

Compiler Design for SNNs on Custom Neuromorphic Chips.
SEP 2, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
SNN Compiler Evolution and Objectives
Spiking Neural Networks (SNNs) represent a biologically inspired computing paradigm that has evolved significantly over the past two decades. The development of SNN compilers has paralleled advancements in neuromorphic hardware, transitioning from basic proof-of-concept implementations to sophisticated toolchains capable of optimizing complex neural networks for specialized hardware architectures.
The evolution of SNN compilers began in the early 2000s with rudimentary translation tools that could map simple spiking neuron models to digital circuits. These early compilers focused primarily on direct implementation of neuron dynamics without significant optimization. By 2010, the second generation of SNN compilers emerged, introducing basic optimization techniques such as spike event compression and memory access pattern improvements.
The period from 2015 to 2020 marked a significant advancement with the introduction of automated mapping tools that could translate conventional artificial neural networks (ANNs) to their SNN counterparts. This development broadened the application scope of SNNs by leveraging the extensive ecosystem of ANN frameworks while benefiting from the energy efficiency of spike-based computation.
Current state-of-the-art SNN compilers aim to bridge the gap between algorithmic descriptions of neural networks and the physical constraints of neuromorphic hardware. They incorporate sophisticated optimization techniques including spike timing-dependent plasticity (STDP) learning rule implementations, neuron model approximations, and hardware-aware mapping strategies that consider the unique characteristics of target neuromorphic architectures.
The primary objective of modern SNN compiler design is to maximize computational efficiency while preserving the biological fidelity that gives SNNs their unique advantages. This involves balancing several competing factors: energy consumption, processing speed, memory utilization, and accuracy of neural dynamics representation.
Another critical goal is to provide abstraction layers that shield developers from the complexities of neuromorphic hardware implementation details. This democratizes access to neuromorphic computing by allowing researchers and developers to focus on algorithmic innovations rather than hardware-specific optimizations.
Looking forward, SNN compiler technology aims to support increasingly heterogeneous neuromorphic architectures, facilitate seamless integration with conventional computing paradigms, and enable real-time learning capabilities. The ultimate vision is to develop compiler frameworks that can automatically identify optimal implementations for specific applications, dynamically adapting network structures and parameters to maximize performance across diverse workloads and hardware configurations.
The evolution of SNN compilers began in the early 2000s with rudimentary translation tools that could map simple spiking neuron models to digital circuits. These early compilers focused primarily on direct implementation of neuron dynamics without significant optimization. By 2010, the second generation of SNN compilers emerged, introducing basic optimization techniques such as spike event compression and memory access pattern improvements.
The period from 2015 to 2020 marked a significant advancement with the introduction of automated mapping tools that could translate conventional artificial neural networks (ANNs) to their SNN counterparts. This development broadened the application scope of SNNs by leveraging the extensive ecosystem of ANN frameworks while benefiting from the energy efficiency of spike-based computation.
Current state-of-the-art SNN compilers aim to bridge the gap between algorithmic descriptions of neural networks and the physical constraints of neuromorphic hardware. They incorporate sophisticated optimization techniques including spike timing-dependent plasticity (STDP) learning rule implementations, neuron model approximations, and hardware-aware mapping strategies that consider the unique characteristics of target neuromorphic architectures.
The primary objective of modern SNN compiler design is to maximize computational efficiency while preserving the biological fidelity that gives SNNs their unique advantages. This involves balancing several competing factors: energy consumption, processing speed, memory utilization, and accuracy of neural dynamics representation.
Another critical goal is to provide abstraction layers that shield developers from the complexities of neuromorphic hardware implementation details. This democratizes access to neuromorphic computing by allowing researchers and developers to focus on algorithmic innovations rather than hardware-specific optimizations.
Looking forward, SNN compiler technology aims to support increasingly heterogeneous neuromorphic architectures, facilitate seamless integration with conventional computing paradigms, and enable real-time learning capabilities. The ultimate vision is to develop compiler frameworks that can automatically identify optimal implementations for specific applications, dynamically adapting network structures and parameters to maximize performance across diverse workloads and hardware configurations.
