

Random Access And Retrieval Methods In DNA Data Storage
AUG 27, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
DNA Storage Background and Objectives
DNA data storage represents a revolutionary approach to digital information preservation, leveraging the biological molecule's exceptional data density and longevity. Since the concept's introduction in the 1980s, DNA storage has evolved from theoretical possibility to practical implementation, with significant milestones achieved by researchers at Harvard, ETH Zurich, and Microsoft Research demonstrating increasingly efficient encoding and retrieval methods.
The fundamental principle of DNA storage involves converting binary data into nucleotide sequences, synthesizing these sequences into physical DNA molecules, and later sequencing them to retrieve the original information. This approach offers theoretical storage densities of up to 455 exabytes per gram of DNA, far exceeding conventional electronic storage media by orders of magnitude.
The evolution of DNA storage technology has been driven by advances in DNA synthesis and sequencing technologies, computational algorithms for encoding and error correction, and biochemical techniques for DNA manipulation and preservation. The cost trajectory has shown consistent improvement, with synthesis costs decreasing from $10,000 per megabyte in 2000 to approximately $0.01 per megabyte in recent demonstrations.
Random access capability represents a critical technical objective for practical DNA storage systems. Unlike early implementations that required sequencing entire DNA pools to retrieve specific data, modern approaches aim to enable selective retrieval of targeted information without processing the entire archive. This functionality is essential for making DNA storage viable for real-world applications beyond archival purposes.
The primary technical objectives in this field include: developing robust random access methods that minimize false positives and cross-contamination; reducing latency in data retrieval operations; improving encoding density while maintaining error resilience; and establishing standardized protocols for DNA-based information systems that ensure interoperability and longevity.
Long-term goals for DNA storage technology encompass achieving commercially viable cost structures, reducing synthesis and sequencing times to enable practical read/write operations, and developing integrated systems that seamlessly bridge the gap between digital computing infrastructure and biochemical storage media. The ultimate vision is to create hybrid storage architectures where DNA serves as an ultra-dense, energy-efficient tier for cold storage of rarely accessed but valuable data.
The fundamental principle of DNA storage involves converting binary data into nucleotide sequences, synthesizing these sequences into physical DNA molecules, and later sequencing them to retrieve the original information. This approach offers theoretical storage densities of up to 455 exabytes per gram of DNA, far exceeding conventional electronic storage media by orders of magnitude.
The evolution of DNA storage technology has been driven by advances in DNA synthesis and sequencing technologies, computational algorithms for encoding and error correction, and biochemical techniques for DNA manipulation and preservation. The cost trajectory has shown consistent improvement, with synthesis costs decreasing from $10,000 per megabyte in 2000 to approximately $0.01 per megabyte in recent demonstrations.
Random access capability represents a critical technical objective for practical DNA storage systems. Unlike early implementations that required sequencing entire DNA pools to retrieve specific data, modern approaches aim to enable selective retrieval of targeted information without processing the entire archive. This functionality is essential for making DNA storage viable for real-world applications beyond archival purposes.
The primary technical objectives in this field include: developing robust random access methods that minimize false positives and cross-contamination; reducing latency in data retrieval operations; improving encoding density while maintaining error resilience; and establishing standardized protocols for DNA-based information systems that ensure interoperability and longevity.
Long-term goals for DNA storage technology encompass achieving commercially viable cost structures, reducing synthesis and sequencing times to enable practical read/write operations, and developing integrated systems that seamlessly bridge the gap between digital computing infrastructure and biochemical storage media. The ultimate vision is to create hybrid storage architectures where DNA serves as an ultra-dense, energy-efficient tier for cold storage of rarely accessed but valuable data.
Market Analysis for DNA Data Storage Solutions
The DNA data storage market is experiencing significant growth as traditional storage technologies approach their physical limitations. Current market projections indicate the global DNA data storage market will reach approximately $3.3 billion by 2030, with a compound annual growth rate exceeding 70% between 2023-2030. This remarkable growth trajectory is driven by the exponential increase in global data production, which is expected to reach 175 zettabytes by 2025, creating urgent demand for novel storage solutions.
