

Cloud Integration And Workflows For DNA Data Storage
AUG 27, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
DNA Data Storage Background and Objectives
DNA data storage represents a revolutionary approach to digital information preservation, leveraging the biological molecule's exceptional data density and longevity. Since the concept's introduction in the 1980s, DNA storage has evolved from theoretical possibility to practical implementation, with significant milestones including Church et al.'s Harvard demonstration in 2012 and Microsoft's fully automated DNA storage system in 2019.
The fundamental principle exploits DNA's quaternary encoding system (A, T, G, C) to store binary data, offering theoretical storage densities of up to 455 exabytes per gram—orders of magnitude greater than conventional electronic media. Additionally, DNA's natural stability enables data preservation for thousands of years under proper conditions, addressing the obsolescence challenges plaguing traditional storage technologies.
Current technological objectives focus on overcoming the remaining barriers to practical implementation. These include reducing synthesis and sequencing costs, which have decreased dramatically but remain prohibitive for mass adoption. The industry aims to achieve costs below $100 per terabyte for writing and $10 per terabyte for reading to become competitive with magnetic tape storage.
Speed optimization represents another critical goal, as current DNA read/write processes operate at rates incompatible with real-time applications. Research targets accelerating these processes through improved biochemical techniques and parallelization. Error correction mechanisms also require enhancement to ensure data integrity across the synthesis-storage-sequencing pipeline.
Cloud integration presents a particularly promising direction, potentially transforming DNA storage from an isolated technology into a seamlessly integrated component of modern data infrastructure. The vision involves developing standardized workflows and APIs that allow cloud service providers to incorporate DNA storage as a tier within their existing storage hierarchies, particularly for cold storage applications.
The ultimate objective is establishing DNA data storage as a viable, sustainable solution for long-term archival needs, especially for the exponentially growing volumes of rarely accessed but valuable data. This aligns with broader sustainability goals, as DNA storage offers minimal energy requirements for maintenance compared to power-hungry data centers, potentially reducing the digital ecosystem's environmental footprint while addressing the looming data storage crisis.
The fundamental principle exploits DNA's quaternary encoding system (A, T, G, C) to store binary data, offering theoretical storage densities of up to 455 exabytes per gram—orders of magnitude greater than conventional electronic media. Additionally, DNA's natural stability enables data preservation for thousands of years under proper conditions, addressing the obsolescence challenges plaguing traditional storage technologies.
Current technological objectives focus on overcoming the remaining barriers to practical implementation. These include reducing synthesis and sequencing costs, which have decreased dramatically but remain prohibitive for mass adoption. The industry aims to achieve costs below $100 per terabyte for writing and $10 per terabyte for reading to become competitive with magnetic tape storage.
Speed optimization represents another critical goal, as current DNA read/write processes operate at rates incompatible with real-time applications. Research targets accelerating these processes through improved biochemical techniques and parallelization. Error correction mechanisms also require enhancement to ensure data integrity across the synthesis-storage-sequencing pipeline.
Cloud integration presents a particularly promising direction, potentially transforming DNA storage from an isolated technology into a seamlessly integrated component of modern data infrastructure. The vision involves developing standardized workflows and APIs that allow cloud service providers to incorporate DNA storage as a tier within their existing storage hierarchies, particularly for cold storage applications.
The ultimate objective is establishing DNA data storage as a viable, sustainable solution for long-term archival needs, especially for the exponentially growing volumes of rarely accessed but valuable data. This aligns with broader sustainability goals, as DNA storage offers minimal energy requirements for maintenance compared to power-hungry data centers, potentially reducing the digital ecosystem's environmental footprint while addressing the looming data storage crisis.
Market Analysis for DNA Storage Solutions
The DNA data storage market is experiencing significant growth as organizations seek sustainable, high-density storage solutions for the exponential increase in data generation. Current market projections indicate the global DNA data storage market will reach approximately $3.3 billion by 2030, with a compound annual growth rate exceeding 58% between 2023-2030. This remarkable growth trajectory is driven by the fundamental limitations of conventional storage technologies in meeting future data demands.
