

Storage Density Limits And Theoretical Frameworks For DNA Data Storage
AUG 27, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
DNA Data Storage Evolution and Objectives
DNA data storage has evolved significantly since its conceptual introduction in the 1960s, transitioning from theoretical possibility to practical implementation. The foundational breakthrough came in 2012 when Church et al. demonstrated the feasibility of encoding and retrieving information in synthesized DNA molecules. This milestone established DNA as a viable alternative to conventional storage media, leveraging its inherent molecular stability and information density capabilities.
The evolution trajectory accelerated with Goldman's work in 2013, which introduced error correction mechanisms and redundancy protocols essential for reliable data retrieval. By 2015, researchers had achieved remarkable advancements in encoding algorithms, enabling more efficient conversion between binary and nucleotide-based information systems. The period between 2016-2019 witnessed substantial improvements in synthesis and sequencing technologies, dramatically reducing both cost and error rates.
Recent developments have focused on addressing scalability challenges, with notable progress in random-access methodologies that allow selective retrieval of specific data segments without processing entire DNA archives. Parallel advancements in enzymatic synthesis techniques have begun to replace traditional phosphoramidite chemistry approaches, promising significant cost reductions and throughput improvements.
The primary objective of DNA data storage research centers on maximizing storage density while maintaining data integrity. Theoretical frameworks suggest DNA could potentially store up to 455 exabytes per gram, vastly surpassing conventional electronic media. However, realizing this potential requires overcoming several technical barriers, including synthesis limitations, sequencing accuracy, and practical retrieval mechanisms.
Current research objectives include developing robust encoding schemes that optimize the inherent quaternary nature of DNA's four nucleotides while minimizing homopolymer sequences that cause synthesis and sequencing errors. Additionally, researchers aim to establish standardized theoretical frameworks for evaluating storage density limits under various biochemical constraints and environmental conditions.
Long-term objectives extend to creating comprehensive systems that integrate DNA storage with traditional computing architectures, establishing protocols for data migration, and developing hybrid systems that leverage the complementary strengths of electronic and molecular storage paradigms. The field is increasingly focused on practical implementation strategies that could transition DNA storage from laboratory demonstrations to commercial viability within the next decade.
The convergence of synthetic biology, information theory, and materials science continues to drive innovation in this domain, with interdisciplinary collaboration emerging as a critical factor in addressing the complex challenges of DNA-based information storage systems.
The evolution trajectory accelerated with Goldman's work in 2013, which introduced error correction mechanisms and redundancy protocols essential for reliable data retrieval. By 2015, researchers had achieved remarkable advancements in encoding algorithms, enabling more efficient conversion between binary and nucleotide-based information systems. The period between 2016-2019 witnessed substantial improvements in synthesis and sequencing technologies, dramatically reducing both cost and error rates.
Recent developments have focused on addressing scalability challenges, with notable progress in random-access methodologies that allow selective retrieval of specific data segments without processing entire DNA archives. Parallel advancements in enzymatic synthesis techniques have begun to replace traditional phosphoramidite chemistry approaches, promising significant cost reductions and throughput improvements.
The primary objective of DNA data storage research centers on maximizing storage density while maintaining data integrity. Theoretical frameworks suggest DNA could potentially store up to 455 exabytes per gram, vastly surpassing conventional electronic media. However, realizing this potential requires overcoming several technical barriers, including synthesis limitations, sequencing accuracy, and practical retrieval mechanisms.
Current research objectives include developing robust encoding schemes that optimize the inherent quaternary nature of DNA's four nucleotides while minimizing homopolymer sequences that cause synthesis and sequencing errors. Additionally, researchers aim to establish standardized theoretical frameworks for evaluating storage density limits under various biochemical constraints and environmental conditions.
Long-term objectives extend to creating comprehensive systems that integrate DNA storage with traditional computing architectures, establishing protocols for data migration, and developing hybrid systems that leverage the complementary strengths of electronic and molecular storage paradigms. The field is increasingly focused on practical implementation strategies that could transition DNA storage from laboratory demonstrations to commercial viability within the next decade.
The convergence of synthetic biology, information theory, and materials science continues to drive innovation in this domain, with interdisciplinary collaboration emerging as a critical factor in addressing the complex challenges of DNA-based information storage systems.