The primary market segments for DNA data storage include government archives, scientific research institutions, healthcare organizations, and large technology companies with massive long-term storage requirements. These sectors prioritize data longevity, security, and density - precisely the advantages that DNA storage offers. Government and national archives represent the largest current market segment, with approximately 40% of pilot projects and investments.
Customer needs analysis reveals several critical requirements driving market adoption. Foremost is the need for efficient random access and retrieval methods, as current technologies often require sequencing entire DNA pools to access specific data fragments. Organizations require retrieval times under 24 hours and error rates below 1 in 10^9 bits to consider DNA storage viable for operational use.
Market barriers include high synthesis and sequencing costs, currently estimated at $0.0001 per base for synthesis and $0.00001 per base for sequencing. These costs must decrease by 2-3 orders of magnitude to achieve broad commercial viability. Additionally, the lack of standardized encoding/decoding protocols and random access methodologies presents significant obstacles to market growth.
Competitive analysis shows several key players developing random access technologies for DNA storage. Catalog Technologies has pioneered enzymatic approaches to data retrieval, while Twist Bioscience focuses on PCR-based random access methods. Microsoft Research, in collaboration with the University of Washington, has developed a promising magnetic bead-based retrieval system that demonstrates 100% accuracy for accessing specific data blocks.
Market forecasts suggest that improved random access technologies could accelerate market adoption by 30-40%, particularly in time-sensitive applications like healthcare and financial services. The development of standardized random access protocols could potentially expand the addressable market by an additional $1.2 billion by 2035.
Regional analysis indicates North America currently dominates the DNA data storage market with approximately 60% share, followed by Europe at 25% and Asia-Pacific at 12%. However, China's significant investments in synthetic biology infrastructure suggest it may become a major market player within the next five years.
The primary market segments for DNA data storage include government archives, scientific research institutions, healthcare organizations, and large technology companies with massive long-term storage requirements. These sectors prioritize data longevity, security, and density - precisely the advantages that DNA storage offers. Government and national archives represent the largest current market segment, with approximately 40% of pilot projects and investments.
Customer needs analysis reveals several critical requirements driving market adoption. Foremost is the need for efficient random access and retrieval methods, as current technologies often require sequencing entire DNA pools to access specific data fragments. Organizations require retrieval times under 24 hours and error rates below 1 in 10^9 bits to consider DNA storage viable for operational use.
Market barriers include high synthesis and sequencing costs, currently estimated at $0.0001 per base for synthesis and $0.00001 per base for sequencing. These costs must decrease by 2-3 orders of magnitude to achieve broad commercial viability. Additionally, the lack of standardized encoding/decoding protocols and random access methodologies presents significant obstacles to market growth.
Competitive analysis shows several key players developing random access technologies for DNA storage. Catalog Technologies has pioneered enzymatic approaches to data retrieval, while Twist Bioscience focuses on PCR-based random access methods. Microsoft Research, in collaboration with the University of Washington, has developed a promising magnetic bead-based retrieval system that demonstrates 100% accuracy for accessing specific data blocks.
Market forecasts suggest that improved random access technologies could accelerate market adoption by 30-40%, particularly in time-sensitive applications like healthcare and financial services. The development of standardized random access protocols could potentially expand the addressable market by an additional $1.2 billion by 2035.
Regional analysis indicates North America currently dominates the DNA data storage market with approximately 60% share, followed by Europe at 25% and Asia-Pacific at 12%. However, China's significant investments in synthetic biology infrastructure suggest it may become a major market player within the next five years.
Current Challenges in DNA Random Access Methods
Despite significant advancements in DNA data storage technology, random access methods continue to face substantial challenges that impede widespread practical implementation. The current PCR-based random access techniques, while functional, suffer from several critical limitations. Primer design complexity represents a major bottleneck, as the need for unique, non-cross-hybridizing primers becomes exponentially more difficult as the data volume increases. This challenge is compounded by the inherent constraints of PCR chemistry, which limits the theoretical maximum number of unique primers available for addressing different data blocks.
