Primer Design And Cross-Talk Control For DNA Data Storage
AUG 27, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
DNA Data Storage Primer Design Background and Objectives
DNA data storage has emerged as a promising solution to the exponential growth of digital data, leveraging the remarkable information density and longevity of DNA molecules. The evolution of this technology can be traced back to the 1980s when the theoretical possibility of using DNA for data storage was first proposed. However, significant practical advancements only materialized in the early 2000s with pioneering experiments demonstrating the feasibility of encoding and retrieving digital information from synthesized DNA sequences.
The field has experienced accelerated development over the past decade, with milestone achievements including Microsoft's 200MB DNA storage system in 2016 and subsequent demonstrations of petabyte-scale storage potential. This rapid progress has been driven by parallel advancements in DNA synthesis and sequencing technologies, which have dramatically reduced costs and improved accuracy.
Primer design represents a critical component in DNA data storage systems, functioning as the addressing mechanism that enables selective access to stored information. Effective primers must balance specificity, thermodynamic stability, and compatibility with the overall storage architecture. The evolution of primer design strategies has moved from simple complementary sequences to sophisticated computational approaches that optimize for minimal cross-hybridization.
The primary technical objective in this domain is to develop robust primer design methodologies that enable reliable random access to stored data while minimizing cross-talk between different data blocks. This involves creating primers that can selectively amplify target sequences without inadvertently accessing unintended regions, even in the presence of millions of distinct DNA strands.
Current research aims to establish standardized frameworks for primer design that can accommodate increasing storage densities while maintaining retrieval accuracy. The field is trending toward algorithmic approaches that incorporate machine learning techniques to predict and mitigate potential cross-hybridization events, thereby enhancing the overall system reliability.
Looking forward, the technology trajectory points toward integrated primer design systems that dynamically adapt to the specific characteristics of the encoded data, the storage environment, and the retrieval requirements. The ultimate goal is to achieve error-free random access to exabyte-scale DNA data archives with minimal latency and energy consumption, positioning DNA storage as a viable alternative to conventional electronic storage technologies for long-term data preservation.
The field has experienced accelerated development over the past decade, with milestone achievements including Microsoft's 200MB DNA storage system in 2016 and subsequent demonstrations of petabyte-scale storage potential. This rapid progress has been driven by parallel advancements in DNA synthesis and sequencing technologies, which have dramatically reduced costs and improved accuracy.
Primer design represents a critical component in DNA data storage systems, functioning as the addressing mechanism that enables selective access to stored information. Effective primers must balance specificity, thermodynamic stability, and compatibility with the overall storage architecture. The evolution of primer design strategies has moved from simple complementary sequences to sophisticated computational approaches that optimize for minimal cross-hybridization.
The primary technical objective in this domain is to develop robust primer design methodologies that enable reliable random access to stored data while minimizing cross-talk between different data blocks. This involves creating primers that can selectively amplify target sequences without inadvertently accessing unintended regions, even in the presence of millions of distinct DNA strands.
Current research aims to establish standardized frameworks for primer design that can accommodate increasing storage densities while maintaining retrieval accuracy. The field is trending toward algorithmic approaches that incorporate machine learning techniques to predict and mitigate potential cross-hybridization events, thereby enhancing the overall system reliability.
Looking forward, the technology trajectory points toward integrated primer design systems that dynamically adapt to the specific characteristics of the encoded data, the storage environment, and the retrieval requirements. The ultimate goal is to achieve error-free random access to exabyte-scale DNA data archives with minimal latency and energy consumption, positioning DNA storage as a viable alternative to conventional electronic storage technologies for long-term data preservation.
Market Analysis for DNA-Based Data Storage Solutions
The global market for data storage solutions is experiencing unprecedented growth, driven by the exponential increase in data generation across industries. Traditional storage technologies are approaching their physical limitations, creating a significant opportunity for alternative solutions like DNA-based data storage. Current projections indicate the digital universe will reach 175 zettabytes by 2025, with existing storage infrastructure struggling to accommodate this volume efficiently and sustainably.
