

How to Optimize RRAM Influence on Machine Learning Rates
SEP 10, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
RRAM Technology Evolution and Optimization Goals
Resistive Random Access Memory (RRAM) has evolved significantly since its conceptualization in the early 2000s. Initially developed as a non-volatile memory solution, RRAM has progressed through several technological generations, each addressing specific limitations of previous iterations. The first generation focused primarily on basic switching mechanisms and material exploration, while subsequent generations have increasingly emphasized reliability, endurance, and integration capabilities with conventional CMOS technology.
The evolution of RRAM technology has been marked by significant breakthroughs in material science. Early implementations relied heavily on binary metal oxides such as HfO2 and TiO2, which demonstrated the fundamental resistive switching behavior but suffered from variability issues. Recent advancements have explored complex oxides, 2D materials, and various dopants to enhance performance metrics, particularly targeting the stability of resistance states and reduction of forming voltage requirements.
From an architectural perspective, RRAM has transitioned from simple crossbar arrays to sophisticated 3D stacking configurations, enabling higher density and improved energy efficiency. This architectural evolution has been crucial in positioning RRAM as a viable technology for neuromorphic computing applications, where high density and low power consumption are paramount considerations.
The optimization goals for RRAM in machine learning applications are multifaceted. Primary objectives include reducing cycle-to-cycle and device-to-device variability, which directly impacts the precision and reliability of neural network implementations. Enhancing the dynamic range of resistance states is another critical goal, as it determines the number of distinct weight values that can be represented in a neural network, directly influencing model accuracy.
Energy efficiency represents another key optimization target. Current research aims to minimize the energy required for programming operations while maintaining reliable state changes, a balance that is essential for large-scale deployment in energy-constrained environments such as edge computing devices and IoT applications.
Speed optimization constitutes a significant focus area, particularly in accelerating the training phase of machine learning models. This involves not only improving the switching speed of individual RRAM cells but also developing efficient programming algorithms and peripheral circuitry that can exploit the inherent parallelism of RRAM arrays.
Scalability and manufacturing compatibility remain ongoing challenges. The industry is actively pursuing fabrication techniques that allow for smaller feature sizes while maintaining performance characteristics, with particular emphasis on compatibility with standard semiconductor manufacturing processes to facilitate widespread adoption and cost-effective production.
The evolution of RRAM technology has been marked by significant breakthroughs in material science. Early implementations relied heavily on binary metal oxides such as HfO2 and TiO2, which demonstrated the fundamental resistive switching behavior but suffered from variability issues. Recent advancements have explored complex oxides, 2D materials, and various dopants to enhance performance metrics, particularly targeting the stability of resistance states and reduction of forming voltage requirements.
From an architectural perspective, RRAM has transitioned from simple crossbar arrays to sophisticated 3D stacking configurations, enabling higher density and improved energy efficiency. This architectural evolution has been crucial in positioning RRAM as a viable technology for neuromorphic computing applications, where high density and low power consumption are paramount considerations.
The optimization goals for RRAM in machine learning applications are multifaceted. Primary objectives include reducing cycle-to-cycle and device-to-device variability, which directly impacts the precision and reliability of neural network implementations. Enhancing the dynamic range of resistance states is another critical goal, as it determines the number of distinct weight values that can be represented in a neural network, directly influencing model accuracy.
Energy efficiency represents another key optimization target. Current research aims to minimize the energy required for programming operations while maintaining reliable state changes, a balance that is essential for large-scale deployment in energy-constrained environments such as edge computing devices and IoT applications.
Speed optimization constitutes a significant focus area, particularly in accelerating the training phase of machine learning models. This involves not only improving the switching speed of individual RRAM cells but also developing efficient programming algorithms and peripheral circuitry that can exploit the inherent parallelism of RRAM arrays.
Scalability and manufacturing compatibility remain ongoing challenges. The industry is actively pursuing fabrication techniques that allow for smaller feature sizes while maintaining performance characteristics, with particular emphasis on compatibility with standard semiconductor manufacturing processes to facilitate widespread adoption and cost-effective production.
