

Sequencing Workflows And Throughput Optimization For DNA Data Storage
AUG 27, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
DNA Data Storage Technology Background and Objectives
DNA data storage represents a revolutionary approach to digital information preservation, leveraging the biological properties of deoxyribonucleic acid to store vast amounts of data in an incredibly dense format. The concept emerged in the 1960s with the recognition of DNA's information-carrying capacity, but practical implementations only began materializing in the late 1980s. The field has experienced accelerated development over the past decade, driven by advancements in DNA synthesis and sequencing technologies.
The evolution of DNA data storage technology has been marked by several milestone achievements. In 2012, researchers at Harvard University encoded a 52,000-word book in DNA, demonstrating the feasibility of the approach. By 2019, scientists had successfully stored and retrieved 16GB of data from synthetic DNA molecules, highlighting the technology's potential for high-capacity storage applications.
Current DNA data storage systems operate through a workflow that converts binary digital data into DNA nucleotide sequences, synthesizes these sequences, stores the resulting DNA molecules, and later retrieves the information through sequencing and decoding processes. The sequencing workflow represents a critical bottleneck in this pipeline, directly impacting throughput, accuracy, and cost-effectiveness of the entire system.
The primary objective of optimizing sequencing workflows for DNA data storage is to enhance read accuracy while maximizing throughput capacity. This involves developing improved sequencing methodologies that can rapidly and reliably decode information from synthesized DNA strands, even in the presence of synthesis errors or molecular degradation. Additionally, optimization aims to reduce the computational complexity associated with error correction and data reconstruction.
Technical goals include achieving sequencing speeds that enable practical retrieval times for large datasets, minimizing error rates to below 10^-9 per nucleotide, and developing scalable workflows capable of handling petabyte-scale storage systems. Furthermore, the technology aims to establish protocols that maintain data integrity over centuries, leveraging DNA's exceptional stability under proper storage conditions.
The long-term vision encompasses creating end-to-end DNA data storage systems with throughput capabilities comparable to traditional electronic storage media, while offering superior longevity, density, and sustainability. This requires fundamental advancements in sequencing technologies, particularly in areas of parallel processing, molecular manipulation, and signal detection sensitivity.
As global data generation continues to accelerate exponentially, DNA data storage represents a promising solution to the impending storage crisis, potentially offering storage densities up to 1,000 times greater than conventional electronic media while consuming minimal energy during long-term preservation.
The evolution of DNA data storage technology has been marked by several milestone achievements. In 2012, researchers at Harvard University encoded a 52,000-word book in DNA, demonstrating the feasibility of the approach. By 2019, scientists had successfully stored and retrieved 16GB of data from synthetic DNA molecules, highlighting the technology's potential for high-capacity storage applications.
Current DNA data storage systems operate through a workflow that converts binary digital data into DNA nucleotide sequences, synthesizes these sequences, stores the resulting DNA molecules, and later retrieves the information through sequencing and decoding processes. The sequencing workflow represents a critical bottleneck in this pipeline, directly impacting throughput, accuracy, and cost-effectiveness of the entire system.
The primary objective of optimizing sequencing workflows for DNA data storage is to enhance read accuracy while maximizing throughput capacity. This involves developing improved sequencing methodologies that can rapidly and reliably decode information from synthesized DNA strands, even in the presence of synthesis errors or molecular degradation. Additionally, optimization aims to reduce the computational complexity associated with error correction and data reconstruction.
Technical goals include achieving sequencing speeds that enable practical retrieval times for large datasets, minimizing error rates to below 10^-9 per nucleotide, and developing scalable workflows capable of handling petabyte-scale storage systems. Furthermore, the technology aims to establish protocols that maintain data integrity over centuries, leveraging DNA's exceptional stability under proper storage conditions.
The long-term vision encompasses creating end-to-end DNA data storage systems with throughput capabilities comparable to traditional electronic storage media, while offering superior longevity, density, and sustainability. This requires fundamental advancements in sequencing technologies, particularly in areas of parallel processing, molecular manipulation, and signal detection sensitivity.