DNA data storage represents a revolutionary approach to this challenge, offering theoretical storage densities of up to 455 exabytes per gram of DNA. This remarkable capacity positions DNA-based solutions as a potentially transformative technology for long-term archival storage. Market analysis reveals growing interest from major data center operators, cloud service providers, and organizations with critical long-term data preservation needs, including government archives, research institutions, and healthcare organizations.
The current market valuation for DNA data storage remains relatively small, primarily consisting of research funding and early commercial explorations. However, industry forecasts suggest significant growth potential as the technology matures. Key market drivers include the increasing cost-effectiveness of DNA synthesis and sequencing technologies, which have seen dramatic price reductions over the past decade, making commercial applications increasingly viable.
Market segmentation analysis indicates three primary application categories emerging: ultra-long-term archival storage (100+ years), high-density storage for rarely accessed data, and specialized applications requiring biological integration. The primer design and cross-talk control technologies represent critical enablers for market adoption, as they directly impact storage density, reliability, and cost-effectiveness of the overall solution.
Geographical market distribution shows North America leading in research and development investments, with significant activity also occurring in Europe and Asia-Pacific regions. The competitive landscape features both specialized biotechnology startups focused exclusively on DNA data storage and established technology corporations exploring diversification opportunities.
Customer adoption barriers include current high costs, relatively slow read/write speeds, and concerns about technological maturity. Market research indicates that initial commercial adoption will likely focus on specialized use cases where traditional storage solutions are inadequate, such as century-scale archival requirements or environments with extreme physical constraints.
The market timeline suggests pilot commercial deployments within 3-5 years, with broader market penetration expected in the 7-10 year timeframe as costs decrease and performance improves. Effective primer design and cross-talk control technologies will be decisive factors in accelerating this timeline by addressing fundamental technical challenges that currently limit commercial viability.
DNA data storage represents a revolutionary approach to this challenge, offering theoretical storage densities of up to 455 exabytes per gram of DNA. This remarkable capacity positions DNA-based solutions as a potentially transformative technology for long-term archival storage. Market analysis reveals growing interest from major data center operators, cloud service providers, and organizations with critical long-term data preservation needs, including government archives, research institutions, and healthcare organizations.
The current market valuation for DNA data storage remains relatively small, primarily consisting of research funding and early commercial explorations. However, industry forecasts suggest significant growth potential as the technology matures. Key market drivers include the increasing cost-effectiveness of DNA synthesis and sequencing technologies, which have seen dramatic price reductions over the past decade, making commercial applications increasingly viable.
Market segmentation analysis indicates three primary application categories emerging: ultra-long-term archival storage (100+ years), high-density storage for rarely accessed data, and specialized applications requiring biological integration. The primer design and cross-talk control technologies represent critical enablers for market adoption, as they directly impact storage density, reliability, and cost-effectiveness of the overall solution.
Geographical market distribution shows North America leading in research and development investments, with significant activity also occurring in Europe and Asia-Pacific regions. The competitive landscape features both specialized biotechnology startups focused exclusively on DNA data storage and established technology corporations exploring diversification opportunities.
Customer adoption barriers include current high costs, relatively slow read/write speeds, and concerns about technological maturity. Market research indicates that initial commercial adoption will likely focus on specialized use cases where traditional storage solutions are inadequate, such as century-scale archival requirements or environments with extreme physical constraints.
The market timeline suggests pilot commercial deployments within 3-5 years, with broader market penetration expected in the 7-10 year timeframe as costs decrease and performance improves. Effective primer design and cross-talk control technologies will be decisive factors in accelerating this timeline by addressing fundamental technical challenges that currently limit commercial viability.
Current Challenges in DNA Primer Design and Cross-Talk
DNA data storage faces significant technical hurdles in primer design and cross-talk control. The current primer design methodologies struggle with scalability as storage capacity increases, requiring thousands of unique primers that must maintain specificity while avoiding unwanted interactions. Traditional computational approaches become exponentially complex when dealing with large primer sets, leading to inefficient design processes and suboptimal primer selection.
Cross-talk between DNA strands represents one of the most persistent challenges in the field. When multiple DNA sequences are stored in the same solution, unintended hybridization between primers and non-target sequences can occur, resulting in data corruption during retrieval processes. Current systems report cross-talk rates of 5-15% in high-density storage environments, which is unacceptably high for practical applications requiring data integrity.
