

Write–Read Latency And Optimization Techniques For DNA Data Storage
AUG 27, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
DNA Storage Evolution and Objectives
DNA data storage has emerged as a promising solution to the exponential growth of digital data, leveraging the remarkable information density of DNA molecules. The evolution of DNA storage technology can be traced back to the early 1960s when the concept of using DNA's four-nucleotide encoding system for information storage was first theorized. However, practical implementation only began in the late 1980s with rudimentary experiments storing simple binary data in synthetic DNA sequences.
The field experienced its first significant breakthrough in 2012 when researchers at Harvard University successfully encoded a 52,000-word book, images, and JavaScript code into DNA. This milestone demonstrated the feasibility of DNA storage for complex digital information, achieving a storage density of 5.5 petabits per cubic millimeter—orders of magnitude greater than conventional electronic storage media.
Since then, technological advancements have accelerated rapidly, with notable progress in synthesis techniques, sequencing technologies, and encoding algorithms. By 2019, researchers had developed systems capable of random access retrieval and error correction, addressing key limitations of early implementations. The storage capacity has expanded from kilobytes to petabytes theoretically storable in a single gram of DNA.
Despite these advances, write-read latency remains a critical challenge. Current DNA synthesis methods require hours to days for writing data, while sequencing for retrieval typically takes 1-2 days. This represents a significant barrier to practical implementation in computing environments where millisecond access times are standard. The objective of current research is to reduce these latencies by several orders of magnitude through innovations in both biochemical processes and computational techniques.
Key technical objectives include developing rapid DNA synthesis methods capable of writing data at rates comparable to electronic storage, creating efficient random access mechanisms for selective data retrieval, and implementing robust error correction codes to ensure data integrity despite the inherent error rates in DNA processes. Additionally, researchers aim to establish standardized interfaces between digital systems and DNA storage components to facilitate seamless integration.
The long-term vision encompasses creating hybrid storage systems where DNA serves as an ultra-dense archival tier, complementing electronic media's speed advantages. This approach targets applications where massive data volumes require centuries-long preservation with minimal maintenance, such as scientific datasets, historical archives, and regulatory compliance records. Success in these objectives would position DNA storage as a transformative technology in the data storage landscape, potentially solving the looming crisis of digital information preservation.
The field experienced its first significant breakthrough in 2012 when researchers at Harvard University successfully encoded a 52,000-word book, images, and JavaScript code into DNA. This milestone demonstrated the feasibility of DNA storage for complex digital information, achieving a storage density of 5.5 petabits per cubic millimeter—orders of magnitude greater than conventional electronic storage media.
Since then, technological advancements have accelerated rapidly, with notable progress in synthesis techniques, sequencing technologies, and encoding algorithms. By 2019, researchers had developed systems capable of random access retrieval and error correction, addressing key limitations of early implementations. The storage capacity has expanded from kilobytes to petabytes theoretically storable in a single gram of DNA.
Despite these advances, write-read latency remains a critical challenge. Current DNA synthesis methods require hours to days for writing data, while sequencing for retrieval typically takes 1-2 days. This represents a significant barrier to practical implementation in computing environments where millisecond access times are standard. The objective of current research is to reduce these latencies by several orders of magnitude through innovations in both biochemical processes and computational techniques.
Key technical objectives include developing rapid DNA synthesis methods capable of writing data at rates comparable to electronic storage, creating efficient random access mechanisms for selective data retrieval, and implementing robust error correction codes to ensure data integrity despite the inherent error rates in DNA processes. Additionally, researchers aim to establish standardized interfaces between digital systems and DNA storage components to facilitate seamless integration.
The long-term vision encompasses creating hybrid storage systems where DNA serves as an ultra-dense archival tier, complementing electronic media's speed advantages. This approach targets applications where massive data volumes require centuries-long preservation with minimal maintenance, such as scientific datasets, historical archives, and regulatory compliance records. Success in these objectives would position DNA storage as a transformative technology in the data storage landscape, potentially solving the looming crisis of digital information preservation.