Market Analysis for Neuromorphic Computing Solutions
The neuromorphic computing market is experiencing significant growth, driven by increasing demand for AI applications that require energy-efficient processing of neural networks. Current market valuations place the global neuromorphic computing sector at approximately $3.2 billion in 2023, with projections indicating a compound annual growth rate of 24.7% through 2030. This growth trajectory is supported by substantial investments from both private and public sectors, with government initiatives like the EU's Human Brain Project and DARPA's SyNAPSE program allocating hundreds of millions in funding.
The demand for specialized compiler solutions for Spiking Neural Networks (SNNs) on custom neuromorphic hardware stems from several market factors. Traditional computing architectures face fundamental limitations in energy efficiency when implementing neural networks, creating a market gap that neuromorphic solutions aim to fill. Industries including autonomous vehicles, robotics, IoT edge devices, and healthcare monitoring systems represent primary market segments, each requiring ultra-low power consumption while maintaining real-time processing capabilities.
Market research indicates that the edge computing segment represents the fastest-growing application area for neuromorphic chips, with an estimated 32% annual growth rate. This is particularly relevant for SNN compiler design, as edge devices require optimized software stacks that can efficiently translate neural algorithms to specialized hardware while minimizing power consumption.
Geographically, North America currently leads the market with approximately 42% share, followed by Europe and Asia-Pacific regions. However, the Asia-Pacific region is expected to witness the highest growth rate in the coming years due to increasing investments in AI infrastructure and neuromorphic research initiatives in countries like China, Japan, and South Korea.
Customer needs analysis reveals several critical requirements driving market demand for SNN compilers: optimization for power efficiency (reducing energy consumption by 100-1000x compared to traditional approaches), latency reduction for real-time applications, and compatibility with existing AI frameworks to reduce adoption barriers. Additionally, there is growing demand for compiler solutions that can adapt to the heterogeneous nature of emerging neuromorphic hardware platforms.
Market barriers include the fragmentation of hardware architectures, limited standardization across neuromorphic platforms, and the technical complexity of efficiently mapping conventional neural networks to spike-based implementations. These challenges represent significant opportunities for compiler technologies that can abstract hardware complexities and provide unified programming models.
The demand for specialized compiler solutions for Spiking Neural Networks (SNNs) on custom neuromorphic hardware stems from several market factors. Traditional computing architectures face fundamental limitations in energy efficiency when implementing neural networks, creating a market gap that neuromorphic solutions aim to fill. Industries including autonomous vehicles, robotics, IoT edge devices, and healthcare monitoring systems represent primary market segments, each requiring ultra-low power consumption while maintaining real-time processing capabilities.
Market research indicates that the edge computing segment represents the fastest-growing application area for neuromorphic chips, with an estimated 32% annual growth rate. This is particularly relevant for SNN compiler design, as edge devices require optimized software stacks that can efficiently translate neural algorithms to specialized hardware while minimizing power consumption.
Geographically, North America currently leads the market with approximately 42% share, followed by Europe and Asia-Pacific regions. However, the Asia-Pacific region is expected to witness the highest growth rate in the coming years due to increasing investments in AI infrastructure and neuromorphic research initiatives in countries like China, Japan, and South Korea.
Customer needs analysis reveals several critical requirements driving market demand for SNN compilers: optimization for power efficiency (reducing energy consumption by 100-1000x compared to traditional approaches), latency reduction for real-time applications, and compatibility with existing AI frameworks to reduce adoption barriers. Additionally, there is growing demand for compiler solutions that can adapt to the heterogeneous nature of emerging neuromorphic hardware platforms.
Market barriers include the fragmentation of hardware architectures, limited standardization across neuromorphic platforms, and the technical complexity of efficiently mapping conventional neural networks to spike-based implementations. These challenges represent significant opportunities for compiler technologies that can abstract hardware complexities and provide unified programming models.
Current SNN Compiler Challenges and Limitations
Despite significant advancements in neuromorphic computing, current SNN compiler technologies face substantial challenges that impede their widespread adoption and effectiveness. One primary limitation is the lack of standardized intermediate representations (IRs) specifically designed for SNNs. While traditional neural network compilers utilize well-established IRs like ONNX or TVM, these frameworks are fundamentally designed for rate-based neural networks and struggle to efficiently represent the temporal dynamics and event-driven nature of spiking networks.