Amplification bias presents another significant obstacle, where certain DNA sequences are preferentially amplified during PCR, leading to uneven representation of data and potential information loss. This bias can result in read errors and data corruption, particularly when retrieving specific information from large DNA data pools. Additionally, the physical process of PCR introduces the risk of contamination and unwanted amplification of non-target sequences, further compromising data integrity.
The time efficiency of current random access methods remains problematic for practical applications. PCR-based retrieval typically requires hours to complete, making real-time or rapid data access impossible with existing technologies. This limitation severely restricts the potential use cases for DNA data storage in scenarios requiring quick information retrieval.
Scalability concerns also persist, as current methods struggle to maintain efficiency when scaled to petabyte or exabyte levels of data storage. The addressing system becomes increasingly complex and unwieldy at these scales, necessitating novel approaches to data organization and retrieval. Furthermore, the physical separation of targeted DNA sequences from the larger pool remains technically challenging, often resulting in the retrieval of unwanted sequences alongside the desired data.
Energy consumption represents another significant challenge, with current random access methods requiring substantial thermal cycling and enzymatic processes that consume considerable energy. This high energy requirement contradicts one of the primary advantages of DNA storage – its theoretical energy efficiency compared to electronic storage media.
The integration of random access capabilities with other aspects of the DNA data storage workflow, such as synthesis and sequencing, lacks standardization and seamless compatibility. This fragmentation in the technological ecosystem creates additional barriers to developing end-to-end solutions for practical DNA data storage systems with efficient random access capabilities.
Amplification bias presents another significant obstacle, where certain DNA sequences are preferentially amplified during PCR, leading to uneven representation of data and potential information loss. This bias can result in read errors and data corruption, particularly when retrieving specific information from large DNA data pools. Additionally, the physical process of PCR introduces the risk of contamination and unwanted amplification of non-target sequences, further compromising data integrity.
The time efficiency of current random access methods remains problematic for practical applications. PCR-based retrieval typically requires hours to complete, making real-time or rapid data access impossible with existing technologies. This limitation severely restricts the potential use cases for DNA data storage in scenarios requiring quick information retrieval.
Scalability concerns also persist, as current methods struggle to maintain efficiency when scaled to petabyte or exabyte levels of data storage. The addressing system becomes increasingly complex and unwieldy at these scales, necessitating novel approaches to data organization and retrieval. Furthermore, the physical separation of targeted DNA sequences from the larger pool remains technically challenging, often resulting in the retrieval of unwanted sequences alongside the desired data.
Energy consumption represents another significant challenge, with current random access methods requiring substantial thermal cycling and enzymatic processes that consume considerable energy. This high energy requirement contradicts one of the primary advantages of DNA storage – its theoretical energy efficiency compared to electronic storage media.
The integration of random access capabilities with other aspects of the DNA data storage workflow, such as synthesis and sequencing, lacks standardization and seamless compatibility. This fragmentation in the technological ecosystem creates additional barriers to developing end-to-end solutions for practical DNA data storage systems with efficient random access capabilities.
Current Random Access Retrieval Techniques
01 DNA-based data storage encoding and decoding methods
DNA-based data storage systems utilize specific encoding and decoding methods to convert digital information into DNA sequences and retrieve it back. These methods involve algorithms that translate binary data into nucleotide sequences (A, T, G, C) with error correction capabilities. Advanced encoding schemes optimize for storage density while maintaining data integrity, and specialized decoding techniques ensure accurate retrieval of the original information from synthesized DNA molecules.- PCR-based random access methods for DNA data storage: Polymerase Chain Reaction (PCR) techniques can be used to selectively amplify and retrieve specific DNA sequences from a DNA data storage system. By designing unique primer binding sites that flank the stored data sequences, PCR enables random access to targeted information without needing to sequence the entire DNA archive. This approach significantly improves retrieval efficiency and reduces the time and resources required to access specific data segments within large DNA storage systems.
- Addressing and indexing schemes for DNA data retrieval: Advanced addressing and indexing schemes enable efficient random access to specific data segments within DNA storage systems. These methods involve incorporating unique address sequences or barcodes into DNA strands that store data, allowing for selective retrieval of target information. Hierarchical indexing structures can be implemented to organize DNA-encoded data, similar to file systems in conventional digital storage, facilitating faster search and retrieval operations without processing the entire dataset.