As global data generation continues to accelerate exponentially, DNA data storage represents a promising solution to the impending storage crisis, potentially offering storage densities up to 1,000 times greater than conventional electronic media while consuming minimal energy during long-term preservation.
Market Analysis for DNA-Based Storage Solutions
The DNA data storage market is experiencing significant growth, driven by the exponential increase in global data production and the limitations of conventional storage technologies. Current projections estimate the DNA data storage market to reach approximately $3.3 billion by 2030, with a compound annual growth rate exceeding 58% between 2023 and 2030. This remarkable growth trajectory reflects the urgent need for innovative storage solutions that can address the challenges of data explosion.
The primary market segments for DNA-based storage solutions include government archives, scientific research institutions, healthcare organizations, and large technology companies with massive data centers. These sectors generate enormous volumes of cold data that require long-term preservation but infrequent access. The healthcare and life sciences segment represents the largest potential market, accounting for roughly 30% of the projected demand, followed by government and defense applications at 25%.
Customer requirements across these segments emphasize several key factors: storage density, longevity, data integrity, retrieval speed, and cost-effectiveness. While DNA storage excels in density (theoretical capacity of 455 exabytes per gram) and longevity (thousands of years under proper conditions), current limitations in sequencing workflows and throughput optimization represent significant barriers to widespread adoption.
Market analysis reveals that the cost structure remains prohibitive for mainstream commercial applications, with current estimates at approximately $1,000 per megabyte of stored data. Industry experts project that technological advancements in sequencing workflows could reduce this cost to $100 per gigabyte by 2025, potentially reaching $1 per gigabyte by 2030, which would position DNA storage as competitive with magnetic tape for archival purposes.
Regional market distribution shows North America leading with approximately 45% market share, followed by Europe (30%) and Asia-Pacific (20%). The United States, United Kingdom, China, and Germany host the majority of companies and research institutions advancing DNA storage technologies, with significant government funding initiatives supporting development in these regions.
Customer adoption patterns indicate a phased approach, beginning with specialized applications in national archives and critical scientific data preservation before expanding to broader commercial applications. Market surveys suggest that 78% of enterprise data center operators express interest in DNA storage solutions, but cite sequencing workflow efficiency and throughput optimization as critical factors influencing adoption decisions.
The primary market segments for DNA-based storage solutions include government archives, scientific research institutions, healthcare organizations, and large technology companies with massive data centers. These sectors generate enormous volumes of cold data that require long-term preservation but infrequent access. The healthcare and life sciences segment represents the largest potential market, accounting for roughly 30% of the projected demand, followed by government and defense applications at 25%.
Customer requirements across these segments emphasize several key factors: storage density, longevity, data integrity, retrieval speed, and cost-effectiveness. While DNA storage excels in density (theoretical capacity of 455 exabytes per gram) and longevity (thousands of years under proper conditions), current limitations in sequencing workflows and throughput optimization represent significant barriers to widespread adoption.
Market analysis reveals that the cost structure remains prohibitive for mainstream commercial applications, with current estimates at approximately $1,000 per megabyte of stored data. Industry experts project that technological advancements in sequencing workflows could reduce this cost to $100 per gigabyte by 2025, potentially reaching $1 per gigabyte by 2030, which would position DNA storage as competitive with magnetic tape for archival purposes.
Regional market distribution shows North America leading with approximately 45% market share, followed by Europe (30%) and Asia-Pacific (20%). The United States, United Kingdom, China, and Germany host the majority of companies and research institutions advancing DNA storage technologies, with significant government funding initiatives supporting development in these regions.
Customer adoption patterns indicate a phased approach, beginning with specialized applications in national archives and critical scientific data preservation before expanding to broader commercial applications. Market surveys suggest that 78% of enterprise data center operators express interest in DNA storage solutions, but cite sequencing workflow efficiency and throughput optimization as critical factors influencing adoption decisions.
Current Sequencing Challenges and Limitations
Despite significant advancements in DNA sequencing technologies, current DNA data storage systems face several critical challenges that limit their practical implementation. The throughput of existing sequencing platforms remains insufficient for large-scale DNA data storage applications, with even high-end systems like Illumina NovaSeq and Oxford Nanopore PromethION struggling to match the data retrieval speeds required for competitive storage solutions. Most commercial sequencing platforms were designed primarily for genomic applications rather than synthetic DNA data retrieval, creating a fundamental mismatch in optimization parameters.