The hardware-software co-design challenge presents another significant barrier. Neuromorphic hardware architectures vary dramatically across vendors, with diverse approaches to neuron models, synaptic connections, and spike communication protocols. This heterogeneity makes it exceedingly difficult to develop compiler toolchains that can effectively target multiple neuromorphic platforms while optimizing for their specific characteristics.
Memory management and data movement optimization remain particularly problematic for SNN compilers. The event-driven nature of SNNs creates irregular memory access patterns that are fundamentally different from the dense matrix operations in conventional DNNs. Current compiler technologies lack sophisticated mechanisms to optimize these spike-based data flows, resulting in inefficient hardware utilization and increased power consumption.
Timing and synchronization issues further complicate the compiler design landscape. SNNs operate with precise temporal dynamics where spike timing carries critical information. Existing compilers struggle to preserve these temporal relationships when mapping networks to hardware, especially when dealing with different clock domains or asynchronous processing elements common in neuromorphic systems.
The optimization space for SNNs differs substantially from traditional neural networks. While DNN compilers focus on parallelizing matrix operations and reducing precision, SNN compilers must consider spike sparsity, event-driven processing, and energy-per-spike metrics. Current optimization techniques are often borrowed from conventional compilers and fail to leverage the unique characteristics of spiking computation.
Debugging and profiling tools for SNN compilers remain primitive compared to their DNN counterparts. Developers lack sophisticated visualization tools for spike trains, timing analysis, and hardware resource utilization. This deficiency makes it challenging to identify performance bottlenecks or correctness issues in compiled SNN implementations.
Finally, the translation gap between rate-based models and spike-based execution presents a fundamental challenge. Many SNN applications begin with models trained in conventional frameworks that must be converted to spiking implementations. Current compilers provide limited support for this conversion process, often resulting in significant accuracy loss or performance degradation when deployed on neuromorphic hardware.
The hardware-software co-design challenge presents another significant barrier. Neuromorphic hardware architectures vary dramatically across vendors, with diverse approaches to neuron models, synaptic connections, and spike communication protocols. This heterogeneity makes it exceedingly difficult to develop compiler toolchains that can effectively target multiple neuromorphic platforms while optimizing for their specific characteristics.
Memory management and data movement optimization remain particularly problematic for SNN compilers. The event-driven nature of SNNs creates irregular memory access patterns that are fundamentally different from the dense matrix operations in conventional DNNs. Current compiler technologies lack sophisticated mechanisms to optimize these spike-based data flows, resulting in inefficient hardware utilization and increased power consumption.
Timing and synchronization issues further complicate the compiler design landscape. SNNs operate with precise temporal dynamics where spike timing carries critical information. Existing compilers struggle to preserve these temporal relationships when mapping networks to hardware, especially when dealing with different clock domains or asynchronous processing elements common in neuromorphic systems.
The optimization space for SNNs differs substantially from traditional neural networks. While DNN compilers focus on parallelizing matrix operations and reducing precision, SNN compilers must consider spike sparsity, event-driven processing, and energy-per-spike metrics. Current optimization techniques are often borrowed from conventional compilers and fail to leverage the unique characteristics of spiking computation.
Debugging and profiling tools for SNN compilers remain primitive compared to their DNN counterparts. Developers lack sophisticated visualization tools for spike trains, timing analysis, and hardware resource utilization. This deficiency makes it challenging to identify performance bottlenecks or correctness issues in compiled SNN implementations.
Finally, the translation gap between rate-based models and spike-based execution presents a fundamental challenge. Many SNN applications begin with models trained in conventional frameworks that must be converted to spiking implementations. Current compilers provide limited support for this conversion process, often resulting in significant accuracy loss or performance degradation when deployed on neuromorphic hardware.
State-of-the-Art SNN Compiler Architectures
01 Optimization techniques for SNN compilers
Various optimization techniques can be employed in SNN compilers to improve compilation efficiency. These include algorithmic optimizations that reduce computational complexity, memory access optimizations that minimize data transfer overhead, and parallel processing techniques that leverage multi-core architectures. These optimizations help to reduce compilation time and improve the overall efficiency of the SNN compilation process.- Optimization techniques for SNN compilers: Various optimization techniques can be employed in compilers for Spiking Neural Networks to improve compilation efficiency. These include algorithmic optimizations that reduce computational complexity, memory access optimizations that minimize data movement, and specialized instruction scheduling for neuromorphic hardware. These techniques help to reduce compilation time and improve the performance of the compiled SNN models on target hardware platforms.
