Venture Landscape And Strategic Partnerships In DNA Data Storage
AUG 27, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
DNA Storage Evolution and Objectives
DNA data storage has evolved from a theoretical concept to a promising technology for addressing the exponential growth in global data production. The journey began in 1988 when scientists first demonstrated the feasibility of storing information in DNA molecules. However, significant advancements only emerged in the early 2010s when Church et al. and Goldman et al. published groundbreaking papers showcasing practical implementations of DNA storage systems with unprecedented data density capabilities.
The evolution of DNA data storage has been characterized by continuous improvements in encoding algorithms, synthesis techniques, and sequencing technologies. Early systems suffered from high error rates and prohibitive costs, but recent innovations have dramatically enhanced reliability while reducing expenses. The development trajectory has moved from proof-of-concept demonstrations storing kilobytes of data to current systems capable of managing megabytes, with theoretical potential for exabyte-scale storage in minimal physical space.
The primary objective of DNA data storage technology is to harness the exceptional information density of DNA molecules, which can theoretically store up to 455 exabytes per gram. This represents a solution to the impending data storage crisis, as conventional electronic storage media approach their physical limits while global data production continues to accelerate exponentially. Additionally, DNA offers remarkable durability, with potential preservation timeframes of thousands of years under proper conditions, compared to decades for traditional media.
Technical objectives in this field include reducing synthesis and sequencing costs, which remain the primary barriers to widespread adoption. Current estimates place DNA storage costs at approximately $1,000 per megabyte, requiring a reduction of several orders of magnitude to become commercially viable. Researchers aim to achieve this through innovations in enzymatic synthesis methods and nanopore sequencing technologies.
Another critical objective involves improving read/write speeds, as current DNA storage systems operate significantly slower than electronic alternatives. Parallel processing techniques and microfluidic systems represent promising approaches to address this limitation. Additionally, researchers are working to enhance encoding schemes to improve data integrity, reduce redundancy requirements, and facilitate random access to specific data segments within DNA archives.
The long-term vision for DNA data storage encompasses its integration into hybrid storage systems, where it serves as an archival tier for rarely accessed but valuable data. This approach aligns with the technology's strengths in density and longevity while mitigating concerns about access speed limitations.
The evolution of DNA data storage has been characterized by continuous improvements in encoding algorithms, synthesis techniques, and sequencing technologies. Early systems suffered from high error rates and prohibitive costs, but recent innovations have dramatically enhanced reliability while reducing expenses. The development trajectory has moved from proof-of-concept demonstrations storing kilobytes of data to current systems capable of managing megabytes, with theoretical potential for exabyte-scale storage in minimal physical space.
The primary objective of DNA data storage technology is to harness the exceptional information density of DNA molecules, which can theoretically store up to 455 exabytes per gram. This represents a solution to the impending data storage crisis, as conventional electronic storage media approach their physical limits while global data production continues to accelerate exponentially. Additionally, DNA offers remarkable durability, with potential preservation timeframes of thousands of years under proper conditions, compared to decades for traditional media.
Technical objectives in this field include reducing synthesis and sequencing costs, which remain the primary barriers to widespread adoption. Current estimates place DNA storage costs at approximately $1,000 per megabyte, requiring a reduction of several orders of magnitude to become commercially viable. Researchers aim to achieve this through innovations in enzymatic synthesis methods and nanopore sequencing technologies.
Another critical objective involves improving read/write speeds, as current DNA storage systems operate significantly slower than electronic alternatives. Parallel processing techniques and microfluidic systems represent promising approaches to address this limitation. Additionally, researchers are working to enhance encoding schemes to improve data integrity, reduce redundancy requirements, and facilitate random access to specific data segments within DNA archives.
The long-term vision for DNA data storage encompasses its integration into hybrid storage systems, where it serves as an archival tier for rarely accessed but valuable data. This approach aligns with the technology's strengths in density and longevity while mitigating concerns about access speed limitations.
