Lessons Learned From Pilot Deployments Of DNA Data Storage
AUG 27, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
DNA Data Storage Evolution and Objectives
DNA data storage has evolved from a theoretical concept to a promising solution for long-term data archiving over the past few decades. The journey began in 1988 when scientists first demonstrated the possibility of storing information in DNA. However, significant advancements only emerged in the early 2010s when researchers at Harvard University successfully stored a 659-kB book in DNA, marking a pivotal moment in the field's development.
The evolution accelerated with the introduction of next-generation sequencing technologies, which dramatically reduced the cost of DNA synthesis and sequencing. By 2016, Microsoft and the University of Washington had stored 200MB of data in DNA and successfully retrieved it, demonstrating the practical viability of this technology for data storage applications. This milestone represented a crucial step toward commercial feasibility.
Recent years have witnessed exponential growth in storage capacity and retrieval accuracy. The development of error-correction algorithms specifically designed for DNA storage has significantly enhanced data integrity, addressing one of the primary challenges in this field. Additionally, innovations in encoding schemes have improved storage density, allowing more information to be packed into shorter DNA sequences.
Pilot deployments have revealed valuable insights into the practical implementation of DNA data storage systems. These deployments have demonstrated the technology's exceptional durability, with data remaining intact under various environmental conditions that would destroy conventional storage media. However, they have also highlighted challenges related to scaling, cost efficiency, and integration with existing digital infrastructure.
The primary objective of DNA data storage research is to develop a commercially viable alternative to traditional storage technologies for long-term archival purposes. This includes reducing synthesis and sequencing costs to competitive levels, increasing storage density to theoretical limits, and developing standardized protocols for data encoding and retrieval. Current estimates suggest that DNA could potentially store all the world's digital information in a space the size of a standard shipping container.
Another critical objective is to enhance the accessibility of stored data through faster random access methods. Current pilot deployments have demonstrated that while DNA excels at data preservation, retrieval times remain significantly longer than electronic storage. Research efforts are focused on developing molecular techniques that allow for selective access to specific data segments without sequencing entire DNA pools.
Looking forward, the field aims to establish DNA data storage as a mainstream archival solution for critical data that requires centuries of preservation. This includes cultural heritage, scientific records, and governmental archives. The ultimate goal is to create a sustainable, energy-efficient storage medium that can preserve humanity's digital legacy for thousands of years.
The evolution accelerated with the introduction of next-generation sequencing technologies, which dramatically reduced the cost of DNA synthesis and sequencing. By 2016, Microsoft and the University of Washington had stored 200MB of data in DNA and successfully retrieved it, demonstrating the practical viability of this technology for data storage applications. This milestone represented a crucial step toward commercial feasibility.
Recent years have witnessed exponential growth in storage capacity and retrieval accuracy. The development of error-correction algorithms specifically designed for DNA storage has significantly enhanced data integrity, addressing one of the primary challenges in this field. Additionally, innovations in encoding schemes have improved storage density, allowing more information to be packed into shorter DNA sequences.
Pilot deployments have revealed valuable insights into the practical implementation of DNA data storage systems. These deployments have demonstrated the technology's exceptional durability, with data remaining intact under various environmental conditions that would destroy conventional storage media. However, they have also highlighted challenges related to scaling, cost efficiency, and integration with existing digital infrastructure.
The primary objective of DNA data storage research is to develop a commercially viable alternative to traditional storage technologies for long-term archival purposes. This includes reducing synthesis and sequencing costs to competitive levels, increasing storage density to theoretical limits, and developing standardized protocols for data encoding and retrieval. Current estimates suggest that DNA could potentially store all the world's digital information in a space the size of a standard shipping container.
Another critical objective is to enhance the accessibility of stored data through faster random access methods. Current pilot deployments have demonstrated that while DNA excels at data preservation, retrieval times remain significantly longer than electronic storage. Research efforts are focused on developing molecular techniques that allow for selective access to specific data segments without sequencing entire DNA pools.