- Hardware-specific compilation strategies: Compilers for SNNs can be designed with hardware-specific strategies to maximize efficiency on particular neuromorphic computing platforms. These strategies include mapping neural network topologies to specific hardware architectures, optimizing spike timing for hardware constraints, and leveraging specialized neuromorphic processing units. By tailoring the compilation process to the target hardware, significant improvements in execution speed and energy efficiency can be achieved.
- Spike encoding and compression techniques: Efficient encoding and compression of spike trains is crucial for SNN compilation efficiency. Techniques include temporal coding schemes that reduce the number of spikes needed to represent information, spike train compression algorithms that minimize memory requirements, and event-based processing optimizations. These approaches reduce the computational overhead associated with processing and transmitting spike data, leading to more efficient SNN implementations.
- Parallelization and distributed compilation frameworks: Parallelization strategies and distributed compilation frameworks can significantly improve the efficiency of SNN compilation. These include parallel spike processing algorithms, distributed training and inference pipelines, and multi-core compilation techniques. By leveraging parallel computing resources, these approaches can reduce compilation time for large-scale SNN models and enable more efficient deployment across computing clusters or neuromorphic systems.
- Model transformation and simplification techniques: Transforming and simplifying SNN models before compilation can lead to significant efficiency improvements. Techniques include neuron model approximations that reduce computational complexity, network pruning to eliminate redundant connections, and quantization methods that reduce precision requirements. These preprocessing steps can dramatically reduce the computational demands of the compilation process and improve the runtime performance of the compiled networks.
02 Hardware-specific compilation strategies
SNN compilers can be designed to target specific hardware architectures, such as neuromorphic chips, GPUs, or FPGAs. By tailoring the compilation process to the target hardware, these compilers can generate more efficient code that takes advantage of hardware-specific features. This approach can significantly improve the execution efficiency of SNNs on specialized hardware platforms.Expand Specific Solutions03 Intermediate representation for SNNs
Using specialized intermediate representations (IRs) in SNN compilers can improve compilation efficiency. These IRs are designed to capture the unique characteristics of spiking neural networks, such as temporal dynamics and event-driven computation. By using these specialized IRs, compilers can perform more effective optimizations and generate more efficient code for SNN execution.Expand Specific Solutions04 Energy-efficient compilation techniques
Energy efficiency is a critical concern in SNN compilation. Compilers can employ various techniques to minimize energy consumption, such as reducing the number of spike events, optimizing neuron activation thresholds, and scheduling computations to minimize power usage. These techniques help to make SNNs more suitable for deployment on energy-constrained devices.Expand Specific Solutions05 Runtime adaptation and dynamic compilation
Dynamic compilation techniques allow SNNs to adapt to changing runtime conditions. These techniques include just-in-time compilation, runtime parameter tuning, and adaptive optimization based on execution patterns. By enabling runtime adaptation, these approaches can improve the efficiency of SNN execution across different workloads and operating conditions.Expand Specific Solutions
Leading Organizations in Neuromorphic Chip Compilation
The neuromorphic computing landscape for SNNs on custom chips is evolving rapidly, currently transitioning from research to early commercialization. The market is projected to grow significantly as energy-efficient AI solutions become critical for edge computing. While still maturing, the technology has attracted major players across different sectors. Industry leaders like IBM, Intel, and Samsung are developing proprietary neuromorphic architectures, while specialized startups like Innatera and Syntiant focus on ultra-low-power edge applications. Academic institutions, particularly Zhejiang University, Fudan University, and HKU, are advancing fundamental research through collaborations with industry partners, creating a competitive ecosystem that balances innovation from specialized startups with the manufacturing capabilities of established semiconductor companies.
International Business Machines Corp.