Market Analysis for RRAM in ML Applications
The RRAM (Resistive Random-Access Memory) market within machine learning applications is experiencing significant growth, driven by the increasing demand for efficient, high-performance computing solutions for AI workloads. Current market valuations place the global RRAM sector at approximately $1.2 billion, with projections indicating a compound annual growth rate of 16% through 2028, specifically for ML applications.
The market demand for RRAM in machine learning is primarily fueled by the limitations of conventional computing architectures when handling complex neural networks. Traditional von Neumann architectures create bottlenecks due to the separation between processing and memory units, resulting in substantial energy consumption and latency issues. RRAM offers a compelling solution through in-memory computing capabilities, potentially reducing energy requirements by up to 90% for certain ML operations.
Industry analysis reveals three primary market segments for RRAM in machine learning: edge computing devices, data center accelerators, and autonomous systems. Edge computing represents the fastest-growing segment with 22% annual growth, as manufacturers seek to implement ML capabilities in resource-constrained environments. The data center segment, while growing more modestly at 14%, represents the largest market share by revenue.
Geographically, North America leads RRAM adoption in ML applications with 42% market share, followed by Asia-Pacific at 38%, which is demonstrating the fastest growth trajectory. Europe accounts for 16% of the market, with particular strength in automotive and industrial applications of RRAM-based ML systems.
Customer segmentation shows that technology companies constitute 48% of RRAM-ML market demand, followed by automotive (18%), healthcare (14%), and industrial automation (12%). The remaining 8% is distributed across various smaller application domains. This distribution highlights the technology's broad applicability across multiple industries.
Market challenges include competition from alternative emerging memory technologies such as MRAM and PCM, which are also targeting ML acceleration applications. Additionally, the relatively higher cost of RRAM implementation compared to conventional DRAM solutions presents adoption barriers, particularly for price-sensitive applications.
Opportunity analysis indicates that the integration of RRAM with specialized ML processors could create a market subsegment worth $300 million by 2025. Furthermore, the development of standardized RRAM-based ML acceleration modules could significantly expand market penetration in mid-tier applications where cost-performance balance is critical.
The market demand for RRAM in machine learning is primarily fueled by the limitations of conventional computing architectures when handling complex neural networks. Traditional von Neumann architectures create bottlenecks due to the separation between processing and memory units, resulting in substantial energy consumption and latency issues. RRAM offers a compelling solution through in-memory computing capabilities, potentially reducing energy requirements by up to 90% for certain ML operations.
Industry analysis reveals three primary market segments for RRAM in machine learning: edge computing devices, data center accelerators, and autonomous systems. Edge computing represents the fastest-growing segment with 22% annual growth, as manufacturers seek to implement ML capabilities in resource-constrained environments. The data center segment, while growing more modestly at 14%, represents the largest market share by revenue.
Geographically, North America leads RRAM adoption in ML applications with 42% market share, followed by Asia-Pacific at 38%, which is demonstrating the fastest growth trajectory. Europe accounts for 16% of the market, with particular strength in automotive and industrial applications of RRAM-based ML systems.
Customer segmentation shows that technology companies constitute 48% of RRAM-ML market demand, followed by automotive (18%), healthcare (14%), and industrial automation (12%). The remaining 8% is distributed across various smaller application domains. This distribution highlights the technology's broad applicability across multiple industries.
Market challenges include competition from alternative emerging memory technologies such as MRAM and PCM, which are also targeting ML acceleration applications. Additionally, the relatively higher cost of RRAM implementation compared to conventional DRAM solutions presents adoption barriers, particularly for price-sensitive applications.
Opportunity analysis indicates that the integration of RRAM with specialized ML processors could create a market subsegment worth $300 million by 2025. Furthermore, the development of standardized RRAM-based ML acceleration modules could significantly expand market penetration in mid-tier applications where cost-performance balance is critical.
Current RRAM Limitations and Technical Challenges
Despite the promising potential of Resistive Random Access Memory (RRAM) in accelerating machine learning applications, several significant technical limitations currently impede its widespread adoption and optimal performance. The non-linear and stochastic switching behavior of RRAM devices presents a fundamental challenge, as it introduces unpredictability in the resistance states, directly affecting the precision and reliability of machine learning computations. This variability manifests as cycle-to-cycle and device-to-device variations, making consistent performance across large arrays difficult to achieve.
