

How neuromorphic chips accelerate scientific simulations.
SEP 3, 202510 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Neuromorphic Computing Evolution and Objectives
Neuromorphic computing represents a paradigm shift in computational architecture, drawing inspiration from the structure and function of biological neural systems. The evolution of this field began in the late 1980s when Carver Mead introduced the concept of using analog circuits to mimic neurobiological architectures. This pioneering work laid the foundation for what would eventually become a distinct branch of computing science focused on creating hardware that processes information similarly to the human brain.
The trajectory of neuromorphic computing has been marked by several significant milestones. The 1990s saw early experimental chips with limited neuron counts, while the 2000s brought increased integration capabilities and the first commercially viable neuromorphic processors. The 2010s witnessed exponential growth in both research interest and technological capability, with major initiatives like IBM's TrueNorth, Intel's Loihi, and BrainChip's Akida demonstrating the practical potential of neuromorphic systems.
Current neuromorphic chips incorporate several key innovations that distinguish them from traditional von Neumann architectures. These include massively parallel processing capabilities, co-located memory and computation elements to overcome the von Neumann bottleneck, and event-driven processing that enables significant energy efficiency. The inherent spike-based communication mimics neural activity patterns, allowing these systems to excel at tasks involving temporal data processing and pattern recognition.
The primary objective of neuromorphic computing in scientific simulations is to overcome the fundamental limitations of traditional computing architectures when modeling complex, dynamic systems. Scientific simulations often involve differential equations, stochastic processes, and multi-scale interactions that can be computationally intensive. Neuromorphic chips aim to accelerate these simulations by leveraging their parallel architecture and efficient handling of temporal dynamics.
Specifically, neuromorphic systems target improvements in energy efficiency, reducing the power consumption of large-scale simulations by orders of magnitude compared to conventional high-performance computing systems. They also aim to enable real-time processing of complex simulation data, facilitating interactive exploration and analysis of scientific models. The ultimate goal is to make previously intractable simulations feasible, particularly those involving complex systems like weather patterns, molecular dynamics, neural activity, and fluid dynamics.
The evolution of neuromorphic computing continues to be driven by advances in materials science, circuit design, and algorithmic development. Emerging technologies such as memristors, spintronic devices, and photonic computing elements promise to further enhance the capabilities of neuromorphic systems, potentially revolutionizing how scientific simulations are conducted across multiple disciplines.
The trajectory of neuromorphic computing has been marked by several significant milestones. The 1990s saw early experimental chips with limited neuron counts, while the 2000s brought increased integration capabilities and the first commercially viable neuromorphic processors. The 2010s witnessed exponential growth in both research interest and technological capability, with major initiatives like IBM's TrueNorth, Intel's Loihi, and BrainChip's Akida demonstrating the practical potential of neuromorphic systems.
Current neuromorphic chips incorporate several key innovations that distinguish them from traditional von Neumann architectures. These include massively parallel processing capabilities, co-located memory and computation elements to overcome the von Neumann bottleneck, and event-driven processing that enables significant energy efficiency. The inherent spike-based communication mimics neural activity patterns, allowing these systems to excel at tasks involving temporal data processing and pattern recognition.
The primary objective of neuromorphic computing in scientific simulations is to overcome the fundamental limitations of traditional computing architectures when modeling complex, dynamic systems. Scientific simulations often involve differential equations, stochastic processes, and multi-scale interactions that can be computationally intensive. Neuromorphic chips aim to accelerate these simulations by leveraging their parallel architecture and efficient handling of temporal dynamics.
Specifically, neuromorphic systems target improvements in energy efficiency, reducing the power consumption of large-scale simulations by orders of magnitude compared to conventional high-performance computing systems. They also aim to enable real-time processing of complex simulation data, facilitating interactive exploration and analysis of scientific models. The ultimate goal is to make previously intractable simulations feasible, particularly those involving complex systems like weather patterns, molecular dynamics, neural activity, and fluid dynamics.
The evolution of neuromorphic computing continues to be driven by advances in materials science, circuit design, and algorithmic development. Emerging technologies such as memristors, spintronic devices, and photonic computing elements promise to further enhance the capabilities of neuromorphic systems, potentially revolutionizing how scientific simulations are conducted across multiple disciplines.