Temperature sensitivity further complicates primer functionality, as hybridization conditions must be precisely controlled to ensure specific binding. Even minor temperature fluctuations can dramatically increase cross-talk rates, making robust storage systems difficult to implement in variable environments. This temperature dependence limits the practical deployment of DNA storage technologies outside controlled laboratory settings.
The chemical stability of primers presents another significant challenge. DNA primers can degrade over time due to oxidation, hydrolysis, or enzymatic activity, potentially leading to data loss or corruption. Current preservation methods extend primer viability to several years, but fall short of the decades-long stability required for archival storage applications.
Synthesis errors in primers contribute substantially to system unreliability. Current DNA synthesis technologies introduce errors at rates of approximately 1 in 200 bases, creating primers with insertions, deletions, or substitutions that may bind incorrectly or fail to bind altogether. These errors compound in large-scale systems, reducing overall data retrieval accuracy.
Standardization remains elusive in the field, with researchers using diverse and often incompatible primer design approaches. The lack of unified protocols for primer design, cross-talk assessment, and quality control hampers progress and makes comparative analysis between different storage systems challenging.
Economic considerations also constrain advancement, as high-quality primer synthesis remains expensive at scale. The cost of synthesizing thousands of unique primers with high fidelity significantly impacts the economic viability of DNA data storage systems, particularly for applications requiring frequent data access and retrieval.
Cross-talk between DNA strands represents one of the most persistent challenges in the field. When multiple DNA sequences are stored in the same solution, unintended hybridization between primers and non-target sequences can occur, resulting in data corruption during retrieval processes. Current systems report cross-talk rates of 5-15% in high-density storage environments, which is unacceptably high for practical applications requiring data integrity.
Temperature sensitivity further complicates primer functionality, as hybridization conditions must be precisely controlled to ensure specific binding. Even minor temperature fluctuations can dramatically increase cross-talk rates, making robust storage systems difficult to implement in variable environments. This temperature dependence limits the practical deployment of DNA storage technologies outside controlled laboratory settings.
The chemical stability of primers presents another significant challenge. DNA primers can degrade over time due to oxidation, hydrolysis, or enzymatic activity, potentially leading to data loss or corruption. Current preservation methods extend primer viability to several years, but fall short of the decades-long stability required for archival storage applications.
Synthesis errors in primers contribute substantially to system unreliability. Current DNA synthesis technologies introduce errors at rates of approximately 1 in 200 bases, creating primers with insertions, deletions, or substitutions that may bind incorrectly or fail to bind altogether. These errors compound in large-scale systems, reducing overall data retrieval accuracy.
Standardization remains elusive in the field, with researchers using diverse and often incompatible primer design approaches. The lack of unified protocols for primer design, cross-talk assessment, and quality control hampers progress and makes comparative analysis between different storage systems challenging.
Economic considerations also constrain advancement, as high-quality primer synthesis remains expensive at scale. The cost of synthesizing thousands of unique primers with high fidelity significantly impacts the economic viability of DNA data storage systems, particularly for applications requiring frequent data access and retrieval.
Current Primer Design Methodologies and Cross-Talk Mitigation
01 Optical techniques for DNA data storage cross-talk control
Optical techniques are employed to minimize cross-talk in DNA data storage systems. These methods include specialized optical configurations, beam focusing techniques, and optical isolation strategies that help maintain signal integrity. Advanced optical systems can precisely target specific DNA storage locations while minimizing interference with adjacent storage areas, thereby reducing cross-talk between data channels and improving overall storage reliability and data retrieval accuracy.- Error correction techniques for DNA data storage: Various error correction techniques are employed in DNA data storage systems to minimize cross-talk and ensure data integrity. These include advanced coding schemes, redundancy mechanisms, and error detection algorithms specifically designed for the unique characteristics of DNA-based storage. These methods help to identify and correct errors that may occur during DNA synthesis, storage, or sequencing processes, thereby reducing cross-talk between adjacent data points.
- Spatial separation strategies for DNA data storage: Spatial separation techniques are implemented to control cross-talk in DNA data storage systems. By physically separating DNA molecules or creating distinct compartments for different data sets, interference between adjacent data points can be minimized. These strategies may involve microfluidic devices, nanoscale structures, or specialized storage containers that maintain physical boundaries between different DNA sequences, thereby reducing the risk of cross-contamination and cross-talk.