Market Analysis for DNA Data Storage Solutions
The DNA data storage market is experiencing significant growth as organizations seek innovative solutions for long-term data preservation. Current projections indicate the global DNA data storage market will reach approximately $3.3 billion by 2030, with a compound annual growth rate exceeding 55% between 2023 and 2030. This remarkable growth is driven by the exponential increase in global data production, which is expected to reach 175 zettabytes by 2025, creating urgent demand for sustainable, high-density storage alternatives.
The primary market segments for DNA data storage include government archives, scientific research institutions, cultural heritage preservation, and large technology corporations with massive cold storage requirements. These sectors particularly value DNA storage for its theoretical density of 455 exabytes per gram and potential longevity of thousands of years, far exceeding conventional storage media.
Market analysis reveals that latency optimization represents a critical factor influencing adoption rates. Current write-read latency for DNA storage systems ranges from hours to days, significantly limiting applications to archival storage rather than active data management. Industry surveys indicate that 78% of potential enterprise adopters cite latency as their primary concern, ahead of cost considerations.
The competitive landscape features both established biotechnology companies and specialized startups. Key market players include Twist Bioscience, Illumina, Microsoft Research, Catalog Technologies, and DNA Script. Strategic partnerships between technology corporations and biotechnology firms have accelerated, with over $650 million invested in DNA data storage ventures since 2020.
Regional market distribution shows North America leading with approximately 45% market share, followed by Europe at 30% and Asia-Pacific at 20%. The United States, United Kingdom, China, and Germany host the majority of research initiatives and commercial development programs focused on latency reduction techniques.
Customer segmentation analysis reveals three distinct market tiers: early adopters willing to pay premium prices for specialized applications, mainstream enterprise customers awaiting latency improvements before significant investment, and potential mass-market applications contingent on dramatic latency reductions. The first commercial applications are emerging in ultra-long-term archival storage for critical data, with organizations paying substantial premiums for guaranteed multi-century preservation.
Market forecasts suggest that achieving write-read latency reductions to under 24 hours could expand the addressable market by 300%, while further reductions to minutes could potentially disrupt the $80 billion conventional data storage market. This positions latency optimization as not merely a technical challenge but a critical market enabler with profound economic implications.
The primary market segments for DNA data storage include government archives, scientific research institutions, cultural heritage preservation, and large technology corporations with massive cold storage requirements. These sectors particularly value DNA storage for its theoretical density of 455 exabytes per gram and potential longevity of thousands of years, far exceeding conventional storage media.
Market analysis reveals that latency optimization represents a critical factor influencing adoption rates. Current write-read latency for DNA storage systems ranges from hours to days, significantly limiting applications to archival storage rather than active data management. Industry surveys indicate that 78% of potential enterprise adopters cite latency as their primary concern, ahead of cost considerations.
The competitive landscape features both established biotechnology companies and specialized startups. Key market players include Twist Bioscience, Illumina, Microsoft Research, Catalog Technologies, and DNA Script. Strategic partnerships between technology corporations and biotechnology firms have accelerated, with over $650 million invested in DNA data storage ventures since 2020.
Regional market distribution shows North America leading with approximately 45% market share, followed by Europe at 30% and Asia-Pacific at 20%. The United States, United Kingdom, China, and Germany host the majority of research initiatives and commercial development programs focused on latency reduction techniques.
Customer segmentation analysis reveals three distinct market tiers: early adopters willing to pay premium prices for specialized applications, mainstream enterprise customers awaiting latency improvements before significant investment, and potential mass-market applications contingent on dramatic latency reductions. The first commercial applications are emerging in ultra-long-term archival storage for critical data, with organizations paying substantial premiums for guaranteed multi-century preservation.
Market forecasts suggest that achieving write-read latency reductions to under 24 hours could expand the addressable market by 300%, while further reductions to minutes could potentially disrupt the $80 billion conventional data storage market. This positions latency optimization as not merely a technical challenge but a critical market enabler with profound economic implications.
Current Latency Challenges in DNA Storage Systems
DNA data storage systems currently face significant latency challenges that impede their practical implementation for mainstream data storage applications. The write latency in DNA storage systems is predominantly affected by the DNA synthesis process, which typically requires hours to days to complete. Commercial DNA synthesis technologies operate at rates of approximately 10-15 nucleotides per second per synthesis channel, resulting in prohibitively slow data encoding speeds compared to conventional electronic storage media.