Market Analysis for Biological Data Storage Solutions
The global biological data storage market is experiencing unprecedented growth, driven by the exponential increase in data generation across sectors. Current projections estimate the DNA data storage market to reach $3.5 billion by 2030, with a compound annual growth rate of approximately 58% between 2023 and 2030. This remarkable growth trajectory reflects the urgent need for alternative storage solutions as conventional technologies approach their physical limits.
Healthcare and life sciences represent the largest market segment, accounting for nearly 40% of potential applications. The genomic sequencing revolution alone generates petabytes of data annually, creating immediate demand for high-density, long-term storage solutions. Pharmaceutical companies are particularly interested in DNA storage for preserving valuable research data and intellectual property that must be retained for decades.
Government and defense sectors constitute the second-largest market segment, with intelligence agencies and national archives exploring DNA storage for classified information and historical records. These institutions value DNA's exceptional durability and security features, with estimated investments of $800 million projected by 2028.
Commercial cloud service providers represent the fastest-growing segment, with major players like Microsoft, Google, and Amazon actively developing DNA storage capabilities to address their massive data center requirements. Industry analysts predict that by 2035, up to 15% of archival cold storage could transition to molecular-based systems.
Geographically, North America leads the market with approximately 45% share, followed by Europe (30%) and Asia-Pacific (20%). The Asia-Pacific region, particularly China and Singapore, demonstrates the highest growth rate as national initiatives prioritize next-generation data storage technologies.
Customer willingness to adopt DNA storage varies significantly by application. Mission-critical archival storage commands premium pricing, with early adopters willing to pay up to 20 times current storage costs for irreplaceable data. However, mainstream adoption requires cost reduction to approximately $1000 per terabyte to compete with magnetic tape systems.
Market barriers include high synthesis and sequencing costs, technical complexity, and regulatory uncertainties regarding biosecurity. Despite these challenges, venture capital investment in DNA storage startups exceeded $650 million in 2022, indicating strong confidence in the technology's commercial potential.
The market demonstrates classic early-adopter characteristics, with specialized applications driving initial commercialization while broader applications await cost reductions and standardization. Industry consortia are forming to establish technical standards and protocols, which will be crucial for market expansion beyond niche applications.
Healthcare and life sciences represent the largest market segment, accounting for nearly 40% of potential applications. The genomic sequencing revolution alone generates petabytes of data annually, creating immediate demand for high-density, long-term storage solutions. Pharmaceutical companies are particularly interested in DNA storage for preserving valuable research data and intellectual property that must be retained for decades.
Government and defense sectors constitute the second-largest market segment, with intelligence agencies and national archives exploring DNA storage for classified information and historical records. These institutions value DNA's exceptional durability and security features, with estimated investments of $800 million projected by 2028.
Commercial cloud service providers represent the fastest-growing segment, with major players like Microsoft, Google, and Amazon actively developing DNA storage capabilities to address their massive data center requirements. Industry analysts predict that by 2035, up to 15% of archival cold storage could transition to molecular-based systems.
Geographically, North America leads the market with approximately 45% share, followed by Europe (30%) and Asia-Pacific (20%). The Asia-Pacific region, particularly China and Singapore, demonstrates the highest growth rate as national initiatives prioritize next-generation data storage technologies.
Customer willingness to adopt DNA storage varies significantly by application. Mission-critical archival storage commands premium pricing, with early adopters willing to pay up to 20 times current storage costs for irreplaceable data. However, mainstream adoption requires cost reduction to approximately $1000 per terabyte to compete with magnetic tape systems.
Market barriers include high synthesis and sequencing costs, technical complexity, and regulatory uncertainties regarding biosecurity. Despite these challenges, venture capital investment in DNA storage startups exceeded $650 million in 2022, indicating strong confidence in the technology's commercial potential.
The market demonstrates classic early-adopter characteristics, with specialized applications driving initial commercialization while broader applications await cost reductions and standardization. Industry consortia are forming to establish technical standards and protocols, which will be crucial for market expansion beyond niche applications.
Current Density Limits and Technical Barriers
DNA data storage technology currently achieves practical density levels of approximately 10^15 bytes per cubic millimeter, which is several orders of magnitude higher than conventional electronic storage media. However, this remains significantly below the theoretical maximum density of 10^18 bytes per cubic millimeter that DNA could potentially support. This gap represents one of the fundamental challenges in the field.