Error rates present another significant limitation, particularly for nanopore-based technologies which, while offering advantages in portability and real-time sequencing, still exhibit error rates of 5-15% compared to the sub-1% rates of Illumina platforms. These error rates necessitate complex error correction algorithms that add computational overhead and reduce effective throughput.
Sample preparation workflows remain labor-intensive and time-consuming, typically requiring 4-24 hours before sequencing can begin. The complexity of library preparation protocols, including DNA extraction, amplification, and adapter ligation, creates bottlenecks that significantly impact overall data retrieval times. Automation solutions exist but remain costly and not fully optimized for DNA data storage applications.
Sequencing depth requirements further complicate matters, as DNA data storage systems typically require higher coverage (30-100x) than many biological applications to ensure data integrity. This requirement substantially increases sequencing time and cost per gigabyte of recovered data.
The bioinformatics pipeline for converting sequenced DNA back to digital data represents another major challenge. Current workflows involve multiple computational steps including base calling, quality filtering, demultiplexing, and decoding, each adding latency to the data retrieval process. These pipelines were largely developed for genomic applications and lack optimization for the specific characteristics of synthetic DNA data.
Cost remains prohibitively high, with current sequencing expenses ranging from $100-1000 per gigabyte of recovered data, orders of magnitude higher than conventional digital storage technologies. While sequencing costs have declined historically, the rate of decrease has slowed in recent years, suggesting that revolutionary rather than evolutionary changes may be needed to achieve economic viability.
Scalability issues also persist, as most current sequencing platforms cannot be easily parallelized to the degree necessary for handling petabyte-scale DNA data archives. The physical footprint and infrastructure requirements of high-throughput sequencers further limit deployment flexibility in diverse storage environments.
Error rates present another significant limitation, particularly for nanopore-based technologies which, while offering advantages in portability and real-time sequencing, still exhibit error rates of 5-15% compared to the sub-1% rates of Illumina platforms. These error rates necessitate complex error correction algorithms that add computational overhead and reduce effective throughput.
Sample preparation workflows remain labor-intensive and time-consuming, typically requiring 4-24 hours before sequencing can begin. The complexity of library preparation protocols, including DNA extraction, amplification, and adapter ligation, creates bottlenecks that significantly impact overall data retrieval times. Automation solutions exist but remain costly and not fully optimized for DNA data storage applications.
Sequencing depth requirements further complicate matters, as DNA data storage systems typically require higher coverage (30-100x) than many biological applications to ensure data integrity. This requirement substantially increases sequencing time and cost per gigabyte of recovered data.
The bioinformatics pipeline for converting sequenced DNA back to digital data represents another major challenge. Current workflows involve multiple computational steps including base calling, quality filtering, demultiplexing, and decoding, each adding latency to the data retrieval process. These pipelines were largely developed for genomic applications and lack optimization for the specific characteristics of synthetic DNA data.
Cost remains prohibitively high, with current sequencing expenses ranging from $100-1000 per gigabyte of recovered data, orders of magnitude higher than conventional digital storage technologies. While sequencing costs have declined historically, the rate of decrease has slowed in recent years, suggesting that revolutionary rather than evolutionary changes may be needed to achieve economic viability.
Scalability issues also persist, as most current sequencing platforms cannot be easily parallelized to the degree necessary for handling petabyte-scale DNA data archives. The physical footprint and infrastructure requirements of high-throughput sequencers further limit deployment flexibility in diverse storage environments.
Current Sequencing Workflow Optimization Approaches
01 High-throughput DNA synthesis and sequencing methods
Advanced methods for high-throughput DNA synthesis and sequencing are crucial for improving DNA data storage throughput. These techniques enable faster writing and reading of information stored in DNA molecules, significantly increasing the overall throughput of DNA data storage systems. Innovations in this area include parallel synthesis processes, improved sequencing technologies, and optimized molecular biology protocols that allow for more efficient data encoding and retrieval.- High-throughput DNA synthesis and sequencing methods: Advanced DNA synthesis and sequencing technologies have been developed to increase the throughput of DNA data storage systems. These methods include parallel synthesis techniques, improved sequencing platforms, and optimized protocols that allow for faster writing and reading of information stored in DNA. By enhancing the efficiency of these processes, the overall throughput of DNA data storage systems can be significantly increased, making them more practical for large-scale data storage applications.