Market Analysis for DNA Data Storage Solutions
The DNA data storage market is experiencing significant growth, driven by the exponential increase in global data production and the limitations of conventional storage technologies. Current projections indicate the global DNA data storage market could reach $3.5 billion by 2030, with a compound annual growth rate exceeding 55% between 2023 and 2030. This remarkable growth trajectory is fueled by the fundamental advantages DNA offers as a storage medium, including unprecedented data density, longevity, and energy efficiency.
Primary market segments for DNA data storage include government archives, scientific research institutions, healthcare organizations, and large technology corporations with massive data retention requirements. These sectors generate enormous volumes of cold data—information that requires long-term preservation but infrequent access—making them ideal early adopters for DNA storage solutions.
Demand analysis reveals several key drivers accelerating market development. The exponential growth of digital data, estimated to reach 175 zettabytes globally by 2025, is creating urgent needs for alternative storage technologies. Traditional storage media face physical limitations in density and durability, while DNA can theoretically store 455 exabytes per gram and remain stable for thousands of years without active maintenance.
Regulatory factors are also influencing market dynamics, with data sovereignty laws and long-term preservation requirements creating favorable conditions for DNA storage adoption. The healthcare sector, with its strict data retention policies, represents a particularly promising vertical market, as genomic and medical imaging data continue to grow at unprecedented rates.
Cost remains the primary barrier to widespread commercialization, with current DNA synthesis and sequencing expenses making the technology economically viable only for the most valuable archival data. However, the cost curve is trending downward, with synthesis costs decreasing from $0.10 per base pair in 2020 to projections approaching $0.001 per base pair by 2025, potentially enabling broader market penetration.
Regional market analysis indicates North America currently leads in research investment and commercial development, with approximately 45% of global activity. Europe follows with significant academic research initiatives, while Asia-Pacific demonstrates the fastest growth rate, particularly in China and Singapore where substantial government funding is accelerating development.
Customer readiness surveys indicate that while awareness of DNA data storage is increasing among potential enterprise customers, most organizations remain in exploratory phases rather than implementation planning. The technology is widely perceived as promising but not yet mature enough for mainstream adoption, suggesting a market that is still in its early development stage but positioned for substantial growth as technical and economic barriers continue to diminish.
Primary market segments for DNA data storage include government archives, scientific research institutions, healthcare organizations, and large technology corporations with massive data retention requirements. These sectors generate enormous volumes of cold data—information that requires long-term preservation but infrequent access—making them ideal early adopters for DNA storage solutions.
Demand analysis reveals several key drivers accelerating market development. The exponential growth of digital data, estimated to reach 175 zettabytes globally by 2025, is creating urgent needs for alternative storage technologies. Traditional storage media face physical limitations in density and durability, while DNA can theoretically store 455 exabytes per gram and remain stable for thousands of years without active maintenance.
Regulatory factors are also influencing market dynamics, with data sovereignty laws and long-term preservation requirements creating favorable conditions for DNA storage adoption. The healthcare sector, with its strict data retention policies, represents a particularly promising vertical market, as genomic and medical imaging data continue to grow at unprecedented rates.
Cost remains the primary barrier to widespread commercialization, with current DNA synthesis and sequencing expenses making the technology economically viable only for the most valuable archival data. However, the cost curve is trending downward, with synthesis costs decreasing from $0.10 per base pair in 2020 to projections approaching $0.001 per base pair by 2025, potentially enabling broader market penetration.
Regional market analysis indicates North America currently leads in research investment and commercial development, with approximately 45% of global activity. Europe follows with significant academic research initiatives, while Asia-Pacific demonstrates the fastest growth rate, particularly in China and Singapore where substantial government funding is accelerating development.
Customer readiness surveys indicate that while awareness of DNA data storage is increasing among potential enterprise customers, most organizations remain in exploratory phases rather than implementation planning. The technology is widely perceived as promising but not yet mature enough for mainstream adoption, suggesting a market that is still in its early development stage but positioned for substantial growth as technical and economic barriers continue to diminish.