Looking forward, the field aims to establish DNA data storage as a mainstream archival solution for critical data that requires centuries of preservation. This includes cultural heritage, scientific records, and governmental archives. The ultimate goal is to create a sustainable, energy-efficient storage medium that can preserve humanity's digital legacy for thousands of years.
Market Analysis for DNA Storage Solutions
The DNA data storage market is experiencing significant growth as organizations seek innovative solutions for long-term data preservation. Current market projections indicate the global DNA data storage market could reach $3.3 billion by 2030, with a compound annual growth rate exceeding 58% between 2023-2030. This remarkable growth trajectory is driven by the exponential increase in global data production, which is expected to reach 175 zettabytes by 2025, creating urgent demand for sustainable, high-density storage alternatives.
The market segmentation reveals distinct application sectors, with archival storage representing the largest current opportunity. Scientific research institutions, national archives, and cultural heritage organizations are early adopters, valuing DNA's exceptional durability for preserving irreplaceable data. The financial services sector shows increasing interest, particularly for regulatory compliance data that must be retained for decades.
Healthcare and life sciences represent another substantial market segment, with pharmaceutical companies and biobanks exploring DNA storage for clinical trial data and genetic information. The technology sector, including cloud service providers, is investing heavily in research partnerships to develop commercially viable solutions for cold storage tiers.
Geographically, North America dominates the current market landscape, accounting for approximately 45% of investments in DNA storage research and commercialization efforts. The European market follows at 30%, with significant government-backed initiatives in the UK, Switzerland, and Germany. The Asia-Pacific region is experiencing the fastest growth rate, with substantial investments from China and Japan in particular.
Customer demand analysis reveals several key priorities driving market interest. Storage density ranks as the primary advantage, with DNA's theoretical capacity reaching 455 exabytes per gram. Longevity is the second most valued attribute, with properly preserved DNA remaining readable for thousands of years compared to conventional media's typical 5-10 year lifespan.
Market barriers remain significant, with cost being the most prohibitive factor. Current DNA synthesis and sequencing costs range between $1,000-10,000 per megabyte, though this represents a dramatic improvement from previous years. Read/write speeds present another major limitation, with data retrieval typically requiring hours compared to milliseconds for electronic storage.
The competitive landscape features both established biotechnology companies and specialized startups. Key market players include Twist Bioscience, Illumina, and Microsoft Research, alongside emerging players like Catalog Technologies, DNA Script, and Iridia. Strategic partnerships between technology companies and biotechnology firms characterize the current market dynamics, with significant venture capital flowing into startups focused on addressing technical bottlenecks.
The market segmentation reveals distinct application sectors, with archival storage representing the largest current opportunity. Scientific research institutions, national archives, and cultural heritage organizations are early adopters, valuing DNA's exceptional durability for preserving irreplaceable data. The financial services sector shows increasing interest, particularly for regulatory compliance data that must be retained for decades.
Healthcare and life sciences represent another substantial market segment, with pharmaceutical companies and biobanks exploring DNA storage for clinical trial data and genetic information. The technology sector, including cloud service providers, is investing heavily in research partnerships to develop commercially viable solutions for cold storage tiers.
Geographically, North America dominates the current market landscape, accounting for approximately 45% of investments in DNA storage research and commercialization efforts. The European market follows at 30%, with significant government-backed initiatives in the UK, Switzerland, and Germany. The Asia-Pacific region is experiencing the fastest growth rate, with substantial investments from China and Japan in particular.
Customer demand analysis reveals several key priorities driving market interest. Storage density ranks as the primary advantage, with DNA's theoretical capacity reaching 455 exabytes per gram. Longevity is the second most valued attribute, with properly preserved DNA remaining readable for thousands of years compared to conventional media's typical 5-10 year lifespan.
