Organizations in Neuromorphic Computing
Neuromorphic computing for sparse data processing is in an early growth phase, with a market expected to expand significantly as AI applications proliferate. The technology demonstrates moderate maturity, with key players developing specialized hardware solutions. Intel leads with its Loihi chip, while IBM's TrueNorth architecture offers competitive capabilities. Academic institutions like Tsinghua University and KAIST are advancing fundamental research. Emerging companies such as Innatera Nanosystems and Syntiant are introducing innovative approaches, while established semiconductor firms including Samsung, SK Hynix, and Huawei are integrating neuromorphic elements into their AI strategies. The field is characterized by diverse approaches to mimicking brain-like processing for efficient sparse data handling.
Intel Corp.
Technical Solution: Intel's Loihi neuromorphic research chip represents a significant advancement in efficient sparse data processing. The chip features a mesh of 128 neuromorphic cores, each implementing 1,024 spiking neurons for a total of 131,072 neurons and 130 million synapses. Loihi's architecture is specifically optimized for sparse event-driven computation through its asynchronous spike-based communication protocol. When processing sparse data, Loihi activates only the neurons relevant to the input pattern, dramatically reducing power consumption compared to traditional architectures. The chip incorporates sparse coding mechanisms where information is represented by the timing and spatial distribution of spikes rather than continuous values, enabling efficient representation of sparse features. Intel's second-generation Loihi 2 further enhances sparse data processing with programmable neuron models, up to 10x faster processing speeds, and up to 60x more inter-chip bandwidth. The system's event-driven paradigm ensures computational resources are allocated only when and where needed, making it particularly efficient for applications with naturally sparse data like sensor networks, robotics, and real-time signal processing.
Strengths: Highly energy-efficient (1000x more efficient than general-purpose computing for certain workloads); scalable architecture supporting large-scale networks; flexible programmability allowing adaptation to different sparse data applications. Weaknesses: Still primarily a research platform with limited commercial deployment; requires specialized programming approaches; integration challenges with conventional computing infrastructure.
International Business Machines Corp.
Technical Solution: IBM's neuromorphic system, TrueNorth, employs a revolutionary architecture specifically designed for sparse data processing. The system utilizes a non-von Neumann architecture with a million digital neurons and 256 million synapses organized into 4,096 neurosynaptic cores. For sparse data processing, TrueNorth implements event-driven computation where only active neurons consume power and contribute to processing. This approach allows the system to achieve remarkable energy efficiency—consuming just 70mW during real-time operation, which is orders of magnitude more efficient than conventional architectures. IBM's neuromorphic chips incorporate specialized circuits that exploit sparsity through compressed data formats and selective activation, enabling efficient pattern recognition in sparse datasets. The system's parallel processing capabilities allow it to handle multiple sparse inputs simultaneously without performance degradation, making it particularly effective for applications like computer vision and sensor data analysis where information is naturally sparse.
Strengths: Exceptional energy efficiency (20mW per cm²) makes it ideal for edge computing; highly scalable architecture; inherent parallelism enables real-time processing of multiple sparse data streams. Weaknesses: Programming complexity requires specialized knowledge; limited precision compared to traditional computing systems; challenges in adapting conventional algorithms to the neuromorphic paradigm.
Key Neuromorphic Algorithms and Hardware Innovations
Sparse neuromorphic processor
PatentActiveUS20170357889A1
Innovation
- A processor architecture that leverages sparsity by using inference and classification modules with parallel convolutional operations to generate sparse representations, reducing computational needs and power consumption through optimized parallel processing and sparse convolvers.




Systems and Methods of Sparsity Exploiting
PatentInactiveUS20240095510A1
Innovation
- A neuromorphic integrated circuit with a multi-layered neural network in an analog multiplier array, where two-quadrant multipliers are wired to ground and draw negligible current when input signal or weight values are zero, promoting sparsity and minimizing power consumption, and a method to train the network to drive weight values toward zero using a training algorithm.