Endurance limitations represent another critical challenge, with many RRAM devices exhibiting degradation after 10^6 to 10^9 switching cycles. While this may be sufficient for conventional memory applications, machine learning workloads—particularly during training phases—require significantly more read/write operations, potentially leading to premature device failure and accuracy degradation over time.
The retention characteristics of RRAM cells pose additional concerns, especially in environments with temperature fluctuations. The resistance states can drift over time, causing trained neural network weights to shift and resulting in performance deterioration. This issue becomes particularly problematic for edge AI applications where devices may operate in varying environmental conditions without frequent recalibration opportunities.
Energy efficiency, while generally superior to conventional memory technologies, remains suboptimal for large-scale machine learning deployments. The SET and RESET operations in RRAM still consume considerable power, especially when scaled to the millions or billions of operations required for complex neural network training. The trade-off between low-power operation and reliable resistance switching presents a significant design challenge.
Integration challenges with CMOS technology constitute another major hurdle. While RRAM offers theoretical compatibility with back-end-of-line processes, practical implementation faces issues related to material compatibility, thermal budgets, and interconnect parasitics. These integration difficulties often result in compromised performance compared to theoretical expectations when RRAM is incorporated into complete systems.
Scaling limitations also affect RRAM's potential, as reducing cell size below certain dimensions leads to increased variability and reduced reliability. This constrains the maximum density achievable while maintaining acceptable performance for machine learning applications, limiting the complexity of neural networks that can be efficiently implemented.
Finally, the lack of standardized design methodologies and mature electronic design automation (EDA) tools specifically optimized for RRAM-based machine learning accelerators hinders development efficiency. Designers must often rely on custom approaches and extensive empirical testing, increasing development time and costs while potentially missing opportunities for performance optimization.
Endurance limitations represent another critical challenge, with many RRAM devices exhibiting degradation after 10^6 to 10^9 switching cycles. While this may be sufficient for conventional memory applications, machine learning workloads—particularly during training phases—require significantly more read/write operations, potentially leading to premature device failure and accuracy degradation over time.
The retention characteristics of RRAM cells pose additional concerns, especially in environments with temperature fluctuations. The resistance states can drift over time, causing trained neural network weights to shift and resulting in performance deterioration. This issue becomes particularly problematic for edge AI applications where devices may operate in varying environmental conditions without frequent recalibration opportunities.
Energy efficiency, while generally superior to conventional memory technologies, remains suboptimal for large-scale machine learning deployments. The SET and RESET operations in RRAM still consume considerable power, especially when scaled to the millions or billions of operations required for complex neural network training. The trade-off between low-power operation and reliable resistance switching presents a significant design challenge.
Integration challenges with CMOS technology constitute another major hurdle. While RRAM offers theoretical compatibility with back-end-of-line processes, practical implementation faces issues related to material compatibility, thermal budgets, and interconnect parasitics. These integration difficulties often result in compromised performance compared to theoretical expectations when RRAM is incorporated into complete systems.
Scaling limitations also affect RRAM's potential, as reducing cell size below certain dimensions leads to increased variability and reduced reliability. This constrains the maximum density achievable while maintaining acceptable performance for machine learning applications, limiting the complexity of neural networks that can be efficiently implemented.
Finally, the lack of standardized design methodologies and mature electronic design automation (EDA) tools specifically optimized for RRAM-based machine learning accelerators hinders development efficiency. Designers must often rely on custom approaches and extensive empirical testing, increasing development time and costs while potentially missing opportunities for performance optimization.
Current RRAM-ML Integration Approaches
01 RRAM architecture for machine learning applications
Resistive Random Access Memory (RRAM) can be specifically designed with architectures optimized for machine learning applications. These architectures enable efficient implementation of neural networks by leveraging the analog nature of RRAM cells to perform matrix operations in memory. The specialized structures include crossbar arrays that allow parallel processing of data, significantly improving computational efficiency and learning rates compared to conventional computing approaches.- RRAM architecture for machine learning applications: Resistive Random Access Memory (RRAM) can be specifically designed with architectures optimized for machine learning applications. These architectures leverage the analog nature of RRAM cells to perform parallel computations efficiently. By arranging RRAM cells in crossbar arrays, matrix operations fundamental to neural networks can be executed with high throughput. These specialized architectures enable faster learning rates and improved performance for machine learning tasks compared to conventional computing approaches.