Market barriers remain significant, with cost being the most prohibitive factor. Current DNA synthesis and sequencing costs range between $1,000-10,000 per megabyte, though this represents a dramatic improvement from previous years. Read/write speeds present another major limitation, with data retrieval typically requiring hours compared to milliseconds for electronic storage.
The competitive landscape features both established biotechnology companies and specialized startups. Key market players include Twist Bioscience, Illumina, and Microsoft Research, alongside emerging players like Catalog Technologies, DNA Script, and Iridia. Strategic partnerships between technology companies and biotechnology firms characterize the current market dynamics, with significant venture capital flowing into startups focused on addressing technical bottlenecks.
Current DNA Storage Technology Landscape
DNA data storage technology has evolved significantly over the past decade, with several key approaches currently dominating the landscape. The most prevalent method involves synthesizing DNA strands that encode digital information using the four nucleotide bases (A, T, G, C) as the storage medium. These synthetic DNA molecules are then preserved in controlled environments and can be retrieved and sequenced when data access is required.
Current commercial efforts are led by companies like Twist Bioscience, which provides DNA synthesis services, and Catalog Technologies, which has developed a unique encoding approach that separates the synthesis of DNA molecules from the encoding of information. Microsoft Research has also made significant strides through their partnership with the University of Washington in Project Parabricks, demonstrating practical DNA storage systems.
The technical capabilities of current DNA storage systems have reached impressive benchmarks. Recent pilot deployments have achieved storage densities exceeding 215 petabytes per gram of DNA, theoretical durability of thousands of years under proper storage conditions, and retrieval accuracy rates above 99% when employing robust error correction codes. However, these systems still face substantial challenges in write speeds (currently measured in kilobits per second) and read latency (hours to days).
Cost remains a significant barrier to widespread adoption, with current DNA synthesis costs at approximately $0.001 per base pair. This translates to roughly $100,000 per gigabyte of stored data, making it prohibitively expensive for most applications. Sequencing costs have decreased more rapidly than synthesis costs, following a trend similar to Moore's Law, but still represent a substantial expense in the storage ecosystem.
The infrastructure supporting DNA data storage is still largely confined to specialized laboratory environments. Pilot deployments typically utilize climate-controlled facilities with precise temperature and humidity regulation. Recent innovations have begun to address this limitation through the development of automated, miniaturized DNA synthesis and sequencing platforms that could eventually enable more accessible deployment scenarios.
Encoding and decoding algorithms have become increasingly sophisticated, with current approaches employing advanced error correction codes, addressing schemes for random access, and compression techniques specifically optimized for the constraints of DNA-based storage. These computational advances have significantly improved the practical viability of DNA storage systems despite the physical limitations of the underlying biochemical processes.
Current commercial efforts are led by companies like Twist Bioscience, which provides DNA synthesis services, and Catalog Technologies, which has developed a unique encoding approach that separates the synthesis of DNA molecules from the encoding of information. Microsoft Research has also made significant strides through their partnership with the University of Washington in Project Parabricks, demonstrating practical DNA storage systems.
The technical capabilities of current DNA storage systems have reached impressive benchmarks. Recent pilot deployments have achieved storage densities exceeding 215 petabytes per gram of DNA, theoretical durability of thousands of years under proper storage conditions, and retrieval accuracy rates above 99% when employing robust error correction codes. However, these systems still face substantial challenges in write speeds (currently measured in kilobits per second) and read latency (hours to days).
Cost remains a significant barrier to widespread adoption, with current DNA synthesis costs at approximately $0.001 per base pair. This translates to roughly $100,000 per gigabyte of stored data, making it prohibitively expensive for most applications. Sequencing costs have decreased more rapidly than synthesis costs, following a trend similar to Moore's Law, but still represent a substantial expense in the storage ecosystem.