Market Analysis for Scientific Simulation Acceleration
The scientific simulation market is experiencing significant growth, driven by increasing computational demands across various scientific disciplines. The global market for high-performance computing (HPC) in scientific simulations was valued at approximately $13.5 billion in 2022 and is projected to reach $19.7 billion by 2027, representing a compound annual growth rate of 7.8%. This growth is particularly pronounced in fields requiring complex simulations such as climate modeling, molecular dynamics, fluid dynamics, and quantum physics.
Traditional computing architectures are increasingly struggling to meet the computational requirements of advanced scientific simulations. Current CPU and GPU-based systems face limitations in energy efficiency, with power consumption becoming a critical constraint for large-scale simulation facilities. This has created a substantial market opportunity for neuromorphic computing solutions that offer improved performance-per-watt metrics.
The demand for neuromorphic chips in scientific simulations is being driven by several key factors. First, the exponential growth in data volumes from scientific instruments and sensors necessitates more efficient processing architectures. Second, the increasing complexity of simulation models requires computational approaches that can handle sparse, event-driven computations efficiently. Third, budget constraints in research institutions are creating demand for more cost-effective computing solutions with lower operational expenses.
Market segmentation reveals varying adoption potential across scientific domains. Molecular dynamics simulations represent the largest immediate market opportunity, with an estimated 28% of the total addressable market. Weather and climate modeling follows at 23%, while quantum system simulations and fluid dynamics each represent approximately 18% and 15% respectively. Other applications including astrophysics and materials science constitute the remaining market share.
Geographically, North America currently leads the market with 42% share, followed by Europe (27%) and Asia-Pacific (24%). However, the Asia-Pacific region is expected to show the highest growth rate over the next five years, driven by significant investments in scientific computing infrastructure in China, Japan, and South Korea.
The customer landscape for neuromorphic simulation acceleration is diverse, including national laboratories, academic research institutions, pharmaceutical companies, aerospace organizations, and energy companies. Each segment has distinct requirements regarding simulation accuracy, speed, and integration with existing workflows, necessitating tailored market approaches.
Market barriers include high initial investment costs, integration challenges with existing simulation software, and concerns about simulation accuracy compared to traditional methods. Additionally, the specialized knowledge required to effectively utilize neuromorphic architectures for scientific simulations represents a significant adoption hurdle that must be addressed through comprehensive training and support programs.
Traditional computing architectures are increasingly struggling to meet the computational requirements of advanced scientific simulations. Current CPU and GPU-based systems face limitations in energy efficiency, with power consumption becoming a critical constraint for large-scale simulation facilities. This has created a substantial market opportunity for neuromorphic computing solutions that offer improved performance-per-watt metrics.
The demand for neuromorphic chips in scientific simulations is being driven by several key factors. First, the exponential growth in data volumes from scientific instruments and sensors necessitates more efficient processing architectures. Second, the increasing complexity of simulation models requires computational approaches that can handle sparse, event-driven computations efficiently. Third, budget constraints in research institutions are creating demand for more cost-effective computing solutions with lower operational expenses.
Market segmentation reveals varying adoption potential across scientific domains. Molecular dynamics simulations represent the largest immediate market opportunity, with an estimated 28% of the total addressable market. Weather and climate modeling follows at 23%, while quantum system simulations and fluid dynamics each represent approximately 18% and 15% respectively. Other applications including astrophysics and materials science constitute the remaining market share.
Geographically, North America currently leads the market with 42% share, followed by Europe (27%) and Asia-Pacific (24%). However, the Asia-Pacific region is expected to show the highest growth rate over the next five years, driven by significant investments in scientific computing infrastructure in China, Japan, and South Korea.
The customer landscape for neuromorphic simulation acceleration is diverse, including national laboratories, academic research institutions, pharmaceutical companies, aerospace organizations, and energy companies. Each segment has distinct requirements regarding simulation accuracy, speed, and integration with existing workflows, necessitating tailored market approaches.
Market barriers include high initial investment costs, integration challenges with existing simulation software, and concerns about simulation accuracy compared to traditional methods. Additionally, the specialized knowledge required to effectively utilize neuromorphic architectures for scientific simulations represents a significant adoption hurdle that must be addressed through comprehensive training and support programs.