Technical Challenges in DNA Data Storage
Despite the promising potential of DNA data storage, several significant technical challenges impede its widespread adoption. The primary obstacle remains the high cost associated with DNA synthesis and sequencing. Current synthesis costs hover around $0.001 per base, translating to approximately $1 million per terabyte of data—orders of magnitude higher than conventional storage media. While sequencing costs have decreased dramatically following the Human Genome Project, they remain prohibitively expensive for routine data retrieval operations.
The write speed presents another critical bottleneck. Contemporary DNA synthesis technologies operate at rates of approximately 200 nucleotides per second per writing head, resulting in data writing speeds measured in kilobytes per second—vastly slower than electronic storage systems that function at gigabytes per second. This limitation severely restricts real-time applications and makes DNA storage impractical for dynamic data environments.
Error rates in DNA synthesis and sequencing constitute a significant technical hurdle. While DNA naturally exhibits error rates of approximately 1 in 10^8 nucleotides during replication, artificial synthesis introduces errors at much higher frequencies—typically 1 in 100 to 1 in 200 bases. These errors necessitate sophisticated error correction algorithms and redundancy mechanisms, increasing storage overhead and computational complexity.
Random access capability represents another formidable challenge. Unlike electronic storage where specific data blocks can be directly accessed, retrieving targeted information from DNA storage currently requires accessing the entire dataset through PCR amplification and sequencing. This process is time-consuming and resource-intensive, making selective data retrieval inefficient.
The stability of synthetic DNA under various environmental conditions remains problematic. While properly preserved DNA can theoretically last millennia, practical storage environments may expose DNA to temperature fluctuations, humidity, and chemical contaminants that accelerate degradation. Developing robust encapsulation technologies and preservation protocols is essential for ensuring long-term data integrity.
Standardization across the DNA data storage ecosystem presents a significant challenge. The field currently lacks unified protocols for encoding schemes, file systems, and data organization. This fragmentation hampers interoperability between different DNA storage implementations and complicates the development of a cohesive technological ecosystem.
Scaling DNA synthesis and sequencing technologies to industrial levels while maintaining accuracy represents perhaps the most daunting challenge. Current methods remain largely laboratory-based and manual, requiring substantial innovation to achieve the automation and throughput necessary for commercial viability.
The write speed presents another critical bottleneck. Contemporary DNA synthesis technologies operate at rates of approximately 200 nucleotides per second per writing head, resulting in data writing speeds measured in kilobytes per second—vastly slower than electronic storage systems that function at gigabytes per second. This limitation severely restricts real-time applications and makes DNA storage impractical for dynamic data environments.
Error rates in DNA synthesis and sequencing constitute a significant technical hurdle. While DNA naturally exhibits error rates of approximately 1 in 10^8 nucleotides during replication, artificial synthesis introduces errors at much higher frequencies—typically 1 in 100 to 1 in 200 bases. These errors necessitate sophisticated error correction algorithms and redundancy mechanisms, increasing storage overhead and computational complexity.
Random access capability represents another formidable challenge. Unlike electronic storage where specific data blocks can be directly accessed, retrieving targeted information from DNA storage currently requires accessing the entire dataset through PCR amplification and sequencing. This process is time-consuming and resource-intensive, making selective data retrieval inefficient.
The stability of synthetic DNA under various environmental conditions remains problematic. While properly preserved DNA can theoretically last millennia, practical storage environments may expose DNA to temperature fluctuations, humidity, and chemical contaminants that accelerate degradation. Developing robust encapsulation technologies and preservation protocols is essential for ensuring long-term data integrity.
Standardization across the DNA data storage ecosystem presents a significant challenge. The field currently lacks unified protocols for encoding schemes, file systems, and data organization. This fragmentation hampers interoperability between different DNA storage implementations and complicates the development of a cohesive technological ecosystem.