The infrastructure supporting DNA data storage is still largely confined to specialized laboratory environments. Pilot deployments typically utilize climate-controlled facilities with precise temperature and humidity regulation. Recent innovations have begun to address this limitation through the development of automated, miniaturized DNA synthesis and sequencing platforms that could eventually enable more accessible deployment scenarios.
Encoding and decoding algorithms have become increasingly sophisticated, with current approaches employing advanced error correction codes, addressing schemes for random access, and compression techniques specifically optimized for the constraints of DNA-based storage. These computational advances have significantly improved the practical viability of DNA storage systems despite the physical limitations of the underlying biochemical processes.
Pilot Deployment Methodologies
01 DNA data storage encoding and decoding techniques
Various methods for encoding digital information into DNA sequences and decoding it back have been developed. These techniques involve converting binary data into nucleotide sequences using specific algorithms that optimize for storage density, error correction, and retrieval efficiency. Lessons learned include the importance of robust encoding schemes that can withstand the biological constraints of DNA synthesis and sequencing, as well as the need for efficient indexing systems to locate specific data within large DNA archives.- DNA-based data storage technologies: DNA molecules can be used as a medium for data storage due to their high density and long-term stability. These technologies involve encoding digital information into DNA sequences, which can then be synthesized, stored, and later sequenced to retrieve the original data. DNA data storage offers advantages such as exceptional information density, longevity, and energy efficiency compared to conventional electronic storage methods.
- Error correction and data integrity in DNA storage: Maintaining data integrity in DNA storage systems requires robust error correction mechanisms to address issues such as synthesis errors, sequencing errors, and DNA degradation over time. Various error correction coding schemes have been developed specifically for DNA storage to ensure reliable data retrieval. These approaches include redundancy encoding, specialized algorithms for DNA-specific error patterns, and methods to verify data integrity during both storage and retrieval processes.
- DNA data storage system architectures: The architecture of DNA data storage systems encompasses the overall design, including encoding/decoding methods, physical storage conditions, and retrieval mechanisms. Different architectural approaches address challenges such as random access to specific data segments, scalability, and integration with existing digital systems. These architectures may include indexing strategies, physical organization of DNA pools, and interfaces between digital and biological domains.
- Security and encryption in DNA data storage: Security considerations for DNA data storage include encryption methods specifically designed for biological media, access control mechanisms, and protection against unauthorized sequencing or data theft. Specialized encryption approaches have been developed that work within the constraints of DNA-based systems while providing robust security. These methods ensure that sensitive information stored in DNA remains protected throughout its lifecycle.
- Practical implementation challenges and solutions: Implementing DNA data storage systems faces practical challenges including cost, speed of data writing and reading, scalability, and integration with existing IT infrastructure. Solutions include improved synthesis and sequencing technologies, standardized interfaces, and hybrid approaches that combine the benefits of electronic and DNA-based storage. Lessons learned from early implementations have led to optimizations in protocols, workflows, and system designs to make DNA data storage more practical for real-world applications.