Technical Solution: IBM's TrueNorth neuromorphic architecture features a specialized compiler framework that translates conventional neural networks into spiking neural networks (SNNs) optimized for their hardware. The compiler implements a multi-stage process including network conversion, topology mapping, and timing optimization specifically designed for event-based computation. IBM's approach includes sophisticated algorithms for neuron placement that minimize communication overhead between cores while maximizing parallelism. Their compiler technology incorporates spike timing-dependent plasticity (STDP) learning rules directly into the compilation process, enabling on-chip learning capabilities. The system achieves remarkable energy efficiency of approximately 70 milliwatts per million neurons, representing orders of magnitude improvement over traditional computing architectures. IBM's compiler framework also features advanced debugging and visualization tools that provide insights into network behavior during execution.
Strengths: Industry-leading energy efficiency with proven scalability to million-neuron implementations. Comprehensive toolchain with strong integration between hardware and software layers. Weaknesses: Proprietary ecosystem limits broader adoption and academic exploration. Requires specialized knowledge to fully utilize the architecture's capabilities.
Intel Corp.
Technical Solution: Intel's Loihi neuromorphic research chip is supported by a comprehensive compiler framework called Nengo that bridges the gap between algorithmic descriptions and neuromorphic hardware implementation. The compiler employs a hierarchical approach to mapping SNNs onto Loihi's neuromorphic cores, with sophisticated optimization techniques for spike routing and neuron allocation. Intel's compiler technology features automatic partitioning algorithms that distribute neural networks across multiple Loihi chips while minimizing inter-chip communication. The framework includes specialized support for implementing convolutional neural networks as SNNs, with optimizations for weight sharing and feature extraction. Intel's compiler achieves up to 1000x improvement in energy efficiency compared to conventional computing architectures for certain workloads, particularly in sparse, event-driven applications. The system supports both rate-coded and temporal coding schemes, providing flexibility for different application requirements.
Strengths: Robust academic and commercial ecosystem with extensive documentation and research partnerships. Scalable architecture supporting large-scale neuromorphic systems through chip interconnection. Weaknesses: Higher power consumption compared to some specialized neuromorphic solutions. Complex programming model requires significant expertise to achieve optimal performance.
Key Innovations in Neuromorphic Compilation Techniques
Brain-like chip-oriented spiking neural network compiling method and system
PatentPendingCN119692404A
Innovation
- By registering the SNN Relay operator in the TVM and establishing association with the brain-like chip operator library, the intermediate representation conversion and optimization of the SNN model described by the high-level language development framework to the brain-like chip are realized, and optimization methods such as operator fusion and data layout conversion are combined to generate and deploy file packages.
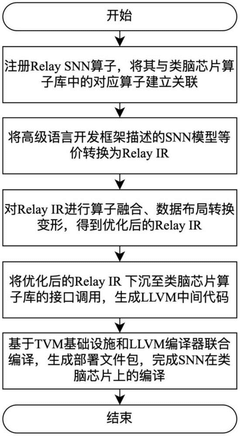
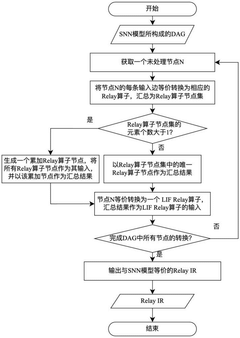
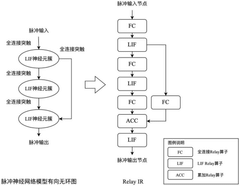
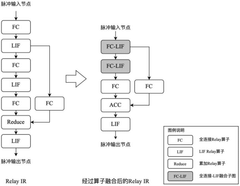
Method for neuromorphic implementation of convolutional neural networks
PatentActiveUS10387774B1
Innovation
- The system adapts CNN architecture by making output values positive, removing biases, replacing sigmoid functions with HalfRect functions, and using spatial linear subsampling instead of max-pooling, allowing the converted SNN to be implemented on neuromorphic hardware with minimal performance loss.