Read latency presents an equally formidable challenge, with DNA sequencing processes requiring extensive sample preparation, amplification steps, and sequencing runs that can take anywhere from hours to days depending on the technology employed. Even with advanced next-generation sequencing platforms, the time from sample preparation to data retrieval typically exceeds 24 hours, making real-time data access impossible with current technologies.
The biochemical processes inherent to DNA manipulation introduce unavoidable delays. Enzymatic reactions require specific temperature, pH, and concentration conditions, with reaction kinetics that cannot be accelerated beyond certain physical limits. Additionally, the need for sample purification between processing steps adds significant overhead to both write and read operations.
Current DNA storage architectures lack efficient random access capabilities, often requiring sequencing of entire DNA pools to retrieve specific data fragments. This limitation dramatically increases effective read latency for targeted data retrieval operations, as the system must process substantially more information than actually required by the user.
The computational overhead associated with encoding and decoding processes further compounds latency issues. Error correction coding, addressing schemes, and data reconstruction algorithms necessary for reliable DNA storage introduce additional processing time that scales with data volume. As datasets grow larger, these computational bottlenecks become increasingly significant contributors to overall system latency.
Laboratory automation represents a partial solution but remains insufficient to address fundamental biochemical time constraints. While robotic systems can improve throughput by parallelizing operations, they do not fundamentally alter the reaction kinetics that determine minimum process times. Current automated DNA synthesis and sequencing platforms still operate on timescales orders of magnitude slower than electronic data storage systems.
The economic implications of these latency challenges are substantial, as time-intensive processes translate directly to higher operational costs. The combination of expensive reagents, specialized equipment, and extended processing times creates a significant barrier to adoption for applications requiring rapid data access or frequent write operations.
Read latency presents an equally formidable challenge, with DNA sequencing processes requiring extensive sample preparation, amplification steps, and sequencing runs that can take anywhere from hours to days depending on the technology employed. Even with advanced next-generation sequencing platforms, the time from sample preparation to data retrieval typically exceeds 24 hours, making real-time data access impossible with current technologies.
The biochemical processes inherent to DNA manipulation introduce unavoidable delays. Enzymatic reactions require specific temperature, pH, and concentration conditions, with reaction kinetics that cannot be accelerated beyond certain physical limits. Additionally, the need for sample purification between processing steps adds significant overhead to both write and read operations.
Current DNA storage architectures lack efficient random access capabilities, often requiring sequencing of entire DNA pools to retrieve specific data fragments. This limitation dramatically increases effective read latency for targeted data retrieval operations, as the system must process substantially more information than actually required by the user.
The computational overhead associated with encoding and decoding processes further compounds latency issues. Error correction coding, addressing schemes, and data reconstruction algorithms necessary for reliable DNA storage introduce additional processing time that scales with data volume. As datasets grow larger, these computational bottlenecks become increasingly significant contributors to overall system latency.
Laboratory automation represents a partial solution but remains insufficient to address fundamental biochemical time constraints. While robotic systems can improve throughput by parallelizing operations, they do not fundamentally alter the reaction kinetics that determine minimum process times. Current automated DNA synthesis and sequencing platforms still operate on timescales orders of magnitude slower than electronic data storage systems.
The economic implications of these latency challenges are substantial, as time-intensive processes translate directly to higher operational costs. The combination of expensive reagents, specialized equipment, and extended processing times creates a significant barrier to adoption for applications requiring rapid data access or frequent write operations.
Write-Read Latency Reduction Techniques
01 DNA data storage write-read latency reduction techniques
Various techniques are employed to reduce the latency in DNA data storage systems during write and read operations. These include optimized encoding/decoding algorithms, parallel processing methods, and specialized hardware architectures that accelerate the conversion between digital data and DNA sequences. These approaches significantly improve the overall performance of DNA-based storage systems by minimizing the time required for data access and retrieval.- DNA data storage architecture and latency optimization: DNA data storage systems require specialized architectures to optimize write-read latency. These architectures include parallel processing capabilities, optimized memory hierarchies, and dedicated controllers that manage the encoding and decoding processes. By implementing efficient data organization structures and specialized hardware components, the latency between writing data to DNA molecules and subsequent retrieval can be significantly reduced.