- Signal processing methods for cross-talk reduction: Advanced signal processing methods are utilized to reduce cross-talk in DNA data storage systems. These techniques involve sophisticated algorithms for signal filtering, noise reduction, and data extraction that can distinguish between intended signals and interference. By applying these processing methods during the reading and writing of DNA-stored data, the system can effectively minimize cross-talk and improve the accuracy of data retrieval.
- Molecular design optimization for cross-talk control: Optimizing the molecular design of DNA sequences used for data storage can significantly reduce cross-talk. This involves careful selection of nucleotide sequences that minimize unwanted hybridization between different data strands, designing primer regions that ensure specific amplification, and incorporating molecular spacers or barriers. These design considerations help to maintain data integrity by preventing unintended interactions between different DNA sequences.
- Optical and electronic systems for cross-talk control: Specialized optical and electronic systems are developed to control cross-talk in DNA data storage. These systems include advanced reading mechanisms that can precisely target specific DNA sequences, optical focusing techniques that minimize interference from adjacent molecules, and electronic detection methods with high specificity. By improving the precision of data reading and writing processes, these systems effectively reduce cross-talk and enhance the reliability of DNA data storage.
02 Error correction and signal processing for DNA data integrity
Error correction codes and advanced signal processing algorithms are implemented to mitigate cross-talk effects in DNA data storage. These techniques include specialized encoding schemes that can detect and correct errors caused by cross-talk between adjacent DNA sequences. Signal processing methods help filter out noise and interference, enhancing the reliability of data retrieval from DNA storage systems even when cross-talk occurs, thus maintaining data integrity across multiple storage and retrieval cycles.Expand Specific Solutions03 Physical isolation and spatial separation techniques
Physical isolation methods are used to control cross-talk in DNA data storage systems by creating distinct compartmentalization of DNA sequences. These approaches include microfluidic chambers, nanoscale wells, and other physical barriers that separate DNA strands containing different data. By maintaining adequate spatial separation between DNA sequences, these techniques prevent unwanted interactions and hybridizations that could lead to cross-talk, thereby preserving the fidelity of stored information.Expand Specific Solutions04 Chemical and biochemical approaches to reduce interference
Chemical and biochemical strategies are employed to minimize cross-talk in DNA data storage systems. These include specialized buffer solutions, chemical modifications to DNA bases, and controlled reaction environments that reduce non-specific binding. By manipulating the chemical properties of DNA molecules and their surrounding environment, these approaches enhance the specificity of DNA interactions during both writing and reading processes, thereby reducing cross-contamination between different data sequences.Expand Specific Solutions05 Electronic monitoring and control systems
Electronic monitoring and control systems are implemented to detect and mitigate cross-talk in DNA data storage. These systems include sensors that monitor signal integrity, feedback mechanisms that adjust storage and retrieval parameters in real-time, and electronic filters that can distinguish between intended signals and cross-talk noise. By continuously monitoring the storage environment and data transfer processes, these electronic systems can identify potential cross-talk issues and implement corrective measures to maintain data accuracy.Expand Specific Solutions
Leading Organizations in DNA Data Storage Research
DNA data storage technology is currently in an early development stage, characterized by rapid innovation but limited commercial deployment. The market size is projected to grow significantly as storage demands increase, though it remains a niche segment within the broader data storage industry. From a technical maturity perspective, key players are advancing different aspects of primer design and cross-talk control challenges. Microsoft Technology Licensing and University of Washington lead in fundamental research and patent development, while companies like Catalog Technologies focus on practical encoding solutions. Western Digital and Hitachi are leveraging their data storage expertise to explore DNA-based alternatives. Academic institutions including Peking University and Huazhong University of Science & Technology are contributing significant research on cross-talk minimization techniques, while Google explores algorithmic approaches to optimize primer design efficiency.
Western Digital Corp.