The primary technical barrier limiting current DNA storage density is the error rate in DNA synthesis and sequencing processes. Current DNA synthesis technologies exhibit error rates of approximately 1 in 100 to 1 in 200 bases, necessitating substantial redundancy in stored information to ensure data integrity. This redundancy directly reduces the effective storage density achievable in practical systems.
Molecular stability presents another significant challenge. While DNA can theoretically remain stable for thousands of years under ideal conditions, practical storage environments often accelerate degradation. Chemical processes such as depurination and oxidation can damage DNA molecules over time, requiring additional error correction mechanisms that further reduce effective storage density.
Physical handling limitations also constrain current density achievements. The manipulation of DNA at nanoscale requires specialized equipment and techniques that have not yet been optimized for high-throughput data operations. Current methods for random access to specific data segments within DNA archives remain inefficient, requiring either extensive indexing schemes or complete sequencing of large portions of the archive.
Encoding and decoding complexity represents a significant technical barrier. Current algorithms must balance information density against error resilience, often sacrificing theoretical maximum density for practical reliability. The computational overhead for encoding and decoding increases exponentially with higher density encoding schemes.
Cost factors further limit practical density implementations. While DNA synthesis costs have decreased dramatically from approximately $1 per base in 2000 to about $0.001 per base today, this remains prohibitively expensive for large-scale data storage applications. Similarly, sequencing costs, though reduced, still present economic barriers to achieving maximum theoretical densities.
Biochemical constraints, particularly related to DNA secondary structure formation and sequence-dependent synthesis efficiency, impose additional limitations on achievable density. Certain DNA sequences are inherently more difficult to synthesize accurately, creating practical constraints on the information patterns that can be reliably encoded.
The primary technical barrier limiting current DNA storage density is the error rate in DNA synthesis and sequencing processes. Current DNA synthesis technologies exhibit error rates of approximately 1 in 100 to 1 in 200 bases, necessitating substantial redundancy in stored information to ensure data integrity. This redundancy directly reduces the effective storage density achievable in practical systems.
Molecular stability presents another significant challenge. While DNA can theoretically remain stable for thousands of years under ideal conditions, practical storage environments often accelerate degradation. Chemical processes such as depurination and oxidation can damage DNA molecules over time, requiring additional error correction mechanisms that further reduce effective storage density.
Physical handling limitations also constrain current density achievements. The manipulation of DNA at nanoscale requires specialized equipment and techniques that have not yet been optimized for high-throughput data operations. Current methods for random access to specific data segments within DNA archives remain inefficient, requiring either extensive indexing schemes or complete sequencing of large portions of the archive.
Encoding and decoding complexity represents a significant technical barrier. Current algorithms must balance information density against error resilience, often sacrificing theoretical maximum density for practical reliability. The computational overhead for encoding and decoding increases exponentially with higher density encoding schemes.
Cost factors further limit practical density implementations. While DNA synthesis costs have decreased dramatically from approximately $1 per base in 2000 to about $0.001 per base today, this remains prohibitively expensive for large-scale data storage applications. Similarly, sequencing costs, though reduced, still present economic barriers to achieving maximum theoretical densities.
Biochemical constraints, particularly related to DNA secondary structure formation and sequence-dependent synthesis efficiency, impose additional limitations on achievable density. Certain DNA sequences are inherently more difficult to synthesize accurately, creating practical constraints on the information patterns that can be reliably encoded.
Existing DNA Encoding and Decoding Methodologies
01 High-density DNA storage techniques
Advanced techniques for achieving high-density DNA data storage involve specialized encoding methods and molecular structures that maximize information storage capacity. These approaches can achieve theoretical storage densities several orders of magnitude higher than conventional electronic storage media. By optimizing nucleotide sequences and developing novel DNA architectures, researchers have created systems capable of storing petabytes of data in minimal physical space, demonstrating DNA's potential as an ultra-compact storage medium.- High-density DNA storage techniques: Advanced techniques for achieving high-density DNA data storage involve specialized encoding methods and molecular structures that maximize information storage capacity. These approaches enable packing more data into smaller DNA volumes by optimizing nucleotide sequences and developing novel storage architectures. Such techniques can achieve storage densities that far exceed conventional electronic storage media, with theoretical limits approaching exabytes per gram of DNA.