Key market segments for DNA storage include government archives, scientific research institutions, healthcare organizations, and large technology companies with massive data retention requirements. These sectors generate enormous volumes of cold data that require long-term preservation but infrequent access, making them ideal candidates for DNA storage solutions.
Cloud integration represents a critical market opportunity, as major cloud service providers seek differentiation through novel storage tiers. Companies like Microsoft, in collaboration with Twist Bioscience, have already demonstrated proof-of-concept cloud-integrated DNA storage systems. The market potential for cloud-integrated DNA storage workflows is particularly promising, as it addresses the significant technical barriers that currently limit widespread adoption.
Market analysis reveals several driving factors accelerating demand. Data centers face unsustainable energy consumption and physical space constraints with traditional storage media. Environmental sustainability concerns are pushing organizations toward greener alternatives, with DNA storage offering minimal carbon footprint during the retention phase. Additionally, regulatory requirements for long-term data preservation in sectors like healthcare and finance create demand for century-scale storage solutions.
Customer pain points in the current market include prohibitive costs (currently exceeding $1,000 per MB), slow read/write speeds, and complex workflows requiring specialized expertise. Cloud-integrated workflows that abstract these complexities represent a significant value proposition for potential customers.
Regional market analysis shows North America leading adoption, particularly in research applications, while Asia-Pacific markets are expected to demonstrate the fastest growth rate due to increasing data center investments and government-backed initiatives in countries like China, Japan, and Singapore.
The competitive landscape features both established biotechnology companies pivoting toward data storage applications and startups focused exclusively on DNA storage solutions. Strategic partnerships between cloud providers and biotechnology firms are becoming increasingly common, indicating market consolidation and ecosystem development around standardized workflows and integration protocols.
Key market segments for DNA storage include government archives, scientific research institutions, healthcare organizations, and large technology companies with massive data retention requirements. These sectors generate enormous volumes of cold data that require long-term preservation but infrequent access, making them ideal candidates for DNA storage solutions.
Cloud integration represents a critical market opportunity, as major cloud service providers seek differentiation through novel storage tiers. Companies like Microsoft, in collaboration with Twist Bioscience, have already demonstrated proof-of-concept cloud-integrated DNA storage systems. The market potential for cloud-integrated DNA storage workflows is particularly promising, as it addresses the significant technical barriers that currently limit widespread adoption.
Market analysis reveals several driving factors accelerating demand. Data centers face unsustainable energy consumption and physical space constraints with traditional storage media. Environmental sustainability concerns are pushing organizations toward greener alternatives, with DNA storage offering minimal carbon footprint during the retention phase. Additionally, regulatory requirements for long-term data preservation in sectors like healthcare and finance create demand for century-scale storage solutions.
Customer pain points in the current market include prohibitive costs (currently exceeding $1,000 per MB), slow read/write speeds, and complex workflows requiring specialized expertise. Cloud-integrated workflows that abstract these complexities represent a significant value proposition for potential customers.
Regional market analysis shows North America leading adoption, particularly in research applications, while Asia-Pacific markets are expected to demonstrate the fastest growth rate due to increasing data center investments and government-backed initiatives in countries like China, Japan, and Singapore.
The competitive landscape features both established biotechnology companies pivoting toward data storage applications and startups focused exclusively on DNA storage solutions. Strategic partnerships between cloud providers and biotechnology firms are becoming increasingly common, indicating market consolidation and ecosystem development around standardized workflows and integration protocols.
Technical Challenges in DNA Data Storage
Despite significant advancements in DNA data storage technology, numerous technical challenges persist that impede its widespread adoption. The encoding and decoding processes remain complex and error-prone, with current methods struggling to achieve the perfect translation between binary data and nucleotide sequences. Error rates in DNA synthesis and sequencing, though improving, still exceed those acceptable for reliable data storage, necessitating sophisticated error correction mechanisms that add computational overhead.
DNA synthesis speed represents a critical bottleneck, with current technologies operating at rates of kilobits per second—orders of magnitude slower than electronic storage writing speeds. This limitation makes the initial data writing process prohibitively time-consuming for large-scale applications. Similarly, DNA sequencing, while faster than synthesis, still requires hours to days depending on the volume of data being retrieved.