- Encoding and decoding algorithms for DNA data storage: Specialized encoding and decoding algorithms have been developed to optimize the throughput of DNA data storage systems. These algorithms efficiently convert digital information into DNA sequences and back, while incorporating error correction mechanisms to ensure data integrity. Advanced computational methods help maximize the information density that can be stored in DNA molecules while maintaining reliable retrieval, thereby increasing the effective throughput of the storage system.
- Parallel processing and automation in DNA data storage: Implementing parallel processing and automation technologies in DNA data storage systems significantly enhances throughput. Automated liquid handling systems, microfluidic platforms, and robotic systems enable simultaneous processing of multiple DNA samples. These approaches reduce the time required for DNA synthesis, amplification, and sequencing operations, thereby increasing the overall throughput of the storage system and making it more scalable for practical applications.
- Storage density optimization techniques: Various techniques have been developed to optimize the storage density of DNA data storage systems, which directly impacts throughput. These include molecular addressing schemes, improved DNA strand organization, and innovative storage architectures that maximize the amount of information that can be stored and retrieved per unit of time. By increasing the information density, these methods enhance the effective throughput of DNA-based storage systems.
- Error correction and data integrity methods: Advanced error correction and data integrity methods have been developed to improve the reliability and throughput of DNA data storage systems. These include redundancy coding, error-detecting codes, and sophisticated algorithms that can identify and correct errors during the reading process. By reducing the need for repeated reads or writes, these methods enhance the effective throughput of DNA data storage while maintaining data integrity even at higher processing speeds.
02 Error correction and data encoding algorithms
Sophisticated error correction and data encoding algorithms are essential for reliable high-throughput DNA data storage. These computational approaches help to overcome the inherent error rates in DNA synthesis and sequencing, ensuring data integrity while maximizing storage density. Advanced encoding schemes optimize how digital information is converted into DNA sequences, while error correction mechanisms allow for accurate data recovery despite molecular degradation or sequencing errors.Expand Specific Solutions03 Automated systems for DNA data processing
Automated systems and platforms for DNA data processing enhance throughput by streamlining the workflow from digital data to DNA storage and back. These systems integrate robotics, microfluidics, and computational components to automate the encoding, synthesis, storage, retrieval, and decoding processes. By reducing manual handling and increasing process efficiency, these automated platforms significantly improve the speed and scale of DNA data storage operations.Expand Specific Solutions04 Parallel processing techniques for DNA data storage
Parallel processing techniques enable simultaneous handling of multiple DNA data storage operations, dramatically increasing throughput. These approaches involve concurrent synthesis or sequencing of multiple DNA strands, parallel computational processing for encoding and decoding, and multiplexed storage and retrieval systems. By performing operations in parallel rather than sequentially, these techniques overcome bottlenecks in the DNA data storage pipeline.Expand Specific Solutions05 Molecular indexing and addressing systems
Molecular indexing and addressing systems improve DNA data storage throughput by enabling random access to specific data within large DNA archives. These systems incorporate unique molecular identifiers or barcodes into DNA sequences, allowing for selective retrieval of targeted information without processing the entire dataset. Efficient indexing strategies reduce the time and resources required for data access, significantly enhancing the practical throughput of DNA storage systems.Expand Specific Solutions
Leading Companies and Research Institutions in DNA Storage
The DNA data storage market is currently in an early growth phase, characterized by significant research activity but limited commercial deployment. The global market size is estimated to reach $2-3 billion by 2025, with a CAGR exceeding 30%. Regarding technical maturity, the field is transitioning from proof-of-concept to early commercialization, with key players developing distinct approaches. Illumina leads in sequencing technology infrastructure, while BGI and Roche Sequencing Solutions are advancing high-throughput sequencing platforms. Academic institutions like Tianjin University and Huazhong University are pioneering algorithmic innovations. Technology companies including IBM, Huawei, and Samsung are developing computational solutions for throughput optimization. Specialized firms such as Edico Genome, Atgenomix, and SOPHiA GENETICS are creating workflow management systems to address bottlenecks in data processing pipelines.