- DNA sequencing and retrieval methods for data storage: Efficient sequencing and retrieval methods are crucial for practical DNA data storage systems. These methods include advanced reading technologies that can accurately decode information stored in DNA molecules, error correction mechanisms to ensure data integrity, and indexing systems that allow for selective access to specific data segments without sequencing the entire DNA archive. These approaches enhance the reliability and accessibility of data stored in DNA.
- DNA storage system architectures: Comprehensive system architectures for DNA data storage include integrated solutions that address the entire workflow from encoding digital data to DNA, physical storage of DNA molecules, and retrieval and decoding of the stored information. These architectures incorporate specialized hardware and software components designed to optimize storage density while maintaining data integrity and accessibility. Some systems employ hierarchical storage structures to balance density, cost, and retrieval speed.
- Encoding algorithms for DNA data storage: Specialized encoding algorithms transform digital data into DNA nucleotide sequences while maximizing storage density and minimizing error rates. These algorithms address challenges specific to DNA storage, such as avoiding repetitive sequences that can cause synthesis errors, balancing GC content, and implementing robust error correction codes. Advanced encoding schemes can incorporate multiple layers of redundancy while maintaining high information density.
- Physical storage and preservation of DNA data: Methods for physically storing and preserving DNA molecules are essential for maintaining data integrity over long periods. These include encapsulation techniques that protect DNA from environmental degradation, specialized storage media that maintain optimal conditions for DNA stability, and preservation protocols that prevent chemical or biological breakdown of the molecules. Such approaches enable theoretical storage lifespans of thousands of years while maintaining the high storage density inherent to DNA.
02 DNA encoding and decoding methods for data storage
Specific encoding and decoding algorithms have been developed to efficiently translate digital information into DNA sequences and back. These methods address challenges such as error correction, sequence optimization, and data retrieval efficiency. By implementing sophisticated coding schemes, researchers can maximize storage density while ensuring data integrity and recoverability. These approaches often incorporate redundancy mechanisms and specialized sequence designs to overcome the biological limitations of DNA storage systems.Expand Specific Solutions03 Physical storage architectures for DNA data
Various physical architectures have been developed for organizing and accessing DNA-stored data. These include microfluidic systems, nanopore arrays, and specialized storage containers that maintain DNA integrity while facilitating rapid access. The physical organization of DNA molecules plays a crucial role in achieving maximum storage density while maintaining practical usability. These architectures often incorporate innovative approaches to DNA synthesis, storage, and retrieval to optimize the overall system performance.Expand Specific Solutions04 Error correction and data integrity in high-density DNA storage
Maintaining data integrity at high storage densities requires specialized error correction mechanisms. These include redundancy coding, sequence optimization to avoid error-prone patterns, and sophisticated error detection algorithms. By implementing these techniques, DNA storage systems can achieve reliable data preservation despite the inherent biological challenges of DNA synthesis, storage, and sequencing. These approaches balance the trade-off between maximum storage density and necessary error correction overhead.Expand Specific Solutions05 Scalable DNA synthesis and sequencing for high-density storage
Advancements in DNA synthesis and sequencing technologies are critical for practical high-density DNA data storage. These include parallel synthesis methods, high-throughput sequencing platforms, and automated systems for DNA manipulation. By improving the efficiency and accuracy of these processes, researchers can achieve higher effective storage densities while reducing the cost and time required for data writing and reading operations. These technological improvements are essential for making DNA data storage commercially viable at scale.Expand Specific Solutions
Leading Research Institutions and Commercial Entities
DNA data storage technology is currently in an early development phase, with significant research momentum but limited commercial deployment. The market is projected to grow substantially, potentially reaching billions of dollars by 2030 as storage density approaches theoretical limits of 1 exabyte per cubic centimeter. Leading academic institutions (MIT, University of Washington, Tsinghua University) are collaborating with technology giants (Microsoft, Seagate) to overcome key challenges. Companies like Iridia and Molecular Assemblies are developing enzymatic synthesis methods, while BGI and Integrated DNA Technologies focus on sequencing technologies. The competitive landscape features diverse approaches: Microsoft emphasizes algorithmic efficiency, Huawei explores hybrid systems, and startups like Roswell ME develop novel molecular recording techniques. Technical maturity varies across encoding/decoding methods, synthesis technologies, and storage architectures, with most solutions at TRL 3-5.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft has developed a comprehensive DNA data storage system called "Molecular Information Storage" (MIST) that addresses storage density limits through several innovations. Their approach uses enzymatic synthesis rather than traditional phosphoramidite chemistry, enabling longer DNA strands with fewer errors. Microsoft's system achieves theoretical storage densities approaching 1 exabyte per cubic centimeter by optimizing encoding schemes that maximize information density while maintaining error correction capabilities. Their framework incorporates a layered architecture with specialized encoding algorithms that adapt to DNA's unique properties, including addressing homopolymer challenges and GC content balancing. Microsoft has demonstrated practical implementations achieving 200-250 petabytes per gram of DNA, approaching the theoretical limit of 455 exabytes per gram. Their system includes novel random access methods using PCR-based selective retrieval with minimal cross-contamination, enabling practical data retrieval without sequencing entire DNA pools.