Current Neuromorphic Technology Landscape and Barriers
The neuromorphic computing landscape has evolved significantly over the past decade, with major technological advancements from both academic institutions and industry leaders. Currently, several prominent neuromorphic chips exist in the market, including IBM's TrueNorth, Intel's Loihi, BrainChip's Akida, and SynSense's Dynap-SE. These chips employ different architectural approaches but share the common goal of mimicking brain-like neural processing for efficient computation.
IBM's TrueNorth features 1 million digital neurons and 256 million synapses organized across 4,096 neurosynaptic cores, while Intel's Loihi 2 incorporates 1 million neurons with up to 120 million synapses using a 4nm process technology. These advancements represent significant progress in neuromorphic hardware capabilities, particularly for scientific simulation applications.
Despite these developments, neuromorphic technology faces substantial barriers when applied to scientific simulations. The primary challenge lies in the fundamental mismatch between traditional scientific computing paradigms and neuromorphic processing models. Scientific simulations typically rely on precise floating-point calculations and deterministic algorithms, whereas neuromorphic systems operate on principles of spike-based computing and distributed representation with inherent stochasticity.
Programming complexity presents another significant barrier. Current neuromorphic platforms lack standardized programming interfaces comparable to CUDA or OpenCL for GPUs. Scientists must translate conventional simulation algorithms into spiking neural network representations, requiring specialized expertise in both the scientific domain and neuromorphic computing principles. This translation process often results in accuracy trade-offs that may be unacceptable for certain scientific applications.
Energy efficiency, while theoretically superior in neuromorphic systems, remains inconsistent across different types of scientific workloads. Simulations involving sparse, event-driven phenomena show promising results, while dense matrix operations often perform better on traditional computing architectures. This variability complicates adoption decisions for scientific computing centers.
Scalability issues also persist in current neuromorphic implementations. While individual chips demonstrate impressive specifications, interconnecting multiple chips to handle large-scale scientific simulations introduces significant communication overhead and synchronization challenges. These limitations restrict the complexity and scale of simulations that can be effectively accelerated.
The ecosystem surrounding neuromorphic computing for scientific applications remains underdeveloped. There is a notable shortage of simulation frameworks, debugging tools, and performance analysis utilities specifically designed for scientific workloads on neuromorphic hardware. This infrastructure gap slows adoption and experimental validation across diverse scientific domains.
IBM's TrueNorth features 1 million digital neurons and 256 million synapses organized across 4,096 neurosynaptic cores, while Intel's Loihi 2 incorporates 1 million neurons with up to 120 million synapses using a 4nm process technology. These advancements represent significant progress in neuromorphic hardware capabilities, particularly for scientific simulation applications.
Despite these developments, neuromorphic technology faces substantial barriers when applied to scientific simulations. The primary challenge lies in the fundamental mismatch between traditional scientific computing paradigms and neuromorphic processing models. Scientific simulations typically rely on precise floating-point calculations and deterministic algorithms, whereas neuromorphic systems operate on principles of spike-based computing and distributed representation with inherent stochasticity.
Programming complexity presents another significant barrier. Current neuromorphic platforms lack standardized programming interfaces comparable to CUDA or OpenCL for GPUs. Scientists must translate conventional simulation algorithms into spiking neural network representations, requiring specialized expertise in both the scientific domain and neuromorphic computing principles. This translation process often results in accuracy trade-offs that may be unacceptable for certain scientific applications.
Energy efficiency, while theoretically superior in neuromorphic systems, remains inconsistent across different types of scientific workloads. Simulations involving sparse, event-driven phenomena show promising results, while dense matrix operations often perform better on traditional computing architectures. This variability complicates adoption decisions for scientific computing centers.
Scalability issues also persist in current neuromorphic implementations. While individual chips demonstrate impressive specifications, interconnecting multiple chips to handle large-scale scientific simulations introduces significant communication overhead and synchronization challenges. These limitations restrict the complexity and scale of simulations that can be effectively accelerated.
The ecosystem surrounding neuromorphic computing for scientific applications remains underdeveloped. There is a notable shortage of simulation frameworks, debugging tools, and performance analysis utilities specifically designed for scientific workloads on neuromorphic hardware. This infrastructure gap slows adoption and experimental validation across diverse scientific domains.