- Microfluidic and nanopore-based DNA data retrieval systems: Microfluidic platforms and nanopore technologies offer innovative approaches for random access and retrieval of DNA-stored data. These systems use specialized channels and pores to isolate and identify specific DNA sequences containing the desired information. Microfluidic devices can separate DNA strands based on their physical or chemical properties, while nanopore systems can read the sequence of individual DNA molecules as they pass through a nanoscale opening, enabling direct access to targeted data without extensive sample preparation.
- CRISPR-Cas based DNA data search and retrieval: CRISPR-Cas systems can be adapted for selective retrieval of specific DNA sequences in DNA data storage applications. By designing guide RNAs that target unique address sequences, CRISPR-Cas proteins can locate and cleave specific DNA fragments containing the desired information, effectively creating a molecular search engine. This biological approach to random access enables highly specific retrieval of data from complex DNA libraries without requiring physical separation of the entire storage medium.
- Error correction and data integrity in DNA retrieval systems: Error correction mechanisms are essential for maintaining data integrity during random access and retrieval from DNA storage systems. These methods include redundancy coding, parity checks, and advanced error-correcting codes specifically designed for the unique error profiles of DNA synthesis, storage, and sequencing. By implementing robust error detection and correction algorithms, these systems can ensure accurate data retrieval even in the presence of mutations, insertions, deletions, or other forms of DNA damage that might occur during long-term storage.
02 Random access mechanisms for DNA data storage
Random access mechanisms allow selective retrieval of specific data segments from DNA storage without sequencing the entire library. These techniques typically employ unique address sequences or primers that flank the stored data, enabling targeted amplification of desired information through PCR-based methods. This approach significantly reduces retrieval time and computational resources compared to sequencing the entire DNA archive, making DNA data storage more practical for real-world applications.Expand Specific Solutions03 Error correction and data integrity in DNA storage
Error correction mechanisms are essential for maintaining data integrity in DNA storage systems due to synthesis errors, sequencing mistakes, and DNA degradation over time. These systems implement redundancy coding, parity checks, and specialized algorithms to detect and correct errors during both storage and retrieval processes. Advanced error correction techniques can recover original data even when portions of the DNA molecules are damaged or lost, ensuring reliable long-term storage.Expand Specific Solutions04 Physical storage and retrieval infrastructure for DNA data
Physical infrastructure for DNA data storage includes specialized hardware and microfluidic systems for organizing, preserving, and accessing DNA libraries. These systems incorporate automated sample handling, temperature-controlled storage environments, and integration with synthesis and sequencing technologies. Modern DNA storage architectures may include compartmentalized storage units, barcoding systems for physical organization, and robotic retrieval mechanisms to enable efficient access to specific data segments.Expand Specific Solutions05 Indexing and addressing strategies for DNA data retrieval
Indexing and addressing strategies create organizational frameworks that enable efficient location and retrieval of specific data within large DNA storage archives. These approaches include hierarchical addressing schemes, molecular barcoding, and metadata management systems that map between digital addresses and physical DNA locations. Advanced indexing methods optimize search operations by creating logical structures that minimize the number of PCR or sequencing operations needed to locate and retrieve targeted information.Expand Specific Solutions
Leading Organizations in DNA Data Storage Research
DNA data storage technology is currently in an early development phase, characterized by significant research activity but limited commercial deployment. The market, while still nascent with an estimated value under $100 million, shows promising growth potential as data storage demands increase exponentially. Technologically, the field is advancing rapidly with key players demonstrating varied maturity levels. Microsoft leads commercial development with practical storage systems and random access capabilities, while academic institutions like Tsinghua University and Tianjin University contribute fundamental research breakthroughs. Illumina and BGI leverage their sequencing expertise to address retrieval challenges, while specialized companies such as Guardant Health and Annoroad Gene Technology are developing complementary technologies for efficient DNA data manipulation and access methods.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft has pioneered significant advancements in DNA data storage through their molecular information systems research. Their approach utilizes synthetic DNA molecules to encode digital data, achieving remarkable storage density of approximately 1 exabyte per cubic inch[1]. Microsoft's random access method employs PCR-based techniques with unique address sequences flanking data-bearing DNA segments, allowing selective amplification and retrieval of specific data blocks without accessing the entire dataset[2]. Their system incorporates error-correction codes specifically designed for the DNA medium, addressing the unique error profiles of synthesis and sequencing. Microsoft has also developed specialized encoding algorithms that translate binary data into DNA nucleotide sequences while avoiding problematic sequence patterns that could cause errors during synthesis or sequencing[3]. Their end-to-end system architecture integrates these components with automated liquid handling systems for practical implementation.