Technical Solution: Western Digital has developed proprietary DNA data storage technologies focusing on primer design optimization and cross-talk control for high-density archival applications. Their system employs computational algorithms that generate primer sequences with optimal thermodynamic properties, ensuring specific binding during data retrieval operations. Western Digital's approach incorporates physical separation techniques that organize DNA strands into spatially distinct compartments, reducing the risk of cross-hybridization between data blocks. Their technology utilizes specialized encoding schemes that maintain adequate Hamming distance between primer sequences, minimizing the probability of non-specific amplification. Western Digital has demonstrated the use of multi-layer addressing systems where data blocks are identified by combinations of primers, increasing the theoretical address space while maintaining specificity. Their system includes robust error detection and correction mechanisms that can identify and compensate for synthesis errors in primer regions, improving overall data retrieval reliability.
Strengths: Integration with existing data storage infrastructure; industrial-scale implementation potential; strong focus on reliability and durability. Weaknesses: Less published research compared to academic institutions; potential focus on proprietary rather than open standards; may prioritize commercial applications over fundamental research.
University of Washington
Technical Solution: The University of Washington has developed a comprehensive DNA data storage system with particular focus on primer design optimization and cross-talk minimization. Their approach employs a sophisticated primer design algorithm that generates orthogonal primer sets with minimal sequence similarity, reducing the risk of non-specific amplification during data retrieval. The UW system incorporates a hierarchical addressing scheme where data is organized into logical blocks, each accessible via unique primer pairs that maintain specificity even in complex mixtures. Their technology utilizes molecular simulation tools to predict potential cross-hybridization events before physical implementation, allowing for iterative refinement of primer sequences. The UW team has pioneered the use of "strand displacement" techniques that enable selective access to specific data blocks while minimizing interference with adjacent sequences. Their system includes specialized buffer compositions and thermal cycling protocols that enhance primer specificity during PCR-based retrieval operations, further reducing cross-talk between data blocks.
Strengths: Strong academic research foundation; demonstrated practical implementations; innovative addressing schemes for random access. Weaknesses: May require specialized laboratory expertise; some approaches still at research stage rather than commercial deployment; potential scalability challenges for very large datasets.
Key Innovations in DNA Sequence Encoding and Decoding
Primer design system
PatentInactiveUS20030097223A1
Innovation
- A high-throughput primer design system using bioinformatics to design primers for multiple exons based on nucleotide sequence data from public databases, where PCR is performed using these primers to amplify DNA fragments, and the exons are then determined by analyzing the amplified fragments.

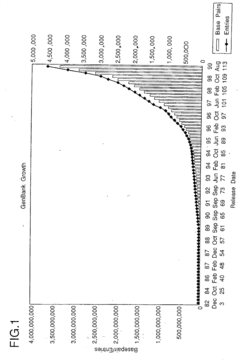
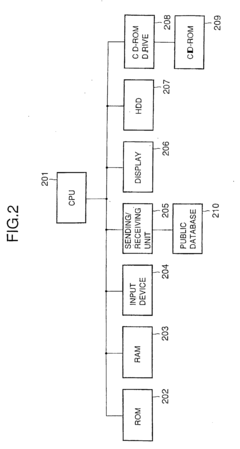
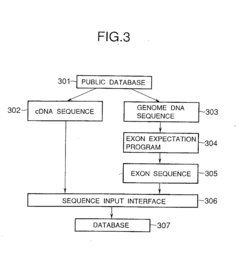
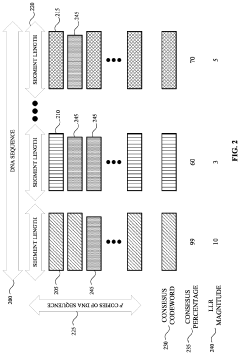
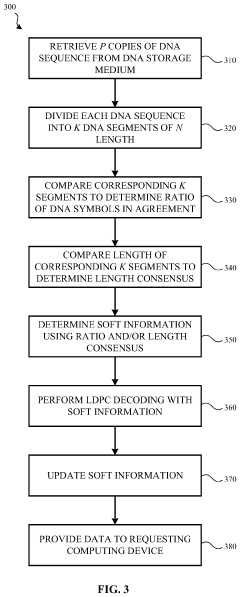
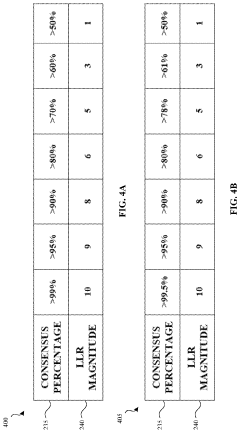
Generating and updating soft information for DNA-based storage systems
PatentPendingUS20240168676A1
Innovation
- Generating and updating soft information by comparing multiple copies of DNA sequences to determine bit error rates and log likelihood ratios, which are then used to enhance the accuracy and efficiency of low-density parity-check (LDPC) codes in DNA-based storage systems.