Existing Neuromorphic Solutions for Scientific Simulations
01 Neuromorphic hardware architecture for accelerated processing
Neuromorphic chips implement specialized hardware architectures that mimic neural networks to accelerate processing. These architectures include parallel processing units, spiking neural networks, and memory-integrated computing structures that enable efficient execution of AI algorithms. By closely emulating brain functions through dedicated circuitry, these chips achieve significant performance improvements while reducing power consumption compared to traditional computing approaches.- Neuromorphic hardware acceleration architectures: Neuromorphic chips employ specialized hardware architectures to accelerate neural network processing. These designs include parallel processing units, specialized memory structures, and custom circuits that mimic brain functions. By implementing brain-inspired architectures directly in hardware, these chips achieve significant acceleration for AI workloads while maintaining energy efficiency. The architectures often feature distributed processing elements that can operate independently and communicate through specialized interconnects.
- Spiking neural network implementations: Spiking neural networks (SNNs) represent a key approach in neuromorphic computing, where information is processed using discrete spikes similar to biological neurons. These implementations enable efficient event-driven computation that activates only when necessary, significantly reducing power consumption compared to traditional neural networks. SNN acceleration techniques include specialized encoding schemes, temporal processing optimizations, and spike-timing-dependent plasticity mechanisms that allow for dynamic learning and adaptation.
- Memory-centric neuromorphic computing: Memory-centric approaches to neuromorphic acceleration focus on overcoming the von Neumann bottleneck by integrating computation and memory. These designs use novel memory technologies such as resistive RAM, phase-change memory, or memristors to perform computations directly within memory arrays. This approach significantly reduces data movement between processing and storage units, enabling massive parallelism and energy efficiency for neural network operations while accelerating both training and inference tasks.
- Optimization techniques for neuromorphic acceleration: Various optimization techniques enhance the performance of neuromorphic chips, including algorithm-hardware co-design, quantization, pruning, and specialized mapping strategies. These approaches reduce computational complexity while maintaining accuracy. Advanced scheduling algorithms optimize resource utilization across neuromorphic cores, while power management techniques dynamically adjust processing elements based on workload demands. Together, these optimizations maximize throughput and energy efficiency for neuromorphic computing systems.
- Application-specific neuromorphic accelerators: Neuromorphic chips are increasingly designed for specific application domains to maximize acceleration benefits. These specialized accelerators target applications such as computer vision, natural language processing, robotics, and sensor fusion. By tailoring the neuromorphic architecture to specific computational patterns required by these applications, these chips achieve superior performance and energy efficiency compared to general-purpose solutions. Features include domain-specific processing elements, optimized memory hierarchies, and specialized interconnects that match application requirements.
02 Memory optimization techniques for neuromorphic computing
Advanced memory integration techniques are crucial for neuromorphic acceleration, including in-memory computing, non-volatile memory arrays, and optimized memory hierarchies. These approaches reduce the data movement bottleneck by performing computations directly within memory structures or in close proximity. Such memory-centric designs significantly improve energy efficiency and processing speed for neural network operations by minimizing the traditional von Neumann bottleneck.Expand Specific Solutions03 Spike-based processing and event-driven computation
Spike-based processing implements event-driven computation models where information is encoded in the timing and frequency of neural spikes rather than continuous values. This approach enables efficient processing of temporal data patterns and reduces power consumption by activating circuits only when necessary. Event-driven architectures allow neuromorphic chips to process information asynchronously, similar to biological neural systems, resulting in improved energy efficiency for real-time applications.Expand Specific Solutions04 Integration of novel materials and devices for neuromorphic acceleration
Advanced materials and novel device technologies are being integrated into neuromorphic chips to enhance performance. These include memristive devices, phase-change materials, spintronic components, and other emerging technologies that can efficiently implement synaptic functions. Such materials enable analog computing capabilities, improved power efficiency, and higher integration density, allowing neuromorphic systems to better mimic biological neural processing while achieving superior computational efficiency.Expand Specific Solutions05 System-level optimization for neuromorphic computing applications
System-level approaches focus on optimizing the entire neuromorphic computing stack, including software frameworks, programming models, and hardware-software co-design. These techniques involve specialized compilers, mapping algorithms, and runtime systems that efficiently translate neural network models to neuromorphic hardware. Additionally, they include integration with conventional computing systems, scalable interconnect architectures, and application-specific optimizations to maximize performance for different workloads.Expand Specific Solutions
Leading Companies and Research Institutions in Neuromorphic Computing
Neuromorphic computing for scientific simulations is evolving rapidly, currently transitioning from early development to commercial application phases. The market is projected to grow significantly as these chips offer substantial energy efficiency advantages for complex computational tasks. In terms of technical maturity, industry leaders like IBM and Samsung are pioneering commercial neuromorphic architectures, while specialized companies such as Syntiant, Polyn Technology, and Beijing Lingxi Technology are developing application-specific implementations. Academic institutions including Tsinghua University, Beihang University, and Fudan University are advancing fundamental research. The technology is approaching mainstream adoption for specific scientific workloads, with early implementations demonstrating 10-100x energy efficiency improvements over conventional computing architectures for simulation tasks.