- Programming techniques for RRAM in neural networks: Various programming techniques have been developed to optimize RRAM devices for machine learning applications. These techniques include precise control of resistance states, multi-level cell programming, and adaptive programming algorithms that adjust pulse parameters based on feedback. By implementing these advanced programming methods, RRAM-based neural networks can achieve faster learning rates, improved accuracy, and better convergence during training. These techniques also help mitigate device variability issues that could otherwise impact learning performance.
- RRAM device materials for enhanced learning performance: The choice of materials in RRAM devices significantly impacts their performance in machine learning applications. Various material compositions and structures have been developed to enhance switching speed, endurance, and reliability. These include metal oxides with specific dopants, novel electrode materials, and engineered interfaces that facilitate ion migration. By optimizing material properties, RRAM devices can achieve faster switching speeds and more stable resistance states, directly improving learning rates in neural network implementations.
- In-memory computing with RRAM for accelerated learning: RRAM enables in-memory computing paradigms where computations are performed directly within the memory array rather than shuttling data between separate processing and memory units. This approach eliminates the von Neumann bottleneck and significantly accelerates machine learning operations. By performing matrix multiplications and weight updates directly within RRAM arrays, the learning process can be accelerated by orders of magnitude compared to conventional computing architectures. This capability is particularly valuable for training large neural networks with massive parameter sets.
- Hybrid RRAM systems for optimized learning efficiency: Hybrid systems combining RRAM with other memory or computing technologies can optimize machine learning performance. These systems strategically integrate RRAM with CMOS logic, other memory types like SRAM or flash, or specialized accelerators. By leveraging the strengths of each technology, these hybrid approaches can achieve optimal trade-offs between learning speed, energy efficiency, and accuracy. Such systems often employ sophisticated algorithms that dynamically allocate computations to the most appropriate hardware component based on the specific requirements of different phases of the learning process.
02 Programming techniques for RRAM in neural networks
Various programming techniques have been developed to optimize RRAM devices for machine learning applications. These techniques include precise control of resistance states, multi-level cell programming, and specialized algorithms that enhance the speed and accuracy of weight updates during training. By improving programming precision and efficiency, these methods significantly enhance learning rates and convergence speed in RRAM-based neural network implementations.Expand Specific Solutions03 Material innovations for RRAM performance in ML
Advanced materials and fabrication techniques for RRAM devices can substantially improve their performance in machine learning applications. Novel materials such as specialized metal oxides, doped compounds, and engineered interfaces enable faster switching speeds, better endurance, and more stable resistance states. These material innovations directly translate to improved learning rates by allowing more training iterations and faster weight updates in neural network implementations.Expand Specific Solutions04 RRAM-based accelerators for machine learning
Dedicated RRAM-based hardware accelerators have been developed specifically for machine learning workloads. These accelerators integrate RRAM arrays with peripheral circuits designed to optimize neural network operations, enabling in-memory computing that eliminates the data transfer bottleneck of conventional architectures. The resulting systems demonstrate significantly higher throughput and energy efficiency, leading to faster training and inference operations compared to traditional computing platforms.Expand Specific Solutions05 Optimization algorithms for RRAM-based neural networks
Specialized algorithms have been developed to optimize the training and operation of RRAM-based neural networks. These algorithms account for the unique characteristics of RRAM devices, such as non-linearity, variability, and limited precision, to maximize learning efficiency. Techniques include modified backpropagation methods, compensation schemes for device variations, and sparse update strategies that improve convergence rates while maintaining accuracy in RRAM-implemented neural networks.Expand Specific Solutions