Illumina, Inc.
Technical Solution: Illumina has developed DRAGEN (Dynamic Read Analysis for GENomics) Bio-IT Platform, a comprehensive suite for DNA data storage optimization. This hardware-accelerated platform implements highly optimized algorithms for mapping, aligning, sorting, and variant calling, significantly reducing analysis time from hours to minutes. Their sequencing workflow optimization includes parallel processing capabilities that can analyze multiple samples simultaneously while maintaining high accuracy. Illumina's platform incorporates machine learning algorithms to predict and mitigate bottlenecks in the sequencing pipeline, automatically adjusting computational resources based on workload demands. Their recent advancements include integration of compression algorithms specifically designed for genomic data, reducing storage requirements by up to 80% compared to standard formats while preserving data integrity. The platform also features automated quality control checkpoints throughout the workflow to ensure data reliability and consistency.
Strengths: Industry-leading throughput capabilities with proven scalability for large genomic datasets; comprehensive end-to-end solution from sequencing to storage. Weaknesses: Proprietary ecosystem may limit interoperability with third-party tools; higher initial investment compared to some competitors.
BGI Research
Technical Solution: BGI Research has pioneered the DNBSEQ™ technology platform for DNA data storage optimization, featuring a unique DNA nanoball (DNB) preparation method that significantly enhances sequencing accuracy while reducing reagent consumption. Their workflow optimization approach incorporates a modular design that allows for flexible configuration based on throughput requirements, from small-scale research projects to massive population-level studies. BGI's data processing pipeline employs distributed computing architecture with load balancing algorithms that dynamically allocate computational resources across different stages of the workflow, eliminating processing bottlenecks. Their storage solution implements a tiered approach where frequently accessed data remains in high-performance storage while archival data transitions to more cost-effective cold storage with specialized compression. BGI has also developed proprietary algorithms for error correction in long-read sequencing data, improving both storage efficiency and data integrity for challenging genomic regions.
Strengths: Cost-effective sequencing technology with scalable throughput options; integrated hardware and software ecosystem designed specifically for genomic data. Weaknesses: Less market penetration in Western countries compared to competitors; some proprietary formats may require conversion for use with third-party analysis tools.
Key Patents and Breakthroughs in Throughput Enhancement
Methods and systems for DNA data storage
PatentWO2018132457A1
Innovation
- A DNA data storage system utilizing a DNA reading device with molecular sensors and encoder/decoder algorithms that enable high-density, low-cost, and long-lasting storage by converting binary data into DNA sequences and back, using CMOS chip-based molecular electronics sensors for efficient reading and writing.
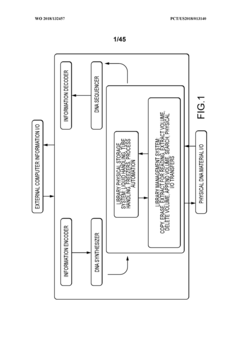
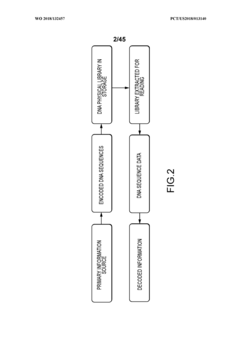
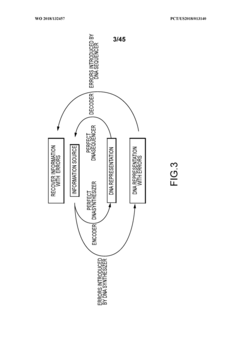
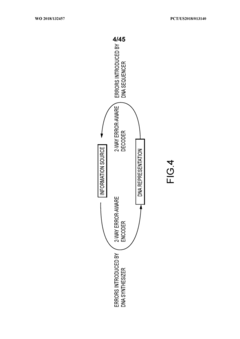
Method and apparatus for performing data storage by using DNA, and storage device
PatentWO2022266802A1
Innovation
- By converting the binary sequence of the data to be stored into a base sequence and dividing it into core sequence fragments with overlapping regions, using a pre-synthesized DNA molecule library for storage, the total number of bases in DNA synthesis and the number of synthesized DNA molecules are reduced. , reduce storage costs.