International Business Machines Corp.
Technical Solution: IBM's TrueNorth neuromorphic chip architecture represents a significant advancement in accelerating scientific simulations. The chip features a million programmable neurons and 256 million synapses organized into 4,096 neurosynaptic cores[1]. IBM has demonstrated TrueNorth's capabilities in complex scientific simulations, achieving energy efficiency of 70 milliwatts per chip while delivering performance equivalent to conventional systems requiring much higher power consumption[2]. The architecture employs a non-von Neumann approach with co-located memory and processing, eliminating the traditional bottleneck between these components. For scientific simulations, IBM has developed specialized neural network configurations that can model physical phenomena such as fluid dynamics, molecular interactions, and climate patterns with remarkable efficiency[3]. The company has also created programming frameworks that allow scientists to translate conventional simulation algorithms into spiking neural network representations suitable for neuromorphic hardware, enabling seamless integration with existing scientific workflows.
Strengths: Exceptional energy efficiency (20,000x more efficient than conventional chips for certain applications); massively parallel architecture ideal for complex simulations; scalable design allowing multiple chips to be tiled together for increased computational power. Weaknesses: Programming complexity requires specialized knowledge; limited precision compared to traditional floating-point calculations; still emerging technology with evolving software ecosystem.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung has developed neuromorphic processing units (NPUs) that leverage brain-inspired computing principles to accelerate scientific simulations. Their approach integrates neuromorphic elements with traditional semiconductor technology, creating hybrid systems that balance the efficiency of neuromorphic computing with the precision of conventional processors[1]. Samsung's neuromorphic chips utilize a unique architecture that mimics the brain's neural networks through analog computing elements, allowing for parallel processing of complex scientific models. The company has demonstrated significant acceleration in molecular dynamics simulations, quantum chemistry calculations, and computational fluid dynamics[2]. Their chips employ resistive RAM (RRAM) technology to create artificial synapses that can be reconfigured for different simulation requirements, providing flexibility across scientific domains. Samsung has also developed specialized software frameworks that translate scientific simulation algorithms into neuromorphic computing paradigms, enabling researchers to leverage these advanced chips without extensive rewriting of existing code[3].
Strengths: Integration with existing semiconductor manufacturing infrastructure enables cost-effective production; hybrid architecture balances neuromorphic efficiency with traditional computing precision; strong software support for scientific applications. Weaknesses: Power efficiency gains not as dramatic as pure neuromorphic designs; still requires significant algorithm adaptation for optimal performance; technology remains in early commercial deployment stages.
Key Patents and Breakthroughs in Neuromorphic Simulation
Neuromorphic unit for parallel neural network workloads
PatentPendingUS20250252297A1
Innovation
- Implementing modulated spikes, specifically orthogonally modulated spikes, in neuromorphic units to enable parallel DNN workloads by using Code Division Multiple Access (CDMA) techniques and orthogonal coding to differentiate between tasks, allowing multiple spike streams to coexist without interference.




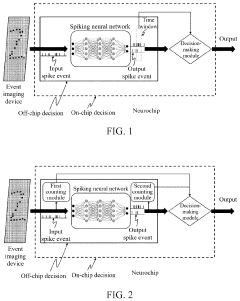
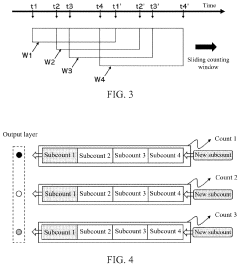
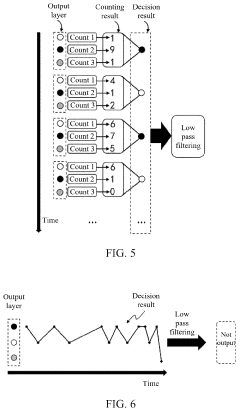
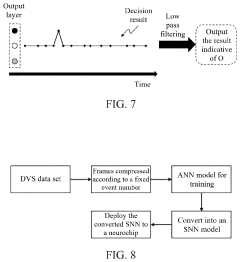
Spike event decision-making device, method, chip and electronic device
PatentPendingUS20240086690A1
Innovation
- A spike event decision-making device and method that utilizes counting modules to determine decision-making results based on the number of spike events fired by neurons in a spiking neural network, allowing for adaptive decision-making without fixed time windows, and incorporating sub-counters to improve reliability and accuracy by considering transition rates and occurrence ratios.