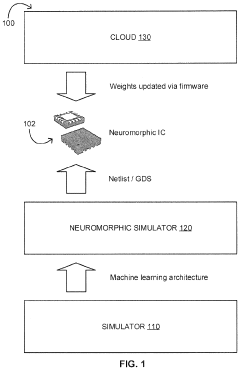
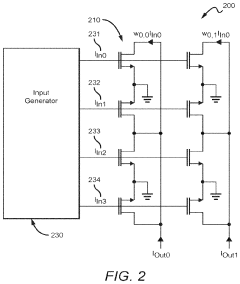
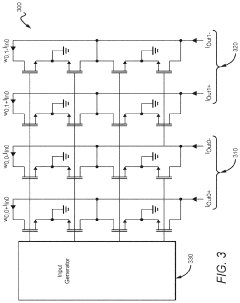
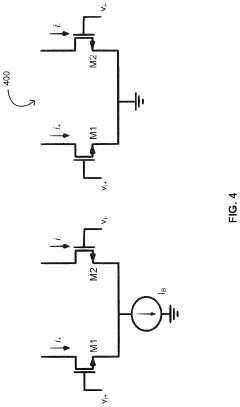
Energy Efficiency Metrics and Benchmarking
Evaluating the energy efficiency of neuromorphic systems when processing sparse data requires specialized metrics and benchmarking approaches that differ significantly from traditional computing paradigms. The inherent event-driven nature of neuromorphic hardware creates unique opportunities for energy optimization when handling sparse data patterns, necessitating appropriate measurement frameworks to quantify these advantages.
Traditional computing metrics like FLOPS/watt prove inadequate for neuromorphic systems, as they fail to capture the fundamental operational differences. Instead, metrics such as synaptic operations per second per watt (SOPS/W) and energy per spike have emerged as more relevant indicators. These metrics directly measure the energy consumed during the processing of sparse, event-driven data, providing a more accurate representation of neuromorphic efficiency.
Benchmarking neuromorphic systems presents unique challenges due to the lack of standardized frameworks. Recent efforts have established specialized benchmarks like N-MNIST and SHD (Spiking Heidelberg Digits) that specifically evaluate performance on sparse, temporal data patterns. These benchmarks measure both computational accuracy and energy consumption, enabling fair comparisons between different neuromorphic architectures and against conventional computing systems.
The sparsity ratio—defined as the proportion of active neurons or synapses relative to the total available—serves as a critical parameter in energy efficiency assessments. Empirical studies demonstrate that neuromorphic systems achieve exponential energy savings as data sparsity increases, with some implementations showing 100-1000x efficiency improvements over conventional processors when sparsity exceeds 95%.
Dynamic power scaling represents another important dimension in neuromorphic benchmarking. Unlike traditional processors that maintain relatively constant power consumption regardless of computational load, neuromorphic systems can scale power consumption proportionally to neural activity. This property enables these systems to achieve near-zero idle power when processing extremely sparse data, a characteristic that must be captured in comprehensive benchmarking methodologies.
Standardization efforts are currently underway through initiatives like the Neuromorphic Computing Benchmark (NCB) suite, which aims to establish consistent evaluation protocols across different hardware platforms. These standards incorporate sparsity-aware metrics that specifically measure how efficiently systems exploit data sparsity to reduce energy consumption, providing a foundation for meaningful cross-platform comparisons and guiding future hardware optimizations.
Traditional computing metrics like FLOPS/watt prove inadequate for neuromorphic systems, as they fail to capture the fundamental operational differences. Instead, metrics such as synaptic operations per second per watt (SOPS/W) and energy per spike have emerged as more relevant indicators. These metrics directly measure the energy consumed during the processing of sparse, event-driven data, providing a more accurate representation of neuromorphic efficiency.
Benchmarking neuromorphic systems presents unique challenges due to the lack of standardized frameworks. Recent efforts have established specialized benchmarks like N-MNIST and SHD (Spiking Heidelberg Digits) that specifically evaluate performance on sparse, temporal data patterns. These benchmarks measure both computational accuracy and energy consumption, enabling fair comparisons between different neuromorphic architectures and against conventional computing systems.
The sparsity ratio—defined as the proportion of active neurons or synapses relative to the total available—serves as a critical parameter in energy efficiency assessments. Empirical studies demonstrate that neuromorphic systems achieve exponential energy savings as data sparsity increases, with some implementations showing 100-1000x efficiency improvements over conventional processors when sparsity exceeds 95%.
Dynamic power scaling represents another important dimension in neuromorphic benchmarking. Unlike traditional processors that maintain relatively constant power consumption regardless of computational load, neuromorphic systems can scale power consumption proportionally to neural activity. This property enables these systems to achieve near-zero idle power when processing extremely sparse data, a characteristic that must be captured in comprehensive benchmarking methodologies.