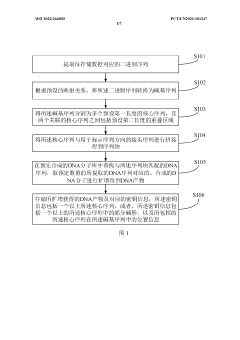


Regulatory Framework for Biological Data Storage Systems
The regulatory landscape for DNA data storage systems is rapidly evolving as this technology transitions from research laboratories to potential commercial applications. Currently, biological data storage systems exist in a regulatory gray area, with oversight divided among multiple agencies including the FDA, EPA, and in some jurisdictions, specialized biotechnology regulatory bodies. The lack of a unified regulatory framework specifically addressing DNA data storage creates uncertainty for researchers and companies developing these technologies.
Key regulatory considerations include biosafety protocols that must be established to prevent unintended environmental release of synthetic DNA containing encoded data. These protocols typically require physical containment measures, chemical modifications to prevent biological activity of storage DNA, and strict disposal procedures. Additionally, biosecurity regulations aim to prevent malicious use of DNA synthesis technology, requiring screening of DNA sequences against databases of known pathogens and toxins before synthesis.
Data privacy and security regulations present another critical dimension, as information stored in DNA may include sensitive personal data, intellectual property, or classified information. Existing frameworks like GDPR in Europe and HIPAA in the United States may apply to DNA-stored data, but their application remains untested in courts. The durability of DNA as a storage medium (potentially thousands of years) creates unprecedented regulatory challenges regarding long-term data governance and access controls.
Standardization efforts are emerging through organizations like the DNA Data Storage Alliance and ISO technical committees, working to establish industry standards for DNA synthesis, sequencing, and data encoding/decoding processes specific to storage applications. These standards will be crucial for regulatory compliance and interoperability between different DNA storage systems.
International regulatory harmonization remains a significant challenge, with different approaches across regions potentially creating barriers to global deployment of DNA data storage technologies. The European Union has taken a more precautionary approach through its biotechnology regulations, while the United States has generally adopted a more innovation-friendly regulatory stance.
As sequencing workflows and throughput optimization continue to advance, regulatory frameworks will need to evolve to address novel challenges while balancing innovation with appropriate safeguards. Future regulatory developments will likely include specialized certification processes for DNA data storage facilities, chain-of-custody requirements for DNA-stored information, and specific provisions addressing the unique characteristics of biological storage media.
Key regulatory considerations include biosafety protocols that must be established to prevent unintended environmental release of synthetic DNA containing encoded data. These protocols typically require physical containment measures, chemical modifications to prevent biological activity of storage DNA, and strict disposal procedures. Additionally, biosecurity regulations aim to prevent malicious use of DNA synthesis technology, requiring screening of DNA sequences against databases of known pathogens and toxins before synthesis.
Data privacy and security regulations present another critical dimension, as information stored in DNA may include sensitive personal data, intellectual property, or classified information. Existing frameworks like GDPR in Europe and HIPAA in the United States may apply to DNA-stored data, but their application remains untested in courts. The durability of DNA as a storage medium (potentially thousands of years) creates unprecedented regulatory challenges regarding long-term data governance and access controls.
Standardization efforts are emerging through organizations like the DNA Data Storage Alliance and ISO technical committees, working to establish industry standards for DNA synthesis, sequencing, and data encoding/decoding processes specific to storage applications. These standards will be crucial for regulatory compliance and interoperability between different DNA storage systems.
International regulatory harmonization remains a significant challenge, with different approaches across regions potentially creating barriers to global deployment of DNA data storage technologies. The European Union has taken a more precautionary approach through its biotechnology regulations, while the United States has generally adopted a more innovation-friendly regulatory stance.