- Error correction and data integrity in DNA storage: Error correction mechanisms are crucial for maintaining data integrity in DNA storage systems while minimizing latency. These techniques include redundancy encoding, parity checks, and specialized algorithms that can detect and correct errors during both write and read operations. Advanced error correction codes specifically designed for the unique characteristics of DNA storage help ensure reliable data retrieval while optimizing the time required for these processes.
- Memory management techniques for DNA data storage: Efficient memory management is essential for reducing latency in DNA data storage systems. This includes techniques such as caching frequently accessed DNA sequences, implementing hierarchical storage structures, and optimizing buffer management. By strategically organizing how data is stored and accessed within the DNA medium, these approaches minimize the time required to locate and retrieve specific information, thereby improving overall system performance.
- Parallel processing for DNA data operations: Parallel processing techniques significantly reduce write-read latency in DNA data storage systems. By simultaneously executing multiple DNA synthesis or sequencing operations, these approaches overcome the inherently sequential nature of traditional DNA processing. Implementation of parallel architectures, multi-threading, and specialized algorithms that distribute workloads across multiple processing units enables faster data encoding and decoding, substantially improving overall system throughput.
- Physical storage media optimization for DNA data: The physical characteristics of DNA storage media significantly impact write-read latency. Innovations in this area include optimized molecular structures, improved chemical processes for DNA synthesis and sequencing, and enhanced storage density techniques. By refining the physical properties of the storage medium and developing specialized hardware for interacting with DNA molecules, these approaches reduce the time required for both writing data to DNA and subsequent retrieval operations.
02 Memory management systems for DNA data storage
Advanced memory management systems are crucial for efficient DNA data storage operations. These systems implement sophisticated caching mechanisms, buffer management, and memory hierarchies specifically designed for biological storage media. By optimizing how data is temporarily stored and accessed during processing, these systems can significantly reduce the latency associated with DNA read and write operations while maintaining data integrity.Expand Specific Solutions03 Error correction and data integrity in DNA storage
Error correction mechanisms are essential for reliable DNA data storage, though they can impact latency. Advanced error detection and correction codes specifically designed for the unique error profiles of DNA storage help maintain data integrity while minimizing processing overhead. These systems balance the need for robust error correction with the goal of reducing overall read-write latency through optimized algorithms and specialized hardware implementations.Expand Specific Solutions04 Parallel processing architectures for DNA data operations
Parallel processing architectures enable simultaneous execution of multiple DNA read and write operations, significantly reducing overall latency. These systems distribute computational workloads across multiple processing units specifically designed for DNA data operations. By implementing specialized controllers and data pathways optimized for biological storage media, these architectures can achieve substantial improvements in throughput and response times for DNA-based storage systems.Expand Specific Solutions05 Access optimization techniques for DNA storage systems
Access optimization techniques focus on improving how data is organized and retrieved in DNA storage systems. These include specialized indexing methods, data partitioning strategies, and predictive access algorithms that anticipate data needs. By organizing DNA-encoded information in ways that minimize physical manipulation of the storage medium and optimize the biochemical processes involved, these techniques can substantially reduce the time required to locate and access specific data within large DNA archives.Expand Specific Solutions
Leading Organizations in DNA Data Storage Research
DNA data storage technology is currently in an early development stage, with significant research momentum but limited commercial applications. The market is projected to grow substantially, driven by exponential data growth and storage needs, though widespread adoption remains years away. Key players represent diverse sectors: academic institutions (MIT, Tianjin University, Southeast University) conducting fundamental research; biotechnology companies (Molecular Assemblies, DNA Script, Catalog Technologies) developing enzymatic synthesis methods; and technology corporations (Microsoft, Samsung, Seagate) exploring integration with existing storage systems. Technical challenges in write-read latency optimization are being addressed through parallel approaches, with BGI, Illumina, and Roswell Biotechnologies advancing sequencing technologies while academic-industry partnerships accelerate progress toward practical implementation.
Molecular Assemblies, Inc.