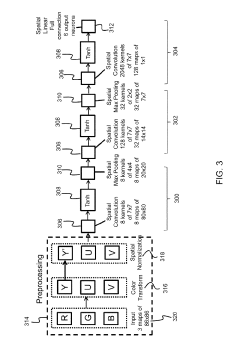
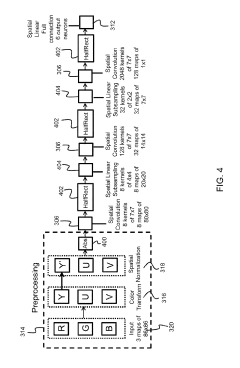
Energy Efficiency Optimization Strategies
Energy efficiency stands as a paramount concern in the design of compilers for Spiking Neural Networks (SNNs) on custom neuromorphic hardware. Traditional von Neumann architectures consume significant power during data movement between memory and processing units, whereas neuromorphic systems aim to mimic the brain's energy-efficient information processing. Current neuromorphic chips demonstrate power consumption in the milliwatt range, representing orders of magnitude improvement over conventional GPU implementations for certain SNN workloads.
Several optimization strategies have emerged to maximize energy efficiency in SNN compiler design. Spike-aware scheduling techniques prioritize computation based on neuronal activity patterns, effectively reducing unnecessary operations when neurons remain inactive. This event-driven approach capitalizes on the sparse temporal nature of spiking networks, where information is encoded in discrete spike events rather than continuous values.
Memory access optimization represents another critical strategy, with specialized memory hierarchies designed to minimize the energy cost of spike data retrieval and storage. Compiler techniques that optimize data locality and reduce off-chip memory accesses can significantly decrease power consumption. Some implementations utilize local memory buffers adjacent to processing elements, enabling efficient spike propagation without accessing energy-intensive global memory structures.
Precision adaptation mechanisms dynamically adjust computational precision based on application requirements. Unlike traditional deep learning frameworks that often use fixed-precision operations, SNN compilers can implement mixed-precision computing where different network layers or even individual neurons operate at varying levels of numerical precision. This approach allows energy to be allocated precisely where needed for maintaining accuracy while reducing overall power consumption.
Hardware-software co-design strategies enable compilers to leverage chip-specific power management features. Modern neuromorphic architectures incorporate fine-grained power gating, allowing inactive neural circuits to be temporarily powered down. Effective compilers generate code that orchestrates these power states in coordination with computational requirements, maximizing idle periods for circuit components not actively processing spikes.
Workload distribution optimization balances computation across available neuromorphic cores to prevent hotspots and enable uniform power dissipation. Advanced compilers implement thermal-aware mapping algorithms that consider both the computational demands of neural network partitions and their thermal implications, extending hardware lifespan while maintaining consistent performance under thermal constraints.
Several optimization strategies have emerged to maximize energy efficiency in SNN compiler design. Spike-aware scheduling techniques prioritize computation based on neuronal activity patterns, effectively reducing unnecessary operations when neurons remain inactive. This event-driven approach capitalizes on the sparse temporal nature of spiking networks, where information is encoded in discrete spike events rather than continuous values.
Memory access optimization represents another critical strategy, with specialized memory hierarchies designed to minimize the energy cost of spike data retrieval and storage. Compiler techniques that optimize data locality and reduce off-chip memory accesses can significantly decrease power consumption. Some implementations utilize local memory buffers adjacent to processing elements, enabling efficient spike propagation without accessing energy-intensive global memory structures.
Precision adaptation mechanisms dynamically adjust computational precision based on application requirements. Unlike traditional deep learning frameworks that often use fixed-precision operations, SNN compilers can implement mixed-precision computing where different network layers or even individual neurons operate at varying levels of numerical precision. This approach allows energy to be allocated precisely where needed for maintaining accuracy while reducing overall power consumption.
Hardware-software co-design strategies enable compilers to leverage chip-specific power management features. Modern neuromorphic architectures incorporate fine-grained power gating, allowing inactive neural circuits to be temporarily powered down. Effective compilers generate code that orchestrates these power states in coordination with computational requirements, maximizing idle periods for circuit components not actively processing spikes.
Workload distribution optimization balances computation across available neuromorphic cores to prevent hotspots and enable uniform power dissipation. Advanced compilers implement thermal-aware mapping algorithms that consider both the computational demands of neural network partitions and their thermal implications, extending hardware lifespan while maintaining consistent performance under thermal constraints.