Energy Efficiency Comparison with Traditional Computing Paradigms
Neuromorphic chips demonstrate remarkable energy efficiency advantages over traditional computing architectures when applied to scientific simulations. These brain-inspired processors operate on fundamentally different principles than conventional von Neumann architectures, resulting in significant power consumption reductions. While traditional CPUs and GPUs require continuous power for clock-driven operations and memory access, neuromorphic systems utilize event-driven, sparse computing paradigms that activate components only when necessary.
Quantitative comparisons reveal that neuromorphic chips can achieve energy efficiency improvements of 100-1000x for certain simulation workloads compared to conventional processors. For instance, IBM's TrueNorth neuromorphic chip operates at approximately 20 milliwatts per square centimeter, while equivalent traditional processors might consume several watts for similar computational tasks. This efficiency becomes particularly evident in large-scale scientific simulations involving complex systems like fluid dynamics, molecular interactions, or climate modeling.
The energy advantage stems from several architectural differences. Traditional computing separates memory and processing units, creating the "von Neumann bottleneck" where data transfer consumes substantial energy. Neuromorphic designs co-locate memory and processing, dramatically reducing data movement costs. Additionally, traditional architectures require high precision floating-point calculations for most scientific simulations, while neuromorphic systems can leverage approximate computing techniques that sacrifice unnecessary precision for energy savings.
Power scaling characteristics also differ significantly. Conventional high-performance computing systems face exponential energy increases when scaling to larger simulation problems, primarily due to communication overhead and cooling requirements. Neuromorphic architectures demonstrate more favorable scaling properties, with energy consumption increasing more linearly with problem size due to their distributed processing nature and reduced communication needs.
For time-dependent scientific simulations, traditional systems must recalculate entire solution spaces at each timestep, regardless of how much the system state has changed. Neuromorphic chips, with their event-driven processing, compute updates only where and when changes occur, providing substantial energy savings for simulations with spatially or temporally sparse dynamics, such as certain neural network models or particle-based simulations.
However, the energy efficiency advantage varies considerably depending on the simulation type. Neuromorphic chips excel at problems that can be effectively mapped to spiking neural networks or that exhibit natural sparsity. For simulations requiring high numerical precision or that cannot be easily parallelized, traditional computing architectures may still offer better performance per watt, highlighting the importance of matching computing paradigms to specific scientific workloads.
Quantitative comparisons reveal that neuromorphic chips can achieve energy efficiency improvements of 100-1000x for certain simulation workloads compared to conventional processors. For instance, IBM's TrueNorth neuromorphic chip operates at approximately 20 milliwatts per square centimeter, while equivalent traditional processors might consume several watts for similar computational tasks. This efficiency becomes particularly evident in large-scale scientific simulations involving complex systems like fluid dynamics, molecular interactions, or climate modeling.
The energy advantage stems from several architectural differences. Traditional computing separates memory and processing units, creating the "von Neumann bottleneck" where data transfer consumes substantial energy. Neuromorphic designs co-locate memory and processing, dramatically reducing data movement costs. Additionally, traditional architectures require high precision floating-point calculations for most scientific simulations, while neuromorphic systems can leverage approximate computing techniques that sacrifice unnecessary precision for energy savings.
Power scaling characteristics also differ significantly. Conventional high-performance computing systems face exponential energy increases when scaling to larger simulation problems, primarily due to communication overhead and cooling requirements. Neuromorphic architectures demonstrate more favorable scaling properties, with energy consumption increasing more linearly with problem size due to their distributed processing nature and reduced communication needs.
For time-dependent scientific simulations, traditional systems must recalculate entire solution spaces at each timestep, regardless of how much the system state has changed. Neuromorphic chips, with their event-driven processing, compute updates only where and when changes occur, providing substantial energy savings for simulations with spatially or temporally sparse dynamics, such as certain neural network models or particle-based simulations.