02 Error correction and data integrity in DNA storage
DNA storage systems face unique challenges related to data integrity due to synthesis errors, sequencing errors, and DNA degradation over time. Various error correction mechanisms have been implemented to ensure data reliability, including redundancy coding, parity checks, and specialized algorithms designed for the biological context. Lessons learned highlight the trade-off between storage density and error resilience, and the importance of developing error correction codes specifically tailored to the error profiles of DNA storage technologies.Expand Specific Solutions03 DNA data storage architecture and system design
The architecture of DNA data storage systems encompasses the physical storage medium, retrieval mechanisms, and the interface with conventional computing systems. Innovations include random access capabilities, hierarchical storage structures, and integration with existing data management frameworks. Key lessons learned relate to the importance of modular system design that can accommodate technological advances in DNA synthesis and sequencing, as well as the need for standardized interfaces between biological and digital components of the storage ecosystem.Expand Specific Solutions04 Longevity and stability of DNA-based storage
One of the primary advantages of DNA data storage is its potential for extremely long-term data preservation. Research has focused on methods to enhance the stability of stored DNA, including encapsulation techniques, preservation media, and controlled environmental conditions. Lessons learned emphasize the importance of proper sample preparation, storage conditions, and periodic refreshing strategies to maintain data integrity over centuries or millennia, as well as the need for standardized protocols for assessing DNA stability in storage applications.Expand Specific Solutions05 Scalability and commercialization challenges
The transition from laboratory demonstrations to practical, commercially viable DNA data storage systems faces significant challenges related to cost, throughput, and integration with existing infrastructure. Lessons learned include the critical importance of reducing DNA synthesis and sequencing costs, increasing the speed of data writing and reading operations, and developing automated workflows that minimize human intervention. Additionally, the establishment of industry standards and the creation of specialized hardware for DNA data operations have emerged as key factors for successful commercialization.Expand Specific Solutions
Key Industry Players in DNA Storage
DNA data storage technology is currently in an early development phase, transitioning from proof-of-concept to pilot deployments. The market remains nascent but shows significant growth potential, estimated to reach $35-40 billion by 2030. Technical maturity varies across key players: academic institutions (MIT, Tsinghua University, Tianjin University) focus on fundamental research; specialized companies (Catalog Technologies, Iridia, Roswell Biotechnologies) are developing commercial platforms; while established technology corporations (Microsoft, Western Digital, Seagate) are exploring integration possibilities. Current challenges include improving write/read speeds, reducing costs, and standardizing protocols. The ecosystem demonstrates a collaborative approach between academia, startups, and industry leaders, with recent pilot deployments providing valuable insights into practical implementation challenges and potential solutions for this promising archival storage technology.
Catalog Technologies, Inc.
Technical Solution: Catalog Technologies has developed a unique DNA data storage platform called CATALOG that separates the synthesis of DNA from the encoding of information. Their approach uses pre-synthesized DNA molecules as building blocks that can be assembled in different combinations to represent data, rather than synthesizing custom DNA sequences for each data point. This method significantly reduces the cost and time required for DNA data storage. In their pilot deployments, Catalog has demonstrated the ability to store 16GB of data in DNA, including books, images, and videos. Their Shannon prototype machine can write 4MB of data into DNA per day, with plans to scale to terabytes. Catalog's technology uses enzymatic approaches for both writing and reading DNA data, which offers advantages in speed and cost compared to traditional phosphoramidite chemistry methods. Their system includes specialized software for encoding/decoding and error correction to ensure data integrity across the storage lifecycle.
Strengths: Scalable approach that decouples synthesis from encoding, reducing costs; higher throughput than traditional methods; enzymatic processes that are more environmentally friendly. Weaknesses: Still faces challenges in read/write speeds compared to electronic storage; requires specialized equipment and expertise; current deployment scale remains limited compared to commercial data storage needs.
Battelle Memorial Institute
Technical Solution: Battelle Memorial Institute has pioneered significant advancements in DNA data storage through their pilot deployments focusing on long-term archival applications. Their approach utilizes a robust encoding scheme that converts digital binary data into DNA nucleotide sequences with sophisticated error correction mechanisms. Battelle's system incorporates a multi-layer preservation strategy where data is stored in dehydrated DNA encapsulated in specialized protective matrices that shield the molecules from environmental degradation. Their pilot deployments have demonstrated successful recovery of data after accelerated aging tests equivalent to hundreds of years of storage. Battelle has also developed automated microfluidic systems for DNA synthesis and sequencing that improve the efficiency of the write and read processes. Their technology includes specialized software algorithms for encoding/decoding that maximize information density while maintaining data integrity. Battelle's approach emphasizes security features, including molecular encryption techniques that provide an additional layer of data protection beyond traditional digital security measures.