Hardware-Software Co-design Approaches
Hardware-Software Co-design approaches for SNN compilers on neuromorphic chips represent a critical integration strategy that optimizes both hardware architecture and software frameworks simultaneously. This methodology acknowledges the intrinsic relationship between neuromorphic hardware constraints and the efficiency of SNN deployment. Traditional compiler design approaches that separate hardware and software concerns have proven inadequate for the unique computational paradigm of spiking neural networks.
The co-design process typically begins with hardware characterization, where compiler designers work closely with chip architects to understand specific neuromorphic hardware features such as neuron models, synaptic plasticity mechanisms, and on-chip memory hierarchies. This collaborative approach enables the development of hardware-aware intermediate representations (IRs) that can effectively capture both the computational semantics of SNNs and the execution capabilities of target neuromorphic platforms.
Energy efficiency optimization represents a primary objective in these co-design approaches. By analyzing the power consumption profiles of different neuromorphic operations, compiler frameworks can make informed decisions about operation scheduling, memory access patterns, and spike event handling. Some advanced co-design methodologies incorporate hardware-in-the-loop techniques, where compiler optimizations are validated against actual chip performance in real-time.
Timing constraints present another critical consideration in hardware-software co-design. Neuromorphic architectures often implement event-driven computation with strict timing requirements for spike propagation. Effective compilers must therefore incorporate timing analysis tools that can verify whether compiled SNN models will meet these temporal constraints when deployed on target hardware.
Memory management strategies constitute a significant component of co-design approaches. Neuromorphic chips typically feature heterogeneous memory architectures with different access latencies and energy profiles. Co-designed compilers leverage hardware-specific memory models to optimize data placement, minimize costly data movements, and maximize utilization of on-chip memory resources.
Feedback-driven optimization loops represent an emerging trend in hardware-software co-design for SNNs. These approaches utilize performance metrics gathered from hardware execution to refine compiler optimization strategies iteratively. Such feedback mechanisms have demonstrated significant improvements in both execution speed and energy efficiency across various neuromorphic platforms, including IBM's TrueNorth, Intel's Loihi, and SpiNNaker systems.
Standardization efforts are gradually emerging to facilitate hardware-software co-design across different neuromorphic platforms. Initiatives like PyNN and the Neuro-vector-machine (NVM) abstraction aim to provide unified programming interfaces while preserving the ability to target hardware-specific optimizations through specialized compiler backends.
The co-design process typically begins with hardware characterization, where compiler designers work closely with chip architects to understand specific neuromorphic hardware features such as neuron models, synaptic plasticity mechanisms, and on-chip memory hierarchies. This collaborative approach enables the development of hardware-aware intermediate representations (IRs) that can effectively capture both the computational semantics of SNNs and the execution capabilities of target neuromorphic platforms.
Energy efficiency optimization represents a primary objective in these co-design approaches. By analyzing the power consumption profiles of different neuromorphic operations, compiler frameworks can make informed decisions about operation scheduling, memory access patterns, and spike event handling. Some advanced co-design methodologies incorporate hardware-in-the-loop techniques, where compiler optimizations are validated against actual chip performance in real-time.
Timing constraints present another critical consideration in hardware-software co-design. Neuromorphic architectures often implement event-driven computation with strict timing requirements for spike propagation. Effective compilers must therefore incorporate timing analysis tools that can verify whether compiled SNN models will meet these temporal constraints when deployed on target hardware.
Memory management strategies constitute a significant component of co-design approaches. Neuromorphic chips typically feature heterogeneous memory architectures with different access latencies and energy profiles. Co-designed compilers leverage hardware-specific memory models to optimize data placement, minimize costly data movements, and maximize utilization of on-chip memory resources.
Feedback-driven optimization loops represent an emerging trend in hardware-software co-design for SNNs. These approaches utilize performance metrics gathered from hardware execution to refine compiler optimization strategies iteratively. Such feedback mechanisms have demonstrated significant improvements in both execution speed and energy efficiency across various neuromorphic platforms, including IBM's TrueNorth, Intel's Loihi, and SpiNNaker systems.
Standardization efforts are gradually emerging to facilitate hardware-software co-design across different neuromorphic platforms. Initiatives like PyNN and the Neuro-vector-machine (NVM) abstraction aim to provide unified programming interfaces while preserving the ability to target hardware-specific optimizations through specialized compiler backends.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!