Strengths: Industry-leading integration of enzymatic synthesis with advanced encoding algorithms; demonstrated practical implementations approaching theoretical limits; strong error correction capabilities. Weaknesses: Still requires significant cost reduction to become commercially viable; enzymatic synthesis speed remains a bottleneck for large-scale deployment.
Massachusetts Institute of Technology
Technical Solution: MIT has pioneered theoretical frameworks for DNA data storage that push the boundaries of storage density limits. Their approach centers on a mathematical model that optimizes the trade-off between information density and error rates in DNA storage systems. MIT researchers have developed novel encoding schemes that achieve near-Shannon capacity limits for DNA storage channels, enabling theoretical densities of up to 10^20 bits per gram. Their framework incorporates sophisticated error correction codes specifically designed for the unique error profiles of DNA synthesis and sequencing. MIT has also advanced the concept of "molecular indexing" that enables random access to stored data without sequencing entire DNA pools, significantly improving retrieval efficiency. Their research includes innovative approaches to DNA origami structures that can increase spatial organization of DNA molecules, potentially increasing practical storage density by an order of magnitude beyond current implementations. MIT's theoretical work has established fundamental limits on achievable storage density considering molecular stability, synthesis constraints, and thermodynamic boundaries.
Strengths: World-class theoretical foundations; innovative encoding schemes approaching information-theoretic limits; pioneering work on molecular indexing for efficient data retrieval. Weaknesses: Some theoretical approaches remain challenging to implement with current synthesis technologies; focus on theoretical frameworks sometimes outpaces practical implementations.
Breakthrough Research in DNA Storage Density
Error correction for nucleotide data stores
PatentWO2017083177A1
Innovation
- The implementation of an error correction method using invertible summary operations, such as the exclusive or (XOR) operation, is applied to generate error-correction sequences that provide redundancy, allowing for the regeneration of missing or corrupted data by combining summary information with partial input data, thereby enhancing data integrity and reliability.
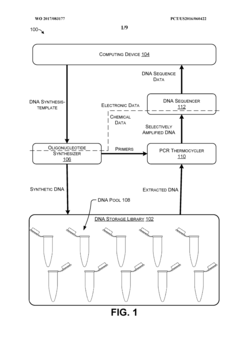
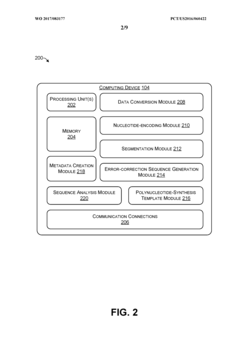
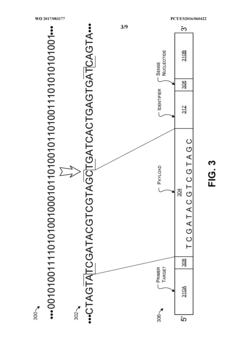
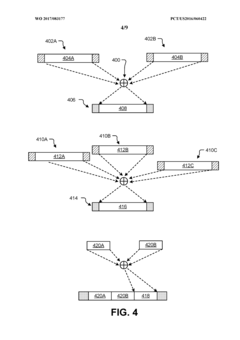
Trace reconstruction of polymer sequences using quality scores
PatentWO2021086734A1
Innovation
- The implementation of a trace reconstruction method using quality scores from sequencers for weighted majority voting to generate a consensus output sequence, which improves the accuracy of error correction by leveraging confidence levels in nucleotide reads.