The integration of DNA storage with cloud infrastructure presents unique challenges. Current cloud architectures are optimized for electronic storage media with near-instantaneous access times, whereas DNA storage operates on fundamentally different timescales. Developing middleware and APIs that can effectively bridge this temporal gap while maintaining compatibility with existing cloud services remains problematic.
Workflow management for DNA data storage introduces additional complexity. The physical handling of DNA samples requires specialized equipment and expertise not typically found in data centers. Establishing automated systems for sample tracking, storage condition monitoring, and retrieval orchestration demands novel approaches to workflow design and implementation.
Long-term stability of stored DNA presents both advantages and challenges. While properly preserved DNA can potentially last thousands of years, practical storage conditions must balance preservation quality with cost and accessibility. Environmental factors such as temperature, humidity, and exposure to chemicals or radiation can degrade DNA integrity over time, necessitating robust storage solutions.
Standardization across the DNA data storage ecosystem remains underdeveloped. The lack of universal protocols for data encoding, physical storage formats, and retrieval methodologies hampers interoperability between different systems and technologies. This fragmentation impedes the development of cohesive cloud integration strategies and standardized workflows.
Cost factors continue to present significant barriers, with current DNA synthesis expenses reaching approximately $0.001 per base pair. For petabyte-scale storage, these costs become prohibitive compared to conventional electronic storage options, despite DNA's theoretical density advantages. Achieving economic viability requires orders-of-magnitude reductions in synthesis and sequencing costs.
DNA synthesis speed represents a critical bottleneck, with current technologies operating at rates of kilobits per second—orders of magnitude slower than electronic storage writing speeds. This limitation makes the initial data writing process prohibitively time-consuming for large-scale applications. Similarly, DNA sequencing, while faster than synthesis, still requires hours to days depending on the volume of data being retrieved.
The integration of DNA storage with cloud infrastructure presents unique challenges. Current cloud architectures are optimized for electronic storage media with near-instantaneous access times, whereas DNA storage operates on fundamentally different timescales. Developing middleware and APIs that can effectively bridge this temporal gap while maintaining compatibility with existing cloud services remains problematic.
Workflow management for DNA data storage introduces additional complexity. The physical handling of DNA samples requires specialized equipment and expertise not typically found in data centers. Establishing automated systems for sample tracking, storage condition monitoring, and retrieval orchestration demands novel approaches to workflow design and implementation.
Long-term stability of stored DNA presents both advantages and challenges. While properly preserved DNA can potentially last thousands of years, practical storage conditions must balance preservation quality with cost and accessibility. Environmental factors such as temperature, humidity, and exposure to chemicals or radiation can degrade DNA integrity over time, necessitating robust storage solutions.
Standardization across the DNA data storage ecosystem remains underdeveloped. The lack of universal protocols for data encoding, physical storage formats, and retrieval methodologies hampers interoperability between different systems and technologies. This fragmentation impedes the development of cohesive cloud integration strategies and standardized workflows.
Cost factors continue to present significant barriers, with current DNA synthesis expenses reaching approximately $0.001 per base pair. For petabyte-scale storage, these costs become prohibitive compared to conventional electronic storage options, despite DNA's theoretical density advantages. Achieving economic viability requires orders-of-magnitude reductions in synthesis and sequencing costs.
Cloud Integration Architectures for DNA Storage
01 DNA encoding and decoding methods for data storage
Various methods for encoding digital data into DNA sequences and decoding DNA back into digital data have been developed. These techniques involve converting binary data into nucleotide sequences using specific encoding algorithms that optimize for DNA synthesis constraints, error correction, and data density. Advanced encoding schemes may incorporate redundancy for error detection and correction, similar to traditional digital storage systems but adapted for the biological medium.- DNA encoding and decoding methods for data storage: Various methods for encoding digital data into DNA sequences and decoding DNA back into digital information. These techniques involve algorithms that convert binary data into nucleotide sequences while addressing challenges such as error correction, data density optimization, and sequence stability. The encoding schemes are designed to avoid problematic DNA patterns like homopolymers or repetitive sequences that could cause errors during synthesis or sequencing.