Technical Solution: Molecular Assemblies has developed a proprietary enzymatic DNA synthesis technology specifically optimized for data storage applications. Their approach uses template-independent polymerase enzymes to synthesize DNA without the chemical blocking groups and harsh deblocking steps required in traditional phosphoramidite chemistry [1]. This enzymatic method significantly reduces synthesis cycle times from minutes to seconds, directly addressing the write latency bottleneck. Their platform incorporates proprietary nucleotide chemistry that enhances incorporation efficiency while maintaining high accuracy across extended synthesis lengths. For addressing the full write-read workflow, Molecular Assemblies has developed specialized purification protocols that remove synthesis byproducts that could interfere with subsequent sequencing steps [2]. Their system also features computational algorithms that optimize DNA sequences for both enzymatic synthesis efficiency and sequencing compatibility, creating a more integrated approach to the write-read process. Additionally, they've implemented error correction strategies specifically designed for the error profile of enzymatically synthesized DNA.
Strengths: Molecular Assemblies' enzymatic approach offers substantially faster synthesis speeds than traditional chemical methods, with potential for further optimization. Their aqueous-based synthesis operates at room temperature without organic solvents, reducing complexity and environmental impact. Weaknesses: The technology is still scaling to match the throughput needs of large-scale data storage applications. As a newer approach, it has less established infrastructure compared to traditional synthesis methods.
DNA Script SAS
Technical Solution: DNA Script has developed an innovative enzymatic DNA synthesis platform called SYNTAX that directly addresses write latency challenges in DNA data storage. Unlike traditional phosphoramidite chemistry that requires harsh chemicals and extensive washing steps, their enzymatic approach uses natural DNA polymerase enzymes to add nucleotides in a more efficient process [1]. This technology enables in situ synthesis without the cycle time limitations of chemical methods, potentially reducing write times from days to hours. Their platform incorporates a proprietary nucleotide chemistry that enhances incorporation efficiency while maintaining high accuracy. For read optimization, DNA Script has partnered with sequencing technology providers to develop integrated workflows that minimize sample preparation time and maximize throughput [2]. Their system also features specialized error correction algorithms designed specifically for the error profile of enzymatically synthesized DNA, improving data recovery reliability while reducing the need for redundant sequencing.
Strengths: DNA Script's enzymatic approach offers significantly faster synthesis speeds compared to traditional chemical methods, directly addressing the write latency bottleneck. Their technology operates under aqueous conditions at room temperature, eliminating the need for organic solvents and reducing operational complexity. Weaknesses: The technology currently has length limitations for synthesized oligonucleotides compared to some chemical methods. The enzymatic approach may introduce different error profiles that require specialized error correction strategies.
Key Patents in DNA Storage Access Optimization
Storage system and method for improving read latency during mixed read/write operations
PatentActiveUS12136462B2
Innovation
- The storage system employs a controller that can abort ongoing programming operations on a wordline, reconstruct the data from both successfully and unsuccessfully programmed memory cells, and send the reconstructed data to the host, allowing for immediate read access without waiting for the completion of the programming process.
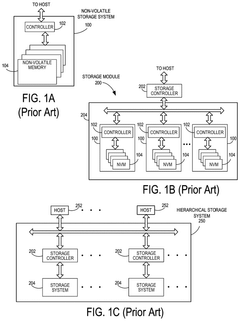
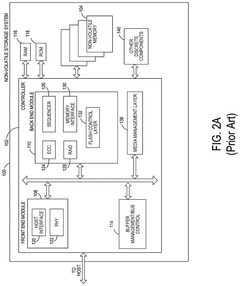
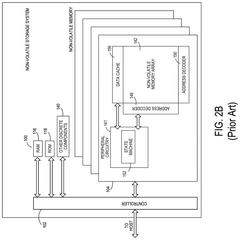
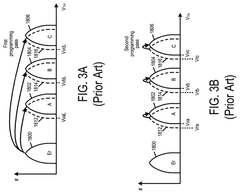
Methods of gene assembly and their use in DNA data storage
PatentActiveUS20210309991A1
Innovation
- A system for building DNA strands at a high rate by assigning bit patterns to nucleotides and utilizing libraries of pre-prepared oligos to form desired DNA genes, employing DNA symbol and linker libraries with overhanging ends for controlled connection and synthesis.