Scaling DNA synthesis and sequencing technologies to industrial levels while maintaining accuracy represents perhaps the most daunting challenge. Current methods remain largely laboratory-based and manual, requiring substantial innovation to achieve the automation and throughput necessary for commercial viability.
Current DNA Data Encoding Methodologies
01 DNA encoding and decoding methods for data storage
Various methods for encoding digital data into DNA sequences and decoding DNA back to digital data. These techniques involve algorithms that convert binary data into nucleotide sequences while addressing challenges such as error correction, data density optimization, and sequence stability. The encoding schemes are designed to avoid problematic DNA patterns like homopolymers and ensure reliable data retrieval through specialized decoding processes.- DNA encoding and decoding methods for data storage: Various methods for encoding digital data into DNA sequences and decoding DNA back to digital data have been developed. These techniques involve converting binary data into nucleotide sequences using specific encoding algorithms that optimize for DNA synthesis constraints, error correction, and data density. Advanced encoding schemes can incorporate redundancy and error-correction codes to ensure data integrity during storage and retrieval processes.
- DNA synthesis and sequencing technologies for data storage: Specialized DNA synthesis and sequencing technologies have been developed specifically for data storage applications. These technologies focus on improving the accuracy, speed, and cost-effectiveness of writing and reading DNA-stored data. Innovations include high-throughput parallel synthesis methods, microfluidic platforms for DNA manipulation, and advanced sequencing techniques that can rapidly retrieve stored information with minimal error rates.
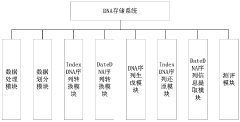
- DNA storage system architectures and management: Complete system architectures for DNA-based data storage have been designed to address the entire workflow from data input to retrieval. These systems include components for data preprocessing, encoding, physical storage organization, indexing, retrieval selection, and decoding. Management systems provide interfaces between traditional computing systems and DNA storage, including file systems, addressing schemes, and protocols for efficient data organization and access.
- DNA preservation and stability enhancement methods: Methods to enhance the long-term stability and preservation of DNA-stored data have been developed to address the challenges of maintaining data integrity over extended periods. These include encapsulation techniques, specialized storage media, dehydration processes, and chemical modifications that protect DNA molecules from degradation. Environmental control systems and protective formulations help maintain the physical integrity of DNA under various storage conditions.
- Random access and selective retrieval in DNA data storage: Technologies enabling random access and selective retrieval of specific data segments from DNA storage systems have been developed to overcome limitations of sequential access. These methods incorporate molecular addressing schemes, PCR-based selection techniques, and specialized indexing approaches that allow targeted retrieval of desired data without needing to sequence the entire DNA archive. Such capabilities are essential for practical implementation of DNA storage in real-world applications.