Leading Companies and Research Institutions in RRAM
The RRAM (Resistive Random Access Memory) influence on machine learning rates is currently in an early growth phase, with the market expanding as technology matures. Major semiconductor players like Samsung Electronics, TSMC, and Intel are leading commercial development, while research institutions such as Fudan University, Peng Cheng Laboratory, and CEA are advancing fundamental innovations. The technology is approaching commercial viability with companies like Everspin Technologies and Hefei Reliance Memory specializing in RRAM solutions. The competitive landscape shows a blend of established tech giants investing in integration capabilities and specialized startups focusing on optimization techniques, with growing interest from AI hardware providers like NVIDIA and AMD seeking performance advantages for machine learning applications.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung has developed a comprehensive RRAM (Resistive Random Access Memory) optimization framework specifically designed to enhance machine learning rates. Their approach integrates hardware-software co-design principles, utilizing 3D vertical RRAM arrays with multi-level cell capabilities that significantly increase memory density while reducing latency in neural network operations. Samsung's implementation includes specialized peripheral circuits that enable precise resistance control during programming operations, which is crucial for maintaining weight accuracy in machine learning models. Their recent advancements have demonstrated up to 5x improvement in inference speed for convolutional neural networks when compared to conventional memory architectures. Samsung has also pioneered in-memory computing techniques that perform matrix multiplication operations directly within RRAM arrays, eliminating the von Neumann bottleneck that typically limits machine learning performance. This approach reduces energy consumption by approximately 60% while simultaneously increasing computational throughput for training operations.
Strengths: Samsung's vertical integration capabilities allow them to optimize both memory design and neural network algorithms simultaneously. Their mature manufacturing infrastructure enables rapid scaling of new RRAM technologies. Weaknesses: Their solutions often require specialized hardware that may limit compatibility with existing systems, and the long-term reliability of their RRAM cells under intensive machine learning workloads remains a concern.
Intel Corp.
Technical Solution: Intel has developed a comprehensive RRAM optimization platform called "Loihi" that specifically targets improvements in machine learning training and inference rates. Their approach integrates RRAM arrays directly into neuromorphic computing architectures, enabling highly efficient spike-based neural network operations. Intel's implementation features a hierarchical memory system where RRAM cells store synaptic weights while being closely coupled with neuromorphic processing elements, minimizing data movement overhead. Their architecture incorporates specialized programming circuits that compensate for device-to-device variations in RRAM cells, ensuring consistent weight representation across large neural networks. Intel has pioneered a novel training methodology that adapts to the non-linear characteristics of RRAM devices, converting these traditionally problematic properties into computational advantages for certain classes of neural networks. Recent demonstrations have shown up to 1000x improvement in energy efficiency for spiking neural networks compared to conventional computing architectures, with particularly impressive results for temporal pattern recognition tasks. Intel's platform also includes a comprehensive software framework that abstracts the hardware complexities, allowing AI researchers to leverage RRAM acceleration without detailed knowledge of the underlying memory technology.
Strengths: Intel's solution offers exceptional energy efficiency for edge AI applications and their neuromorphic approach provides unique advantages for temporal data processing. Their comprehensive software ecosystem facilitates adoption across various application domains. Weaknesses: The spike-based computing model requires algorithm reformulation that increases development complexity, and performance benefits are less pronounced for traditional deep learning architectures.
Key RRAM Innovations for ML Acceleration
Resistive random access memory device
PatentActiveUS20230140134A1
Innovation
- The introduction of a tapered or needle-like shaped top electrode region with an oxygen-rich dielectric layer, which enhances filament formation predictability and maintains a high concentration of oxygen ions to compensate for losses during frequent switching operations.