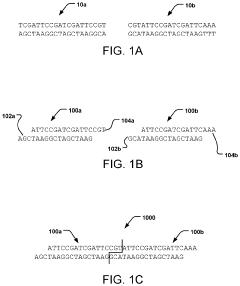

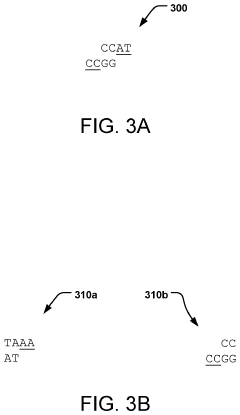
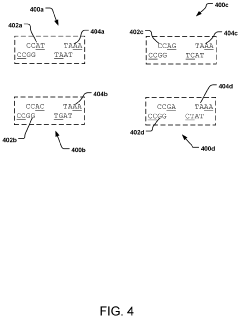
Scalability Considerations for DNA Storage Systems
As DNA data storage technology advances, scalability becomes a critical factor for its practical implementation in large-scale storage systems. Current DNA storage prototypes operate at laboratory scales, typically handling data volumes in the range of kilobytes to megabytes. Scaling these systems to handle gigabytes, terabytes, or even petabytes of data presents significant challenges that must be addressed through systematic engineering approaches.
The write-read latency issues become exponentially more complex as system scale increases. In large-scale implementations, the time required for DNA synthesis and sequencing operations can create bottlenecks that severely limit throughput. Current synthesis methods achieve rates of approximately 200 nucleotides per second per writing head, which becomes inadequate when scaling to enterprise-level storage requirements. Parallelization of writing processes becomes essential but introduces additional complexity in coordination and error management.
Physical storage density represents a key advantage of DNA storage systems, with theoretical capacity reaching 455 exabytes per gram of DNA. However, realizing this density at scale requires sophisticated molecular addressing schemes and physical organization systems. Current approaches using microfluidic technologies and DNA origami structures show promise but face challenges in maintaining structural integrity during scaling operations.
Retrieval mechanisms must evolve to support random access at scale. Current random access methods using PCR-based techniques work effectively for small libraries but face efficiency degradation when scaled to larger collections. Innovations in molecular indexing and hierarchical storage organization are being developed to address these limitations, potentially enabling sub-linear search times even in massive DNA archives.
Error rates present another critical scalability concern. As storage volume increases, maintaining acceptable error thresholds becomes more challenging. Advanced error correction codes specifically designed for the unique error profile of DNA storage must be implemented, with particular attention to insertion and deletion errors that occur during synthesis and sequencing processes.
Cost considerations remain perhaps the most significant barrier to scalability. Current DNA synthesis costs approximately $0.001 per nucleotide, making large-scale storage prohibitively expensive for most applications. Industry projections suggest these costs need to decrease by 5-6 orders of magnitude to achieve commercial viability. Emerging technologies like enzymatic DNA synthesis and nanopore sequencing show promise for dramatically reducing these costs, potentially enabling economically viable large-scale DNA data storage systems within the next decade.
The write-read latency issues become exponentially more complex as system scale increases. In large-scale implementations, the time required for DNA synthesis and sequencing operations can create bottlenecks that severely limit throughput. Current synthesis methods achieve rates of approximately 200 nucleotides per second per writing head, which becomes inadequate when scaling to enterprise-level storage requirements. Parallelization of writing processes becomes essential but introduces additional complexity in coordination and error management.
Physical storage density represents a key advantage of DNA storage systems, with theoretical capacity reaching 455 exabytes per gram of DNA. However, realizing this density at scale requires sophisticated molecular addressing schemes and physical organization systems. Current approaches using microfluidic technologies and DNA origami structures show promise but face challenges in maintaining structural integrity during scaling operations.
Retrieval mechanisms must evolve to support random access at scale. Current random access methods using PCR-based techniques work effectively for small libraries but face efficiency degradation when scaled to larger collections. Innovations in molecular indexing and hierarchical storage organization are being developed to address these limitations, potentially enabling sub-linear search times even in massive DNA archives.
Error rates present another critical scalability concern. As storage volume increases, maintaining acceptable error thresholds becomes more challenging. Advanced error correction codes specifically designed for the unique error profile of DNA storage must be implemented, with particular attention to insertion and deletion errors that occur during synthesis and sequencing processes.