Strengths: Exceptional long-term stability with demonstrated preservation capabilities; robust error correction systems; integrated security features at the molecular level. Weaknesses: Higher cost per megabyte compared to conventional storage; relatively slow data access times; requires specialized laboratory infrastructure for data retrieval operations.
Technical Breakthroughs in DNA Encoding
Automatic identification, definition and management of data for DNA storage systems
PatentActiveUS10963469B2
Innovation
- A DNA storage support process and component that defines 'apocalypse day data' (ADD) characteristics, integrating with existing storage management tools to prioritize data assets for optimal storage in DNA systems, using a data classifier and policy manager to automatically identify and recommend data for DNA storage based on cost, value, and volume considerations.
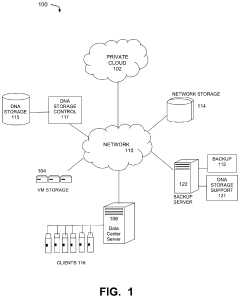
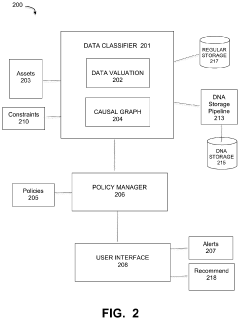
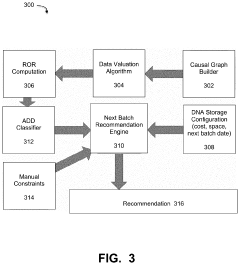
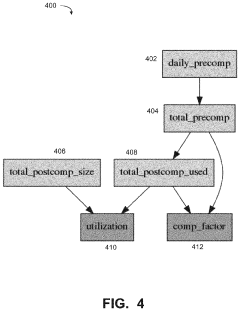
DNA data storage using reusable nucleic acids
PatentActiveUS11308055B2
Innovation
- The use of nucleic acid-based data storage systems where each data storage nucleic acid represents a bit-mer sequence that encodes information and its position within a bit string, allowing for reusable nucleic acid sequences to be used, enabling efficient storage and retrieval by pooling and indexing nucleic acids with primer binding sequences for selective amplification.
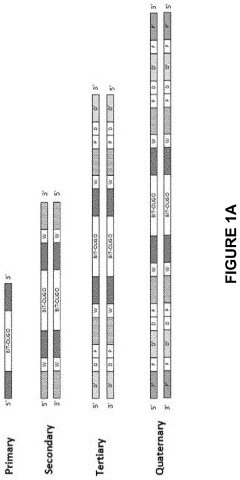
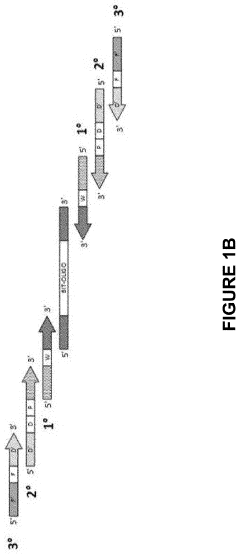
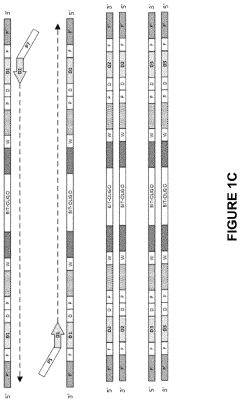
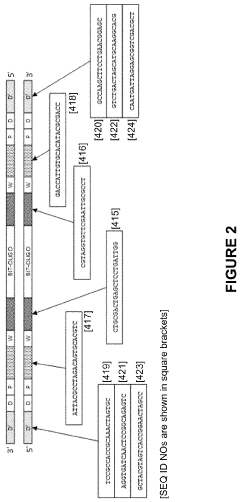
Scalability Challenges and Solutions
DNA data storage pilot deployments have revealed significant scalability challenges that must be addressed before widespread commercial adoption. The most pressing issue is the throughput limitation in both writing and reading processes. Current DNA synthesis methods achieve only kilobytes to megabytes per day, falling far short of the gigabyte to terabyte requirements of modern data centers. This bottleneck creates prohibitive time constraints for large-scale data operations.