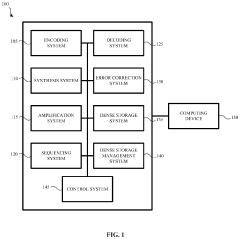
Scalability and Cost Analysis of DNA Data Storage Systems
The economic viability of DNA data storage systems hinges critically on their scalability and cost structure. Current DNA synthesis costs range from $0.001 to $0.2 per nucleotide, with sequencing costs approximately $0.0001 per nucleotide. These figures translate to roughly $1 million per gigabyte for writing and $10,000 per gigabyte for reading - prohibitively expensive compared to conventional electronic storage media. However, historical trends show DNA synthesis costs declining at a rate of 100-fold per decade, suggesting potential economic feasibility within 10-15 years.
Scaling DNA data storage systems presents unique challenges distinct from traditional electronic storage. The molecular nature of DNA storage creates non-linear relationships between system size and operational parameters. For instance, as storage capacity increases, cross-talk between DNA strands becomes exponentially more problematic, requiring more sophisticated primer design strategies. Mathematical models indicate that with current technologies, cross-talk probability increases approximately as O(n²) where n represents the number of unique DNA sequences.
Infrastructure requirements for industrial-scale DNA data storage differ substantially from laboratory implementations. Commercial viability demands automated synthesis and sequencing platforms capable of handling petabyte-scale data. Current estimates suggest that a data center-equivalent DNA storage facility would require approximately 10,000 square feet of laboratory space, specialized environmental controls, and dedicated bioinformatics infrastructure - representing capital expenditures of $50-100 million.
Energy consumption presents a significant advantage for DNA storage systems. While electronic data centers consume 10-20 MW of continuous power, equivalent DNA storage would require only 1-5% of this energy during active reading/writing operations, with negligible energy for long-term storage. This translates to operational cost savings of approximately 95% for archival storage scenarios extending beyond five years.
The economic inflection point for DNA data storage appears to be in long-term, rarely-accessed archival applications. Cost modeling suggests that for data retained over 50+ years with access frequencies below once per decade, DNA storage could become cost-competitive with magnetic tape by approximately 2030, assuming continued technological advancement. The crossover point for more frequently accessed data remains further in the future, likely beyond 2040 without significant technological breakthroughs in primer design and cross-talk control.
Scaling DNA data storage systems presents unique challenges distinct from traditional electronic storage. The molecular nature of DNA storage creates non-linear relationships between system size and operational parameters. For instance, as storage capacity increases, cross-talk between DNA strands becomes exponentially more problematic, requiring more sophisticated primer design strategies. Mathematical models indicate that with current technologies, cross-talk probability increases approximately as O(n²) where n represents the number of unique DNA sequences.
Infrastructure requirements for industrial-scale DNA data storage differ substantially from laboratory implementations. Commercial viability demands automated synthesis and sequencing platforms capable of handling petabyte-scale data. Current estimates suggest that a data center-equivalent DNA storage facility would require approximately 10,000 square feet of laboratory space, specialized environmental controls, and dedicated bioinformatics infrastructure - representing capital expenditures of $50-100 million.
Energy consumption presents a significant advantage for DNA storage systems. While electronic data centers consume 10-20 MW of continuous power, equivalent DNA storage would require only 1-5% of this energy during active reading/writing operations, with negligible energy for long-term storage. This translates to operational cost savings of approximately 95% for archival storage scenarios extending beyond five years.
The economic inflection point for DNA data storage appears to be in long-term, rarely-accessed archival applications. Cost modeling suggests that for data retained over 50+ years with access frequencies below once per decade, DNA storage could become cost-competitive with magnetic tape by approximately 2030, assuming continued technological advancement. The crossover point for more frequently accessed data remains further in the future, likely beyond 2040 without significant technological breakthroughs in primer design and cross-talk control.