02 DNA storage system architectures
Hardware and system architectures designed specifically for DNA-based data storage. These systems integrate components for DNA synthesis, storage, and sequencing into cohesive platforms that can interface with conventional computing systems. The architectures include specialized modules for data processing, error correction, and management of DNA libraries, enabling practical implementation of DNA storage in data centers and other applications.Expand Specific Solutions03 Random access and retrieval methods in DNA storage
Techniques for selectively accessing and retrieving specific data stored in DNA without sequencing the entire DNA library. These methods use molecular approaches such as PCR-based selection with unique address sequences or primers that target particular data segments. Random access capabilities significantly enhance the practicality of DNA storage by allowing efficient retrieval of desired information without processing the entire dataset.Expand Specific Solutions04 Error correction and data integrity in DNA storage
Specialized error correction codes and redundancy mechanisms designed for the unique error profile of DNA storage. These techniques address errors that occur during DNA synthesis, storage, and sequencing, including insertions, deletions, and substitutions. Advanced error correction strategies incorporate redundancy across multiple DNA molecules and utilize sophisticated algorithms to reconstruct original data even when portions of the DNA are damaged or lost.Expand Specific Solutions05 Long-term preservation and stability of DNA-stored data
Methods for ensuring the long-term stability and preservation of data stored in DNA. These approaches include encapsulation techniques, specialized storage media, and environmental control systems that protect DNA from degradation. Chemical modifications to DNA molecules and preservation additives enhance stability, while specialized containers provide protection against environmental factors like humidity, temperature fluctuations, and oxidative damage, enabling data retention for potentially thousands of years.Expand Specific Solutions
Key Industry Players and Partnership Ecosystem
DNA data storage technology is currently in an early development phase, characterized by significant research activity but limited commercial deployment. The market, estimated to reach $1-2 billion by 2030, is experiencing rapid growth driven by exponential data storage needs. Key players represent diverse sectors: academic institutions (MIT, Tianjin University, Southeast University), technology corporations (Microsoft, Intel, Western Digital), and specialized biotechnology firms (Twist Bioscience, Iridia, Roswell Biotechnologies). The technology remains in pre-commercial maturity, with companies like BGI Research and Twist Bioscience leading in DNA synthesis capabilities, while Microsoft and Iridia focus on developing practical storage architectures. Strategic partnerships between technology and biotechnology sectors are accelerating development, with cross-industry collaborations emerging as essential for overcoming technical barriers to commercialization.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft has pioneered significant advancements in DNA data storage through its comprehensive end-to-end system architecture. Their approach involves converting digital binary data into DNA sequences using a custom encoding scheme that optimizes for DNA synthesis constraints while maximizing data density. Microsoft's system incorporates sophisticated error correction codes specifically designed for the unique error profiles of DNA storage, enabling reliable data recovery despite synthesis and sequencing errors. Their platform includes automated liquid handling systems for high-throughput DNA library preparation and a computational pipeline that efficiently processes raw sequencing data back into digital information. Microsoft has demonstrated storage densities exceeding 1 exabyte per cubic centimeter and has achieved successful retrieval of data after multiple synthesis-sequencing cycles, proving the technology's durability. Their recent innovations include random-access capabilities allowing selective retrieval of specific data subsets without sequencing entire DNA pools.
Strengths: Industry-leading encoding algorithms with superior error correction capabilities; established infrastructure for end-to-end DNA storage workflow; strong partnerships with synthesis and sequencing technology providers. Weaknesses: High operational costs; current technology still requires specialized laboratory equipment; retrieval speeds remain significantly slower than electronic storage.
Massachusetts Institute of Technology
Technical Solution: MIT has pioneered groundbreaking research in DNA data storage through its innovative molecular encoding and retrieval systems. Their approach leverages advanced computational biology techniques to optimize DNA sequence design, maximizing data density while minimizing synthesis errors and cross-sequence interference. MIT researchers have developed novel encoding schemes that adapt to the specific error profiles of different DNA synthesis and sequencing technologies, enabling robust data recovery even with imperfect molecular processes. Their platform incorporates machine learning algorithms that continuously improve encoding efficiency based on empirical error data. MIT has demonstrated successful storage and retrieval of several megabytes of data in synthetic DNA with unprecedented accuracy rates, and their work on enzymatic DNA synthesis methods promises to dramatically reduce the cost and increase the speed of DNA data writing. Additionally, their research into nanopore-based direct reading of DNA information has shown potential for significant improvements in data retrieval speeds compared to traditional sequencing approaches.
Strengths: Cutting-edge research in computational encoding and error correction; innovative approaches to both DNA synthesis and sequencing challenges; strong interdisciplinary collaboration between computer science and molecular biology. Weaknesses: Research-focused approach may face challenges in commercial scaling; technologies still primarily at laboratory proof-of-concept stage; requires partnerships with industry for practical implementation.