Strengths: Industry-leading storage density; robust error correction tailored to DNA medium; demonstrated practical random access capabilities with selective retrieval. Weaknesses: Still requires specialized laboratory equipment; relatively slow read/write speeds compared to electronic storage; higher cost per byte than conventional storage methods; limited write-rewrite cycles.
Illumina, Inc.
Technical Solution: Illumina has developed advanced sequencing-based retrieval methods for DNA data storage that leverage their industry-leading next-generation sequencing (NGS) technology. Their approach integrates specialized library preparation techniques with high-throughput sequencing to enable efficient random access to stored information[1]. The company's system employs unique molecular identifiers (UMIs) and custom indexing strategies that allow for selective amplification and sequencing of targeted data regions without processing the entire DNA archive[2]. Illumina's platform incorporates proprietary sequencing chemistry optimized for synthetic DNA reading, achieving error rates below 0.1% through their advanced base-calling algorithms and quality scoring systems[3]. Their technology stack includes specialized bioinformatics tools designed specifically for decoding and error correction of data stored in synthetic DNA, with particular attention to handling homopolymer runs and GC-content variations that typically challenge sequencing accuracy[4]. The system architecture supports parallel retrieval operations, significantly improving data access times compared to earlier DNA storage implementations.
Strengths: Exceptional sequencing accuracy; high-throughput parallel reading capabilities; established global infrastructure and expertise in sequencing technology; integrated workflow from DNA preparation to data retrieval. Weaknesses: Higher equipment costs than some competitors; dependence on proprietary reagents and instruments; limited focus on the writing/synthesis aspect of DNA storage; retrieval speed still significantly slower than electronic storage.
Key Innovations in DNA Addressing Systems
Re-writable DNA-Based Digital Storage with Random Access
PatentActiveUS20200035331A1
Innovation
- The implementation of a DNA sequence encoding method that uses unique address sequences at each end of data blocks, allowing for random access by using PCR amplification and sequencing, and enabling data rewriting through DNA editing techniques, ensuring high probability of selecting the correct data block and allowing for replacement or modification of stored information.
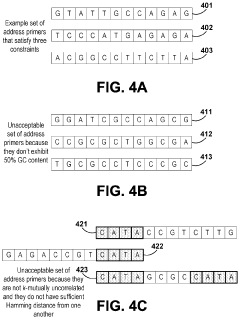
A random access method for single-stranded DNA data storage information
PatentActiveCN113981053B
Innovation
- Design stem-loop primers with selectivity enhancement modules to identify target DNA fragments through complementary pairing of fixed loop regions and stem regions, and combine with specific polymerase chain reactions to achieve high selectivity and high-precision randomization of DNA data storage information. access.
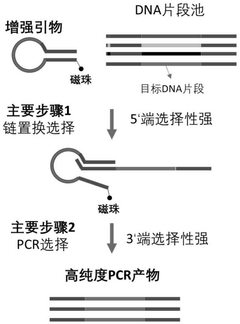
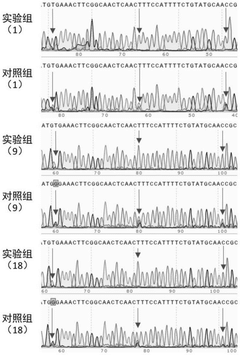
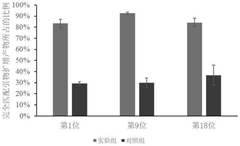
Scalability and Cost Considerations
The scalability of DNA data storage systems presents significant challenges as data volumes continue to grow exponentially. Current DNA synthesis technologies face throughput limitations, with commercial platforms typically producing oligonucleotides at rates insufficient for large-scale data storage applications. The synthesis cost remains prohibitively high at approximately $0.001 per nucleotide, translating to roughly $1 million per gigabyte of stored data. This economic barrier severely restricts widespread adoption despite DNA's theoretical storage density advantages.