- DNA synthesis and sequencing technologies for data storage: Specialized DNA synthesis and sequencing technologies developed specifically for data storage applications. These include high-throughput synthesis methods for creating DNA strands that contain encoded data, as well as advanced sequencing techniques optimized for retrieving information from DNA storage systems. The technologies focus on improving accuracy, speed, and cost-effectiveness of writing and reading data in DNA format.
- DNA storage system architectures and hardware: Physical systems and hardware architectures designed for DNA-based data storage. These include specialized devices for DNA storage management, retrieval systems, and integrated platforms that combine synthesis, storage, and sequencing capabilities. The hardware solutions address challenges such as sample indexing, physical storage conditions, and automation of DNA data access processes.
- Error correction and data integrity in DNA storage: Methods for ensuring data integrity and error correction in DNA-based storage systems. These include specialized coding schemes, redundancy mechanisms, and error detection algorithms designed to overcome the unique challenges of DNA storage, such as synthesis errors, sequencing errors, and degradation over time. The approaches aim to achieve reliable long-term data preservation despite the inherent biological variability of DNA molecules.
- Random access and indexing methods for DNA data storage: Techniques for enabling random access to specific data within large DNA storage archives. These include molecular indexing systems, address-based retrieval methods, and selective amplification approaches that allow targeted retrieval of specific data without sequencing entire DNA libraries. The methods enable practical use of DNA storage by providing ways to efficiently access only the needed portions of stored information.
02 DNA synthesis and sequencing technologies for data storage
Specialized DNA synthesis and sequencing technologies have been developed specifically for data storage applications. These technologies focus on improving accuracy, throughput, and cost-effectiveness of writing and reading DNA-stored data. Innovations include parallel synthesis methods, microfluidic platforms, and nanopore sequencing adaptations that are optimized for the unique requirements of synthetic DNA data storage rather than genomic applications.Expand Specific Solutions03 Storage architecture and indexing systems for DNA data
Novel storage architectures and indexing systems have been designed to organize and retrieve DNA-stored data efficiently. These systems include physical storage solutions for DNA libraries, addressing schemes to locate specific data fragments, and hierarchical organization methods. The architectures often incorporate random access capabilities to retrieve specific data without sequencing entire DNA pools, significantly improving data access times.Expand Specific Solutions04 Error correction and data integrity in DNA storage
Specialized error correction codes and data integrity mechanisms have been developed to address the unique error profiles of DNA storage. These include methods to handle insertion, deletion, and substitution errors that occur during synthesis, storage, and sequencing. Advanced error correction techniques incorporate redundancy, parity checks, and statistical approaches tailored to the biochemical properties of DNA, ensuring data can be recovered accurately even after extended storage periods.Expand Specific Solutions05 Long-term preservation and stability of DNA-stored data
Methods for ensuring the long-term stability and preservation of DNA-stored data have been developed. These include encapsulation techniques, dehydration processes, and specialized storage media that protect DNA from environmental degradation. Some approaches involve storing DNA in specialized containers or matrices that minimize exposure to damaging factors such as oxygen, water, and UV radiation, potentially enabling data retention for thousands of years without active maintenance.Expand Specific Solutions
Key Industry Players in DNA Data Storage
Cloud integration and workflows for DNA data storage represent an emerging field at the intersection of biotechnology and information technology. The market is in its early growth phase, with significant research activity but limited commercial deployment. Current market size is modest but projected to expand rapidly as storage demands increase exponentially. From a technical maturity perspective, the ecosystem shows varying levels of advancement. Illumina leads in sequencing technology essential for DNA data retrieval, while BGI Research and BGI Shenzhen contribute significant genomic expertise. Academic institutions like Tianjin University and Huazhong University are advancing fundamental research. Roswell Biotechnologies and Twist Bioscience are developing specialized hardware and synthetic DNA solutions respectively. Microsoft and Roche represent major technology and healthcare players exploring integration possibilities, indicating growing cross-industry interest in this transformative storage paradigm.