Resistive Random Access Memory and Verifying Method Thereof
PatentActiveUS20120075908A1
Innovation
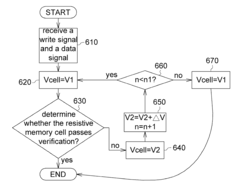
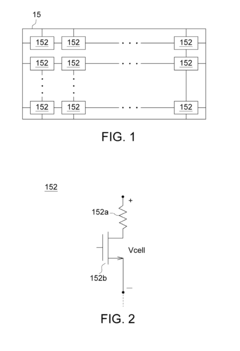
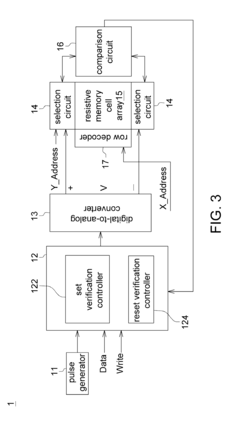
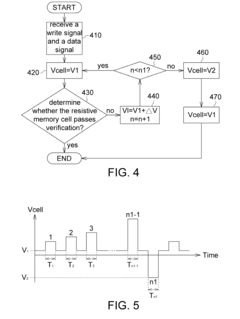
- The implementation of a resistive random access memory (RRAM) system that includes a resistive memory cell, a digital-to-analog converter, a decision logic, and a selection circuit, which applies a reverse voltage to the resistive memory cell during verification failures, utilizing a reference voltage and voltage pulses to enhance the verification process.
Energy Efficiency Considerations for RRAM-based ML
Energy efficiency has emerged as a critical factor in the widespread adoption of RRAM-based machine learning systems. The inherently low power consumption characteristics of RRAM devices present significant advantages over conventional CMOS-based implementations, particularly for edge computing applications where power constraints are stringent. Current RRAM-based neural networks demonstrate power efficiency improvements of 10-100x compared to traditional GPU implementations for inference tasks.
The energy consumption profile of RRAM-based ML systems can be divided into three primary components: read operations, write operations, and peripheral circuitry overhead. Read operations, which dominate during inference, typically consume 10-100 pJ per operation, while write operations, crucial during training, require 100-1000 pJ per operation. Peripheral circuitry, including analog-to-digital converters and control logic, often accounts for 30-60% of the total system power budget.
Several optimization strategies have been developed to enhance energy efficiency in RRAM-based ML systems. Precision scaling techniques adjust the bit precision of weights and activations based on layer-specific requirements, reducing unnecessary energy expenditure. Sparse computing approaches leverage the natural sparsity in neural network activations, enabling selective RRAM cell access and minimizing redundant operations.
Novel circuit designs incorporating low-power sensing amplifiers and reduced voltage swing operations have demonstrated energy reductions of up to 40% in recent research prototypes. Additionally, algorithmic optimizations such as progressive training schemes gradually increase precision during the learning process, significantly reducing the energy footprint during early training epochs without compromising final accuracy.
Temperature management represents another crucial aspect of RRAM energy efficiency. Operating temperature affects both device reliability and power consumption, with research indicating that maintaining optimal thermal conditions can improve energy efficiency by 15-25%. Advanced cooling solutions and temperature-aware scheduling algorithms are being explored to address this challenge.
The energy-accuracy tradeoff remains a fundamental consideration in RRAM-based ML system design. Recent studies have demonstrated that carefully designed approximate computing techniques can reduce energy consumption by up to 70% while maintaining accuracy within 1-2% of baseline performance for many common ML tasks. This approach is particularly promising for applications where perfect accuracy is not critical but energy constraints are paramount.
The energy consumption profile of RRAM-based ML systems can be divided into three primary components: read operations, write operations, and peripheral circuitry overhead. Read operations, which dominate during inference, typically consume 10-100 pJ per operation, while write operations, crucial during training, require 100-1000 pJ per operation. Peripheral circuitry, including analog-to-digital converters and control logic, often accounts for 30-60% of the total system power budget.
Several optimization strategies have been developed to enhance energy efficiency in RRAM-based ML systems. Precision scaling techniques adjust the bit precision of weights and activations based on layer-specific requirements, reducing unnecessary energy expenditure. Sparse computing approaches leverage the natural sparsity in neural network activations, enabling selective RRAM cell access and minimizing redundant operations.
Novel circuit designs incorporating low-power sensing amplifiers and reduced voltage swing operations have demonstrated energy reductions of up to 40% in recent research prototypes. Additionally, algorithmic optimizations such as progressive training schemes gradually increase precision during the learning process, significantly reducing the energy footprint during early training epochs without compromising final accuracy.