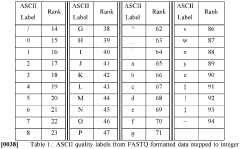
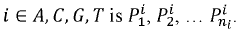
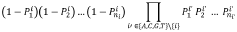

Bioinformatics Infrastructure Requirements
The implementation of DNA data storage systems requires robust bioinformatics infrastructure to handle the complex processes of encoding, synthesizing, storing, retrieving, and decoding DNA-based data. Current computational frameworks must be significantly enhanced to manage the unique challenges presented by DNA as a storage medium.
High-performance computing systems are essential for processing the massive datasets involved in DNA storage operations. These systems need to handle both the encoding algorithms that convert binary data to nucleotide sequences and the decoding processes that translate sequenced DNA back to digital information. The computational requirements increase exponentially with storage capacity, necessitating scalable architecture designs that can evolve alongside advances in DNA synthesis and sequencing technologies.
Database management systems specifically optimized for DNA storage applications represent another critical infrastructure component. These systems must efficiently index and retrieve DNA-based information while maintaining data integrity across multiple read-write cycles. Traditional database architectures are inadequate for handling the unique error profiles and access patterns of DNA storage, requiring novel approaches to data organization and retrieval mechanisms.
Error correction frameworks constitute a fundamental element of the bioinformatics infrastructure. DNA storage inherently introduces various types of errors during synthesis, storage, and sequencing processes. Sophisticated error detection and correction algorithms must be integrated into the infrastructure to ensure data reliability. These algorithms need to address insertion, deletion, and substitution errors that occur at rates significantly higher than in conventional digital storage media.
Specialized software tools for sequence alignment, assembly, and analysis form another layer of the required infrastructure. These tools must be adapted to handle the specific characteristics of synthetic DNA designed for data storage rather than naturally occurring genomic sequences. The software ecosystem should support both wet-lab operations and in silico data processing with seamless integration between these domains.
Cloud-based infrastructure solutions offer promising approaches for democratizing access to DNA data storage technologies. By providing scalable computational resources and standardized bioinformatics pipelines, cloud platforms can reduce the entry barriers for organizations interested in adopting DNA storage solutions. However, these platforms must address the substantial bandwidth requirements for transferring data between physical DNA repositories and computational resources.
Security and privacy frameworks represent essential components of the bioinformatics infrastructure. As DNA storage potentially handles sensitive information, robust encryption methods and access control mechanisms must be implemented throughout the storage and retrieval workflow. These security measures should be designed specifically for the unique characteristics of DNA-based information systems.
High-performance computing systems are essential for processing the massive datasets involved in DNA storage operations. These systems need to handle both the encoding algorithms that convert binary data to nucleotide sequences and the decoding processes that translate sequenced DNA back to digital information. The computational requirements increase exponentially with storage capacity, necessitating scalable architecture designs that can evolve alongside advances in DNA synthesis and sequencing technologies.
Database management systems specifically optimized for DNA storage applications represent another critical infrastructure component. These systems must efficiently index and retrieve DNA-based information while maintaining data integrity across multiple read-write cycles. Traditional database architectures are inadequate for handling the unique error profiles and access patterns of DNA storage, requiring novel approaches to data organization and retrieval mechanisms.
Error correction frameworks constitute a fundamental element of the bioinformatics infrastructure. DNA storage inherently introduces various types of errors during synthesis, storage, and sequencing processes. Sophisticated error detection and correction algorithms must be integrated into the infrastructure to ensure data reliability. These algorithms need to address insertion, deletion, and substitution errors that occur at rates significantly higher than in conventional digital storage media.
Specialized software tools for sequence alignment, assembly, and analysis form another layer of the required infrastructure. These tools must be adapted to handle the specific characteristics of synthetic DNA designed for data storage rather than naturally occurring genomic sequences. The software ecosystem should support both wet-lab operations and in silico data processing with seamless integration between these domains.
Cloud-based infrastructure solutions offer promising approaches for democratizing access to DNA data storage technologies. By providing scalable computational resources and standardized bioinformatics pipelines, cloud platforms can reduce the entry barriers for organizations interested in adopting DNA storage solutions. However, these platforms must address the substantial bandwidth requirements for transferring data between physical DNA repositories and computational resources.