Cost factors present another major scalability barrier. Despite decreasing costs in DNA synthesis, current expenses remain at approximately $1,000 per megabyte, making it economically unfeasible for most applications. Industry projections suggest costs must decrease by 5-6 orders of magnitude to compete with conventional storage technologies.
Physical infrastructure requirements pose additional challenges. Pilot deployments have demonstrated that specialized laboratory environments, equipment, and expertise are necessary for DNA data operations. The transition from controlled laboratory settings to standardized data center environments requires significant engineering solutions to ensure reliability and integration with existing systems.
Error rates and quality control mechanisms represent critical technical hurdles. As storage volume increases, maintaining acceptable error thresholds becomes increasingly difficult. Pilot deployments have shown that scaling up synthesis and sequencing processes often leads to higher error rates, necessitating more sophisticated error correction algorithms and quality assurance protocols.
Several promising solutions have emerged from these pilot experiences. Microfluidic automation technologies are being developed to parallelize DNA synthesis and sequencing processes, potentially increasing throughput by orders of magnitude. Companies like Catalog DNA have demonstrated custom-designed DNA writing machines that significantly improve writing speeds through novel enzymatic approaches.
Algorithmic improvements in encoding and error correction are proving essential for scalability. Advanced encoding schemes that maximize information density while maintaining robustness against errors have shown promising results in pilot deployments. Additionally, machine learning approaches for error detection and correction are demonstrating improved accuracy rates at scale.
Standardization efforts represent another crucial development path. Industry consortia are working to establish common interfaces, protocols, and quality metrics to facilitate integration of DNA storage systems with conventional IT infrastructure. These standards will be essential for transitioning from isolated pilot projects to enterprise-ready storage solutions.
Cost factors present another major scalability barrier. Despite decreasing costs in DNA synthesis, current expenses remain at approximately $1,000 per megabyte, making it economically unfeasible for most applications. Industry projections suggest costs must decrease by 5-6 orders of magnitude to compete with conventional storage technologies.
Physical infrastructure requirements pose additional challenges. Pilot deployments have demonstrated that specialized laboratory environments, equipment, and expertise are necessary for DNA data operations. The transition from controlled laboratory settings to standardized data center environments requires significant engineering solutions to ensure reliability and integration with existing systems.
Error rates and quality control mechanisms represent critical technical hurdles. As storage volume increases, maintaining acceptable error thresholds becomes increasingly difficult. Pilot deployments have shown that scaling up synthesis and sequencing processes often leads to higher error rates, necessitating more sophisticated error correction algorithms and quality assurance protocols.
Several promising solutions have emerged from these pilot experiences. Microfluidic automation technologies are being developed to parallelize DNA synthesis and sequencing processes, potentially increasing throughput by orders of magnitude. Companies like Catalog DNA have demonstrated custom-designed DNA writing machines that significantly improve writing speeds through novel enzymatic approaches.
Algorithmic improvements in encoding and error correction are proving essential for scalability. Advanced encoding schemes that maximize information density while maintaining robustness against errors have shown promising results in pilot deployments. Additionally, machine learning approaches for error detection and correction are demonstrating improved accuracy rates at scale.
Standardization efforts represent another crucial development path. Industry consortia are working to establish common interfaces, protocols, and quality metrics to facilitate integration of DNA storage systems with conventional IT infrastructure. These standards will be essential for transitioning from isolated pilot projects to enterprise-ready storage solutions.
Regulatory Framework for Biological Data Systems
The regulatory landscape for DNA data storage systems is evolving rapidly as this emerging technology transitions from laboratory experiments to pilot deployments. Current regulatory frameworks were primarily designed for conventional digital storage systems and biotechnology applications separately, creating significant gaps when these domains converge. The FDA, EPA, and Department of Energy have begun developing preliminary guidelines for biological data systems, though comprehensive regulations remain underdeveloped.