Random access capabilities further complicate scalability considerations. While PCR-based retrieval methods offer specificity, they become increasingly inefficient when scaled to petabyte-level archives. The amplification process introduces bias and potential data corruption when attempting to access specific data fragments within massive DNA pools. Additionally, the time required for retrieval operations increases substantially with archive size, creating bottlenecks in practical applications.
Physical infrastructure requirements represent another dimension of the scalability challenge. DNA storage systems require specialized laboratory equipment for synthesis, storage, and sequencing processes. These facilities demand controlled environmental conditions and trained personnel, adding operational overhead that scales with system capacity. The centralized nature of such infrastructure limits geographical distribution and redundancy options compared to traditional digital storage systems.
Energy consumption patterns differ significantly from electronic storage. While DNA storage requires minimal energy for long-term preservation (theoretically lasting thousands of years at appropriate temperatures), the energy demands for writing and reading operations are currently intensive. Synthesis and sequencing processes consume substantial power, though this is partially offset by the negligible maintenance energy requirements during storage periods.
Technological convergence may offer pathways to improved scalability. Emerging microfluidic platforms and enzymatic synthesis methods show promise for reducing both cost and physical footprint. These approaches could potentially decrease synthesis costs by orders of magnitude while increasing throughput. Similarly, nanopore sequencing technologies continue to evolve toward faster, more portable reading capabilities that could address retrieval bottlenecks.
Economic models suggest that DNA data storage may initially find viability in specialized archival applications where long-term preservation justifies higher upfront costs. The crossover point where DNA storage becomes economically competitive with traditional methods depends heavily on synthesis cost reductions and improvements in random access efficiency. Current projections indicate that at least a 100-fold decrease in synthesis costs would be necessary before DNA storage could compete in broader market segments.
Random access capabilities further complicate scalability considerations. While PCR-based retrieval methods offer specificity, they become increasingly inefficient when scaled to petabyte-level archives. The amplification process introduces bias and potential data corruption when attempting to access specific data fragments within massive DNA pools. Additionally, the time required for retrieval operations increases substantially with archive size, creating bottlenecks in practical applications.
Physical infrastructure requirements represent another dimension of the scalability challenge. DNA storage systems require specialized laboratory equipment for synthesis, storage, and sequencing processes. These facilities demand controlled environmental conditions and trained personnel, adding operational overhead that scales with system capacity. The centralized nature of such infrastructure limits geographical distribution and redundancy options compared to traditional digital storage systems.
Energy consumption patterns differ significantly from electronic storage. While DNA storage requires minimal energy for long-term preservation (theoretically lasting thousands of years at appropriate temperatures), the energy demands for writing and reading operations are currently intensive. Synthesis and sequencing processes consume substantial power, though this is partially offset by the negligible maintenance energy requirements during storage periods.
Technological convergence may offer pathways to improved scalability. Emerging microfluidic platforms and enzymatic synthesis methods show promise for reducing both cost and physical footprint. These approaches could potentially decrease synthesis costs by orders of magnitude while increasing throughput. Similarly, nanopore sequencing technologies continue to evolve toward faster, more portable reading capabilities that could address retrieval bottlenecks.
Economic models suggest that DNA data storage may initially find viability in specialized archival applications where long-term preservation justifies higher upfront costs. The crossover point where DNA storage becomes economically competitive with traditional methods depends heavily on synthesis cost reductions and improvements in random access efficiency. Current projections indicate that at least a 100-fold decrease in synthesis costs would be necessary before DNA storage could compete in broader market segments.
Standardization Efforts in DNA Storage
The standardization of DNA storage technologies represents a critical step toward widespread commercial adoption and interoperability across different platforms and implementations. Currently, several international organizations are actively developing frameworks and protocols to establish common standards in this emerging field.