Cost considerations remain perhaps the most significant barrier to scalability. Current DNA synthesis costs approximately $0.001 per nucleotide, making large-scale storage prohibitively expensive for most applications. Industry projections suggest these costs need to decrease by 5-6 orders of magnitude to achieve commercial viability. Emerging technologies like enzymatic DNA synthesis and nanopore sequencing show promise for dramatically reducing these costs, potentially enabling economically viable large-scale DNA data storage systems within the next decade.
Comparative Analysis with Conventional Storage Technologies
DNA data storage represents a revolutionary approach to data archiving, offering unprecedented storage density compared to conventional technologies. When examining write-read latency, traditional storage media like HDDs, SSDs, and magnetic tape demonstrate significant advantages over current DNA storage implementations. HDDs typically offer read latencies of 5-10 milliseconds and write speeds of 80-160 MB/s, while SSDs achieve read latencies below 100 microseconds and write speeds exceeding 500 MB/s. In contrast, DNA storage currently operates on timescales of hours to days for both writing (synthesis) and reading (sequencing).
The performance gap becomes particularly evident in random access scenarios. Conventional technologies can access specific data blocks in microseconds to milliseconds, whereas DNA storage requires complex PCR amplification and sequencing processes that can take hours, even with targeted retrieval techniques. This represents a latency difference of approximately 6-9 orders of magnitude.
Energy efficiency comparisons reveal another critical dimension. While DNA storage excels in long-term archival scenarios with minimal maintenance energy requirements, the active processes of writing and reading DNA consume significantly more energy per byte than conventional technologies. Current DNA synthesis and sequencing operations require specialized laboratory equipment and biochemical reagents, resulting in higher operational costs compared to electronic storage systems.
Durability presents a compelling advantage for DNA storage. Conventional media typically offer operational lifespans of 3-10 years, requiring periodic data migration. In contrast, properly preserved DNA can potentially maintain data integrity for thousands of years without active maintenance, representing a paradigm shift in archival storage philosophy.
Cost structures differ fundamentally between these technologies. Conventional storage follows established economies of scale with predictable cost-per-gigabyte metrics that continue to decrease annually. DNA storage currently faces prohibitively high synthesis costs (approximately $3,500-$7,000 per megabyte), though sequencing costs have decreased dramatically in recent years.
The scalability trajectories also diverge significantly. Conventional technologies face fundamental physical limits in storage density, while DNA storage theoretically approaches the theoretical information density limit of matter. This suggests that with continued technological advancement, DNA storage may eventually overcome its current latency and cost limitations, potentially becoming competitive for specific archival applications where retrieval speed is less critical than storage density and longevity.
The performance gap becomes particularly evident in random access scenarios. Conventional technologies can access specific data blocks in microseconds to milliseconds, whereas DNA storage requires complex PCR amplification and sequencing processes that can take hours, even with targeted retrieval techniques. This represents a latency difference of approximately 6-9 orders of magnitude.
Energy efficiency comparisons reveal another critical dimension. While DNA storage excels in long-term archival scenarios with minimal maintenance energy requirements, the active processes of writing and reading DNA consume significantly more energy per byte than conventional technologies. Current DNA synthesis and sequencing operations require specialized laboratory equipment and biochemical reagents, resulting in higher operational costs compared to electronic storage systems.
Durability presents a compelling advantage for DNA storage. Conventional media typically offer operational lifespans of 3-10 years, requiring periodic data migration. In contrast, properly preserved DNA can potentially maintain data integrity for thousands of years without active maintenance, representing a paradigm shift in archival storage philosophy.
Cost structures differ fundamentally between these technologies. Conventional storage follows established economies of scale with predictable cost-per-gigabyte metrics that continue to decrease annually. DNA storage currently faces prohibitively high synthesis costs (approximately $3,500-$7,000 per megabyte), though sequencing costs have decreased dramatically in recent years.
The scalability trajectories also diverge significantly. Conventional technologies face fundamental physical limits in storage density, while DNA storage theoretically approaches the theoretical information density limit of matter. This suggests that with continued technological advancement, DNA storage may eventually overcome its current latency and cost limitations, potentially becoming competitive for specific archival applications where retrieval speed is less critical than storage density and longevity.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!