Environmental Impact and Sustainability of DNA Storage Technologies
DNA data storage technology, while promising revolutionary advancements in data archiving capabilities, presents significant environmental considerations that must be evaluated alongside its technical merits. The environmental footprint of DNA storage systems differs substantially from conventional electronic storage technologies. DNA synthesis processes currently rely on chemical reagents that may include hazardous materials such as acetonitrile and tetrazole derivatives. However, the environmental impact per bit of information stored is potentially lower than traditional storage media when considering long-term archival scenarios.
The sustainability advantages of DNA storage are particularly noteworthy. DNA molecules can theoretically store information for thousands of years under proper conditions, compared to the 5-10 year lifespan of conventional hard drives. This extended longevity translates to reduced electronic waste generation and decreased resource consumption for replacement media. Furthermore, the information density of DNA (theoretically up to 455 exabytes per gram) means significantly less physical material is required to store equivalent data volumes.
Energy consumption represents another critical environmental consideration. While DNA synthesis and sequencing currently require substantial energy inputs, the storage phase itself is passive, requiring no electricity. This contrasts sharply with data centers that continuously consume electricity for data maintenance. Research by the University of Washington suggests that DNA storage could potentially reduce the carbon footprint of long-term data archiving by orders of magnitude compared to conventional methods.
Primer design and cross-talk control methodologies directly impact environmental sustainability through their influence on synthesis efficiency and error rates. More efficient primers reduce the need for redundant DNA synthesis, thereby minimizing chemical waste and energy consumption. Similarly, effective cross-talk control reduces sequencing errors, decreasing the need for error-correction redundancy and additional sequencing runs.
Emerging green chemistry approaches are being developed specifically for DNA synthesis, including enzyme-based methods that operate in aqueous solutions rather than organic solvents. These approaches promise to further reduce the environmental impact of DNA data storage technologies. Additionally, circular economy principles are being explored for DNA storage systems, including the potential recycling of oligonucleotides and reuse of sequencing equipment.
As DNA data storage technologies mature, life cycle assessment methodologies must be applied to comprehensively evaluate their environmental impact from raw material extraction through synthesis, storage, retrieval, and eventual disposal or recycling. This holistic approach will ensure that the environmental benefits of this promising technology are maximized while potential negative impacts are minimized.
The sustainability advantages of DNA storage are particularly noteworthy. DNA molecules can theoretically store information for thousands of years under proper conditions, compared to the 5-10 year lifespan of conventional hard drives. This extended longevity translates to reduced electronic waste generation and decreased resource consumption for replacement media. Furthermore, the information density of DNA (theoretically up to 455 exabytes per gram) means significantly less physical material is required to store equivalent data volumes.
Energy consumption represents another critical environmental consideration. While DNA synthesis and sequencing currently require substantial energy inputs, the storage phase itself is passive, requiring no electricity. This contrasts sharply with data centers that continuously consume electricity for data maintenance. Research by the University of Washington suggests that DNA storage could potentially reduce the carbon footprint of long-term data archiving by orders of magnitude compared to conventional methods.
Primer design and cross-talk control methodologies directly impact environmental sustainability through their influence on synthesis efficiency and error rates. More efficient primers reduce the need for redundant DNA synthesis, thereby minimizing chemical waste and energy consumption. Similarly, effective cross-talk control reduces sequencing errors, decreasing the need for error-correction redundancy and additional sequencing runs.
Emerging green chemistry approaches are being developed specifically for DNA synthesis, including enzyme-based methods that operate in aqueous solutions rather than organic solvents. These approaches promise to further reduce the environmental impact of DNA data storage technologies. Additionally, circular economy principles are being explored for DNA storage systems, including the potential recycling of oligonucleotides and reuse of sequencing equipment.
As DNA data storage technologies mature, life cycle assessment methodologies must be applied to comprehensively evaluate their environmental impact from raw material extraction through synthesis, storage, retrieval, and eventual disposal or recycling. This holistic approach will ensure that the environmental benefits of this promising technology are maximized while potential negative impacts are minimized.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!