Illumina, Inc.
Technical Solution: Illumina has developed an integrated cloud-based workflow system for DNA data storage that leverages their market-leading sequencing technology. Their platform, called BaseSpace Sequence Hub, has been adapted to support DNA data storage applications by providing specialized bioinformatics tools for encoding, decoding, and managing data stored in DNA. Illumina's solution focuses on the sequencing (reading) aspect of DNA storage, offering high-throughput, accurate sequencing capabilities essential for reliable data retrieval. Their workflow integrates with cloud storage providers through a comprehensive API layer that handles the translation between digital data and biological sequences. Illumina has demonstrated sequencing accuracy exceeding 99.9% for DNA-stored data and has developed proprietary error correction algorithms specifically designed for data storage applications. Their platform includes automated quality control processes that verify data integrity throughout the storage lifecycle and provides detailed analytics on storage efficiency and performance metrics[5][6].
Strengths: World-leading DNA sequencing technology with highest accuracy rates; established global infrastructure for sequencing support; comprehensive bioinformatics tools specifically optimized for data applications. Weaknesses: Less focus on the synthesis (writing) aspect of DNA storage; higher costs associated with their proprietary sequencing platforms; limited commercial-scale implementations beyond research projects.
BGI Research
Technical Solution: BGI Research has developed a comprehensive cloud-integrated DNA data storage platform called DNACloud that combines their DNBSEQ sequencing technology with specialized data management workflows. Their system employs a modular architecture that separates the logical data layer from physical DNA storage, allowing flexible integration with various cloud providers. BGI's platform features proprietary encoding algorithms that optimize for the characteristics of their sequencing technology, achieving higher data density and reliability. Their workflow includes automated sample preparation, synthesis coordination, and sequencing processes managed through a unified cloud interface. BGI has demonstrated storage of up to 100GB of data in DNA with their system and has developed specialized preservation techniques that maintain data integrity in various environmental conditions. Their platform includes comprehensive data security features, including molecular encryption methods that make the data unreadable without specific decryption keys, and supports hybrid storage models that combine conventional and DNA-based approaches based on data access patterns and retention requirements[7][8].
Strengths: Vertically integrated solution controlling both sequencing technology and data management; strong position in Asian markets with government support; competitive pricing compared to Western alternatives. Weaknesses: Less established presence in Western markets; fewer integration options with major Western cloud providers; technology still primarily in research phase with limited commercial deployment.
Core Patents and Research in DNA-Cloud Integration
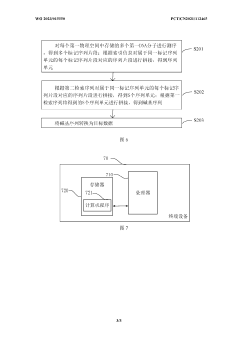
DNA storage method and system and electronic equipment
PatentActiveCN111091876A
Innovation
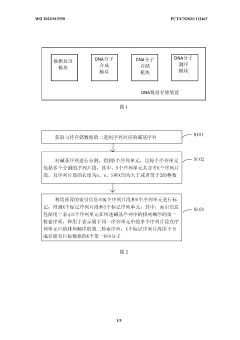
- By converting the storage file into binary and dividing it into fixed-size DNA storage units, and using the IndexDNA sequence and DateDNA algorithm for encoding and decoding, a base sequence that can be used for DNA synthesis is generated to achieve efficient encoding and storage of different types of data.

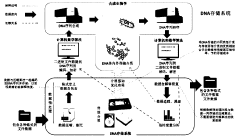
DNA data storage method and apparatus, device, and readable storage medium
PatentWO2023015550A1
Innovation
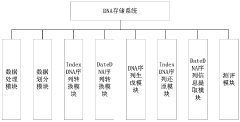
- By converting the binary sequence to be stored into the corresponding base sequence, dividing it into multiple sequence units and divided sequence fragments, using preset index information to mark these sequence fragments and units, and finally synthesizing DNA molecules. storage.