Standardization efforts are currently underway through initiatives like the Neuromorphic Computing Benchmark (NCB) suite, which aims to establish consistent evaluation protocols across different hardware platforms. These standards incorporate sparsity-aware metrics that specifically measure how efficiently systems exploit data sparsity to reduce energy consumption, providing a foundation for meaningful cross-platform comparisons and guiding future hardware optimizations.
Neuromorphic Integration with Edge Computing Systems
The integration of neuromorphic computing with edge computing systems represents a significant advancement in processing sparse data efficiently at the network edge. Neuromorphic architectures, inspired by the human brain's neural structure, offer unique advantages when deployed in edge computing environments where power constraints and real-time processing requirements are paramount.
Edge computing systems benefit from neuromorphic integration primarily through dramatic reductions in power consumption. Traditional computing architectures process data continuously regardless of information content, whereas neuromorphic systems employ event-driven processing that activates only when meaningful data is present. This approach is particularly effective for sparse data streams common in IoT sensors and mobile devices, where significant portions of incoming data contain minimal actionable information.
The technical implementation of this integration typically involves specialized hardware accelerators that complement traditional edge processors. These neuromorphic components can be designed as co-processors or dedicated processing units that handle specific computational tasks optimized for sparse data processing. Intel's Loihi chip and IBM's TrueNorth represent commercial implementations that demonstrate this capability, achieving orders of magnitude improvement in energy efficiency for certain workloads.
Communication protocols between neuromorphic components and conventional edge computing systems present unique challenges. Address-Event Representation (AER) has emerged as a common protocol that efficiently encodes sparse neural events, minimizing data transfer requirements between system components. This approach aligns well with edge computing's bandwidth constraints.
Real-world applications benefiting from this integration include smart surveillance systems that can detect anomalies while consuming minimal power, environmental monitoring networks that process sensor data locally, and augmented reality devices that require real-time pattern recognition. In these scenarios, the neuromorphic components handle the sparse, event-driven data while traditional processors manage more structured computational tasks.
Deployment architectures typically follow one of three models: fully integrated systems where neuromorphic processors are embedded directly within edge devices; hybrid systems where neuromorphic accelerators complement traditional processors; or distributed systems where neuromorphic processing occurs across multiple edge nodes. Each approach offers different trade-offs between processing capability, power efficiency, and implementation complexity.
The scalability of these integrated systems remains an active research area, with current implementations demonstrating promising results for applications with naturally sparse data representations. As neuromorphic hardware continues to mature, its integration with edge computing infrastructure will likely expand to address increasingly complex computational challenges at the network edge.
Edge computing systems benefit from neuromorphic integration primarily through dramatic reductions in power consumption. Traditional computing architectures process data continuously regardless of information content, whereas neuromorphic systems employ event-driven processing that activates only when meaningful data is present. This approach is particularly effective for sparse data streams common in IoT sensors and mobile devices, where significant portions of incoming data contain minimal actionable information.
The technical implementation of this integration typically involves specialized hardware accelerators that complement traditional edge processors. These neuromorphic components can be designed as co-processors or dedicated processing units that handle specific computational tasks optimized for sparse data processing. Intel's Loihi chip and IBM's TrueNorth represent commercial implementations that demonstrate this capability, achieving orders of magnitude improvement in energy efficiency for certain workloads.
Communication protocols between neuromorphic components and conventional edge computing systems present unique challenges. Address-Event Representation (AER) has emerged as a common protocol that efficiently encodes sparse neural events, minimizing data transfer requirements between system components. This approach aligns well with edge computing's bandwidth constraints.
Real-world applications benefiting from this integration include smart surveillance systems that can detect anomalies while consuming minimal power, environmental monitoring networks that process sensor data locally, and augmented reality devices that require real-time pattern recognition. In these scenarios, the neuromorphic components handle the sparse, event-driven data while traditional processors manage more structured computational tasks.
Deployment architectures typically follow one of three models: fully integrated systems where neuromorphic processors are embedded directly within edge devices; hybrid systems where neuromorphic accelerators complement traditional processors; or distributed systems where neuromorphic processing occurs across multiple edge nodes. Each approach offers different trade-offs between processing capability, power efficiency, and implementation complexity.
The scalability of these integrated systems remains an active research area, with current implementations demonstrating promising results for applications with naturally sparse data representations. As neuromorphic hardware continues to mature, its integration with edge computing infrastructure will likely expand to address increasingly complex computational challenges at the network edge.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!