Breakthrough Patents in DNA Storage Technology
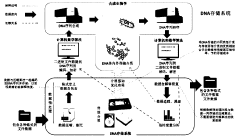
DNA storage method and system and electronic equipment
PatentActiveCN111091876A
Innovation
- By converting the storage file into binary and dividing it into fixed-size DNA storage units, and using the IndexDNA sequence and DateDNA algorithm for encoding and decoding, a base sequence that can be used for DNA synthesis is generated to achieve efficient encoding and storage of different types of data.

Investment Landscape in DNA Storage Ventures
The DNA data storage investment landscape has witnessed significant growth over the past decade, with venture capital funding accelerating particularly since 2016. Major funding rounds have been secured by pioneering companies like Catalog Technologies ($35 million Series B in 2021), Twist Bioscience ($70 million for their DNA synthesis platform), and Iridia ($24 million Series B focused on electronic addressing for DNA storage).
Investment patterns reveal a strategic shift from early exploratory funding to more substantial growth-stage investments as the technology approaches commercial viability. Venture capital firms specializing in deep tech and biotechnology, including Illumina Ventures, Khosla Ventures, and Data Collective, have emerged as leading investors in this space, often participating in multiple funding rounds across different companies in the ecosystem.
Corporate venture arms from technology giants have also entered the arena, with Microsoft, Intel, and Western Digital making strategic investments. These corporations view DNA storage not merely as a financial opportunity but as a strategic technology that could transform their core businesses in the coming decades.
Geographic distribution of investments shows concentration in biotech hubs, with the Boston/Cambridge area, San Francisco Bay Area, and emerging clusters in Europe (particularly the UK and Switzerland) attracting the majority of funding. This regional concentration facilitates collaboration between academic institutions, startups, and established industry players.
Investment trends indicate increasing confidence in the commercial potential of DNA data storage, with funding rounds growing in size and frequency. Early-stage investments typically focus on fundamental technological breakthroughs in DNA synthesis and sequencing, while later-stage funding targets scaling capabilities and developing commercial applications.
The investment ecosystem has evolved to include specialized accelerators and incubators dedicated to supporting DNA storage startups. Programs like IndieBio and Y Combinator have created tailored tracks for companies in this space, providing not only capital but also specialized mentorship and access to laboratory facilities.
Return on investment timelines remain longer than typical venture investments, with investors recognizing the extended development cycles inherent in deep tech. This has led to the emergence of patient capital sources specifically structured to accommodate the unique development timeline of DNA storage technologies, with investment horizons extending to 7-10 years rather than the traditional 3-5 year venture capital cycle.
Investment patterns reveal a strategic shift from early exploratory funding to more substantial growth-stage investments as the technology approaches commercial viability. Venture capital firms specializing in deep tech and biotechnology, including Illumina Ventures, Khosla Ventures, and Data Collective, have emerged as leading investors in this space, often participating in multiple funding rounds across different companies in the ecosystem.
Corporate venture arms from technology giants have also entered the arena, with Microsoft, Intel, and Western Digital making strategic investments. These corporations view DNA storage not merely as a financial opportunity but as a strategic technology that could transform their core businesses in the coming decades.
Geographic distribution of investments shows concentration in biotech hubs, with the Boston/Cambridge area, San Francisco Bay Area, and emerging clusters in Europe (particularly the UK and Switzerland) attracting the majority of funding. This regional concentration facilitates collaboration between academic institutions, startups, and established industry players.
Investment trends indicate increasing confidence in the commercial potential of DNA data storage, with funding rounds growing in size and frequency. Early-stage investments typically focus on fundamental technological breakthroughs in DNA synthesis and sequencing, while later-stage funding targets scaling capabilities and developing commercial applications.
The investment ecosystem has evolved to include specialized accelerators and incubators dedicated to supporting DNA storage startups. Programs like IndieBio and Y Combinator have created tailored tracks for companies in this space, providing not only capital but also specialized mentorship and access to laboratory facilities.