Security and privacy frameworks represent essential components of the bioinformatics infrastructure. As DNA storage potentially handles sensitive information, robust encryption methods and access control mechanisms must be implemented throughout the storage and retrieval workflow. These security measures should be designed specifically for the unique characteristics of DNA-based information systems.
Biosecurity and Data Integrity Considerations
DNA data storage systems present unique biosecurity challenges that extend beyond traditional digital storage concerns. The manipulation of genetic material for data storage raises significant biosecurity risks, including the potential creation of harmful biological sequences. Malicious actors could theoretically encode dangerous pathogen genomes or toxin synthesis instructions within DNA storage systems, creating bioweapons vectors that bypass traditional biosecurity screening methods. This risk is amplified by the increasing accessibility of DNA synthesis technologies and the difficulty in distinguishing between benign data-encoding DNA and sequences with biological functionality.
Data integrity in DNA storage faces distinctive challenges due to the biological nature of the medium. Natural degradation processes can introduce errors over time, with oxidation, hydrolysis, and radiation exposure potentially altering nucleotide sequences. These physical vulnerabilities necessitate robust error correction mechanisms specifically designed for the unique error profiles of DNA storage. Unlike traditional digital storage, DNA-based systems must account for insertion, deletion, and substitution errors that occur at different rates depending on sequence context and storage conditions.
Encryption and access control present another critical dimension for DNA data storage security. Conventional cryptographic approaches require adaptation for the biological medium, as DNA's physical properties and synthesis/sequencing constraints create unique implementation challenges. Researchers are developing DNA-specific encryption protocols that maintain data security while remaining compatible with biological processing steps. These systems must balance security requirements with the practical limitations of DNA synthesis, sequencing throughput, and error rates.
Regulatory frameworks for DNA data storage remain underdeveloped, creating potential biosecurity gaps. Current regulations governing synthetic DNA primarily focus on known pathogen sequences rather than encrypted or encoded data. The dual-use nature of DNA storage technology—serving both legitimate data archiving needs and potential misuse—complicates regulatory approaches. International coordination is essential to establish comprehensive oversight mechanisms that address both biosecurity and data protection concerns without impeding technological advancement.
Environmental considerations also intersect with biosecurity in DNA storage systems. Containment protocols must prevent accidental release of synthetic DNA into natural environments, where unintended biological interactions could occur. Additionally, secure disposal methods for DNA-encoded data must be developed to prevent unauthorized recovery of sensitive information from discarded materials. These environmental safeguards represent an important dimension of the overall biosecurity framework for DNA data storage technologies.
Data integrity in DNA storage faces distinctive challenges due to the biological nature of the medium. Natural degradation processes can introduce errors over time, with oxidation, hydrolysis, and radiation exposure potentially altering nucleotide sequences. These physical vulnerabilities necessitate robust error correction mechanisms specifically designed for the unique error profiles of DNA storage. Unlike traditional digital storage, DNA-based systems must account for insertion, deletion, and substitution errors that occur at different rates depending on sequence context and storage conditions.
Encryption and access control present another critical dimension for DNA data storage security. Conventional cryptographic approaches require adaptation for the biological medium, as DNA's physical properties and synthesis/sequencing constraints create unique implementation challenges. Researchers are developing DNA-specific encryption protocols that maintain data security while remaining compatible with biological processing steps. These systems must balance security requirements with the practical limitations of DNA synthesis, sequencing throughput, and error rates.
Regulatory frameworks for DNA data storage remain underdeveloped, creating potential biosecurity gaps. Current regulations governing synthetic DNA primarily focus on known pathogen sequences rather than encrypted or encoded data. The dual-use nature of DNA storage technology—serving both legitimate data archiving needs and potential misuse—complicates regulatory approaches. International coordination is essential to establish comprehensive oversight mechanisms that address both biosecurity and data protection concerns without impeding technological advancement.
Environmental considerations also intersect with biosecurity in DNA storage systems. Containment protocols must prevent accidental release of synthetic DNA into natural environments, where unintended biological interactions could occur. Additionally, secure disposal methods for DNA-encoded data must be developed to prevent unauthorized recovery of sensitive information from discarded materials. These environmental safeguards represent an important dimension of the overall biosecurity framework for DNA data storage technologies.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!