As sequencing workflows and throughput optimization continue to advance, regulatory frameworks will need to evolve to address novel challenges while balancing innovation with appropriate safeguards. Future regulatory developments will likely include specialized certification processes for DNA data storage facilities, chain-of-custody requirements for DNA-stored information, and specific provisions addressing the unique characteristics of biological storage media.
Cost-Benefit Analysis of DNA Storage Implementation
Implementing DNA storage systems requires careful consideration of economic factors alongside technical capabilities. Current DNA synthesis costs range from $0.001 to $0.0001 per base, while sequencing costs have decreased to approximately $1,000 per human genome. For practical data storage applications, these costs remain prohibitively high compared to conventional electronic storage media. A comprehensive cost model indicates that DNA storage becomes economically viable only at scales exceeding 1 petabyte, with long-term archival requirements of 50+ years.
The throughput optimization of sequencing workflows directly impacts the cost-effectiveness of DNA data storage systems. Enhanced sequencing speeds reduce operational expenses and increase the practical utility of DNA as a storage medium. Recent advancements in nanopore sequencing technology have demonstrated potential for real-time data access with significantly lower capital equipment investments compared to traditional sequencing platforms.
Energy consumption represents another critical economic factor. DNA storage offers remarkable efficiency advantages, requiring minimal energy for long-term maintenance compared to conventional data centers that consume approximately 1% of global electricity. This energy efficiency translates to substantial operational cost savings over extended storage periods, particularly for cold storage applications where data access frequency is low.
Infrastructure requirements present both challenges and opportunities. While DNA storage necessitates specialized laboratory equipment for synthesis and sequencing, it eliminates the need for continuous power supply and regular hardware refreshes that electronic storage demands. The physical footprint advantage is substantial - a single gram of DNA can theoretically store 215 petabytes of data, offering orders of magnitude improvement in storage density compared to magnetic or solid-state technologies.
The economic viability timeline suggests DNA storage will initially serve niche applications where long-term preservation and extreme density justify premium costs. As synthesis and sequencing technologies continue to advance, broader commercial adoption becomes feasible. Industry projections indicate potential cost parity with magnetic tape storage by 2030-2035 for specific use cases, contingent upon continued investment in optimizing sequencing workflows and throughput.
Return on investment calculations must account for the extraordinary durability of DNA storage. Unlike electronic media requiring migration every 3-5 years, properly preserved DNA can maintain data integrity for centuries, eliminating costly refresh cycles and providing substantial lifetime value despite higher initial implementation costs.
The throughput optimization of sequencing workflows directly impacts the cost-effectiveness of DNA data storage systems. Enhanced sequencing speeds reduce operational expenses and increase the practical utility of DNA as a storage medium. Recent advancements in nanopore sequencing technology have demonstrated potential for real-time data access with significantly lower capital equipment investments compared to traditional sequencing platforms.
Energy consumption represents another critical economic factor. DNA storage offers remarkable efficiency advantages, requiring minimal energy for long-term maintenance compared to conventional data centers that consume approximately 1% of global electricity. This energy efficiency translates to substantial operational cost savings over extended storage periods, particularly for cold storage applications where data access frequency is low.
Infrastructure requirements present both challenges and opportunities. While DNA storage necessitates specialized laboratory equipment for synthesis and sequencing, it eliminates the need for continuous power supply and regular hardware refreshes that electronic storage demands. The physical footprint advantage is substantial - a single gram of DNA can theoretically store 215 petabytes of data, offering orders of magnitude improvement in storage density compared to magnetic or solid-state technologies.
The economic viability timeline suggests DNA storage will initially serve niche applications where long-term preservation and extreme density justify premium costs. As synthesis and sequencing technologies continue to advance, broader commercial adoption becomes feasible. Industry projections indicate potential cost parity with magnetic tape storage by 2030-2035 for specific use cases, contingent upon continued investment in optimizing sequencing workflows and throughput.
Return on investment calculations must account for the extraordinary durability of DNA storage. Unlike electronic media requiring migration every 3-5 years, properly preserved DNA can maintain data integrity for centuries, eliminating costly refresh cycles and providing substantial lifetime value despite higher initial implementation costs.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!