Key regulatory considerations include biosafety protocols that address potential environmental impacts of synthetic DNA used for data storage. These protocols typically require physical containment measures, non-viable DNA constructs, and regular safety assessments. Several pilot deployments have demonstrated compliance with these requirements through specialized laboratory facilities and modified DNA structures that cannot replicate in natural environments.
Data security and privacy regulations present unique challenges for DNA storage systems. While traditional data protection frameworks like GDPR and HIPAA apply conceptually, their implementation requires novel approaches. Pilot deployments have revealed the need for encryption standards specifically designed for biological media, as conventional digital encryption methods may not translate effectively to nucleotide sequences.
Intellectual property protection represents another regulatory dimension, with patent landscapes becoming increasingly complex. Early deployments have generated numerous patent applications covering DNA synthesis techniques, encoding algorithms, and retrieval methods. Cross-licensing agreements have emerged as a common strategy among industry pioneers to navigate this complex IP environment.
International regulatory harmonization remains a significant challenge. Pilot deployments spanning multiple jurisdictions have encountered conflicting requirements, highlighting the need for standardized global frameworks. Organizations like ISO and IEEE have initiated working groups focused on developing technical standards for DNA data storage, which could eventually inform regulatory approaches.
Ethical oversight mechanisms constitute an essential component of the regulatory framework. Several pilot deployments have established independent ethics committees to address concerns regarding potential misuse of synthetic DNA technologies. These committees typically include diverse stakeholders from scientific, legal, and public policy backgrounds to ensure comprehensive ethical assessment.
The lessons from early deployments suggest that adaptive regulatory frameworks—capable of evolving alongside technological advancements—will be crucial for the responsible development of DNA data storage systems. Regulatory sandboxes, which allow controlled testing of new technologies under modified regulatory requirements, have proven particularly effective in balancing innovation with appropriate oversight.
Key regulatory considerations include biosafety protocols that address potential environmental impacts of synthetic DNA used for data storage. These protocols typically require physical containment measures, non-viable DNA constructs, and regular safety assessments. Several pilot deployments have demonstrated compliance with these requirements through specialized laboratory facilities and modified DNA structures that cannot replicate in natural environments.
Data security and privacy regulations present unique challenges for DNA storage systems. While traditional data protection frameworks like GDPR and HIPAA apply conceptually, their implementation requires novel approaches. Pilot deployments have revealed the need for encryption standards specifically designed for biological media, as conventional digital encryption methods may not translate effectively to nucleotide sequences.
Intellectual property protection represents another regulatory dimension, with patent landscapes becoming increasingly complex. Early deployments have generated numerous patent applications covering DNA synthesis techniques, encoding algorithms, and retrieval methods. Cross-licensing agreements have emerged as a common strategy among industry pioneers to navigate this complex IP environment.
International regulatory harmonization remains a significant challenge. Pilot deployments spanning multiple jurisdictions have encountered conflicting requirements, highlighting the need for standardized global frameworks. Organizations like ISO and IEEE have initiated working groups focused on developing technical standards for DNA data storage, which could eventually inform regulatory approaches.
Ethical oversight mechanisms constitute an essential component of the regulatory framework. Several pilot deployments have established independent ethics committees to address concerns regarding potential misuse of synthetic DNA technologies. These committees typically include diverse stakeholders from scientific, legal, and public policy backgrounds to ensure comprehensive ethical assessment.
The lessons from early deployments suggest that adaptive regulatory frameworks—capable of evolving alongside technological advancements—will be crucial for the responsible development of DNA data storage systems. Regulatory sandboxes, which allow controlled testing of new technologies under modified regulatory requirements, have proven particularly effective in balancing innovation with appropriate oversight.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!