However, the energy efficiency advantage varies considerably depending on the simulation type. Neuromorphic chips excel at problems that can be effectively mapped to spiking neural networks or that exhibit natural sparsity. For simulations requiring high numerical precision or that cannot be easily parallelized, traditional computing architectures may still offer better performance per watt, highlighting the importance of matching computing paradigms to specific scientific workloads.
Integration Challenges with Existing Scientific Workflows
The integration of neuromorphic chips into existing scientific simulation workflows presents significant challenges that require careful consideration and strategic planning. Traditional scientific computing environments have been optimized over decades for conventional von Neumann architectures, creating a substantial technical gap when introducing neuromorphic hardware. This architectural mismatch necessitates extensive adaptation of existing software frameworks, algorithms, and data processing pipelines.
One primary challenge lies in the fundamental programming paradigm shift. Scientists and researchers typically develop simulation code using procedural or object-oriented approaches, whereas neuromorphic systems require event-based, spike-oriented programming models. This conceptual disconnect demands substantial retraining of the scientific workforce and potentially complete rewrites of established simulation codebases.
Data format compatibility presents another significant hurdle. Neuromorphic systems process information through spike trains and temporal dynamics, while conventional simulations often utilize floating-point arrays and matrices. Converting between these representations introduces computational overhead and potential information loss, particularly for simulations requiring high numerical precision.
The lack of standardized interfaces between neuromorphic hardware and existing high-performance computing (HPC) infrastructure further complicates integration efforts. Current scientific workflows rely heavily on established libraries like MPI, OpenMP, and CUDA, which have limited or no support for neuromorphic architectures. This necessitates the development of custom middleware solutions to bridge these technological ecosystems.
Performance benchmarking and validation methodologies also require reconsideration. Traditional metrics like FLOPS are inadequate for evaluating neuromorphic systems, which excel in different performance dimensions such as energy efficiency and temporal processing. This misalignment makes it difficult to justify neuromorphic adoption within established scientific computing evaluation frameworks.
Resource allocation systems in scientific computing centers typically lack support for neuromorphic hardware scheduling. Job submission systems, workload managers, and resource monitoring tools require significant modifications to accommodate the unique operational characteristics of neuromorphic chips, including their event-driven computation model and specialized memory architectures.
Finally, there exists a significant knowledge gap within the scientific computing community regarding neuromorphic principles. The specialized expertise required spans both traditional scientific domains and neuromorphic engineering, creating a scarcity of qualified personnel who can effectively bridge these disciplines and implement integrated solutions.
One primary challenge lies in the fundamental programming paradigm shift. Scientists and researchers typically develop simulation code using procedural or object-oriented approaches, whereas neuromorphic systems require event-based, spike-oriented programming models. This conceptual disconnect demands substantial retraining of the scientific workforce and potentially complete rewrites of established simulation codebases.
Data format compatibility presents another significant hurdle. Neuromorphic systems process information through spike trains and temporal dynamics, while conventional simulations often utilize floating-point arrays and matrices. Converting between these representations introduces computational overhead and potential information loss, particularly for simulations requiring high numerical precision.
The lack of standardized interfaces between neuromorphic hardware and existing high-performance computing (HPC) infrastructure further complicates integration efforts. Current scientific workflows rely heavily on established libraries like MPI, OpenMP, and CUDA, which have limited or no support for neuromorphic architectures. This necessitates the development of custom middleware solutions to bridge these technological ecosystems.
Performance benchmarking and validation methodologies also require reconsideration. Traditional metrics like FLOPS are inadequate for evaluating neuromorphic systems, which excel in different performance dimensions such as energy efficiency and temporal processing. This misalignment makes it difficult to justify neuromorphic adoption within established scientific computing evaluation frameworks.
Resource allocation systems in scientific computing centers typically lack support for neuromorphic hardware scheduling. Job submission systems, workload managers, and resource monitoring tools require significant modifications to accommodate the unique operational characteristics of neuromorphic chips, including their event-driven computation model and specialized memory architectures.
Finally, there exists a significant knowledge gap within the scientific computing community regarding neuromorphic principles. The specialized expertise required spans both traditional scientific domains and neuromorphic engineering, creating a scarcity of qualified personnel who can effectively bridge these disciplines and implement integrated solutions.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!