Scalability and Performance Considerations
As DNA data storage systems scale from laboratory prototypes to production environments, several critical performance considerations emerge. The integration with cloud infrastructure introduces both opportunities and challenges for system scalability. Current DNA storage architectures must address throughput limitations, with encoding and decoding processes representing significant bottlenecks. Laboratory-scale systems typically process data at rates measured in kilobytes per second, whereas practical applications require throughput improvements of several orders of magnitude to compete with conventional storage technologies.
Cloud-based workflows for DNA data storage must be designed with parallelization capabilities to distribute computational workloads across multiple nodes. Benchmarking data indicates that encoding algorithms can achieve up to 40x performance improvements when properly distributed across cloud computing resources. However, this parallelization introduces additional complexity in maintaining data integrity and managing workflow dependencies.
Latency presents another critical consideration, particularly for random access operations. While DNA storage excels at archival applications with less stringent retrieval time requirements, many enterprise use cases demand response times under specific thresholds. Cloud integration strategies must therefore incorporate caching mechanisms and predictive retrieval algorithms to mitigate the inherent access delays of DNA-based systems.
Resource utilization efficiency becomes paramount when scaling DNA storage workflows in cloud environments. The computational intensity of error correction codes and the specialized nature of DNA synthesis and sequencing processes create unique resource allocation challenges. Cloud cost models must be adapted to account for these workload characteristics, with preliminary studies suggesting hybrid approaches that leverage specialized hardware accelerators for encoding/decoding operations while utilizing standard cloud instances for workflow management.
Security and data integrity verification processes introduce additional performance overhead that scales with data volume. Implementing cryptographic operations and error detection mechanisms within the DNA storage workflow requires careful optimization to prevent these safeguards from becoming performance bottlenecks. Cloud-native security services must be integrated with DNA-specific verification techniques to maintain both performance and data protection standards.
The integration of DNA storage with existing cloud storage tiers requires performance-aware API design and standardized interfaces. Current implementations demonstrate variable performance characteristics depending on the complexity of the translation layer between conventional digital formats and DNA-encoded data. Establishing performance benchmarks and standardized testing methodologies will be essential for comparing different implementation approaches as the technology matures.
Cloud-based workflows for DNA data storage must be designed with parallelization capabilities to distribute computational workloads across multiple nodes. Benchmarking data indicates that encoding algorithms can achieve up to 40x performance improvements when properly distributed across cloud computing resources. However, this parallelization introduces additional complexity in maintaining data integrity and managing workflow dependencies.
Latency presents another critical consideration, particularly for random access operations. While DNA storage excels at archival applications with less stringent retrieval time requirements, many enterprise use cases demand response times under specific thresholds. Cloud integration strategies must therefore incorporate caching mechanisms and predictive retrieval algorithms to mitigate the inherent access delays of DNA-based systems.
Resource utilization efficiency becomes paramount when scaling DNA storage workflows in cloud environments. The computational intensity of error correction codes and the specialized nature of DNA synthesis and sequencing processes create unique resource allocation challenges. Cloud cost models must be adapted to account for these workload characteristics, with preliminary studies suggesting hybrid approaches that leverage specialized hardware accelerators for encoding/decoding operations while utilizing standard cloud instances for workflow management.
Security and data integrity verification processes introduce additional performance overhead that scales with data volume. Implementing cryptographic operations and error detection mechanisms within the DNA storage workflow requires careful optimization to prevent these safeguards from becoming performance bottlenecks. Cloud-native security services must be integrated with DNA-specific verification techniques to maintain both performance and data protection standards.
The integration of DNA storage with existing cloud storage tiers requires performance-aware API design and standardized interfaces. Current implementations demonstrate variable performance characteristics depending on the complexity of the translation layer between conventional digital formats and DNA-encoded data. Establishing performance benchmarks and standardized testing methodologies will be essential for comparing different implementation approaches as the technology matures.
Data Security and Regulatory Compliance
DNA data storage systems face unique security and regulatory challenges that require specialized approaches to ensure data integrity, confidentiality, and compliance with evolving legal frameworks. As these systems integrate with cloud infrastructure, organizations must implement robust security measures that address both the biological and digital aspects of DNA-based storage solutions.