Temperature management represents another crucial aspect of RRAM energy efficiency. Operating temperature affects both device reliability and power consumption, with research indicating that maintaining optimal thermal conditions can improve energy efficiency by 15-25%. Advanced cooling solutions and temperature-aware scheduling algorithms are being explored to address this challenge.
The energy-accuracy tradeoff remains a fundamental consideration in RRAM-based ML system design. Recent studies have demonstrated that carefully designed approximate computing techniques can reduce energy consumption by up to 70% while maintaining accuracy within 1-2% of baseline performance for many common ML tasks. This approach is particularly promising for applications where perfect accuracy is not critical but energy constraints are paramount.
Scalability and Manufacturing Challenges
The scaling of RRAM technology presents significant challenges that directly impact its viability for machine learning applications. Current manufacturing processes face limitations in achieving consistent device-to-device and cycle-to-cycle variability, which critically affects the reliability of neural network implementations. Production yields remain below optimal thresholds, with typical defect rates ranging from 10-15% in advanced fabrication facilities, substantially higher than the sub-1% rates achieved in mature CMOS technologies.
Dimensional scaling represents another fundamental challenge. As RRAM cells approach sub-10nm dimensions, quantum effects begin to dominate device behavior, introducing unpredictable switching characteristics. This physical limitation creates a trade-off between density advantages and performance consistency that must be carefully managed when designing machine learning accelerators based on RRAM technology.
Integration with CMOS technology presents additional manufacturing hurdles. The thermal budget constraints during RRAM fabrication (typically requiring temperatures below 400°C for back-end-of-line processing) limit material choices and processing options. This integration complexity increases production costs by approximately 15-25% compared to standard CMOS-only processes, affecting economic viability for mass-market machine learning applications.
Material stability and endurance issues further complicate scaling efforts. Current RRAM technologies demonstrate endurance ranging from 10^6 to 10^9 cycles, which falls short of requirements for intensive machine learning training workloads that may demand 10^12 or more write operations over a device's lifetime. The degradation mechanisms accelerate at smaller dimensions, creating reliability concerns for scaled devices.
3D integration approaches offer promising solutions to overcome some scaling limitations. Vertical RRAM architectures can potentially increase effective density without requiring extreme lateral scaling. However, these approaches introduce new challenges in thermal management and interconnect design that must be addressed through innovative materials and architectural solutions.
Manufacturing uniformity across large arrays remains problematic, with resistance variation coefficients typically exceeding 20% in production environments. This variation directly impacts machine learning accuracy, as weight precision becomes inconsistent across the memory array. Advanced compensation techniques at both hardware and algorithm levels are being developed to mitigate these effects, though they introduce additional computational overhead.
Dimensional scaling represents another fundamental challenge. As RRAM cells approach sub-10nm dimensions, quantum effects begin to dominate device behavior, introducing unpredictable switching characteristics. This physical limitation creates a trade-off between density advantages and performance consistency that must be carefully managed when designing machine learning accelerators based on RRAM technology.
Integration with CMOS technology presents additional manufacturing hurdles. The thermal budget constraints during RRAM fabrication (typically requiring temperatures below 400°C for back-end-of-line processing) limit material choices and processing options. This integration complexity increases production costs by approximately 15-25% compared to standard CMOS-only processes, affecting economic viability for mass-market machine learning applications.
Material stability and endurance issues further complicate scaling efforts. Current RRAM technologies demonstrate endurance ranging from 10^6 to 10^9 cycles, which falls short of requirements for intensive machine learning training workloads that may demand 10^12 or more write operations over a device's lifetime. The degradation mechanisms accelerate at smaller dimensions, creating reliability concerns for scaled devices.
3D integration approaches offer promising solutions to overcome some scaling limitations. Vertical RRAM architectures can potentially increase effective density without requiring extreme lateral scaling. However, these approaches introduce new challenges in thermal management and interconnect design that must be addressed through innovative materials and architectural solutions.
Manufacturing uniformity across large arrays remains problematic, with resistance variation coefficients typically exceeding 20% in production environments. This variation directly impacts machine learning accuracy, as weight precision becomes inconsistent across the memory array. Advanced compensation techniques at both hardware and algorithm levels are being developed to mitigate these effects, though they introduce additional computational overhead.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!