The DNA Data Storage Alliance, formed in 2020 by industry leaders including Illumina, Microsoft Research, Twist Bioscience, and Western Digital, has been instrumental in creating technical specifications for DNA-based storage systems. Their working groups focus on developing standardized approaches for encoding, random access mechanisms, and retrieval methodologies that can be universally implemented across different technological platforms.
ISO/IEC JTC 1/SC 29 has initiated work on standardizing DNA storage under the broader digital storage standardization efforts. Their technical committee is specifically addressing the development of standardized file formats, metadata structures, and access protocols that would enable seamless integration of DNA storage with existing digital infrastructure while supporting efficient random access capabilities.
The IEEE has established the IEEE 2410 working group dedicated to standardizing aspects of synthetic DNA storage, with particular emphasis on developing common interfaces for random access and retrieval operations. Their framework aims to ensure that DNA storage systems from different manufacturers can interact effectively while maintaining consistent performance metrics for data access times and retrieval accuracy.
SNIA (Storage Networking Industry Association) has incorporated DNA storage considerations into their technical roadmap, focusing on standardizing the integration of DNA-based systems with conventional storage architectures. Their efforts include defining standard APIs for random access operations and establishing performance benchmarks specific to DNA storage retrieval methods.
Academia-industry collaborations, such as those coordinated through the Molecular Information Storage (MIST) consortium, are contributing to standardization by developing open reference architectures for DNA storage systems with standardized random access protocols. These collaborative efforts aim to accelerate the development of practical implementations while ensuring cross-compatibility.
Key challenges in standardization include reconciling the diverse approaches to random access markers, addressing the variability in DNA synthesis and sequencing technologies, and establishing common metrics for evaluating retrieval efficiency. The development of standardized error correction codes specifically optimized for DNA storage represents another critical area requiring consensus among stakeholders.
As the field matures, these standardization efforts will likely converge toward a unified framework that balances technological innovation with practical implementation considerations, ultimately facilitating the transition of DNA storage from research laboratories to commercial applications.
The DNA Data Storage Alliance, formed in 2020 by industry leaders including Illumina, Microsoft Research, Twist Bioscience, and Western Digital, has been instrumental in creating technical specifications for DNA-based storage systems. Their working groups focus on developing standardized approaches for encoding, random access mechanisms, and retrieval methodologies that can be universally implemented across different technological platforms.
ISO/IEC JTC 1/SC 29 has initiated work on standardizing DNA storage under the broader digital storage standardization efforts. Their technical committee is specifically addressing the development of standardized file formats, metadata structures, and access protocols that would enable seamless integration of DNA storage with existing digital infrastructure while supporting efficient random access capabilities.
The IEEE has established the IEEE 2410 working group dedicated to standardizing aspects of synthetic DNA storage, with particular emphasis on developing common interfaces for random access and retrieval operations. Their framework aims to ensure that DNA storage systems from different manufacturers can interact effectively while maintaining consistent performance metrics for data access times and retrieval accuracy.
SNIA (Storage Networking Industry Association) has incorporated DNA storage considerations into their technical roadmap, focusing on standardizing the integration of DNA-based systems with conventional storage architectures. Their efforts include defining standard APIs for random access operations and establishing performance benchmarks specific to DNA storage retrieval methods.
Academia-industry collaborations, such as those coordinated through the Molecular Information Storage (MIST) consortium, are contributing to standardization by developing open reference architectures for DNA storage systems with standardized random access protocols. These collaborative efforts aim to accelerate the development of practical implementations while ensuring cross-compatibility.
Key challenges in standardization include reconciling the diverse approaches to random access markers, addressing the variability in DNA synthesis and sequencing technologies, and establishing common metrics for evaluating retrieval efficiency. The development of standardized error correction codes specifically optimized for DNA storage represents another critical area requiring consensus among stakeholders.
As the field matures, these standardization efforts will likely converge toward a unified framework that balances technological innovation with practical implementation considerations, ultimately facilitating the transition of DNA storage from research laboratories to commercial applications.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!