The security architecture for DNA data storage must incorporate end-to-end encryption throughout the workflow, from initial data encoding to synthesis, storage, retrieval, and sequencing. Current implementations typically utilize AES-256 encryption for data at rest and TLS 1.3 for data in transit, with specialized cryptographic protocols being developed specifically for the unique characteristics of DNA storage media.
Access control mechanisms present particular challenges in DNA storage environments where physical access to samples must be restricted alongside digital access controls. Leading solutions implement multi-factor authentication combined with physical security measures such as biometric verification for laboratory environments where DNA samples are handled.
Regulatory compliance for DNA data storage spans multiple domains including healthcare regulations (HIPAA in the US), general data protection frameworks (GDPR in Europe, CCPA in California), and emerging biotechnology regulations. Organizations implementing DNA storage solutions must navigate this complex regulatory landscape while preparing for forthcoming legislation specifically addressing synthetic DNA and biological data storage.
Data sovereignty considerations add another layer of complexity, as DNA-encoded data may be subject to different jurisdictional requirements based on where the physical DNA is synthesized, stored, and sequenced. Cloud integration workflows must incorporate geofencing capabilities to ensure compliance with regional data residency requirements.
Audit trails and chain of custody documentation are essential components of compliant DNA storage systems. Immutable logging mechanisms, often implemented using blockchain technology, provide verifiable records of all operations performed on DNA-stored data, from initial encoding through synthesis, storage, and retrieval processes.
Incident response protocols for DNA data storage systems must address both conventional cybersecurity breaches and unique scenarios such as unauthorized DNA synthesis or physical theft of DNA samples. These protocols should include specialized procedures for containment and forensic analysis of biological storage media.
Industry standards for DNA data security are still evolving, with organizations like ISO, NIST, and the DNA Data Storage Alliance working to establish frameworks specifically addressing the security requirements of biological storage systems. Early adopters are advised to participate in these standardization efforts while implementing best practices from adjacent fields such as biobanking and digital archiving.
The security architecture for DNA data storage must incorporate end-to-end encryption throughout the workflow, from initial data encoding to synthesis, storage, retrieval, and sequencing. Current implementations typically utilize AES-256 encryption for data at rest and TLS 1.3 for data in transit, with specialized cryptographic protocols being developed specifically for the unique characteristics of DNA storage media.
Access control mechanisms present particular challenges in DNA storage environments where physical access to samples must be restricted alongside digital access controls. Leading solutions implement multi-factor authentication combined with physical security measures such as biometric verification for laboratory environments where DNA samples are handled.
Regulatory compliance for DNA data storage spans multiple domains including healthcare regulations (HIPAA in the US), general data protection frameworks (GDPR in Europe, CCPA in California), and emerging biotechnology regulations. Organizations implementing DNA storage solutions must navigate this complex regulatory landscape while preparing for forthcoming legislation specifically addressing synthetic DNA and biological data storage.
Data sovereignty considerations add another layer of complexity, as DNA-encoded data may be subject to different jurisdictional requirements based on where the physical DNA is synthesized, stored, and sequenced. Cloud integration workflows must incorporate geofencing capabilities to ensure compliance with regional data residency requirements.
Audit trails and chain of custody documentation are essential components of compliant DNA storage systems. Immutable logging mechanisms, often implemented using blockchain technology, provide verifiable records of all operations performed on DNA-stored data, from initial encoding through synthesis, storage, and retrieval processes.
Incident response protocols for DNA data storage systems must address both conventional cybersecurity breaches and unique scenarios such as unauthorized DNA synthesis or physical theft of DNA samples. These protocols should include specialized procedures for containment and forensic analysis of biological storage media.
Industry standards for DNA data security are still evolving, with organizations like ISO, NIST, and the DNA Data Storage Alliance working to establish frameworks specifically addressing the security requirements of biological storage systems. Early adopters are advised to participate in these standardization efforts while implementing best practices from adjacent fields such as biobanking and digital archiving.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!