Return on investment timelines remain longer than typical venture investments, with investors recognizing the extended development cycles inherent in deep tech. This has led to the emergence of patient capital sources specifically structured to accommodate the unique development timeline of DNA storage technologies, with investment horizons extending to 7-10 years rather than the traditional 3-5 year venture capital cycle.
Regulatory Framework for Biological Data Storage
The regulatory landscape for DNA data storage is evolving rapidly as this emerging technology approaches commercial viability. Currently, DNA data storage exists in a regulatory gray area, with no specific frameworks designed to address its unique characteristics. Instead, it falls under multiple existing regulatory domains including data protection laws, biosafety regulations, and intellectual property frameworks.
In the United States, the FDA and EPA have preliminary oversight of synthetic DNA technologies, but neither agency has established clear guidelines for data storage applications. The EU's more precautionary approach is evident in its General Data Protection Regulation (GDPR), which, while not specifically addressing DNA storage, contains provisions that would impact how personal data stored in DNA could be handled and protected.
Biosafety regulations present another critical regulatory dimension. The Cartagena Protocol on Biosafety provides international guidelines for the safe handling of modified biological materials, which could potentially apply to engineered DNA storage systems. National biosafety frameworks vary significantly, creating a complex compliance landscape for companies operating globally in this space.
Intellectual property protection represents a third regulatory pillar. Patent offices worldwide are grappling with how to classify and evaluate DNA data storage innovations. The dual nature of these technologies—both biological and computational—creates unique challenges for patent examiners and applicants alike.
Standardization efforts are beginning to emerge through organizations like the DNA Data Storage Alliance, which is working to establish technical standards that could inform future regulatory frameworks. These efforts are crucial for ensuring interoperability and safety across different implementations of the technology.
Looking forward, regulatory development will likely follow a co-evolutionary path with the technology itself. Early-stage partnerships between industry pioneers and regulatory bodies will be essential in crafting frameworks that balance innovation with appropriate safeguards. Companies like Twist Bioscience and Microsoft are already engaging with policymakers to help shape these emerging regulations.
For venture investors and strategic partners in this space, regulatory uncertainty represents both a risk and an opportunity. Those who actively participate in regulatory development may gain competitive advantages through favorable framework design, while those who ignore regulatory considerations may face significant barriers to market entry.
In the United States, the FDA and EPA have preliminary oversight of synthetic DNA technologies, but neither agency has established clear guidelines for data storage applications. The EU's more precautionary approach is evident in its General Data Protection Regulation (GDPR), which, while not specifically addressing DNA storage, contains provisions that would impact how personal data stored in DNA could be handled and protected.
Biosafety regulations present another critical regulatory dimension. The Cartagena Protocol on Biosafety provides international guidelines for the safe handling of modified biological materials, which could potentially apply to engineered DNA storage systems. National biosafety frameworks vary significantly, creating a complex compliance landscape for companies operating globally in this space.
Intellectual property protection represents a third regulatory pillar. Patent offices worldwide are grappling with how to classify and evaluate DNA data storage innovations. The dual nature of these technologies—both biological and computational—creates unique challenges for patent examiners and applicants alike.
Standardization efforts are beginning to emerge through organizations like the DNA Data Storage Alliance, which is working to establish technical standards that could inform future regulatory frameworks. These efforts are crucial for ensuring interoperability and safety across different implementations of the technology.
Looking forward, regulatory development will likely follow a co-evolutionary path with the technology itself. Early-stage partnerships between industry pioneers and regulatory bodies will be essential in crafting frameworks that balance innovation with appropriate safeguards. Companies like Twist Bioscience and Microsoft are already engaging with policymakers to help shape these emerging regulations.
For venture investors and strategic partners in this space, regulatory uncertainty represents both a risk and an opportunity. Those who actively participate in regulatory development may gain competitive advantages through favorable framework design, while those who ignore regulatory considerations may face significant barriers to market entry.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!